
基于深度匹配的由稀疏到稠密大位移运动光流估计
2022-09-30 12:44张道文张聪炫
自动化学报 2022年9期
陈 震 张道文 张聪炫 汪 洋
光流反映了图像序列像素点亮度的时空域变化与图像中物体运动及结构的关系,其不仅包含了被观察物体的运动参数,而且携带丰富的三维结构信息.因此,光流计算技术广泛引用于各类高级视觉任务,例如机器人视觉系统[1]、异常行为检测[2]、无人机导航与避障[3]和医学影像分析等[4].
20 世纪80 年代,Horn 等[5]首次提出光流概念和计算方法后,针对光流计算模型和优化方法的研究不断涌现.根据研究路线的不同,光流计算技术研究可大致分为3 类: 1)变分光流计算技术;2)图像匹配光流计算技术;3)深度学习光流计算技术.在光流计算研究早期,受益于变分模型能够产生稠密光流场且具有计算精度高、拓展性强等显著优点,变分光流计算技术成为主流方法.针对光照变化问题,Brox 等[6]提出基于图像梯度的守恒假设模型,提高了亮度突变下数据项的可靠性.针对光流计算的鲁棒性问题,Sun 等[7]提出基于非局部约束的光流估计模型,采用加权中值滤波在图像金字塔各层消除溢出点对光流计算的影响.针对全局优化模型对图像噪声敏感的问题,Drulea 等[8]设计全局与局部结合的优化策略,有效提高了光流计算的抗噪性.针对传统平滑模型易导致边缘模糊的问题,Perona等[9]提出基于图像结构张量的光流扩散模型,通过控制光流在图像边缘不同方向的扩散程度抑制了边缘模糊现象.针对运动边界的过度分割问题,Weickert 等[10]提出基于光流驱动的各向异性扩散策略,使得光流结果更加体现运动边缘细节.鉴于图像边缘和运动边界并不完全重合,Zimmer 等[11]联合图像梯度各项同性扩散与光流控制各向异性扩散策略设计自适应平滑项,使得光流估计结果既贴合图像边缘又充分体现运动边界.然而,由于该类方法需采用迭代运算最小化能量泛函,导致其时间消耗过大.
近年来,随着深度学习理论与技术的快速发展,基于卷积神经网络的光流计算技术成为研究热点.Dosovitskiy 等[12]首先构建了基于有监督学习的光流估计模型FlowNet,该研究验证了通过卷积架构直接估计原始图像光流的可行性.针对FlowNet模型光流估计精度较低的问题,Ilg 等[13]采用网络堆叠策略提高网络深度,并设计FlowNetSD 模型估计小位移运动光流,大幅提高了网络模型的光流预测精度.为降低网络模型的复杂度,Ranjan 等[14]将空间金字塔与卷积神经网络相结合,通过图像变形技术处理大位移运动,显著减小了模型的尺寸和参数量.针对卷积操作易导致光流估计结果过于平滑的问题,Hui 等[15]将金字塔特征提取网络与光流估计网络分开处理,通过引入正则化项保护了光流的边缘结构信息.针对遮挡区域光流估计的可靠性问题,文献[16]通过图像序列前向与后向光流耦合图像遮挡区域,并设计基于遮挡检测的光流估计网络模型,提高了运动遮挡图像序列光流估计鲁棒性.虽然深度学习光流模型在计算精度和效率等方面已取得突破性进展,但是该类方法通常需要大量标签数据训练模型参数,导致现阶段难以直接应用于现实场景的光流估计任务.
