
基于密集轨迹和光流二值化图的行为识别算法
2022-10-17 11:06刘於锡寇福蔚许国梁
计算机工程与应用 2022年20期
周 航,刘於锡,龚 越,寇福蔚,许国梁
北京交通大学 电子信息工程学院,北京 100044
人体行为识别是计算机视觉的重要研究方向,具有非常深远的应用前景。目前人体行为识别的方法主要有两种:一种是传统方法即基于手动提取特征的方法,如本文使用到的iDT算法[1];另一种是基于深度学习的行为识别方法,其中较为经典的是Simonyan等[2]提出的用于行为识别的双流卷积神经网络。
传统识别方法的过程主要有三步:特征提取、特征编码和动作分类。其中特征提取就是先对视频进行采样,然后在采样点或者采样区域内提取蕴含动作信息的特征描述符。近年来,随着深度学习领域的发展,越来越多基于深度学习的特征提取算法应运而生,逐渐取代了传统的手动提取特征的方法并成为了该领域的主流。然而,基于深度学习的算法需要大量数据对其模型进行训练,有着一定局限性,因此很多研究提出将手动提取出的特征与深度学习得到的特征结合形成新的特征描述符,比如Wang等[3]提出的描述符TDD(trajectorypooled deep-convolutional descriptor),这种描述符是通过将传统算法中的iDT算法所提取出的描述符与多尺度的卷积特征一起池化所得,保留了手动特征和深度特征各自的优点,并取得了很高的准确率。
由上可知,虽然目前基于深度学习的方法相较于传统方法有着明显的提升,但是传统方法的很多模块仍能运用到深度学习算法中,所以基于传统算法的研究仍有重要的研究价值。其中,Wang等[4]提出的密集轨迹算法(dense trajetcories,DT)是传统算法中非常经典的算法,该算法首先在每帧中按照一定间隔密集采样兴趣点,并利用密集光流算法对其进行跟踪并连接成运动轨迹,之后将轨迹邻域划分成细小的子空间,从每个子空间中提取特征描述符。该算法在当时是非常有效的算法,但其缺点是对相机运动敏感,此后Jain等[5]提出了一种补偿相机运动的方法,以滤除因镜头移动引起的光流。之后Wang等[1]同样考虑到了相机的运动,提出了一种改进的密集轨迹算法iDT,该算法使用SURF(speeded up robust features)兴趣点匹配以及光流匹配来估计相机的运动,从而减少了其产生的影响。从此iDT算法取代了DT算法,成为了传统方法中的主流方法。
此后出现了很多基于iDT的改进算法,其中较为常见的改进方向是改进iDT算法用到的特征描述符,即Laptev等[6]在识别过程中运用的定向梯度直方图(histograms of oriented gradients,HOG)和光流直方图(histograms of optical flow,HOF),以及Wang等[4]用到的基于光流的运动边界直方图(motion boundary histograms,MBH),其中HOG专注于静态外观信息;而HOF捕获的则是局部运动信息;效果最好的MBH可以在一定程度上消除恒定的摄像机运动,从而保留了运动边界信息,并且可以很好地检测到人体,因此能具备更好的鲁棒性。在上述描述符的基础上,Jain等[5]基于差分运动标量、散度、旋度和剪切特征设计一个新的运动描述符即DCS描述符,它捕获有关局部运动模式的其他信息,从而提高了识别准确率。