
基于深度卷积神经网络的智能试卷合分系统
2022-10-10 08:25荣宪伟
哈尔滨师范大学自然科学学报 2022年3期
何 苗,荣宪伟
(哈尔滨师范大学)
0 引言
纸质试卷是一种传统的考试载体,它的优点是使用方便、成本低廉,在小学、中学到大学的不同层级、不同种类的教育中都占据了主流的位置,比如中小学生的各类考试,师范类高校的专业师范认证及评估工作,都需要应用纸质试卷,并把所得分数作为其评判标准[1].然而,在纸质试卷的应用中,往往要用人工进行手写判分、合分.最常用的合分方法是把试卷的各个题目的得分对应书写到试卷卷头的分数栏中,然后依赖人工对各个分项的分数进行整合,在合分试卷量较小时,采用心算进行人工合分容易出错;在合分试卷量较大时,借助计算器或计算机又要输入每题分数,费时费力.因此该文设计实现了一个基于Mask R-CNN[2]与LeNet-5[3]相结合的卷积神经网络的智能纸质试卷合分系统,可识别含有小数点的分数,降低了传统依赖人工对合分的工作量,并减小了合分误差.
1 相关工作
智能试卷合分系统可以分为表格检测和手写数字识别两个部分,表格检测是为了定位分数栏在图片中的具体位置,手写数字识别用于对检测出来的分数栏区域的字符进行识别,最终得出图片中的各题分数之和.
1.1 表格检测
表格检测算法分两种,一种是采用传统的方法进行检测,另一种是基于深度学习方法进行检测.Chandran 等学者提出了一个以通过水平和垂直方向为线索的树的形式表示表格结构的系统[4].Kieninger等学者提出了一种采用自底向上的方法对所采样的图像进行连通分支分析的T-Recs系统,根据定义的规律进行合并,得出逻辑文字块[5].Gilani和 Sun等学者在Faster R-CNN网络框架上进行了改进,对于表格检测有着较好的效果[6-7].Siddiqui 等学者[8]提出了通过应用可变形卷积技术在Faster R-CNN 以及 FPN(Feature Pyramid Networks)网络框架上完成表格检测任务[9].在实际的复杂场景中,具有良好的鲁棒性.
1.2 手写数字识别
分析人工进行合分试卷的过程,关键在于,合分者可以准确地辨识出由试卷评阅人人工填写的分数栏中的各题目分数,其本质即为手写数字识别的过程.手写数字识别的基本原理是将输入样本数字与相应的标准样本数字相匹配,以最大相似的样本数字为识别结果.传统的数字识别有SVM、BP神经网络、MRFSE、聚类分析、运动图像等算法[10].在进行识别前,需要对样本图像进行归一化,平滑去噪,字符切分,二值化,笔画细化,特征提取,重构模型等统一的预处理,同时由于具有大量的网络训练参数,导致了识别过程的耗时长且结构复杂.而卷积神经网络的结构使得它更贴近于生物神经系统,使其具有迅速学习和良好记忆的能力.为了达到更好的识别效果,通过对卷积神经网络、VGG网络与LeNet网络等的改进成为了当前手写数字识别领域所研究的热点内容[11].
2 基于深度学习的试卷合分系统设计
虽然现阶段手写数字识别的识别率可以高达98%以上,但识别试卷卷头手写分数的识别率并不是特别理想,尤其是在识别含有小数点的手写分数时,该文方法是利用摄像头实时获取试卷卷头分数栏信息,实现带有小数点的手写分数的识别与各题分数求和功能,且能够适应不同种类的试卷.该系统首先采用摄像头对试卷进行实时采样,利用Mask RCNN对采样后的图像进行表格的定位检测,并对其进行去噪、灰度化、二值化、形态学处理等预处理工作,然后对预处理后的图像的字符进行外轮廓的检测,获取外轮廓的面积后对字符及小数点进行分割,并利用LeNet5卷积神经网络对分割出的字符进行识别,最后将每道题识别出来的分数与通过函数计算得到的总分显示在GUI界面中.该方法适用于不同试卷分数栏手写分数的求和,并取得了较好的实验效果.