图像匹配光流计算技术是通过像素点匹配关系确定图像运动场,因此对大位移运动具有较好的准确性和鲁棒性.Brox 等[17]首先提出在光流估计能量泛函引入基于刚性描述子的匹配约束项,提高了刚性大位移运动场景下光流计算的准确性.针对传统匹配算法在弱纹理区域难以有效匹配的问题,Weinzaepfel 等[18]利用交错卷积与最大池化操作进行稠密采样求解像素点匹配关系,有效提高了弱纹理区域的光流计算精度.针对非刚性大位移运动光流计算的准确性问题,张聪炫等[19]提出基于非刚性稠密匹配的大位移光流计算方法,有效提高了非刚性大位移运动场景下光流估计的精度与鲁棒性.Hu 等[20]采用金字塔分层迭代优化策略求解图像局部块匹配关系,显著改善了光流估计的噪声问题.针对光流计算在遮挡、运动边界和非刚性运动等情况下易产生运动边界模糊的问题,Revaud 等[21]采用图像边缘驱动的稠密插值策略初始化光流估计能量泛函,实验证明该方法对大位移和运动遮挡具有很好的边缘保护作用.针对稠密插值模型易受匹配噪声影响的问题,Hu 等[22]提出基于分段滤波的超像素匹配光流估计方法,显著降低了匹配噪声对光流估计精度的影响.
现阶段,图像匹配光流计算方法已成为解决大位移运动光流计算准确性和可靠性问题的重要手段,但是该类方法在复杂场景、非刚性运动和运动模糊等图像区域易产生错误匹配,导致光流估计效果不佳.针对以上问题,本文提出基于深度匹配的由稀疏到稠密大位移光流计算方法,首先利用深度匹配计算初始稀疏运动场,然后采用邻域支持优化模型剔除错误匹配像素点,获得鲁棒稀疏运动场;最后对稀疏运动场进行稠密插值并最小化能量泛函求解稠密光流.实验结果表明本文方法具有较高的光流估计精度,尤其对大位移、非刚性运动以及运动遮挡等困难场景具有较好的鲁棒性.
1 基于深度匹配的鲁棒稀疏运动场
1.1 深度匹配
针对传统匹配模型在非刚性形变和大位移运动区域易产生匹配错误的问题,Revaud 等[23]提出基于区域划分的深度匹配方法,有效提高了非刚性形变和大位移运动区域的像素点匹配精度.如图1所示,深度匹配首先将传统采样窗口划分为N个子区域,然后根据子区域的相似性分别优化各子区域的位置,进而利用子区域位置确定像素点的匹配关系.
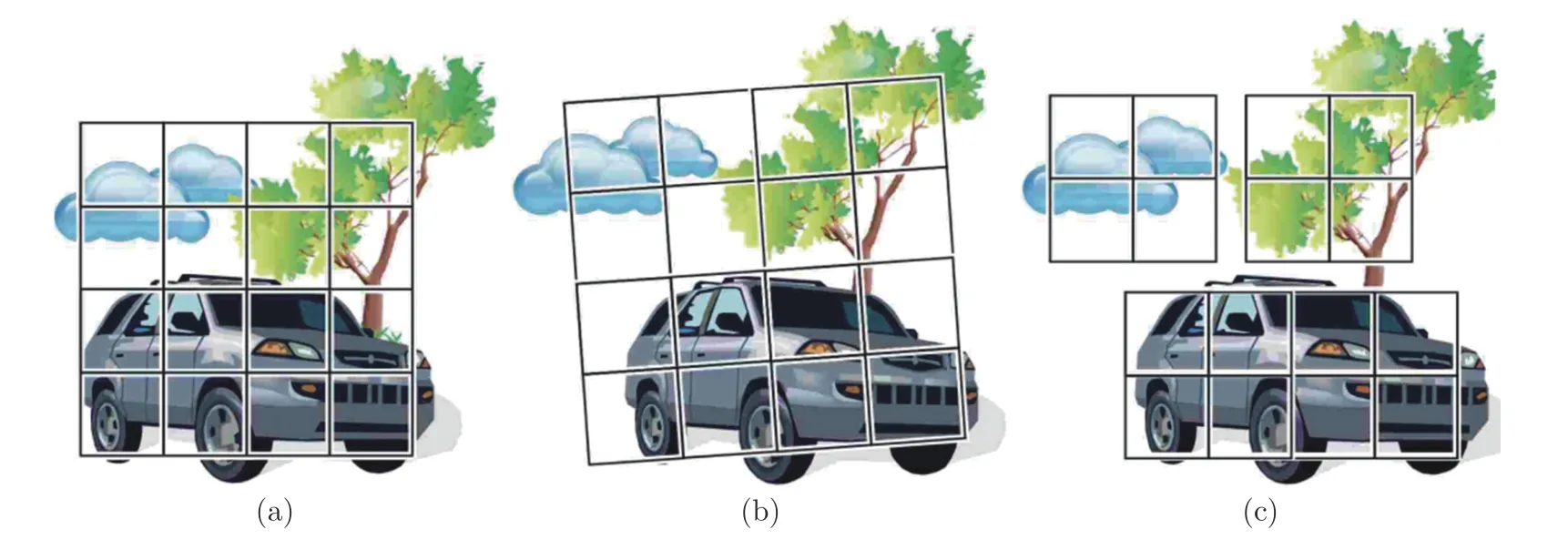
