
注意力特征融合SSD算法对遥感图像的目标检测*
2022-10-20 04:08尹法林王天一
网络安全与数据管理 2022年9期
尹法林,王天一
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
0 引言
近年来卫星遥感技术在自然灾害救助和高空目标侦察等方面得到广泛的应用,成为军事侦察、海洋勘测等领域不可缺少的工具[1-3]。气候、光照等自然条件的影响,使得识别遥感图像中的目标有很多困难。因此,对复杂场景下的遥感图像目标检测识别的研究具有重要的价值[4-5]。
随着深度学习[6]在计算机视觉领域的发展,使用卷积神经网络[7-8]对图像中的目标进行识别已经成为研究的热门课题。2012年AlexNet[8]网络在ImageNet图像分类比赛中成绩突出,从此出现了以深度卷积神经网络为基础的目标检测算法。之后出现的双阶段目标检测算法Fast R-CNN[9]、Faster R-CNN[10]等进一步提高了检测的精度,但是检测速度很慢。2016年Redmon等在CVPR会议上提出统一实时目标检测算法YOLO[11],该算法利用回归得到边界框和类别概率,在检测速度上有明显的提升,但是检测精度偏低。同年,Liu等在ECCV会议上提出了多尺度单发射击检测算法SSD[12],该算法通过用不同尺度的特征图来提取特征,在满足实时性的同时,提高了检测精度。
针对小目标检测的准确率不高,文献[13]提出了自注意力特征融合模块。遥感数据集中基本都是小目标物体,而小目标物体主要以浅层特征图来检测[14],因此对SSD算法网络中的浅层特征图进行融合,可提高目标检测的准确性;针对训练过程中正负样本失衡导致的模型退化问题,采用聚焦分类损失函数(focal classification loss)[15-16]对原始的损失函数进行优化。本文在原始SSD算法的基础上,提出了注意力特征融合SSD(Attention Feature Fusion SSD,AFF-SSD)算法,以提升对遥感图像目标检测的平均准确率。
1 AFF-SSD算法
