
基于像素值排序与块再分的可逆数据隐藏算法
2022-10-16 12:27:20任方杨益萍薛斐元
计算机工程 2022年10期
任方,杨益萍,薛斐元
(1.西安邮电大学 网络空间安全学院,西安 710121;2.西安邮电大学 无线网络安全技术国家工程实验室,西安 710121)
0 概述
可逆数据隐藏是一种只需要对载体图像的像素进行轻微修改,并将数据隐藏在载体图像中的技术。该技术从被嵌入数据的载体图像中无损地提取数据,同时完全恢复出原载体图像[1-2]。可逆数据隐藏技术在医学图像[3-5]、军事图像、法律取证等领域中传输和使用数据时,能够确保数据不失真[6-8]。
早期的可逆数据隐藏技术[9-11]通过压缩载体图像的一个位平面来创造空间,并进行数据嵌入,但其可逆性高度依赖于压缩算法的性能。文献[12]提出DE 算法,通过对载体图像进行整数小波变换,同时计算并扩展差值,以嵌入可逆数据。为充分利用自然图像的冗余空间,预测误差扩展(Prediction Error Expansion,PEE)[13]采用预测误差代替DE 算法中的差值,受到许多研究人员的关注[14-16]。
文献[17]结合PEE 提出像素值排序(Pixel Value Ordering,PVO)算法。该算法将载体图像分成非重叠同等大小的块,并对块内的像素进行排序,通过计算预测误差为块中最大(小)值与次大(小)值的差值,以修改最大(小)值嵌入数据。在PVO 算法中,预测误差等于1 的图像块被用于嵌入数据,预测误差等于0 的图像块未被利用。文献[18]提出改进的PVO(IPVO)算法,根据最大(小)值和次大(小)值的空间位置预测误差,误差等于0 和误差等于1 的图像块都被用于嵌入数据,以提高PVO 的嵌入容量。文献[19]提出PVO-K,同时修改k个最大(小)值以嵌入1 bit数据,当k=1时,PVO-K退化为PVO。文献[20]提出PPVO,打破了PVO 中分块的限制,将每个像素作为一个嵌入单元。文献[21]将PVO 生成的预测误差两两分为一组,采用2D 的方式成对修改误差以嵌入数据。研究人员利用可逆约束对像素进行动态预测,从而提升PVO 的嵌入容量[22]。为获得更大的嵌入容量,文献[23]将图像块的复杂度分为m个级别,根据不同级别动态地修改块内像素的个数。
本文提出基于像素值排序的块再分算法。构建12种分块模式将1 个图像块分为2 个子块,对每个子块采用不同的扫描顺序及嵌入策略,以充分利用图像块中每个像素之间的相关性。此外,设计一种局部复杂度的计算方式,当嵌入数据时,只处理复杂度小于阈值的图像块,提高嵌入数据后图像的视觉质量。
1 基于像素值排序的可逆数据隐藏算法
