
数据平衡与模型融合的用户购买行为预测
2022-10-10 09:25李伊林段海龙林振荣
计算机应用与软件 2022年9期
李伊林 段海龙 林振荣
1(江西省水利科学研究院 江西 南昌 330029) 2(南昌大学信息工程学院 江西 南昌 330031)
0 引 言
随着电子商务的快速发展,电商平台每天会产生海量的用户浏览、购买、商品评价等用户行为数据。如果电子商务平台能够从海量的用户行为数据中挖掘用户潜在的意图,就能够为用户提供更加个性化的服务和更加精准的营销活动。
国内外的大部分学者对于用户行为预测的研究主要都是基于客户的历史行为数据,在对购买行为预测的研究中,葛绍林等[1]构建了基于深度森林的预测模型对用户购买行为进行预测。张鹏翼等[2]利用机器学习中的分类模型,结合C&R决策树和(Logistics)逻辑回归模型,利用电子商务平台消费者数据进行消费行为预测。用户购买行为预测的复杂性使得单一的算法容易对用户购买行为预测陷入过拟合,为此许多学者提出了多模型融合的方法来解决这一问题。祝歆等[3]、刘潇蔓[4]分别应用Logistic回归、支持向量机、这两者的融合方法搭建了购买预测模型,证明融合算法的精确程度高于单一算法,并指出尝试其他算法以及融合算法是未来的研究方向。李旭阳等[5]结合LSTM算法预测的时序性提出了一种基于LSTM与随机森林相结合的预测模型,通过实验发现融合模型在准确率和召回率上均比单一随机森林模型更高。
综上本文提出基于XGBoost融合模型对用户购买行为进行预测。融合模型利用LSTM、XGBoost、LR算法从不同角度对用户行为进行预测,然后用XGBoost算法拟合各个算法的预测结果作为最终的预测结果。
1 改进的欠采样方法
用户网络购物行为数据存在的最大的问题就是数据分布不均衡,用户购买的过程中存在大量的用户点击、浏览、加购物车等数据,但是用户的下单数据的比例却很少[6]。为了提升不均衡数据的建模效果,提高少数类样本分类精确度,可通过算法层面和数据层面进行数据均衡化处理,即设计学习算法或改进学习算法提升其对少数类样本的识别率,或者利用欠采样、过采样或两者结合的方法降低数据集的不均衡度。
随机采样是当前解决类别不平衡问题最简单和应用最广泛的采样技术,随机欠采样方法通过随机的删除适量的多数类样本数据以达到平衡数据集的效果[7-8],但是随机删除负多数类样本可能会删除到一些典型的样本,使得模型预测精度下降。随机欠采样数据平衡方法伪码描述如算法1所示。
