
融合注意力机制的弱监督迷彩伪装目标检测算法
2022-10-20 04:08:18权冀川梁新宇郭安文王中伟
网络安全与数据管理 2022年9期
杨 辉,权冀川,梁新宇,郭安文,王中伟
(1.陆军工程大学 指挥控制工程学院,江苏 南京 210007;2.中国人民解放军 73658部队)
0 引言
军事上采用迷彩伪装的目的是隐蔽自己、欺骗敌人、提高战场生存能力。相对于通用的目标检测任务,图像中的迷彩伪装目标与背景环境融合度较大,实现其目标检测任务更加困难。
目前,对迷彩伪装目标检测研究的工作较少。传统的检测方法主要把迷彩伪装目标看作是一种具有特殊纹理结构的目标,并针对这一特性设计相应算法提取迷彩纹理,从而实现迷彩伪装目标的检测。Bhajantri等人[1]将目标的迷彩伪装纹理作为一类物体,然后对该类物体进行检测。Sengottuvelan等人[2]通过图像的结构信息,确定图像中是否存在迷彩伪装目标。Wu等人[3]根据目标在三维凸面上的灰度差异来检测迷彩伪装目标。尽管传统方法可以实现对迷彩目标的检测,但该类方法仅利用了图像的浅层特征信息,其检测效果相对较差。
近年来的研究工作主要是使用基于深度卷积神经网络的强监督目标检测算法完成迷彩伪装目标的检测任务。Deng等人[4]针对迷彩伪装目标的特性,在RetinaNet[5]算法的基础上嵌入了空间注意力和通道注意力模块。同时,基于定位置信得分构建了新的预测框过滤算法,有效实现了对迷彩伪装人员的检 测。Wang等 人[6]以YOLO(You Only Look Once)v5算法为基础,设计了一种针对迷彩伪装目标的检测算法,该算法在骨干网络中加入了注意力机制,同时加入非对称卷积模块增强了目标的语义信息,从而提升了迷彩伪装目标的检测精度。虽然强监督目标检测算法比传统方法的检测效果有了很大的提升,但该类算法模型需要在大规模标注精度高的数据集上进行训练,检测结果严重依赖于数据集标注的精度。目前的数据集标注工作主要是靠人工完成,而人工标注在很大程度上容易受人的主观因素影响,在军事应用领域很难获得大规模的且标注精度高的数据集。
在军事领域,受保密等特殊条件限制,很难构建包含迷彩伪装目标的大规模图片数据集。并且,图片中的迷彩伪装目标与图片背景的融合度较大,从本质上增加了目标检测的难度。同时在人工标注时也很容易造成误标或漏标,严重影响数据集的使用效果。若在小规模且标注精度低的数据集上训练强监督目标检测算法,则训练出来的模型对迷彩伪装目标的检测效果会很不理想。而弱监督目标检测算法可以很好地克服强监督目标检测算法的这一局限性。弱监督目标检测算法只需要带有图像级标签(不需要标注出目标在图像中的具体位置,只需要标明图像中包含物体的类别)的数据集就能实现目标检测,大幅降低了对数据集标注的要求。因此,弱监督目标检测算法比强监督目标检测算法具有更强的适应能力。
