
健康类虚假信息的人工神经网络识别与治理*
2022-10-17 07:45:14赵冰洁
现代传播-中国传媒大学学报 2022年8期
詹 骞 赵冰洁
伴随新型冠状病毒的爆发,一场声势浩大的“信疫”(infodemic)也几近同时席卷全球,根据世界卫生组织的定义,“信疫”是指“信息过多——有些准确而有些不准确——这使得人们在需要时难以找到可信赖的来源和可靠的指南”①。该词的诞生可以追溯至严重急性呼吸系统综合症(SARS)疫情爆发时期,大量真假混杂信息使公众陷入集体焦虑,而真相“失声”对政治经济领域造成的危害于当时已然显露。如今面对情形更加严峻的新冠肺炎疫情,诸多真伪莫辨的信息在各类平台上的快速扩散强化了人们的焦虑情绪,也加重了“信疫”的规模与危害。
追究此次“信疫”爆发的根源,新冠肺炎疫情自身的严重性无疑是其中推动力之一,但最重要的还是整个社会的传播格局早已今非昔比。②传统媒体的影响力在一定程度上减弱,而相对疏于监管审查的各类社交媒体平台成为主流,多元发声路径造成的信息混杂以及不断被建构的信息过滤泡等都在加剧信息识别的难度。社交媒体在流量为王的逐利性传播逻辑引导下,大量推荐娱乐化、浅表化的内容,用户感官长期接触浅层次的信息刺激,导致其对部分主流严肃内容和公共议题的认知和理解能力缺乏。③由是,整体信息环境的理性客观被弱化,虚假信息进而泛滥。
根据一项基于2006年至2017年间Twitter上约12.6万个经过验证的信息的研究,各个类别的虚假信息都有着较真实信息明显更快的传播力与更深的影响力。④而在诸类信息中,相对于财经信息、科技信息、体育信息等,健康信息是大众的刚性需求⑤,公众对健康议题关注度的不断提升促发了此类信息在网络上的产生与传播。相较于真实信息,健康类虚假信息借助其更高的情感性⑥、更强的煽动性和匹配度⑦,往往会有更大的传播影响力和更严重的破坏力,亟待治理。但海量的信息治理已并非简单人力监管与审查所能解决,技术的底层参与是必不可少的治理手段。这也正是此次研究的出发点,以跨学科的视野对虚假信息的算法设计与算法治理效果进行探索,试图从微观层面观察算法治理的功效进而探讨以此为核心开展协同治理的可能性。
一、文献回顾:虚假信息的算法治理
(一)基于数字技术的算法治理
数字技术的弊端在当下不断显露,虚假信息、数据安全、隐私泄露等成为全球各国共同关注的问题,数字治理(digital governance)即是针对这一情形提出的共识性方案,其治理主体由政府、市民和企业构成。⑧在企业层面,对虚假信息的人工监管是一种有效手段,但同时更高效的方案,即算法治理(algorithmic governance)逐渐成为数字治理体系中具有核心地位和决定意义的子体系。⑨
当前的算法治理以社交平台为中心划分为内部与外部两种逻辑,分别指向虚假信息进入传播之前和进入流通之后的治理逻辑。在内部算法治理方面,由于社交平台算法对流量的追求,信息生成后并不会立刻进入快速传播阶段,而是会进入冷启动阶段,随后依据内容的反馈情况来决定是否予以进一步大量推荐。在此过程中,算法便可尽早对内容的真实性进行识别。目前采用的相关措施包括识别虚假信息中的高频关键词、通过机器学习模拟信息可能带来的情绪进而分析识别等,或是在此过程中针对被检测到的虚假信息的信源进行“降权”处理,以提升早期检测的识别效率。对于已经进入传播阶段的虚假信息,则需要借助外部算法进行治理,也即本研究希望去探索的,针对信息文本本身构建模型来识别虚假信息,之后才有可能进入更加精准的人工再次甄别与辟谣环节,提高信息鉴别的效率。
(二)人工神经网络与虚假信息的识别
虚假信息的算法识别包括基于机器学习的检测和基于深度学习的检测。机器学习方法的局限十分明显,人工设计的信息分类特征既耗费精力,又难以做到全面覆盖,普适性也较弱,随后发展出来的基于深度学习的检测方法则能够较好地解决上述问题。这类方法以人工神经网络(artificial neural network)为代表,算法能够通过给定的数据集来自行学习,寻找其中各类特征与条件,信息检测的准确率以及速率都得到了提升。
