
基于Scrapy-Redis的分布式爬取当当网图书数据
2022-10-10 01:23:14胡学军李嘉诚
软件工程 2022年10期
胡学军,李嘉诚
(上海理工大学机械工程系,上海 200082)
1 引言(Introduction)
随着互联网技术的蓬勃发展,变化之一就是网络数据的增长曲线就像指数函数图像一般,而网络爬虫是获取数据的手段之一。初期单机模式的网络爬虫技术将需要抓取的链接组成一个队列,再循环逐个地爬取,直至结束。
分布式爬虫技术就等同于同时使用多台单机网络爬虫抓取和处理数据,抓取相同页面信息时,显著地缩短了时间。随着爬虫手段的逐步优化和一次次技术上的迭代,许多大型的互联网公司(如百度、谷歌等)都研发出了自己的复杂的分布式网络爬虫,但是这一类资源是未开放的。目前公开可使用的爬虫资源,如Scrapy,就是典型的单机模式,此外还有很多类似的爬虫技术。当然也存在一些爬虫技术采用的是分布式模式,如Nutch、Igloo等,但是这类系统在实现的过程中是比较复杂的。
本文研究基于Scrapy-Redis框架,设计和实现一个针对当当网图书信息抓取的分布式系统。
2 基础理论(Basic theory)
2.1 Scrapy框架组件和工作原理
在网络爬虫开发中,Python是使用最广泛的设计语言,Scrapy则是使用最为简单和方便的一种。Scrapy框架是基于Twisted开发的,而Twisted是一款使用Python语言实现的基于事件驱动网络引擎框架。相较于其他网络爬虫技术,该框架的优势在于它是已经封装好的,同时能够执行多个任务,且抓取网站内容时速度很快,也能将抓取内容下载到本地,方便使用者使用。
Scrapy框架主要的组件就是作为核心的爬虫引擎(Scrapy Engine)、负责路由(URL)调度处理的调度器(Scheduler)、在互联网上下载所需要的数据时使用的下载器(Downloader),以及处理需求定义、页面解析等使用到的爬虫(Spider)组件;项目管道(Item Pipeline)组件作为下载下来的数据的加工厂,可以对其进行清除、存储和验证等操作;两个中间件(下载中间件和爬虫中间件)是连接组件的纽带。
Scrapy工作流程如图1所示,URL和下载数据在各组件之间的流走如图中的箭头方向所示(图中编号1—10为数据走向)。
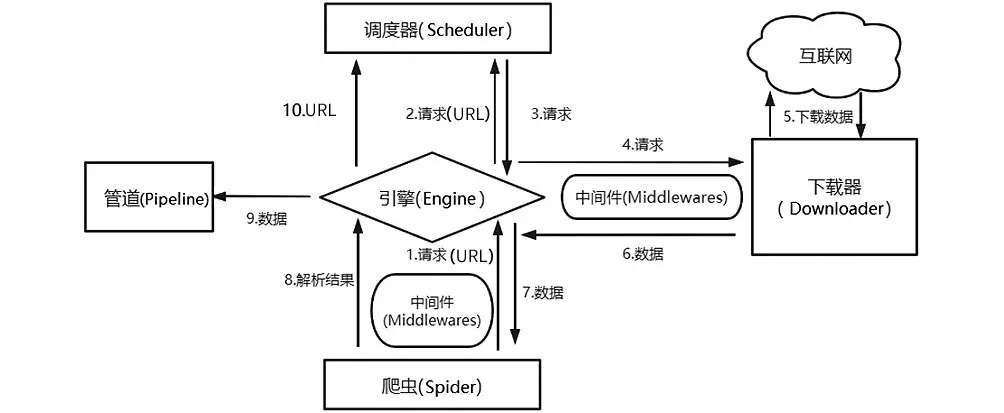
图1 Scrapy工作流程图Fig.1 Workflow chart of Scrapy
Scrapy的工作原理可以概括如下:爬虫先根据初始的需下载的网页URL到互联网上下载该网页数据;在整个下载数据过程中,新的要下载的网页URL会持续加入Scheduler中的等待下载队列里;爬虫按照下载队列的顺序一次抓取网页,直到下载队列为空。
2.2 网络爬虫的分布式架构技术
(1)Scrapy-Redis框架
