
家系抽样大小对云南松遗传力估算的影响
2021-10-21 11:36:24孙继伟李熙颜蔡年辉许玉兰杨利华
西南林业大学学报 2021年5期
孙继伟 王 丹 李熙颜 陈 诗 蔡年辉 许玉兰 杨利华
(1. 西南林业大学 西南山地森林资源保育与利用教育部重点实验室,云南 昆明 650233;2. 西南林业大学云南省高校林木遗传改良与繁育重点实验室,云南 昆明 650233;3. 普洱市林业和草原科学研究所,云南 普洱 665099)
云南松(Pinus yunnanensis)是云南省主要用材树种及重要的生态树种,其遗传改良与良种培育工作的开展对分布区内的经济发展和生态环境建设具有重大意义。然而,受天然更新、人为干扰、病虫害等因素的影响,云南松天然林出现退化[1-3],云南松人工林多数为纯林,由于其生态系统功能的弱化,人工林也出现不同程度退化[4]。以往开展云南松子代测定时通常测量所有试验苗木,尤其是研究生长性状,逐株地多指标测量苗木需要耗费大量人力物力[5]。与此同时,由于国家禁止采伐天然林用于商业,我国的木材使用持续依靠进口,数量不断增大,然而社会需求持续增长与供应不足之间的矛盾一直是突出问题[5]。加强对于用材树种的遗传育种研究,可以有效促进林业产业发展,进而缓解木材供应与需要的矛盾。
苗高和地径通常作为用材树种遗传改良的目标,云南松的子代测定在20世纪90年代有较多的研究[6-8],最初学者们通过子代测定进行选优、建立无性系种子园,使人工林的经济效益提高[9],与此同时,通过子代测定选择具有优良性状的双亲建立母树林[10]。子代测定研究工作在其他树种中较多,目前云南松这方面的研究多集中于苗期选择[11-13],且研究多采用随机抽样或全样本测量的方法,全样本测定的方法得到的结果精确度高但需要耗费大量人力物力,使测量成本高昂。遗传参数估算是群体遗传学研究的主要内容之一,测定材料、试验设计和生境等因素影响遗传参数估算值,除这些因素,基因型与环境的互作效应、小样本抽样等也会影响,其中样本容量或是在某一特定群体中育种群体的大小对遗传力估算值影响较大[14-15]。对子代进行遗传测定可估算亲本性状的配合力和遗传力等重要参数,其结果可指导种子园的营建,选择优良性状的云南松家系,为下一步培育提供繁殖材料,是遗传改良的重要内容[16-17]。
云南松的子代测定研究成果来看,测定子代遗传参数需要的样本量如何确定,还是一个值得探讨的问题。影响家系样本量对于子代遗传力估算可以从估算精度及子代测定所需的临界样本量2方面进行探讨[18]。提高精度主要可以通过选择不同的交配设计,鉴于此,本研究主要从如何确定家系样本量进行讨论。在遗传力估算值有较高精度的条件下,按家系样本量间隔为10的梯度随机抽取云南松半同胞家系,研究不同家系样本量梯度对遗传力估算的影响,进而确定地径及苗高的遗传力估算需要的最低样本量,为今后云南松苗期遗传测定所需的最佳样本量和选择方式提供参考。
