
基于偏相关性测试的递归式因果推断算法
2022-10-16 12:27陈铭杰张浩彭昱忠谢峰庞悦
计算机工程 2022年10期
陈铭杰,张浩,彭昱忠,谢峰,庞悦
(1.东莞理工学院 计算机科学与技术学院,广东 东莞 523808;2.广东石油化工学院 计算机学院,广东 茂名 525099;3.复旦大学 计算机科学技术学院,上海 200433;4.南宁师范大学 计算机与信息工程学院,南宁 530001;5.北京大学 数学科学学院,北京 100871;6.中国银联博士后科研工作站,上海 201201)
0 概述
在因果关系推断问题中,研究者通常使用统计独立性测试[1]和条件独立性测试[2]对数据集间蕴含的因果关系进行推断,因此,对于数据中因果信息的获取尤为重要[3]。以PC 算法[4]为例,作为一个经典的基于约束的因果推断算法,其算法原理是根据数据集间变量的联合概率分布与条件概率分布特点,通过条件独立性(Conditional Independence,CI)测试判断变量之间是否满足独立性或条件独立性,在进行一系列基于方向规则的判断后构造出一个大致的因果网络图。此图通常是一个部分有向无环图(Partial Directed Acyclic Graph,PDAG),其中包含一组马尔可夫(Markov)等价类,而不是一个完全准确的因果网络图。
因为CI 测试的条件集会较大程度影响到测试结果的准确率,所以CI 测试比统计独立性测试的难度要大得多[5]。对于CI 测试,一般有三种使用场景:一种是数据离散分布的情况,可以根据对应的条件概率P(X,Y|Z)=P(X|Z)P(Y|Z)将条件集合Z变为单个条件变量,然后使用常用的条件互信息或卡方检验技术判断条件独立性关系是否成立[5];另外两种分别针对数据连续分布和混合连续离散分布的情况,会采用离散化的方法对数据进行离散化处理,然后通过传统的CI 测试方法即第一种场景中的条件互信息和卡方检验等方法进行检验,但是存在的问题是在离散化的过程中容易丢失一些数据信息,导致最终推断结果不够准确。虽然可以通过计算条件密度估计值PX|YZ=PX|Z间的距离来检验CI 测试是否准确[6],但是当数据量较大时,离散的区间比较难设定,过大容易导致数据丢失,过小则需要很多的样本量,在Z较大的情况下,离散化数据和估算条件密度都是需要解决的重要问题。
近年来,研究者提出一系列基于核函数的CI 测试方法。这些方法可以利用高阶矩信息将观测变量映射到再生核希尔伯特空间(RKHSs),此时的变量具有帮助推断高维变量分布的特点,如独立性和同质性[7]。文献[8]提出一种利用希尔伯特-施密特范数的条件交叉协方差算子,它是可以对应到RKHSs函数下x和y条件协方差的一种度量。该方法证实了如果与之对应的RKHSs 是特征核[9-11],则算子范数为0且x⊥y|Z。相关文献以及深入研究表明,基于核方法的CI 测试可以从给定的变量中获得比基于离散数据集的CI 测试更多且更完整的信息,同时也表明基于核方法的CI 测试在因果推断场景中能够发现更准确的因果关系。
