
增强的张量鲁棒主成分分析模型及其应用
2022-11-03 11:41:00赵奉营杨宏伟赵丽娜
北京化工大学学报(自然科学版) 2022年4期
赵奉营 杨宏伟 赵丽娜*
(北京化工大学1.数理学院;2.信息中心, 北京 100029)
引 言
鲁棒主成分分析(RPCA)是低秩恢复问题的一种。 Candès 等[1]提出基于矩阵的RPCA 方法(matrix RPCA, MRPCA),能够从被稀疏大噪声损坏的观测数据中恢复出隐含的低秩分量;MRPCA 将观测数据分解为低秩分量和稀疏分量,用矩阵核范数约束低秩分量,矩阵范数约束稀疏分量。 该模型简单且易于求解,被广泛应用在视觉处理任务中,如图像恢复和背景建模[1-2]。 但是MRPCA 方法会将观测数据矩阵化,这样的预处理步骤会导致不必要的信息损失,带来次优的恢复结果。 针对此问题,许多基于张量的RPCA 方法被相继提出,如基于Tucker 分解[3]的求和核范 数(sum nuclear norm,SNN) 模型[4]、基于张量火车分解[5]的张量火车核范数(tensor train nuclear norm,TTNN)模型[6]和基于张量环(tensor ring,TR) 分解的鲁棒张量环补全(robust tensor ring completion,RTRC)模型[7]等。 为了刻画张量不同模型之间的相关性,研究者们在SNN、TTNN 和RTRC 中通过特殊的矩阵化策略将张量展开为一组矩阵,提出了可用交替方向乘子算法(ADMM) 求解的张量鲁棒主成分分析(tensor-RPCA,TRPCA)模型。 Kilmer 等[8]提出了一种新的张量乘法t 积(tensor-tensor product)和张量奇异值分解(tensor singular value decomposition,t-SVD)策略。 在t 积和t-SVD 的张量框架下,Lu 等[2]提出了张量核范数(tensor nuclear norm,TNN)概念,Zhou等[9]提出了张量低秩表示(low rank tensor representation,LRTR)模型。 在TNN 和LRTR 模型中,以基于t 积的张量核范数t-TNN 作为tubal 秩的凸包络,t-TNN 等价于张量的所有前切片组成的块循环矩阵的核范数或者张量按模3 方向作离散傅里叶变换所得张量的所有前切片组成的块对角矩阵的核范数,因此t-TNN 可以看作一种特殊的矩阵化方式,用来刻画张量的空间信息和第三通道的相关性。 此外,t-SVD 可以利用快速傅里叶变换加速计算,并且tubal 秩可以描述张量子空间结构。 上述模型在图像恢复和背景建模中取得了较好的效果,但是对输入数据低秩结构的强依赖性问题仍然没有得到解决。
针对上述问题,本文在t 积和t-SVD 的张量框架下提出一个增强的张量鲁棒主成分分析模型(E-TRPCA)用于图像恢复和背景建模。 首先学习得到一个字典张量,并构造了一个增强的张量核范数(E-TNN)正则项;其次,在低秩张量表示的基础上,提出了一个去随机噪声的模型;最后,设计了一个高效的交替方向乘子算法来解决所提出的问题。在图像恢复和背景建模上的实验证明了所提方法的优越性。
1 张量奇异值分解框架
1.1 符号说明
给定 张量A ∈Rh×w×s,A(1,:,:)、A(:,1,:)以 及A(:,:,1)分别是A 的第一个横切片、第一个侧切片和第一个前切片,Ai,j,k是A 在(i,j,k)位置的元素。unfold()运算将张量展开为矩阵,fold()运算是其逆运算。
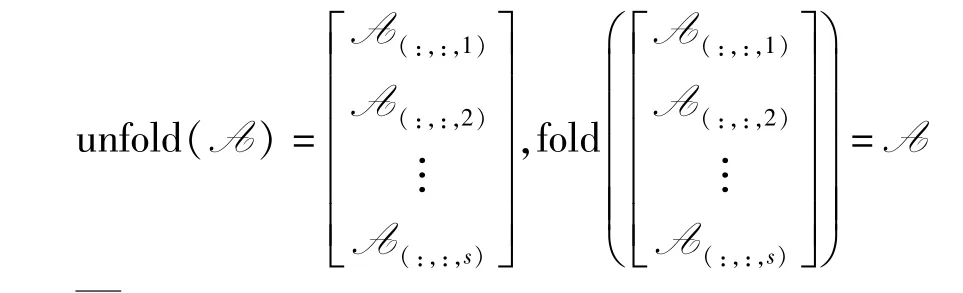
A=fft(A,[],3)记为对A 的每个管道的离散傅里叶变换。