Scrapy框架并不支持抓取URL在各个爬虫端之间共享,也就不支持分布式操作。在Scrapy单机爬虫系统中存在一个由deque模块实现的本地爬取队列Queue。这个队列是依靠Scheduler组件负责维护的,是独一无二的,并且它具有不被多个Scheduler共享的特性,造成了Scrapy框架不能实现分布式抓取数据。但是Scrapy框架具有易扩展的特点,通过Scrapy-Redis组件引入Redis数据库代替Scrapy框架的单机内存来存储待抓取的URL,Redis数据库自身又有能共享数据库给多个爬虫端的特性,这样就把抓取队列共享出去了。
Scrapy-Redis架构图如图2所示,它是Scrapy框架和Redis数据库的结合。
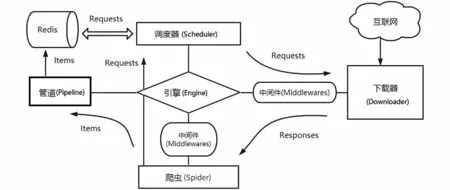
图2 Scrapy-Redis架构图Fig.2 Scrapy-Redis architecture diagram
(2)Scrapy-Redis框架爬虫的主流模式
分布式爬虫系统架构复杂多变,目前公认的两种主要分类形式:主从模式和对等模式。
对等模式字面上就可以理解,系统里每一台计算机都是平等的,它们都要参与爬虫工作,各自完成自己的任务,互不影响。每台计算机的任务通过哈希(Hash)函数计算分配。
主从模式是由一台主机和若干从机组成的,如图3所示,我们把主机叫作Master节点,把从机叫作Slave节点。主从模式把Redis数据库搭建在Master上,请求的判重、分配和数据的存储都交给Master,不执行抓取任务;Slave负责运行爬虫程序,并把新的请求发送给Master。本文采用的是主从模式。
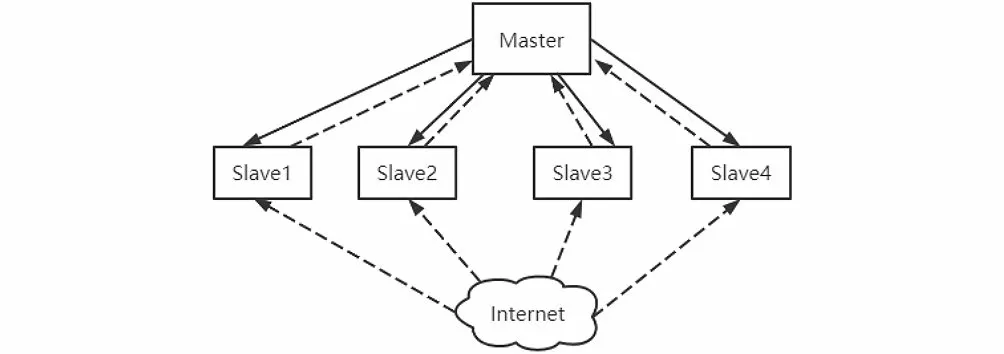
图3 主从分布式策略Fig.3 Master-Slave distributed strategy
3 布隆过滤器算法(Bloom Filter algorithm)
3.1 基本布隆过滤器原理
巴顿·布隆于1970 年提出了布隆过滤器算法,它可以描述为把所有元素存到一个集合里,然后去比较判断某一元素是否存在,其实现是依靠Hash函数能够把一个大的数据集映射到一个小的数据集上。它的优势就是让大规模的数据得到压缩,减少了存储所消耗的空间,同时查询时间也比其他算法短。
(1)算法描述
第一步是位数组的定义。布隆过滤器是将数据保存在位数组里,所以首先是位数组定义,然后设位数组长度为,各个位置初始值为0。
第二步是添加元素。假设独立的Hash函数个数是,布隆过滤器算法把想要添加的元素用Hash函数计算次,得到对应于位数组上的不同位置,将多个不相同的位置设为1,如图4所示。
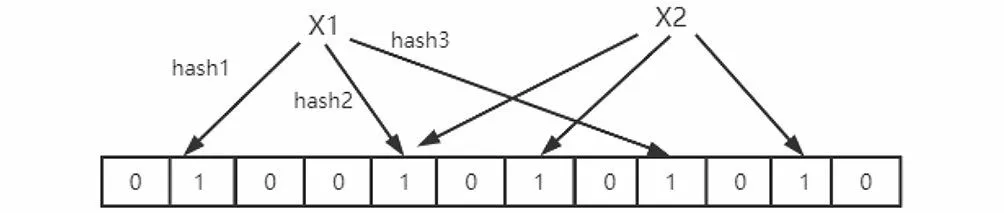
图4 添加元素Fig.4 Adding elements
第三步是查询元素。将要查询的元素执行和第二步一样的操作,通过Hash函数进行映射,也就是计算次,把得到的值对应地放到位数组上。假设这些位置上出现一个0,则可以判断该元素肯定不在我们要查询的集合中;如果这些位置全为1,则不能判断是否在集合中,因为布隆过滤器存在误判率。
