
基于改进WL图核的代码克隆检测方法*
2022-10-20 04:08:12班必奂,徐云
网络安全与数据管理 2022年9期
班 必 奂,徐 云
(1.中国科学技术大学 大数据学院,安徽 合肥 230026;2.安徽省高性能计算重点实验室,安徽 合肥 230026;3.中国科学技术大学 计算机科学与技术学院,安徽 合肥 230026)
0 引言
在实际的软件系统开发过程中,开发人员出于提高开发效率或者降低软件错误风险的原因,通常会将其他模块中功能相同或者相近的代码片段通过复制—修改(或不修改)—粘贴的模式引入到当前正在开发的模块中,这些粘贴而来的功能相同或相似的代码片段在学术界通常被称为克隆代码[1]。大量的研究表明,过多的克隆代码会给软件系统带来维护成本提高[2]和Bug蔓延[3]等问题。例如,假设某一段代码中存在Bug并且这段代码被复制粘贴在不同的位置,那么这个Bug将会随着这些克隆代码在整个软件中传播,进而增加了维护的难度。因此,检测出软件系统中的克隆代码并对其进行统一管理是非常有必要的。
随着代码克隆检测技术的不断发展,高级别代码克隆(即Type-3和Type-4克隆)的检测成为当前的研究热点之一。由于高级别克隆代码往往在复制粘贴之后还进行了一些修改,因此也更有可能存在Bug[4]。另外,修改所导致的差异性也使得这一类型的克隆更加难以被检测。
得益于程序依赖图(Program Dependency Graph,PDG)中所包含的大量语法结构信息和语义信息,基于PDG的克隆检测方法在检测高级别克隆上更具优势,能够检测出更多的结构相似但文本差异较大的高级别克隆代码。但在已有的方法中,采用精确图匹配算法的CCSharp[5]、GPLAG[6]等克隆检测方法存在时间性能差和召回率低的缺点,而采用Weisfeiler-Lehman(WL)图核进行近似图匹配计算的CCGraph[7],受限于节点初始标签的单一性和WL图核迭代过程中对近似子结构识别能力的缺失,召回率也相对较低。为此,本文针对WL图核算法在PDG克隆检测应用中存在的缺陷,提出了一种改进思路:首先利用语法分析技术将PDG节点所包含的源代码信息解析为特征向量的形式来作为该节点的初始标签,使其能够保留更多的语义信息;然后通过引入局部敏感哈希技术提升PDG中近似子结构的识别能力,进而提升高级别克隆的召回率。
1 相关研究
1.1 基于文本的方法
基于文本的代码克隆检测方法通常将代码片段视为普通的字符序列,通过计算这些代码字符序列的相似度来寻找克隆。例如在经过一系列如删除注释、删除多余空行和对代码格式重新排布之后再使用字符串匹配算法来检测克隆。典型的研究成果为Baker所提出的工具Dup[8]。此类方法优点在于检测的速度非常快,但往往只能检测出Type-1克隆以及部分Type-2克隆,更高级别的Type-3和Type-4克隆则几乎无法检测。
1.2 基于Token的方法
基于Token的代码克隆检测方法主要思路依然是采用字符串匹配相关的算法来检测克隆,其与基于文本的方法最大的区别就是在进行比对之前增加了词法分析过程,例如,将变量名统一解析为“id”。因此,这种方法能够忽略变量重命名带来的影响,除了能够快速并且较为精确地识别出Type-1克隆以外,还能够识别出Type-2克隆和少量的相似度较高的Type-3克隆,但对于文本相似度较低的Type-3克隆则几乎无法检测。其中,SourcererCC[9]和CCAligner[10]是这类方法中比较典型的工具。