目前,基于类激活图[7](Class Active Mapping,CAM)的模型是弱监督目标检测算法(Weakly Supervised Object Detection,WSOD)中最常用的模型之一。然而,基于CAM的模型最初是针对分类任务进行训练的,其设计目标与检测算法不一致。具体来说,分类任务更加关注来卷积神经网络(Convolutional Neural Networks,CNN)深层的具有语义意义的特征。相比之下,源自CNN浅层的特征包含的语义信息较少,但语义更加丰富。在细节上,浅层特征边缘更清晰,失真更少。但由于以下两个缺陷,浅层和深层特征的直接融合对于WSOD是无效的:(1)由于监督信息不足,嵌入在浅层特征中的有意义的信息容易受到背景噪声干扰;(2)在原始区域中只有最具有辨别力的区域被激活。
为了克服上述缺陷,本文采用了一种简单但有效的浅层特征感知伪监督目标定位[8](Shallow featureaware Pseudo supervised Object Localization,SPOL)算法来实现迷彩伪装目标检测任务。该算法最大限度地嵌入浅层的低级特征,生成的CAM区域更加广泛和清晰,在公共数据集中取得了最好的结果,如表1所示。
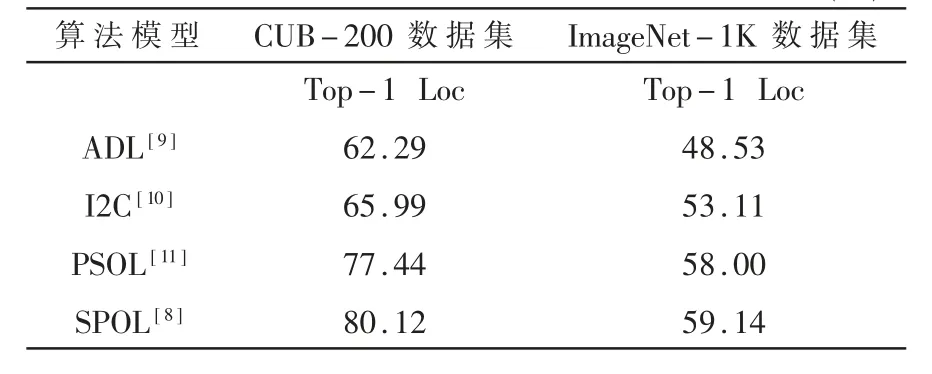
表1 SPOL算法与其他主流算法在公共数据集上的实验对比 (%)
然而迷彩伪装目标与背景相似度大,导致SPOL算法在该类目标上的检测精度较低。针对这一问题,本文分别融合了卷积块注意力模块(Convolutional Block Attention Module,CBAM)[12]和SE(Squeeze-and-Excitation)[13]注意力模块,使模型更加关注迷彩伪装目标所在的区域,以此提高模型提取特征的能力。实验表明,加入CBAM模块后,算法的检测精度提高了4.29%;加入SE模块后,算法的检测精度提高了8.01%;同时加入CBAM模块和SE模块后,该指标提高了7.23%,从而验证了本文算法在弱监督迷彩伪装目标检测任务中的有效性。
1 SPOL算法结构
SPOL算法模型主要包括两个阶段,CAM生成和与类别无关的分割,其算法流程如图1所示(输入图像首先进入CAM生成模块(即MFF-Net1)获得初始的CAM。然后使用高斯分布先验获得高斯增强的CAM。同时,将产生的伪标签作为与类别无关的分割模块(即MFF-Net2)的监督)。在CAM生成阶段,乘法特征融合网络(Multiplicative Feature Fusion Net,MFF-Net)旨在聚合浅层和深层特征。与以往的融合方法不同,MFF-Net网络中的特征以协同方式处理,即具有清晰背景的深层特征帮助抑制浅层的噪声,而浅层具有丰富局部结构的特征使对象边界更清晰。在与类别无关的分割阶段,使用高斯先验伪标签(Gaussian Prior Pseudo Label,GPPL)模块对初始的CAM进行细化,然后将其视为类不可知分割模块训练的伪标签。具体来说,充分利用初始的整个CAM作为加权系数,通过所有坐标的均值和方差计算得到物体的权重。然后,可以生成具有均值和方差的高斯分布,称为高斯先验伪标签。结合GPPL和原始CAM,可以得到改善的CAM。为了进一步细化这些区域,通过使用组合的GPPL和CAM作为伪标签设计了一个与类别无关的分割模型,在训练阶段,具有不同大小的CAM响应区域将分别被二值化为前景和背景。同时,使用两个预定义的阈值,其他部分将被忽略以避免训练期间标签的冲突。训练结束后,与初始CAM相比,获得的对象掩码将更加完整。最后,边界框提取器应用于对象掩码以获得最终的目标检测结果。

