
Emoji自然语言处理综述
2022-10-10 09:25杨暑东
计算机应用与软件 2022年9期
杨 暑 东
(大连理工大学 辽宁 大连 116024)
0 引 言
与表情有关的数字符号包含但不限于表情包(sticker)、颜文字(emoticon)和绘文字(emoji),本文研究的对象是emoji。
1982年前后日本用户通过普通文字字符的组合将表情融合进枯燥的文本中,至此诞生了颜文字,kaomoji是日文“顔文字”的英文假名,英文意译为emoticon,是emotion icon的缩写,颜文字至今还在广泛使用,如:对不起“orz”,大长腿的人说对不起“or2”,大头的人说对不起“Orz”。

20世纪各大科技公司emoji编码和视觉渲染的差异,导致了乱码或emoji信息孤岛[3]。为解决这一问题,Unicode在2010年6.0版本中首次引入了emoji,即对emoji的编码进行了标准化,开启了emoji世界语的大门。在2020年Unicode emoji 13.0版本中共有3 304个emoji,这样无论用户在哪使用任何设备都可以快速输入emoji,同时传达思想和情绪。emoji作为网络时代的交流符号,丰富了网络交流语言。
1 Emoji理论基础
1.1 Emoji语义特点
Lu等[4]认为emoji与词典中定义的自然语言相比,emoji本质上是符号的自由组合,没有固定的词法和语法,因此emoji的自由理解和自由使用给数据分析和数据挖掘带来了相当大的挑战。该文献认为视觉化的emoji没有语言障碍,因此可在不同国家用户之间进行交流。受文化和年龄代际影响等,不同用户对同一emoji可能会出现不同的理解与使用行为。emoji的流行程度通常遵循幂律分布,验证了9.3%的emoji占总使用量的90%。Coman等[5]认为emoji的使用高度依赖于人类用户对emoji视觉渲染的理解。Unicode emoji在不同平台的视觉渲染不一致[6];即使单个emoji渲染一致,但对零宽连接符的处理不一致的话,所综合出来的emoji组合也是不一致的;用户或平台对颜色、肤色等变换符的处理可能不一致[7],因此综上等原因会导致广泛存在的跨平台沟通偏差问题。
Emoji的广泛采用是普适计算的一种有趣实践。Evans[8]认为非语言暗示是一种情感表达,但是在传统数字通信中,这些提示丢失了,这可能导致通信偏差,而emoji恰恰履行了这个功能。emoji甚至可以反映作者真正的情感极性,如果丢弃emoji,那么情感极性可能会判断出错,例如:“受疫情影响,我不能返校了”,根据emoji综合判断作者其实是正面情绪,但如果丢弃emoji则可能判断是中性或负面情绪。emoji可以作为自然语言处理(Natural Language Processing,NLP)技术的补充,通过将emoji用法与其他上下文信息进行综合,更加准确地了解用户的偏好,提高网络信息处理的准确性。Pavalanathan等[9]研究表明,在微博领域,后起之秀emoji有逐渐取代颜文字之势。
1.2 实际应用
Emoji自然语言处理在很多领域都有了实际应用,用于提高网络信息处理的准确性[10]和互联网用户体验[5]。
情绪识别。Lu等[10]对GitHub网络社区的语料库使用词嵌入、SentiStrength-SE等工具来计算emoji的情感得分与情感分布,进行情绪识别,与不使用emoji自然语言处理相比更有助于优化网络社区的迭代过程,以及提高Github上的协作效率。
攻击性言语检测。Hettiarachchi等[11]将emoji信息集成到胶囊网络中,用于检测攻击性内容,与纯文本自然语言处理相比,结合emoji的处理在识别目标侮辱、非针对性侮辱等攻击类型,以及识别个人、组织等攻击目标的应用上性能更佳。
Emoji预测。Coman等[5]横向对比支持向量机、fastText、长短时记忆循环神经网络、卷积神经网络四种emoji模型,根据推文来预测最相关的emoji,有助于软键盘输入法的优化。Zhang等[12]使用迁移学习模型预测推文最有可能的emoji。
舆情监控。Zhao等[13]将95个emoji对应到生气、厌恶、喜悦和悲伤4个类标签,利用快速朴素贝叶斯分类器对包含350万个标记的微博语料进行训练,并且用增量学习法来处理情感转移和新词问题,进而实现更精准的微博实时舆情监控。