基于核函数的方法,通过将变量集的条件概率分布空间映射到基于平方可积函数空间的高维的线性空间,找出一种单向或双向映射关系,如KCIT[12]。这种方法准确率较高,但运算复杂度也非常高,一般来说,当变量个数超过10 或样本量大于2 000 时,就很难在一般的计算环境中运行。因此,该方法难以在高维数据场景中高效地解决因果推断问题。由此可见,因果推断的一个关键难题就是设计一个合适的CI 测试方法,使之能够在高维数据场景下也能高效运行。
本文提出一种基于偏相关性测试的因果推断算法CIPCT,从递归分治的角度应对数据集和条件集过大的情况。采用变量/特征分割方法将变量集递归式地分割成多个子数据集,使用因果推断算法对每个子数据集进行因果推断,得到对应的子结果。在此基础上,通过合并策略对所有的子结果进行合并整理,得到与原始数据集相对应的因果网络。此外,在“分-治-合”过程中采用较为高效的偏相关性测试,避免计算复杂度高的核密度估算,进一步提高因果推断的效率。
1 相关研究
本节将介绍一些关于提升因果推断速度的工作。在研究因果关系相关问题时,函数模型性能也是其中一个决定性因素。本文采用加性噪声模型(Additive Noise Model,ANM)作为因果函数模型,以此作为函数模型的优势在于:一是有独特的模型特性;二是数据都有一个特殊的加噪声项,可以借此获取额外的信息[13]。由于基于最小残差平方的回归方法估算可得到关于Z的非线性平方可积函数,因此文献[14]对(xi,Z)和(xj,Z)分别做非线性回归得到函数f和g,通过检验f和g是否存在将CI 测试简化为两到三个统计独立性测试[15]。当加性噪声模型的特性被加以利用,即可避免估算条件概率密度,减少条件集Z所引起的高维难题,从而获取完整的因果信息,加速CI 测试并打破Markov 等价类限制。
在打破Markov等价类限制的前提下,文献[16-17]提出一种利用残差独立性发现条件独立性的方法,其对于Z维度具有更好的鲁棒性。Markov 等价类包含三个结构:x1→x2→x3,x1←x2→x3,x1←x2←x3,这三个结构有着相同的条件独立性和统计独立性,在传统的因果推断算法下判断异常艰难,但是这三个结构所具有的独特的外加噪声项是完全不同的。文献[18]通过最小二乘回归计算出残差,利用外加噪声项验证条件独立性等价于残差独立性,使得CI 测试进一步简化成一个独立性测试,从而进一步提升速度。
2 预备知识
2.1 因果网络
因果网络是一种概率推理模型,由一组随机变量X={x1,x2,…,xn}以及对应的顶点集V={v1,v2,…,vn}和顶点间边的集合E={e1,e2,…,em}组成,记作G(X,V,E)。可以看出,因果网络是由一组随机变量X与其相对应的一个有向无环图G(V,E)构成的,其要求X的联合概率分布P(X)与G(V,E)是对应的,其中,E={e(xi,xj)|xi,xj∈X}表示有向无环图G中两个变量xi和xj之间的边集合,e(xi,xj)表示变量xi和xj之间的关系,可以是xi-xj、xi→xj或xi←xj。需要注意的是,在因果推断领域中,为了方便或提高阅读性,在不影响理解的情况下,通常用X同时表示变量与节点,不分开论述。
2.2 马尔可夫等价
当有两个有向无环图是马尔可夫等价类时,即两个有向无环图满足包含同样节点、边(不考虑方向)和V结构的条件时,它们具有完全一样的独立性与条件独立性。以图1、图2 为例,这两个网络结构是属于马尔可夫等价的,他们的独立性和条件独立性一致:1)独立性:X不独立Y,X不独立Z和Y不独立Z;2)条件独立性:X不独立Y|Z,X⊥Z|Y,Y不独立Z|X。因此,对于马尔可夫等价类,由于它们都具有相同的独立性与条件独立性,因此CI 测试无法正确判断出真实结构。

