
基于深度学习的立体影像视差估计方法综述
2022-10-17 10:59王道累肖佳威李建康
计算机工程与应用 2022年20期
王道累,肖佳威,李建康,朱 瑞
上海电力大学 能源与机械工程学院,上海 200090
从RGB图像中估算深度是计算机视觉、图形和机器学习领域一直在探索的问题之一[1],其关键在于找到空间像素对应点,然后通过三角剖分实现深度恢复,通常称为视差估计或立体匹配。视差是指左右图像中同物体在水平位置的差异[2],即在左图中位置(x,y)的物体与其相对的右图中的位置(x-d,y)。当物体的视差d已知时,可用公式z=fB/d计算它的深度:其中f是相机的焦距,B是相机中心之间的距离。在给定相机在不同水平位置拍摄的两幅图像,将其校正后,可以计算出左侧图像中每个像素的差值[3]。双目视差估计利用左右视图之间的交叉参考的优势,获得场景中物体的深度信息,在几何信息推断方面表现出强的性能和鲁棒性,广泛应用于自动驾驶[4]、机器人定位[5]、医疗诊断[6]和三维场景重构[7]等领域。典型的立体匹配算法包括四个步骤:匹配代价计算、代价聚合、视差优化、视差后处理[8]。它们可以大致分为全局方法和局部方法,全局方法通常通过最小化包含数据和平滑项的全局目标函数来解决优化问题[9],而局部方法只考虑邻域信息[10]。
尽管传统视差估计方法已取得巨大进展,针对无纹理区域、重复图案和薄结构等问题[11],仍难以解决。近年来,深度学习发展迅速,表现出较强的图像理解能力[12]。为了更好地估计立体图像对中的视差,卷积神经网络被应用在双目视差估计中。深度学习模型可通过一个卷积神经网络[13](convolutional neural networks,CNN)将匹配代价计算、代价聚合、视差优化集合起来,并取得完整且稠密的视差图。
1 非端到端视差估计方法
非端到端的视差估计方法模仿了传统视差估计方法,将其中的一部分或者多个部分通过CNN来代替。MC-CNN[14]最先提出使用卷积神经网络学习小图像块的相似性度量来计算匹配代价,通过构建一个包含相似和不相似补丁块的二元分类数据集进行训练,在当时的KITTI数据集和Mddlebury数据集上优于其他方法,有力地证明了CNN提取特征优于手工提取特征。尽管具有良好的精度,但MC-CNN具有计算消耗较大、计算速度较慢的问题。Shaked等[15]提出了一种新的多级加权残差路径高速网络来计算匹配代价,使用支持图像块多级比较的混合损失进行训练。Chen等[16]通过深度嵌入模型来利用外观数据来学习相应图像块之间的视觉相似性关系,并将强度值显示映射到嵌入特征空间以测量像素的不相似性。这些方法并不能直接得到良好的视差图,通常需要初始代价通过非学习的后处理函数进行优化,包括交叉代价聚合[17]、亚像素增强[18]、左右一致性检测和滤波等操作[19]。
传统方法中除匹配代价以外的部分也可由神经网络来计算,SGM-Net[20]设计了一种使用半全局匹配预测高精度稠密视差图的神经网络。它是一种基于学习惩罚估计的方法,将一个小的图像块及其位置输入到带有半全局匹配的网络中,预测3D结构对象的惩罚,引入一种新的损失函数,能使用稀疏注释的视差图。因其半全局匹配惩罚代价标签获取繁琐,其训练耗时耗力。
视差后处理的过程也可以在神经网络中进行,并取得良好的效果。Gidaris和Komodakis[21]通过训练一个深度神经网络,将输出标签和输入图像的初始估计作为输入,预测标签的新的精确估计。它将标签改进分为三个步骤:(1)检测不正确的初始标签估计;(2)用新标签替代不正确标签;(3)预测剩余标签来细化更新的标签。这一过程虽然能提升一定精度,但需要消耗巨大计算资源。
非端到端的视差估计方法相对于传统方法精度方面有巨大提升,但是其需要消耗巨大的计算资源,预测一张图片的时间较长。而且视差估计过程中感受野有限,缺乏上下文信息,仍然无法避免视差后处理,正逐渐被端到端的视差估计方法所取代。
2 端到端视差估计方法