反讽检测。反语(Irony)、讽刺(Sarcasm)的修辞方式给NLP带来了极大的复杂性,传统情绪识别难以识别反讽语料中的实际情感,Singh等[14]利用emoji2vec将emoji的官方释义来替换emoji,对推文进行反讽分析。Gupta等[15]将人工神经网络作为分类器来训练emoji反讽检测模型。
Emoji生成。在生成模型(Generative Model)大家族中,有两个家族特别著名,分别是变分自编码器(Variational Auto Encoder,VAE)和生成对抗网络(Generative Adversarial Networks,GAN)。Yamaguchi等[16]采用条件VAE基于文本输入来自动生成emoji。Radpour等[17]对82种常用面部emoji进行词嵌入,用深度卷积GAN生成emoji组合。
协同过滤的预处理。Seyednezhad等[18]通过emoji与词汇的双模网络方法来识别emoji的潜在模式,从emoji使用习惯识别用户,用于改善后端的协同过滤推荐算法。
人机对话系统的用户体验优化。传统的智能问答等人机对话系统的训练用语料集一般是普通字符文本[19],这在判断带有emoji的对话时可能产生问题。引入emoji处理机制可以优化智能客服系统[20]、聊天机器人[21]等的用户体验。
1.3 常用数据集
含有emoji的数据集正在逐渐涌现,以下是一些常用的emoji数据集或语料库。
(1) Unicode emoji标准库,目前最新版本是2020年的Unicode emoji 13.0版,共有3 304个emoji。
(2) EmojiNet Datasets是最大的机器可读的emoji语义库[22]。在没有附加严格语义的情况下,emoji可根据其上下文具有不同的含义。类似于自然语言处理中的词义消歧任务,机器也需要对emoji进行消歧。该数据库的目标是构建工具和算法以提高emoji在机器中的可识别性。
(3) EmojifyData-EN语料库,包含1 800万条带有emoji的推文,并对@、#Hashtag和URL等隐私数据进行了脱敏预处理。
(4) COMP90049 2018SM1 Project 2语料库是内嵌在Kaggle竞赛中的一个小型emoji语料库,包含12 159条带有emoji的推文,含有作者ID、emoji和推文文本等信息。
常用数据集信息如表1所示。
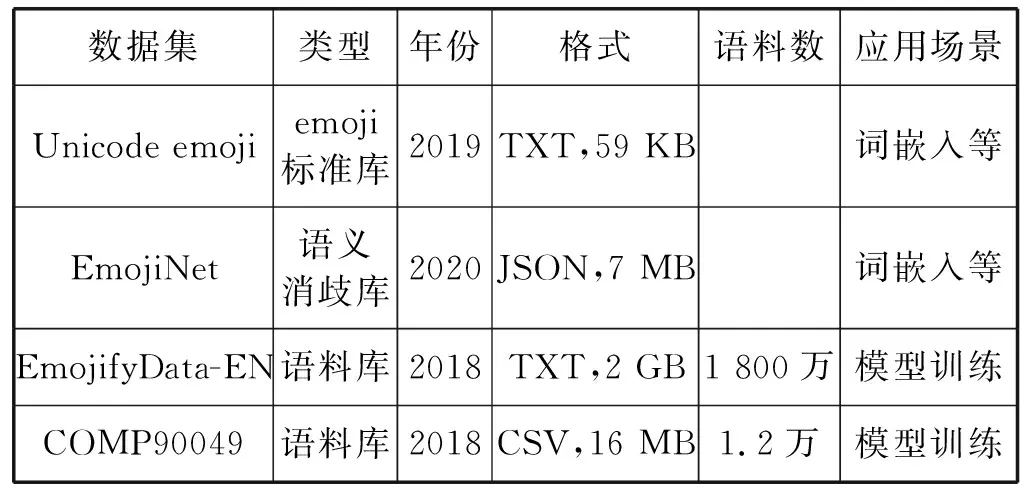
表1 常用emoji数据集
1.4 偏差模型
从emoji诞生、发展到成熟的进程中,NLP在处理emoji的手法上也在逐渐发展和成熟。最原始的处理方法是将emoji视为停用词然后舍弃;之后出现了文本替代法,就是将emoji的Unicode官方解释替代emoji本身,即语料经过替代的预处理之后,均是普通的文字;Wijeratne等[22]认为同一个emoji在不同上下文中用于表达不同感觉的事实以及全世界所有语言都使用了emoji的事实使得将传统的NLP技术应用于它们尤其困难,于是出现了emoji词嵌入、emoji神经网络模型和emoji社会网络模型等处理方法。
人工智能的愿景之一是构筑一个没有偏差的理想世界,然而Caliskan等[23]通过实证研究发现机器学习能从语料中习得类似人类的偏见,所以意识到偏差的普遍存在才能对其进行有效的补偿。emoji自然语言处理技术的发展史其实也是减弱emoji偏差的历史,与Web偏差类似[24],emoji偏差也存在着级联循环,抽象出emoji的偏差结构是解决偏差问题面临的首要挑战,图1展现了不同类型的偏差如何影响emoji的使用。用户行为偏差源自不同时代不同地域用户的上网行为所产生的隐形偏差,导致用户在Web上、不同操作系统上、不同软件上行为的细微差异;不同操作系统、不同软件的emoji视觉渲染会导致emoji渲染偏差[25];这些有偏的数据以及对数据的有偏采样会导致采样偏差;对emoji预处理的差异会导致预处理偏差;不同的分类模型会产生不同的算法偏差;动态的软键盘设计差异和人机界面设计的差异会导致人机交互偏差;信息“茧房效应”会导致自选择偏差;这些积累后的偏差会产生新内容或使用记录,进而级联反馈到Web,再产生不同类型的二阶偏差。
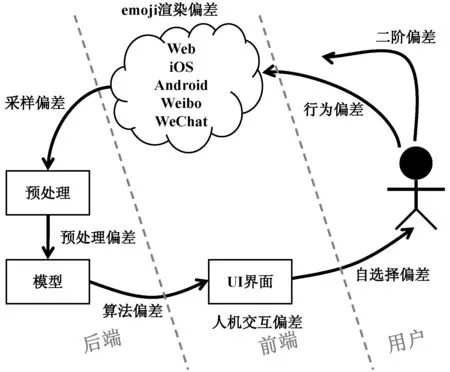
