
数据流决策树集成分类算法综述
2022-10-10 09:25申明尧杜诗语张春砚
计算机应用与软件 2022年9期
申明尧 韩 萌 杜诗语 孙 蕊 张春砚
(北方民族大学计算机科学与工程学院 宁夏 银川 750021)
0 引 言
近年来,随着技术的快速发展,互联网每天都会产生海量的数据,如超市交易、互联网搜索请求、电话记录、卫星数据和天文学等。数据流的出现改变了人们存储、通信和处理数据的方式。与传统的数据集相比,数据流呈现出连续、高容量、开放式和概念漂移的新特征[1]。在数据流中,数据到达的速度远快于传统算法中多遍扫描和重复分析的速度,因此传统算法无法有效处理数据流。目前,数据流模型已广泛应用于生活中的各个领域,逐渐成为数据传输的主流趋势。决策树算法作为数据流分类最有效的方法之一,具有速度快、实用、易于理解、容易提取规则等优点[2],在医疗诊断、天气预报、行为分析和网络安全等领域发挥出越来越重要的作用。
数据流决策树分类算法按照分类模型可分为决策树单分类算法和决策树集成分类算法。相较于单分类算法,决策树集成分类算法具有更好的时空效率和更高的准确性,因此被广泛应用于各种分类任务。其中,随机决策树(Random Decision Tree, RDT)[3]和随机森林(Random Forest, RF)[4]是经典的两个算法,后续出现的大部分算法都是基于它们实现的。例如,数据流的半随机多决策树算法(Semi-Random Multiple decision Trees for Data Streams, SRMTDS)[5]、多个半随机决策树算法(Multiple SemiRandom Decision Trees, MSRT)[6]、随机普通集成算法(Random Ordinality Ensembles, ROE)[7]、基于聚类的分类器选择算法(Classifier Selection Based on Clustering, CSBC)[8]和在线随机森林算法(Online Random Forest, ORF)[9]等。此外,用于概念漂移检测和处理的决策树集成算法有基于随机决策树的概念漂移检测算法(Concept Drifting Detection Based on Random Ensembling Decision Tree, CDRDT)[10]、不确定处理概念漂移快速决策树算法(Uncertainty-handling Concept-adapting Very Fast Decision Tree, UCVFDT)[11]、基于概念漂移数据流的集成决策树算法(Ensemble Random Decision Trees for Concept-drifting Data Streams, EDTC)[12]、随机决策树算法(Random Decision Tree, RDT)和霍夫丁选项树算法(Hoeffding Option Tree, HOT)[13]等。