端到端的视差估计方法将视差估计的所有步骤集成到一个网络中去,极大地提高了匹配精度和速度,被广泛地应用于机器人导航[22]、增强现实[23]和虚拟现实[24]。PSMNet(pyramid stereo matching network)[25]提出了一种端到端的金字塔视差估计网络,设计了一种空间金字塔池化模块(spatial pyramid pooling,SPP)用于增加感受野,将不同规模和位置的上下文信息利用起来,形成代价体;设计了堆叠沙漏3D卷积神经网络(stacked hourglass 3D CNN),结合中间监督,并拓展代价体中区域上下文支持。为了减少人类在神经网络设计上的精力,LEAStereo(hierarchical neural architecture search for deep stereo matching)[26]提出一种将人类特定任务知识整合到神经架构搜索(neural architecture search,NAS)框架中,从端到端分层NAS架构来进行深度立体匹配,利用体积立体匹配管道,允许网络自动选择最优结构的特征网和匹配网。
虽然上述的网络能够很好地学习图像的全局上下文信息,能够对图像对进行高精度的双目视差估计,但是在训练和使用的过程中计算的参数量过大,需要占用巨大的GPU(graphics processing unit)资源[27]。在实际应用过程中,人们更加倾向于使用更加轻量化的模型,在保持一定精度的基础上取得良好的视差估计效果[28]。GA-Net(guided aggregation net)[29]提出了半全局聚合层(semi-global aggregation layer,SGA)和局部引导聚合层(local guided aggregation layer,LGA),尽可能少地使用3D卷积,计算成本和内存占用得到极大减少。SGA层实现了半全局匹配(semi-global matching,SGM)的近似可微分,使匹配代价在全图的不同方向聚合,而LGA层遵循传统的代价滤波策略,被用来处理细结构和边缘对象。为了显著加快当前最先进的视差估计算法的运行速度,以实现实时推理,DeepPruner(learning efficient stereo matching via differentiable patchmatch)[30]设计了一个可微分的PatchMatch模块,在不评估所有代价体的情况下去除大部分差异,得到稀疏表示的代价体,减少计算量和内存。BGNet(bilateral grid learning networks)[31]设计了一种基于深度学习的双边网络的新型保边上采样模块,通过切片操作从低分辨率代价体中有效地获得高分辨率代价体进行视差估计,许多现有的网络都可以加入此模块,并有相当的精度,如GC-Net(geometry and context network)[32]、PSMNet[25]和GA-Net[29]等,并可以加速4~29倍。
端到端的视差估计方法在生成精确的几何信息方面有广泛的前景和鲁棒性,使用大规模的数据集对深度学习模型进行训练,能够使其在许多立体视觉任务中都表现出良好的性能,相比于传统的视差估计方法取得了显著的提升,成为现阶段研究的热点之一[33]。然而,端到端的视差估计方法训练过程缓慢,需要消耗巨大的计算资源,其使用的立体数据集需要包含高质量的曲面法线和真实视差图,高质量数据集制作费时费力。
3 无监督视差估计方法
高精度的数据集对网络训练的好坏具有重要的作用,但是带有真实视差图的高精度数据集制作较为昂贵。一些不具有真实视差图的数据集获取较为简单,为此一些无监督视差估计方法被提出[34]。无监督的方法以无监督的方式驱动网络,依赖于最小光度扭曲误差。近年来,基于空间变换和视图合成的无监督学习方法被提出,并取得了不错的精度。
DeepStereo[35]提出一种新的深度学习架构,对大量位姿图像集进行训练,直接从像素中合成新的视图。深度回归网络直接回归到给定输入图像的像素颜色输出,对传统方法的故障模式也有用,能够在宽基线分隔的视图之间进行插值。Deep3D[36]设计了一个深度神经网络,通过最小像素级重建损失,将左视图作为输入,内部估计一个软概率视差图,然后渲染出一个新的右图像,直接从一个视图预测另一个视图。这些视图合成网络为无监督视差估计提供了强大的支持。