图1 emoji偏差模型
系统设计者只能解决系统后端和系统前端的一系列偏差,而如何减弱包含自选择偏差和行为偏差在内的用户层面的偏差不在本研究范围之内。与系统后端偏差相比,前端偏差更加宏观,因为一般而言,硬件、操作系统等对于系统设计者而言属于不可控因素,所以前端偏差的可观可控性不如后端偏差。综上原因,学界的研究热点主要集中在如何弱化系统后端的偏差,包括采样偏差、预处理偏差和算法偏差。目前主流的门类包括简单粗暴的文本替代法、机器学习、端到端的深度学习,以及另辟蹊径的社会网络分析法。
2 Emoji自然语言处理流程与偏差补偿
Emoji自然语言处理流程大致分为采样、预处理、和分类三个阶段,各阶段与emoji偏差链路的映射关系如图2所示。
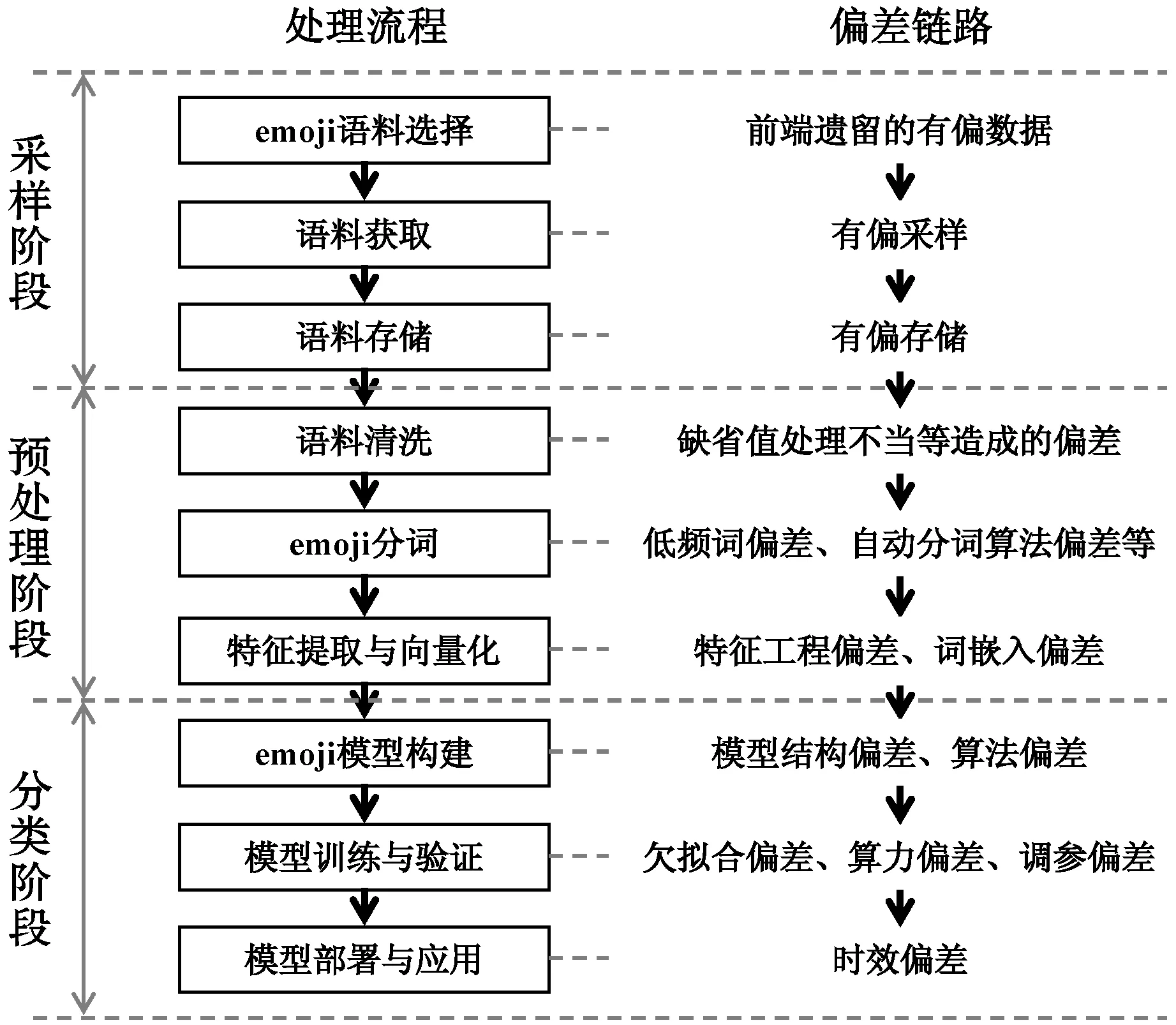
图2 emoji NLP流程与偏差链路映射关系
2.1 采样阶段
采样阶段的emoji自然语言处理一般包括语料库选择、网络爬虫和数据存储等。语料库选择的恰当与否直接关系着数据是否有偏。
在以下因素的共同作用下,不同采样策略会从源头产生不同采样偏差,进而影响语料处理的最终结果,比如:互联网用户能力水平不一致;互联网上语料质量参差不齐;互联网存在大量的虚假和冗余内容;时间序列会影响语料特征等。
当没有适合的开源emoji语料库时,一般需要通过网络爬虫工具进行爬取才能取得[26]。受网站反爬取机制的影响[27],网络爬虫所爬取的内容已经是有偏采样的语料。采样策略与语料获取对应于偏差链路的采样偏差。
数据存储涉及编码、数据库等问题。Unicode于2010年发布了emoji,同年MySQL数据库在5.5版本追加了utf8mb4编码。utf8mb4是对utf8的一个扩展,全面支持emoji。所以为了让爬取出的语料完整地存入数据库,应当更换字符集为utf8mb4。当数据库配置不当时,有可能导致emoji的有偏存储。
2.2 预处理阶段
预处理阶段的emoji自然语言处理一般包括对语料进行语料清洗、分词、特征提取和向量化等,此阶段产生的偏差对应于emoji偏差模型的预处理偏差。
语料清洗。原始语料中可能存在不一致、不完整等异常数据或敏感的、对结论无影响的隐私数据、重复出现的冗余数据。异常数据和冗余数据会影响后续处理的执行效率和效果,甚至对结果产生偏差,而隐私信息会引起不必要的麻烦,所以预处理阶段首先要进行语料清洗。常见的清洗手段是通过正则表达式匹配,编写脚本按规则整理内容,具体包括去重、对齐、删除和标注等。
分词。由于emoji没有固定的词法和句法,比如:词性可根据上下文变换;emoji出现的位置不固定;多emoji连用或单一emoji重复使用等。以上导致分词变得复杂,词典维护难。因此包括正向最大匹配法、逆向最大匹配法、双向最大匹配法等在内的依赖于词典的规则分词方法不适用于emoji分词。随着大规模语料库的建立,基于统计的分词方法逐渐成为主流,与规则分词方法相比,统计分词无须人工维护词典,能处理歧义和未登录词,但分词效果依赖于训练语料的数量和质量,且对算力要求较大。
特征提取与向量化。对于采用非深度学习的模型,特征工程决定了后续模型性能的上限,而后续模型的优化只是在逼近这个上限而已。去停用词的策略根据分析目的不同而有所不同,比如感叹号、语气词一般是被当作停用词删掉的,但在情感分析场景下,emoji、感叹号和语气词等是应当被保留的。词性标注(Part of Speech,POS)环节对于某些自然语言处理来说是不必要的,比如文本分类,但对于情感分析、推理等应用场景,一般还需要进行词性标注、命名实体识别(Named Entity Recognition,NER)等处理环节。emoji位置等词序特征是有助于分析的,所以实务中一般不采用去除词序关系的词袋模型(Bag of Word,BOW),而是采用向量化模型,常见的实例有独热编码(One-Hot)、word2vec、emoji2vec、doc2vec等。其中独热编码原理最简单,适合对微型语料进行处理。word2vec主要包含两个实例模型:Skip-Gram和连续词袋模型(Continuous Bag of Words,CBOW),以及两种高效训练方法:负采样(Negative Sampling)和层次Softmax(Hierarchical Softmax)。