Ali等[7]提出了一些基于光流的运动学特征,包括散度、旋度、对称和反对称流场,流动梯度和应变张量的速率的第二和第三主要不变量,以及旋转张量速率的第三主要不变量。Carmona等[8]介绍了一种添加时间模板的方法,将视频序列视为三阶张量,并计算三个不同的投影,使用几个函数从视频序列中投射数据,并通过求和池将它们组合在一起。Liao等[9]提出了轨迹的多个相对描述符,即相对运动描述符和相对位置描述符,它们分别用于捕获相对运动信息和相对位置信息,此外提出了将深度特征与手工特征相结合的相对深度特征描述符。随着更多新的描述符的提出,多种特征的融合成为了新的挑战。李岚等[10]在DT算法的基础上加入了时空兴趣点特征(STIP),更重要的是实现了全新加权方式的特征融合,可以突出性能更加优越的特征描述符。
以上对于特征描述符的改进算法相较于iDT算法虽然能够取得更高的准确率,但往往增大了数据量和计算量。然而iDT算法本就有着很多数据量的冗余,其提取的轨迹数量往往非常庞大,其中混杂着一些不需要的背景轨迹,因此轨迹的滤除也是iDT算法的一种重要的改进方向。王晓芳等[11]利用两个阶段的显著性检测,识别出人体行为区域,继而获取该区域的轨迹,删除了大量无关轨迹,但此方法的显著性检测过程过于复杂。Dong等[12]通过采样点和光流的大小确定前景区域,然后在前景中提取轨迹,从而减少了冗余的轨迹,与此同时提出运动差异描述符(motion difference descriptor,MDD)来表示相关时间信息。
本文的主要贡献在于提出了基于iDT的轨迹滤除算法,相较于上述算法有着计算速度非常快的优点,并且能够在保证准确率的同时减少了轨迹数量。本文提出的轨迹滤除算法通过将光流图进行二值化来表示各点的相对有效性并基于此判断轨迹是否满足有效条件,滤除不满足条件的轨迹。这种算法的计算量较小,有着很好的实用性。
1 理论与方法
1.1 DT及iDT算法介绍
2013年,Wang等[4]提出了DT算法,在当时识别准确率领先于其他算法,随后,为了消除相机运动的影响,Wang等[1]在DT算法的基础上提出了iDT算法。算法过程如下:
首先将视频的每一帧分出至多8个尺度,之后在每个尺度按照固定的像素步长进行采样,并将自相关矩阵的特征值较小的兴趣点滤除。
密集采样得到兴趣点之后,计算出当前帧的密集光流场,光流场是一个二维矢量场,表示像素的灰度瞬时变化率,蕴含目标的瞬时速度的信息,因此可以利用光流跟踪获得的密集采样点进而形成轨迹,如公式(1)。其中(xt,yt)为当前第t帧的兴趣点的位置,(xt+1,yt+1)为下一帧的位置。M是3×3的中值滤波内核,ωt为光流场。

之后把得到的兴趣点在每一帧的位置串联起来组成密集轨迹(pt,pt+1,pt+2,…)。为了防止漂移现象的发生,限定轨迹的长度L=15帧。得到轨迹之后对两帧轨迹坐标做差得到静态轨迹的形状描述符,即位移向量的序列(Δpt,…,Δpt+L-1),密集轨迹本身的形状描述符为30维。
如图1所示,图(a)表示在该帧进行密集采样得到兴趣点;图(b)表示计算得到的光流场,这里用光流矢量图表示光流矢量在每个像素的大小和方向;图(c)表示由公式(1)计算出的兴趣点下一帧的位置,以及兴趣点在两帧之间的位移组成的轨迹;图(d)表示兴趣点经过第L帧之后的连续轨迹,这里L=15。