图像损失函数在无监督的视差估计中也有使用,Garg等[37]提出了第一个利用图像重建损失进行单视图深度预测的深度卷积神经网络,通过类似于自动编解码器的方式训练网络。为此,其使用预测的深度和已知的视点间位移显式生成目标图像的反向扭曲,以重建源图像,重建中的光度误差是编码器的重建损失。该网络虽然与单视图深度估计的最佳监督学习方法相当,但是单个图像整体尺度模糊,单目视差估计不仅在绝对意义上准确,而且在细节恢复上效果也不好。
单独解决图像重建问题会导致深度图像质量差,Godard等[38]提出一种新的训练损失方法,加强了左右图像差异之间的一致性,其还充分利用了极线几何优势。这一致性约束极大的提高了网络性能,这项工作标志基于最小化光度扭曲误差的无监督视差估计方法的成熟。Flow2Stereo[39]提出了一种无监督模型,联合学习光流和视差估计,将视差估计当做光流估计的特殊情况,利用立体视觉的三维几何信息指导同一网络来估计光流与视差。
无监督的视差估计方法解决了缺乏真实视差图难以对神经网络的训练的问题,仅使用一些较易拍摄的左右视图就可对网络进行训练,极大地减少了数据集制作的成本。但是,其在弱纹理区域,图像重建损失函数无法得到良好的有监督信号,而且并没有办法得到视差图的真实尺度,重建出来的效果一般,在实际应用中受到一定限制。
4 视差估计网络模型比较
在深度学习视差估计网络实际应用中,为了方便和易于使用,需要将视差估计的整个过程集合到同一网络上进行。而且对重建出来的图像质量要求也较高,使用端到端的视差估计方法是一种很好的选择。本文选取5种深度学习视差估计方法,分别是PSMNet[25]、GA-Net[29]、LEAStereo[26]、DeepPruner[30]、BGNet[31],PSMNet和GANet是预测较慢,有不错精度的视差估计网络,Deep-Pruner、BGNet是能够实时预测的最新网络,而LEAStereo是神经架构搜索生成的网络,对这些网络实验比较实时和非实时网络之间的精度和参数量,以及神经网络搜索产生的网络与人工设计的网络之间的差异。其中PSMNet的创新性在于其设计空间金字塔池化模块和堆叠沙漏3D卷积神经网络,充分利用全局上下文信息;GA-Net利用引导代价聚合代替广泛使用的3D卷积,降低计算成本并获得更好的精度;LEAStereo将神经架构搜索运用到视差估计任务中,允许网络自动选择最优结的特征网和匹配网;DeepPruner开发了一个可微分的PatchMatch模块,逐步减少搜索空间,高效地计算高似然假设的成本量。BGNet设计了一种新的基于学习双边网格切片操作的边缘保护代价体上采样模块,通过切片操作从低分辨率代价体中有效地获得高分辨率代价体进行视差估计。
4.1 PSMNet
PSMNet[25]是深度学习视差估计模型中最经典的算法之一,后续很多算法将其作为参考。其创新点在于使用金字塔池化模块和扩张卷积用于增加感受野,将特征由像素级拓展到不同感受野尺度的区域级,将全局和局部特征线索用于形成视差估计代价体。此外,还设计了一个堆叠沙漏3D卷积神经网络结合中间监督,以规范代价体,为提高上下文信息提取率,以自上而下/自下而上的方式对代价体多次处理。
PSMNet是一种端到端的视差估计网络,其模拟传统的视差估计流程,将问题分解为特征提取、特征代价体的构建和稠密匹配这几个阶段,每个阶段由可微块组成,从而实现的端到端的训练。PSMNet模型由4个步骤组成:(1)通过一系列的2D卷积提取图像的一元特征,并将输出的特征图输入SPP模块来收集上下文信息,然后将这些特征进行融合,这些模块本身之间权重都是共享的;(2)在每个视差级别上将左特征映射和它们对应的右特征映射连接起来,形成一个成本量,从而产生一个4D体积(H×W×D×F),其中H、W为图像的高、宽,D为视差值,F为特征尺寸;(3)为了沿着视差维和空间维聚合特征信息,使用了堆叠沙漏(编码器-解码器)架构,由重复的自顶向下/自底向上处理和中间监督组成,三个主要的沙漏网络共同组成该结构,每一个都生成一个视差图,总损失计算为三个损失的加权和;(4)通过双线性插值将代价体上升到H×W×D,通过回归来计算视差,使用softmax操作σ(·)从预测成本Cd中求得每个视差概率d,预测视差d̂通过每个视差d按其概率加权的和计算。PSMNet网络结构图如图1所示[25]。