如图1所示,AFF-SSD算法网络结构是基于VGG16[17]网络修改而来的,将VGG16网络的FC6、FC7全连接层改为Conv6、FC7卷积层,并在后面添加了4个 卷 积 层(Conv8、Conv9、Conv10、Conv11),然 后 将Conv4_3层和FC7层特征融合组成新的Conv4_3层,将FC7层和Conv6_2层特征融合组成新的FC7层。整个网络结构有6个特征图,这6个特征图有不同的感受野,会产生不同尺寸的候选框,预测不同大小的目标物体。在网络结构中,由于浅层特征图感受野小、分辨率高,用来预测小目标物体;深层特征图感受野较大,用来预测较大的物体目标。
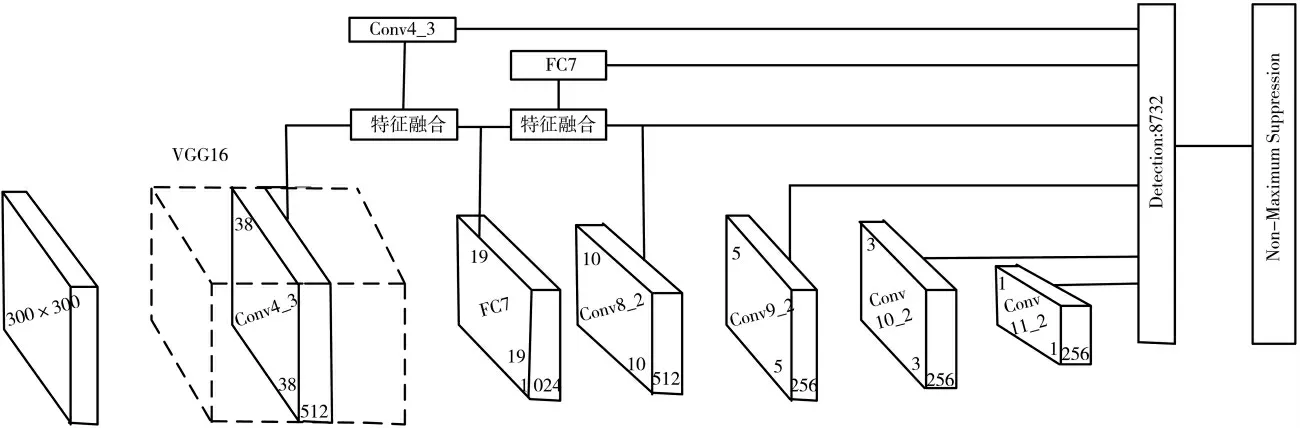
图1 AFF-SSD算法网络结构
网络以300×300图片作为输入,通过池化下采样使得图片尺寸逐渐减小,6个特征图尺寸分别为38×38,19×19,10×10,5×5,3×3,1×1,每个特征图生成候选框的数量分别为4,6,6,6,4,4,整个网络会产生8 732个候选框来预测目标物体。最后通过非极大值抑制(Non-Maximum Suppression,NMS)算法[18]过滤掉多余边界框并产生最终检测结果。
1.1 注意力模块
注意力模块本质上是通过矩阵转置相乘进行相关性计算,增加依赖性较强的特征权重,降低噪声干扰,提高对有效信息的利用率。在卷积神经网络模型中,由于卷积核选择一般都比较小,导致每次卷积操作只能提取部分的特征信息,对于距离卷积核较远的特征信息不容易被提取。为了捕捉数据和特征的内部相关性,使得远距离的特征存在依赖关系,本文提出了通道注意力模块和空间注意力模块,结构如图2、图3所示。
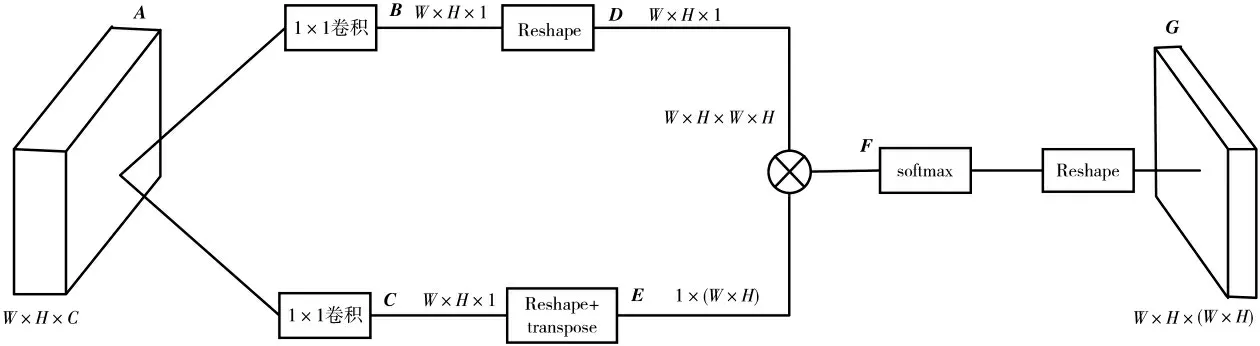
图3 空间注意力模块
通道注意力模块如图2所示,其作用为建立通道之间的依赖关系,增强语义信息的表达。输入特征图A维度为W×H×C,通过对特征图A卷积得到特征图B、C,维度均为W×H×C1,将特征图B进行维度重排和矩阵转置得到矩阵D,维度为C1×(W×H),将特征图C进行维度重排得到矩阵E,维度为(W×H)×C1。然后矩阵D和矩阵E相乘,得到特征图矩阵H,维度为C1×C1,将矩阵H在列方向上使用softmax进行归一化,得到通道注意力矩阵,具体操作如下:
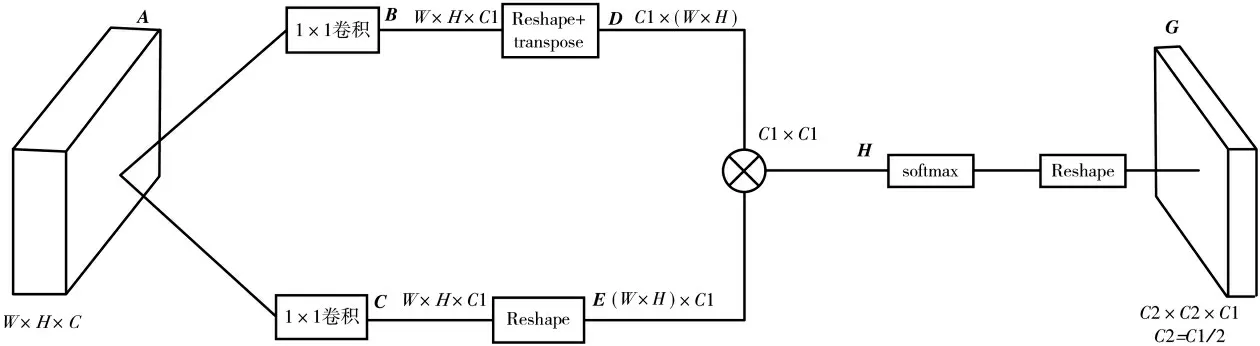
图2 通道注意力模块

式中Bji为第i个像素和第j个像素之间的相关性,二者特征越相似,则转置相乘得到的相关性越大,在注意力特征图像上具有更高的特征值。Hij为矩阵H中的各元素。最后将矩阵H维度重排得到通道注意力特征图G,维度为C2×C2×C1,其中C2=C1/2。
空间注意力模块如图3所示,其作用为降低噪声,加强对重要特征信息的提取。输入特征图A维度为W×H×C,通过对特征图A卷积得到特征图B、C,维度为W×H×1,将特征图B进行维度重排得到矩阵D,维度为W×H×1,将特征图C进行维度重排和矩阵转置得到矩阵E,维度为1×(W×H),然后矩阵D和矩阵E相乘,得到特征图矩阵F,维度为W×H×W×H,将矩阵F在列方向上使用softmax进行归一化,得到空间注意力矩阵。最后将矩阵F维度重排得到空间注意力特征图G,维度为W×H×(W×H)。
1.2 注意力特征融合模块
在SSD算法中,不同特征图的特征信息没有融合,使得用于检测小目标物体的浅层特征图缺乏足够的语义信息,因此对小目标物体的检测效果不好。传统的特征融合方法都要进行上采样操作,而上采样会引入大量噪声,对小物体目标识别会有影响。同时在卷积神经网络中,由于卷积核尺寸一般设置都比较小,导致每次卷积操作只能覆盖卷积核附近的像素点区域。对于图片上距离较远的相关特征信息不容易被卷积核捕获。针对以上问题,结合通道注意力模块和空间注意力模块,本文提出了注意力特征融合模块,对SSD算法卷积神经网络浅层特征图特征融合。
图4所示为注意力特征融合模块,在模块中有两个输入:第n个特征图和第n+1个特征图。
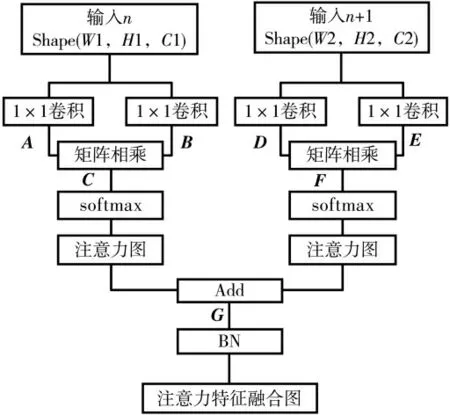
图4 注意力特征融合模块