图1 密集采样及轨迹跟踪示意图Fig.1 Dense sampling and trajectory tracking diagram
iDT算法采用的其他特征描述符有:梯度方向直方图(HOG)、光流梯度方向直方图(HOF)、运动边界直方图(MBH)。HOG的方向量化为8个bin,故其描述符维数为96(即2×2×3×8);HOF与HOG相比添加了一个额外的bin用来记录光流幅度低于阈值的像素,所以最终描述符维数为108(即2×2×3×9);分别为光流的水平和垂直分量求导数,得到MBH的两个方向上的值MBHx和MBHy,两者的方向也量化为8个bin,故维数均为96(即2×2×3×8)。
将上述各特征向量串联,得到每条轨迹的总特征向量维数为426(30+96+108+192)。
1.2 基于光流二值化图的轨迹筛选算法
在原本的iDT算法中,对是否滤除轨迹有两种判别依据,其依据如下:在由L=15帧的位移组成的轨迹T=(Δpt,…,Δpt+L)上,计算出所有位移的标准差σ,将不满足t1<σ<t2的轨迹滤除。并且找到轨迹中的最大位移Δpmax,将不满足t3<Δpmax<t4滤除。其中t1、t2、t3和t4都是固定的阈值。
上述滤除轨迹的算法主要滤除的是固定背景点以及漂移点,在镜头固定且背景简单的场景下能起到可靠的效果,如在KTH、Weizmann数据集。然而在较为复杂的场景中,则不能有效滤除无关的背景轨迹,尤其是在镜头快速移动或强烈晃动的情况下。这是由于上述算法的滤除阈值是固定的,而每个兴趣点会随着镜头的移动产生一定的位移,这些镜头引起的位移在之前的算法中也常常被认为是有效的,导致从有镜头移动的视频中提取的轨迹往往数量庞大。在iDT算法中,Wang等[4]在DT算法的基础上考虑了镜头移动产生的影响,利用SURF兴趣点匹配以及光流匹配对镜头移动进行了抑制,并得到了抵消镜头移动的光流图。尽管如此,其对于滤除阈值t1、t2、t3和t4并没有改进。由于阈值还是固定的,在很多背景复杂的情况下还是不能得到理想的滤除效果。
因为人体的运动相较于背景的运动更为复杂和剧烈,所以光流图中最为显著的部分通常就是人物主体。因此,可以通过保留光流图中的主要部分对背景中杂乱的光流进行滤除,从而滤除背景轨迹。在与行为识别领域相关的运动目标跟踪领域,通过对光流灰度图进行二值化来识别目标也是一个比较有效的方法(如文献[13-14]),所以基于此思想提出的本文算法可以取得较好的效果。
为了减小iDT算法提取的轨迹数量,同时保证滤除的是人物主体以外的部分,本文提出基于光流灰度二值化的轨迹筛选算法。这种算法的优点是能在保证准确率的同时滤除一定数量的轨迹,并且其对计算量的需求很小。在滤除阈值tv=5的条件下滤除的效果如图2所示。图2中(a)表示原始视频中的某一帧,(b)的白色轨迹表示阈值为5时被滤除的轨迹,(c)表示原本iDT算法保留的轨迹。

图2 本文算法与iDT算法的轨迹对比Fig.2 Trajectories extracted by proposed algorithm compared with iDT
下面将介绍本文提出的基于光流二值化的轨迹滤除算法,其算法流程图如图3。