图1 PSMNet网络结构示意图Fig.1 Diagram of PSMNet network structure
4.2 GA-Net
GA-Net[29]的主要创新点是提出了SGA层和LGA层,更好地学习局部和全局代价之间的关系。相比于PSMNet使用了大量的3D卷积,通过这两层结构替换其中的3D卷积层,提升视差估计精度,减少立方计算和内存复杂度。GA层的浮点运算方面的计算复杂度小于一个3D卷积层1/100,仅使用两层引导聚合块的网络远优于19个3D卷积层的GCNet[32],可以通过GA层构建实时的模型。
在新的神经网络层中,第一种是SGA,它是受SGM[40]的启发,是半全局匹配的可微近似。在SGM中有许多用户定义的参数(P1、P2),这些参数的调优并不简单[20]。而且其代价聚合和惩罚是固定的,这包括所有的像素、区域和图像,对不同条件的适应性较低。难最小值选择还会导致在视差估计过程中产生大量的前向平行曲面。Zhang等[29]提出一种新的可反向传播的半全局代价聚合步骤,如下式所示:
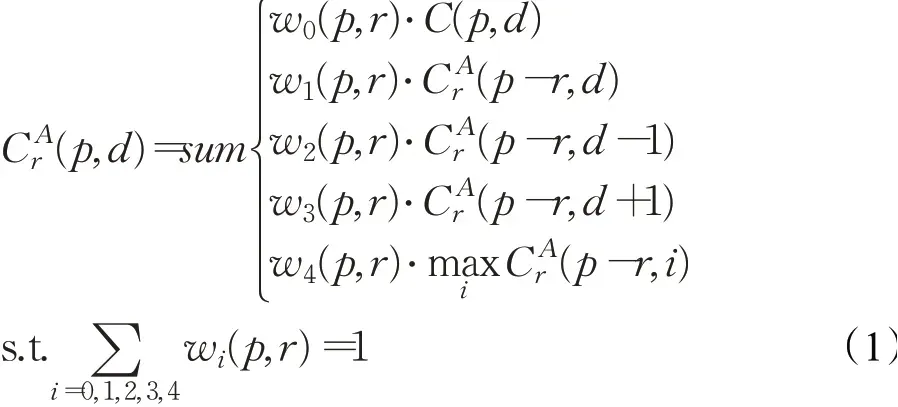

图2 GA-Net网络结构示意图Fig.2 Diagram of GA-Net network structure
第二种是LGA,它是受局部代价聚合(local matching cost matching)[41]的启发,遵循传统的代价过滤策略来细化细结构和边缘对象。不同于传统的代价滤波器,使用K×K的滤波器在代价体的K×K的局部区域Np,LGA用三个K×K的滤波器在每个像素位置p进行滤波,产生视差分别为d、d-1、d+1。它表示如下:
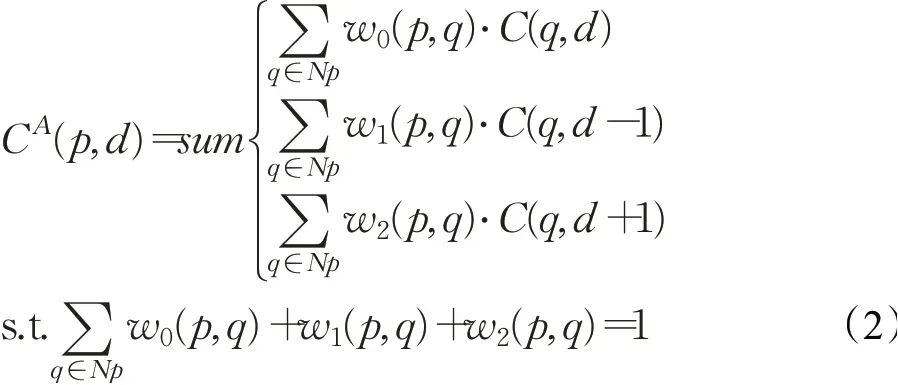
其中,C(q,d)表示候选视差d在位置q的代价体;CA(p,d)表示候选视差d在位置p的代价体;w0、w1、w2为3个滤波器的权值矩阵。
GA-Net网络结构如图2所示。首先将左右视图输入由不同层之间紧密相连的堆叠沙漏网络,特征提取块由左视图和右视图共享,然后通过文献[42]中的方法将提取出的左右图像特征构建成4D代价体,最后再使用几个SGA层模块进行代价聚合,并在softmax层之前和之后使用LGA层进行视差回归,得到视差图。图中快速引导子网络为绿色块,其实现类似于文献[43],它使用参考图像作为输入,聚合权重w作为输出,对于4D代价体C,四个方向聚合的H×W×D×F(K=5)权重矩阵通过引导子网络的输出分割、重塑并归一化求得,对应切片d的不同视差的聚合具有相同的聚合权重。
4.3 LEAStereo
相较于PSMNet[25]和GA-Net[29]花费大量的时间用于神经网络的设计上,为了减少人类在神经网络设计方面的精力,通过使用NAS(neural architecture search),使网络能够在一组操作中进行选择(例如:具有不同过滤器大小的卷积),能够找到一个更好地适应当前问题的最佳架构。由于人类设计的最先进的深度立体匹配网络规模已经非常庞大,基于现有的计算资源,直接将NAS应用到这样的海量结构是不可能的。LEAStereo[26]通过将特定任务的人类知识融入到NAS中,实现深度视差估计,遵循深度视差估计的常规步骤,且可以联合优化整个网络结构。
与文献[44-46]中的NAS算法只有单一的编码器/编码器-解码器架构不同,文中算法能够搜索两个网络的结构、特征映射的大小、特征体积的大小和输出视差的大小。与文献[44]只搜索单元级结构不同,允许网络搜索单元级结构和网络级结构,综上所述,将几何知识与神经网络结构搜索相结合,实现一个端到端层次NAS深度视差估计框架。LEAStereo网络总体架构如图3所示[26],主要部分组成:提取局部图像特征的2D特征网、4D特征体、从连接的特征中计算和聚合匹配成本的3D匹配网,以及将计算代价体投影到视差地图的软argmin层。NAS只对包含可训练参数的特征网和匹配网进行搜索,LEAStereo网络结构如图3所示。

图3 LEAStereo网络结构示意图Fig.3 Diagram of LEAStereo network structure
