
深度程序理解视角下代码搜索研究综述
2022-10-17 10:59汶东震刘海峰林鸿飞
计算机工程与应用 2022年20期
汶东震,张 帆,刘海峰,杨 亮,徐 博,林 原,林鸿飞
大连理工大学,辽宁 大连 116024
开发人员在面对日常工作任务时会进行大量搜索行为,从公共资源库(包含开源社区、论坛博客等)或私有资源库(内部软件仓库、源代码平台、社区等)搜索可复用的代码片段、特定问题的解决方案、算法设计、软件文档以及软件工具等内容,以充分利用已有的软件开发资源和经验,在提高软件复用性的同时,降低开发成本并提升开发效率。Singer等人[1]于1997年针对软件开发者行为进行跟踪调研,相关研究结果表明代码搜索(code search)已成为软件开发活动中最为常见活动。
而Sadowski等人[2]研究表明,开发者平均每个工作日会构造12条查询语句对遇到的问题进行搜索。可以看到,代码搜索在软件开发活动中重要性日益提高。
Liu等人[3]针对代码搜索工具相关工作进行了文献总结。作者从代码仓库组织、查询文本、检索模型以及评价方法角度,针对代码搜索工具建立分类体系进行归类。
代码搜索从搜索形式可分为,基于自然语言查询的代码搜索、基于测试用例的代码搜索[4]、面向缺陷检测的代码搜索、代码克隆检测、应用程序接口搜索等[5]。其共同点在于从用户需求出发,结合信息检索、程序理解以及机器学习等技术对符合用户需求的代码文件或片段进行定位。
其中,基于自然语言查询的代码搜索更为贴近开发者实际需求,是目前代码搜索研究中的热点。代码搜索任务和传统Ad-hoc任务类似,但代码搜索任务还具有以下难点:
(1)跨模态匹配问题。代码搜索任务中查询和文档分别处于不同模态。其中查询主要以自然语言形式表达,而目标文档则是程序语言语法约束的源代码文本,在计算匹配时需要考虑跨模态语义鸿沟问题。
(2)查询意图理解问题。代码搜索任务中查询所表达的意图较为多样。其包括用户开发需求、实现特定技术路线的构造性需求以及使用特定接口的API需求等,在构建检索模型对用户查询需求进行理解时需要将软件工程领域知识与语义理解模型结合。
(3)程序理解问题。代码搜索模型首先需要建立对检索对象源代码片段的理解。其包括代码基础语法语义、API功能信息、代码结构特征以及代码功能特性等。其中标识符和程序结构是构建程序理解的核心。
可以看到,当前代码搜索研究主要面临的问题是如何理解程序功能以及基于程序理解的查询意图匹配,即基于程序理解对自然语言和代码片段进行联合建模。本文则从程序理解视角出发,针对近期代码搜索研究进展进行梳理。
1 深度程序理解
1.1 程序理解
程序理解是软件工程中的关键活动,1968年召开的北约软件工程会议明确了程序理解在软件工程中的重要性[6]。软件工程师在进行软件重用、维护、迁移、逆向工程等任务时都依赖对于程序的理解[7]。
在协作开发场景下,开发者需要了解软件架构以及接口设计模式,进而对软件功能进行开发和实现;而在软件维护中,维护者需要了解已有项目中的主要功能和实现方法,以此为基础才能进一步进行缺陷检查以及修复。“理解”本质上是通过学习的手段,建立从理解的对象(如文本、源代码等)所属的概念域,到理解的主体(人、模型)所熟悉的概念域的(概念)映射[6]。
程序理解的主体是整个软件系统或者部分软件系统,旨在研究其如何运行[8]。
程序理解任务包括构建从代码模型到应用领域问题各抽象层次上的模型[9];利用领域知识理解软件,构建软件制品与使用场景之间的认知模型[10];通过阅读源代码判断其作用以及与其他构件之间的关系等。其最终目的在于支撑软件维护、演化和再工程。
按照实现方式分类,程序理解可分为基于分析和基于学习两种主要方法。基于分析的程序理解方法十分依赖分析者的个人知识和经验,构建程序理解模型等价于手动构造相关特征集。这类方法往往和具体软件系统耦合,相关经验规则较难迁移到其他项目中。同时,随着软件规模的增大,分析所需资源会随之加升高,效率会随之降低。
1.2 深度程序理解
互联网上大量开源代码的出现为基于学习的程序理解方法提供了充分的数据保证[11]。而近期Hindle等人[12]和Allmanis等人[13]研究表明,程序源代码具有和自然语言相似的特性,这种自然性(naturalness)为结合统计模型尤其是深度模型进行源代码分析理解提供了理论依据。Tu等人[14]针对源代码局部性(localness)对统计建模的影响进行了深入分析。Chen等人[15]则对深度源代码建模中的进展和挑战进行了详细梳理。
基于深度学习的程序理解框架如图1所示。其主要包含两个阶段,首先根据任务不同构建源代码文本的对应表示形式,在此基础上通过深度模型构建源代码特征向量并应用于具体任务中。