PVO 算法[17]通过对图像进行分块,并将块内的n个像素按照升序排列,使得xσ(1)≤xσ(2)≤…≤xσ(n),在此基础上,计算预测误差emax=xσ(n)-xσ(n-1)。PVO 和IPVO 算法的预测误差直方图如图1 所示。
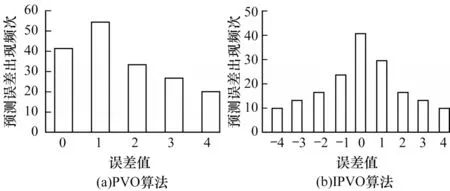
图1 PVO 和IPVO 算法的预测误差直方图Fig.1 Prediction error histogram of PVO and IPVO algorithms
POV 预测误差emax的直方图误差范围在(0,+∞),峰值点为1。PVO 算法通过emax=1 来嵌入数据。
文献[18]提出改进的像素值排序(IPVO)算法,其目的是利用在PVO 算法中被放弃的最大(小)值与次大(小)值相等的图像块来嵌入数据。IPVO 计算得到的预测误差dmax=xu-xv,其中u=min(σ(n),σ(n-1)),v=max(σ(n),σ(n-1))。IPOV 预测的误差直方图如图1(b)所示,预测误差dmax的直方图误差范围在(-∞,+∞),峰值点为0。IPVO 利用dmax=0和dmax=1 来嵌入数据,大幅增大了PVO 的嵌入容量。

IPVO 在3×3 图像块最大值上嵌入和提取数据的过程如图2 所示。

图2 IPVO 算法在最大像素上嵌入和提取数据的过程Fig.2 The process embedding and extraction data of IPVO algorithm on maximum pixel

2 本文算法
2.1 分块模式
分块模式将原始图像分成3×3 不重叠的块,将每一个块内包含的9个像素划分为2个像素集,即像素集A和像素集B。像素集A 包含4 个像素,采用次大像素值预测最大像素值和次小像素值的方法。像素集B 包含当前块内剩下的5 个像素,采用中值像素分别预测其余4 个像素的方法。这样的划分方式共有种,其目的是为了更充分利用像素之间的相关性。由于像素之间的相关性越高,产生的预测误差直方图分布越集中,因此可被用于嵌入数据的像素就越多。本文考虑到像素与像素之间的距离越近,其相关性越好,因此,像素集的划分应尽可能地让像素集内的像素彼此相连。在这种划分方式中,12 种细分块的模式如图3 所示。

图3 12 种分块模式Fig.3 12 block modes
2.2 数据嵌入与提取
本文采用图3 中的模式1 进行数据嵌入与提取。
2.2.1 数据嵌入
数据分块示意图如图4 所示。
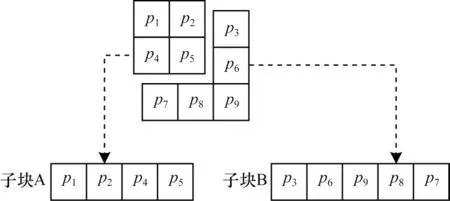
图4 数据分块示意图Fig.4 Schematic diagram of data block