本文的主要贡献如下:(1) 分别从Bagging、Boosting和Stacking三种集成学习框架的角度对决策树集成分类算法进行了详细的分类和总结。(2) 对数据流中存在的概念漂移问题及其处理方法进行了分析和总结。(3) 从多角度对文章中所提及的算法进行分析,有助于研究者们根据算法的优缺点选择合适的算法进行下一步研究工作。
1 集成学习框架
集成学习的思路是通过合并多个模型来提升机器学习性能,这种方法相较于单个模型通常能够获得更好的预测结果。集成方法是目前最有前途的研究方向之一[14],已经被证明是提高预测精度或者可以将复杂、困难的学习问题分解为更简单、容易的子问题的有效方法[15]。其目标为将不同的分类器组成一个元分类器,与单分类器相比,元分类器具有更好的泛化性能。集成分类器的大致图解如图1所示。

图1 集成分类器图解
一般来说,集成学习框架主要分为三大类,分别为用于减少方差的Bagging、用于减少偏差的Boosting和用于提升预测结果的Stacking。
1.1 Bagging
Bagging是一种简单而有效的方法,用于生成独立模型的集合,其中使用从原始数据集中取得的实例样本来训练每个诱导器[16]。它从训练集中进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果。算法具体过程如图2所示。

图2 Bagging算法图解
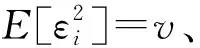
(1)

国内外的研究者们已对基于Bagging集成学习框架的决策树分类算法进行了相关研究,开发并更新了大量的算法模型,以满足人们的需求。Fan等[3]提出了一种随机决策树(RDT)算法,该算法只需扫描一次训练数据,以更新多个随机树中的统计数据,且所构造树的结构完全独立于训练数据。结果表明,随机树算法的存储器需求明显少于学习单个最佳树,即使非常大的训练数据也可能完全保存在主存储器中。此外,基于Breiman提出的随机森林算法[18],Abdulsalam等[19]提出了一种扩展的在线流随机森林算法,使用节点窗口和树窗口来决定何时构建新树、转换边界节点或执行有限形式的修剪。同时,Hu等[5]设计了一种用于数据流的半随机多决策树增量(Semi-Random Multiple decision Trees for Data Streams, SRMTDS)算法,其在叶片处引入朴素贝叶斯分类器,提高了树的预测精度。在此基础上,Li等[6]提出了一种基于半随机多决策树的MSRT概念漂移数据流算法。