bcirc()运算是将张量A 变为块循环矩阵的运算
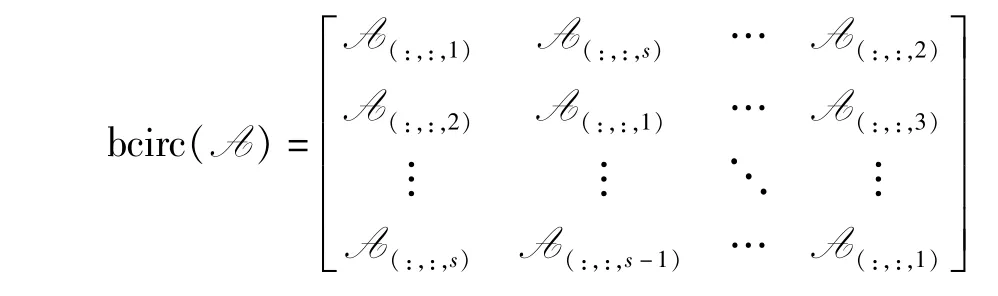
1.2 t 积和张量奇异值分解
定义1(t 积) 给定张量A ∈Rh×l×s,B ∈Rl×w×s,则t 积定义为[8]
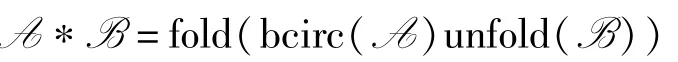
定义2(正交张量) 如果Q∈Rn×n×l满足QT*Q = Q*QT= I∈Rn×n×l,则Q 为正交张量。 进一步,如果Q∈Rp×q×l满足QT*Q=I∈Rq×q×l,则Q 为部分正交张量。
定义3(张量奇异值分解)[2]给定张量A∈Rh×w×s,它可以分解为如下形式
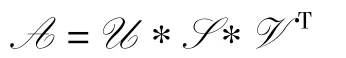
式中,U∈Rh×h×s,V∈Rw×w×s是正交张量,S∈Rh×w×s是f-diagonal张量。
定义4(管道秩) 给定张量A∈Rh×w×s,则张量的管道秩为S 中非零管道的个数[10],记为rankt(A)
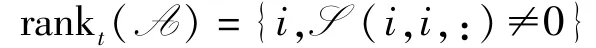
式中,A=U*S*VT是A 的t-SVD 分解。
定义5(张量核范数)[2]A =U*S*VT是A 的t-SVD,A∈Rh×w×s,则A 的核范数表示为
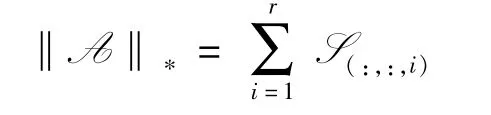
其中,r=rankt(A)。
引理1张量A∈Rh×w×s,B∈Rw×h×s,令F =A*B,则有:
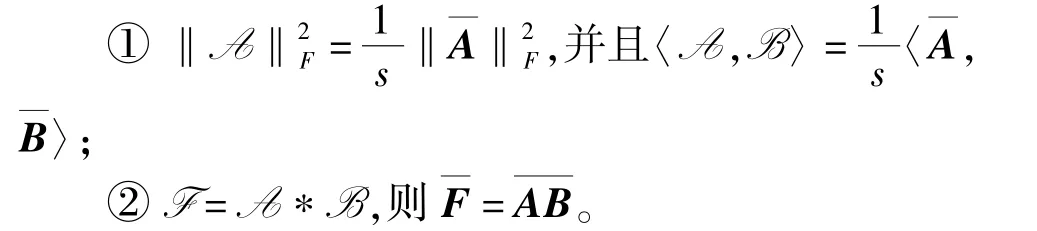
引理2[11]∀A∈Rm×n,则问题
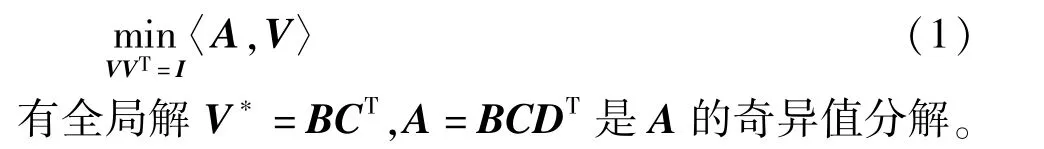
根据引理1,本文给出了引理2 的张量推广形式。
定理1任给张量A∈Rh×w×s,问题

证明由引理1 以及的块对角结构可知,问题(2)可以分解为以下子问题
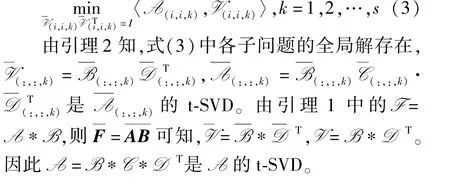
2 E-TRPCA 方法
2.1 基于t-SVD 的E-TRPCA 模型
如图1 所示,矩阵可以分解为两个矩阵的积[12]
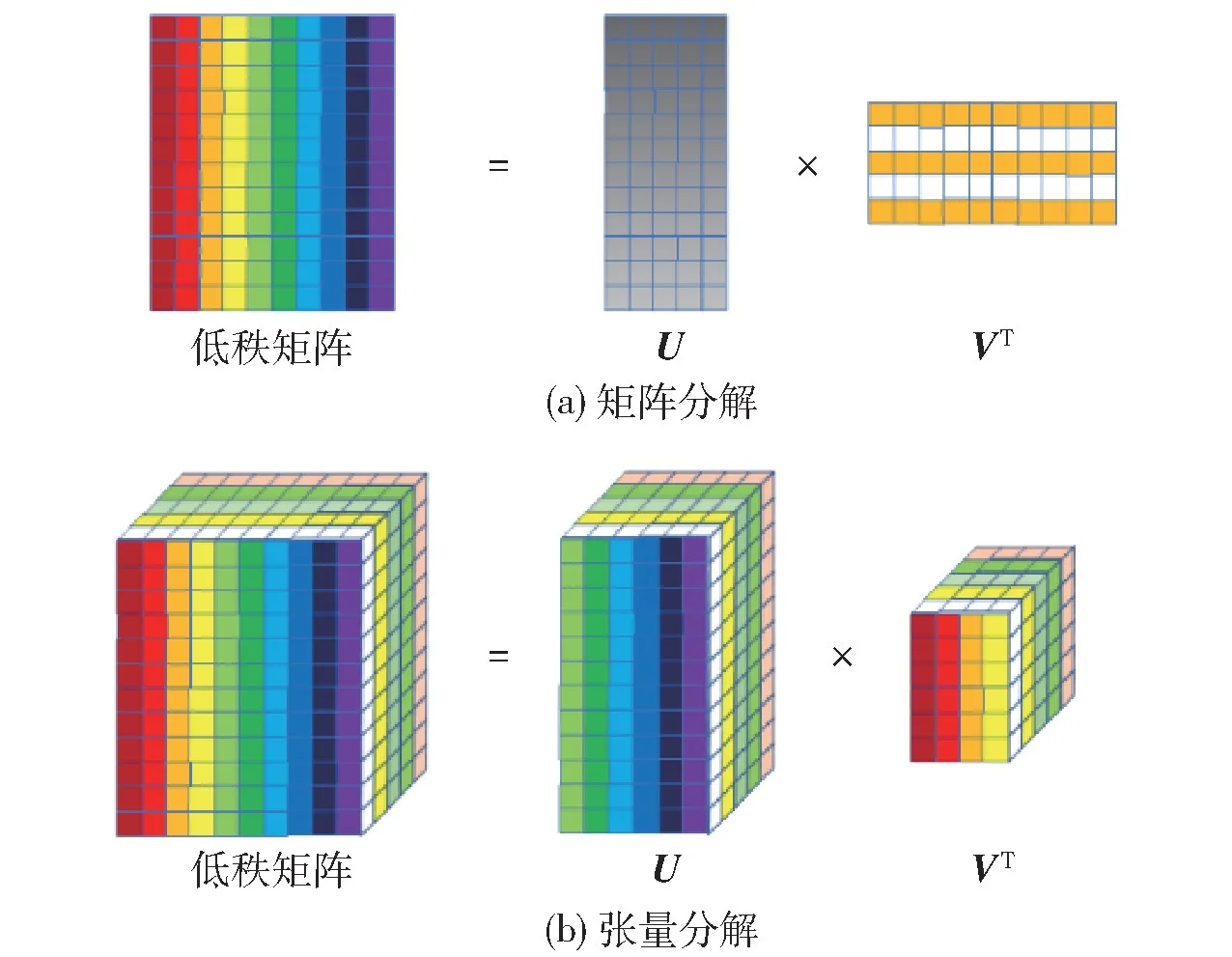
图1 低秩分解Fig.1 Low-rank factorization