该文所设计的系统结构框图如图1所示,后续部分会对每个阶段进行详细的描述.

图1 系统结构框图
2.1 图像采集
图像采集利用Pycharm中的OpenCV库与PyQt5相结合的方式实现打开读取显示电脑摄像头实时拍摄画面.点击按钮,开启预览窗口,对试卷进行瞬时抓拍,并将所收集到的图象进行存储,或将已在其他设备上采集的图像直接存储到相应的文件夹中,在系统中需要采集的对象为任意尺寸的手写试卷得分栏,如图2所示.
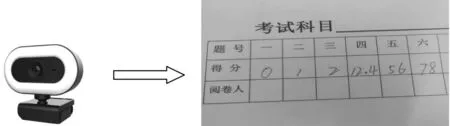
图2 摄像头实时采集对象图像
2.2 表格检测与定位
随着深度学习在计算机视觉领域中的发展,有一些研究学者参考了图像任务中的语义分割方法,使用全卷积神经网络(Fully convolutional networks, FCN)算法来进行表格结构识别[12],分别对表格的列和行进行分割,然后通过后处理分析行列的重叠区域,恢复每一个单元格的结构.后面通过结合FCN的层级优化方法[13]使得FCN在表格类数据上表现得更好,得到了不错的结果.进一步地,结合目标检测的SSD[14]和YOLOv3[15]算法,使得基于FCN的系列算法可以在表格结构识别上得到不错的效果.
该文采用了Mask R-CNN卷积神经网络对采样后的图形进行表格的检测与分割.Mask R-CNN在Faster RCNN的基础上进行了改进,采用ResNet-FPN的架构进行特征提取,并在原来的基础上多加了一个Mask预测分支.结构框图如图3所示,Mask R-CNN在有效检测目标的基础上,同时输出高质量的实例分割mask,用RolAlign代替了Faster R-CNN中的RoIPooling,由于RoIPooling使用取整量化,使特征图RoI映射到原图RoI的空间不对齐明显,从而导致误差;常规的ROI Pooling的反向传播如公式(1)
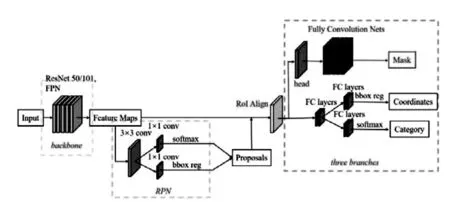
图3 Mask R-CNN结构框图
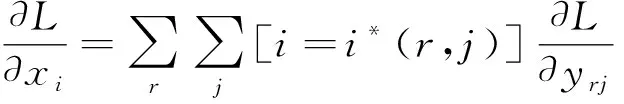
(1)
从式(1)可知,只有在池化后,任意一个点的像素值均使用当前点xi的像素值(即符合xi=i*(r,j)),才可以在处回传梯度.式(1)中,xi表示池化前特征图上的像素点;yrj表示池化后的第r个候选区域的第j个点;i*(r,j)表示点yrj像素值的来源.
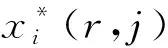
(2)
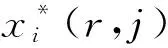
该文采用的方法为先在开源的COCO数据集上进行预训练,然后通过迁移学习的方法在TableBank数据集上进行训练,最后对表格进行分割,分割的结果只有像素区域的行和列坐标,然后需要对这些坐标范围进行重叠区域的分析,行和列的重叠区域即为一个单元格,最后得到了单元格的集合,为了得到单元格的坐标范围,需要把单元格集合按从左到右、从上到下的顺序进行排序,从而得到每一个单元格所属行列的值,即可实现表格的检测与定位,输出结果如图4所示.