1 材料与方法
1.1 试验材料
试验地位于云南省昆明市盘龙区西南林业大学苗圃内,东经102°45′41″,北纬25°04′00″,播种所用种子来源于3个不同的采种点,分别为云南宜良、新平和禄丰,共140个半同胞家系。
1.2 苗木培育与测定
采用完全随机区组试验,以株行距5 cm×10 cm进行点播,每个家系播种2行,每行播种20粒,共40粒种子,设置3个重复,每个家系播种120粒。将存活9 196个单株作为测定植株,苗龄为2 a,分别使用直尺和电子游标卡尺测量苗高和地径,其中苗高精确到0.1 cm,地径精确到0.01 mm,分家系记录,各家系植株数见下表1。
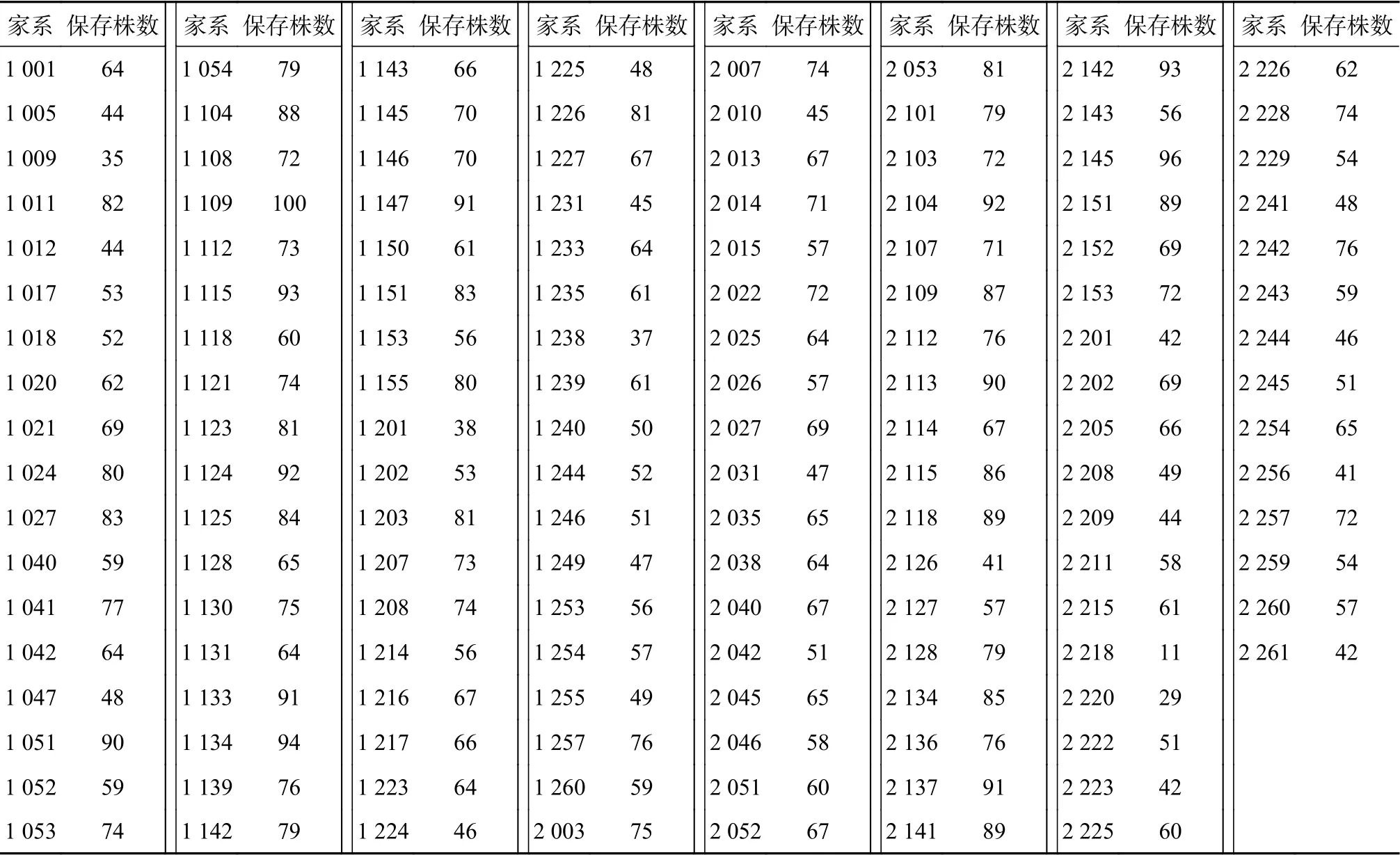
表1 2年生云南松苗木各家系保存数Table 1 Preservation number of different families of 2-year-old P. yunnanensis seedlings
1.3 抽样与遗传参数的计算
利用Excel 2010整理录入数据,为所有家系进行编号。利用课题组前期编写好的随机抽样程序(从140个家系中不放回的抽取n个家系作为样本量)对数据进行预抽取,经过预抽取,设置家系样本量梯度为10、20、30、40、50、···、140,共14个家系样本量梯度,标记为F1、F2、F3、F4、F5、···、F14。按此梯度对整理好的数据进行正式抽取,每次抽取并导出表格文件,用家系样本量加上抽取次数对文件进行命名,如第1次抽取家系样本量为10的数据,命名为:family10 1st。第1轮每个家系抽取30次,并数据进行方差分析及样本量确定。数据分析包括以下几个方面。
1)遗传参数估算。使用HalfsibSS 1.0软件对导出的数据进行分析[19],将导出表格的第1行修改为指定格式,如有3个重复,对2个指标分析10个家系样本量下的遗传参数,应将第1行修改为‘block3 family10 trait2’。更改格式后需要将文件另存为文本文件的格式,导入进行分析,可以得到该家系样本量的家系遗传力和标准差。
2)家系遗传力的均值与变异系数。对不同家系样本量计算输出的结果进行整理,使用SPSS进行均值比较,计算苗高和地径家系遗传力的极值、均值、标准差[20],计算各样本量下家系遗传力的变异系数(平均值/标准差×100%),用来估算各性状表现的离散程度,即变异系数越小,离散程度越低,反之离散程度越高。