借助t 积,可以把矩阵的情形推广到张量情形
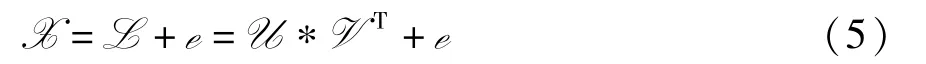
事实上,如果对V 施加一个正交约束,则有U=L*V。 与传统的核范数最小化(nuclear norm minimization,NNM)问题相同,对分量U施加低秩约束,则可以构造如下E-TNN 正则项
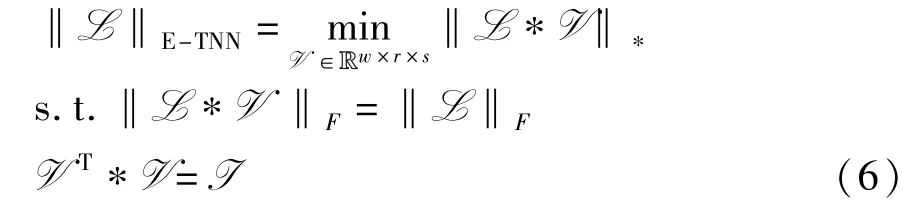
第一个是约束在变换结果L*V 上的Frobenius范数,这有助于避免变换引起的信息损失;第二个是对V 的正交约束,倾向于使变换后的结果L*V 尽可能保留低秩张量L 的信息,此外它还可以帮助获得该变量的闭式解。 由于不容易直接求解上述问题,因此将式(6)重新表述为以下等价问题
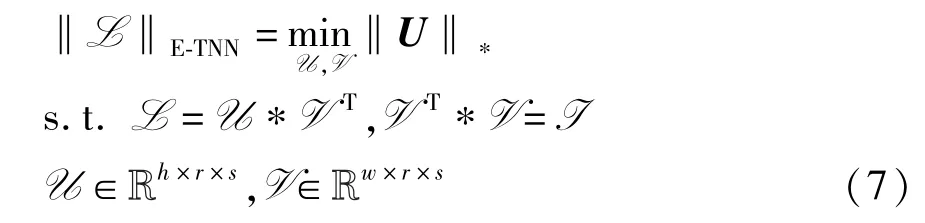
与TNN 一样,E-TNN 同样作用在分量L 上,不同之处在于E-TNN 不直接约束L 本身,而是约束从L 中学习得到的一组基,这组基是L 的所有侧切面的一个线性表示[9]。 矩阵分解可以把矩阵分解为字典和稀疏矩阵的积,因此,借助上述张量工具,把分量L 分解为字典张量U 和投影张量V 的共轭转置的乘积。 字典张量U 由分量L 经过正交变换得到:U = L*V,V 是正交变换张量,维度为w×r×s,r<w。 另外,字典张量U 的规模总是小于低秩分量L,这使得它们受到噪声损坏的影响较小,从而可以获得更鲁棒的恢复效果。
将E-TNN 正则项嵌入到TRPCA 模型,得到如下低秩张量恢复模型
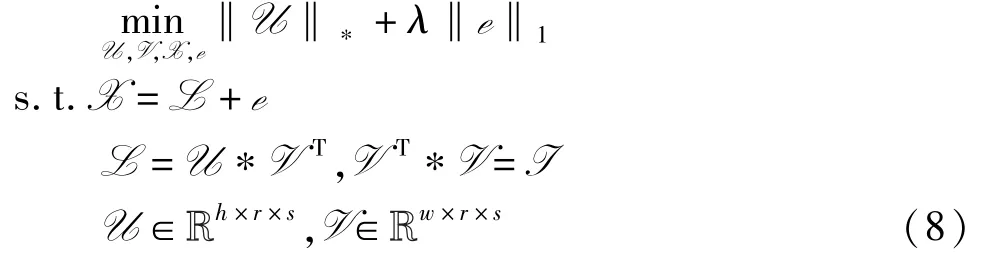
式中X,L,e∈Rh×w×s分别为观测张量、低秩张量和稀疏张量,l1范数来约束稀疏张量,λ为超参数。
2.2 ADMM 优化
本节中,通过ADMM 算法[13]求解模型(8)。 由模型(8)得到以下增广拉格朗日函数。
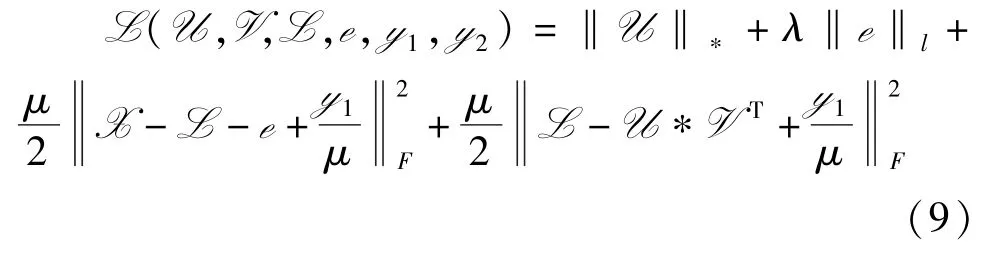
式中,μ为惩罚项系数。 ADMM 可以把上述问题分解为如下的5 个子问题,在每一个子问题中,固定其余变量不变,只更新一个变量。
L 子问题 从式(9)中找出所有包含L 的项,得到如下更新公式
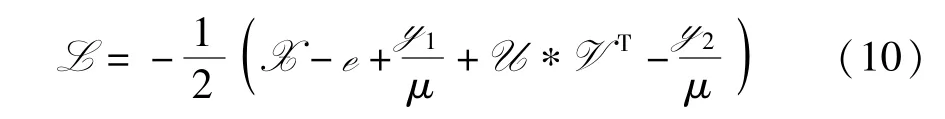
U 子问题 从式(9)中找出所有包含U 的项,得到如下问题
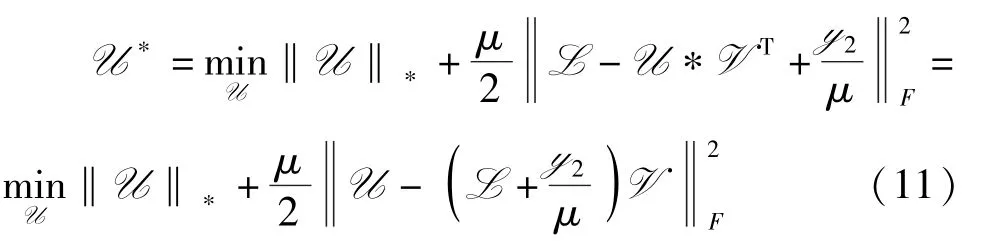
这个子问题可以通过张量奇异值阈值算子[2]求解
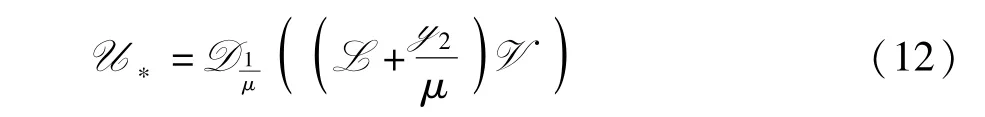
V 子问题 从式(9)中找出所有包含V 的项,令P=L+,得到如下问题
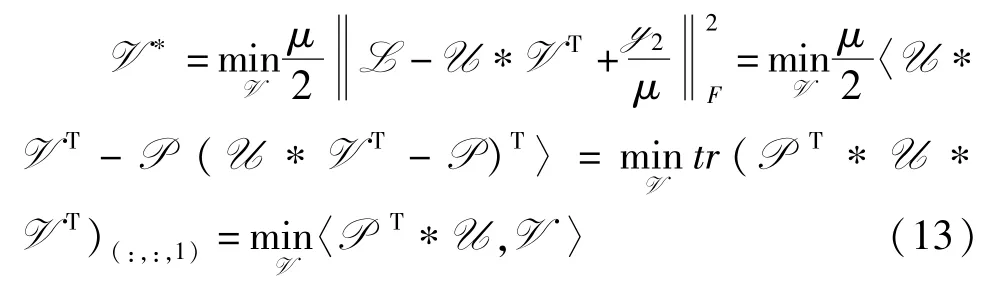
由定理1 可知
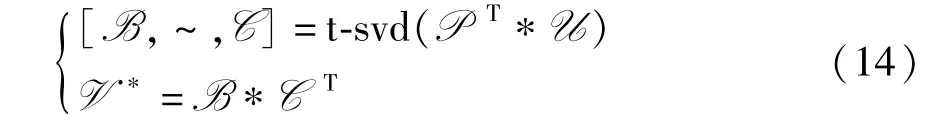
e 子问题 从式(9)中找出所有包含e 的项,得到如下问题
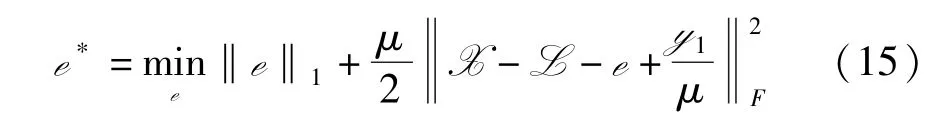
这个子问题可以通过软阈值收缩算子[14]来得到闭式解
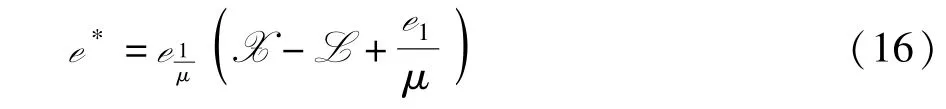
拉格朗日乘子 y1,y2通过如下公式来更新
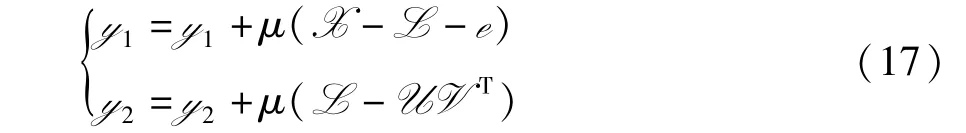
综上所述,求解E-TRPCA 模型(8)的ADMM算法(算法1)详细过程如下。