(2)性能分析
布隆过滤器算法使用个相互独立的Hash函数,逐一地把原始数据集合中的元素映射到数组中。查阅相关文献了解到,如果存在一个元素S,其被错误判断为属于该集合的概率如式(1)所示。
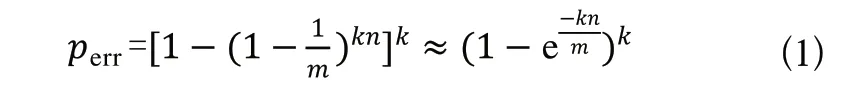
由式(1)可以看出,影响该值大小的三个因素:Hash函数个数、位数组长度和原始数据集合。当原始数据不断增加时,位数组长度也要和其同步线性增长,才能让误判率保持稳定。而Hash函数个数的最优解如式(2)所示。
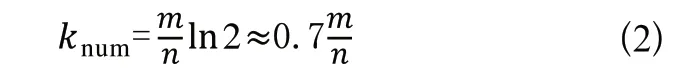
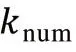
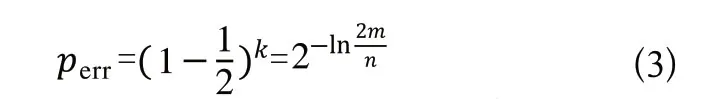
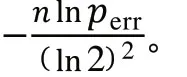
3.2 布隆过滤器算法实现
布隆过滤器算法的代码实现步骤如下所述。
第一步是初始化位数组,定义一个Init(self,size,HashCount)方法,其中size表示位数组长度,通过导入bitarray对象可以把二进制串转化为bitarray对象,然后其又能转化为bytes,实现字符串和二进制之间的转化;HashCount表示Hash函数的个数。采用集合(set)形式来表示算法对位数组的初始化。
第二步是对查询元素进行哈希计算,采用的是不同的Hash函数。先导入Murmurhash3,然后把该元素计算次,得到对应的哈希值。
第三步是验证第二步中要查询的元素是否存在,利用集合查找方法在位数组中进行查找操作。如果对应的位置上出现0,则认为要查询的元素不在集合中,执行第四步。
第四步是把URL添加进集合,定义一个add(self,item)方法实现该目标。
4 系统设计和实现(System design and implementation)
4.1 系统流程图
对当当网的网站结构进行分析,不难发现页面之间存在“父子”关系。我们把网页按不同层次进行处理,把页面内所有的其他链接归类成它的二级页面链接。从首页开始,逐级对剩下的页面进行搜索,把符合规则的链接加入待抓取队列中。系统基本流程图如图5所示。
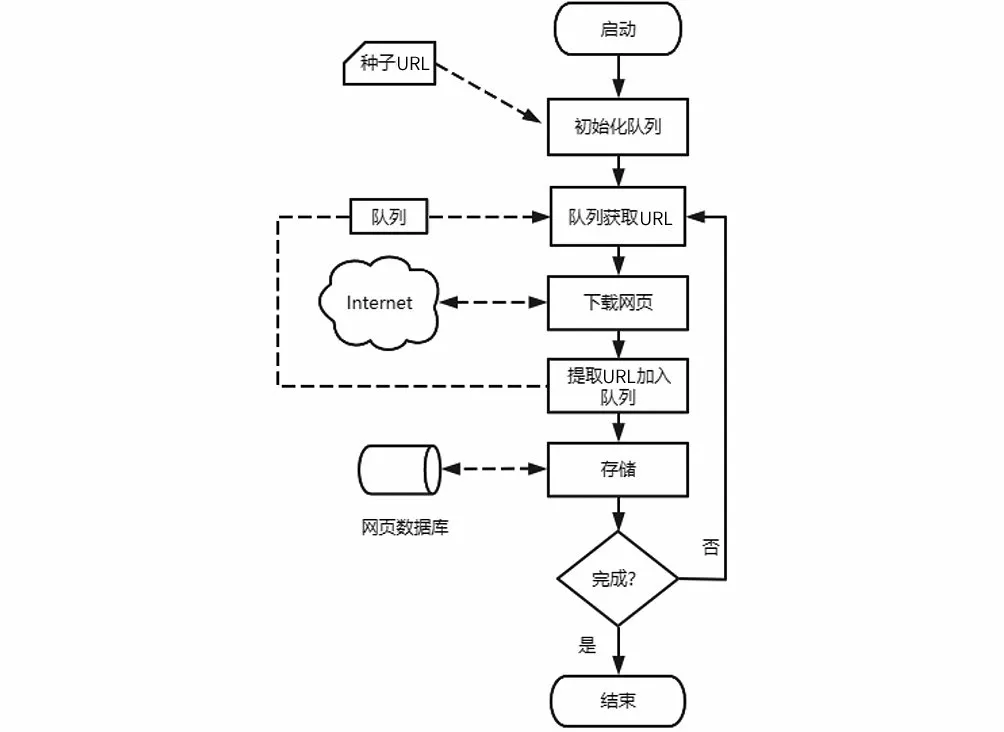
图5 系统基本流程图Fig.5 Basic flow chat of the system
4.2 数据库设计
(1)数据表设计
Scrapy爬虫下载数据后,通过Item_Loader机制把解析的数据存放到爬虫模型Item中,最后使用项目管道模块存储数据。如表1所示为数据字典设计。

表1 数据字典设计Tab.1 Data dictionary design
(2)数据存储
设计完数据字典以后,采用MySQL数据库来存储爬取到的数据,在Pipeline.py文件中编写Scrapy框架和数据库链接的代码及操作数据库的SQL语句。实现流程如下所述。