与SRMTDS算法相反,它首先生成不同类型节点对应的备选子树,然后利用Hoeffding界的不等式,使用两个阈值来区分真正的概念漂移和噪声。但是,由于在构建原始树时需要准备额外的子树,因此对空间和运行时开销的要求更高。Oza等[20]引入了在线套袋,它提出了标准套袋的限制,要求提供预先提供的整套训练套件用于学习。假设在线学习中,每个新的传入实例可以在每个基类分类器的更新过程中被复制零次、一次或多次。Lee等[21]进一步发展了这种方法的理论基础,提出了一个贝叶斯在线Bagging,相当于批量贝叶斯版本,与无损学习算法相结合,获得了无损的在线装袋方法。Bifet等介绍了Oza算法的两种修改,称为自适应大小Hoeffding树(Adaptive-Size Hoeffding Tree, ASHT)[22]和Leveraging Bagging[23],旨在为基类分类的输入和输出增加更多随机化。霍夫丁选项树(Hoeffding Option Trees, HOT)[24]可以看作是Kirkby选项树的扩展。它允许每个训练示例更新一组选项节点而不仅仅是一个单独的叶子。它提供了一个紧凑的结构,就像一组加权分类器一样。和常规的Hoeffding树相似,它们是以增量方式构建的。Gama等[25]提出了一种超快速树木森林(Ultra Fast Forest of Trees, UFFT)算法,使用Hoeffding树的集合进行在线学习。它们的拆分标准仅适用于二元分类任务。为了处理多类问题,应用二进制分解,为每个可能的类对构造二叉树。当新实例到达时,只有当二进制基类分类器使用此实例的真实类标签时,才会更新每个分类器[26]。装袋算法的另一种变型是改进的装袋算法(Improved Bagging Algorithm, IBA)[27]。IBA通过用信息熵标记每个样本来改进重采样过程。Bagging++[28]是通过利用Bagging从传入的数据块构建新模型而设计的,作为对Learn++的优化。
1.2 Boosting
Boosting指的是通过算法集合将弱学习器转换为强学习器,其主要原则是训练一系列的弱学习器。所谓弱学习器是指仅比随机猜测好一点点的模型,例如较小的决策树,训练的方式是利用加权的数据,在训练的早期对于错分数据给予较大的权重。Boosting是一个迭代的过程,每次在新分类器中强调上一个分类器中被错误分类的样本(增加错误分类样本的权重),最后将这些模型组合起来的方法。每次对正确分类的样本降权,对错误分类的样本加权,最后分类器是多个弱分类器的加权组合。算法具体过程如图3所示。Boosting不是像Bagging那样重新采样训练数据集,而是调整训练数据集的分布[29]。

图3 Boosting算法图解
Boosting方法大多采用加性模型来组合弱学习器,即可以将集成的学习器表示为如下形式[30]:
(2)
式中:hm表示第m个基学习器;βm表示第m个基学习器的系数;am表示第m个基学习器的参数;M表示基学习器的个数。对于Boosting树方法,由于基学习器的系数βm为1,可将加性模型简写为:
(3)
在给定损失函数L及训练数据的条件下,学习加性模型就是一个搜寻参数使得损失函数极小化的过程,即:
(4)
此时,直接求解这个极小值是个很复杂的优化问题,采用前向分步算法来简化这一问题。前向分步算法本质上是一种贪心算法,它通过每一步只学习一个基函数及其系数,逐步逼近优化目标来简化复杂度。
首先,重写一下加性模型的表达形式,共生成M个基分类器,当前迭代次数为m,即在第m个循环中,Boosting树的加性模型可以写为:
Hm(x)=Hm-1(x)+hm(x;am)
(5)
前向分步算法只要求在第m轮时,优化当前轮次的基学习器的参数,使得损失函数最小以简化算法,即:
(6)
这里优化当前轮次的基学习器的参数,在经典的GBDT[31]算法中,采取的是非常暴力的遍历的方式,即在每个节点划分的时候,遍历所有属性和可能的节点划分数值,在当前指定的损失函数下使损失达到最小。
当采用平方损失函数,即:
L(y,Hm)=(y-Hm)2
(7)
得到:
L(y,Hm-1(x)+hm(x;am))=
[y-Hm-1(x)-hm(x;am)]2=
[r-hm(x;am)]2
(8)
式中:r=y-Hm-1(x)即上一轮基学习器训练完成以后,m-1个基学习器与标签的残差。所以,对于回归问题的Boosting树而言,每一步只需要拟合当前模型的残差即可。
在应用Boosting进行分类的决策树集成算法中,最经典的算法便是梯度提升决策树算法(Gradient Boosting Decision Tree, GBDT)[31]。它是建立在一堆回归决策树之上的集合模型,具有众所周知的泛化能力。作为基于迭代积累的监督决策树算法,它构造了一组弱学习器(树)并将结果累积为最终预测输出。它具有适应性,易于理解。此外,它产生高度精确的模型[32],并成功应用于各种应用中。XGBoost[33]是一个相当成熟的基于GBDT的机器学习范例。它是一个大规模的分布式梯度提升库,实现了寻找近似分裂点并允许并行计算的GBDT算法。此外,基于Online Boosting算法,Pocock等[34]提出了一种在线非平稳提升算法(Online Non-Stationary Boosting, ONSBoost),该算法提供了一种应对流数据中概念漂移的方法,同时保持在线提升的有用属性,即处理流数据的增量学习的能力,以及固定数量的分类,从而固定内存使用。Freund等[35]提出了一种自适应提升算法(AdaBoost),它是用于构建集合模型的著名的依赖算法之一,其主要思想是关注以前在训练新诱导器时错误分类的实例。Chu等[36]提出了数据流自适应挖掘的快速轻增压算法。它基于动态样本权重分配方案,该方案通过变化检测进行扩展以处理概念漂移。变化检测方法旨在实现可能导致整体性能严重恶化的重要数据变化,并将过时的集合替换为从头开始构建的集合。