emoji2vec[28]是对word2vec的一种补充,emoji2vec直接从词典或官方释义进行词嵌入,嵌入到与word2vec相同的高维空间。Illendula等[29]认为外部知识的使用可以提高NLP任务的准确性,利用外部知识来学习单词嵌入,从而在单词相似性和单词类比任务方面提供了更好的准确性,emoji嵌入可以增强emoji预测、emoji相似度和emoji语义消歧任务的性能。Ramaswamy等[30]验证了使用现成的词嵌入模型进行预训练可以大大加快emoji模型的收敛速度。另外,emoji使用频率服从长尾分布,属于不平衡分类,Ramaswamy等还验证了联邦学习计算范式对稀疏数据和不平衡分类数据有更好的适应性。emoji在不同主题场景下,其含义、词性可能发生变化,因此主题提取有助于提高NLP任务的准确性,常见的主题模型有采用奇异值分解(Singular Value Decomposition,SVD)来蛮力破解的LSA算法、基于词共现分析的LDA算法等。
2.3 分类阶段
这一阶段的emoji自然语言处理一般包括模型构建、模型训练和模型验证,此阶段产生的偏差对应于emoji偏差模型的算法偏差。模型训练的目标是防止过拟合、欠拟合和提高泛化能力。
本阶段的难点主要有:在主题方面,同一个句子其语义根据会话的主题而有所不同,Seyednezhad等[18]基于多主题方法探讨emoji的情感及其类别,其认为emoji位置、情绪属性、频率、语义四者之间具有相关关系。在时序方面,Barbieri等[31]认为时间序列信息能影响emoji的解释和预测,使用时间信息可以显著提高某些emoji的准确性。在隐私保护方面,Ramaswamy等[30]采用联邦学习的策略,与服务器训练的模型相比,联邦模型显示出更好的性能,同时将用户数据保留在其设备上。在反讽处理方面,反讽修辞方式与字面意思无关,需要捕获更深层次的语义信息[32],另外权威的反讽数据集较少且规模不大,所以训练难度较大。在上下文处理方面,由于在线会话中以短文本为主,文本的长度限制了对上下文重要信息的捕获。
本阶段可能产生的偏差主要有:因模型中层次顺序结构构建不当所导致的模型结构偏差;因梯度下降等优化算法配置不当所导致的算法偏差;因过度简化模型所导致的欠拟合偏差;因算力不足而影响模型性能的算力偏差;因超参数过多不能兼顾所导致的调参偏差;因模型训练时间过长而不适用于当下实际情景的时效偏差等。
2.4 偏差补偿策略
对上述流程中各个环节的偏差,从整体考虑有如下偏差补偿策略:
策略一,算力提高策略。提高算力会减弱分类阶段的算力偏差、调参偏差、时效偏差,而且只要提高算力就能起到立竿见影的补偿效果。此策略适用于项目时间紧迫且人力资源投入紧张,但财务预算富余的情景。
策略二,端到端策略。即通过多层神经网络规避人工处理环节,减少偏差链路的长度。比如采用深度学习的方式来规避人工特征工程的环节,巧妙避免人工特征工程偏差。
策略三,外包与众包策略。比如:基于已有的、成熟的词嵌入模型进行训练会提高准确率,减少词嵌入偏差,同时会节省时间;联邦学习可以在不交换数据的情况下共同建模[30],避免了有偏采样。
3 模型对比
3.1 模型分类
Kopev等[33]按照应用原理将分类模型分为四种,分别为线性分类器、非线性分类器、深度学习模型和集成模型。近几年出现了社会网络模型分类器,因此共分为五种类型:
线性分类器。本类模型是参数的线性函数,因此一般用于处理简单分类。主要有朴素贝叶斯分类器(Naive Bayes)、逻辑回归模型(Logistic Regression)、线性核的支持向量机等。本类模型在实务中已不多见,因为线性分类器的性能对特征工程的依赖程度较大,会放大特征工程偏差。
非线性分类器。本类模型是线性分类器的升级版,模型分界面可以是曲面或者是超平面的组合。典型的非线性分类器有决策树、随机森林和非线性核的支持向量机。
深度学习模型。深度学习是端到端偏差补偿策略的有效实践。含有多个隐层的感知器就是一种深度学习结构,该结构通过组合低层特征形成更抽象的高层来表示特征。神经网络可以视为能够拟合任意函数的黑盒,只要训练数据足够多,当给定特定的输入,就能得到预期的输出。Encoder-Decoder框架可以看作是处理由一个句子生成另外一个句子的通用处理框架,如图3所示。句子对

图3 Encoder-Decoder框架