3)不同家系样本量间遗传力差异性检验。使用SPSS 24.0进行方差分析,Duncan法进行多重比较。以确定不同家系样本量间的差异显著性,进而确定家系样本量对云南松子代测定遗传力估算的影响。
1.4 临界家系样本量的确定
本研究设置的14个梯度中每个被抽取的家系都包含该家系所有单株,取苗高和地径2个生长性状的遗传力不再随样本量增加发生显著变化时的家系样本量,即遗传力估算值趋于平稳时的家系样本量作为临界样本量,利用的3种方法,结合图表确定临界样本量[21]。
1)计算每个梯度与相邻梯度遗传参数差的绝对值,对所有结果取平均,得到所有梯度遗传参数估算值的平均绝对差值(MAD):
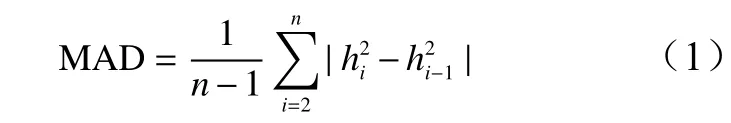
2)计算所有14个梯度的性状遗传力估算值,求取平均值(AV),再确定1个正整数m,条件(其中,k为随机比例因子,如0.05或0.1,AVm为最后n-m+1个梯度的遗传力的平均值)。正整数m的确定方法同方法1。
3)计算所有14个梯度性状遗传力估算值的标准差(SD),再确定1个正整数m,使得相邻梯度间遗传力满足条件SD。正整数m的确定方法同方法1。
2 结果与分析
2.1 不同家系样本量下地径和苗高的基本情况
各家系样本量梯度地径和苗高的均值分别为11.28 mm和13.3 cm,随机抽取不同梯度家系样本量使得苗高、地径生长的情况均值较相近。苗高指标各家系梯度生长量变化范围是12.6~14.8cm,变异系数20.53%;地径指标的各家系梯度生长量变化范围是10.57~11.82 mm,变异系数3.36%(表2),即各家系样本量的随机抽取结果相对比较稳定。对各家系梯度间进行方差分析,结果表明苗高、地径均值及变异系数在各梯度间均无显著差异。
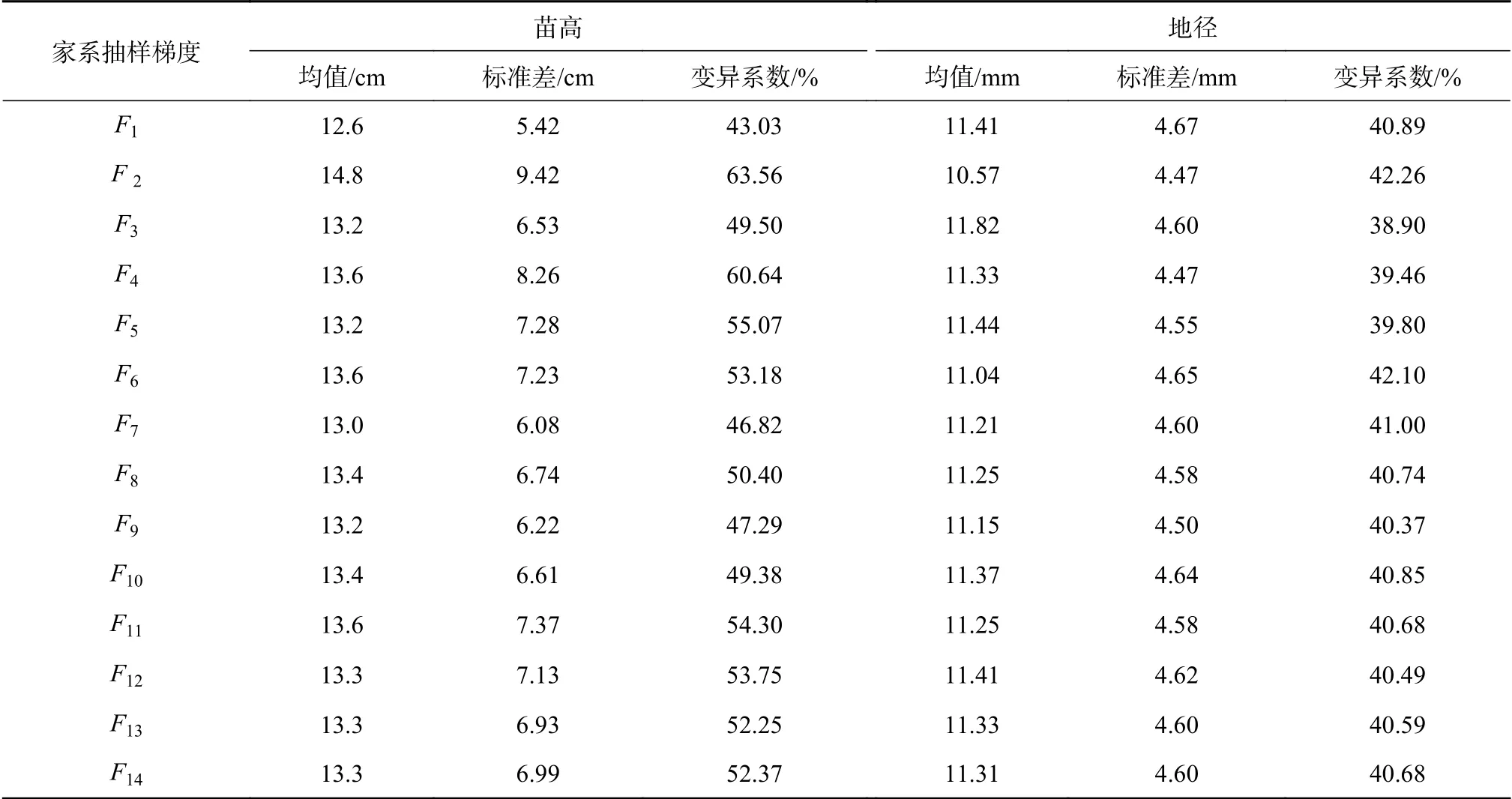
表2 云南松苗木各家系样本梯度苗高和地径指标生长量的基本情况Table 2 Basic information of P. yunnanensis seedling height and ground diameter for each family sample size
2.2 不同家系样本容量对地径遗传力的影响
被测群体的14个梯度地径指标的家系遗传力变化范围是0.393 7~0.770 1,试验家系样本量梯度间的地径遗传力具有显著的差异(P<0.05),其中除家系样本量梯度F2外,其余家系样本量梯度的地径家系遗传力均显著大于家系样本量梯度F3,最大的为家系样本量梯度F7,达0.677 0。家系遗传力的最大值为0.770 1,出现在家系样本量梯度F1,即含有10个家系样本量的梯度,其变异系数为18.35%;最小值出现在家系样本量梯度F2,即含有20个家系样本量的梯度,为0.393 7,其变异系数为17.64%。