图1 SPOL算法流程
1.1 乘法特征融合
多尺度特征融合常用于强监督的目标检测[14]、语义分割[15]等任务。然而,这种策略对弱监督目标检测任务无效。因为来自浅层的特征包含太多的背景噪声。如果没有强有力的监督,浅层的特征就会被背景噪声所掩盖,对最终的预测几乎没有效果。因此,该算法采用MFF-Net网络结构(见图2)滤除浅层特征的背景噪声。首先以相同的分辨率(即H×W)对不同分支(即X、Y、Z)的特征进行采样,然后通过逐元素乘法组合到后续的分类器中。
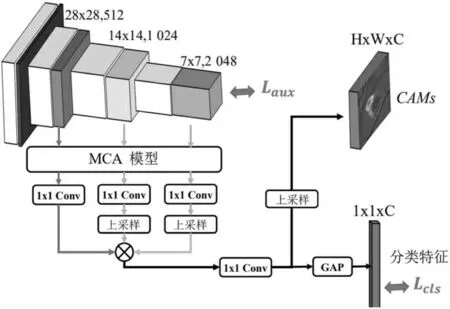
图2 MFF-Net网络结构
与以前的方法不同,MFF-Net网络结构以协同方式处理浅层和深层特征,可以很好地利用浅层特征。为了详细说明这一点,图3介绍了四种具有不同监督风格的方法。具体来说,图3(a)是原始分类模型(例如VGG[16]和ResNet50[17]),其中只有最后一层被监督。因为浅层特征远离监督并受到梯度消失问题的影响,图3(b)显示了深度监督模型,其中深层和浅层特征都被直接监督以驱动网络学习更好的表示。但是由于感受野有限,浅层特征的语义较少并引入了更多的噪声。因此,这种直接监督对弱监督目标检测效果的帮助不大。与这些方法相比,特征融合提供了一种间接监督的形式,即在监督之前组合不同层的特征。
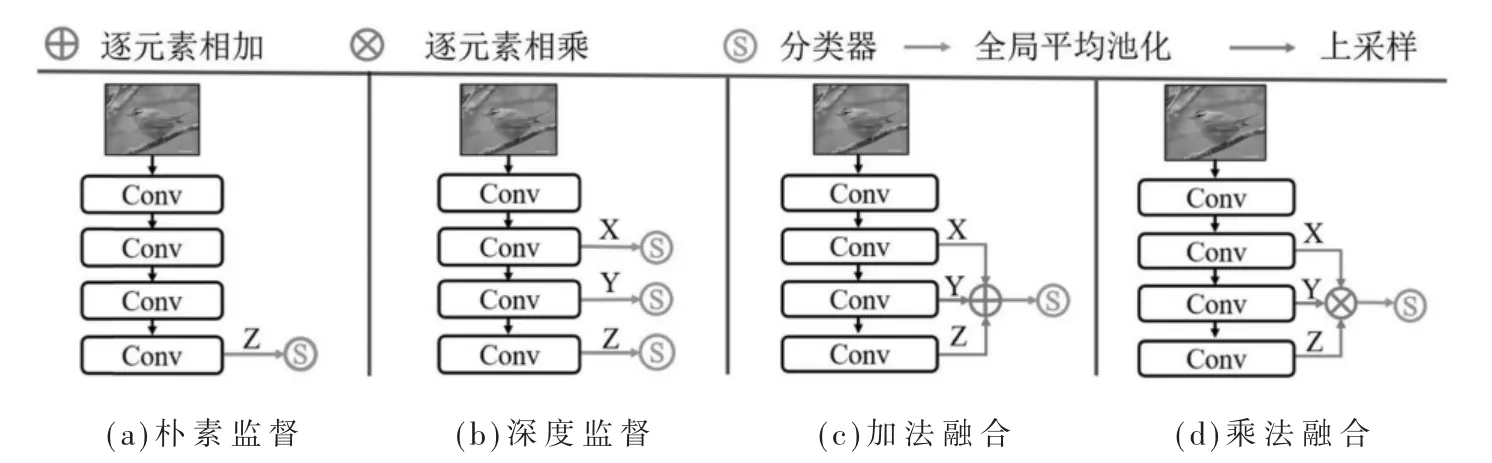
图3 不同监督方式
图3(c)和方程(3)展示常用的加法融合策略。但是,它没有考虑多尺度特征之间的相关性。如方程(4)所示,根据链式法则,在计算网络权重的梯度之前,特征相加对每个分支的梯度是相同的常数,与其他分支没有相关性。也就是说,当一个分支出错时,不会影响其他分支。在这种情况下,网络无法很好地学习每个分支,即使浅层特征是错误的,预测也是可以接受的。虽然它可以在测试阶段提高模型的稳定性,但在训练阶段却降低了模型容量并增加了算法的训练难度。与其他方法不同,在MFF-Net中,不同的分支通过乘法运算进行强耦合,如式(1)所示。式(2)说明了X分支的梯度不是恒定的,而是与Y和Z分支相关的。这三个分支在训练过程中会相互影响。当一个分支未能捕捉到优越的表示时,乘法机制会放大其错误,最终导致预测的错误。也就是说,MFF-Net为网络训练设置了强约束,其中每个分支都必须很好地学习表示。此外,在这种情况下,Y和Z依赖于X。当X得到更好的表示时,Y和Z将得到增强。因此,它们的融合可以产生更准确的预测。
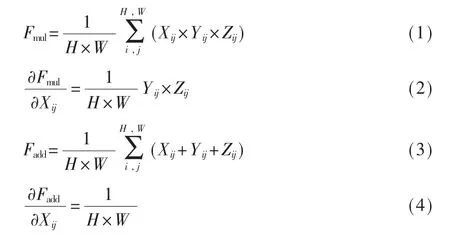
1.2 基于乘法的通道注意力机制