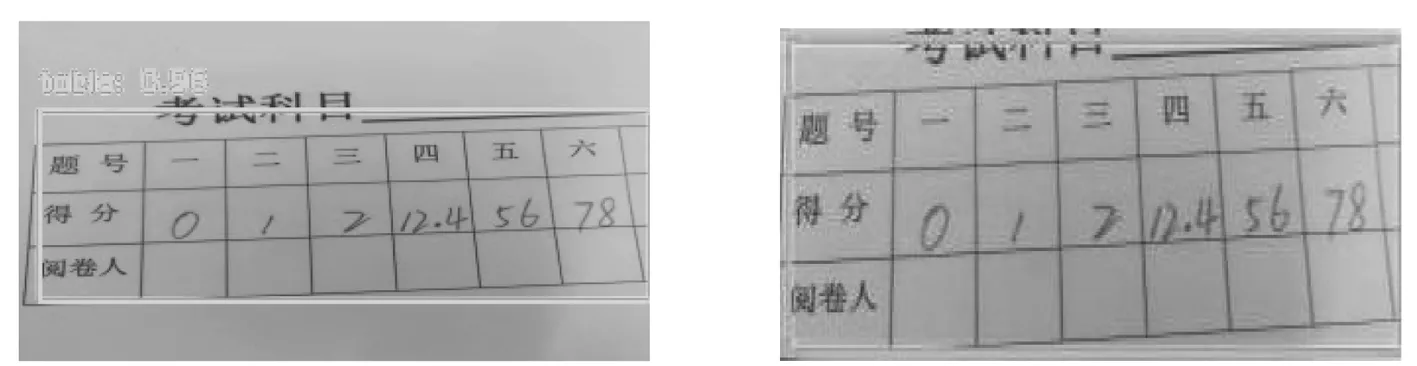
图4 利用Mask R-CNN对采样图像进行表格检测与定位结果图
2.3 字符检测
通过摄像头所采集的图像不乏会存在噪声、光照等干扰的情况,为了提高图像质量及识别精度,该文采用高斯滤波、中值滤波等预处理算法对图像进行去噪处理.然后利用OpenCV库中的RETR_EXTERNAL函数检测外轮廓,通过RETR_CCOMP函数建立两个等级的轮廓,分别为:上面一层为外边界,里面一层为内孔边界信息.如果内孔内还有一个连通物体,那么将这个物体的边界至于顶层.其次,将图像进行灰度化处理和采用自适应阈值二值化的方法得到二值化图像,最后再将二值化的图像进行形态学处理,目的是为了消除二值化图像后的小黑点,填充物体内细小空间、连接邻近物体、平滑其边界,同时并不明显改变其面积,效果如图5所示.
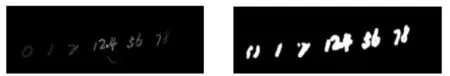
图5 字符检测后形态学处理图像
2.4 字符分割及小数点识别
图像分割是图像处理中的关键技术,它是从分数栏中的手写数字提取出有效特征的前提,是实现分数精确识别的关键.因此,图像分割及小数点的识别过程对于系统后续的识别效果具有重要意义.
该文提出的具体分割操作为针对二值化后的图像再次进行字符外轮廓的检测、获取外轮廓的面积并获得轮廓外接矩形的四点坐标后绘制外接最小矩形,之后进行数字分割,为了使分割后的数字排序与原图像保持一致,该文使用了将上述的外接矩形的四点坐标存入一个列表内,然后根据x轴坐标储存位置的索引,按大小顺序排列,这样存入的坐标就是手写数字的实际顺序保存的方法.然后根据矩形四点坐标在经过预处理后得二值化图像进行切片,得到要的切片图像,之后进行小数点的识别,根据经验,由于小数点的外接轮廓面接要远远小于其他数字的轮廓面积,数字中1是面积最小的,但是其面积也没有小于其他数字面积太多.因此设置判断,若满足5*min_area < max_area那么这个分割图像必然是小数点,这里也采用x轴方向顺序来保存面积,然后获得满足条件的小数点的索引,若不满足则返回.分割结果如图6所示,小数点完美分割并识别出来.
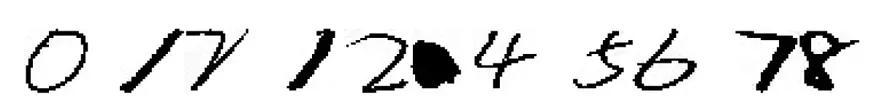
图6 字符分割效果图
2.5 手写数字识别
现阶段,在手写数字识别上已经有许多研究成果,例如模糊逻辑方法[16]、粗糙集方法[17]、统计方法[18]、梯度与曲率方法[19]等,该文采用LeNet-5卷积神经网络对分割后的字符进行识别,该网络由输入层,卷积层,池化层,全连接层,输出层组成.LeNet-5网络结构如图7所示.