算法1随机欠采样算法
输入:训练集S,正负样本比率Sr。
输出:数据平衡后的数据集。
P=S+,N=S-
//从样本集S提取出正样本与负样本数据
//分别放入样本数据集P、N
while len(P)/len(N)>Sr:
//循环从负样本集删除样本,
//直到达到设定的平衡率
Rondomifrom(0,len(N))
//随机生成负样本的下标i
DeleteN[i]
//删除下表i的负样本
end
S=P+N
//合并正负样本数据集
针对随机欠采样数据平衡方法造成数据信息丢失的问题,本文在随机欠采样方法的基础上提出了基于K-means算法[9]的改进随机欠采样方法。改进的随机欠采样数据平衡方法的流程如图1所示。

图1 改进欠采样方法流程
改进的欠采样数据平衡方法是在随机欠采样平衡方法加入K-Means算法对多数类样本数据进行聚类,首先运用K-Means算法将多数类样本划分为多个簇类,然后利用随机欠采样方法从各个不同的簇类中选取一定比例的样本加入新的样本集,最后将新的样本集与少数类样本集合。
K-Means算法的初始化聚类中心对最终的聚类结果影响很大[10],传统的K-Means算法初始化聚类中心是在数据集中随机选取数据对象作为聚类中心,如果在初始化聚类中心时选择的中心样本的距离很近的话会导致K-Means算法难以收敛。基于这种思想本文对传统K-Means算法初始化聚类中心的过程进行了改进,在初始化聚类中心点时使得这些聚类中心尽可能分散。改进初始化聚类中心的具体流程如下:
1) 获得聚类数k和数据样本总数s,将数据集全部加入聚类中心候选数据集中。
2) 随机地从聚类中心候选数据集中选择一个数据作为一个聚类中心,并计算所有数据样本与该聚类中心的欧氏距离,然后将距离最近的前s/k条样本数据移出聚类中心候选数据集。
3) 重复步骤2)直到获得k个聚类中心点。
2 用户购买行为预测模型
2.1 极限梯度提升算法
极限梯度提升算法(eXtreme Gradient Boosting,XGBoost)是由Chen等[11]提出的一种规模较大的算法。当XGBoost使用树算法作为基分类器时,它就是在GBDT算法的基础上做了一些改进。XGBoost算法对每棵树进行了预剪枝,传统GBDT只用损失函数的一阶导数信息进行优化,XGBoost算法对损失函数进行了二阶泰勒展开,同时用到了一、二阶导数信息,相当于使用牛顿法优化损失函数[12-14]。