卷积神经网络具有强大的特征提取能力,可以同时表示前景对象和非目标背景特征。浅层特征的某些部分是不必要的,可以视为噪声,会严重干扰最终预测。因此,如图4所示,在不同层的特征融合之前,采用通道注意力粗略地过滤掉噪声通道。区别于一次只关注一层的传统通道注意力方法,该算法设计了一个基于乘法的通道注意力(Multiplication based Channel Attention,MCA)模块同时处理各个层。
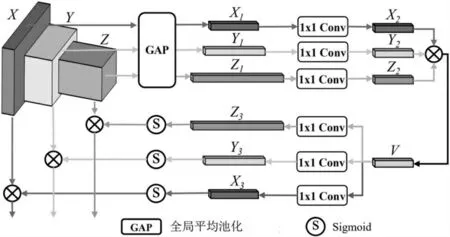
图4 MCA模块
具体来说,对于输入的特征图X∈RH1×W1×C1、Y∈RH2×W2×C2和Z∈RH3×W3×C3,首 先 利 用 全 局 平 均 池化层分别实现X1∈R1×C1、Y1∈R1×C2和Z1∈R1×C3,然后利用3个平行的1×1 Conv层将X1、Y1和Z1分别转移到具有相同维度R1×C′的X2、Y2和Z2。最后,利用逐元素乘法融合得到潜在的特征向量V=X2·Y2·Z2,V∈R1×C′。这种潜在的特征向量表示不同层的特征的相互耦合。因此,可以将通道注意力同时应用于多个层。在相反的方向上,潜在的特征向量通过Sigmoid激 活函数反馈到原始维度,即X3∈R1×C3、Y3∈R1×C3和Z3∈R1×C3。基于X3、Y3、Z3,MCA模 块使用乘法运算实现对每个对应层的通道注意。
1.3 类不可知分割引导的弱监督目标定位
由图1可见,虽然MFF-Net1网络结构已经产生了最初的CAM,但它只关注最具辨别力的区域,还不足以提取准确的定位边界框。为了解决这个问题,进一步提出了伪监督类不可知分割模型,它利用了另一个MFF-Net2网络结构。这个与类别无关的分割模型,丢弃了类别信息,只关注定位信息,即输出仅代表前景或背景。该模型由伪标签生成模块和类别无关的分割模块两部分组成。
(1)分割伪标签生成。首先,通过高斯先验伪标签(GPPL)模块补充CAM。CAM上的每个点(x,y)都被视为一个样本。位置(x,y)处的响应对应于其权重,通过该设置,计算所有样本的x和y之间的均值(μx,μy)、方 差和相关系数ρ。然后,利用这些参数生成二维高斯分布,如式(5)和式(6),有助于定位物体重心并覆盖较宽的物体区域。
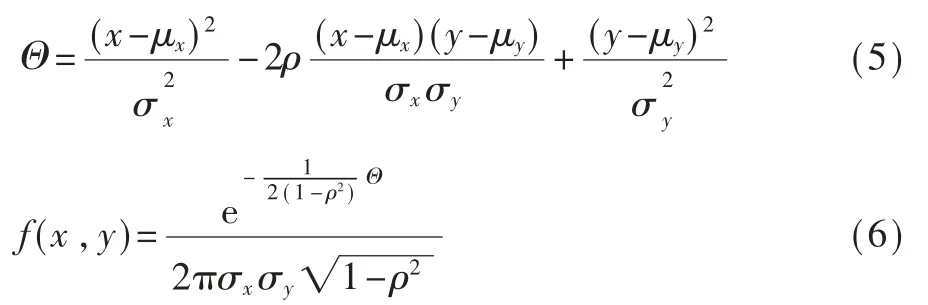
然后将原始CAM与高斯增强的CAM集成在一起,采用元素最大值来获得完整的预测。下一步,增强的CAM被进一步转换为具有两个预定义阈值的3个部分,即高置信度区域对应于前景,低响应区域对应于背景,冲突区域对应于低置信度区域。
(2)类不可知分割和边界框提取。在获得前景和背景伪分割标签后,对类别无关的分割模型(即MFF-Net2)进行训练。虽然只有一部分图像具有像素级标签,但分割模型可以捕获类似的上下文并自动覆盖前景。模型优化好后,可以从类不可知分割的预测掩码中提取边界框。最终的预测结合了提取的边界框和来自独立分类器的分类预测。
1.4 损失方程
CAM的生成过程,除了应用分类损失外,还应用了附加损失。通过最后一个特征图和融合的分类特征计算两个损失,即Laux和Lcls,如图2所示。这两个损失都是使用交叉熵计算的。因此,联合损失Lc=Lcls+Laux用于优化MFF-Net1。 对于类不可知分割,应用二元交叉熵损失来监督分割模型,如式(7)所示。然而,除了冲突区域外,只考虑伪前景和背景区域。具体地,对于前景和背景,wij等于1,而对于那些冲突区域,wij设置为零。最终损失冲突区域被忽略以避免误导网络。