图1 基于区域划分的深度匹配采样窗口示意图 ((a)参考帧采样窗口;(b)传统匹配方法采样窗口;(c)深度匹配算法采样窗口)Fig.1 Illustration of the deep matching sample window based on the regional division ((a) Sample window of the reference frame;(b) Sample window of the traditional matching method;(c) Sample window of the deep matching method)
假设I0和I1分别表示图像序列相邻两帧图像,首先将I0和I1分解为N个非重叠子区域,每个子区域由4 个相邻像素点构成,根据式(1)计算各子区域的匹配关系,即
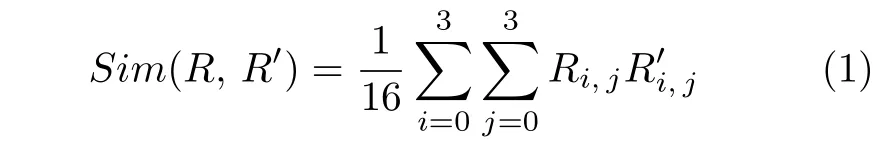
其中,R与R′分别表示I0和I1中互相匹配的两个子区域,表示I0和I1中的像素点描述子,Sim(R,R′)是根据区域相似性确定的子区域匹配关系.则深度匹配的实现过程主要包括以下两步:首先,如图2(a)所示,每四个相邻的子区域经金字塔不断向上层聚合,确定I0和I1中更大的区域匹配关系,直到金字塔顶端;然后,如图2(b)所示,定义相互匹配的区域中心像素点为匹配像素点,由金字塔顶层自上而下的检索各层金字塔中像素点匹配关系,统计各层金字塔中匹配像素点坐标得到稀疏运动场.

图2 深度匹配金字塔采样示意图 ((a)第1 帧子区域聚合;(b)第2 帧子区域聚合)Fig.2 Illustration of the pyramid sampling based deep matching ((a) Subregion polymerization of the first frame;(b) Subregion polymerization of the second frame)
鉴于深度匹配模型在非刚性形变和大位移运动区域相对传统匹配方法具有更高的像素点匹配精度和可靠性,本文首先采用深度匹配模型计算图像序列相邻两帧图像的初始匹配结果.
1.2 基于邻域支持模型的匹配优化
虽然深度匹配能够提高非刚性形变和大位移运动区域的像素点匹配精度,但是由于图像中常常包含噪声、光照变化等因素的干扰,导致其匹配结果可能存在错误匹配像素点.为了剔除初始匹配结果中的错误匹配像素点,本文采用基于运动统计策略的图像匹配优化方法对初始匹配结果进行优化[24],能够有效提高像素点匹配的准确性与可靠性.