当下,人工神经网络已经拥有了相对成熟的自主学习能力,基于其上的各类模型有着不同的学习特点和适用范围,在诸多领域都取得了良好的表现。在自然语言处理领域运用较为广泛的为循环神经网络(Recurrent Neural Network,RNN),其中加入了序列的相关属性,实现了信息在不同神经网络单元中的保存与传递。最先将这一模型引入虚假信息识别的是马(Ma)等人的研究,其得到了虚假信息上下文随时间变化的特征,提升了信息识别的速率,也开创了循环神经网络在这一领域的应用。然而由于循环神经网络自身算法的缺点,其在实践中并不能够很好地处理较长序列的数据,作为一种特殊循环神经网络,长短期记忆网络(Long Short-Term Memory network,LSTM)则成功克服了这一缺点,成为当前常用的人工神经网络之一。高玉君等人对循环神经网络、长短期记忆网络以及其他人工神经网络的虚假信息识别效果进行了对比研究与评估,发现相较于其他的神经网络,长短期记忆网络有着更高的准确率与更低的损失率,取得了较好的检测结果。鉴于此,本研究在长短期记忆网络基础之上来构建虚假信息的识别模型。
(三)虚假信息治理成为交叉学科的重要研究指向
虚假信息识别与治理的相关研究目前并不局限于单一学科,而是成为很多学科共同的研究指向,既有的研究既呈现出不同学科自身的特点,又形成了观点的交融与互构。
在以政府为主导的虚假信息监管和治理中,有情报学领域的三方博弈模型和计算机领域的微博虚假信息提前把关模型。在以个体为核心的虚假信息判别与感知中,信息管理学领域的研究者关注人口学特征对健康类虚假信息的识别。心理学的研究学者则指出即便虚假信息被识别并更正,受众的判断过程中还依然存在对其的部分依赖,需要对正确信息重复更多的次数来进行纠偏。在一般性的治理策略层面,图书馆学领域的学者提出要调动社会教育职能,开展跨行业式的协作治理。新闻传播学和法学领域的学者认为推进立法、强化监控过滤、及时回应公众需求是必由的治理途径。正是受到这些多元研究视野的启发,本研究站在新闻传播学的视野之下,通过智能科学的算法模拟来探讨虚假信息治理的有效模式。
二、研究设计
(一)研究数据的获取:虚假信息集与真实信息集
为探索更加适用于识别虚假信息的算法,此次研究选取真实传播环境中的健康类虚假信息和健康类真实信息作为训练与测试的数据样本。在具体文本来源的选择上,虚假信息选取微信上的“腾讯较真平台”小程序和“微信辟谣助手”小程序中的健康类信息,真实信息则选取丁香医生科普栏目文章。
“微信辟谣助手”小程序共有包括人民网、科普中国、果壳等在内788所辟谣机构加入,目前一共辟谣了8644篇谣传文章;“腾讯较真辟谣”作为腾讯新闻旗下的事实查证平台,其在2021年全年共发布辟谣文章3189篇,为累计超过3.1亿人次提供了辟谣科普。这两个辟谣平台的相关内容均为在现实中传播的虚假信息,经过对所有内容的逐一梳理,从中共收集2000条健康类虚假信息作为研究样本。
为了不造成信息的同质化,健康类真实信息从丁香医生网站获取。该网站成立于2000年,是国内最大的专业医生社区,也是腾讯辟谣平台的最早合作机构之一。本研究采集的丁香医生网站上的健康科普信息,包括“传染病”“职业病”“急救”等多个类别。为使真实信息和虚假信息数量保持一致,以时间倒序的方式收集2000条信息作为研究样本。
将2000条虚假信息和2000条真实信息分别整合入两个文档中,先去除空格、段落符号等干扰信息,再将其以句为单位进行分行处理,使其转变为更利于算法学习的形式,最终得到包含8972句虚假信息与8464句真实信息的数据集。
(二)长短期记忆网络模型的建构
百度的开源人工神经网络深度学习平台飞桨(PaddlePaddle)于2016年8月正式开放源代码,这是中国首个开源开放的深度学习框架,其中包含诸多已有算法,可减少基础搭建的工作成本。故此次采用Paddle Fluid API编程并搭建一个长短期记忆网络(LSTM)用以检测识别虚假信息,搭建过程主要可以分为数据预处理、配置网络、模型训练以及模型评估四个部分(如图1所示)。

图1 人工神经网络算法流程