为了在一个预定义的L层网格中找到一条最优路径,如图4所示。将一个标量与格子里的每个黑色箭头关联起来。其中用β来表示这个标量的集合。在网络搜索空间中,将最小空间分辨率设置为1/24,在此基础上,设计一个降采样率为{3,2,2,2}的四级格架,在特征网的开始,有一个三层的“干”结构,它的第一层是一个3×3的卷积层,stride为3,其次是两层3×3的卷积层,stride为1。其中选择LF=6作为特征网,选择LM=12作为匹配网类似于寻找节点之间的最佳操作,通过使用一组搜索参数β在网格上搜索,以找到其中的路径,使损失最小化。网格中每一层的每个单元都可以接收到同一层的前一个单元的输入,也可以接收到下一层和上一层(如果有后两层)的输入。通过此算法找到的体系结构如图5所示。通过特征网络手工添加了2个跳过连接,一个在节点2和节点5之间,另一个在节点5和节点9之间。
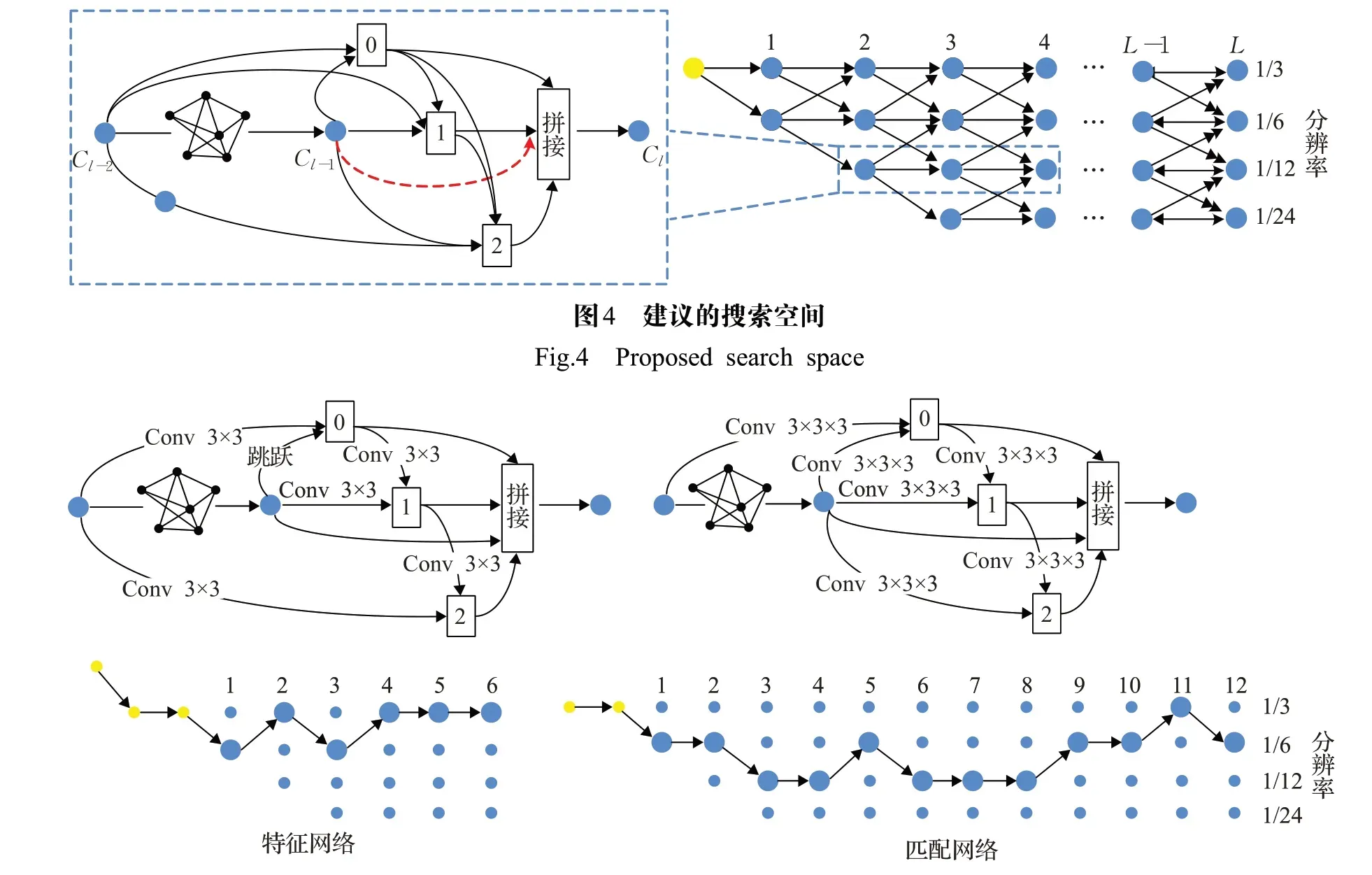
图5 搜索架构Fig.5 Searched architecture
4.4 DeepPruner
视差估计的搜索空间很大,而且相邻像素通常具有相似的差异。为了解决这个问题,Duggal等[30]开发了一个可微分的PatchMatch模块,在不评估所有代价体的情况下去除大部分差异,通过此代价体学习每个像素修剪范围。然后再逐步减少搜索空间,有效地传播这些信息,高效地计算高似然假设的代价体,减少所需计算的参数量和内存。最后,为进一步提升精度,使用图像引导细化模块。DeepPruner网络结构如图6所示[30]。

图6 DeepPruner网络结构示意图Fig.6 Diagram of DeepPruner network structure
DeepPruner中的剪枝模块很大程度上受到了文献[47]的启发,首先循环展开加入粒子PatchMatch操作的神经网络层,并求得预测视差置信范围,进而求得每个像素点处近似边缘分布。解空间通过有效采样和传播修剪,显著提高推理速度。DeepPruner主要由以下四个模块组成:特征提取、通过可微的PatchMatch进行剪枝、代价聚合、视差优化和预测。
可微的PatchMatch将广义PatchMatch展开为一个循环神经网络,算法迭代即为网络展开的过程。该结构由粒子抽样层、传播层、评价层构成。在粒子抽样层中,在均匀分布的预测搜索空间中,每个像素i都会随机生成k个视差值;在传播层中,相邻像素粒子以预定义的热过滤器模式的卷积传递(见图7),每个像素相邻的4个像素点也会受粒子传播。在评价层中,每个像素的左右特征内积求得匹配分数,并且每个像素的最佳视差值会被带入下一次迭代中。传播层和评估层会进行遍历,这一过程是在架构底部的粒子采样层进行的,如图8所示。
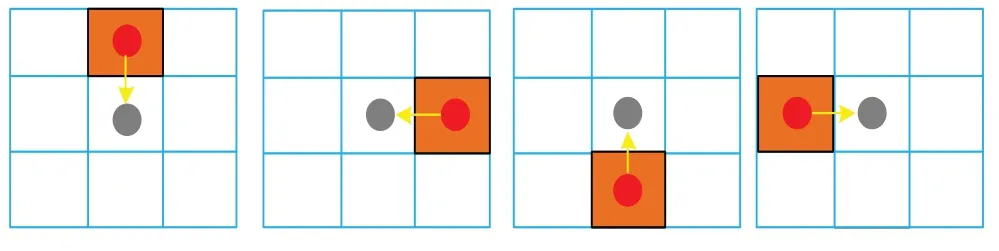
图7 一个热滤波器组位于传播层内Fig.7 One hot filter banks within propagation layer

图8 可微分的Patchmatch操作说明Fig.8 Illustration of differentiable patch match operations
置信区间预测网络解决了像素差异位于狭窄区域的问题,调整每个像素的搜索空间。它由一个卷积编解码结构组成,输入是可微分的PatchMatch、左图像和根据稀疏视差估计而扭曲的右图像,输出是每个像素i的置信范围Ri=[li,ui]。
4.5 BGNet
视差估计网络的实时性和准确性之间的平衡仍然是一个挑战,为了解决这个问题,Xu等[31]提出了一种基于学习后的双边网络切片操作的保边体积上采样模块。经典的视差估计网络StereoNet[48]中从低分辨率聚集的4D代价体回归的2D视差图通过双线性插值和分层细化进行上采样,速度较快,但是与PSM-Net[25]相比精度较低。相反,由于切片层是无参数的,BGNet使得可以在学习后的制导地图的引导下,从一个低分辨率的代价体中高效率地获得一个高分辨率的代价体,在高分辨率下回归视差图,保持高精度和高效率。BGNet网络结构如图9所示[31]。

图9 BGNet网络结构示意图Fig.9 Diagram of BGNet network structure