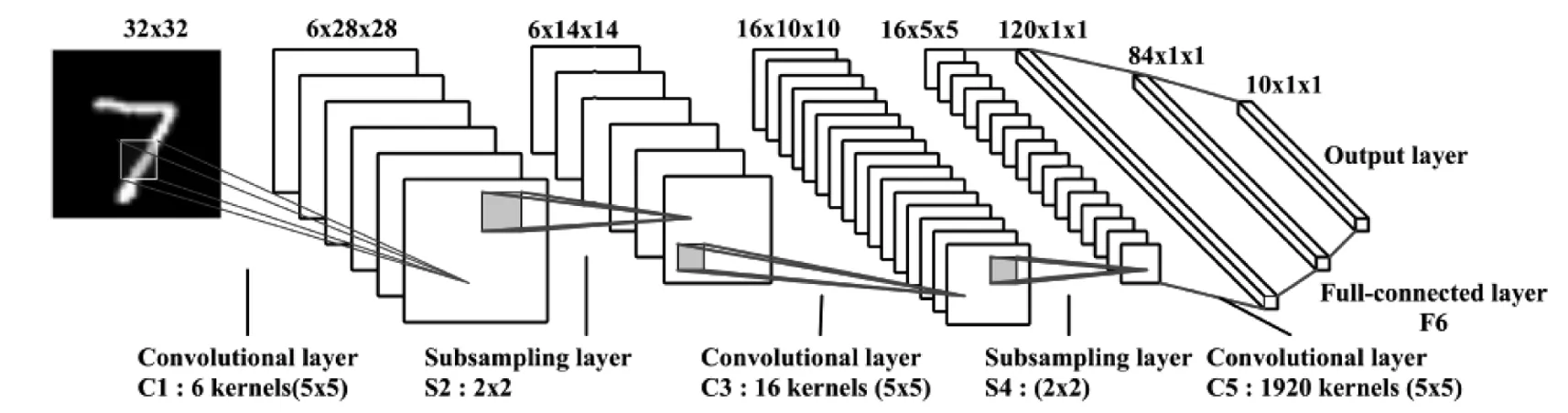
图7 LeNet-5网络结构图
首先进行卷积,卷积过程能有效降低参数的数目.卷积层1使用6个大小为5×5的卷积核对输入层进行卷积运算,池化层1采用最大池化,把池化的大小定为2×2.池化后得到了6个14×14的特征图,并把其作为下一层神经元的输入.通过池化可以降低来自卷积层的特征向量维数,从而减少后续的卷积层处理复杂性.卷积层 2 用大小为5×5的16种不同的卷积核.池化层2的池化大小为2×2,仍采用最大池化.最后输出16个5×5的特征图,神经元也减少至16×5×5=400个.全连接层1继续用5×5的卷积核对S4层的输出进行卷积,卷积核数量增加至120.这样该层的输出图片大小为5-5+1=1,最终输出120个1×1的特征图.这里实际上是与池化层2进行了全连接.全连接层2与上一层进行全连接,输出84张特征图.输出层与上一层全连接,输出长度为10的张量,代表所抽取的特征属于哪个类别,最终确定最大相似概率的数字.以上则是基于LeNet-5模型框架对分割后图像进行识别的过程.
2.6 分数显示
该系统具有可识别不同题数的功能,6~8题均可,程序运行后系统将会把每道题的分数识别并显示出来,并在总分处显示出最后得分.实现方法为:在 GUI 设计中,在 GUI 界面上放置3个按钮,分别命名为“打开本地图片”、“打开摄像头”、“处理分析并计算”,9个文本框用来显示识别出来的分数,分别命名为“一”、“二”、“三”、“四”、“五”、“六”、“七”、“八”、“总分”.效果如图8所示.