数据预处理阶段,主要是对上文提及的8972句虚假信息与8464句真实信息数据进行转化,具体的流程如图2所示。先将收集完成的数据进行解压,分别放置在虚假信息与真实信息文件夹。而后对这些数据进行初步的标记处理,在已有数据集语句的句首添加标签进行区分,其中虚假信息添加0,真实信息添加1。然后采用google公司提供的Word2Vec工具将上述句子转换成算法可以识别的词向量,汇总得到数据词典。此外,根据此次模型的需要,将所有的真实信息与虚假信息数据按照4∶1的配比划分为训练集(train_set)和验证集(eval_set),即7178句虚假信息和6771句真实信息进入训练集,1794句虚假信息和1693句真实信息进入验证集。

图2 数据预处理流程
模型训练部分是在模型各个参数初始化后,使用训练集对模型进行训练并不断修正模型。最后的模型评估部分则是将测试的数据集输入上述模型,求出其对应的损失值(cost)和准确率(acc),以此判断此次构建模型的有效性。
三、研究发现:长短期记忆网络模型能有效识别健康类虚假信息
在实际数据测量前,先对此次虚假信息判别算法的相关参数进行设定,其中共包括True(T)、False(F)、True positive(TP)、True negative(TN)这四个类别。T为正确样本个数;F为错误样本个数;TP为被正确地划分为正例的个数,即实际为真实信息且被算法划分为真实信息的样本数;TN为被正确地划分为负例的个数,即实际为虚假信息且被算法划分为虚假信息的样本数。
为更准确评估此次构建的算法模型,选取准确率(acc)和损失值(cost)两个指标进行测量。其中准确率主要测量被正确判别出真实信息或虚假信息的语句占总样本的百分比,是直接通过上文提及的TP与TN和较T与F和之比得出。
损失值则是通过对比模型预测结果与真实数据的标签得出,能够表征模型对输入信息判断的不确定性降低的程度。其中yi表示样本i的标签,0代表虚假信息,1代表真实信息。pi表示正确预测的概率,1-pi表示预测错误的概率。Cost则是表征神经网络算法优劣的重要数值,该数值越小表明模型效果越好。
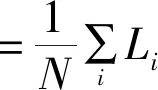
为保证得到的模型具有较好的效用,其需具备较高的准确率(acc)以及较低的损失值(cost)。针对这两个评价指标,在不断增加的迭代次数(iter)中对这两个值进行观测。模型对训练集的13949条语句进行了超过13万次的学习与训练,由图3看出损失值cost不断减小并最终达到0.1左右,而与此同时,准确率也在不断提升,并最终能够维持在0.98。两个评价指标均表现良好,展示了此模型能够在训练集上对信息的真实性进行准确识别,达到了理想的效果。
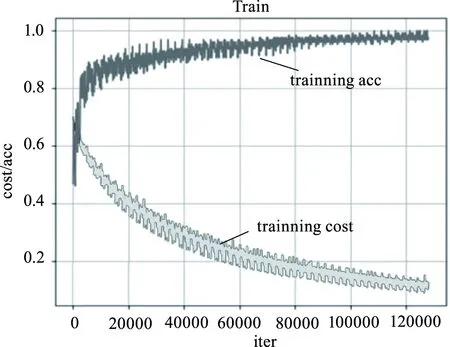
图3 训练集运行结果
模型采用同样的方法来检测测试集中的3487条语句,伴随训练次数不断增加至14万,通过图4可以看出模型的损失值cost能够稳定在0.3上下,而准确率acc能够达到0.9左右,表明各项指标均已达到较好的效果,且模型并未发生过拟合现象。这表明所构建的长短期记忆网络模型通过“自我学习”习得了健康类虚假信息和真实信息的差异,并在给出的信息环境中能够进行较为准确的进行信息识别,寻找出虚假信息。
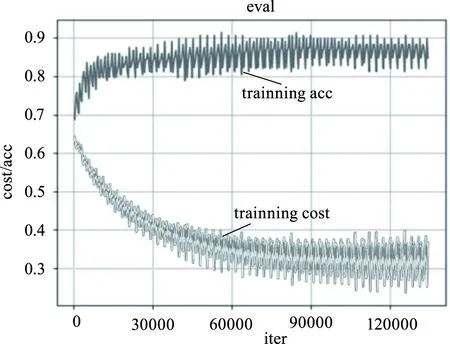
图4 测试集运行结果
四、思考与建议
(一)算法治理虚假信息的限度
本研究是一项跨学科的探索性研究,通过切实的算法实践来考量外部算法治理的建构过程与实际成效。人工神经网络模型的构建与完善建立在大量现实数据基础之上,准确、清晰的海量数据被投进算法,通过不断的深度学习与迭代,训练出算法的“自主意识”和对信息真假的判别标准,一定程度上达成了对人类思维的有效模拟,同时还跨越了人类脑力的计算极限。健康类虚假信息和其他类别的虚假信息一样,常常具有调动情绪的特征,但总体上的语言表达是直接而非间接、明确而非隐晦,便于人工神经网络模型的学习;但对于语言中出现的隐喻、反讽、双关等修辞现象,现有算法还缺乏灵活处理的能力,算法自身还有突破空间。
本研究提出的虚假信息识别模式是典型的文本识别模式,是通过对语句的信息特征来进行判别,专注于文本自身,受互联网复杂传播环境的影响较弱。但这一类模式需要建立在大量的已有数据训练的基础上,在实际的应用中,使得其所能识别的虚假信息多局限在与已有虚假数据类似的信息中,对新型虚假信息的鉴别能力较弱。同时,一些经过人为特殊处理的虚假信息也较难识别,如采用谐音、符号隔开等方式调整后的文本。