社会网络模型。主要分为emoji-词汇双模网络、emoji共现网络和ego network三个子类别。
分类器集成。是以上分类器的组合,与包含于其中的单个分类器相比,集成后的分类器具有更好的泛化性能。主要的集成方式有投票、平均和排名平均等。
3.2 模型介绍
(1) 支持向量机。支持向量机(Support Vector Machine,SVM)的本质是特征空间中最大化间隔的线性分类器,一般仅限于线性可分问题的二元分类,比如emoji情感极性判断。SVM对缺失数据比较敏感,实务中对语料的预处理要求比较严格。SVM属于监督学习模型,语料库需要事先进行人工标注,SVM对计算机算力要求较高,一般仅能处理样本量较小的语料库,因此综上SVM的应用场景比较受限。另外,为规避直接在高维空间进行计算,SVM引入了核函数,拥有高斯核的SVM可以处理非线性可分问题;二叉树结构的SVM级联可以处理多元分类问题。
SVM在特定场景下与深度学习模型性能相当,比如Çöltekin等[34]证明了在没有预训练词嵌入,也没有训练词性标注和句法分析(Syntax Parsing)的条件下,将bag of n-grams作为特征,根据推文来预测高频emoji,在这种场景下SVM比神经网络更优秀。
(2) 逻辑回归。逻辑回归(Logistics Regression)的本质也是监督学习线性分类器,原理简单,但容易出现过拟合。该模型假设条件较多,比如因变量为二分类的分类变量或某事件的发生率,并且是数值型变量;残差和因变量都要服从二项分布;各观测对象间要相互独立;实务中样本数量如果不到变量数量的10倍时预测性能不佳。因此综上原因近年来逻辑回归在emoji自然语言处理中应用较少。Alhessi等[35]用逻辑回归模型对推文进行情感极性判断。
(3) 随机森林。随机森林(Random Forest)是一种包含多个决策树的分类器,随机森林中每棵决策树都有自己的预测结果,随机森林通过统计众数作为其最终预测结果,因此鲁棒性较强,可以降低过拟合的风险,但代价是需要更多的算力来进行训练,即通过提高算力来进行偏差补偿。Guibon等[36]在真实的私人即时消息语料库上使用多标签随机森林模型来预测emoji,其F1分数为84.48%,精度为95.49%。
(4) 卷积神经网络。卷积神经网络(Convolutional Neural Networks,CNN)在传统的NLP实践中已被证明是有效的,并且在句子分类中取得了卓越的性能[37]。在emoji NLP领域,Cui等[37]探索了利用CNN训练含有emoji的语料库进行情感分析,并且验证了CNN的性能要强于SVM。在识别积极情绪的场景下,当召回率小于0.15时,CNN随机模型性能最佳,否则SVM的性能最佳。在识别负面和中性情绪的场景下,CNN非静态模型性能最佳。
(5) 胶囊网络。胶囊网络(Capsule Network)[38]将CNN的极限推到一个新的水平,而且比CNN所需要的训练集要小,但由于采用协议路由算法,训练模型所用的时间较多,适用于文本结构较复杂的场景[39]。Hettiarachchi等[11]提出了一种具有emoji信息的胶囊网络架构,用于检测社交媒体中的冒犯性内容。词嵌入层的输入是字符嵌入和emoji嵌入;然后输出到特征提取层,用于提取文本中的长期记忆依赖;主胶囊网络层主要捕获词序以及语义;卷积胶囊层使用动态路由算法,用于忽略文本中的停用词;之后通过ReLU活化函数输出到全连接层,最后通过Sigmoid函数输出检测结果。该系统具有不依赖于英语语言的特性,因此可以移植到任何其他语言。
(6) 循环神经网络。循环神经网络(Recurrent Neural Network,RNN)可以用来处理上下文不长的自然语言。但RNN对时间步长敏感,即RNN不具有长期记忆,会受到短期记忆的影响。为解决这一问题诞生了带有长短期记忆网络(Long Short-Term Memory,LSTM)和门控循环单元(Gate Recurrent Unit,GRU),它们都是RNN的变种。图4所示为它们的内部结构对比。
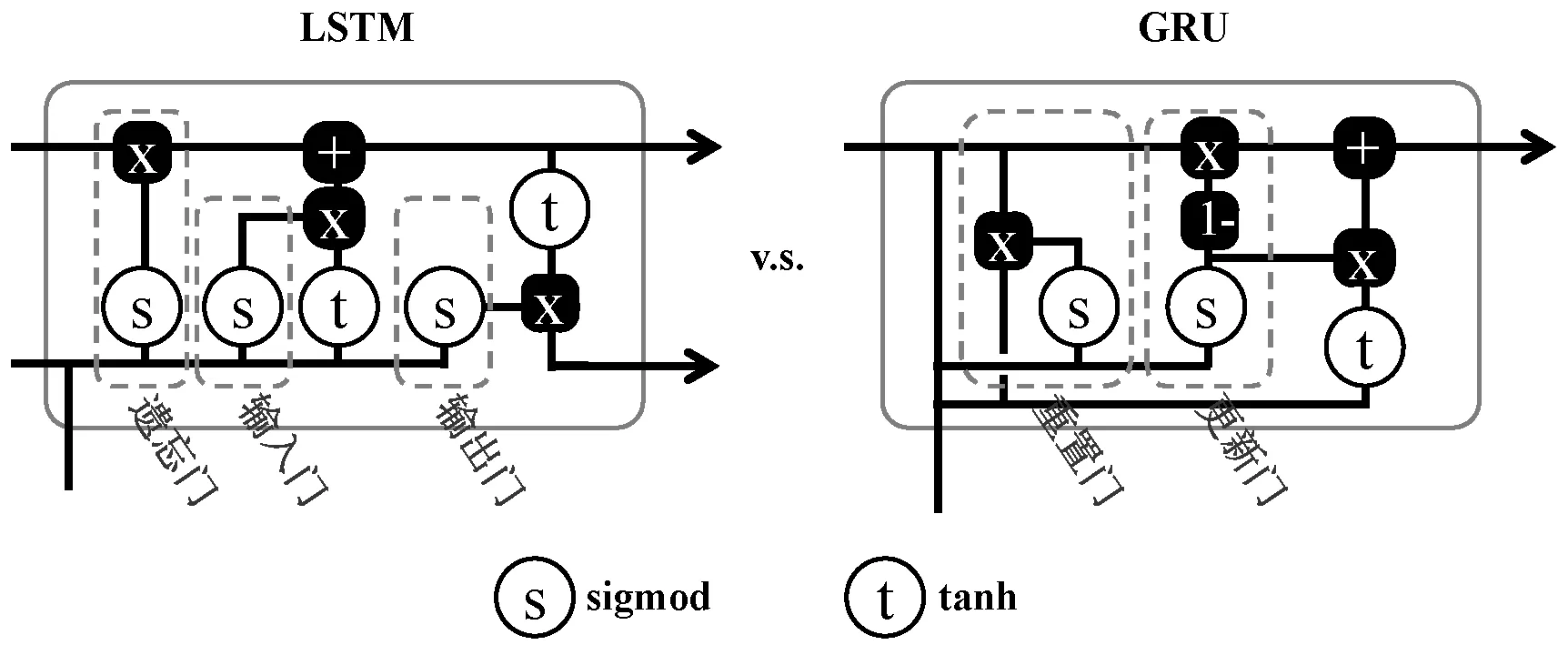
图4 LSTM与GRU内部结构图
