
股票市场风险VaR 与TVaR 测度的比较检验和启示
2022-10-15 06:40刘小毅李存芳高千惠
生产力研究 2022年9期
刘小毅,李存芳,高千惠,成 瑶
(江苏师范大学 商学院,江苏 徐州 221116)
一、引言
在新冠肺炎疫情和俄乌冲突影响下,百年变局加快演进,形成各类因素动态变化、叠加、共振,容易激起国际金融市场动荡,孕育一系列新的金融风险,比如在2020 年3 月9 日、3 月12 日、3 月16日,10 天之内美国股市已经三次触发熔断机制,同时伴随着汇市和债市的错迭动荡。进一步审视,国际上大多数国家进入新冠肺炎疫情常态化的政策趋稳期,美国宏观政策收紧又同一些新兴市场国家脆弱性重叠,世界隐性金融波动难免与我国经济增速下行、风险暴露时期形成交集;国内短期经济下行压力与中长期经济转型压力同在,一些区域及相关行业的风险因素孕育渐趋明显,可能出现局部风险暴露叠加,并发金融风险共振的危机[1-3]。然而,“要把防控金融风险放到更加重要的位置,牢牢守住不发生系统性风险底线”已成为十八大以来党中央的既定方针和重大部署,由于股票市场是金融风险乃至国民经济发展的晴雨表,因此如何采取科学有效的方法测度股票市场风险,成为一项十分重要而紧迫的任务。
此前,学界和业界对于股票市场的风险给予了重点关注。30 国集团于1993 年在《衍生产品的实践和规则》报告中提出以在险价值(Value-at-Risk,VaR)作为风险度量工具,VaR 具体表达了一定置信水平和持有期下股票市场风险资产可能遭损的最大值[4-6]。此后,有些学者研究借用VaR 模型和方法来测度商业银行的操作风险[7],利用VaR 模型和方法具体测量一系列的失真风险案例,并展开比较分析[8]。还有些学者关注操作风险与股票回报之间的相关性,研究发现操作风险与股票回报的相关性曾历经负向变化,进而检验了金融公司和非金融公司操作风险的决定因素[9]。应该承认这些研究肯定VaR 模型的有效性。同时,也有些学者对VaR 模型和方法提出质疑,指出VaR 模型和方法存在不足之处,并提出了以尾部在险价值(Tail-Value-at-Risk,TVaR)等模型和方法进行股票市场的风险测度[10-14]。还有些学者对其进行了一致性和在非正态分布条件下适用性的证明,以及具体应用分析[15-17]。总体看来已有研究还仅停留于一般性的理论分析,缺乏针对我国金融行业特点的深度调查和实证检验。尤其是对于这两类模型和方法在我国股票市场的使用有何差异和优劣,能否作为股票风险测度的可靠依据,如何科学有效地使用这些风险度量工具等问题仍需系统探究。
二、VaR 与TVaR 测度的基本方法
(一)VaR 测度模型
VaR 是Value at Risk 的缩写,即在险价值,定义为在给定的置信水平和持有期下,投资组合可能遭受的损失最大值。设置信水平为α,则VaR 可表示为:

式(1)中△p=pt-p0,为持有期内金融资产的损失,pt为持有期到期后时刻t 的价格,p0为初始价格。
为了具体计算某一VaR 值,可预设r 为持有期内的收益率,其期望为μ,波动率为σ,则pt=p(01+r)。如果令r* 为收益率的最小值,则投资组合在持有期内的最小值为p*=p(01+r*)。由定义可知,期末价值均值减去持有期内的最小价格即为损失的最大值,即:

(二)VaR 计算方法
对于VaR 的实际计算可采取两类方法:
一是参数方法。主要是假设收益率服从某一分布,然后通过估计模型的参数计算VaR 值,最常用的是GARCH 模型。由于计算简便且直观,参数方法的运用十分广泛。然而它本身存在着比较多的缺陷,首先参数方法假设收益率服从某一分布,这是否符合实际情况会直接影响到模型估值的误差;其次对于一些突发事件和特殊情形,参数方法会直接忽略其影响,从而无法充分考虑到这些情况。
二是非参数方法。主要包括蒙特卡洛模拟法和历史模拟法。蒙特卡洛模拟法也叫随机模拟法,它的基本思想是通过随机产生的大量数据与真实数据进行拟合,反复进行抽样实验,模拟数据的随机过程,最终得出真实数据的近似分布。它是一种全值估值方法,拟合了整个过程中的所有数据,对于尖峰厚尾、非线性和极特殊情况的处理都包含在内,解决了非正态分布问题,相较于参数方法精度大大提高。然而它的缺陷也非常明显,首先它使用了大量的随机数进行反复模拟,计算量非常巨大,需要很高的时间成本;其次蒙特卡洛模拟法非常依赖于使用的随机过程模型,所以有着显著的模型风险。历史模拟法则假设历史会不断重演,选取观测到的一部分历史数据,模拟未来数据的可能走势,并算出VaR 值。它也是一种全值估值方法,计算简单且直观,容易理解。它不仅克服了参数方法中的缺陷,消除了尖峰厚尾与非对称性等分布上的问题,而且并不依赖事先预设和使用的一些模型,基本避免了模型风险的产生。当然,它并非是一种完美的方法,因为它假设历史会不断重演,不利于短期之内的预测,而且它的前提是收益率之间独立同分布,较为苛刻,大多数数据不能完全满足。同时作为一种直接使用历史数据的全值估值方法,极端值也会显著地影响估值的精度。
(三)TVaR 改进成效
对于VaR 存在的缺陷,TVaR 作出了一种风险度量的修正。TVaR 是Tail-Value-at-Risk 的缩写,即条件风险价值,定义为给定置信水平下,投资组合的损失超过VaR 的条件均值,它实际度量的是超额损失的平均水平。其表示形式为:
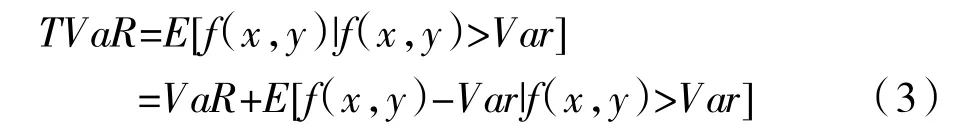
TVaR 作为一个衍生度量工具,符合一致性公理,换言之,它所度量的风险符合次可加性,这与金融风险管理领域中的实际情况相吻合。同时考虑了极端情况与尾部风险,能够有效弥补VaR 的显著缺陷,应该是一个合理改进的风险度量方法[4]。
三、VaR 与TVaR 测度在我国股票市场中的应用检验
(一)数据的选取和处理
我国上海证券交易所的上证综指是以交易所内所有股票作为样本编制的股票指数,深圳证券交易所的深证成指是以交易所内市值规模和流动性排名前500 的股票作为样本编制的股票指数。这两大指数具有很强的代表性,大致反映了我国股票市场的运行情况。
本文的数据分别选取2014 年1 月至2019 年12 月上证综指和深证成指在每个交易日的收盘价,均分别有1 464 个数据。为了便于数据的线性计算,首先对收益率进行对数化处理,得到处理后的收益率。

式(4)中pt为某一交易日当天的收盘价,pt-1为前一天的收盘价。处理完后分别得到1 463 个数据。两组数据的收盘价和收益率情况如图1~图4 所示。

图1 上证综指收盘价
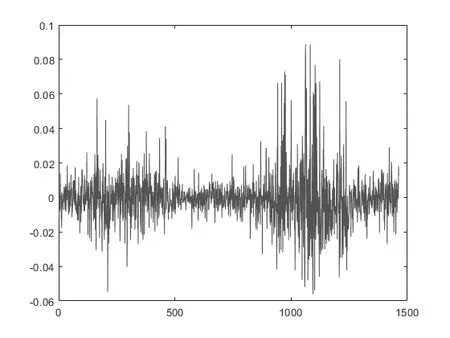
图2 上证综指收益率
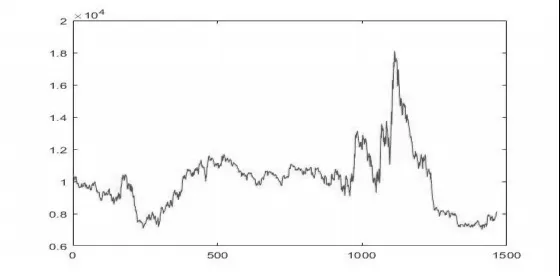
图3 深证成指收盘价