14个梯度的变异系数波动范围是0.29%~18.35%,通过变异系数随家系样本量的变化分析,家系样本量较少的梯度,遗传力估算值波动较大。随家系样本量的增加,遗传力估算值逐渐趋于稳定,家系样本量增加至70个后,遗传力估算的稳定性更加明显。家系样本量梯度F1~F4遗传力估算值及其标准差与含有140个家系的梯度存在较大差异,中间梯度即F5~F14遗传力估算值及其标准差没有较大的差异,总体来看,遗传力参数估算的平均值为0.6~0.7(除家系样本量梯度F3),波动程度在家系样本量梯度大于F7时变得稳定;标准差随参试家系样本量的增加,逐渐减小(表3)。这种趋势体现出参试家系样本量越接近总参试家系(F14=140),其家系遗传力的估算值准确度就越高。鉴于此,在遗传分析研究时,研究者们趋向于在实际操作可行的情况下尽可能多的提取家系样本进行分析计算,从而得到更加准确的结果。

表3 云南松苗木地径和苗高的家系遗传力Table 3 Family heritability estimation of P. yunnanensis seedling height and ground diameter in different family sample size
2.3 不同家系样本容量对苗高遗传力的影响
被测14个梯度苗高的家系遗传力为0.565 7~0.918 0,与地径遗传力不相一致,家系样本梯度间的苗高遗传力具有极显著的差异影响(P<0.01),家系样本梯度F7~F14的苗高遗传力极显著地高于家系样本梯度F1~F5。家系遗传力最大为0.918 0,出现在家系样本量梯度F10,即含有100个家系样本量的梯度,其变异系数为6.00%;最小值出现在家系样本量梯度F1,即含有10个家系的梯度,为0.565 7,其变异系数为13.91%,家系样本梯度F1~F6苗高的遗传力与最大梯度即含有140个家系样本梯度的遗传力估算值相差很大,在家系样本量增加到100个以后,遗传力估算值变化逐渐趋于稳定,中间梯度即F7~F9遗传力的估算值相差不大,但与遗传力估算值最大的梯度仍有一定差距。14个梯度的变异系数波动范围是0.51%~13.91%,通过变异系数随家系样本量梯度的变化分析,家系样本量过少的梯度,遗传力估算值波动较大,家系样本量越大,其变异系数越小。苗高的标准差大小随家系样本量的增加逐渐降低,然而在家系样本量小于70个时,标准差波动范围较大,但整体趋势下标准差仍然随着家系样本量的增加而降低,在家系样本量大于70个后仍持续缓慢降低(表3)。综合分析变异系数和标准差估算值,说明在家系样本量小于70个时遗传力估算的准确度较低,估算值存在较大的偶然性。