假设相邻两帧图像中运动是连续平滑的,那么图像局部区域内中心点与其邻域像素点的运动应一致,则与匹配像素点保持运动一致性的邻域支持像素点数量可以表达为
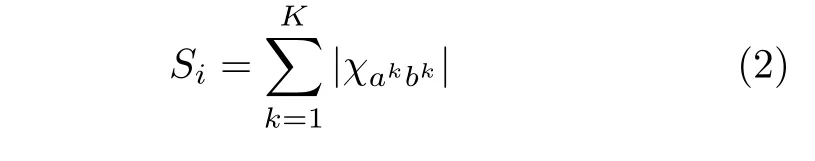
其中,K表示与匹配像素点xi一起运动的邻域个数,a表示第1 帧图像中任意局部区域,b是区域a在下一帧图像中的对应匹配区域,ak →bk表示相邻两帧图像中与匹配像素点xi保持相同几何关系的 第k对匹配区域,表示匹 配 区 域ak →bk内互相匹配的像素点个数.由于本文将深度匹配中各像素点匹配过程近似看作互不干扰的独立事件,由此可知Si近似二项分布

其中,n表示匹配像素点xi各邻域内平均匹配像素点数量.pt=Dt+β(1-Dt)m/M表示a→b为正确匹配区域时,匹配区域a→b内一对像素点互相匹配的概率;pf=β(1-Dt)m/M表示a→b为错误匹配区域时,匹配区域a→b内一对像素点互相匹配的概率.式中,符号Dt表示深度匹配结果的匹配正确率,β表示概率参数,m表示区域b中匹配像素点数量,M表示根据深度匹配计算的稀疏运动场中匹配像素点总数.
由式(3)可知,正确匹配与错误匹配像素点的邻域支持像素点数量具有很大差异性.因此,通过统计任意匹配像素点的邻域支持像素点数量可以判断该像素点是否匹配正确.本文使用标准差与期望值量化邻域支持优化模型对正确匹配像素点与错误匹配像素点的甄别力,可表示为
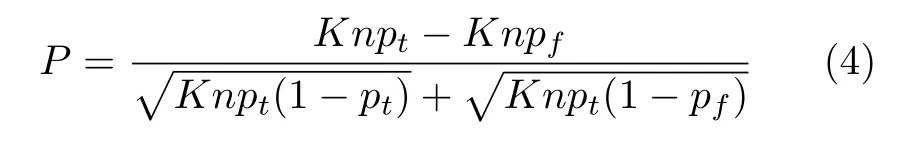
其中,P表示邻域支持模型对匹配像素点的甄别力.由式(4)分析可得P值大小与各变量的变化关系如下所示:

由式(5)可知,随着邻域支持匹配像素点数量的增加,邻域支持模型对正确匹配像素点与错误匹配像素点的甄别力可以扩展到无穷大.此外,邻域支持模型的优化能力还与深度匹配结果的匹配正确率相关,正确率越高,优化能力越强.因此,采用邻域支持优化模型剔除错误匹配像素点能够有效提高稀疏运动场的匹配准确度与鲁棒性.
1.3 基于网格化的稀疏运动场优化
对初始稀疏运动场进行邻域支持优化的目的是剔除错误匹配像素点,但是基于像素点的置信度估计会导致计算成本的显著增加.为了降低计算成本,本文引入网格框架优化邻域支持模型,使得置信度估计独立于图像特征点,而仅与划分的图像网格数量相关,以提高邻域支持优化模型的计算效率.
首先使用网格近似法,将连续两帧图像分别划分为n×n的非重叠图像网格.然后定义前后帧图像中匹配像素点数量最多的网格为候选匹配网格,根据式(6)分别计算候选匹配网格的匹配置信度,即

其中,N表示划分的非重叠图像网格数量,True 表示图像网格i与j匹配正确,False 表示图像网格i与j匹配错误.是匹配网格判断函数,其中,nij表示图像网格i与j相邻网格内匹配像素点的平均数量,α是阈值权重系数.
根据网格匹配结果,本文将相邻两帧图像中像素点坐标皆位于正确匹配网格内的匹配像素点定义为匹配正确的像素点,并将其他匹配像素点剔除,获得超鲁棒稀疏运动场.图3 分别展示了深度匹配模型与本文提出的基于邻域支持的匹配模型针对KITTI 数据库大位移运动图像序列的运动场估计结果.从图中可以看出,本文方法能够有效剔除初始稀疏运动场中的错误匹配像素点对,具有计算精度高、鲁棒性好等显著优点.