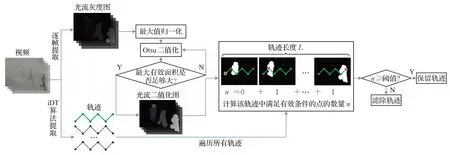
图3 本文提出的轨迹滤除算法流程图Fig.3 Flowchart of proposed trajectory filtering algorithm
首先,对每帧光流灰度图进行最大值归一化,得到归一化后的光流灰度图Fnorm,这一步在每个尺度上都进行。之后利用Otsu算法求得Fnorm的二值化阈值tbin,并由此进行二值化得到光流二值化图Fbin,如公式(2)。其中q1和q2分别表示C1和C2的像素所占比例(C1和C2分别表示大于和小于阈值tbin的灰度像素),m1和m2分别表示C1和C2的像素灰度均值。Fbin上值为1的点表示该点光流有效、0表示无效,p表示像素点。
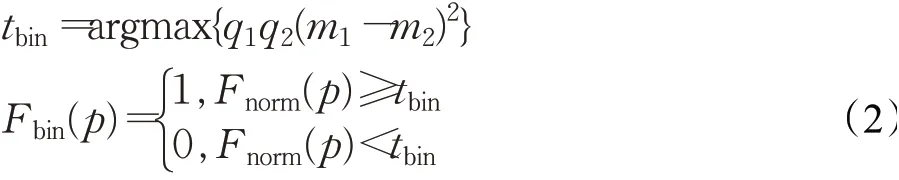
光流灰度图上的每一个点表示该点光流的大小,代表该点运动的剧烈程度。而经过最大值归一化后的Fnorm图表示的是该点的运动相对于这一帧上所有点的运动的有效程度,是相对量。在人体运动视频中,人体的运动往往相对于背景的运动更为有效,因此归一化以后可以抑制部分背景点的光流。
需要注意的是,在实际场景中由于光流会受到反光等外部环境因素的影响,在个别帧会出现局部背景点光流聚焦的情况,由于存在这种情况,第一次二值化后的有效区域会过小。因此,需要计算出Fbin上每个连通区域的面积,若不满足条件(3):

则将会根据公式(4)减小Fnorm上光流较大的值以抑制光流聚焦的情况,并计算出新的S1max,重复上述过程直到其满足条件(3)。其中S1max为光流有效部分中最大连通域的面积,S0为所有光流不有效部分的面积。这样就可以确保有效光流的面积不会被背景点的突变造成的光流聚焦所影响。

得到符合条件(3)的Fbin之后,遍历每条轨迹(pt,…,pt+L),计算该轨迹中满足光流有效条件的点的数量n,如公式(5)。之后设置阈值tv,若n≥tv则保留该轨迹,否则就滤除。其中L表示轨迹的长度,采用文献[1]中的默认值15;pt表示轨迹的第t个点表示轨迹中与pt对应的光流二值化图,和该轨迹(pt,…,pt+L)在同一尺度下,但是只和pt在同一帧。

在第2.3节本文将探讨不同数据库中tv的大小对准确率和滤除率的影响,并综合考虑准确率和滤除率后,在KTH数据集中取tv=3,在UCFsports中取tv=1。
针对光流聚焦情况的处理过程示例如图4所示,该帧经过三次二值化之后得到了满足条件的光流二值化图。其中为了区别于其他连通域,图4中最大连通域以网格填充来表示;不受光流聚焦影响的理想情况下,光流灰度图应该如(c)所示,而实际的结果则是(b)。对(b)进行最大值归一化处理后得到了(d),此时图像整体的灰度值得到了提升。对(d)用Otsu算法求得其第一次的二值化阈值tbin=29(单位为像素灰度,其范围是0~255),并由此进行光流二值化后得到图(e)。在(e)中进行连通区域面积计算,发现其不满足条件(3),于是根据公式(4)对光流聚焦区域进行两次抑制后得到(h)。对(h)进行二值化后,计算得到其S1max=3 239(单位为像素数),此时的S1max已经足够大并满足条件(3),于是将其作为最终的光流二值化结果。