在数据嵌入过程中,对于图4 中的子块A,首先逐行读取子块A 的像素,获得像素序列{p1,p2,p4,p5},然后将其按照升序排列,得到{pω(1),pω(2),pω(3),pω(4)},其中,ω是一个双射,使得pω(1)≤pω(2)≤pω(3)≤pω(4)。如果像素pω(w)=pω(r),并且w<r,则ω(w)<ω(r),计算预测误差e1,j,如式(1)所示:

其中:j∈{1,2};当j=1 时,u=min{ω(j),ω(2)},v=max{ω(j),ω(2)};当j=2 时,u=min{ω(j+1),ω(4)},v=max{ω(j+1),ω(4)}。
如果b为嵌入的数据,b∈{0,1},那么计算得到的水印误差如式(2)所示:
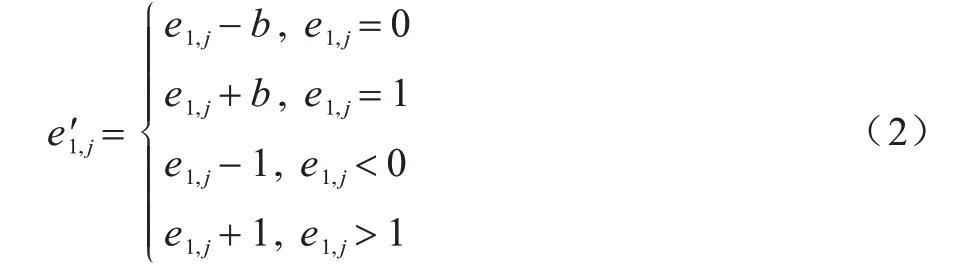
相应地,当数据被嵌入后,子块A 的最小像素pω(1)被修改为:
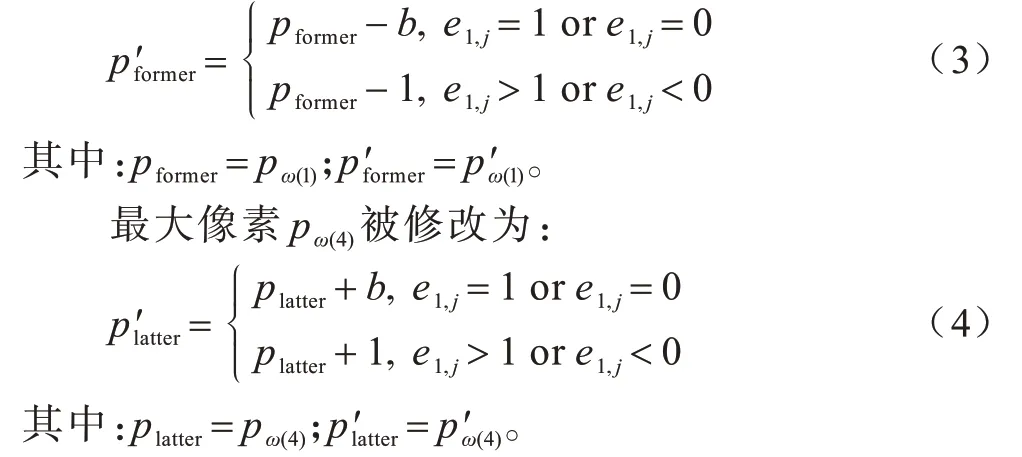
对于子块B,采用从上向下和从右至左的顺序读取像素,得到像素序列{p3,p6,p9,p8,p7},将其按照升序排列得到{pτ(1),pτ(2),pτ(3),pτ(4),pτ(5)},其中,τ是双射,使得pτ(1)≤pτ(2)≤pτ(3)≤pτ(4)≤pτ(5)。如果pτ(w)=pτ(r),并且w<r,则τ(w)<τ(r),预测误差e2,j如式(5)所示:

本文算法将3×3 的图像块修改为可以嵌入6 bit图像块,与PVO 和IPVO 等算法相比,大幅提升了嵌入容量。IPVO 和本文算法的预测误差值对比如图5所示。图5 选取了Lena 的3×3 的图像块,如果采用IPVO 算法,则只能得到2 个可以被用于嵌入数据的预测误差。如果使用本文算法,将得到6 个可以被用来嵌入数据的预测误差。
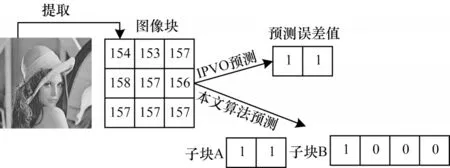
图5 IPVO 算法和本文算法的预测误差值对比Fig.5 Prediction error values comparison between IPVO algorithm and the proposed algorithm
2.2.2 数据提取
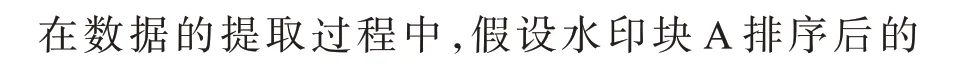


2.2.3 数据嵌入与提取样例
本文算法的数据嵌入与提取过程如图6 所示。数据嵌入过程首先将原始块分为子块A 和子块B,对于子块A,逐行扫描像素,排序得到像素序列pω={159,160,160,161}。根据式(1)计算预测误差e1,1和e1,2,根据式(3)和 式(4)修改最大和最小像素嵌入b1和b2。对于子块B,从上向下和从右到左扫描像素,排序得到像素序列pτ={159,160,160,161,163},根据式(5)计 算4 个预测误差为e2,1、e2,2、e2,3和e2,4,根据式(3)和 式(4)将p8、p6、p5、p9修改为′,以嵌入b3、b4和b5。最后将两个子块内所有被修改的像素更新到原始块对应的位置上,以生成水印块。