计算分析遗传力估算值随家系样本量的变化趋势,分析两变量之间的回归关系,确定其参数方程,得到更加清晰、明确的数量关系,使研究成果对其他主要用材树种的测定选择样本量更有参考价值。经过SPSS软件对苗高和地径与家系样本量回归分析,苗高、地径F值统计量分别103.609(P<0.001)和13.021(P<0.001),表明测量时家系样本量(X)的增加对云南松家系遗传力估算(Y)的回归效果显著,由回归系数表可知回归方程分别为:Y=0.702+0.001X、Y=0.61+0.001X。
2.4 临界家系样本量下苗高及地径遗传力及其标准差估算值
通过3种方法判断的各性状遗传力及其标准差估算所需的临界家系样本量结果(表4)表明:临界样本量的最小值是方法2确定的,最大值是使用方法3确定的。方法2和方法3的k取值越小,表示所要求遗传力估算值波动越小,在该临界样本量下遗传力的估算值和标准差也越高。其中方法3的k取值为0.1时,符合对应判定条件的梯度,说明在该取值下遗传力估算值变化趋势的平稳程度不能满足判定临界样本量的要求。
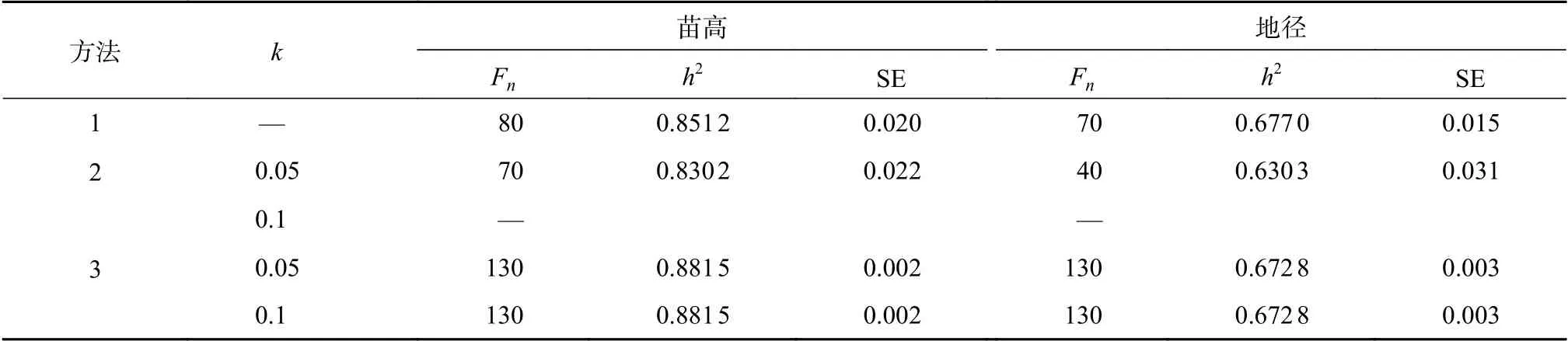
表4 3种方法下两性状遗传力估算所需的临界家系样本量Table 4 The critical sample size of familiy heritability estimation of P. yunnanensis seedling by using 3 methods
综合3种方法,方法1确定的临界家系样本量为70~80个,此时数据波动幅度较小,标准差较小,可以作为本测定群体的家系样本量。方法2将波动幅度与相应家系样本梯度的平均值进行比较,当比例因子k=0.05时,采用40~70个家系进行参数估算即可达到测定目的。方法3当比例因子为0.05时苗高和地径遗传力估算所要求的临界家系样本量最高,此时需采用130个家系进行估算。综合前文性状遗传力及其标准差结果,对于本研究的测定群体,测定的2年生云南松苗木家系数大于70个时,可以获得有一定准确度的遗传力估算值。3种方法确定的临界样本量有差异,地径指标在2年生时其遗传力估算并没有在各家系区分出更明显的子集,所以在讨论对于该群体临界样本量的确定,更倾向于多考虑苗高指标。方法2及方法3定的临界样本量分别为40个和130个,家系样本量为40个时,遗传力估算值仍有较大波动,根据多重比较结果,F4处于第3、4子集,说明该家系样本梯度并不是表现最符合亲本的家系样本量,且不具备较高准确性;家系样本量为130时,虽然得到结果的误差与变异系数较小,但接近全样本测量为对研究及生产无意义。综上所述,在家系样本量为70个时,家系遗传力均值较高,而标准差和变异系数较低;测定的云南松家系数大于70个,既保证其遗传力估算值的准确性,又达到实际生产实验需要。
3 结论与讨论