图1 基于深度神经网络的代码理解框架Fig.1 Framework of source code comprehension on basis of deep neural network model
具体而言,程序源代码首先会根据任务被转换为字符序列(char sequence)、词序列(token sequence)、API序列(API sequence)、抽象语法树(abstract syntax tree,AST)、函数调用图(function call graph,FCP)以及控制流图(control flow graph)等多种形式。
在此基础上,源代码不同表示通过神经网络转换为特征向量后被用于具体任务。
源代码不同表示形式特点以及适用任务如表1所示。基于词的表示[16]的程序建模和自然语言理解模型建模类似,实现简单易于迁移。但由于开发者自定义标识符情况的存在[17-18],基于词的代码建模方法往往会受到词表外词(out of vocabulary,OOV)问题困扰。基于字符序列的建模能够解决OOV问题,但是基于字符符号的表示方式难以学习到词义,因此在表示能力方面较弱。代码中包含的API往往设计规范,同时用词较为固定,因此针对API序列进行学习在代码搜索和摘要任务上都有着良好的效果[19]。

表1 代码理解中间形式Table 1 Intermediate representation for source code comprehension
可以看到,单纯使用词序列作为源代码的表示形式存在表示能力不足的问题,因此结合多模态方法[20]建模源代码逐渐走入研究者的视野。基于语法树的代码建模能够改善序列建模中对于程序结构学习不充分的问题。但现有研究大多采用序列采样的方式[21-22]从语法树中获取节点序列进行表示,对于树结构的利用尚不充分。Wang等人[23]提出一种改进方法用于将语法树信息融合代码表示方法,语法树作为代码序列的平行语料,在与源代码序列对齐的基础上与自然语言片段进行建模,提高了源代码搜索任务效果。
而图神经网络在自然语言文本结构上的建模能力也激发了其在代码建模上的探索[24]。源代码数据相比于自然语言文本更易构建图表示形式,因此结合图结构的程序理解模型有着较好的前景[25]。
可以看到,深度代码理解研究是众多软件工程任务的基础,不同表示形式所带来的特征向量能够为代码搜索任务提供充足的特征信息。下一章则从深度程序理解视角针对代码搜索任务进行定义。
2 代码搜索与文档搜索
代码搜索是信息检索和程序理解的交叉研究,与文档搜索技术类似,二者在诸如查询理解、文档索引、文档排序等多种技术中有着较多共性。但从搜索对象来看,由于源代码自身特性,对于代码的理解包括两个方面,即代码的使用场景以及代码算法原理。
以“冒泡排序”为查询,文档搜索和代码搜索的结果示例如表2所示。可以看到,文档搜索结果中往往包含原始关键词以及围绕关键词展开的一系列概念介绍和组合。而在代码搜索结果中,则重点关注这一算法的具体实现以及代码的正确性。

表2 代码搜索与文档搜索异同Table 2 Differences between code search and documents search
二者的核心差异在于如何实现文档(代码)的理解。同时,基于源代码功能特点、应用场景、功能实现方式等特性将代码与用户意图匹配,是两种搜索方式最大差异。
从形式化角度看,此处记Q为查询文本,C为源代码片段。如公式(1)所示,RQ(Q)为查询文本的表示模型,将用户查询转化为向量形式的中间表示。

相应的如公式(2)所示,RC(C)为程序理解模型,其将输入的代码片段转化为特征向量,进而对代码结构和语义进行表示。

查询文本和代码片段分别通过RQ和RC被表示为中间形式φ,从这两种特征向量出发计算二者匹配性质。如公式(3)所示,M(φQ,φC)表示相关度计算模型,结合向量距离等方式计算查询和代码片段匹配程度。