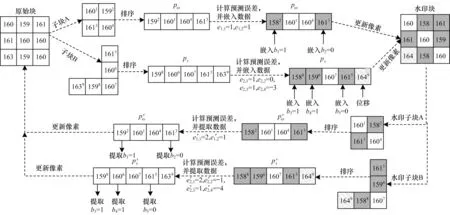
图6 本文算法的数据嵌入与提取过程Fig.6 Data embedding and extraction process of the proposed algorithm
数据提取过程与数据嵌入过程相同,首先对水印块进行分块,得到水印像素序列和,然后分别计算这两个水印序列的预测误差,对于,计算误差和,对于,计算误差,根据式(6)提取出b1、b2、b3、b4和b5,根据式(7)和式(8)恢复出原始像素p2、p3、p8、p6、p5和p9,最后将所有恢复的像素更新到水印块的相对位置上,得到原始块。
2.3 局部复杂度
本文考虑到自然图像中包含大量粗糙块,如果对这些粗糙块进行数据的嵌入操作,将会产生大量的移位像素,从而降低图像的嵌入性能。在文献[17]中,一个块的局部复杂度定义为当前块的次大像素值与次小像素值的差值。然而,当分块较小时,参与排序的像素过少,难以反映灰度值的变化趋势,因此,文献[17]计算的局部复杂度不准确。
由于自然图像的相邻像素呈高度相关关系,因此可以推断相邻图像块的复杂度也具有高度相关关系。一个光滑块周围的图像块也光滑,一个粗糙块周围的图像块必定粗糙。本文定义一个图像块的上下文像素为其所有相邻块中距离该块最近的像素。图像块的上下文像素集C如式(9)所示:
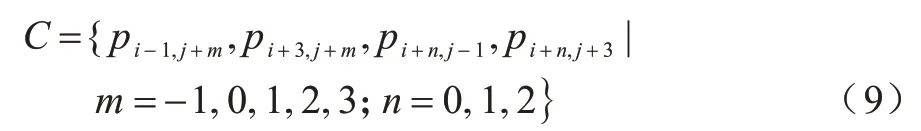
上下文像素集C的方差被定义为图像块的局部复杂度NNL,如式(10)所示:
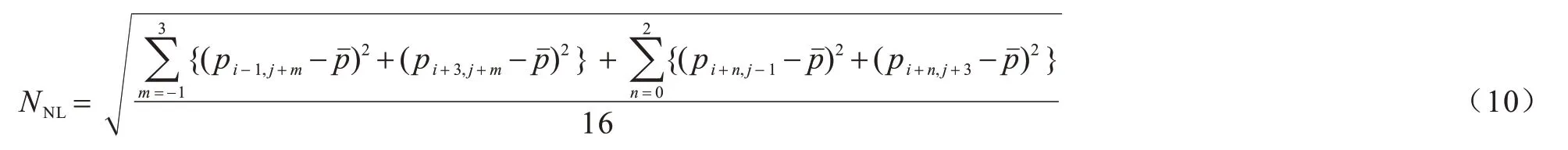
一个3×3 图像块的上下文像素示意图如图7所示。
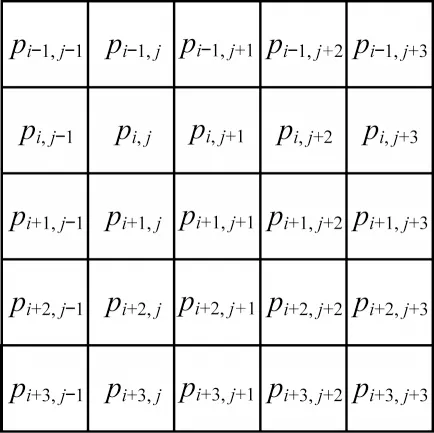
图7 3×3 图像块的上下文像素Fig.7 Context pixel of 3×3 image block
如果一个图像块的NNL小于给定的阈值T,则是平滑块。本文按照2.2 节的方式对平滑块进行块再分,以嵌入数据。如果一个图像块的NNL大于等于给定的阈值T,则为复杂块,对于复杂块不做任何处理。
3 算法流程
3.1 嵌入算法
嵌入算法主要分为以下3 个步骤:
1)图像分块与位置地图的构建。首先将原始图像中除第一行像素以外的所有像素分为3×3 不重叠的块{X1,X2,…,XN},其中,N为块的总数。如果一个像素为255 或者0,则在嵌入过程中有可能被修改为256 或者-1,会造成上溢或者下溢。为解决该问题,若Xi内含有像素255 或者0,将其标记为LLM(i)=1;否则标记为LLM(i)=0。最后将所有的LLM,即图像的位置地图压缩成一个长度为LCLM的比特流串。