1.3 Stacking
Stacking是通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术。与投票和平均不同,Stacking是一个通用的组合过程,其中基本分类器在一个串行模型中非线性组合。在叠加过程中,基分类器称为一级分类器,组合器称为二级分类器(或元分类器)。Stacking的基本思想是利用原始训练数据集训练多个一级分类器,然后利用第一级分类器生成的新数据集训练第二级分类器,将第一级分类器的输出作为新训练数据集的输入特征,原始标签仍然是新训练数据的标签[29]。
Stacking最初来源于Wolpert[37]提出的“堆叠泛化”思想,它通常可以通过从元数据中提取知识来提高分类性能。然而,叠加泛化是非常耗时的,因为通常依赖于V-fold交叉验证过程来估计作为元分类器输入的每个样本的后验类概率,以及许多其他叠加方法[38-39]。Bifet等[40]提出了一种使用堆叠结合受限制的Hoeffding树算法,该算法使用堆叠结合有限属性集树分类的穷举集合,可为给定用户指定大小k的所有可能属性子集生成树分类。此外,由于其算法局限性,该算法仅适用于具有少量属性的数据集。Mashayekhi等[41]根据规则选择的规则准确性和覆盖率计算了决策树集合获得的规则得分,并使用爬山法搜索了一组好的规则。在另一项研究中,Mashayekhi等[42]基于具有下坡移动的爬山方法和稀疏组套索方法,设计了一种启发式搜索方法,从黑箱随机森林模型中提取有效规则。Wang等[43]提出了一种基于XGBoost-LR的Stacking集合信用评分模型。该模型使用XGBoost作为基类分类器,并结合随机子空间和Bootstrap算法来增加基类分类之间的多样性。Logistic回归模型用作次要学习者,将每个XGBoost的结果作为特征变量学习以获得评估模型。Necati等[44]通过修改模型生成和选择技术,采用不同的分类算法作为组合器方法,对Stacking方法进行了改进,与纯机器学习技术相比,该方法始终能提供更高的精度结果。
2 概念漂移问题
2.1 问题描述
概念漂移(Concept Drift)表示目标变量的统计特性随着时间的推移以不可预见的方式变化的现象。随着时间的推移,模型的预测精度将降低。
根据预测分类的类别,概念漂移问题可以分为两类,分别为真实概念漂移和虚假概念漂移,如图4所示。

(a) 原始数据 (b) 真实漂移 (c) 虚假漂移图4 概念漂移类型