XGBoost算法采用加法模型的方式训练模型,每次新增的基模型都是在上一个基模型的基础上训练得到的。
(1)
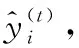
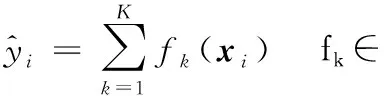
(2)
XGBoost算法在损失函数里引入了正则项,提升了单棵树的泛化能力。式(3)给出了损失函数的计算方法,损失函数包含预测结果的误差评估和正则项,正则项是树的复杂度之和,用于控制模型的复杂度。
(3)
正则项的展开形式如式(4)所示,参数T表示叶子节点的个数,参数w表示叶子节点的预测值。通过参数γ可以对叶子节点的数量进行限制,参数λ可以调节叶子节点的预测值大小防止出现预测值过大的情况,通过这两个参数可以有效地防止过拟合。
(4)
2.2 融合预测模型构建
基于预测模型的预测特点,融合模型的基学习器使用LSTM算法、XGBoost算法、逻辑回归算法,融合模型中基学习器算法与不同类别的预测算法能够结合各类算法的优势提高融合预测模型的泛化能力。融合模型的构造过程描述如下:
(1) 运用改进的过采样平衡方法处理数据集的正负样本不平衡问题,得到数据集D。
(2) 将训练数据集D平均地划分成2份数据集D1、D2。
(3) 用训练数据集D1分别训练LSTM模型、XGBoost预测模型、LR预测模型作为融合模型的基学习器。
(4) 将训练数据集D2输入到各个基学习器获得模型的预测结果,并将预测结果加入到数据集D2的特征属性中。
(5) 用训练集D2训练XGBoost模型作为元学习器,完成融合模型的训练。
融合模型构建流程如图2所示。

图2 融合模型构建流程
3 实 验
3.1 数据介绍
本文的实验数据是JData数据挖掘大赛提供的京东商城真实的在线交易数据。数据集给出2016年2月1日到2016年4月15日的线上交易数据。数据集包含用户基本信息、商品基本信息、用户对商品的评价信息、用户对商品的交互信息,其中备注说明为“脱敏”的字段的具体信息是做了信息隐藏等处理后的内容,以免用户等具体信息泄露。数据集的具体信息如表1-表4所示。

表1 用户基本信息
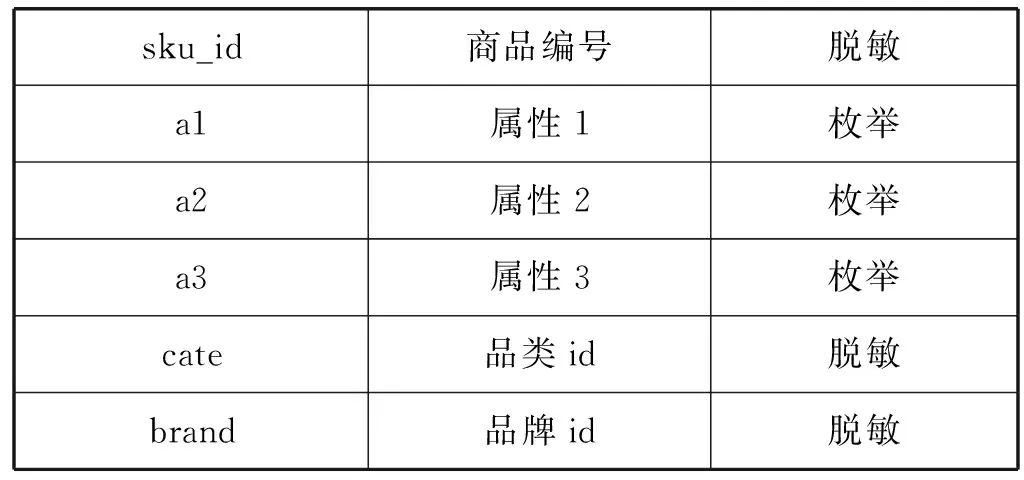
表2 商品基本信息
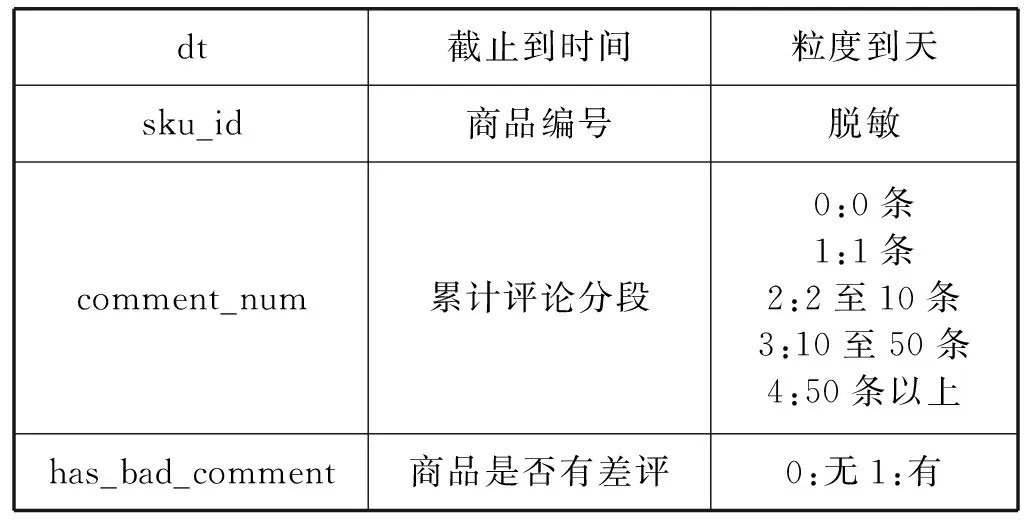