2)秘密数据嵌入。在执行数据嵌入的过程中,嵌入算法只对所有LLM(i)=0 的图像块进行嵌入。对于每个LLM(i)=0 的图像块Xi,首先计算它的局部复杂度NNL。如果NNL≥T,则为粗糙块,不做任何处理;如果NNL<T,则为平滑块。按照2.2.1 节提出的方法进行块再分,根据式(1)和式(5)计算误差e1,j和e2,j,根据式(2)进行误差的扩展或者移位以嵌入秘密数据。当所有的秘密数据都被嵌入完成后,该步骤将停止,最后一个嵌入数据的图像块被记为Xend。
3)辅助数据和位置地图的嵌入。为实现数据的可逆恢复,辅助数据和位置地图被嵌入到图像第一行像素的最低有效位(Least Significant Bit,LSB)中。辅助数据为压缩位置地图的长度LCLM、阈值T、块尺寸以及结束位置Xend。利用这些数据替换图像第一行的LSB,并将替换掉的LSB 压缩成比特流SLSB,最后按照步骤2 将其嵌入到图像的剩余区域中,即{Xend,Xend+1,…,XN}。
3.2 提取算法
提取算法主要分为以下3 个步骤:
1)辅助数据与位置地图的提取。在解码端,提取算法读取水印图像第一行像素的LSB 位,提取LCLM、阈值T、块尺寸、结束位置Xend以及压缩的位置地图,并将其解压得到位置地图。
2)数据提取。首先将水印图像除第一行以外的所有像素分为3×3的块,然后查找每个块的标记LLM(i),计算LLM(i)=0 的水印块复杂度NNL,最后将满足LLM(i)=0 并且NNL<T的水印块按照2.2节的方法进行再分块,计算水印误差和,并根据式(6)提取出秘密数据和压缩的比特流SLSB。
3)图像恢复。首先将提取的秘密数据按照2.2.2节的方法恢复出图像的原始块{X1,X2,…,XN},然后解压SLSB,将其替换掉图像第一行像素的LSB 位,最后恢复出整个图像。
4 实验结果与分析
本文利用MATLAB R2018a 软件在6 幅512×512像素的灰度图像上,对比现有的基于像素值排序的可逆数据隐藏算法与本文算法的性能。6 张测试图如图8 所示,这些图像都是从USC-SIPI 数据库中下载获得,在嵌入过程中数据b是随机生成的0,1序列。

图8 本文实验6 张测试图Fig.8 Six test images of the proposed experiment
本文在12 种分块模式下对Lena 图和Baboon 图进行峰值信噪比(Peak Signal to Noise Ratio,PSNR)对比,结果如图9 所示。从图9 可以看出,当采用分块模式1 时,图像的PSNR 性能最优,因此,本文算法的最优模式为模式1。