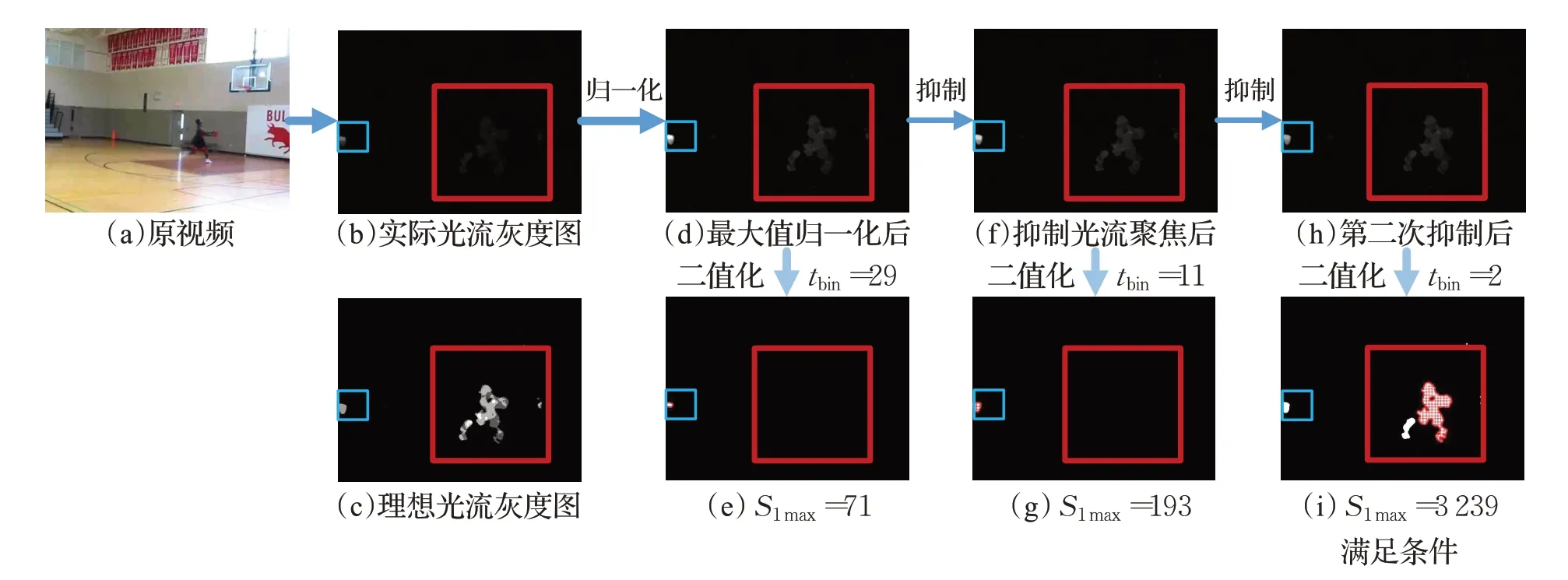
图4 针对光流聚焦现象的处理过程示例图(目标人体区域和光流聚焦区域分别用大小框标识出)Fig.4 Example of processing process for optical flow focusing phenomenon
1.3 特征编码与分类
从筛选后的轨迹周围提取特征之后,每条轨迹形成了426维的轨迹特征向量Tk,将从一个视频中提取出的m个轨迹并联得到m×426的特征矩阵E。对于不同的视频m的值不同,即提取出的轨迹数不同,与视频的分辨率和时长等因素有关。轨迹特征向量Tk由30维轨迹、96维HOG、108维HOF和192维MBH特征组成。Tk和特征矩阵E的表达式:
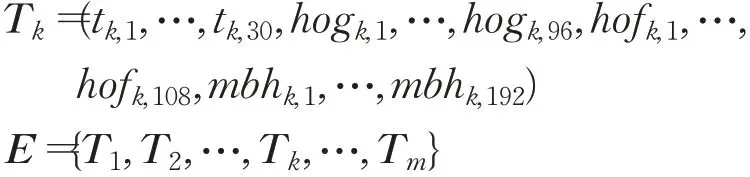
从训练集中随机抽取约200 000条轨迹特征向量,用k-means算法对这些轨迹特征向量进行聚类,得到256个聚类中心向量Ci(i=0,1,…,256),并把这些聚类中心的集合作为视觉词典。其中,初始中心点为随机选取。之后用VLAD(vector of locally aggregated descriptors)算法对训练集的每个视频的特征向量进行编码,得到大小为256×426的编码矩阵,用以描述一个视频。具体过程如下,在一个视频中,对每个轨迹特征向量Tk找到与其欧氏距离最小的聚类中心Ci,同时称Tk是Ci的其中一个轨迹元素。一个视频中,Ci的所有轨迹元素的集合表示为TCi。计算Ci与TCi中各个轨迹Tk的残差向量,将其求和并得到Vi,如公式(6):

将每个聚类中心对应的Vi并联得到一个大小为256×426的矩阵VLAD={V1,V2,…,V256},对该矩阵进行L2归一化得到该视频的VLAD编码矩阵。
对训练集的每个视频进行编码后,给每个编码矩阵贴上动作标签然后训练SVM(support vector machines)分类器,实现行为的分类识别。其中,SVM采用线性核函数,惩戒因子C=100,所有类等权重,采用one-vs-rest分类策略。本文在2.3节对算法的识别性能进行测试。
在KTH数据集中,从动作标签为boxing的第一个视频提取的特征矩阵和编码矩阵的结果如下:

2 实验结果与分析
2.1 数据集和实验环境介绍
本文使用的数据集是KTH和UCF sports。其中KTH有6个动作,595个视频,训练集和测试集的比例为7∶3。UCF sports有10个动作,150个视频,训练集和测试集的比例采用官方建议的2∶1。
本文使用了VLAD算法进行向量编码,并使用线性SVM分类器进行分类。实验环境为Windows 10 64位操作系统,VS2019搭配OpenCV 3.4.1作为开发环境,计算机配置为IntelCorei7-10710U。
2.2 轨迹的分布情况及分析
图5(a)为UCFsports库里每个动作类中的一个视频,图(b)、(c)、(d)是不同阈值tv下将n<tv的轨迹滤除后所保留的轨迹结果,其中图(b)中tv=0(不滤除任何轨迹),(c)中tv=6,(d)中tv=12。据图5所示,n较大的轨迹对人体的跟踪相对更紧密,而n较小的轨迹一般都是背景产生的轨迹,所以这也侧面证明了通过设置阈值tv来滤除轨迹可以一定程度上提高准确率。然而,若tv设置得过大,则可能也会将人体上的轨迹滤除导致准确率降低,在第2.3节将会对这一结论有所体现。