表3 商品评论数据
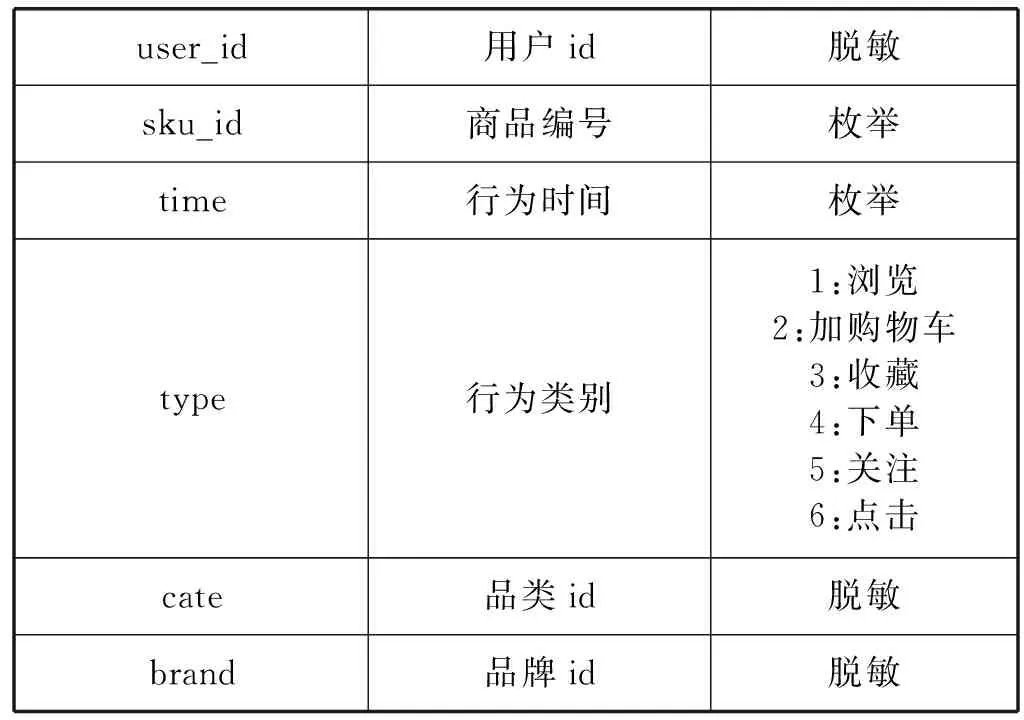
表4 用户行为数据
3.2 数据清洗
对用户商品交互行为分析发现用户的点击行为非常大,结合电子商务用户行为研究可以认为点击行为对于购买行为的影响非常低可以忽略不计。对于浏览行为非常大却没有购买行为的用户可以认定为爬虫用户,这类用户主要是为了获取商城的商品数据,这类数据对预测模型的训练会产生很大影响,所以需要将这类用户的行为数据去除。本文对原始数据的清洗过程如下:
(1) 特征数据缺失用-1填充。
(2) 数值化特征值,对原始数据中的用户属性的性别进行数值化。
(3) 对特征值进行独热编码,本文对用户的行为数据(如加购物车、浏览商品、购买商品)进行独热编码处理。
(4) 删除异常数据,异常数据主要来自于一些基本上没有记录的用户,还有一些就是特别活跃但却没有任何购买记录的爬虫用户的相关数据。如果将这些值放入到训练集的话会严重影响模型的精度,所以将这些异常数据删掉。
3.3 特征提取
经过特征提取与特征选择后,本文最后所用到的预测特征体系由用户特征群、商品特征群、商品类别特征群、用户-商品特征群构成。本文选取的特征情况如下:
(1) 用户特征群。用户特征群由用户的基本特征和用户的衍生特征构成。用户的基本特征包括:用户的等级;用户购买商品的种类数;用户购买商品的品牌、类别数。用户的衍生特征包括:用户对商品的四种交互行为(浏览、收藏、加购物车、关注行为)的购买转化率;用户的购买活跃度(用户购买商品的总次数与购买商品的实际天数的比值);用户购买活跃度在所有用户中的排名。
(2) 商品特征群。商品特征群由商品的基本特征和商品的衍生特征构成。商品基本特征包括:商品的类别、品牌等各类属性;购买该种商品的人数。商品的衍生特征包括: 商品的四种交互行为(关注、收藏、加购物车)的购买转化率;商品的购买人数在该商品所属品类的排名;商品的购买转化率在该商品所属类别的排名;商品的四种交互行为的趋势(商品预测日期前1天的四种交互行为的数量与日平均交互行为数量的比值)。
(3) 商品类别特征群。商品类别特征群包括:不同的商品类别包含的商品的数量;不同的商品类别购买的总人数。
(4) 用户-商品特征群。用户-商品特征群包括:预测日期前,该用户对该商品的四种交互行为数;预测日前第1天、第2天、第3天,该用户对该商品四种交互行为数;预测日前5天、前7天、前9天、前11天,该用户对该商品四种交互行为数。