2.3 复杂度分析
算法1 以三阶张量X∈Rh×w×s作为输入,主要的计算成本是在更新U,V 时产生的。 更新U 需要计算一个大小为h×w×s张量的t-SVD,更新V时需要计算一个大小为w×r×s张量的t-SVD,那么算法1 的时间复杂度为O(max(h,w)rslogs+(max(h,w)r2s))。
3 实验验证
以图像恢复作为仿真实验、背景建模作为真实实验来测试所提方法,并与RPCA 方法[1]、基于Tucker 分解的SNN 方法[4]、基于t-SVD 的TNN 方法[2]、基于张量火车分解的TTNN 方法[6]和基于张量环分解的RTRC 方法[7]这5 种方法进行对比。 其中,RTRC 方法被用来解决张量补全问题,在本文中用于张量鲁棒主成分分析,记为TRNN(tensor ring nuclear norm)。 图像恢复实验中的图片和背景建模中的视频分别用三阶张量和四阶张量存储,它们的值均被缩放到[0,1]。
3.1 图像恢复
使用伯克利分割数据集[15]中的彩色图像进行测试。 图片的大小为321 ×481 ×3 或481 ×321 ×3。 RPCA、TNN、TRNN 和本文方法可以直接处理三阶张量,TTNN 方法在数据输入模型之前采用ketaugmentation (KA)技术作了数据增强处理,因此需要把图片大小调整为320×480×3,再利用KA 方法将图片尺寸转化为[4×4×4×5×4×4×5×6×3]。
噪声模拟 本文主要去除图像中的随机噪声,随机噪声比例p分别设为0.1、0.2、0.3,以p=0.1为例,即图像有10%的像素被设为区间[0,1]之间的一个随机值,被破坏的像素的位置是随机的。
评价指标 为了评价比较方法去除随机噪声的性能,选取峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity index,SSIM)作为评价指标[16],PSNR 值和SSIM 值越高,表示恢复结果越好。
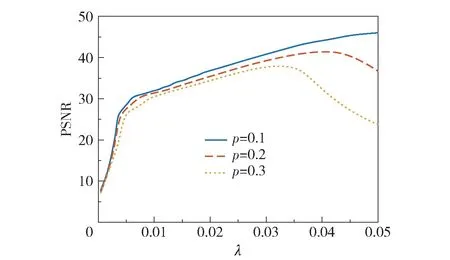
图2 p=0.1,0.2,0.3 时,PSNR 值随λ 的变化曲线Fig.2 PSNR values changing with λ for p=0.1,0.2,0.3
Tubal 秩r用于刻画图像的低秩性。 本文通过遍历r来分析tubal 秩对PSNR 的影响。 由图3(b)可知,随着r的增大,图像的恢复效果也越来越好。为了在效率和性能之间取得一个平衡,将r设为。
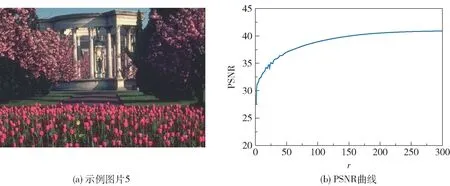
图3 管道秩对PSNR 值的影响Fig.3 The effect of tubal rank on PSNR value
1)视觉效果比较
为了直观地对比图像的恢复结果,从伯克利分割数据集中选取了6 张示例图片进行可视化展示。从图4 ~9 中可以看出,RPCA、SNN、TTNN 和TRNN算法虽然能够去除图片中的随机噪声和椒盐噪声,但这4 种方法不能很好地保留图像中的细节。图4(h) ~9(h)展示了本文所提模型的恢复结果,可以看到添加的噪声被去除,并且图像中的纹理和边缘也得到了很好的保留。 这说明本文提出的E-TNN正则项要比t-SVD 张量框架下的张量核范数更有效。