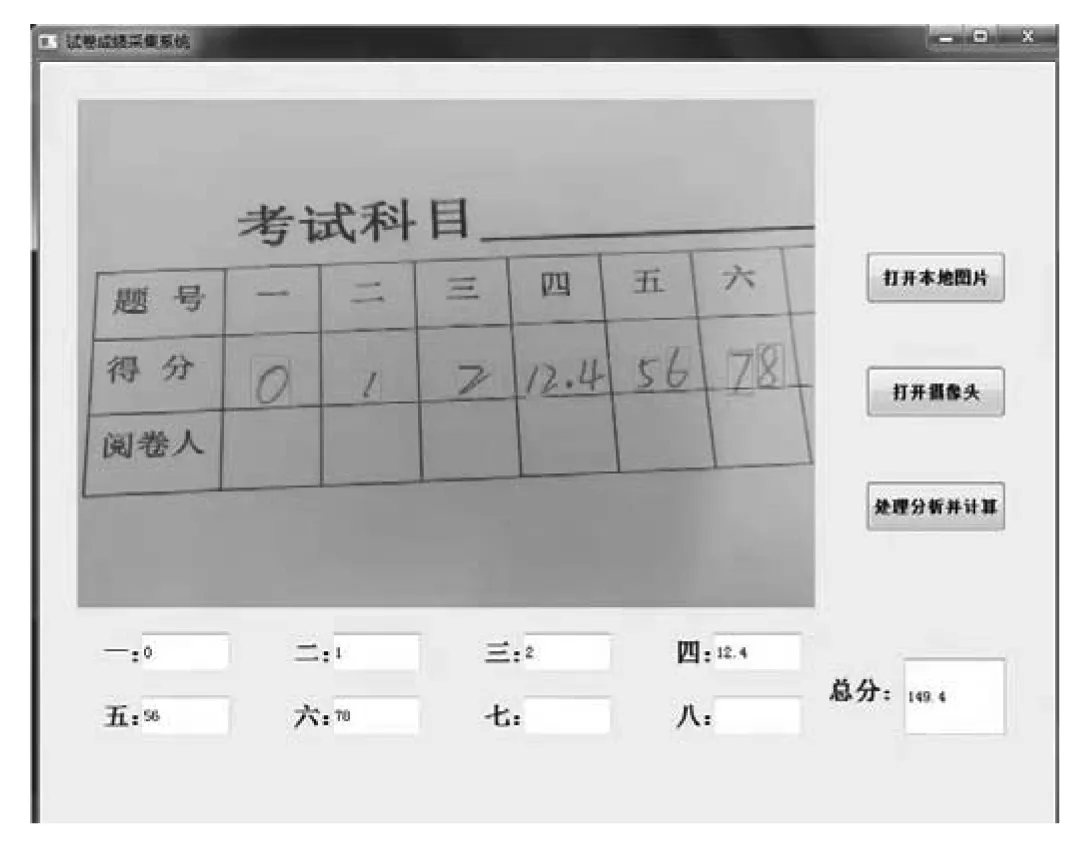
图8 识别后的系统界面
3 实验结果与分析
为了评估本系统可进行试卷分数识别的有效性,进行了一系列实验.
3.1 分数栏检测
(1)数据集.实验数据集来源于Table Bank 数据集[20],Table Bank是一个基于图像的表格检测和识别数据集,它基于Internet上的Word和Latex文档并利用新颖的弱监督机制来构建的,包含417K高质量标签表格.Table Bank数据集总共包含417,234个高质量标记的表格以及它们在各个领域中的原始文档.Table Bank数据集具体数据内容见表1.

表1 Table Bank数据集内容
实验随机从Word和Latex文档中各自采样2000张文档图片作为表格检测的数据集,其中1000张图片用于训练、1000张图片用于测试.每张采样图片至少包含一张表格.
(2)评价指标.检测模块使用目标检测中较常使用的准确率(Precision)、召回率(Recall)和F1值(F1-measure)进行评估性能.
(3)该文检测模块与其他目标检测算法在Table Bank数据集上的实验对比结果见表 2,由对比结果可知,该文方法的准确率和召回率明显高于其他算法.

表2 不同表格检测算法的检测结果对比
3.2 字符识别
(1)数据集.该文选取 MNIST 中的完整数据对LeNet-5模型进行训练和测试.MNIST数据集由7万张黑底白字的手写数字图片构成,在该文实验中,把6万张图片作为训练集,1万张图片作为测试集,1万张图片作为验证集.Batch-size设为200,lr设为0.01,epoch设为40.图9为网络的验证集loss曲线.