3.4 模型评价指标
对于数据类别不平衡的预测存在正样本数量稀少、样本分布较为稀疏的情况,这种情况下预测模型会偏向识别负样本而正样本很难识别到,在实际应用中正样本的识别具有更高的价值。为了更清楚地看到正样本的预测效果,本文采用混淆矩阵、召回率等来评价数据不平衡的分类问题[15]。表5给出了二分类问题的混淆矩阵。

表5 混淆矩阵
针对本文的预测情况的解释:定义U-S(U:user_id用户id,S:sku_id商品id)表示用户和商品的对应关系,模型预测的输出结果就是U-S对,U-S值为1表示用户购买该商品,U-S值为0表示用户不购买该商品。TP是指模型预测为购买情况且实际也购买了的U-S的数量,FP是指模型预测为会产生购买而实际没有购买的U-S数量,TN是指模型预测为不会产生购买而实际上产生购买的U-S数量,FN是指模型预测为不会产生购买实际上也没产生购买的U-S数量。
本文主要关注的是购买行为预测的效果不需要知道未购买行为的预测效果,所以预测模型的评价指标有购买行为预测的精确率(precision)、召回率(recall)。精确率就是模型预测的所有U-S值为1的正确率,这体现了模型对正样本预测的准确率。召回率是指预测对的U-S占所有的实际U-S结果的比率,这体现模型预测正确的U-S对在所有的实际U-S结果的命中率。精确率和召回率的数学公式表示如下:
(5)
为了更好地评价模型,本文选用F1值作为模型的评价指标,F1值计算方法如下:
(6)
3.5 模型参数设置
实验所用的XGBoost预测模型是基于Python的XGBoost类库构建的。LSTM预测模型是基于Keras神经网络库和Scikit-learn机器学习库构建,LR预测模型是基于Scikit-learn机器学习库构建的。通过不同参数组合的方式,对模型的预测结果进行了比较最终确定了模型主要的参数。
(1) XGBoost模型。eta=0.01,n_estimators=700,max_depth=4,min_child_weight=3,gamma=0.3,subsample=0.9,colsample_bytree=0.8,即在模型参数调优的模型学习步长为0.03,决策树的数量为700个,树的最大深度为4,最小叶子权重为3,正则项系数gamma为0.3,训练样本数据的采样比例为0.9,样本特征的采样比例为0.8。