图4 所有对比方法在示例图片1 下的恢复结果(p=0.1)Fig.4 Restoration results of all competing methods for example image 1(p=0.1)

图5 所有对比方法在示例图片2 下的恢复结果(p=0.1)Fig.5 Restoration results of all competing methods for example image 2(p=0.1)

图6 所有对比方法在示例图片3 下的恢复结果(p=0.1)Fig.6 Restoration results of all competing methods for example image 3(p=0.1)

图7 所有对比方法在示例图片4 下的恢复结果(p=0.1)Fig.7 Restoration results of all competing methods for example image 4(p=0.1)

图8 所有对比方法在示例图片5 下的恢复结果(p=0.1)Fig.8 Restoration results of all competing methods for example image 5(p=0.1)
2) 定量结果比较
表1 ~3 分别是6 张示例图片在不同随机噪声比例p=0.1、0.2、0.3 下的PSNR 值和SSIM 值。 可以看出,本文所提模型的PSNR 评价指标在所有的噪声比例中都取得了最好的结果,而且在SSIM 评价指标上也基本上取得了最优或次优的结果。
图10 给出了在p=0.1 时伯克利分割数据集50张图片的PSNR 值和运行时间的比较。 可以看出,与其他几种算法相比,本文所提方法取得的PSNR值最高,并且运行所需时间也仅次于TRNN 方法,远低于其他方法。
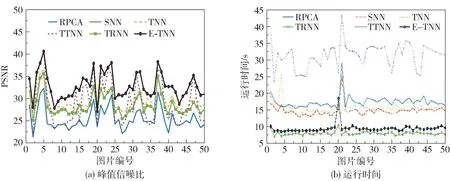
图10 各对比方法在伯克利分割数据集50 张图像上的定量结果比较Fig.10 Quantitative comparison of all competing methods on 50 images of the Berkeley segmentation dataset
此外,由表1 ~3 可知,在示例图片1 和示例图片5 中,所有方法都没有取得比较好的恢复效果,而示例图片4 和示例图片6 的恢复效果较好。
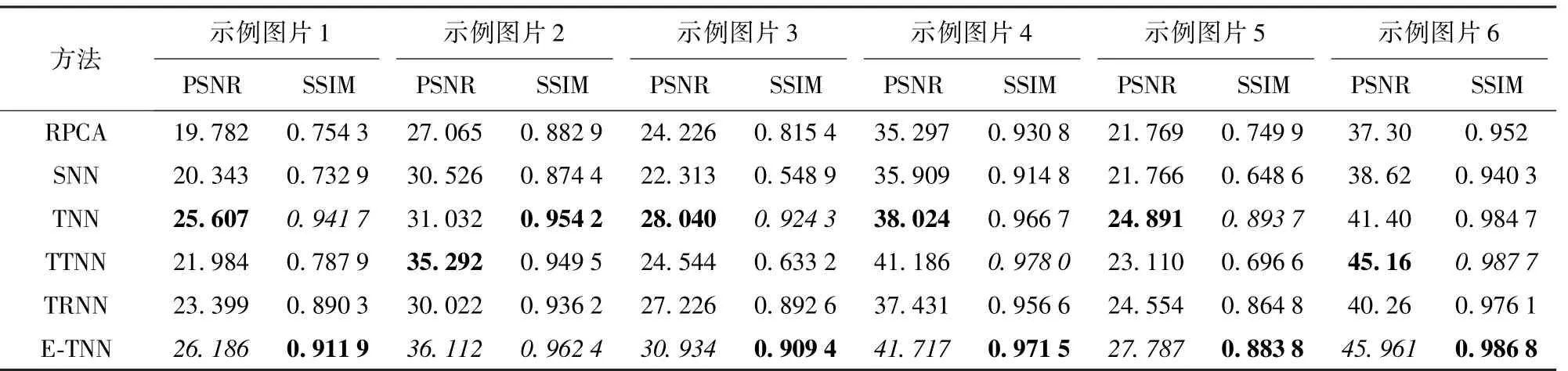
表1 各对比方法在p=0.1 下的PSNR 和SSIM 值比较Table 1 Comparison of the PSNR and SSIM values obtained using all competing methods with p=0.1
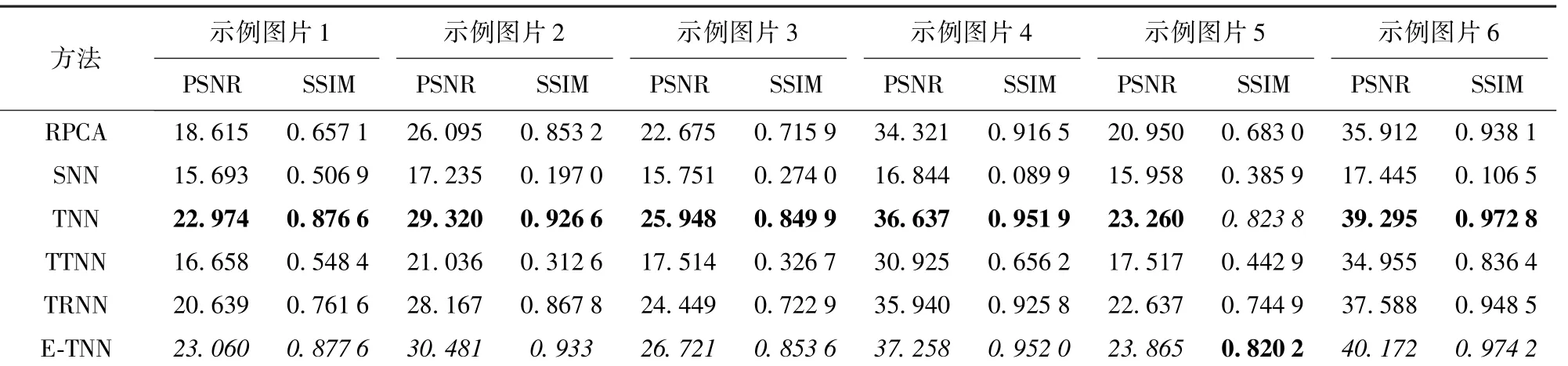
表2 各对比方法在p=0.2 下的PSNR 和SSIM 值比较Table 2 Comparison of the PSNR and SSIM values obtained using all competing methods with p=0.2