第n个特征图,输入维度为W1×H1×C1,其中W1为输入 宽,H1为输入高,C1为输 入通 道数。首先,通过2个1×1卷积降低通道数,使得通道数变为1,维度变为W1×H1×1。然后,合并宽和高得到矩阵A和矩阵B,矩阵A维度为W1×H1;矩阵B维度为W1×H1。将矩阵A与矩阵B相乘,得到矩阵C,维度W=W1×H1,将矩阵C在列方向上使用softmax归一化,得到特征图上所有特征点与某一特征点的相关性。将矩阵C的维度展开得到第n个特征图的空间注意力图。
第n+1个特征图,输入维度为W2×H2×C2,其中W2为输入宽,H2为输入高,C2为输入通道数。首先,通过2个1×1卷积改变通道数,使得通道数C2=W1×H1。然后合并宽和高,得到矩阵D和E。矩阵D维度为(W,N;W=W1×H1,N=W2×H2),矩阵E维度为(N,W;N=W2×H2,W=W1×H1),将矩阵D与矩阵E相乘,得到矩阵F,其维度W=W1×H1,将矩阵F在列方向上使用softmax归一化,得到特征图上所有特征点与某一特征点的相关性。将矩阵F的维度展开得到第n+1个特征图的通道注意力图。将第n个特征图的空间注意力图与第n+1个特征图的通道注意力图使用特征增强方法特征融合。最后,为了增加特征多样性,采用通道拼接的特征融合方法与第n个特征图特征融合,得到注意力特征融合图。
在SSD网 络 中,主 要 由Conv4_3层、FC7层、Conv8_2层来检测小目标物体,相比于Conv4_3层,FC7层拥有更多的语义信息,而Conv4_3层拥有更多的特征信息;与FC7层相比,Conv8_2层拥有更多的语义信息,而FC7层拥有更多的特征信息。因此,在FC7层增加通道注意力模块,可以提取更多的语义信息,在Conv4_3层增加空间注意力模块,可以加强对重要信息的提取,降低噪声的影响,增强对小物体目标的检测能力。
1.3 损失函数优化
为避免因正负样本分布不均导致模型训练退化的问题,结合聚焦分类损失函数,对SSD算法的损失函数进行优化,优化后的损失函数由聚焦分类损失和位置回归损失加权求和获得,公式如下:

聚焦分类损失公式如下:
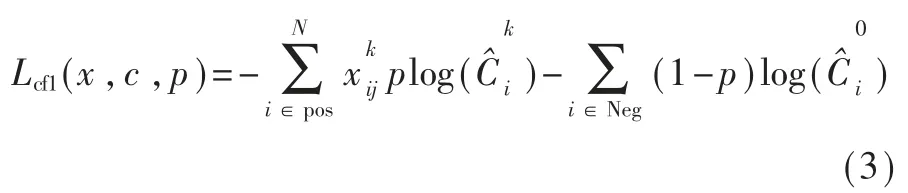
位置回归损失公式如下:

其中,cx,cy是中心点坐标;w,h分别为默认框的宽和高;为候选框的值,表示真实框相对于候选框编码。
1.4 迁移学习
迁移学习是解决小样本数据集相关问题的一个很好方法,其将一个任务上训练好的卷积神经网络模型迁移到另一个任务中,然后通过简单的调整使其适用于一个新的任务。通过模型参数共享,将在大规模数据集中预训练好的网络模型运用到其他任务中,作为其他任务的特征提取器。图5为AFFSSD算法迁移过程,该算法网络中包含有大量要训练的参数,而训练这些参数需要大量的训练数据,由于本文使用的遥感数据集较少,因此在训练网络时容易过拟合,为解决该问题,本文采用迁移学习方法训练网络。
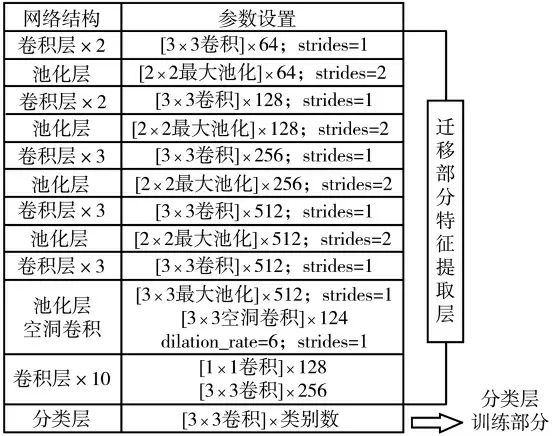
图5 迁移学习过程
2 数据集
本文使用的遥感数据集较小,训练时比较困难,因此在训练时进行数据增强。图像变换方式包括随机亮度变化(-30%~30%)、随机平移(-20%~20%)、随机旋转(30°~180°)、随机翻转(水平或垂直翻转)、尺寸变化(-20%~100%)、随机裁剪等。
首先,在VOC2012数据集进行预训练,将预训练模型的特征提取层和相应权重迁移到本文的训练任务;然后,根据本文训练任务重新设计一个分类层,和迁移过来的特征提取层重新组建一个新的卷积神经网络,用于本文数据集的训练。实验中采用两种方法进行训练:(1)冻结特征提取层,只训练分类层;(2)所有层都训练。
3 实验结果与分析
3.1 实验环境及训练方式
在Python3.7、TensorFlow2.0环境下进行实验,应用labelimg标注数据集;用RTX 2080Ti加速训练,CPU为i7-9700 3.6k@3.60 GHz*8。实验使用Adam优化器,初始学习率设为0.000 4,batch_size设置为8,Dropout为0。
3.2 实验结果与分析