应用简单随机抽样的方法来调查云南松苗木质量,在简单随机抽样的调查方法中,调查对象的样本量的确定一直是一个难题,样本量的确定过程本质上是费用与精度的权衡过程[22]。苗高和地径是衡量苗木品质及估算遗传参数的重要指标[23-24]。本试验以140个云南松2年生半同胞家系共9 196株苗木的为研究材料,通过比较分析在不同家系样本量下苗高和地径遗传力及其标准差估算值的稳定性,探讨家系样本量对性状遗传力估算的影响,进而确定各性状遗传力评估所需的临界样本量。结果表明,遗传力估算值稳定性随着家系样本量的增加而提高,云南松子代苗高和地径遗传力估算的家系样本量较小时,估算值有较大的波动,可通过增加抽样次数在一定范围内提高数据的准确性和代表性。
确定抽样方法时,应该考虑到样本量的多少,因为样本量的大小会影响抽样结果的精度,不同的样本量应该选取不同的抽样方法来进行试验[25]。本研究中家系样本量达到了140个,且抽样时每次抽中仍放回总体,采取了简单随机抽样重复抽样的方法,按不同家系样本量梯度来进行抽样,随着每个家系样本量的增加,相对应的苗高与地径的家系遗传力估算值趋于稳定,标准差不断降低趋近于0。这在张帅楠等[18]对湿地松(Pinus elliottii)的研究中也有报道,样本量大小对性状遗传力估算有影响,小样本量下的遗传力及其标准差估算值不稳定,随样本量或家系量的增加其精度与准确性逐渐增加,在遗传力估计时应采用较大的样本量与尽可能多的家系数,以保证其估算的精度及准确性的结果相似,较大的样本量有利于提高遗传参数估算的精度。毕志宏等[26]也发现了不同的样本量会对白桦(Betula platyphylla)各性状遗传参数产生影响,需要较大的样本容量确保精度。这也与本研究中随着每个家系样本量的增加,相应的苗高与地径的家系遗传力估算值趋于稳定,标准差不断降低趋近于0的结果类似,在相关研究中应考虑到样本量的大小对遗传参数估算的影响。
样本量过小,则估计量方差过大,统计推断的可信度降低,而样本量过大,会浪费人财物力,且调查周期延长,从而丧失抽样调查相对于全面调查的优点[27-28]。所以,如何寻找一个合适的样本量,既能使样本充分地代表总体,又能保证抽样调查耗时少、费用低的优点,这成为抽样理论和实践都必须要面对和回答的课题。样本量临界值的确定均衡了工作量的消耗与调查精度之间的关系,在临界值以下,估算精度随家系样本量增加而提高,到达临界点后,样本量的增加对遗传力估算精度的提高增效微弱[18,26]。本研究中,家系样本量为70个时,家系遗传力均值较稳定,而标准差和变异系数较低,虽然家系样本量在更接近总样本量时获得了更高的精度,但是为了保证其遗传力估算值的准确性,又达到实际生产需要,因此测定的云南松家系数大于或等于70个为宜。