图1 顺连结构Fig.1 Consequent structure

图2 分连结构Fig.2 Disjuncition structure
2.3 忠实性假设
已知一个因果网络G,其中有三个变量(集)X、Y、Z,他们的联合概率分布为P(XYZ),如果满足从X⊥Y|Z可以推导出X、Y被Z集合D分离的条件,那么就称这个联合概率分布P(XYZ)满足关于因果网络G的因果忠实性假设。
3 偏相关性测试
本节将讨论如何在因果推断中应用偏相关性测试检测条件独立性是否成立,这里先给出DAUDIN的关于CI 的一个经典理论[19-20],其中描述了如何在平方可积函数空间中把相关性与独立性相关联,将以该理论支撑本文后续的理论分析。
3.1 条件独立性特性
条件独立性特性(Characterization of Conditional Independence,CCI)的相关定义如下:
令X、Y、Z为3 个随机变量或随机变量集,定义:

CCI 描述的是一种在平方可积函数空间中相关性与独立性的等价关系。后续将给出一些相关的理论分析与结果,即分别在高斯和非高斯情况下偏相关性与条件(不)独立性的关系。
3.2 偏相关性与条件独立性的关系
定理1给定m+2个随机变量:x、y和Z={z1,z2,…,zm},它们都是基于独立的随机变量si(i=1,2,…,l)的线性组合,如果所有的si都符合联合高斯分布,那么x⊥y|Z成立,当且仅当σxy.Z=0。
证明考虑到给定变量集Z后x和y的偏相关性系数为ρxy.Z=,其中σ**.Z(给定Z的协方差)可以认为是投影到Z上的x与y残差的协方差。因此,由独立与相关关系可得出σxy.Z=cov(x-E(x|Z),y-E(y|Z))=0。在联合高斯分布下,σxy.Z=0 ⇒x⊥y|Z。
另一方面,如果x⊥y|Z,那么根据式(7)进行推断,因为E(x-E(x|Z)|Z)=0和E(y-E(y|Z)|Z)=0,所以有x-E(x|Z)∈E1和y-E(y|Z)∈E2。此外,考虑到给定Z关于x和y的偏相关性,由于给定Z后的偏协方差σxy.Z等价于x和y在Z形成的线性空间上投影的协方差,因此有:
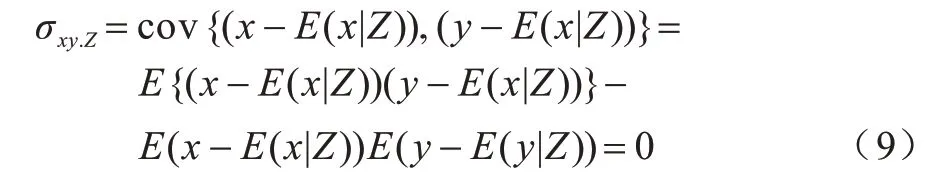
定理2偏相关性不成立与独立成立在联合高斯分布条件下是等价的,即独立性测试可以由偏相关性测试替换。
推论1给定m+2 个随机变量:x、y以及Z={z1,z2,…,zm},它们都是基于独立的随机变量si(i=1,2,…,l)的线性组合,如果所有的si符合联合非高斯分布,那么σxy.Z≠0 ⇒x不独立y|Z。
推论1 可以由定理1 直接推导出,表明在非高斯场景下,偏相关性不成立是条件不独立的充分条件,即可以通过偏相关性测试判定独立性不成立。所以,在非常苛刻的条件——非高斯且偏相关性成立的情况下,无法判断条件独立的情况。因此,在绝大多数情况下,都可以用偏相关性对独立性进行判断,从而大幅缩短检测独立性是否成立的时间。
4 因果推断算法
本节提出基于偏相关性测试的递归式因果推断(CIPCT)算法,对算法基本框架、因果分割、因果方向学习与子图合并4 个部分分别进行介绍。