研究发现,许多学习算法都被用于处理概念漂移,它们分别是基于规则的学习、决策树、朴素贝叶斯和基于实例的径向基函数学习。此外,Cunningham等[45]提出了一种基于实例的动态用于处理概念漂移。Schlimmer等[46]提出了一种基于增量学习的新方法。该方法基于分布式概念描述,分布式概念描述由一组加权符号描述组成。该方法通过在实例描述中为每个学习到的概念添加一个属性,从而在随后的学习中利用先前获得的概念定义。Bifet等[47]提出了一种基于自适应窗口的方法,该方法可以检测不同类型的漂移,其基础是对数据块进行逐块处理,测量连续两个批次之间的差异,作为漂移指示器。实验结果表明,该方法具有较好的漂移检测能力,可以近似地找到概念漂移位置。
2.2 概念漂移处理方法
DDM(漂移检测方法)[48]是数据流概念漂移检测方法中经典算法之一,它使用二项分布来检测变化,并可以处理在预测期间由学习模型产生的分类错误。在DDM的基础上,Manuel等[49]提出了早期漂移检测方法(Early drift detection method, EDDM),该方法是对DDM的改进,用以检测概念漂移。其基本思想为找出分类错误之间的距离以检测变化。它可以在不增加误报率的情况下检测变化,并能够检测缓慢的渐变。该研究表明,它将改善预测的结果。Bifet等[50]提出了一种基于自适应窗口(ADWIN)的方法,该方法可以检测不同类型的漂移,基于通过块处理数据块并测量两个连续批次之间的差异,作为漂移指示器。实验结果表明,该方法能够检测漂移并且可以近似地找到概念漂移位置。Frias等[51]提出了一种基于Hoeffding边界的漂移检测方法(HDDM),该方法是基于窗口的方法,它涉及移动平均线以检测突然变化,主要使用加权移动平均值来检测渐变。累积和检测方法(CUSUM)[52]是一种顺序分析技术,在漂移检测中,它可用于监视变化检测,而且不需要存储数据。同时,Ross等[53]提出了一种指数加权移动平均线图检测方法(EWMAChartDM),用于检测概念漂移。该方法的设计使其能够监控流分类器的错误分类率,同时还可以在不增加预测期间误报率的情况下检测变化。此外,Li等[10]提出了一种基于随机决策树的概念漂移检测算法(CDRDT),该算法可以有效且高效地检测来自嘈杂流数据的概念漂移,并可以有效地区分不同类型的概念漂移与噪声。常见的概念漂移处理技术如表1所示。
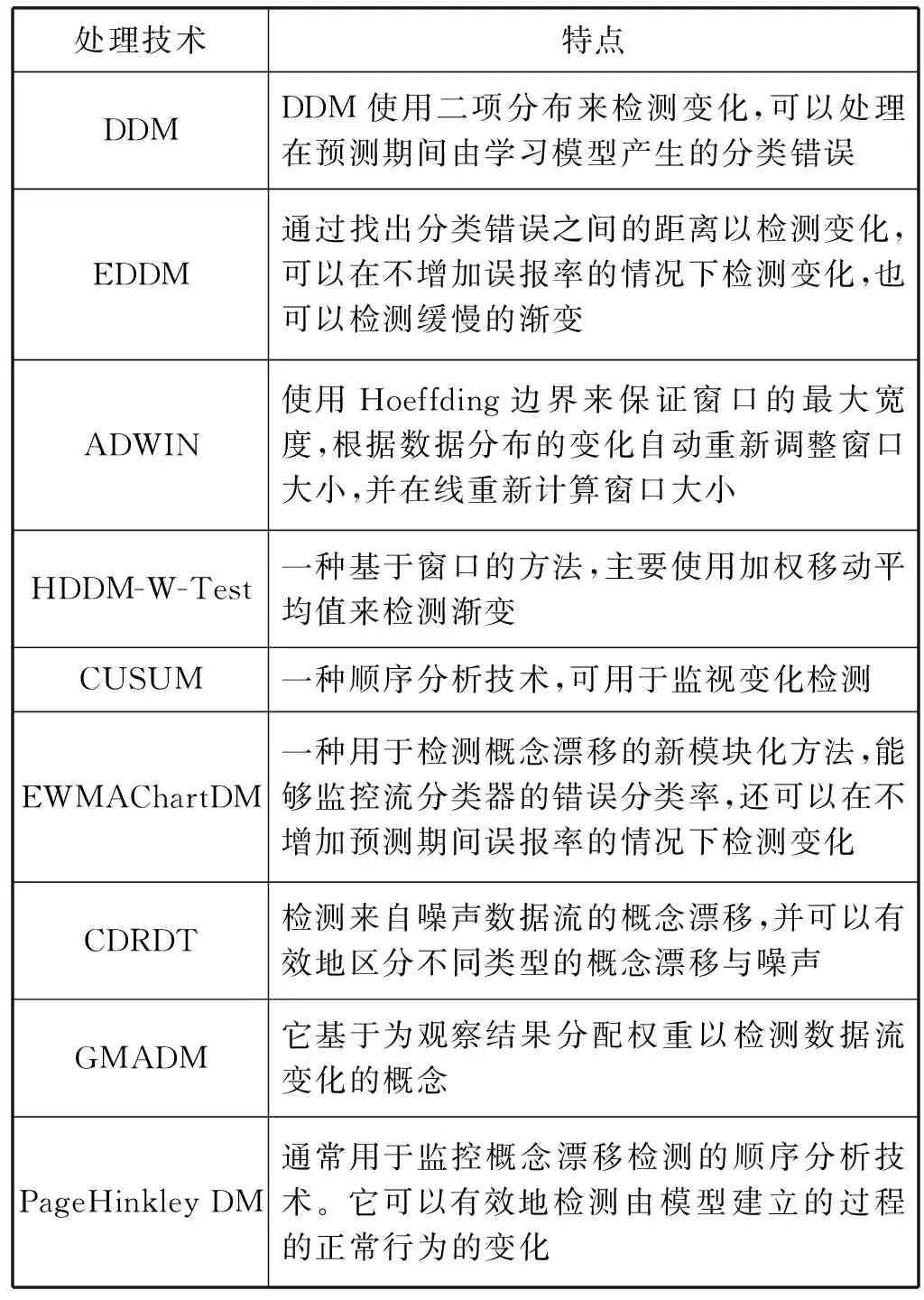
表1 常见概念漂移处理技术
3 算法分析与总结
为了更好地分析和总结数据流决策树集成分类算法的性能,本节从集成学习框架、是否可以处理概念漂移、对比算法、数据集和算法优缺点等几个角度分析总结决策树集成分类算法,算法性能比较结果如表2所示。