图4 深证成指收益率
由图1~图4 可知,我国股票市场的波动量非常大,波动频率特别高。而且两大交易市场的波动趋势基本相似,能够反映出我国股票市场的总体特征。
(二)数据的描述性统计分析
使用SPSS 软件对收益率样本进行偏度、峰度、均值、标准差等基本指标的计算,结果如表1 所示,同时绘制直方图对正态性拟合程度进行判断,如图5、图6 所示。

表1 两大交易市场收益率描述性统计表

图5 上证综指收益率直方图
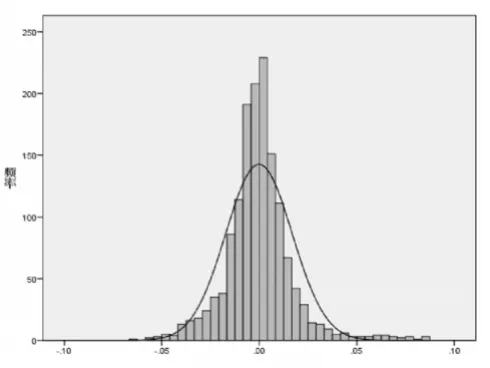
图6 深证成指收益率直方图
由表1 及图5 和图6 可知,上证综指收益率样本的均值为-0.000 3、标准差为0.014 5、偏度为1.164、峰度为7.221,收益率样本具有尖峰和左偏的特征;深证成指收益率样本的均值为-0.000 2、标准差为0.0170 5、偏度为0.875、峰度为4.415,收益率样本同样具有尖峰和左偏的特征。结合正态曲线判断,可认为上证综指、深证成指的收益率样本均不服从正态分布。由此如果使用参数方法会存在一定的分布假设风险,而历史模拟法对收益率的分布未有特别要求,故采用历史模拟法进行实证检验分析。
(三)VaR 值的计算
设定置信区间α 为99%,将收益率序列进行从小到大排序,样本总数1 463*(1-99%)取整后即为此置信水平下收盘价在险价值对应的收益率分位数,即r*=-0.0352。r* 的现实意义为:每日对数收益率不会低于r*,即某日后一天收盘价的变化率不会超过
进一步计算某日的金融头寸pt的在险价值,其中pt-1为前一日的收盘价。对数据处理后两个市场分别得到1 464 个VaR 值,如图7、图8 所示。

图7 上证综指在险价值

图8 深证成指在险价值
取上证综指在险价值走势图第501 个数据验证,即2017 年12 月14 日的在险价值为-115.4,其含义为:上一个交易日即2017 年12 月13 日的收盘价在2017 年12 月14 日的下跌幅度不会超过115.4 点。实际上2017 年12 月13 日的收盘价为3 303.037点,12 月14 日的收盘价为3 292.439 点,下跌了10.598点,处于在险价值限定的范围内。取深证成指在险价值走势图第501 个数据,即2017 年12 月14 日的在险价值为-464,实际2017 年12 月13 日的收盘价为11 110.18 点,12 月14 日的收盘价为11 113.89 点,上涨了3.71 点,仍处在在险价值的限定范围内,说明VaR 模型的建立是基本有效的。
(四)VaR 值的返回检验
将预测的损失最大值代入到收盘价序列中,得到每日收盘价下限的走势,并与实际收盘价进行比较分析发现,仍有部分损失值超过了在险价值,即收盘价曲线与预测下限曲线出现交叉。通过Matlab 程序找到上证综指收盘价的第212、295、939、1018、1048、1059、1060、1073、1077、1094、1095、1102、122、1208、1240 个数据损失值均超过了预测数据,共有15个,预测失败率约为1.03%。深证成指收盘价的第212、295、939、1018、1048、1059、1077、1089、1093、1094、1102、1122、1220、1238 个数据损失值超过了预测数据,共有14 个,预测失败率约为0.96%。
(五)TVaR 的测度修正
为了修正VaR 模型的部分失败预测,更好地限定收盘价走势的下限,采用TVaR 模型进行测度。首先建立一个数组容纳所有损失超出VaR 的收盘价序列;其次算出损失额度,接着求出损失额度的期望,即为超额损失的均值,然后将其与原VaR 进行叠加,可得到具体的TVaR 数值。再而将TVaR 代入到收盘价序列中,便得修正后的收盘价下限走势。同时,为了进一步验证TVaR 模型对VaR 模型的修正是否有效,选择上证综指VaR 的第212 个失败预测点、深证成指VaR 的第1 238 个失败预测点进行观测,结果如图9、图10 所示。