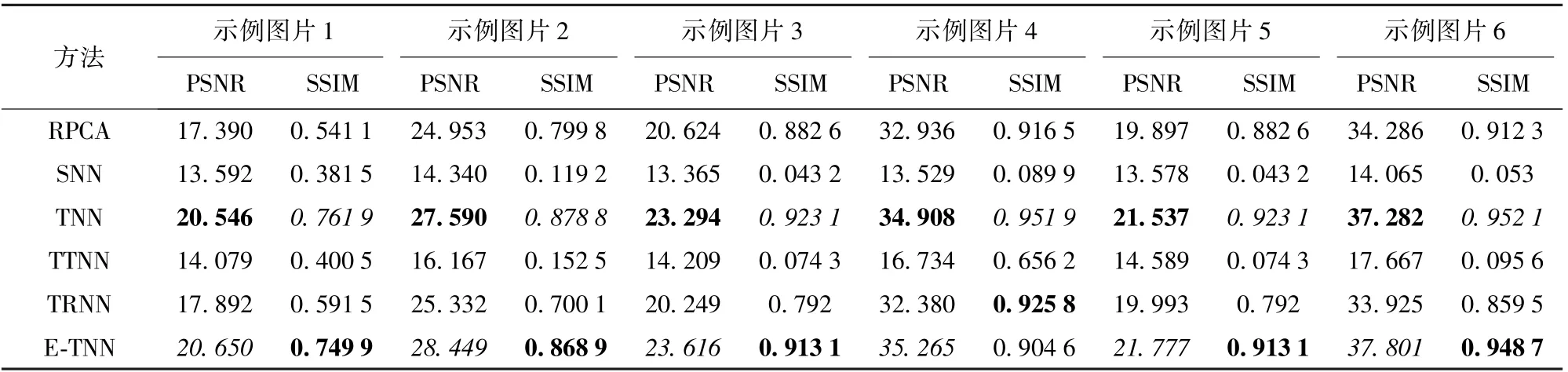
表3 各对比方法在p=0.3 下的PSNR 和SSIM 值比较Table 3 Comparison of the PSNR and SSIM values obtained using all competing methods with p=0.3
RPCA、SNN、TNN、TTNN、TRNN 等方法都假设数据具有低秩结构,对低秩性有强依赖性。 我们发现,对于结构比较复杂、纹理较为丰富的示例图片5(图11(a)),其张量奇异值并没有迅速接近于0(图11(b)),这表明其tubal 秩相对较大,上述方法难以取得好的恢复效果。 而在背景空旷的示例图片6 (图11(c))中,其奇异值则迅速接近于0(图11(d)),表明tubal 秩较小,上述方法可以取得较好的恢复效果。 对此,本文新增了一个参数r用于控制tubal 秩对数据恢复效果的影响,ETRPCA模型中的λ参数可以协调核范数正则项和l1正则项,参数r则可以进一步控制核范数正则项。 由图3 可知,当随机噪声比例p=0.1 时,在不改变其他参数的情况下,r从0 增加300,PSNR 也从25 增加到42,这为处理不同场景的图像提供了一个优化手段。
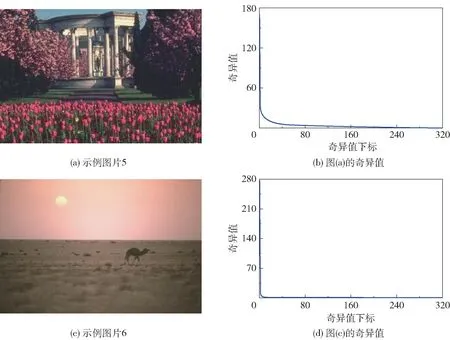
图11 不同图片的奇异值分布Fig.11 Singular value distribution of different images
为了更好地评估本文模型的泛化性,图12 给出了r=150 和r=300 两种情况下本文方法与其他5种方法的PSNR 值比较。 从图中可以看出,当r取150 和300 时,本文所提方法取得的PSNR 值都要高于RPCA、SNN、TNN、TTNN 和TRNN 方法,而且r=300 时所得的结果要好于r=150 时的结果。 这说明在数据是否具有低秩性的先验信息未知的情况下,本文所提方法具有较好的泛化性。
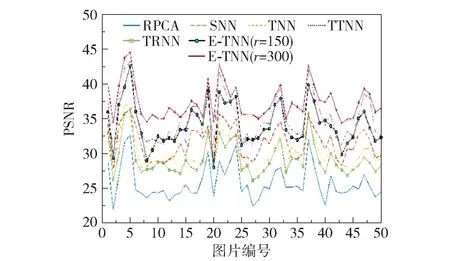
图12 r=150,300 时,50 张图片的PSNR 值Fig.12 PSNR values of 50 images for r=150,300
3.2 背景建模
视频的前景和背景分离任务一直以来都是研究的热点。 视频由连续的帧图像序列组成,其中结构稳定、变动很小的场景内容是视频的背景。由于背景之间的相关性,可以将其视作一个低秩分量,而在视频中所占像素较小且变动显著的物体,如汽车或行人,即为视频的前景,可以视为稀疏分量。 本文选取了driverway(117 帧)[17]和shop(100 帧)[18]两个视频。 在RPCA 算法中,将视频张量h×w× 3 ×f展开为矩阵hw× 3f;在SNN、TNN、TRNN 算法中,将视频张量的大小转化为hw×3 ×f;在本文所提方法中,将视频张量转化为hw×f×3,f表示视频的帧数。
表4 为RPCA、SNN、TNN、TRNN 和本文方法运行时间的比较,图13 ~16 给出了5 种方法在两个视频上的结果(TTNN 方法难以找到一个合适的KA参数,故不参与比较)。 可知5 种方法都可以将运动的行人从背景中提取出来,但本文方法的用时最短。