(7) LSTM。LSTM由Sepp Hochreiter和Jurgen Schmidhuber在1997年首次引入,直到目前还被广泛使用,衍生出很多变种。LSTM与朴素RNN相比,追加了输入门和遗忘门来解决梯度消失和梯度爆炸的问题,从而可以捕捉到远程信息,能够在长序列文本中有更好的性能表现。
Ramaswamy等[30]在LSTM基础之上进行了改进,将输入门与遗忘门进行耦合,与朴素LSTM相比,这种耦合关系将每个单元的参数数量减少了25%,并用此LSTM的变种在联邦学习的计算范式下进行emoji预测。Xie等[40]也在LSTM基础上进行了改进,利用层次化LSTM来构造多回合对话表示,可以很好地捕捉多回合对话中的上下文信息和情感流,并推荐相应的emoji。朴素LSTM将多人多回合对话视为长单词序列,这种扁平化操作会破坏多人对话的层次结构。如图5所示,层次化LSTM利用分层的LSTM分别学习每个句子的表示形式。
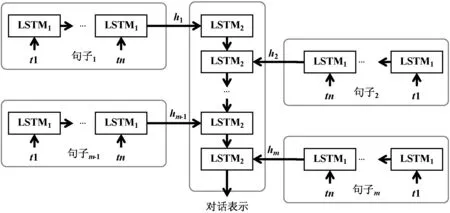
图5 LSTM应用于多回合对话表示的模型
(8) CNN+LSTM和LSTM+CNN。LSTM与CNN神经网络都可以用来进行文本分类。LSTM在文本分类中的作用是提取句子的关键语义信息,根据提取的语义对文本进行分类;而CNN的作用是提取文本特征,根据特征进行分类。LSTM与CNN可以相结合,CNN+LSTM模型首先进行关键特征提取,然后提取文本关键语义信息;LSTM+CNN模型首先提取文本关键语义信息,然后对语义进行关键特征提取。
Sosa等[41]探索了CNN+LSTM、LSTM+CNN两种模型,CNN-LSTM模型的前端由初始卷积层组成,接收词嵌入作为其输入,卷积层提取局部特征,将输出汇集到一个较小的维度,然后输出到LSTM层,LSTM层能够使用这些特征来了解输入的文本排序。经验证,该模型不如LSTM-CNN模型性能佳,甚至比朴素的LSTM模型还差,原因是CNN+LSTM模型前端的卷积层丢失了部分文本序列中的重要信息,而后端的LSTM层仅充当着全连接层的作用,本偏差属于偏差链路中的模型结构偏差。
Wu等[42]结合了LSTM和CNN捕获局部的和远程的上下文信息,以进行推文表示。LSTM-CNN模型的前端是LSTM层,它将接收推文中每一个令牌的词嵌入作为输入,它输出的令牌不仅仅存储初始令牌的信息,还存储任何先前的令牌。LSTM层为原始输入生成一个新的编码,然后LSTM层输出到期望可以提取局部特征的卷积层中,卷积层的输出将被汇集到一个较小的纬度,最终输出情感极性标签。
(9) 引入注意力机制的LSTM。深度学习中的注意力机制借鉴于人类视觉的注意力机制,是利用有限的注意力资源从大量信息中快速筛选出高价值信息,并且忽略低价值信息的机制,能极大地提高信息处理的效率与准确性,主要用于文本翻译、图像描述、语义蕴含、语音识别和文本摘要等。
前文的Encoder-Decoder框架是没有体现注意力机制的。Target中每个词的生成过程:y1=d(C),y2=d(C,y1),y3=d(C,y1,y2)。d()是Decoder的非线性变换函数,可观测到在生成目标句子的词时,不论生成哪个词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。没有注意力机制的模型对短句影响不大,但在长句的情境下会丢失很多关键词信息。Attention模型将固定的中间语义编码C替换为根据当前输出词来调整成加入注意力机制的变化的Ci。增加了注意力机制的Encoder-Decoder框架如图6所示。

图6 引入注意力机制的Encoder-Decoder框架
对于采用RNN及其变种的Decoder来说,通过函数F(hj,Hi-1)来获得目标单词Yi和每个输入单词对应的对齐概率,这个F函数在不同模型里采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布,原理如图7所示。
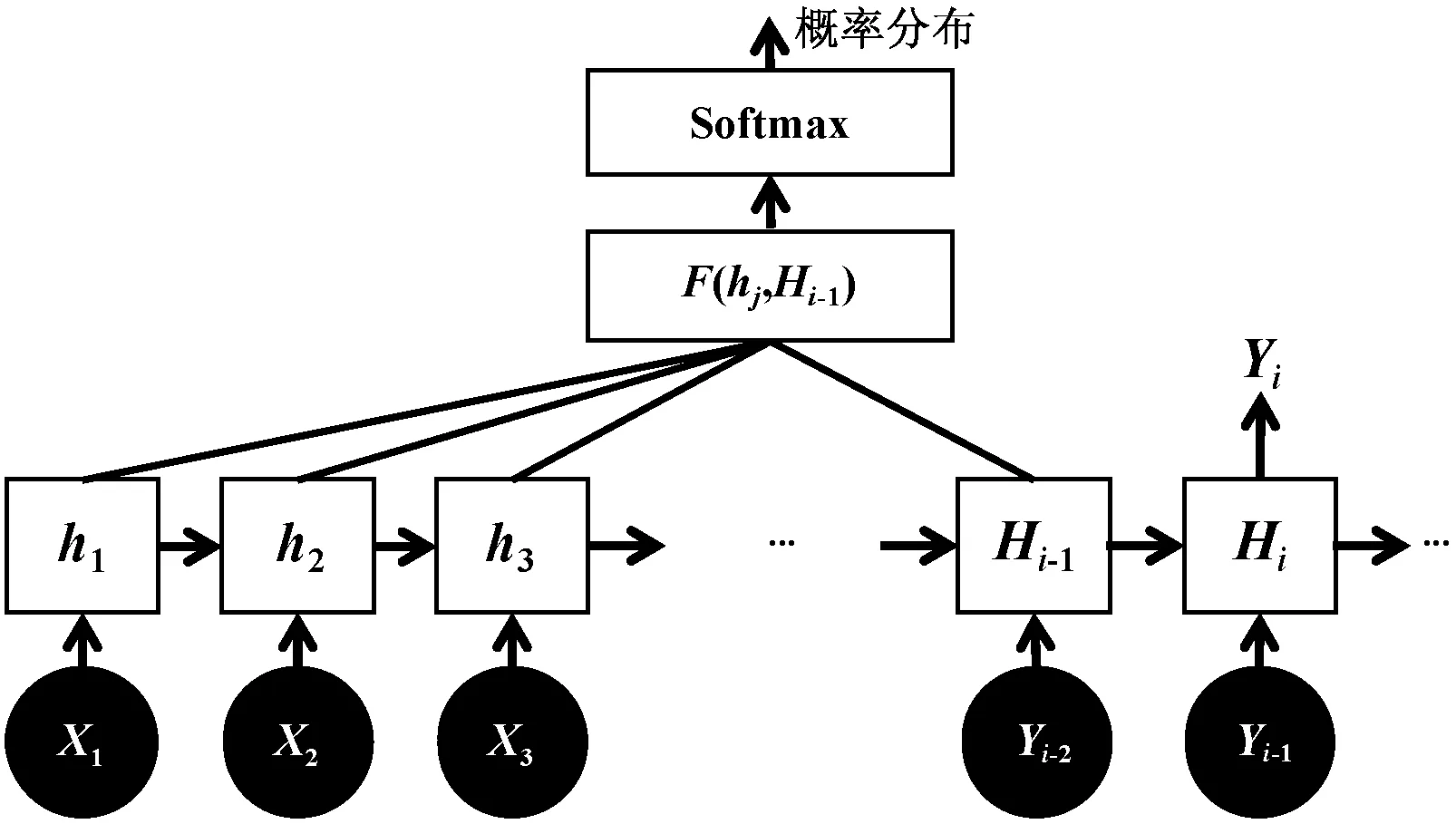
图7 注意力分配概率分布原理图
Barbieri等[31]研究了时间序列是否以及如何影响emoji的解释和预测。其结论是使用时间信息可以显著提高某些emoji的准确性,时序信息处理的位置越靠前,数据越完美。Barbieri等[43]使用标签机制来分析分类器的行为,利用注意力权重来发现和解释emoji的用法,通过实验比较标签机制对emoji分类器性能的影响。研究发现线性分类器、非线性分类器能够预测常用的emoji,但对于不常见的emoji预测准确性偏低。实践证明标签式注意力机制可改善低频emoji预测。