相关性分数ψ越大表明当前代码片段样本与用户意图匹配程度越高。如公式(4)所示,假定有Ca和Cb两个代码片段,Oa和Ob分别表示文档在结果列表中的顺序。则代码片段Ca和Cb与查询文本Q之间的相关性分数大小ψa和ψb关系决定排序位置,相关性分数越大,则在结果列表中的位置越靠前。

可以看到,代码搜索任务难点在于建立对源代码片段的理解,在此基础上实现用户查询意图和代码片段功能语义之间的匹配。
传统的基于信息检索模型的方法中,通常将代码视为普通的自然语言文档,在简单分词、去除停用词以及词干化[26]处理之后,结合自然语言模型对用户查询和代码文档进行向量化,最后计算二者的相似性。
Lucia等人[27]提出基于文本正规化的方法进行代码和文档之间的溯源。Hill等人[28]将方法名信息引入检索模型中增强代码检索结果表现。Lv等人[29]则结合API理解改进基于信息检索的代码搜索系统,其实现简单明了,是常用的研究基线。
Arwan等人[30]将主题模型和Tfidf模型[31]结合引入源代码和查询表示,提升了查询和代码匹配的准确性。Bajracharya等人[32]重新归类了代码搜索特征,并按照语义类别不同重新分配了特征权重,提高了检索效果。Niu等人[33]提出结合排序学习的代码搜索方法。Jiang等人[34]在此基础上对代码搜索特征体系进一步扩充,并将其与排序学习结合。
深度代码搜索研究则结合深度程序理解研究构建检索模型。Jiang等人[35]率先研究了源代码和自然语言之间的语义鸿沟问题。如图2所示,查询文本和代码片段通过自然语言模型和程序理解模型获得特征表示。获取特征向量后,通过深度模型构建匹配关系。