图13 driverway 视频的背景图像Fig.13 Background image for driveway video
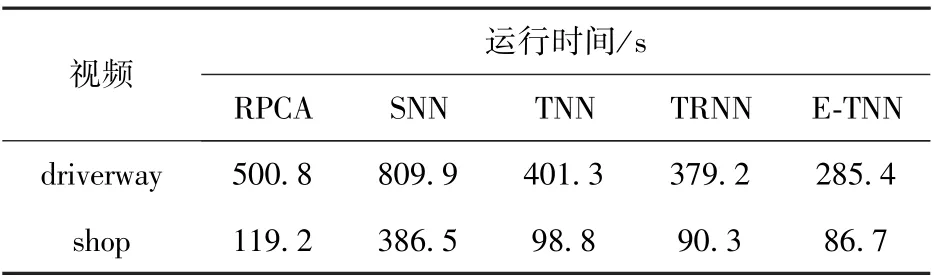
表4 运行时间比较Table 4 Running time comparison
3.3 去除高斯噪声
本文在原有模型的基础上新增了一个正则项‖N‖21来刻画高斯噪声。 通过最小化核范数、l1范数和l21的组合,分离出被混合噪声破坏的干净数据。
l21范数定义如下。
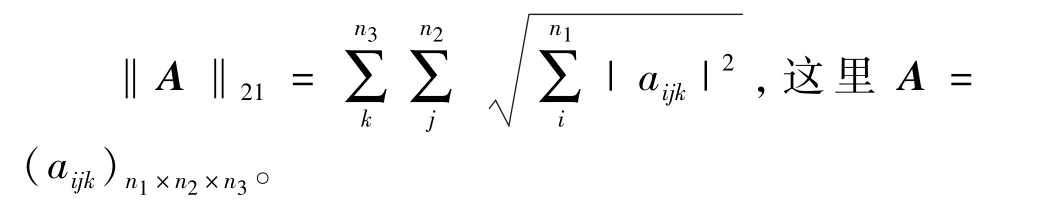
此时,模型(8)可以改写为
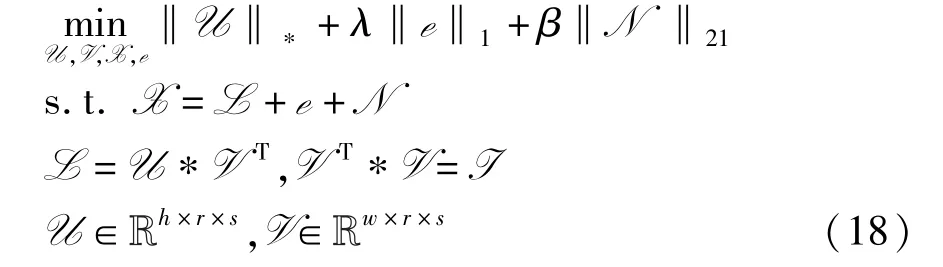
模型(18)的增广拉格朗日函数为
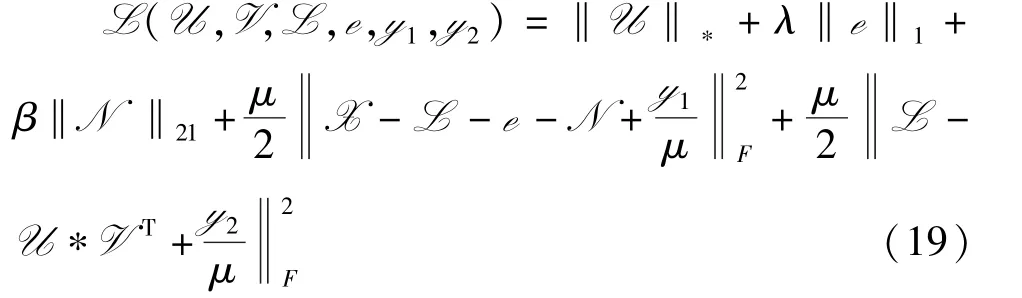