1.3 基于抽象语法树的方法
基于抽象语法树(Abstract Syntax Tree,AST)的代码克隆检测方法主要考虑源代码的语法规则,将源代码转换为其对应的AST形式,然后通过寻找AST之间的相似性来寻找克隆。Deckard[11]是其中较为典型的工具,其主要思想是通过将AST转换为特征向量的形式来快算寻找AST之间的相似性。但由于Type-3克隆的AST结构之间往往差异较大,并且子树的定位较为复杂,因此其召回率并不高。
1.4 基于程序依赖图的方法
基于PDG的代码克隆检测方法首先利用分析工具来生成源代码的程序依赖图,再利用图匹配算法来寻找相似的图结构,相似或者同构的PDG对将被视为克隆。比较典型的方法有CCSharp和CCGraph,其中CCSharp采用了精确子图同构判定算法VF2[12];而CCGraph则采用了基于WL图核的近似图匹配算法。然而这两种方法都没有考虑到高级别克隆对PDG之间的特点,因此召回率偏低。
2 方法设计与实现
本文所提出的检测方法主要由两个部分组成,即预处理阶段和克隆检测阶段。如图1所示,预处理阶段首先生成了与源代码相关的函数级别的PDG,然后利用解析工具将每个顶点所代表的语义解析为特征向量的形式,最后利用滑动窗口算法对所有的PDG建立一个索引表,具有相同Key值的PDG将被视为潜在的克隆对进入到下一个阶段。在克隆检测阶段主要应用改进的WL图核算法进行图相似性的比较,判定其是否为克隆对。
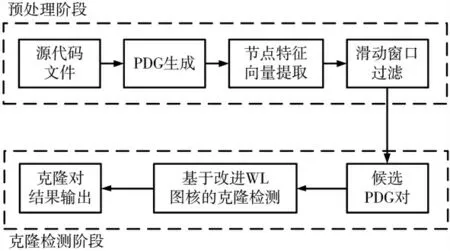
图1 本文代码克隆检测方法流程图
2.1 节点特征向量提取
由于解析工具生成的原始PDG中,图节点的标签被定义为与之相对应的源代码,不利于直接进行图核计算,而如果只将其简单地按照语句类型(如赋值语句、条件判断语句等)进行处理则会损失掉大量有用信息,因此需要对其进行解析,如提取出不同变量个数、赋值运算符个数、加减乘除运算符个数、比较运算符个数、数组访问运算符个数和不同函数调用个数等语义信息(如表1所示),最终以特征向量的形式作为该节点的初始标签。

表1 语义信息类型
例如,假设某个PDG节点所包含源码信息为“OutputStream zOut=new OutputStream(out)”,则该节点的初始标签为[2,1,0,0,0,0,0,0,0,1],表示在该节点中共有2个变量(分别为“zOut”和“out”)且该节点是一个赋值节点,同时还进行了一次函数调用。
2.2 滑动窗口过滤
如算法1所示,在获得所有节点的特征向量之后,将这些特征向量按照其对应顶点在程序流程中出现的先后顺序排序,再利用窗口大小为w,步长为1的滑动窗口在这些排好序的节点上滑动。假设节点的个数为N,则将获得N-w+1个标签(向量)序列。然后,对这N-w+1个序列做哈希,将哈希值作为索引,对应的PDG序号和相关信息作为值插入到索引表中。例如,假设PDG的序号为P1,相应的排好序的标签为{a,b,c,d},窗口大小为3,则索引表的内容为{hash(a,b,c):[P1],hash(b,c,d):[P1]}。最后通过遍历索引表来获取所有的候选克隆对。