第一步:打开Scrapy和MySQL数据库的链接,使用的是open_spider(self,spider)方法,再赋值存储数据服务器的地址(host)、MySQL的端口号(port)、MySQL的用户名(user)、MySQL密码(password)、自定义数据库的名称(name)和字符集(utf8)。
第二步:链接Scrapy和MySQL数据库,引入第三方模块pymysql实现。
第三步:操作数据库,定义一个名为process_item(self,item,spider)的方法,通过Insert into语句来实现数据的存入。
第四步:关闭链接。
4.3 页面解析
Scrapy框架支持多种页面解析工具,本文使用XPath对抓取页面进行解析,主要代码如下所述。

4.4 系统测试和运行结果
在测试时,使用一台主机做Master,两台从机做Slave。由Master主机负责URL的调度队列和协调从机之间的抓取任务,Slave从机负责执行抓取程序,到互联网上下载页面数据并存入数据库。以当当网图书为例,运行1 小时后,抓取图书信息18,000余条,主要为图书的名称、作者、价格、封面和简介信息,如图6所示。
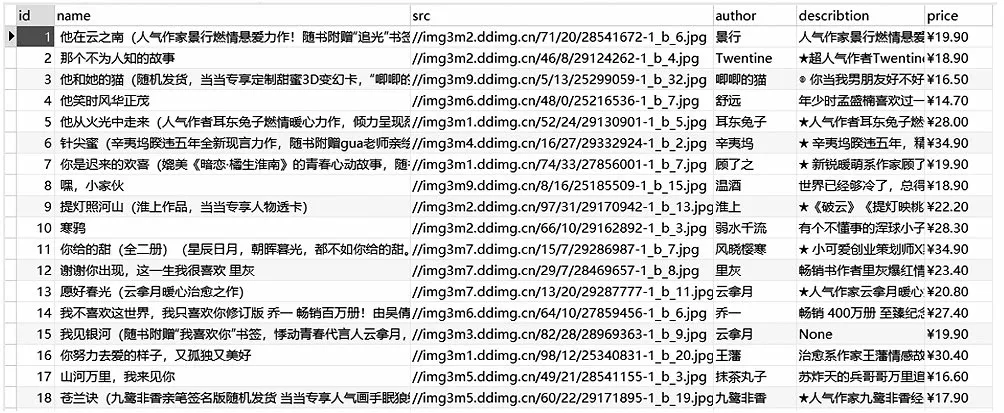
图6 存储在MySQL中的图书相关信息Fig.6 Book information stored in MySQL
5 结论(Conclusion)
互联网发展带来网络数据的大规模增长,网络爬虫也需要变得更加迅速、高效,才能达到使用要求,所以对分布式爬虫的研究具有一定的实用价值。本文从介绍Scrapy框架的组件及其功能入手,讲述了数据在组件之间流动的过程,分析了Scrapy-Redis组件实现分布式抓取数据的原理和主流模式。以抓取当当网图书信息为例,研究了爬行策略、爬虫设计、解析规则和布隆过滤器算法对抓取URL去重等的设计思路,构建了针对抓取当当网图书信息的主从式分布网络爬虫系统。
但是项目在实际运行过程中出现了令人不满意的问题:(1)Master主机对爬虫任务的管理并不理想;(2)布隆过滤器算法相比其他一般算法,在空间利用上更充分,查询时间也更短,但是误判率也是其非常明显的缺点,后续针对布隆过滤器算法URL去重方法,还需要进一步学习。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
电脑报(2022年13期)2022-04-12 00:32:38
现代信息科技(2021年21期)2021-05-07 02:54:12
文萃报·周二版(2020年32期)2020-09-02 07:25:38
电脑报(2020年24期)2020-07-15 06:12:41
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
初中生之友·中旬刊(2015年4期)2015-06-10 09:01:13
考试周刊(2012年88期)2012-04-29 04:36:47