图14 driverway 视频的前景图像Fig.14 Foreground image for driveway video

图15 shop 视频的背景图像Fig.15 Background image for shop video

图16 shop 视频的前景图像Fig.16 Foreground image for shop video
式(19)依然采取ADMM 算法求解,与算法1 相比,求解模型(8)多出一个子问题,即求解‖N‖21子问题,该子问题可以写成如下格式。
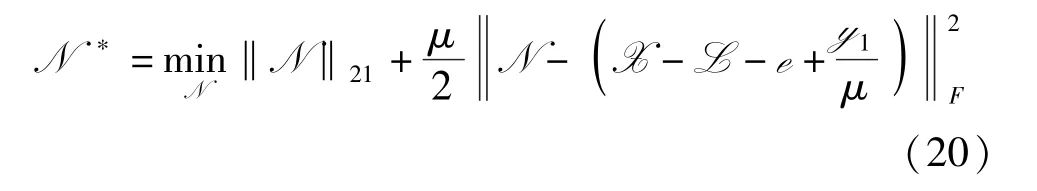

本文将模型(18)应用于图片恢复。 图17 给出了本文方法去除混合噪声的可视化结果。 图17(b)是添加了均值为0、方差为0.05 的高斯噪声和随机噪声比例p=0.2 的示例图片2。 从图17(c) ~(e)可以看出,图像的低秩部分、随机噪声部分和高斯噪声部分都被很好地分离出来。

图17 混合噪声去除Fig.17 Mixture noise removal
4 结束语
本文引入了增强的TNN 正则项(E-TNN),提出一种增强的TRPCA 模型。 与TNN 相比,E-TNN能够在张量数据的子空间投影上计算低秩性,可刻画张量数据中各成分的相关性和差异,从而更真实地反映张量数据的潜在低秩结构。 与张量鲁棒主成分分析方法相比,本文所提算法可以有效地恢复出被噪声破坏的图像,并缩短运行所需时间。 下一步可以基于不同维度的张量数据自动调整字典张量的维度。 此外,基于广义线性变换的t 积张量框架在张量低秩恢复问题中的应用将是未来的研究方向之一。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
山东冶金(2019年5期)2019-11-16 09:09:22
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
中国校外教育(下旬)(2017年8期)2017-10-30 17:32:36
数学物理学报(2017年3期)2017-07-01 16:18:48
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
数学年刊A辑(中文版)(2014年1期)2014-10-30 01:48:06