图2 深度代码搜索研究框架Fig.2 Research framework of deep code search
自然语言模型部分,词表示方面,常用word2vector模型[35]、glove模型[36]以及fasttext模型[37]进行表示;上下文表示方面常用Elmo模型[38]、Bert模型[39]等直接对句子建模获取表示。
匹配模型部分,Mitra等人[40]和Xu等人[41]研究了将排序学习训练目标与深度模型相结合,即神经信息检索模型。Wang等人[42]针对神经检索模型中的损失函数进行了总结,对比学习排序(contrastive learning)、三元排序(triplet loss)等方法逐渐受到关注。Wang等人[43]则结合强化学习改进查询理解,进而提高检索效果。
程序表示模型部分,Allamanis等人[44]进行了较为详细的总结和归类。早期研究将代码片段看作普通文本,结合自然语言建模方法,对词序列[45]和API序列进行建模;随后一些工作逐渐重视代码结构特性,提出结合抽象语法树[46-48]的代码结构建模方法;而源代码较强的图结构使得近期结合图神经网络源代码建模研究正逐步受到重视。
3 深度代码搜索
本章从深度程序理解模型角度对当前代码搜索研究进展进行梳理。
如表3所示,在论文选择依据方面,本文使用code search、code retrieval作为关键字进行搜索,涵盖软件工程、自然语言处理、神经计算等领域。最终,在相关会议、期刊以及预发表平台Arxiv上收集到与深度代码搜索相关的研究共40余篇论文。在此基础上,针对本文剔除了案例研究型论文、系统设计型论文以及没有明确评价指标的研究论文,最终留下27篇进行汇总。
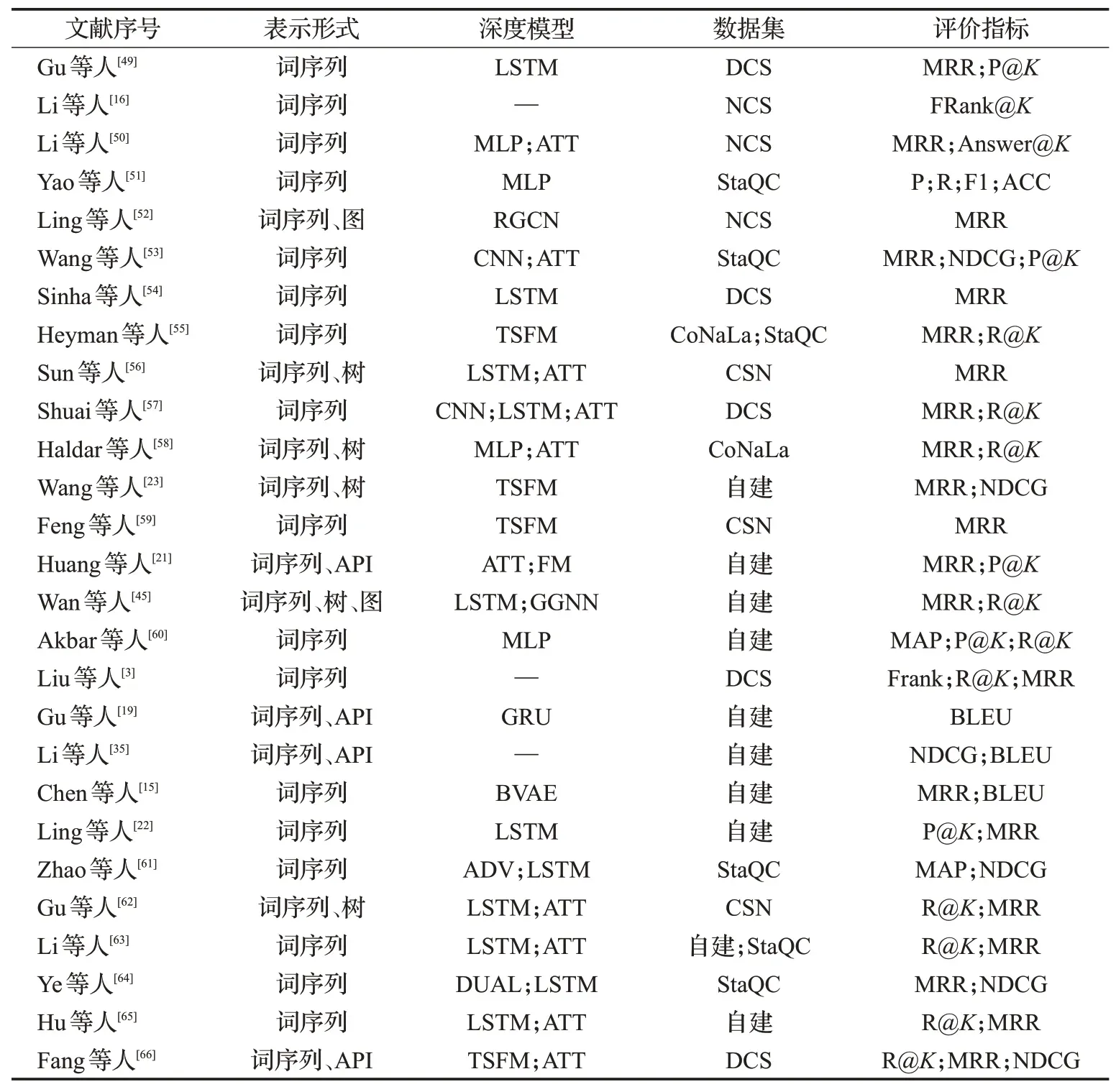
表3 深度代码搜索模型对比Table 3 Comparison between deep code search models
分析维度包括源代码表示形式、深度模型结构、模型评估所使用数据集以及评价指标四个部分。源代码表示形式从深度程序理解视角出发规划,主要包括词序列表示、API序列表示、树结构(主要是抽象语法树)和图结构(函数调用图、语法树子图等)。深度模型结构方面包括卷积网络(CNN)、循环网络(LSTM)、Transformer、注意力机制等。
Gu等人[19]对深度代码搜索进行了早期探索,其首先对API的搜索和生成进行了研究,并在此基础上提出了深度代码搜索模型CodeNN,奠定了深度代码搜索模型的基础框架。而Li等人[16]则结合词向量以无监督方式对源代码进行建模,代码文本被处理为词序列后通过词向量构建篇章表示并在此基础上实现匹配检索。Chen等人[15]在此基础上进一步详细研究了自然语言和API之间的语义鸿沟问题。而Liu等人[3]则结合Li等人方法为代码搜索工具增添模糊查询能力。
从Gu等人工作出发,一系列尝试将不同深度模型架构应用于代码搜索任务中。Li等人[50]初步尝试了将注意力机制引入代码匹配计算中。Wang等人[53]则使用CNN构造多层注意力网络捕获源代码深度语义。Sinha等人[54]则将孪生网络应用于代码搜索任务中以增强查询和代码之间的匹配能力。Ling等人[22]将关键词匹配和句法模式学习相分离,提出在新的代码库上泛化性更强的自适应深度代码搜索模型。Zhao等人[61]则将对抗学习应用于训练过程中,提升了代码与查询文本的匹配度。
单纯序列建模方法难以利用源代码的结构信息,Haldar等人[58]和Sun等人[56]使用抽象语法树来信息增强代码表示能力。Gu等人[62]在此基础上结合语法树建模源代码中的语义依赖。Fang等人[66]则首次将自注意力网络用于代码搜索,Wang等人[23]在此基础上结合自注意力网络对源代码序列信息和结构信息进行统一建模。
图是源代码中普遍存在的结构,Ling等人[52]从语法树出发构建子图以对代码中不同节点之间关系进行建模。之后使用关系图卷积网络建模对查询和代码特征向量进行相互增强,最后提高检索效果。Wan等人[45]则将源代码不同表示方法视为多模态任务,将代码序列、语法树以及图三者融合对代码进行语义建模表示。最终结果取得了SOTA效果,证实融合序列和结构语义在代码理解任务上具有实际效果。
而在预训练模型方面,随着Bert[67]等基于Transformer预训练模型在自然语言处理领域各项任务上取得SOTA结果。部分研究者也开始关注源代码的预训练效果。Feng等人[59]结合对比学习训练范式,在代码文本上进行Bert模型训练。Kanade等人[68]则聚焦于Python代码进行了Bert模型训练,并提出CuBert模型。Guo等人[25]将代码结构加入与训练过程中,提出GraphCodeBert,结合图结构增强了Transformer在预训练代码时的表达能力。而Ishtiaq等人[69]则在CodeBert等模型基础上通过代码搜索任务对与训练模型在具体代码理解任务上的效果进行了实际验证。结果表明,基于Transformer的预训练语言模型在代码理解任务上同样具备良好效果。
4 数据集和评估方法
4.1 评价指标
代码搜索任务评价指标和信息检索任务一致,主要考虑结果的两个方面,即检索结果的相关性以及相关结果的排名次序。
精确度P@K计算方法如公式(5)所示,衡量检索结果中相关文档数量占检索结果的比重,其中K表示一次检索过程中得到的文档数目。