图5 UCFsports中的动作用不同阈值过滤后的轨迹Fig.5 Filtered trajectories for different thresholds
如图6,横轴表示滤除阈值tv,纵轴表示该数据库中n≤tv的轨迹数占总数的比值,即需要滤除的部分,其中n为轨迹中满足光流有效条件的点的数量,如公式(5)。据统计,在KTH和UCF sports数据库中用iDT算法提取的轨迹数量都是约1 000 000条。由图6可知整体来看在tv相同的情况下,KTH中的轨迹相较于UCFsports更难被滤除。在KTH中轨迹集中在阈值较大的区间,n≤3的轨迹数仅占整体的10%,其中满足n=15的轨迹数最多,约占全部轨迹的13%。而UCF sports则与之相反,轨迹集中在阈值较小的区间,n≤3的轨迹数占据了整体的51%。这是因为KTH的场景比较单一,兴趣点及其组成的轨迹在人体上的跟踪非常紧密,所以n的值较大,且非常多的轨迹能够满足n=15,表明该轨迹全程都在人体的主要活动位置。而UCF sports的场景较为复杂,高质量的轨迹较少,所以n的值较小。从第2.3节KTH与UCFsports两个数据集的实验结果对比来看,KTH中的动作准确率相对较高,这证明了n值的大小可以反映轨迹的有效性这一结论。
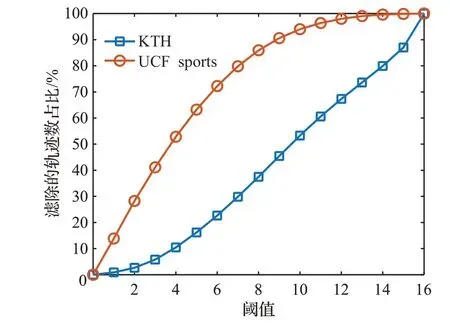
图6 滤除率随tv的变化情况Fig.6 Filtering rate for change of tv
2.3 实验结果与最优参数
本节将给出滤除n<tv后的实验结果,阈值tv=0表示不滤除任何轨迹,其结果即iDT算法原本的准确率。其中,准确率=识别正确动作数/测试集总数,滤除率=由本文算法滤除的轨迹数/轨迹总数。如表1所示,对于KTH库来说,tv=3的情况下,能够在提高1.7个百分点的准确率的同时滤除5.8个百分点的轨迹;tv=5的情况下,能够在准确率不变的情况下滤除16.2个百分点的轨迹。如表2所示,对于UCF sports库来说,tv=1的情况下,能在提高0.2个百分点的准确率的同时滤除13.9个百分点的轨迹。

表1 本文算法在KTH库的准确率和滤除率Table 1 Accuracy and filtering rate on KTH

表2 本文算法在UCF sports库的准确率和滤除率Table 2 Accuracy and filtering rate on UCF sports
如表3所示,在本文实验环境下测得本文算法的计算速度非常快,速度差(v1-v2)/v1仅约3‰,其中v1表示iDT算法速度,v2表示iDT+本文算法速度。
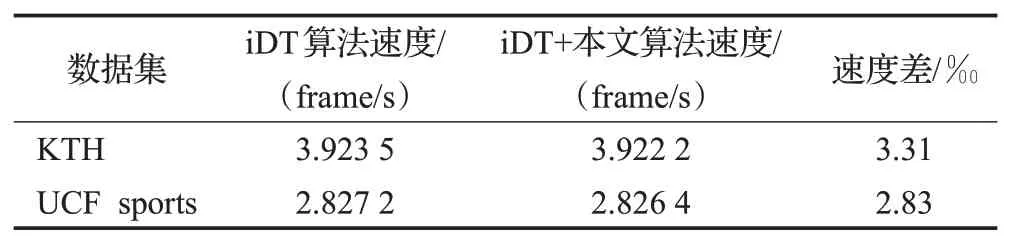
表3 本文算法的平均计算速度Table 3 Average speed of proposed algorithm