4.1 算法基本框架
CIPCT 算法是一种递推式算法,其采用传统的“分-治-合”方法[21-22]进行因果学习,并在具体的算法步骤中融合偏相关性测试。CIPCT 算法流程如图3所示,具体步骤如下:

图3 CIPCT 算法流程Fig.3 Procedure of CIPCT algorithm
1)采用分治策略将庞大的原始数据集进行递归,分解成更小的子数据集,使用高效的偏相关性测试提高效率。
2)在分出若干子数据集的基础上,对每一个子数据集进行因果方向学习,形成子结果。
3)以比较显著性值的方式作为合并策略,对所有的子结果进行合并整理后,得到原始数据集对应的完整因果网络图。
4.2 因果分割
由于传统的因果推断算法在面对高维数据时运行时间较长,因此本文在进行因果分割时采用分治策略,并融合偏相关性测试提升效率。因果分割阶段的目的就是尽可能地将数据集分割成子数据集,子数据集会通过与父数据集相同或更高阶的偏相关性测试继续进行因果分割,从而减少偏相关性测试的次数,缩短算法在高维环境下的耗时。在基于CI 测试的因果推断中,一般将CI 测试的执行次数作为算法时间复杂度,因为与CI测试相比,其他操作在执行时间上可以忽略不计。假设原始变量集V={v1,v2,…,vn}被递归分割成m个子集{V1,V2,…,Vm},其中,对于所有m,有|Vm|≤n。当假设CIPCT 使用PC 算法进行因果推断时,则求解子问题的算法时间复杂度为,其中kmax=max(|V1|,|V2|,…,|Vm|)。另一方面,需要在每次迭代中都构造一个CI 测试表,在最坏的情况下,需要针对原始变量集V计算一个σ阶CI 测试表(σ是预先设定的参数)。因此,递归式推断算法CIPCT 的时间复杂度为如果只使用PC 算法解决因果推断问题,则算法复杂度为O(n22n-2)。由于kmax通常要比n小得多,因此CIPCT 算法的算法时间复杂度较传统基于CI 测试的算法大幅降低。
因果分割的具体实现如算法1 所示,主要步骤如下:
1)构造一个0 阶偏相关性测试表M,其通过对数据集V中v1~vn进行偏相关性测试后得到。Mij=1 表示在0 阶条件下vi和vj相关系数为0,即corr(vi,vj)=0;Mij=0 表示在0 阶条件下vi和vj不相关。
2)从Mij=1 中取vi∈A,vj∈B,把数据集V分为子数据集ABC,其中C中断了AB之间所有联系,要求C必须是满足条件的最小集,但不一定为是A或者B的D 分离集。令D=V,从D中去除掉所有与C不相关的变量,令V1=A∪D,V2=B∪D。
3)若在上一步中无法对V进行因果分割,则构造更高一阶的偏相关性测试表,再执行步骤2。通过以上操作,最后可得一个因果分割V={V1,V2}。
算法1因果分割

4.3 因果方向学习
经过因果分割后将会得到若干个子数据集,此处将使用V结构性质进行因果方向学习。首先从局部结构x-z-y入手,如果在给定某个条件集Z之后,能令x、y满足偏相关性,即pcorr(x,y|Z)=0,根据D 分离准则,此时若z不属于Z,就可以判断出x-z-y结构为x→z←y;然后进行一致性传播[3],推导出剩下边的方向。在因果分割过程中会将这几个相似的局部结构保存,以此来完成下一步子图合并。
4.4 子图合并