除了以上的局限性外,算法自身的“黑箱”、算法公正偏差等争议及其可能带来的技术异化问题也成为亟待解决的新难点。算法“黑箱”是普遍存在的一个现象,尤其在深度学习领域,算法的中间层数据均是由其自身对既有数据的学习提炼得到,人工并不能够探知,这也就使得其具体的计算过程难以被人工干预,具有较高的不可控性。此外,公正偏差也是算法的关键问题之一,算法这种基于大量数据的程序被给予了太高的理性期望,但其背后的设计研发人员也有个人的喜恶或利益倾向,有时难免会被代入算法之中。带有偏见的算法一旦被广泛应用,其中的不公正性被放大,就有可能造成不可逆的后果。
(二)协同治理的可行性
鉴于上述算法治理的局限性,以政府、平台、媒体等多方参与者为主体构建协同治理模式是更加可行的路径。其间,政府是处于主导地位的政策制定与管理者,把握引导整体的传播环境走向。逐利的资本与平台往往用算法充当诱饵制造信息乱象,或者以行业机密为由造成算法黑箱,政府在此间可以作为利益无关方进行独立的监控、协调与平衡。针对部分已经产生较为严重社会影响的虚假信息舆情事件,也需要政府进行及时的调节管控,必要时采取相应的法律手段。但政府的监管与协调往往是事后参与,过程控制能力相对有限。
平台内部有纷繁复杂的各类数据与算法,若要对其进行全面且细致的把控,必然需要引入前端技术人才,这对于政府而言无疑是巨大的负担,因而建立政府与平台以及平台之间的关联规范机制更加可行。平台自身可对算法进行更加严格的审核,同时不断完善虚假信息识别的方案及用户的反馈机制,以此优化平台的参与环境。平台之间建立合作关系,通过相互监督、源码开放等方法构建更高效的虚假信息识别体系。此外,平台并非中立的存在,往往存在着媒体的偏向性和意识形态属性。这也就意味着在对平台适当放权、由其主导算法治理的同时,政府要完善对平台问责的相关规范与立法,进行协调与监督。
根据爱德曼国际公关公司与清华大学国家形象传播研究中心联合发布的《2022年爱德曼信任度调查中国报告》可知,和其他国家相比,中国的受访者对媒体的信任度非常高。这充分说明了我国媒体具有巨大的信息价值影响力。在虚假信息的治理中,媒体把控好内容的编辑与审核,保证自身内容的客观性与真实性。对于已经传播并证实的虚假信息,媒体借助平台及时辟谣,尽早消除或减弱虚假信息带来的恶劣影响。自媒体环境下,用户也对虚假信息的再生产及扩散有着重要的影响,尤其是信息涉入度高、鉴别能力较低且存在主观倾向的用户更难识别虚假信息,且容易进一步传播。用户如果能提升对信息的鉴别能力,建立信息传播的责任意识,就能有效减少极端情绪或虚假信息的传播。
“信疫”时代虚假信息的传播范围以及危害程度都在不断加深,其治理过程需要多主体的共同参与。以平台算法为底层核心,形成虚假信息识别的常态化、过程化机制;政府平衡各平台间的利益关系,并监管由此所导致的算法黑箱问题;媒体则需在保证自身生产与传播客观准确信息的基础上,尽可能削弱已传播的虚假信息带来的影响,多方参与构建兼具稳固性和弹性的协同治理路径,不断净化和改善实现信息传播空间。
(三)治理中的算法张力
算法作为一种技术中介,深刻植入当下的社会生活,联结人的身体与外物,形成人的认知与意识,让人们存在于物质实在与虚拟实在之中。技术作为一种非中立的存在物,不同的技术以不同的方式构造环境。算法既可以用来制造并扩散虚假信息,同时也能够用于有组织的大规模的信息监督和虚假信息识别。不论是前者还是后者,算法的内容生产与结果产出都依据“原始数据输入—机器处理数据—得到最终数据”的链路来运行。算法能够主动进行海量学习、反馈与重构,正如本研究所呈现的,一个小型算法经过了十多万次的迭代后获得稳定,确立了自身的判别标准,而这一过程既是人通过代码编写赋予给算法独特的计算能动性,同时也正是人被算法所取代的部分。就像普通用户看不到算法在何处运行一样,算法的设计者也无法完全掌控算法的具体学习过程,如科学家在围观阿尔法狗的围棋对弈时,不知道程序的盲点和拐点会在何时出现。