(2) LSTM模型。LSTM预测模型是堆叠式LSTM架构,第一层LSTM的units=200,第二层LSTM的units=50,全连接层输出维度1,激活函数使用tanh,损失函数使用mse,优化器选用adam。
(3) LR模型。penalty=L2、C=0.5、solver=liblinear、max_iter=100、class_weight=balance,即模型的正则化方式为L2,惩罚系数0.5,使用了坐标轴下降法来迭代优化损失函数,模型迭代训练100次,由模型计算不同类别样本的权重。
3.6 实验结果分析
通过对实验数据集的分析发现训练集的正负样本比例存在严重失衡,为了更好地训练预测模型本文提出数据平衡策略处理训练数据集。在数据划分后对训练数据集的分析中发现未加入数据平衡策略的原始数据样本数据的正负样本比达到0.002 9,训练集正负样本严重失衡,为此本文利用欠采样平衡方法对数据进行平衡发现正负样本比为0.05时模型预测效果较好。表6给出了XGBoost预测模型、LSTM预测模型和LR预测模型在欠采样平衡方法下的预测效果。对比各个模型在欠采样数据平衡方法下的预测效果,XGBoost模型的预测F1值要明显高于其他两种预测算法,就单一预测模型来说XGBoost对于用户购买行为预测是一个很好的选择。

表6 欠采样平衡方法下各模型预测效果
为了测试不同的k值对基于K-Means算法的欠采样数据平衡方法的影响,对比了不同k值基于K-Means算法的欠采样平衡方法下各个模型的预测效果,图3显示了各个模型在不同k值的基于K-Means算法的欠采样平衡方法的预测F1值。
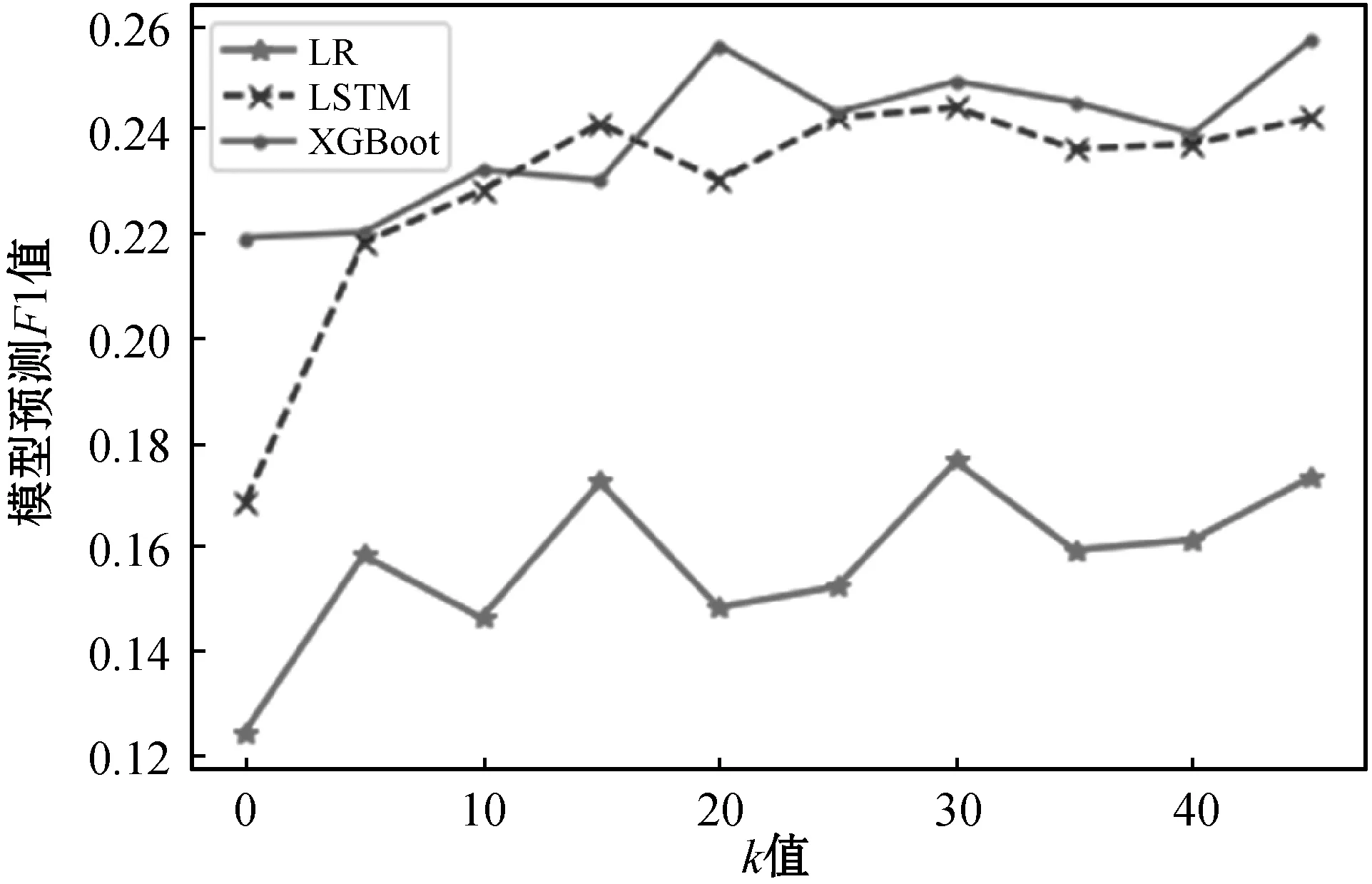
图3 不同k值的改进随机欠采样方法下模型的预测效果
可以看出在随机欠采样平衡方法中加入K-Means算法后数据平衡效果有了明显的提高。对比XGBoost预测模型、LSTM预测模型和LR预测模型在不同k值基于K-Means算法的改进欠采样平衡方法的F1值,k值为30时各个模型的预测F1值都比较高。表7给出加入k值为30的改进欠采样平衡方法后各个模型的预测效果。

表7 加入数据平衡算法模型预测效果
如图4所示,在改进欠采样数据平衡方法下各个模型的预测效果相较于随机欠采样数据平衡方法下的预测效果都有了明显的提升,其中LSTM预测模型预测F1值增长了48%,XGBoost预测模型预测F1值增长17%,LR预测模型预测F1值增长40%。在改进随机欠采样据平衡方法后LR预测模型和LSTM预测模型的预测效果提升较大。