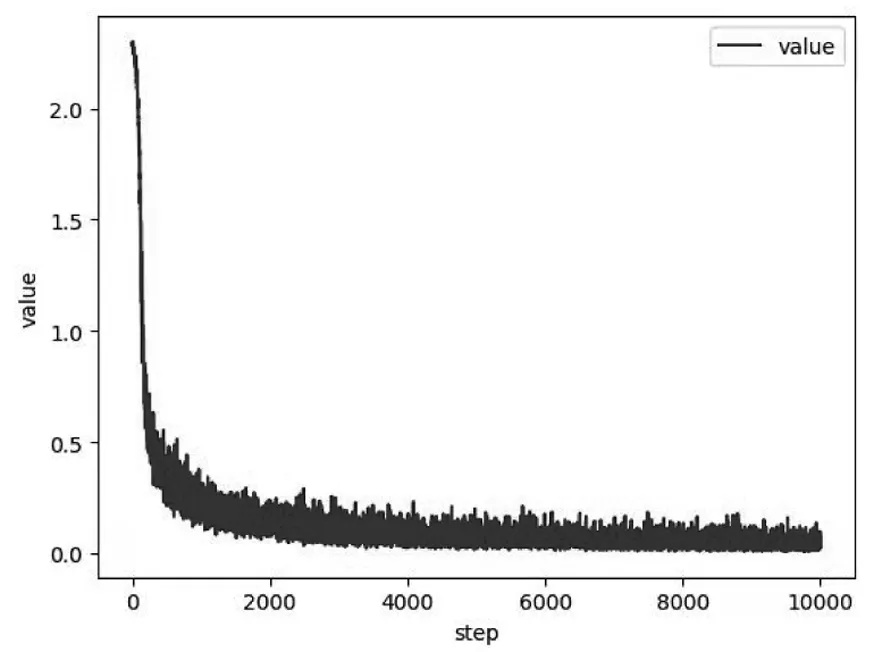
图9 验证集loss曲线图
(2)为了验证该文识别小数点及手写数字的准确率,采用MNIST数据集分别与文献[21]的算法进行对比分析,实验结果见表3.
由表3可知,该文算法的准确率较高.

表3 不同字符识别算法的结果对比
3.3 系统实现
该文采集了32份带有小数点的不同科目的试卷登分表的图像.并在Win7操作系统、Inter(R) Core(TM) i3-4170 CPU,3.70GHz,4.00GB内存的计算机上运行.利用该系统对这32份试卷的分值进行了识别并合分.并与文献[22-23]进行对比分析,结果见表4.

表4 分数识别数据对比结果
该文算法对32份试卷识别的平均准确率为94.87%,见表4,与文献[22-23]进行对比,准确率高,其5.13%的错误率主要来源于试卷分数栏中的手写数字不规范、数字与数字之间有黏连等情况.
4 结论
该文利用Mask R-CNN和LeNet-5模型对设计了一个智能试卷合分系统.通过Mask R-CNN对分数栏定位,使用LeNet-5模型进行手写数字识别,实验结果表明该文使用的方法能够有效地实现带有小数点的纸质版试卷的分数合成,且检测的平均正确率为94.87%.相比传统的试卷分数识别算法,既可以准确识别分数栏表格,也可以识别出带有小数点的手写分数,能够满足在教学中一般实际应用的需要.
然而该系统仍有许多需要改进的地方,如针对黏连数字的分割与识别,数字书写不规范的情况仍存在错误识别的情况,这将是未来的重点研究方向.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
故事作文·低年级(2021年12期)2021-12-21
上海师范大学学报·自然科学版(2019年5期)2019-12-13
文苑·经典美文(2019年8期)2019-08-06
中国新通信(2017年9期)2017-05-27
前卫文学(2016年3期)2016-07-01
学苑创造·B版(2015年8期)2015-07-02
党建文汇·上(2014年8期)2014-10-27
数学大王·中高年级(2009年5期)2009-05-31