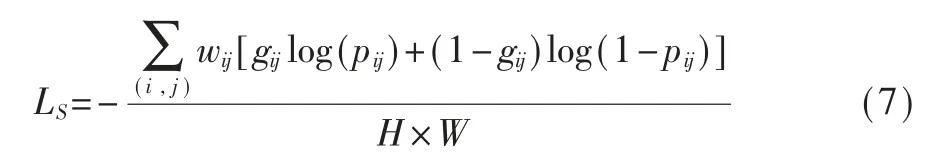
其中pij和gij分别是位置(i,j)处的预测概率和真实标签。
2 改进的SPOL算法
由于迷彩伪装目标与图像背景融合度较大,SPOL算法的检测精度相对较低。为了更进一步提高模型的检测精度,本文在MFF-Net网络模型中融入了注意力模块,使模型更加注重迷彩伪装目标所在的区域,以此增强模型提取特征的能力,得到包含伪装目标更全面的CAM,进而提高模型的检测精度。
2.1 融合CBAM模块的SPOL算法
2.1.1 CBAM模块
CBAM将通道注意力和空间注意力串联起来,通过将通道注意力图和空间注意力图解耦以提高计算效率,并引入全局池化利用空间全局信息。模块结构如图5所示。
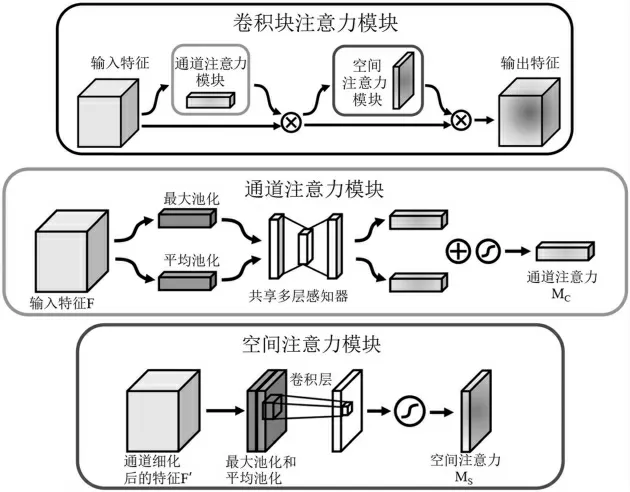
图5 CBAM结构
CBAM模块有两个连续的子模块,通道注意力和空间注意力。给定输入的特征图X∈RC×H×W,它依次推断一维通道注意力向量sc∈RC和二维空间注意力图ss∈RH×W。通道注意力子模块采用两种不同的池化操作来聚合全局信息。它有两个并行分支,分别使用MaxPool和AvgPool操作:
式中GAPs(·)和GMPs(·)表示空间域中的全局平均池化和全局最大池化操作。空间注意力子模块对特征的空间关系进行建模,是对通道注意力子模块的补充。与通道注意力不同,它利用具有大内核的卷积层来生成注意力图。
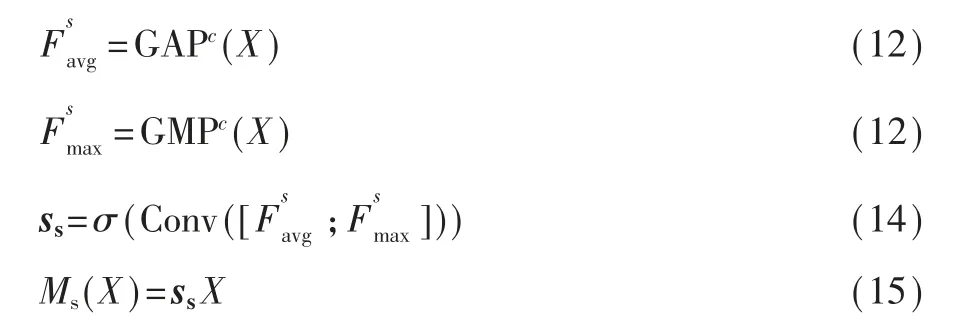
其中Conv(·)表示卷积运算,而GAPc(·)和GMPc(·)是通道域中的全局平均池化和全局最大池化操作。[·]表示通道上的串联。整个注意力过程可以概括为:

CBAM模块依次结合通道注意力和空间注意力,可以利用特征的空间和跨通道关系强调网络关注什么以及关注哪里。即强调有用的通道以及增强信息丰富的本地区域。由于其轻量级设计,CBAM模块可以无缝集成到任何CNN架构中,附加成本可以忽略不计。
2.1.2 融合CBAM模块的MFF-Net网络
原始的MFF-Net网络模型采用ResNet50网络提取特征。虽然该网络具有很强的特征提取能力,但是相比于通用的目标,迷彩伪装目标和背景融合度非常大。目标在图像中不易识别,从而增大了网络提取目标特征的难度。为了缓解这一问题带来的影响,本文在ResNet50网络中加入CBAM模块,让网络更加注意迷彩伪装目标所在的区域,以此增强网络的特征提取能力,增加的具体位置如图6所示。
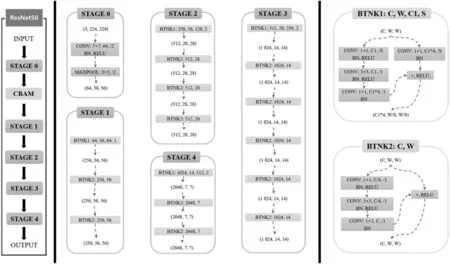
图6 融合CBAM模块的ResNet50网络结构
2.2 融合SE模块的SPOL算法
2.2.1 SE模块
SENet的核心是一个SE模块,用于收集全局信息、捕获通道关系和提高表示能力。SE模块分为两部分:挤压模块和激励模块,模块结构如图7所示。