(10) Bi-GRU。GRU的输入输出结构与朴素RNN相似,但其内部结构与LSTM相似。GRU使用一个门控就可以进行遗忘和选择记忆,参数也较少,而LSTM则要使用更多的门控和更多的参数才能完成同样的任务,因此GRU比LSTM更容易进行训练,而且GRU在较小数据集上比LSTM表现出更好的性能[11]。在实务中,考虑到算力和计算时间成本,越来越多的研究者选择更实用的GRU。
GRU无法对从后向前的信息进行编码。在分类粒度更细的场景下,比如对于强褒义、弱褒义、中性、弱贬义和强贬义的五分类任务需要注意程度词、情感词、否定词之间的交互。双向门控循环单元(Bi-directional Gate Recurrent Unit,Bi-GRU)解决了这个问题,Bi-GRU由前向与后向GRU叠加组合而成,可更好地捕捉双向语义依赖。Bi-GRU可以在每个时间步长向前和向后连接句子矩阵向量,以获得更完整的句子信息[44],因此Bi-GRU通常比GRU效果更好,但代价是训练更费时。
Wang等[45]利用具有注意机制的Bi-GRU来构建emoji预测基础模型,如图8所示。然后采用融合集成的方法进行模型强化,即使用重新加权的方法迭代训练基础模型,每个回合的权重分布取决于前一轮模型预测结果。最后,为获得最佳性能,系统中还对比了软投票和硬投票的性能。软投票是每个预测模型输出所有类别的概率向量,并且对投票模型进行平均加权以便对最终的概率向量进行分类。硬投票是每个模型输出其认为最可能的类别,投票模型从中选择投票模型数量最多的类别作为最终分类。从最常用的20个emoji中选择1个作为预测结果,这种场景下emoji类标签不属于长尾分布,Wang等验证了在该场景下软投票的效果要优于硬投票。如果类标签服从长尾分布,即类不平衡(Class Imbalance)的场景下不能使用强化算法。

图8 Bi-GRU分类器系统架构图
(11) 社会网络分析。社会网络分析(Social Network Analysis,SNA)是基于图论、社会学和管理学等多学科融合的理论和方法,为理解复杂网络的形成、行为模式等提供了一种可计算的分析工具[46]。SNA在emoji自然语义分析中属于冷门领域,另辟蹊径地开创了新的研究范式,因为需要构筑词网,一般适合于社交平台的语料分析。目前有三种主流模型:emoji-词汇双模网络模型、emoji共现网络模型、ego network模型,其中前两种属于整体网,后一种属于自我中心网(ego network),属于整体网的一部分,侧重于研究单个节点的性质[47]。Unicode联盟为每个emoji提供了官方文本描述,然而用户并不会参考官方手册,所以基于emoji Unicode官方文本描述的研究方法在采样阶段都或多或少地引入偏差,而SNA研究范式不依赖于emoji Unicode官方文本描述,巧妙地规避了这部分采样偏差。
Emoji-词汇双模网络。双模网络是指在同一网络下存在两种不同类型节点的复杂网络,多模网络研究属于网络科学的前沿领域,emoji-词汇双模网络将emoji与其他普通词汇视为两种不同的节点,是研究emoji与词汇关系的有力工具之一。Seyednezhad等[18]认为同一个句子其语义根据会话的主题而有所不同,并基于多主题方法探讨emoji的情感及其类别。其认为emoji位置、情绪属性、频率和语义四者之间具有相关关系,通过emoji-词汇的双模网络方法来识别emoji的潜在模式。首先从至少包含一个emoji的推文中提取emoji和词汇,再构建一个emoji和词汇的双模网络,最后使用SNA来分析emoji的语义和情感极性。emoji的语义由与该emoji关联词汇的词频决定,这种方法巧妙地规避了词典训练环节,因此避免了中间环节可能会产生的偏差。
Emoji共现网络。共现指对语料信息中特征项描述的信息共同出现的现象,而共现分析是对共现现象的定量研究,以揭示语料信息的内容关联和特征项所隐含的知识,其中一种工具就是共现网络,属于SNA的研究范畴。共现分析包含文献耦合、共词分析、共链分析等子领域,其中共词分析的研究对象是同一语料中同时出现的词汇对[48],emoji共现网络是供词分析的一个比较前沿的研究方向。NLP系统主要使用从word2vec或GloVe或fastText获得预训练的词嵌入,Illendula等[29]认为外部知识的使用可以提高NLP任务的准确性,利用emoji共现网络用作训练emoji嵌入,可以增强emoji预测、emoji相似度和emoji语义消歧任务的性能。Illendula等采用图嵌入模型,有助于缩放来自大规模信息网络的信息,并将其嵌入到有限维向量空间中。