BGNet是基于CUBG(cost volume upsampling in bilateral grid)模块的基础上设计出来的,其主要由四个模块组成,即特征提取模块、代价体聚合模块、代价体上采样模块和残余视差细化模块。
CUBG模块如图10所示,低分辨率代价体CL和图像特征图为输入,上采样的高分辨率成本体积为输出。CUBG模块操作有双边网格创建和切片。

图10 学习双边网络代价体上采样模块Fig.10 Module of cost volume upsampling in learned bilateral grid(CUBG)
当代价体作为双边网格时,利用3×3的卷积将一个具有四个维度(包括宽度x、高度y、视差d和通道c)的低分辨率(例如:1/8)的聚合代价体CL转化为双边网格B(x,y,d,g),其中宽度x,高度y,视差d,制导特征g。
通过双边网格,可以利用切片层生成3D高分辨率代价体CH(CH∈ℝW,H,D)。切片操作是在高分辨率的二维制导映射G的引导下,在四维双边网格中进行线性插值。切片操作定义为:

其中,s∈(0,1)是网格尺寸w.r.t的宽高比值,即高分辨率代价体尺寸,sG∈(0,1)是网格(lgrid)的灰度值与制导图lgrid的灰度值的比值。制导图G由高分辨率的特征图通过两次1×1卷积生成。与文献[49]中设计的原始网格不同,文中的双边网格是自动从代价体中学习的。在实验中,网格大小通常设置为H/8×W/8×Dmax/8×32,W和H分别为图像的宽度和高度,Dmax为最大视差值。
5 数据集及常用评价指标
为了评估深度学习视差估计模型在不同数据集上的表现,本文选取了三种不同的数据集进行实验;KITTI2015是真实世界的街景数据集,Instereo2K是室内场景大型标签数据集,Middlebury2014是静态室内场景的高分辨率立体数据集。
5.1 KITTI2015数据集
KITTI数据集是一个真实世界的街景数据集,由一辆行驶的汽车在中型城市、农村地区和高速公路上采集得来,记录平台配备2个高分辨率立体相机系统,1个Velodyne HDL-64E激光扫描仪,最先进的OXTS RT 3003的定位系统,摄像机、激光扫描仪和定位系统经过校准和同步,可以提供准确的真实视差[50]。KITTI2015数据集是利用KITTI原始数据集,创建的一个具有独立移动对象和逼真的真实视差的场景流数据集,共包含200张训练图像和200张测试场景[51],分辨率为376×1 242像素。该数据集中的真实视差图是由激光扫描仪得到的稀疏视差图,本文的训练集为具有真值的160张图片,测试集为其余的40张图像。
5.2 Instereo2K数据集
Instereo2K数据集是一个室内场景视差估计的大型真实数据集,该数据集采集平台是一个结构光系统,由2台分辨率为960×1 280像素的彩色摄像头和1台分辨率为768×1 024像素的投影仪组成,相机的CCD传感器的像素大小为3.75 μm,每个相机的镜头焦距为8 mm[52]。该数据集包含2 050对RGB图像及高度精确的视差图,其中2 000对作为训练集,50对作为测试集,分辨率为860×1 280像素,涵盖了不同的室内场景,包括办公室、教室、卧室、客厅和宿舍。与KITTI2015相比,Instereo2K数据集带标签图像数量增加了一个数量级,在2 000对训练集中,本文1 600对图像进行网络训练,其余的400张图片进行精度测试。
5.3 Middlebury2014数据集
Middlebury2014数据集是静态室内场景的高分辨率立体数据集[53],它是在实验室条件下拍摄而来的。它是一个结构化的照明系统采集,该系统包括高效的二维亚像素对应搜索、基于镜头畸变建模的摄影机和摄像机自标定的技术,结合来自多个投影仪的视差估计,在大多数观测表面上实现0.2像素的视差精度。该数据集包含了33个新的600万像素的数据集,其中23个数据集是包含真实视差图的,可以用来训练和验证,10个数据集是不提供真实视差图的,用于测试。每个数据集由多次曝光和多次环境光照下拍摄的输入图像组成,有或没有镜像球来捕捉照明条件,每个数据集提供“完美”和现实的“不完美”校正,并分别提供精确的1维和2维的浮点视差。本文取80%具有真值的图像作为训练集,通过剩余的20%测试精度。