召回率R@K计算方法如公式(6)所示,其主要衡量检索结果中相关文档数目占总体相关文档的比重,K表示一次检索中得到的文档数目。

可以看到,精确度和召回率指标能够衡量前K个检索结果中相关文档比率的情况。
平均倒数排名(mean reciprocal rank,MRR)引入相关文档在结果中顺序进行结果评价。如公式(7)所示Ranki表示相关文档在检索结果中的次序。

如公式(8)所示,平均精确度(average precision)将精确度和文档次序相结合。其中m表示当前检索结果中相关文档总数,N表示检索结果总数,P(k)对应为本次检索结果中前k个结果的精确度(即P@K),rel(k)为一个指示函数,当第k个文档相关时为1否则为0。

MAP指标则将API在所有查询Q上计算了平均。
折扣累积增益(DCG)则将相关性等级引入评价。如公式(9)所示。rel(k)衡量第k个文档的相似性分数,如1~4整数阶段式分数,分母处取当前次序相关的对数作为折扣因子。

而归一化折扣累计增益NDCG指标则使用最优排列结果下的DCG分数对其归一化。除以上指标外,还有Frank评价描述在检索列表中首个相关结果在列表中次序。
4.2 评估数据集
本文针对2016年至今的代码搜索研究工作进行梳理,对其中用于评估模型效果的数据集进行了总结。选择标准方面,数据集必须公开可用,同时至少有两篇以上工作都使用该数据集对模型进行评价。
代码搜索常用评估数据集,如表4所示。其中共涉及七篇工作。数据集构造方面,目前工作主要通过自动化抽取方式构建大规模代码片段——自然语言文本组合作为训练数据。在自动标注基础上结合负采样方法构建验证数据。模型评估使用常见代码搜索问题作为查询,在构建的代码库上进行精细标注。