表1为不同融合方式在测试集上的实验结果。本文采用平均精度(Average Precision,AP)、平均检测精度(mean Average Precision,mAP)、平均检测时间三个评价指标对不同融合方式进行检验。AP是评价目标检测精度的最重要的指标之一,其大小可是以查全率为横轴、召回率为纵轴所围成的面积大小,所围成面积越大,AP值越高,对目标检测越准确。mAP用来判别对多目标物体的检测精度,对每个类别求出AP再求和,然后除以类别数便得到mAP的值,mAP的取值范围是[0,1],其值越高检测精度越好。除了检测精度,目标检测的另一个检测指标是平均检测时间,只有平均检测时间足够短,才能实现实时检测。
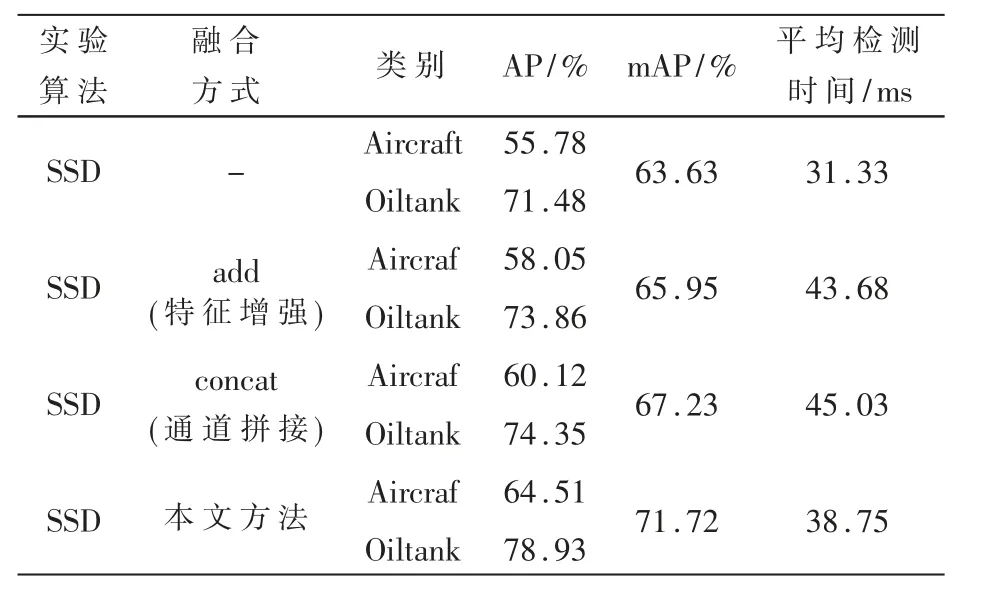
表1 不同融合方式在测试集上的实验结果
为了检测注意力特征融合方法的效果,实验中与传统的融合方法做了比较。由实验结果可知,与传统SSD算法相比,经过注意力特征融合后的SSD算法,虽然平均检测时间增加了7.42 ms,但是平均准确率均值提高了8.09%;与特征增强、通道拼接等传统融合方法相比,无论平均检测时间还是平均准确率均值,都有大幅度的提高。
图6为不同融合方式下的PR曲线。在图6中,垂直直线部分不在PR曲线内,只是一条辅助线,为了显示出不同PR曲线与坐标轴围成面积的差异,从而体现不同融合方式下AP值的差异。以垂直直线为区分条件,从左向右第一条为没有融合的PR曲线,第二条为add(特征增强)融合方式的PR曲线,第三条为concat(通道拼接)特征融合方式的PR曲线,第四条为本文注意力特征融合方式的PR曲线。由图6可知注意力特征融合方式的PR曲线所围成的面积最大,即该方式的AP值最高。
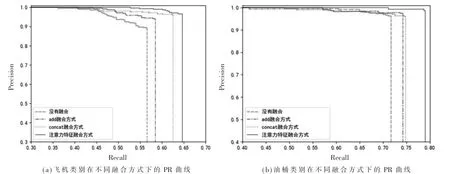
图6 不同类别在不同融合方式下的PR曲线
在图7中,灰色框(上面一层)为SSD算法的检测效果,白色框(下面一层)为AFF-SSD算法的检测效果,可以看出,AFF-SSD算法对小目标物体的检测效果好于SSD算法。

图7 SSD算法与AFF-SSD算法检测效果对比