算法1:滑动窗口过滤算法
输入:所有的待检测PDG集合G,窗口大小w;
输出:候选克隆对C。

2.3 基于改进WL图核的克隆检测
原始的WL图核迭代过程主要分为3步:
(1)对于每个节点,获取其所有的直接邻居节点的标签从而得到一个多重标签;
(2)对每一个多重标签集合进行排序,再利用哈希算法对排序后的多重标签集合进行哈希;
(3)将得到的哈希值作为该节点的新标签进行下一次迭代。
从WL图核的迭代过程中不难看出,两个标签集合即使只相差一个元素,在迭代步骤(2)进行哈希后得到的标签也会完全不同,而随着迭代次数的增加,这些差异将会随着迭代影响到越来越多的节点,最终导致原本相似的两个PDG被判定为不相似。
针对该问题,本文提出改进的WL图核,利用局部敏感哈希的特点,使得迭代过程中差异较小的子结构能够被识别出来。同时,为了降低精度的损失,本文还在子结构匹配过程中引入了向量相似度量方法。
以图2中的两个源代码片段为例,其生成的PDG如图3所示。其中,虚线表示控制流,实线表示数据流。在预处理阶段,已经将节点对应的源码解析为特征向量的形式,如图4(a)和图4(b)所示。改进WL图核算法每次迭代的过程同样也分为3个步骤:

图2 示例代码片段
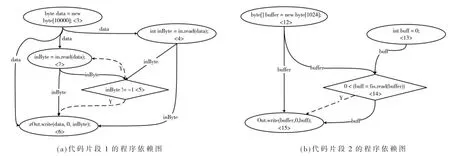
图3 示例代码片段的程序依赖图
(1)将当前节点的邻居节点特征向量信息聚集到当前节点中作为新的特征向量;
(2)根据局部敏感哈希函数以及该节点的类型和上一次迭代的分类情况,对得到的新特征向量进行进一步划分,即:具有相同或相近哈希值并且上一次迭代中被划分为同一类的节点将被视为潜在的相似节点;
(3)计算两张图中相似节点对(即具有相同哈希值并且特征向量的余弦相似度超过指定阈值的节点对)的个数作为本次迭代的图核值。
仍然以图4为例,假设只进行一次迭代。迭代之前,假设节点“<3>”“<12>”和“<13>”被归为同 一 类,节点“<4>”和“<7>”为一类,节点“<6>”和“<15>”为一类。经过迭代步骤(2)后,由于节点“<13>”与节点“<3>”和“<12>”的特征向量相差较大,因此有很大的概率被判定为不相似。而其余节点对之间因为特征向量依旧非常接近,因此将有非常大的可能性仍然被判定为相似(即“<3>”和“<12>”相 似,“<4>”和“<7>”相 似,“<6>”和“<15>”相似),此时本次迭代的图核值为k=2。而如果采用原始的WL图核,迭代后图中的所有节点将会拥有不同的标签,即本次迭代的图核值为0。
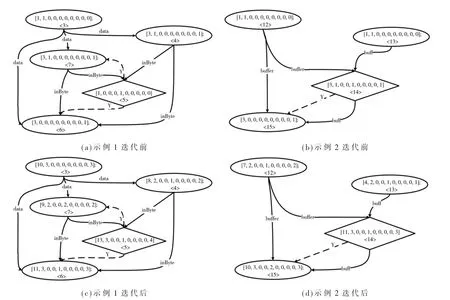
图4 改进WL图核的一次迭代过程示例
最终,总的改进WL图核值定义如下:
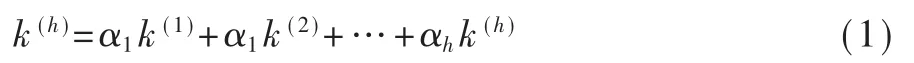
其中k(i)表示第i次迭代的图核值,h表示迭代的总次数,αi为第i次迭代的权重因子。