表4 代码搜索任务评估数据集Table 4 Evaluation datasets for code search task
按照数据标注划分,其中CSN和ROSF数据严格进行了相关性等级标注;DCS、NCS和CosBench首先筛选了自然语言查询,之后在代码库上标注了相关代码片段。
按照评价指标划分,CNS和ROSF可以使用NDCG进行评价;StaQC主要结合文本分类指标进行评价;其余数据集大多采用MRR、P@K以及Frank指标进行评估。
按照编程语言划分,DCS、NCS、ROSF、CosBench数据集主要包含Java编程语言代码数据(涵盖安卓)。CoNaLa数据则结合Stackoverflow社区数据挖掘以及人工标注,构建了含有Java和Python编程语言的数据。StaQC数据集主要包含Python和SQL两种标注结果。CodeSearchNet数据集则包含Java、Python、Php、Ruby、Go、Javascript六种编程语言,覆盖编程语言范围最广。
按照任务划分,StaQC将代码搜索任务转换为相关文档分类问题,因此可结合文本分类方法进行研究;CSN和ROSF数据标注等级信息充分,可结合排序学习方法进行研究;其余数据集中包含的代码片段——自然语言组合可被用于代码摘要任务以及基于摘要技术的代码搜索研究。
4.3 结果对比
本节在数据集和评价指标介绍基础上,从模型效果角度对近期代码搜索实验工作进行梳理,重点侧重基于深度模型的代码搜索方法。评价指标则涵盖Recall、Precision、MRR、MAP、NDCG。统计时,提出数据集的相关文献Baseline相应在文献一栏中加粗注明。部分数据集如StaQC数据集提出时使用分类指标作Baseline,因此此处未注明。
具体结果如表5所示,本文按照数据集、相关文献以及评价指标对结果进行了组织。从数据集角度来看,StaQC数据集应用最为广泛,相对影响力较大。DCS数据集上的实验相对更为充分,不同文献基本覆盖了所有的评价指标。从评价指标角度看,MRR指标是目前代码搜索模型验证时的常用指标。而从编程语言角度来看,目前研究较多的编程语言为Java。

表5 代码搜索模型结果对比Table 5 Comparison of code search model results
5 未来研究展望
代码搜索研究正逐渐受到学界重视,本文从深度程序理解视角出发对代码搜索近期进展进行了梳理,而未来还可以从以下方面对该问题进行研究:
(1)稳定可复现的评价方法。当前多数研究中未开放评估数据集,而开放的数据集中存在着标注不一致等问题。Liu等人[73]研究表明数据集和开源代码问题使得深度模型的结果可复现性存在诸多问题。未来研究中应尝试构建一致明确的数据集和评价方法以及平台,以促进代码搜索研究。
(2)深入研究程序表示技术。源代码的理解和建模是代码搜索任务的关键。大多数模型采用序列建模方式对源代码进行特征抽取表示,少数工作将树、图结构数据简单进行了拼接融合以引入代码结构信息。在未来研究中可以尝试结合图神经网络对代码进行更加深入的结构建模。
(3)多模态源代码建模方法。源代码由标识符和编程语言特定的关键字组成。其中编程语言特定的关键字提供了代码的结构信息,而代码标识符则提供了更为充分的自然语言信息。未来研究中可以将两种模态数据相结合,对代码的结构语义以及自然语义进行统一建模,进而用于代码搜索任务。
(4)代码搜索研究应用问题。当前代码搜索研究重点关注基于深度代码建模方法的重排序问题。而代码搜索工具研究则更加关注代码数据的采集、清洗和管理。代码搜索研究中一些数据处理方法和效果优化方法与实际应用系统之间并不适用。未来研究中可以从实际应用目的出发设计搜索模型。
6 总结
本文首先以深度程序理解视角切入对代码搜索任务进行了定义。其次,以此为基础总结得出深度代码搜索两种研究范式,并进行梳理相关研究成果。同时,本文总结整理了代码搜索任务常见的评估方法。最后结合本文研究结果,对未来研究进行了展望。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
现代信息科技(2021年21期)2021-05-07
电脑爱好者(2017年7期)2017-05-06
新高考·高二数学(2016年7期)2017-01-23
农家书屋(2016年11期)2016-12-23
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
世界汽车(2016年9期)2016-09-29