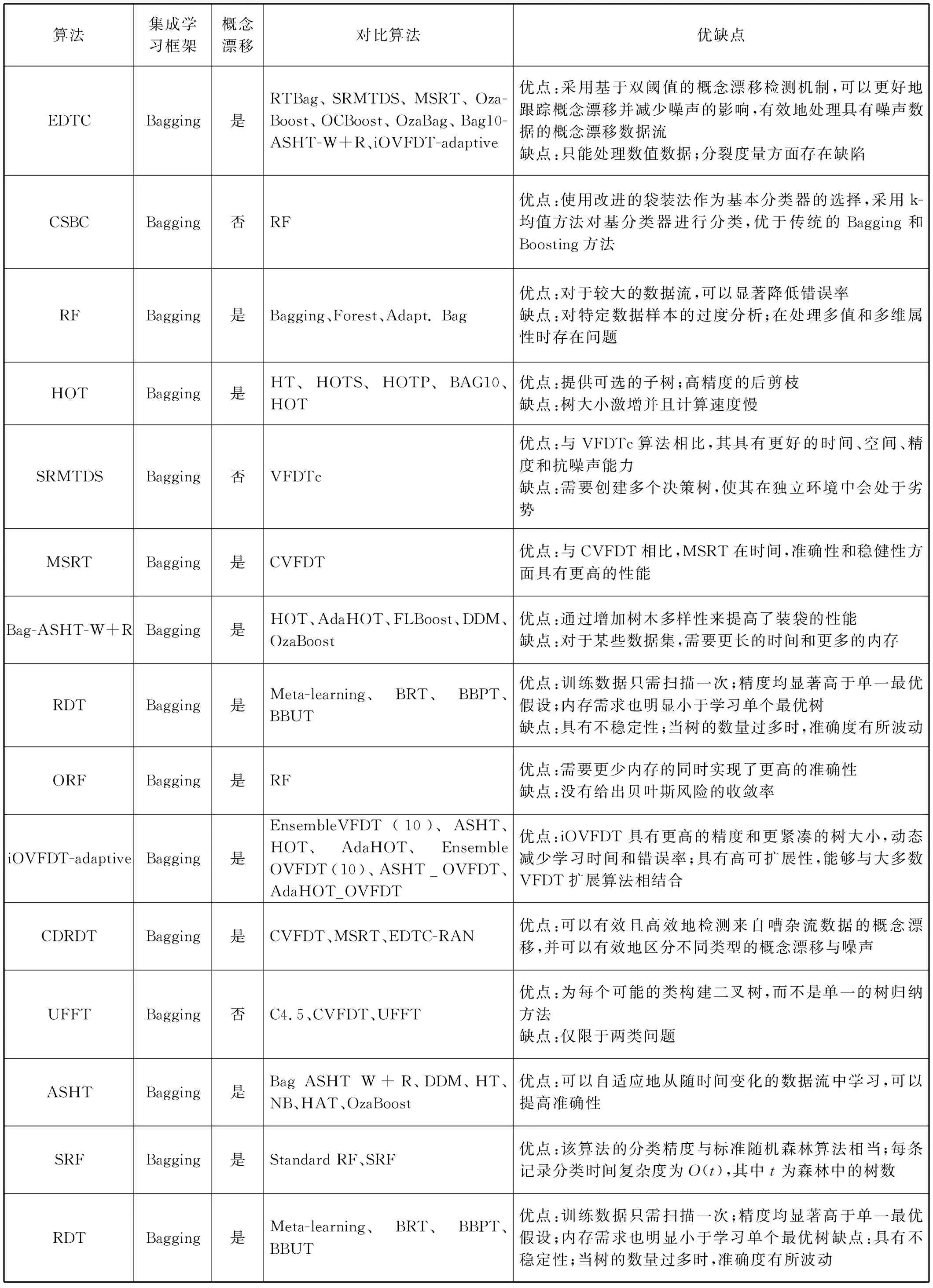
表2 决策树集成分类算法性能比较
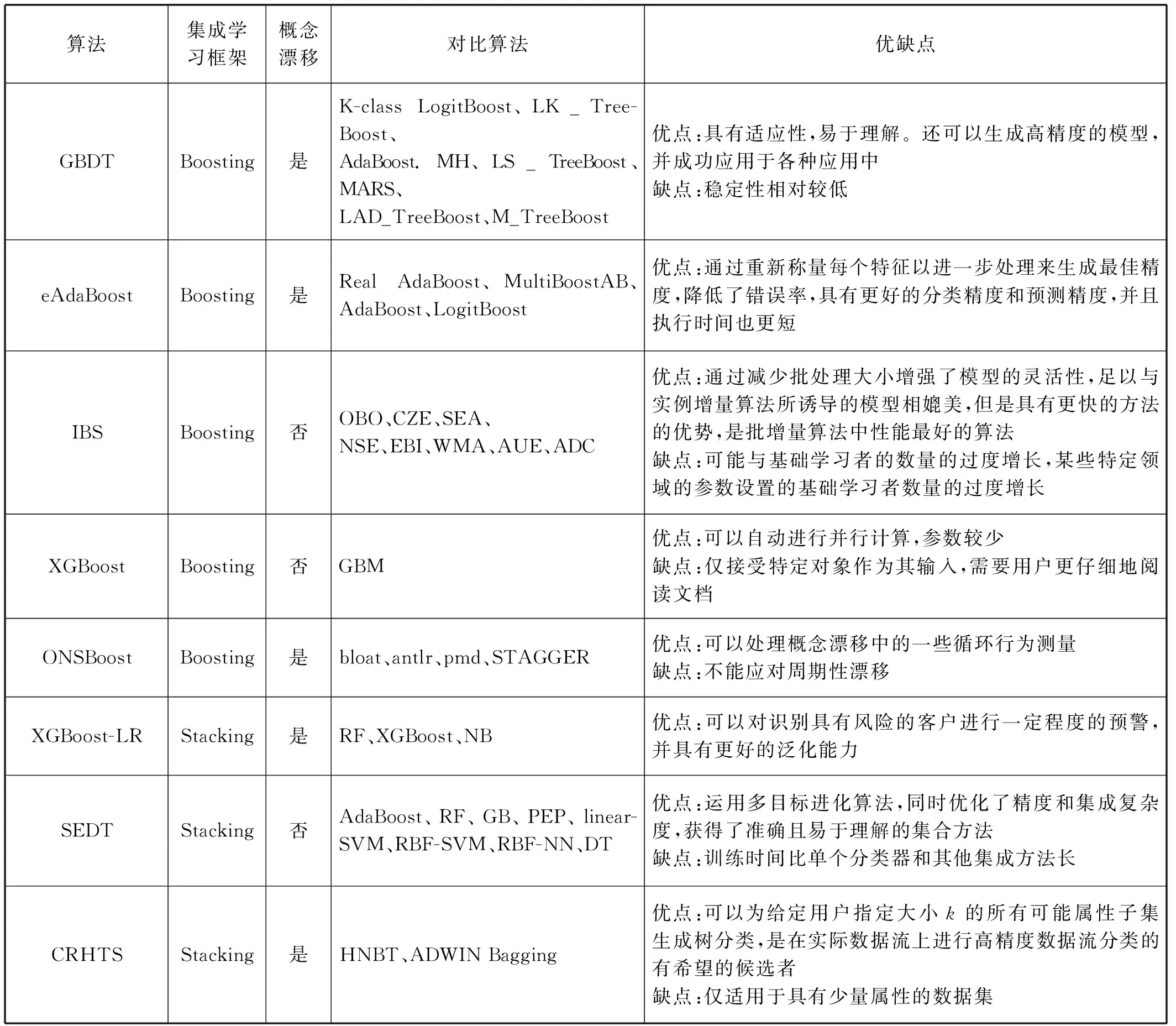
续表2
4 算法应用
4.1 典型应用
数据流决策树集成分类算法由于其高效的时空效率和较高的准确率,被广泛应用于生活中的各个领域,在生物医疗、信用评价、电力预测和湿地测绘等均有突出表现。
在生物医疗领域的最新研究中,Yadav等[54]利用决策树、随机森林、额外树对甲状腺疾病进行分类和预测,并利用Bagging集成框架对得到的结果进行提升,提高了预测的精度。该集成方法在特定参数下,数据集的预测精度达到了100%。Geurts等[55]提出了一种基于随机森林的决策树集成算法对蛋白质组质谱的分析和知识提取,用于识别临床蛋白质组学的生物标志物,从而完成蛋白质组质谱的分类和预测任务。此外,在药物设计方面,数据流决策树集成分类算法也有所涉足。Pu等[56]通过对约160 000个特定药物设计问题的亲和力预测实验对比,LightGBM[57]和XGBoost均表现出比神经网络更高的效率,并可以提取出比传统方法更多的蛋白质-配体结合信息,将药物设计的筛选效率提高到原来的200~1 000倍。
在信用评价领域,Wang等[43]提出了一种基于Stacking的个人信用风险评估模型,该模型使用不同的训练子集及特征采样和参数扰动方法对个人的信用进行风险评估预测。结合上述方法和企业信用评价模型研究的短缺,Sun等[58]提出了一种用于不平衡企业信用评价预测的新决策树集成模型——DTE-SBD,该模型可以处理高风险企业与低风险企业之间的阶级不平衡问题。对552家中国上市公司的财务数据进行了100次实证实验,证明对企业信用评价的不均衡性是有效的,并提高了企业信用评价的正确率。
在电力消耗预测方面,Galicia等[59]对西班牙10年的电力消耗数据进行训练和预测,平均相对误差达到了2%,并已将该模型应用于澳大利亚的太阳能预测。在湿地测绘和分类方面,Berhane等[60]对俄罗斯贝加尔湖塞伦加河三角洲22种复杂淡水三角洲湿地植被和水生生境进行有效监督分类,随机森林算法在大多数情况下都表现出较高的精度,取得了理想的效果。
4.2 主要平台
由于流数据具有连续性和实时性的特点,因此流数据处理平台需要具有实时处理的特点,其将实时数据逐条加载至高性能内存数据库中进行分析和处理,数据迟滞低。目前应用较为广泛的流数据处理平台有Storm[61]、Spark Streaming[62]和Flink[63]等。
作为最佳的流式计算框架之一,Storm平台是Twitter支持开发,并由Clojure语言和Java语言写成,其优点是全内存计算。Storm可以用来处理源源不断的数据,并在处理之后将结果保存在某个存储中。此外,由于Storm的处理组件是分布式的,而且处理延迟极低,因此Storm可以作为分布式RPC框架进行计算。