5.4 常用评价指标
为了评估立体影像视差估计算法的性能或改变其某些参数的影响,需要使用规定的评价指标来判断估计出来的视差图好坏。通常是通过计算一些地面真实数据的误差统计来实现的。常用的评价指标有以下三种:
(1)均方根误差(RMS error),计算的视差图dC(x,y)和地面真值图dT(x,y)之间的均方根,即:

其中,N是像素总和。
(2)端点误差(EPE),计算的视差图dC(x,y)和地面真值图dT(x,y)之间的平均值,即:

其中,N是像素总和。
(3)误匹配像素百分比,计算的视差图dC(x,y)和地面真值图dT(x,y)相差大于δd的像素的比例,即:
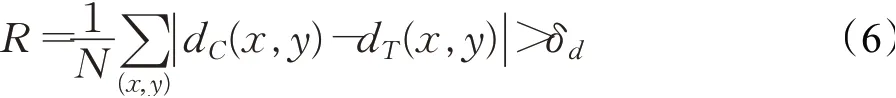
其中,N是像素总和,δd可以取0.5、1.0、2.0、3.0、4.0。
对于KITTI2015基准测试结果,遵循标准评估协议,综合全图像测试误差,选用误匹配像素百分比大于3个像素比例作为评价指标,即3像素误差;鉴于与之前发表的一些研究的一致性,Instereo2K和Middlebury2014数据集选用2像素误差作为评价指标。
6 实验结果与分析
为了能够对深度学习的视差估计网络在室内场景图像的性能和泛化性进行全面的评估,本文设计了两类实验。第一类实验将上述5种深度学习的视差估计网络使用在KITTI2015数据集、Instereo2K数据集和Middlebury2014数据集上,测试其性能,并将它们和经典的SGM方法进行比较。第二类实验是为了测试深度学习视差估计模型的泛化性能,使用BGNet将三种数据集的预训练模型不加任何调整直接运用到各数据集上,测试该网络的鲁棒性。
6.1 深度学习方法和传统SGM方法的比较
5种深度学习视差估计网络测试和训练利用深度学习平台Pytorch进行实现,在Nvidia Tesla P100显卡上进行,显存为16 GB。在训练之前,对数据集进行预处理,将输入的图片进行随机裁剪,PSM-Net、DeepPruner、BGNet裁剪为256×512像素,GA-Net裁剪为240×576像素,LEAstereo裁剪为192×384像素。优化器使用的是Adam(adaptive momentum)优化器(b1=0.9,b2=0.999),最大视差值和批处理大小分别设置为192和4,学习率设置为0.001。在三种数据集上,深度学习视差估计网络和SGM方法误差占比见表1。

表1 深度学习网络和SGM方法在实验中误差占比Table 1 Percentage of deep learning networks and SGM method in experiment 单位:%
KITTI2015上能够取得极佳的效果,在室内图像中也能表现出不错的效果。但由于深度学习模型对各个场景数据集学习能力不同,缺少在包含真实视差和表面法线数据集的训练,如:PSM-Net和GA-Net,相较于传统的SGM算法,在室内场景数据集中并没有取得更优的效果。视差估计网络对几何信息的提取能力,以及数据集中图像的质量和数量对深度学习视差估计模型的预测具有很重要的意义。通过像LEAStereo一样充分利用左右视图交叉参考的优势,在表面法线等几何信息中表现出强的性能,能够更好地捕捉复杂场景的上下文信息,在室内图像的重建中能远超传统的SGM算法。相比较而言,先进的深度学习方法能够减少具有挑战性复杂场景的误匹配现象,取得比传统方法更好的效果。
为了更全面地评估深度学习视差估计网络的性能,将KITTI数据集中的图片分别进行相应裁剪,输入各网络中,分别输出训练过程网络参数总量和运行时间,单位分别是MB和ms,它们都是网络对一幅左右视图进行推理所得数值,结果如表2所示。随着深度学习视差估计网络的不断发展,轻量级的模型能在保持良好的运行时间和少的计算资源的条件下,取得更好的重建,对其运用在室内机器人定位、导航、交互提供良好基础。

表2 深度学习视差估计网络的参数量和运行时间Table 2 Parameter numbers and running time of disparity estimation networks