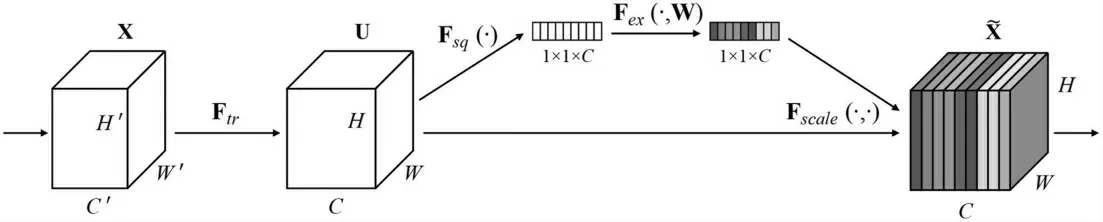
图7 SE模块结构
挤压模块通过全局平均池化操作收集全局空间信息。激励模块使用全连接层和非线性层(ReLU和Sigmoid)捕获通道关系并输出注意力向量。然后,将输入的特征向量与注意力向量中的相应元素相乘来缩放输入特征的每个通道。一个以X为输入和Y为输出的挤压和激励块Fse(带有参数θ)可以表述为:

2.2.2 融合SE模块的MFF-Net网络
尽管在ResNet50网络中融合CBAM模块后,增强了网络提取特征的能力,从而提升了算法的检测效果,但仅在网络的STAGE 0模块后加入CBAM模块,这导致后续的几个模块在进行特征提取操作时无法着重关注迷彩伪装目标所在的区域。为了进一步利用注意力机制提高模型的检测精度,本文在MFF-Net网络模型的ResNet50中融入了SE模块,加入的具体位置如图8所示。
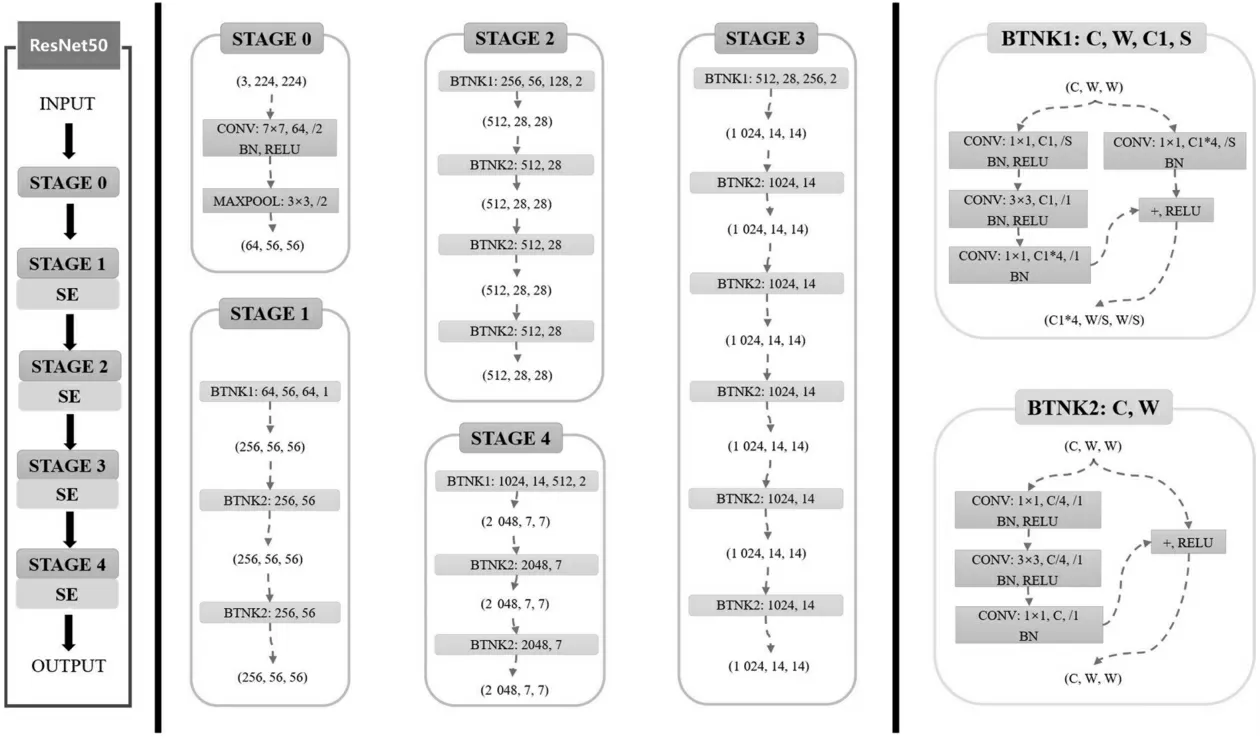
图8 融合SE模块的ResNet50网络结构
2.3 融合CBAM模块和SE模块的SPOL算法
为进一步验证融合注意力模块后目标检测算法的有效性,以及比较不同注意力模块对不同尺度目标检测效果的影响和作用,在上述研究的基础上尝试对两种注意力模块进行融合,改进形成的网络结构如图9所示。
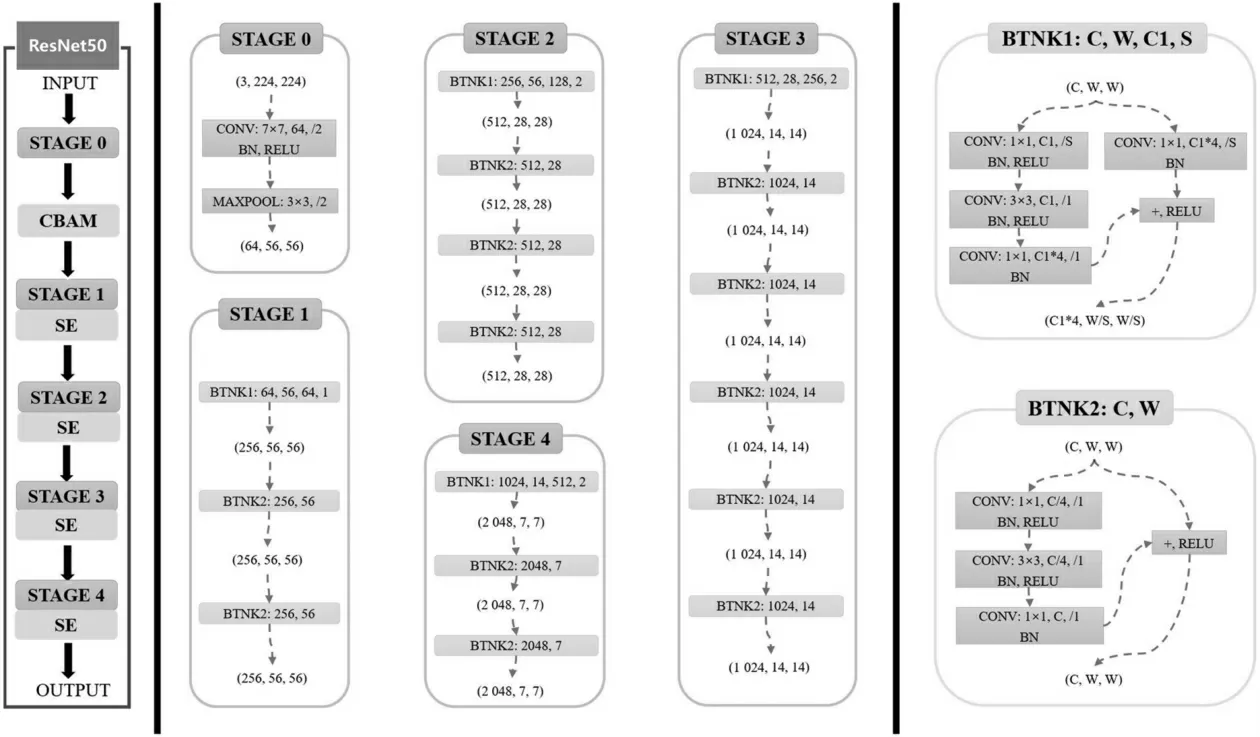
图9 融合CBAM模块和SE模块的ResNet50网络结构
3 实验分析
3.1 数据集
实验采用的目标图像来源于课题组自建数据集CSS[18],该数据集包含雨林、丛林、雪地和山地4种野外环境下多类型的迷彩伪装目标。从实际战场侦察角度看,CSS数据集涵盖了不同场景、不同天候、不同迷彩类型的多尺度伪装目标,可以满足多种迷彩伪装目标检测识别的实验需求。为了满足弱监督迷彩伪装目标检测算法训练和测试的要求,本文在CSS数据集的基础上进行了筛选与重新标注,构建了一个适合弱监督目标检测算法的数据集。该数据集的训练集由6 100张迷彩伪装目标图像组成,其中包括1 000张大目标图像、2 100张中目标图像以及3 000张小目标图像。为了更好地验证本文设计的算法的有效性,构建了两个测试集用于算法的验证:第一个测试集由350张迷彩伪装目标图像组成,只包含大目标和中目标的图像;第二个测试集包括大目标、中目标、小目标三个子集,三个子集都由100张迷彩伪装目标图像组成。其中,将目标所占像素点与全图像素点数量的百分比作为定义目标尺度的依据。小目标所占像素点与全图像素点数量的比值小于或等于1%;中目标所占像素点与全图像素点数量的比值在1%到3%之间;大目标所占像素点与全图像素点数量的比值大于3%,图10展示了不同尺度目标的图像样本。

图10 多尺度目标图像样本
3.2 实验环境
搭建实验环境,使用的服务器操作系统为Ubuntu18.04,使用的应用软件环境及工具包包含CUDA、Python3.8等,使用PyTorch深度学习框架进行实验。实验所用的硬件设备配置如表2所示,训练算法模型时的重要参数设置如表3所示。

表2 实验硬件环境配置