Spark Streaming是构建在Spark基础之上的流数据处理框架,具有吞吐量高和容错能力强的特点,同时支持多种数据输入和输出格式。Spark Streaming是将流式数据分解为一系列的微小数据集,形成离散流,并将其转化为短小的批处理作业进行计算。它是一个基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需的数据量越大,受益越大;数据量小且计算密集度较大时,受益相对较小。
Flink是一个用Java语言和Scala语言编写的开源分布式流处理和批处理系统,在传统数据库系统和大数据分析框架之间起到链接的作用。Flink的核心功能是在数据流上提供数据分发、通信、具备容错的分布式计算。同时,Flink在流处理引擎上构建了批处理引擎,原生支持了迭代计算、内存管理和程序优化。
以上三种平台分别具有不同的功能特点,对特定场景下的流数据处理均有理想的表现,在国内外的研究中应用广泛。
5 结 语
本文以三种集成学习框架的角度介绍了数据流决策树集成分类的相关算法及研究现状,同时对数据流中的概念漂移问题及其处理算法做了详细的阐述。文章的最后,分别以集成学习框架、处理概念漂移的能力、对比算法、数据集和优缺点等角度对所提及的决策树集成分类相关算法进行了分析与总结,并以此分析出集成学习的趋势和未来的研究方向。
可以预见,集成学习方法将得到进一步改进,更适用于大数据流的学习,特别是不依赖于基础学习器并且可以处理高维度的方法,因为这些方法可以很容易并行化并且可扩展。这些努力通常涉及实现分布式机器学习以及平台计算资源利用支撑和应用模型的部署。此外,另一个有前途的研究方向是将集合模型转换为更简单和更全面的模型,同时保持它们所源自的集合的预测准确性[64]。新数据流集成学习方法应该从传统的分类设置转向处理具有挑战性的真实世界场景的新方法,尤其是半监督(部分标记)和不平衡分类的数据流,使得集成学习应用的灵活性和准确性得到更好的价值体现。
猜你喜欢
计算机时代(2022年9期)2022-11-03
航空学报(2022年7期)2022-09-05
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
内燃机与配件(2022年2期)2022-01-17
科学与信息化(2019年28期)2019-10-21
网络空间安全(2019年10期)2019-03-20
软件导刊(2017年4期)2017-06-20
科学与财富(2016年32期)2017-03-04
农机使用与维修(2016年10期)2016-11-10