为了比较深度学习模型和传统SGM方法之间的差异,通过将KITTI2015和Middlebury2014视差结果进行渲染,更加直观地对比差异,如图11所示。深度学习的方法所得到的视差图更加完整,模糊的噪点更少。SGM方法会产生一些空洞区域,需要通过视差后处理消除,深度学习的方法只需将图片输入一个端到端的视差估计网络中,直接得到视差图,节约时间成本,且可以取得更好的效果。

图11 不同深度学习模型的视差结果Fig.11 Disparity results of different deep learning models
6.2 泛化性能
泛化性能对于立体网络来说是非常重要的,具有良好的泛化性能对网络的实际工程应用具有重要的意义。迁移学习是将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。为了验证BGNet在不同场景中的泛化效果,通过使用迁移学习的方法,将在一个数据集上训练所得的模型不经过任何调整直接应用于另一数据集上,通过在另外一个数据集上的精度结果,能够反映出该网络的泛化性能。表3是BGNet的预训练模型在各数据集上的测试结果。
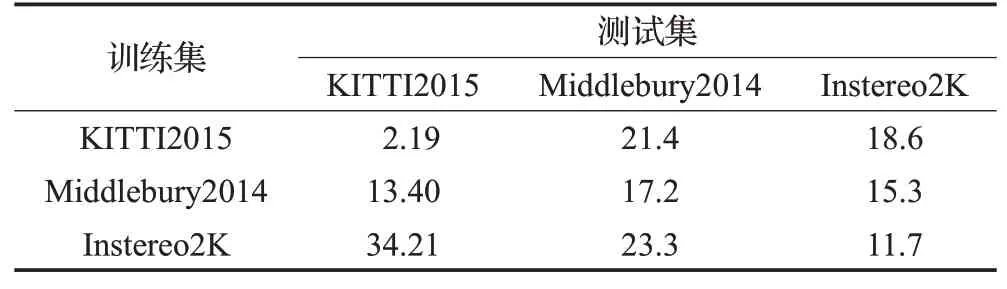
表3 BGNet的预训练模型在各数据集上的测试结果Table 3 Test results of BGNet pretrained model on each dataset 单位:%
总体而言,深度学习的视差估计模型BGNet具有良好的泛化性能,在Middlebury2014和Instereo2K数据集上,使用KITTI2015数据集预训练的模型进行测试,仍能取得不错的效果。而Middlebury2014预训练模型在Instereo2K数据集上能够取得比KITTI2015更好的泛化性能,具有良好的鲁棒性,这是由于KITTI2015数据集更多的包含的是室外场景的特征,对于室内场景特征包含较少。由于Middlebury2014数据集可训练的数据量较少,Instereo2K数据集图片质量一般,其在KITTI2015数据集上表现较差,仍需增加数据集和图像质量。由此可以看出,在室内场景立体匹配中,深度学习视差估计模型已有一定泛化性能,但在不经任何微调的条件下,其效果并不优于传统SGM方法,其泛化性能仍然有待提升。
7 结语
本文对深度学习的视差估计方法进行概述,并将其应用在室内图像数据集中,针对多个不同的数据集,并与SGM方法进行比较,并对其泛化性能进行分析,所得结果表明,首先,在室内图像数据集的视差估计过程中,深度学习模型能够取得很好的效果;其次,在深度学习模型中,以端到端的方式输出视差图,无需后处理,最新的深度学习方法具有比传统SGM方法更好的效果;最后,深度学习的方法具有良好的泛化性能,将在经典的KITTI2015数据集训练的模型,不加任何调整直接应用在室内图像的数据集中能取得不错的效果,但和传统方法相比效果一般,泛化性能有待提升。
现有研究面临难题仍有:
(1)模型泛化性能有待提升,大多深度学习视差估计模型仅在训练的数据集上有良好的效果,用于其他不同的数据集,取得的效果一般。良好的泛化性能在实际应用中具有重要作用。
(2)实时处理能力还较弱,现在所提出的视差估计网络多使用3D和4D代价体,代价聚合时使用2D或3D卷积,计算量较大,计算消耗较大。开发轻量级、计算量较小的网络仍是所面临的挑战之一。
(3)无纹理、反射表面和遮挡区域等不适定区域,很难找到精确的对应点,将高级场景理解和低级特征学习相结合,更多地融合上下文信息,充分学习全局信息是解决途径之一。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
小哥白尼(军事科学)(2022年2期)2022-05-25
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
红领巾·萌芽(2019年8期)2019-08-27
语文世界(初中版)(2018年10期)2018-11-06
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
CHIP新电脑(2016年3期)2016-03-10