表3 训练参数列表
3.3 评价指标
常用的弱监督目标检测评价指标有以下三种:
(1)Top-1定位精度(Top-1 Loc):预测的物体类别必须和物体的真实类别相同,且预测边界框与真实框的交并比的(Intersection-over-Union,IoU)数值超过50%,即预测边界框与真实框的重合率超过50%的比例。
(2)Top-5定位精度(Top-5 Loc):对于预测的物体类别,取可能性最高的5类,只要这5类中包含物体的真实类别,就算分类正确。同时,预测的边界框与真实框的IoU数值超过50%的比例。
(3)GT-known定位精度(GT-known Loc):预测边界框与真实框的IoU数值超过50%的比例。
本文是在迷彩伪装目标数据集上进行的对比实验,该数据集只有单类物体,故采用Top-1 Loc和GT-known Loc作为目标检测结果的评价标准。
3.4 改进算法的实验结果
表4比较了改进算法与原始算法在弱监督迷彩伪装目标图像数据集上的实验结果,采用的是大、中尺度目标混合的验证集。其中,CBAM-SPOL表示融合CBAM模块的检测算法,SE-SPOL表示融合SE模块的检测算法,CBAM-SE-SPOL表示同时融合了CBAM模块和SE模块的检测算法。
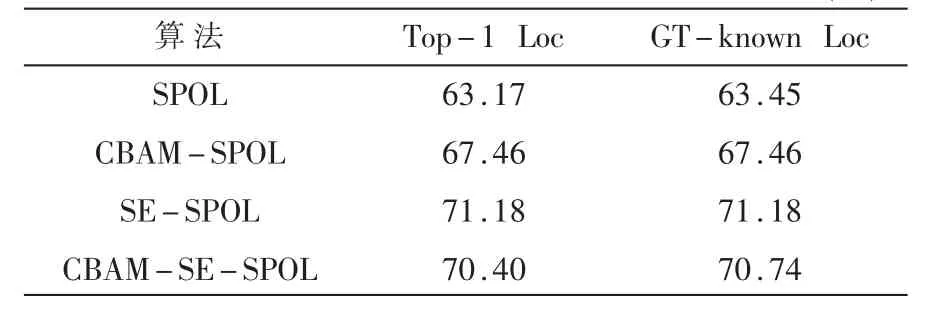
表4 不同算法的实验结果对比 (%)
由表4可见,融合注意力模块后,算法的检测精度比原始算法的检测精度有比较明显的提升。其中,加入CBAM模块后,Top-1 Loc评价指标提高了4.29%;加入SE模块后,该指标提高了8.01%。然而,同时加入CBAM模块和SE模块后,该指标提高了7.23%,仅比只加入CBAM模块提高2.94%,而比只加入SE模块时降低0.78%。主要原因是,同时融合CBAM模块和SE模块后,在模型训练过程中,当输入图像通过CBAM模块时,模型会选择性地丢弃一些不重要的信息,导致后续的SE模块局限于关注CBAM模块保留的特征信息,从而在一定程度上降低了模型提取特征的能力。但总体来说,加入注意力模块后的MFF-Net网络比原始的MFF-Net网络能够提取到更多的有效特征,可增强算法对隐蔽性高的迷彩伪装目标的检测能力。
为了验证注意力模块对各种尺度迷彩伪装目标检测效果的影响,分别采用含有的大目标、中目标、小目标图像的子验证集对上述四种算法进行再次验证,并使用Top-1 Loc作为实验结果的评价指标,实验结果如表5所示。
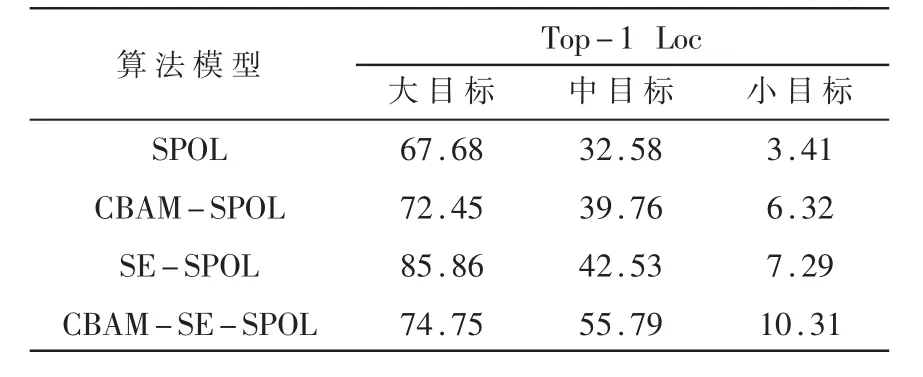
表5 不同算法对多尺度目标的检测结果对比 (%)
从表5中看出,对于三种不同尺度的迷彩伪装目标图像,融合注意力模块后的算法比原始SPOL算法的检测效果都有明显提升。综合比较得出,SE-SPOL算法对大目标图像的检测效果最好,Top-1 Loc评价指标提高了18.18%;CBAM-SE-SPOL算法对中目标图像的检测效果有显著的提升,评价指标比原始SPOL算法提高了23.21%;同时,CBAM-SESPOL算法对小目标图像检测效果的提升也很明显,评价指标提高了6.90%。