表2为不同训练方式在测试集上的实验结果,由实验结果可知,平均准确率均值最低为迁移学习只训练分类层的训练方式,平均准确率均值为57.27%。原因是本文使用的数据集与VOC2012数据集存在差异,只训练分类层,特征提取层参数无法得到更新。而迁移学习训练全部层的平均准确率均值最高,达到75.19%,与迁移学习只训练分类层相比,平均准确率均值提高17.92%,与全新训练方式相比,平均准确率均值提高3.47%,因此,本文使用迁移学习训练全部层作为迁移学习实验结果。
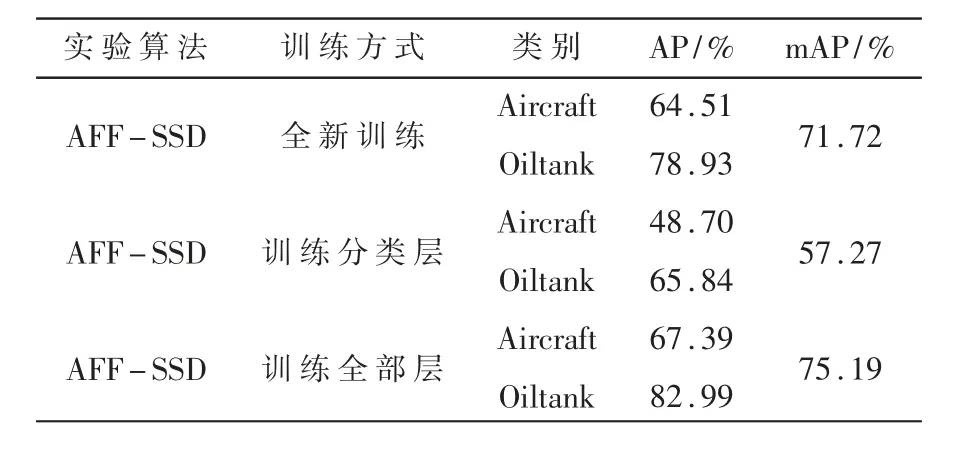
表2 不同训练方式在测试集上的实验结果
图8为AFF-SSD算法迁移学习后的PR曲线。在图8中,垂直直线部分不在PR曲线内,只是一条辅助线,为了显示出PR曲线与坐标轴围成面积,从而体现出AP值。由图8可知经过迁移学习后,飞机类别和油桶类别PR曲线所围成的面积比未经过迁移学习所围成的面积大,即经过迁移学习后,对目标检测的AP有了进一步的提高。
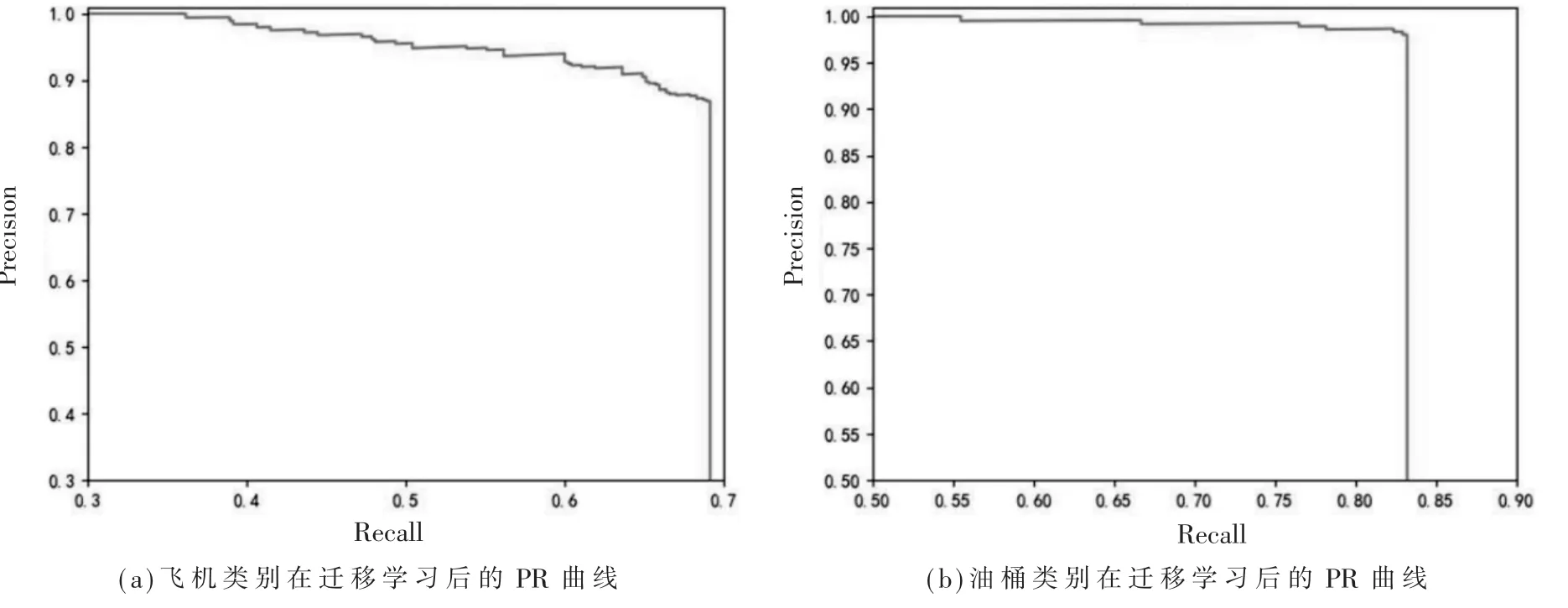
图8 不同类别在迁移学习后的PR曲线
4 结论
针对SSD算法对遥感图像小目标物体检测效果不佳的缺陷,本文提出了一种特征融合增强的SSD小目标检测算法——AFF-SSD算法。该算法的核心思想是加强SSD算法浅层特征图之间的信息交流,使用注意力特征融合模块对SSD算法网络结构的浅层特征图进行特征融合,增强浅层特征图的语义信息,从而提高小目标的检测准确率。此外,针对训练过程中正负样本失衡导致模型退化的问题,对原始的损失函数进行优化。最后,使用迁移学习的方法对网络进行训练,进一步提升检测精度。由实验结果可知,该算法对小目标具有良好的检测效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
当代陕西(2022年4期)2022-04-19
计算技术与自动化(2022年1期)2022-04-15
当代陕西(2020年22期)2021-01-18
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中华诗词(2019年7期)2019-11-25
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