Ego network。ego network网络节点由唯一的一个中心节点(ego),以及该节点的邻居(alter)组成,ego network中的边包含ego与alter之间的边,还有alter与alter之间的边。在emoji语义分析领域,将某一emoji视为ego,从语料库构建emoji与单词的ego network,用上下文的特征来表征emoji的语义。
Zimmermann等[49]认为基于ego network可以提取与emoji语义相关的网络属性特征,包括但不限于Size、Ties、Pairs和Density等属性。
Ai等[50]使用LINE词嵌入模型来训练单词和emoji嵌入,构建共现网络来表示语义结构,通过计算嵌入空间中令牌间的欧氏距离来度量语义相似度,所以LINE嵌入可以在语义上找到相似的令牌,最近邻居关系可以表示为kNN图,借助kNN图和ego network的结构特性来刻画emoji和单词之间的语义关系。
3.3 小 结
没有最好的分类模型,只有根据使用场景选择最适合的分类模型[51],表2是对上文模型的整理。

表2 各分类器横向比较
4 结 语
综上,结合emoji语义和情感的机器学习应用,可以提高网络信息处理的准确性。emoji作为网络时代的交流符号,丰富了网络交流语言,也丰富了人类用户的表达和沟通能力,能够表达自己的情绪并引起同理心,使用户成为更好的沟通者[8],但与此同时emoji也为自然语言处理带来了复杂性。为了最大限度地发挥emoji对社会的潜在价值,需要考虑很多因素,未来的挑战也是多方面的。
第一,emoji自然语言处理需要与更多的学科紧密结合。emoji是一个诞生时间不长,却在全球都有普遍使用的新文字,众口难调是必然的,emoji将与用户一起不断进化,互为因果,仅靠NLP技术不足以应对这种复杂性,因此研究领域将扩大到多学科交叉领域,尤其是非技术领域,比如传播学、社会学、符号学、行为设计学等。大学、互联网巨头和资助机构可以在跨学科研究中起到重要作用。
第二,emoji与其他文字有着本质不同。在书写方面,emoji是不能被广泛书写的文字,因此常规的语言处理方法可能因emoji失效。在数量方面,Unicode emoji存量众多,每年还会产生一定的增量,并占据Unicode新的编码点,所以要避免过度引入新的emoji。在外部性方面,作为全球共用的emoji,可能会关系到某些国家和地区敏感的道德、法律、宗教和文化等因素[52],这可能会给本类研究人员带来法律或道德问题,甚至阻碍这一类研究。
第三,emoji呈现标准化趋势。emoji是自下而上的设计,在细节之处难免存在着缺陷和为弥补此缺陷而颠簸的设计,又因路径依赖不容易回滚,因此带来的固有偏差可能将长期存在。但纵观历史,从20世纪90年代的emoji信息孤岛,到2010年统一码联盟将emoji统一编码,再到2015年出现了emoji国际标准第一版,一旦emoji的视觉渲染被标准化,即图标标准化,那么emoji自然语言处理的难度将大幅下降。
第四,emoji隐私计算生态逐渐形成。随着公众隐私保护意识的养成、相关法律法规的逐步完善,在不泄露用户隐私且符合数据安全保护的原则下进行emoji自然语言处理已成为必然,联邦学习范式提供了可行的解决方案[53],在企业各自数据不出本地的前提下,通过加密实现参数交换与优化,建立虚拟的共有学习模型。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
商界评论(2022年1期)2022-04-13
长江丛刊(2019年25期)2019-11-15
数学大王·趣味逻辑(2019年10期)2019-11-06
电脑知识与技术(2019年23期)2019-11-03
草原(2018年2期)2018-03-02
软件导刊(2017年4期)2017-06-20
科学与财富(2016年30期)2017-03-31