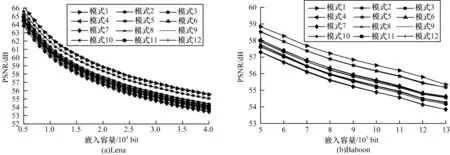
图9 不同分块模式下的PSNR 对比Fig.9 Comparison of PSNR in different block modes
在最优模式下不同算法的PSNR对比如图10所示。从图10可以看出,在大多数情况下,本文算法的PSNR都最优,并且随着嵌入容量的增大,PSNR 的增益更明显。因此,嵌入容量越大,本文算法的性能越优。

图10 不同算法的PSNR 对比Fig.10 PSNR comparison among different algorithms
从图10 可以看出,当Baboon 图的嵌入容量小于8 000 bit 以及Barbara 图的嵌入容量小于12 000 bit时,本文算法的PSNR 不是最高,其原因主要有两个:1)本文算法未根据嵌入容量自适应选择图像块大小,即不能在嵌入容量较低时,采用更大的5×5图像块进行再分块,而对于这类复杂图像,相邻像素联系不紧密,使得对平滑块的选择更为精确,需要更多的上下文像素来计算局部复杂度,因此,本文算法的PSNR 不是最高;2)以上对比的其他算法在实验过程中都通过穷举搜索法选择最优参数,尽管这种方式可以提升PSNR,但是也会增大计算复杂度。
当嵌入容量为1 000 bit 时,不同算法在6 张图上的PSNR 对比如表1 所示。从表1 可以看出,相比其他算法,本文算法的平均PSNR 增益分别为1.22 dB、2.00 dB、2.08 dB、1.99 dB、1.68 dB、0.70 dB。这表明本文算法在低嵌入容量下能够有效提升嵌入数据后的图像质量。
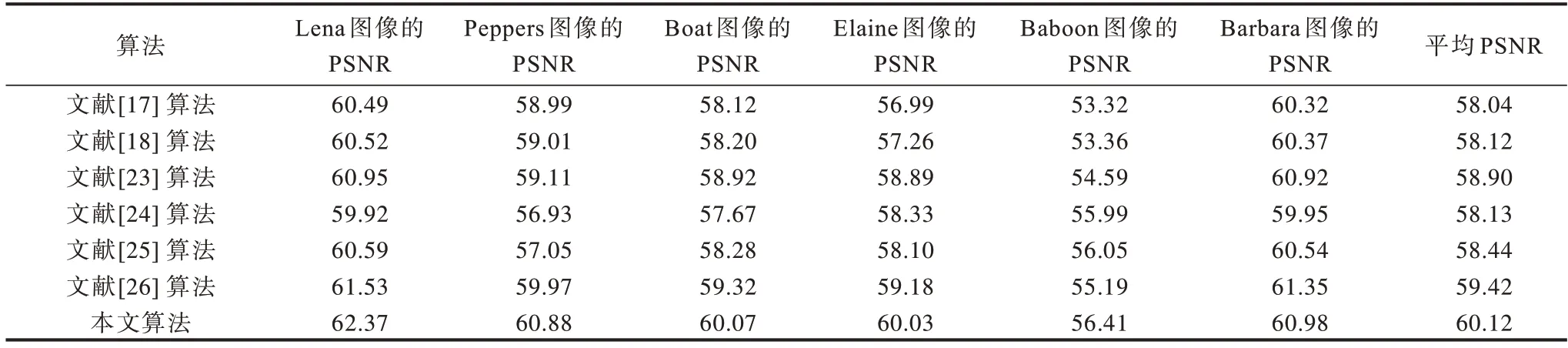
表1 当嵌入容量为1 000 bit 时不同算法的PSNR 对比Table 1 PSNR comparison among different algorithms when embedding capacity is 1 000 bit dB
不同算法的最大嵌入容量对比如图11 所示。分块越小,最大嵌入容量就越大。在文献[17]中,当采用2×2 分块时,图像的嵌入容量达到了最大值。本文算法是在3×3固定大小的分块上实现的。从图11可以看出,本文算法的最大嵌入容量在某些图像上是最大的,其原因为对于一个3×3 大小的图像块,最多可以嵌入6 bit数据,充分地利用了图像块内的每一个像素。不同算法的计算复杂度对比如表2 所示。
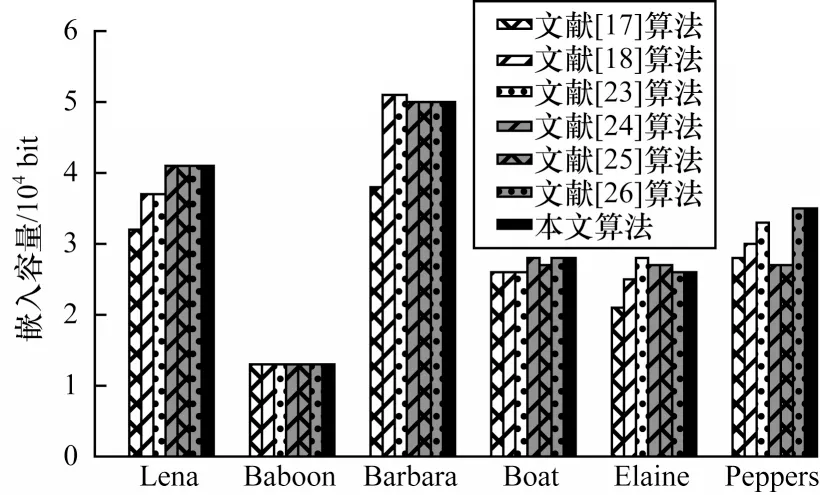
图11 不同算法的最大嵌入容量对比Fig.11 Maximum embedding capacity comparison among different algorithms