算法作为一种解决问题的手段而存在,一直进行着循环的进化:为解决老问题采用新技术,新技术又引起新问题,新问题的解决又要诉诸更新的技术。算法治理文字形态的虚假信息时,专注于自然语言识别;当虚假信息演进到视频深度合成时,算法的专注点转向为图像的分类与复原。算法处理的数据也从连续、有标签的数据向空间化、无标签的复杂数据转变。算法的开发者经由技术选择不断扩张技术的适用范围,技术也在不断的迭代中构建出独特的发展逻辑与路径。在人与技术共存共生的格局下,虚假信息的生产与治理也形成了独有的算法张力,算法既是虚假信息的治理之矛,以智能化的方式抓取其特征;同时也是虚假信息的隐蔽之盾,使之获取了伪装的技术力量。如“深度伪造”也要使用以循环神经网络、卷积神经网络为代表的人工神经网络模型来实现,这就构成了虚假信息生产与识别的技术性竞争。算法在不同目标的竞争中被多方争夺,进而也在不断实现技术的自我超越。
很多知名科技公司推出了开放技术平台,算法的易得性降低了技术应用的门槛,也降低了虚假信息生产的物质成本。基于商业目的、政治目的乃至个人情感目的入场的多元主体均能充分利用算法参与信息生产,加之主体间的利益博弈,造成了虚假信息形态与类别的纷繁多样和整体信息环境的日益复杂。虚假信息生产主体的多元化和治理主体的多元化遥相呼应,在某些语境下部分主体甚至具有同一性,共同构成了交错变动的多元网络关系,而算法始终是其中重要的行动力量。作为主体的人在不断挖掘基于数据的算法智慧,同时也在锤炼驾驭技术的智慧,而算法则为人设定技术使用的阈值和边界,为人的数字治理框定范围。
(本文感谢中国传媒大学数据科学与智能媒体学院赵薇副教授的技术指导。)
注释:
① World Health Organization.NovelCoronavirus(2019-nCoV)SituationReport-13.https://www.who.int/docs/default-source/coronaviruse/situation-reports/20200202-sitrep-13-ncov-v3.pdf?sfvrsn=195f4010_6.2020-02-02.
② 方兴东、谷潇、徐忠良:《“信疫”的根源、规律及治理对策——新技术背景下国际信息传播秩序的失控与重建》,《新闻与写作》,2020年第6期,第35-44页。
③ 马玉宁:《情感与规制:社交媒体虚假信息的传播动因和治理路径》,《中国编辑》,2022年第4期,第51-56页。
④ Vosoughi S,Roy D.TheSpreadofTrueandFalseNewsOnline.Science,vol.359,no.6380,2018.pp.1146-1151.
⑤⑦ 曾祥敏、王孜:《健康传播中的虚假信息扩散机制与网络治理研究》,《现代传播》,2019年第6期,第34-40页。
⑥ Zheng X,Wu S,Nie D.OnlineHealthMisinformationandCorrectiveMessagesinChina:AComparisonofMessageFeatures.Communication Studies,vol.72,no.3,2021.pp.474-489.
⑧ 钟祥铭、方兴东:《数字治理的概念辨析与内涵演进》,《未来传播》,2021年第5期,第10-20页。
⑨ 张吉豫:《构建多元共治的算法治理体系》,《法律科学》(西北政法大学学报),2022年第1期,第115-123页。
猜你喜欢
童话王国·奇妙逻辑推理(2024年5期)2024-06-19 16:03:38
中学生数理化·七年级数学人教版(2020年10期)2020-11-26 08:24:50
数学物理学报(2020年2期)2020-06-02 11:29:24
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
中华手工(2017年2期)2017-06-06 23:00:31
光学精密工程(2016年6期)2016-11-07 09:07:19
现代防御技术(2016年1期)2016-06-01 12:13:27
中外会展(2014年4期)2014-11-27 07:46:46