同时,研究也存在一定的局限性,研究结果显示,对于不同性状最终确定的临界样本量也不同[18,26,29],对于遗传力较低的性状需要增加临界样本量[15]。但本研究由于只分析2个性状并不能证明这一结论,没有囊括苗木的其他生长性状(针叶长、植株根茎叶的鲜质量及干质量等),只用苗高和地径性状进行分析,性状间的互作并没有被考虑进来,会影响其群体遗传参数的研究,故对于试验林其他性状的遗传力估算还需要更深入地研究。
综上所述,在各样本为随机抽取的情况下,各家系梯度的样本相对比较稳定。对各家系样本量梯度间苗高、地径均值及其变异系数均无显著差异,每一梯度的遗传力及其标准差估算结果均无偏移。对于苗高和地径2个性状的家系遗传力估算值在不同家系样本容量梯度间都存在显著的差异,其中苗高存在极显著差异(P<0.01)、地径存在显著差异(P<0.05),即家系样本量对云南松子代测定的苗高和地径的家系遗传力有显著影响。样本量的较小时家系遗传力估算值的变异系数较大,估算精度随着样本量的增加而有规律的增加,另外为了保证估算精度,应不断计算并增加抽样次数。对本研究的云南松半同胞子代来说,3种方法确定的临界样本量有差异,地径指标在2年生时其遗传力估算并没有在各家系区分出更明显的子集,所以在讨论对于该群体临界样本量的确定,更倾向于多考虑苗高指标。方法2及方法3确定的临界样本量分别为40个和130个,家系样本量为40个时,遗传力估算值仍有较大波动,根据多重比较结果,F4处于第3、4子集,说明该家系样本量梯度并不是表现最符合亲本的家系容量,且不具备较高准确性;家系样本量为130个时,虽然得到结果的误差与变异系数较小,但接近全样本测量为对研究及生产无意义。综上所述,在家系样本量为70个时,家系遗传力均值较稳定,而标准差和变异系数较低。样本量大于70个时,既保证其遗传力估算值的准确性,又达到实际生产实验需要。确定临界样本量,对快速、简便的测定苗木提供了可行的参考。
猜你喜欢
西北农业学报(2024年7期)2024-07-12 20:26:59
养猪(2022年4期)2022-08-17 07:07:02
农技服务(2020年1期)2020-12-17 08:15:01
林产工业(2020年8期)2020-08-31 06:58:26
山东农业科学(2019年11期)2019-12-24 01:11:27
现代农业科技(2019年1期)2019-07-11 01:36:25
乡村科技(2019年9期)2019-02-22 06:09:22
山西农业科学(2019年10期)2019-02-12 04:15:51
现代农业科技(2017年24期)2018-01-22 21:35:06
广西林业科学(2016年3期)2016-03-16 05:43:39