以上实验表明在KTH中取tv=3时以及在UCFsports中取tv=1时的识别准确率最高。图7以混淆矩阵的形式给出了这两种情况下的识别结果。由(a)可知,在KTH中的整体准确率很高,其中running的准确率最低,主要原因是running和jogging两个动作本身区别较小。由图7(b)可知,在UCFsports上的准确率相对于KTH较低,原因是前者的运动更多、场景更复杂并且每个动作的样本数更少。其中,Riding-Horse的准确率最低,原因是该动作样本较少且人体本身运动不明显。

图7 在两个数据集上的混淆矩阵结果Fig.7 Confusion matrix on two datasets
2.4 与其他算法实验结果对比
表4是本文算法与近年来其他基于iDT的传统识别算法的比较。其中文献[4]提出了DT算法,在KTH和UCF sports数据集上的准确率分别为94.2%和88.0%,在当时领先于其他算法。文献[1]对DT算法进行改进并提出了iDT算法,其准确率分别为95.4%和88.8%,较文献[4]有一定提升(由于文献中没有使用这两种数据集测试准确率,因此数据仅代表在本文实验环境下的测试结果)。文献[15]根据显著性检测和低秩矩阵回归提出了一种区分前景和背景轨迹的方法,并取得了很高的准确率,分别为97.5%和91.5%,然而该算法对计算量的需求相对较大。文献[16]通过显著性检测确定人体位置并由此缩小采样范围,取得95.4%和88.4%的准确率。文献[17]提出了一种基于动态高斯金字塔改进的SURF算法以加强兴趣点的匹配精度,取得了95.5%和91.4%的准确率。
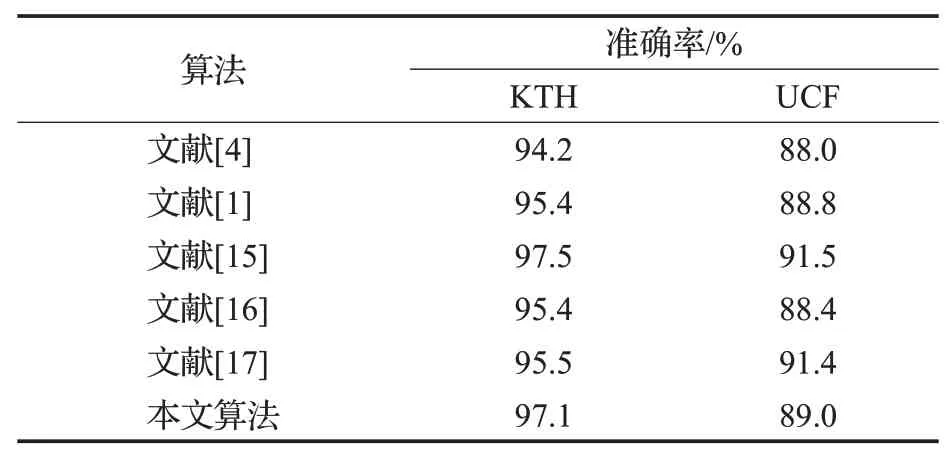
表4 各算法识别准确率对比Table 4 Accuracy compared with other algorithms
而本文提出的轨迹滤除算法在KTH数据集上的准确率为97.1%,在文献[1]的基础上有1.7个百分点的提升,在同类型算法中准确率较高。而在UCF sports数据集上的表现稍逊色,准确率为89.0%,只有0.2个百分点的提升。考虑到目前很多算法虽然能提高准确率,但往往增加了数据量和计算量,而本文算法与其他算法不同,能够在文献[1]的基础上减小数据量,并且计算速度与文献[1]相比只有大约3‰的降低(如表3),在实际应用中可以忽略不计,因此本文算法得到的准确率结果可以说是比较理想的。
3 结束语
目前很多基于密集轨迹算法的人体行为识别算法往往使得特征向量更为冗长,加大了数据量和计算量。而本文提出的通过对光流二值化来判断轨迹是否有效的算法不仅能使准确率得到提升,还能滤除一定数量的轨迹。并且测试结果表明该算法计算量比较小,实时性好。然而该算法还有一定的改进空间,滤除的轨迹超过约20%时会造成准确率的降低,日后将会对这种现象进行深入研究并改进。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
包装工程(2022年9期)2022-05-13
建材发展导向(2021年19期)2021-12-06
现代计算机(2021年10期)2021-05-28
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
集装箱化(2021年1期)2021-04-12
现代计算机(2021年3期)2021-03-24
健康体检与管理(2021年10期)2021-01-03