本文在文献[21]研究的基础上,将子图合并中的CI 测试替换为偏相关测试,根据边与边之间的显著性值sv 的大小决定连接方向。显著性值sv 表示了方向被接受的概率,给出相关的理论分析如下:
定理3对于任意一个无向图或局部无向图,假设给定一个局部结构v1-v2-v3,在对该结构进行基于V结构的方向判断时,接受两个方向v1→v2和v3→v2的概率相同,均为svvstructure:=P(v1⊥v3|S)×P(v1⊥v3|(S∪v2)),其中S为满足CI 的条件集。
证明根据V结构定义,v1与v3在给定某一个条件集S满足CI,而条件集增加中间节点集后不满足CI 这两个特征即可直接推断得到。首先假设给定一个局部V结构v1-v2-v3,当v1→v2和v3→v2时,它们的显著性值分别定义为:

其中:S是对应的D 分离集。然后对比显著性值,取显著性值更大的方向进行方向连接。最后通过合并所有的子因果网络,得到关于原始数据集的完整因果网络结构图。在子图合并过程中,显著性值的计算是在偏相关测试的基础上进行的,通过检测上一步因果分割中的偏相关测试得到显著性值再保存结果,因此,不会增加额外的计算时间。子图合并的具体实现如算法2 所示。
算法2子图合并

5 实验结果与分析
本文所有的实验均在MATLAB R2016a 中进行,运行环境是一台CPU 为i5-7200U,主频为2.50 GHz、内存12 GB 的64 位操作系统的笔记本,将本文提出的CIPCT 算法和目前具有代表性的递归式因果推断算法CAPA[21]进行对比。
实验所用数据为10 组不同的真实因果网络结构[22-23],涵盖了多个领域,表1 中列出了这些数据的网络结构信息,其中,节点数代表维度。
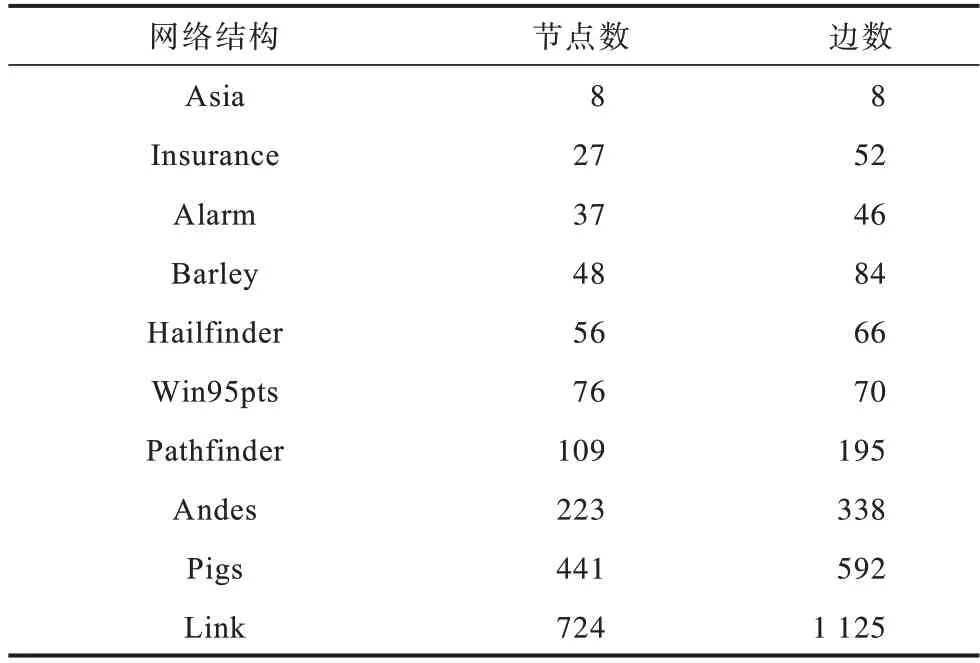
表1 10 个因果网络结构的统计特性Table 1 Statistical characteristics of ten causal network structures
实验分为两种方式进行:首先在不同数据场景下固定相同样本量,将样本量控制在2|V|=2n,这是一种经典的评估样本量、节点个数与准确率关系的方法[14],并同时对比两种推断算法的耗时;然后在相同数据环境下,分别比较不同样本量下的实验结果,评估样本量对准确率、耗时的影响。本文实验使用召回率R、精确率P和F1值F1对算法的综合性能进行评估。其中:召回率反映算法发现因果关系的查全率;精确率反映算法发现因果关系的查准率;F1 值反映算法的综合的准确率。这三个指标的计算公式如下:

5.1 不同数据相同样本量的实验
在不同数据场景下固定相同样本量进行对比实验,选取全部10 个因果网络结构并将样本量控制在2|V|=2n,将提出的CIPCT 算法与CAPA 算法[21]进行对比。对比两种推断算法的准确率,并列出两种算法的运行时间进行分析比较,实验结果如表2 所示,其中加粗数据表示最优值。

表2 CIPIT 和CAPA 算法在不同数据集中的性能对比Table 2 Performance comparison of CIPIT algorithm and CAPA algorithm on different datasets