图9 上证综指VaR、TVaR 与收盘价观测图

图10 深证成指VaR、TVaR 与收盘价观测图
由图9 和图10 可以观察到,VaR 模型预测的失败位置,经TVaR 模型修正,收盘价损失额并未超过在险价值的预测。经进一步检验TVaR 预测曲线与收盘价未有交叉,说明两组数据的失败预测点均被TVaR 模型修正完毕。
四、VaR 与TVaR 测度在我国股票市场中的应用启示
(一)VaR 测度优势明显,劣势突出
通过VaR 模型对沪市和深市的收盘价所进行的下限预测发现,99%的预测值均在实际值的下方,可以认为99%的预测是成功的。然而,其中仍分别有15 个和14 个值偏移到实际值上方,分析其直接原因在于VaR 模型对于两大市场的极端情形考虑不足,尾部风险直接忽略。因此,在肯定VaR 模型应用优势的同时,还必须认清VaR 模型的劣势及其影响,主要体现在三个方面:一是不符合一致性公理。所计算出的在险价值无法叠加计算,在进行资产组合时无法达到风险分散的目的。二是存在较大的模型风险或数据风险。测度方法依赖于随机过程模型或收益率数据的确定分布,而对于一些新股,或者无法获取较长时间段内历史数据的股票,显然难以进行准确的计算,对于在险价值的预测难免出现过高或过低的现象。三是忽视了损失高于VaR 的极端情况,忽略了尾部的风险。容易产生对投资者的误导,甚至有可能导致管理者为了流动资金而强行无视极端损失,产生道德风险与信用风险,诱发较大的金融风险。对此,必须高度重视,进行有效改进。
(二)TVaR 测度优势显著,仍需完善
TVaR 模型针对VaR 模型的具体缺陷进行了相应的改进,构建了一个新的风险度量,重新规划了预测的下限,经验证其失败率远低于VaR 模型,误差更小。分析其直接原因在于TVaR 设计了一个超额损失的条件期望,能有效地消除极端数值和数据厚尾性对VaR 造成的影响,即可修正损失值超过在险价值的部分点位,而且是一个满足一致性的风险度量,总体在险价值等于修正在险价值的部分和。应该看到,TVaR 模型解决了VaR 测度的大部分问题,成为度量股票风险的一种有效工具,但深入分析TVaR 模型仍需进一步改进完善,主要体现在两个方面:一是TVaR计算了超额损失的期望,并不能确保修正所有超额损失位置。当实际损失超出在险价值的数值过大,TVaR就无法修正此处的在险价值。二是TVaR 测度对于风险态度的考虑不足。对于监管者来说,他们的风险态度偏于保守和严格;而对于金融机构来说,希望放松风险管制,从而使更多的准备金可以用来进行投资获利。这就需要TVaR 测度考虑风险态度,以有利于监管者与金融机构达成共识。
总之,对于VaR 与TVaR 测度方法的使用,需要针对我国股票市场的实际,扬长补短,组合运用,以提高股票市场风险测度的科学性、精确性,进一步防控金融风险,促进经济社会高质量发展。
猜你喜欢
数学物理学报(2022年3期)2022-05-25
数学物理学报(2022年2期)2022-04-26
数学物理学报(2020年4期)2020-09-07
数学年刊A辑(中文版)(2020年2期)2020-07-25
投资有道(2018年6期)2018-07-10
股市动态分析(2018年21期)2018-06-07
沈阳工业大学学报(社会科学版)(2018年1期)2018-03-07
股市动态分析(2017年40期)2017-11-01
股市动态分析(2017年22期)2017-06-19
股市动态分析(2016年32期)2016-10-25