产生上述对比效果的主要原因是:(1)大目标在图像中所占的像素点数量多,SE通道注意力本身对大目标的特征提取能力很强,而CBAM模块和SE模块的融合,反而会使模型丢失一些迷彩伪装目标的特征信息,所以当数据集主要包含大目标图像时,更适合用SE-SPOL算法进行检测。(2)中目标和小目标在图像中所占的像素点数量相对较少,先通过CBAM模块使模型关注这两类目标在图像中的大致区域,然后利用SE模块进一步加强模型对这些区域的特征提取能力,会显著改善检测效果;所以当数据集主要包含中目标或小目标时,更适合用CBAM-SE-SPOL算法进行检测。(3)小目标在图像中所占像素点数量太少,同时迷彩伪装目标与图像背景相似度较高,采用的图像级标签不含目标的位置信息,三点原因综合起来会导致模型训练时很难学习到小目标的特征。因此,虽然改进算法也能明显改善对小目标的检测效果,但检测精度还有很大的提升空间。
3.5 目标检测效果分析
图11展示了原始算法与加入不同注意力模块的改进算法生成的像素级伪标签的比较结果。从图中可以看出,加入注意力模块后,改进算法生成的伪标签图像比SPOL算法更加清晰,覆盖的目标像素点更多。可见,改进算法中的MFF-Net2网络可以学习到更全面的目标信息,进而提升了模型的检测精度。
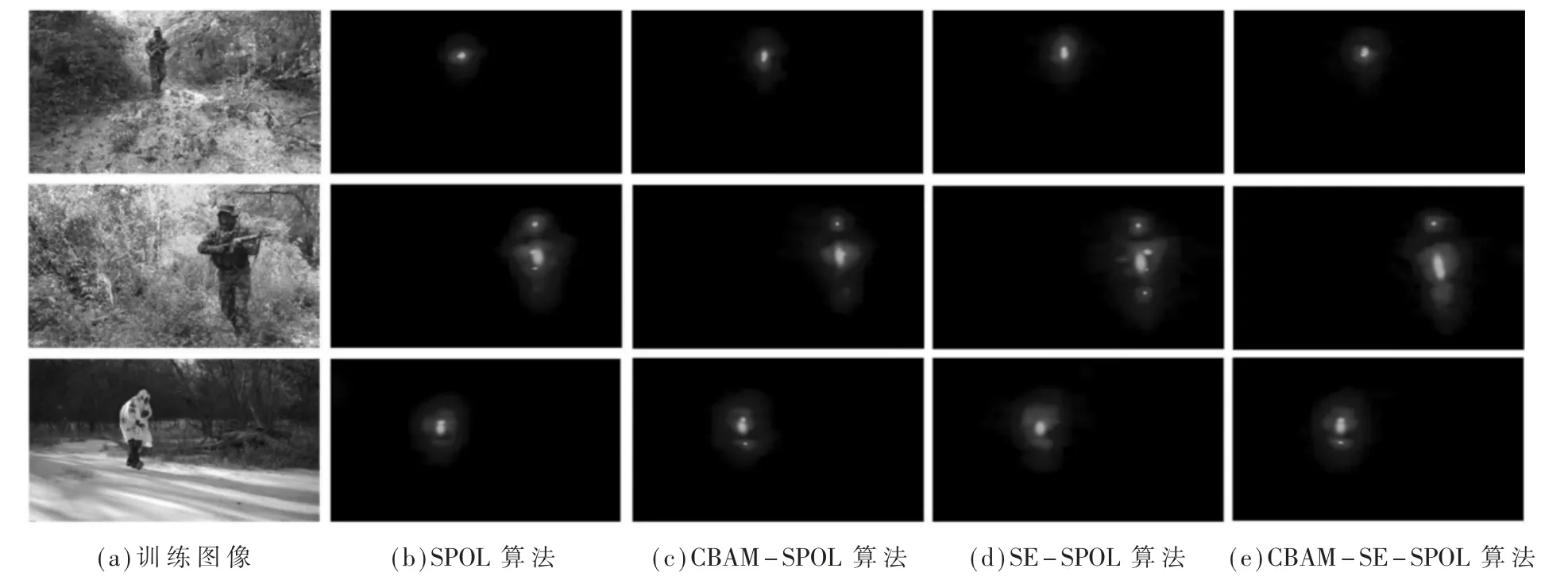
图11 伪标签比较
图12对比了改进算法和原始算法的检测效果。从第1行到第3行分别为大目标图像、中目标图像以及小目标图像。图中,绿色方框表示目标的真实框,红色方框表示算法的预测边界框,红色数值为目标检测的IoU比值。对比可见,本文提出的改进算法模型对目标的预测边界框更加准确,预测边界框与真实框的IoU比值更大,说明预测结果与真实情况更加接近。其中,SE-SPOL算法对大目标的检测效果最好,IoU比值最高;CBAM-SE-SPOL算法对中、小目标的检测效果最好。

图12 检测效果比较
4 结论
本文以弱监督目标定位任务中的SPOL算法为基础,针对迷彩伪装目标图像这一类特殊场景,在算法中加入注意力模块,加强模型对迷彩伪装目标的特征提取能力。不同算法间的实验结果对比表明:本文的算法比原始算法在检测精度上得了到较大的提升。下一步的研究工作是针对实际场景中大量存在的模糊图像,研究采用去模糊算法对图像进行增强,以进一步提高模型的检测精度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
人大建设(2020年4期)2020-09-21 03:39:12
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
人大建设(2017年2期)2017-07-21 10:59:25
传媒评论(2017年3期)2017-06-13 09:18:10
人大建设(2017年9期)2017-02-03 02:53:31
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
浙江人大(2014年4期)2014-03-20 16:20:16