分析表2 结果可以发现,CIPCT 算法的耗时相对较少,但是精确率相对略低,这是因为偏相关性测试对于高维数据时存在错误添加节点的现象。但是由于其采用了计算偏相关性系数的方式,因此在维度增加时可以筛选出更合适的节点,从而加快构造网络结构的速度,进而加快对高维数据的处理速度。
5.2 相同数据不同样本量的实验
设计在相同数据场景下不同样本量的对比实验,挑选Barley(两者准确率相近)和Andes(CAPA 优于CIPIT)分别在不同样本量(n、2n、3n、5n、7n)的情况下进行对比实验,实验结果如表3 所示,其中加粗数据表示最优值。
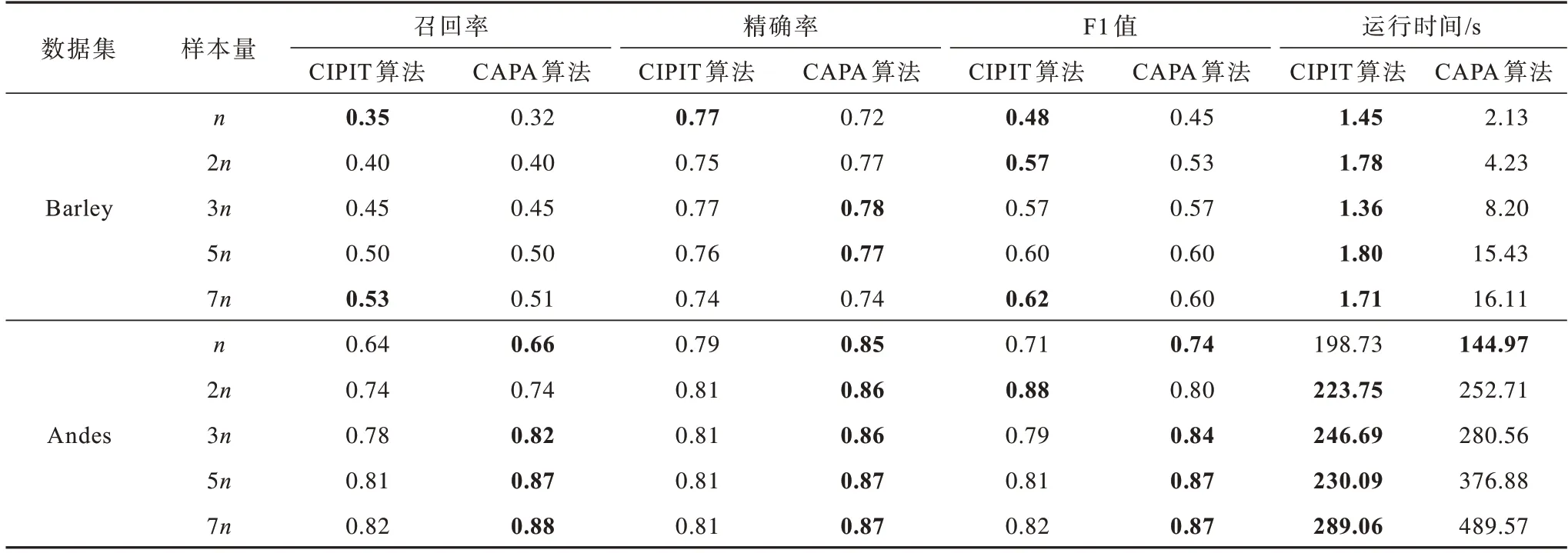
表3 CIPIT 和CAPA 算法在不同样本量下的性能对比Table 3 Performance comparison of CIPIT algorithm and CAPA algorithm under different sample sizes
从表3 可以看出,两种算法在Barley 数据集上准确率几乎持平,而在Andes 数据集上CAPA 优于CIPIT,因为偏相关性测试是一种近似的CI 测试,在特定的网络结构下,如Andes,这个网络结构要求严格的CI,则偏相关性测试效果会一定程度下降。此外,可以看到当维度为n时,在Andes 结构中CI 测试的速度较快,原因是CAPA 采用的是启发式因果分割,在低样本量情况下,加上CI 测试的耗时也可能要比CIPIT 快。
通过对比表3 中的F1 值和运行时间可以看出,虽然本文算法在Andes 网络结构中的F1值略低于CAPA 算法,但对比两种算法的处理时间可知,CIPIT可以在高维网络结构中进行更快速的有效构建,并且在维度越高的数据环境下这种时间差距越明显。由于目前其他的因果推断算法都难以在高维数据环境下进行快速有效的处理,使用偏相关性测试后耗时减少明显,说明本文算法在运算时间上具有显著优势。
6 结束语
本文提出的CIPCT 算法是一种基于偏相关性测试的快速因果推断算法,其在传统的“分-治-合”框架中融入偏相关性测试,从而保证准确率同时提高运算效率。在对因果结构进行降维处理“分”的过程中,将整体的因果网络快速拆分成若干个子因果网络,对每一个子因果网络都进行因果推断,使得因果推断能够在高维数据环境下运行,避免传统CI 测试运算复杂度和时间复杂度高的缺点。实验结果表明,在高维数据环境下,本文算法与目前具有代表性的递归式因果推断算法CAPA 在准确率几乎持平的情况下,速度可提升2~10 倍。后续将改进推断过程及算法框架,将本文算法与神经网络相结合,进一步提升准确率和降低算法复杂度。
猜你喜欢
心理学报(2022年10期)2022-10-12
计算技术与自动化(2022年1期)2022-04-15
中国循证心血管医学杂志(2022年1期)2022-03-15
内蒙古统计(2021年4期)2021-12-06
西南林业大学学报(2021年5期)2021-10-21
密码学报(2021年4期)2021-09-14
成都信息工程大学学报(2021年6期)2021-02-12
计算机技术与发展(2020年2期)2020-04-15
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