在实际应用过程中,由于改进WL图核每次迭代都可以看做是将不同距离的节点标签信息汇聚到当前节点中,例如第i次迭代获取了与当前节点的最短路径距离为i的节点的标签信息,因此对所有的PDG设置一个太大的迭代次数反而会影响到时间性能,除此之外,相距越远的节点对当前节点的影响也应该越小,为此,本文在计算两个PDG之间的图核值时动态地设置迭代次数为(|V1|+|V2|)/2(其中|V|表示PDG中节点的总数),并在每次迭代中加入权重因子αi=(h-i+1)/h来给予距离较近的邻居节点信息更高的权重。
最后,考虑到差异较大的Type-3克隆的PDG中通常只存在一定的局部相似性,因此本文采用了非对称相似性系数来衡量两个PDG之间的相似程度,其计算方式如下:
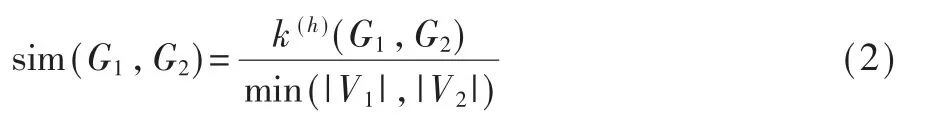
其中G1,G2表示PDG;k(h)(G1,G2)表示这两个PDG的改 进WL图核值;|V1|,|V2|表 示PDG的顶点个数。最终,相似度超过阈值的PDG对将被视为克隆。
3 实验结果与分析
3.1 数据集与实验配置
在验证工具的有效性方面,本文选用了公开的克隆检测数据集BigCloneBench[13]进行实验。该数据集由加拿大的Svajlenko团队构造,从IJaDataset-2.0中选取了总共55 499个Java文件,并标记出其中的8 584 153个真实克隆对和279 032个假克隆对,是学术界用于评估检测工具的常用数据集之一。
为了评估工具的可扩展性,在从IJaDataset-2.0数据集中随机选取出来的1k、10k、1M和10M LoC(Lines of Code)的规模数据集分别进行了实验。
实验环境为Ubuntu 18.04系统,Intel®Xeon®Gold 5120 2.20 GHz CPU,503 GB内存空间。
3.2 评估标准与结果分析
本文主要用精确率、召回率和时间性能三个指标来作为评估标准。在评估召回率方面主要采用了BigCloneEval[14]评估框架。BigCloneEval是基于Big-CloneBench数据集的自动化评估工具,能够根据检测工具所报告的克隆对自动计算出相应的召回率。同时,BigCloneEval还将Type-3克隆按照源代码的相似程度分为了Very Strongly Type-3(即源代码相似度在90%~100%之间)、Strongly Type-3(即源代码相似度在70%~90%之间)、Moderately Type-3(即源代码相似度在50%~70%之间)和Weakly Type-3/Type-4(即源代码相似度在0%~50%之间)。
在对比工具方面,分别选择了各种类型的代码克隆检测工具中比较具有代表性的方法,包括基于Token的检测方法CCAligner、SourcererCC,基于AST的检测方法Deckard,基于深度学习的方法Oreo[15]以及基于PDG的方法CCGraph。由于CCSharp不支持Java语言的检测,因此未进行对比。最终的实验结果如表2所示。
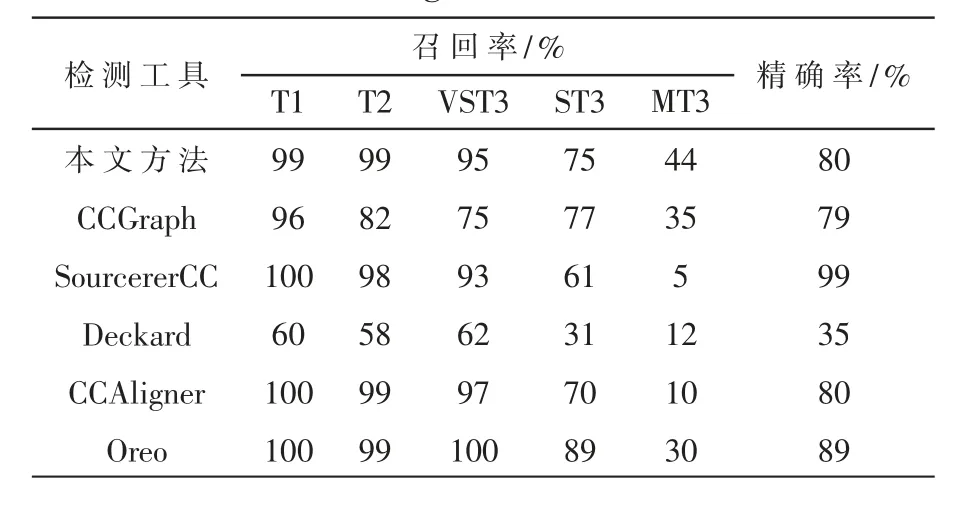
表2 不同工具在BigCloneBench上的检测结果