图4 是否加入平衡方法各个模型预测F1值
为了提高预测模型对用户购买行为预测的准确率。本文结合XGBoost在过拟合处理、训练速度方面的优势和LSTM算法处理时序性问题的优势,通过集成方法将多种算法组合起来进行预测。图5展示了融合预测模型与各个单一预测模型的预测效果,融合模型相对于单一的预测模型预测效果有很大的提升,融合模型F1值相对于预测效果最好的XGBoost预测模型提升了9%。
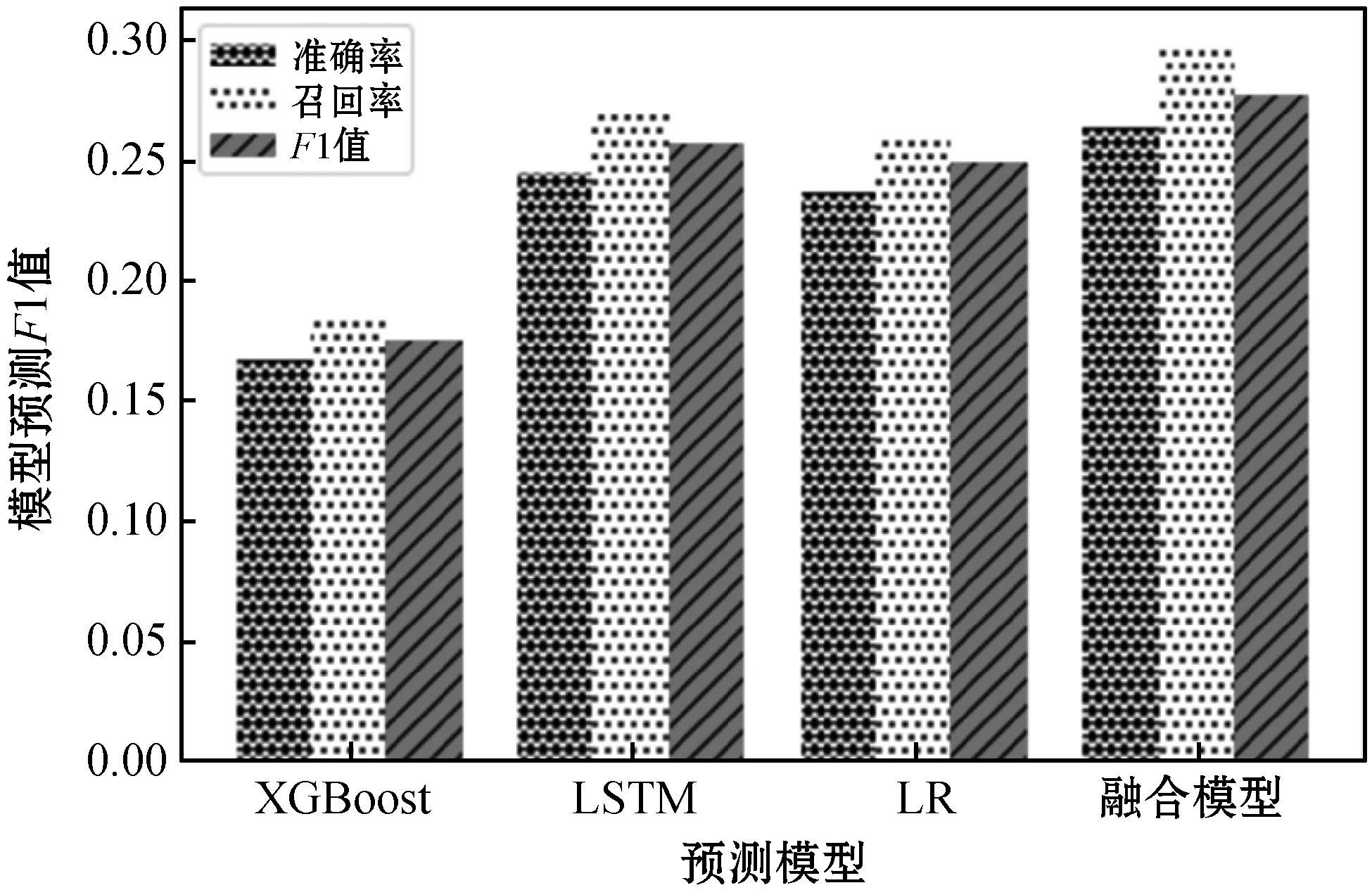
图5 融合模型与单一模型预测效果对比
为了进一步比较各个模型的稳定性,本文将测试数据集的5个预测周期的数据划分出5份测试数据集分别测试各个预测模型,预测结果如图6所示。单一预测模型预测效果最好的是XGBoost预测模型,XGBoost预测模型对各个测试集的预测F1值要高于LSTM预测模型和LR预测模型,但是XGBoost预测模型对不同测试集的预测F1值差别较大。对比XGBoost预测模型的预测效果,基于XGBoost的融合模型的预测效果和预测的稳定性都要优于单一的XGBoost预测模型。

图6 各个模型的预测F1值
4 结 语
对用户行为数据进行分析发现用户行为数据存在不平衡问题,正负样本的严重失衡会对模型的预测效果造成严重影响,对此针对数据的严重失衡问题提出基于K-Means算法的欠采样平衡方法,有效地解决了数据集的正负样本严重失衡的情况。
本文对LR算法、LSTM算法、XGBoost算法进行分析,比较了各个预测算法的特点,利用Stacking集成方法将这些算法进行融合获得融合预测模型算法。最后利用京东大数据提供的公开数据集设计了相关实验,从模型预测准确率、性能等各项指标评估了各个算法模型。实验表明模型基于XGBoost融合预测模型在预测稳定性和预测效果方面要明显优于传统的单一机器学习模型。
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
电子技术与软件工程(2016年23期)2017-03-06
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
金点子生意(2014年4期)2014-04-10