表2 不同算法的计算复杂度对比Table 2 Computational complexity comparison among different algorithms
文献[17]通过穷举搜索出三个最优参数,即块尺寸rL,cL和阈值TL,其中rL∈{2,3,4,5},cL∈{2,3,4,5},TL有NL个候选数,因此,文献[17]的计算复杂度近似为O(16NL)。同理,文献[18]的计算复杂度近似为O(16NP),其中,16和NP分别为最优尺寸rP×cp和最优阈值Tp的候选数。文献[23]需要穷举搜索4 个最优参数,即vT、Tw、rw和cw,其中,rw∈{3,4,5},cw∈{3,4,5},Tw有m个候选数,m=,vT有Nw个候选数。文献[23]的计算复杂度近似为O(9m×Nw)。而本文算法只需要确定一个参数,即阈值T,因此计算复杂度仅为O(N),其中,N为阈值T的候选数。
本文根据不同的嵌入容量,采用不同的最优阈值T*改进本文算法。本文改进的算法与文献[17-18]、文献[23-26]算法在Barbara和Baboon的PSNR对比如图12所示。从图12 可以看出,无论嵌入容量是多少,本文改进算法的PSNR 都远大于现有算法。
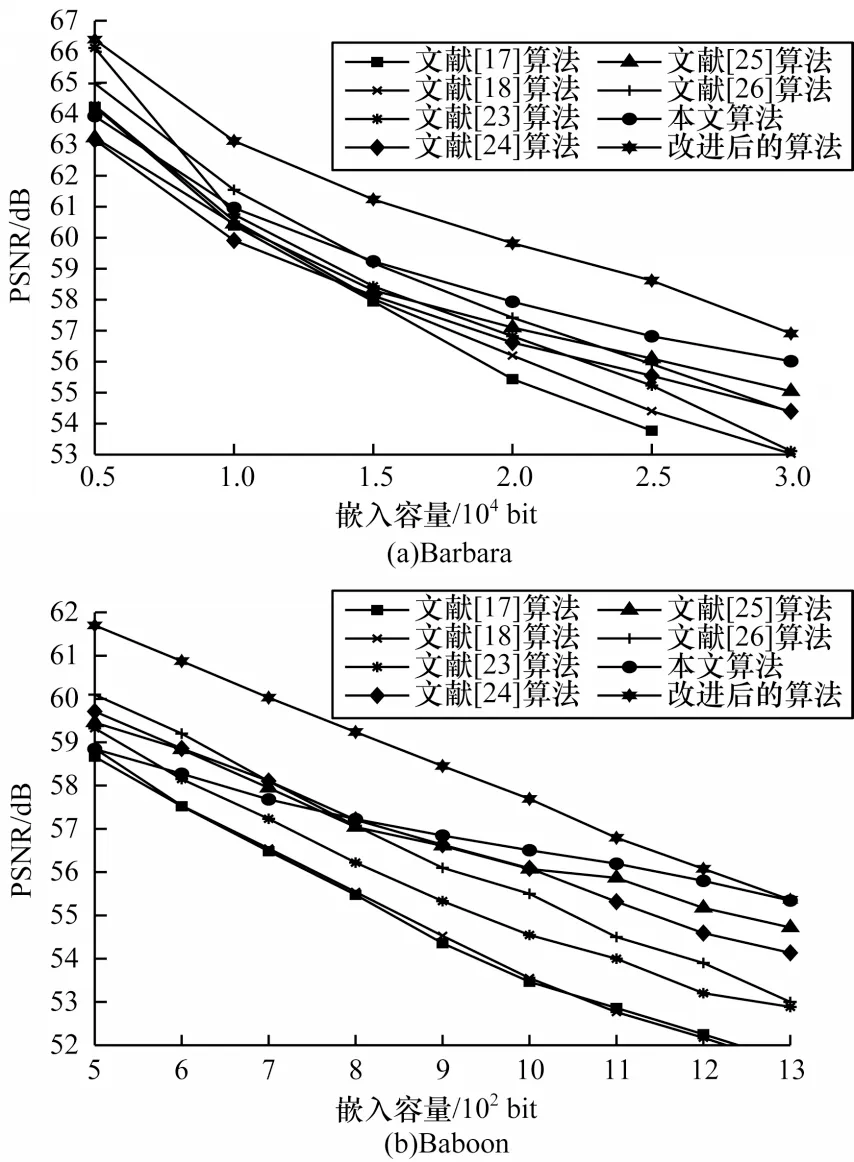
图12 本文改进算法与其他算法的PSNR 对比Fig.12 PSNR comparison among the proposed improved algorithm and other algorithms
5 结束语
本文提出基于像素值排序的可逆数据隐藏算法。通过计算每一个图像块的局部复杂度,并对比局部复杂度与阈值的大小,将局部复杂度小于阈值的图像块进行分块,同时设计12 种分块模式,并通过实验测试不同分块模式下的嵌入性能,选择能够得到最优嵌入性能的模式进行数据嵌入。此外,通过改进本文算法,根据嵌入容量自适应地选择最优阈值T*,以提高嵌入性能。实验结果表明,本文算法能够充分利用图像块内的每个像素,具有较优的嵌入性能。后续将在4×4 和6×6 图像块上设计分块策略,进一步提升图像块的嵌入性能。
猜你喜欢
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
火控雷达技术(2016年3期)2016-02-06 02:30:28
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
电源技术(2015年12期)2015-08-21 08:58:20
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
风能(2015年8期)2015-02-27 10:15:12