在召回率方面,本文方法在除了ST3(Strongly Type-3)克隆以外的所有克隆类型上的召回率明显优于采用原始WL图核的CCGraph。在源代码相似程度最低的MT3(Moderately Type-3)上召回率取得了最好的结果,并且在T1(Type-1)、T2(Type-2)和VST3(Very Strongly Type-3)克隆的召回率与基于Token方法的CCAligner和SourcererCC非常接近,均达到了接近100%的召回率。Type-1和Type-2克隆召回率未达到100%的主要原因是由于PDG生成工具自身存在的问题,致使某些程序未能正确生成相应的PDG。
在精确率方面,由于BigCloneEval评估工具只报告方法的召回率,而检测得到的克隆对数又较大,因此本文从检测结果中随机选取了400对克隆进行人工确认,结果如表2中所示。从表2的结果可以看到,精度最高的工具为SourcererCC,但其MT3克隆的召回率只有5%,而MT3克隆往往是假阳性克隆对的主要来源之一。本文方法略高于CCGraph,这是因为预处理阶段将PDG节点中所包含的源代码信息解析为特征向量的形式保留了更多的语义信息。
在对结果的进一步分析中发现,由于局部敏感哈希函数依然存在一个较小的可能性将特征向量相差较大的节点归为同一类,从而导致了假阳性的产生。实际应用中可以根据用户需求通过调整相似度阈值以及多次哈希取并集的方式来平衡召回率和精确率。
在评估时间性能方面,本文主要对比了同样基于PDG的克隆检测工具。由于CCSharp不支持Java数据集的检测,因此为了体现采用图核方法与采用精确子图同构检测方法的性能差距,本文加入了将WL图核换成CCShrap中所采用的VF2算法进行比对。通过表3的实验结果可以看出,与采用精确子图同构检测的VF2算法相比,采用近似图匹配的本文方法和CCGraph在时间性能方面得到了巨大的提升。但由于本文方法在预处理阶段增加了节点特征向量提取的步骤,因此时间性能上比CCGraph略差,但依然在可接受范围内。
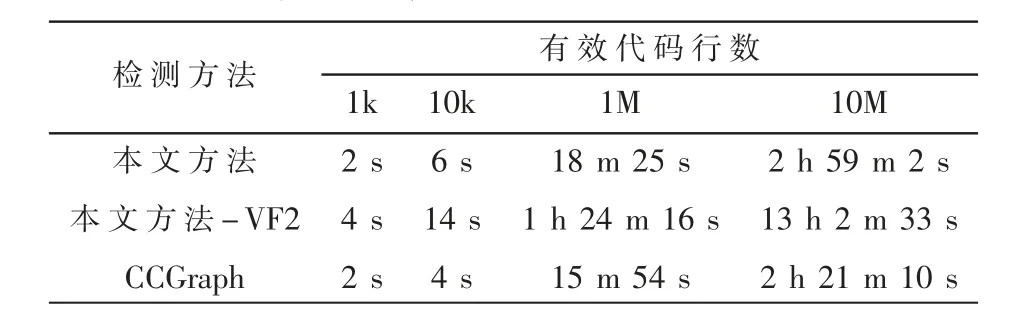
表3 算法运行时间比较
4 结论
本文针对WL图核在PDG近似匹配过程中存在的问题,提出了一种改进思路:在迭代过程中将普通哈希算法替换为局部敏感哈希算法,同时参考上一次迭代的结果来计算图核值。此外,本文还根据改进后的WL图核方法设计并实现了相应的克隆检测工具:首先利用静态解析工具将源代码解析为特征向量的形式;然后根据程序流程的先后顺序对这些特征向量排序,利用滑动窗口算法建立索引表并过滤掉那些不可能为克隆的PDG对;最后利用改进的WL图核方法对候选PDG对进行图相似性检测并输出最后的结果。实验结果表明,本文方法在Type-3克隆上的召回率得到了较大提升,同时在检测精度和时间性能上得到了良好的保持。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
现代信息科技(2021年21期)2021-05-07 21:44:50
中国司法鉴定(2018年4期)2018-07-30 06:08:26
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
工业设计(2016年8期)2016-04-16 02:43:34
中国房地产业(2016年8期)2016-03-01 01:25:55
计算机工程(2015年8期)2015-07-03 12:20:04