图3 本文邻域支持模型运动场优化效果 (蓝色标记符表示匹配正确像素点,红色标记符表示匹配错误像素点)Fig.3 Optimization effect of the motion field by using the proposed neighborhood supporting model (The blue mark indicates the correct matching pixels,the red mark denotes the false matching pixels)
2 基于稠密插值的大位移运动光流估计
2.1 由稀疏到稠密光流估计模型
虽然根据网格化邻域支持模型优化得到的图像序列运动场包含鲁棒光流信息,但是该运动场是稀疏的.现有的图像匹配光流计算方法通常根据像素点的欧氏距离进行插值,以获取稠密光流场.但是由于传统的插值模型仅考虑像素点的绝对距离,因此易导致插值结果出现图像与运动边界模糊的问题.为了保护光流结果的图像与运动边界特征,本文利用边缘保护距离进行由稀疏到稠密插值.
根据局部权重仿射变换原理,采用式(8)对图像序列稀疏运动场进行稠密插值计算光流场
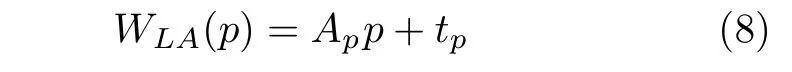
其中,p表示第1 帧图像中任意像素点,符号Ap与tp是像素点p的仿射变换参数,可通过式(9)建立超定方程组求解.

其中,ρpm,p表示像素点pm与p之间所有可能路径,C(ps) 表示运动边缘检测图中像素ps的值,若ps位于运动边缘则C(ps)的值极大,反之为零.由于每个像素点都基于其邻近已知的匹配像素点进行插值,因此能有效保护运动边界.
为了提高插值效率,本文首先根据式(10)对像素点进行聚类,将第1 帧图像中所有像素点分配到距离最近的匹配像素点.然后查找距离任意像素点p最近的匹配像素点pm,并利用匹配像素点pm的仿射变换参数计算像素点p的第2 帧图像对应匹配像素点p′.以上操作仅需计算稀疏运动场中所有匹配像素点的仿射变换参数,即可根据局部像素点聚类插值计算稠密运动场,降低了插值计算的复杂度.最后,为获得平滑的稠密光流,采用式(11)中的能量泛函对稠密运动场进行全局优化,得到最终的稠密光流结果.

式(11)中,w=(u,v)T表示估计光流,Ψ 是惩罚函数,j0为符合亮度守恒假设的运动张量分量,γ为梯度守恒权重,jxy为符合梯度守恒的运动张量分量,∂为平滑项局部平滑权重.
2.2 计算步骤
根据前文叙述,本文由稀疏到稠密光流估计方法的计算步骤如下:
步骤 1.输入图像序列相邻两帧图像I0和I1;
步骤 2.将I0和I1分解为N个非重叠子区域,每个子区域由4 个相邻像素点构成,根据式(1)计算各子区域的匹配关系;
步骤 3.建立图像金字塔,将相邻子区域由金字塔底层向上层聚合,确定图像I0和I1中更大的区域匹配关系,直到金字塔顶层;
步骤 4.定义相互匹配的区域中心像素点为匹配像素点,由金字塔顶层自上而下检索各层金字塔中像素点匹配关系,得到初始稀疏运动场;
步骤 5.根据式(2)计算与匹配像素点保持运动一致性的邻域支持像素点数量,并由式(3)甄别正确匹配与错误匹配像素点;
步骤 6.引入网格框架优化模型,通过式(6)和式(7)剔除错误匹配网格中的像素点,求解鲁棒稀疏运动场;
步骤 7.根据式(10)计算图像匹配像素点之间的边缘保护距离,根据边缘保护距离进行像素点聚类,将图像I0中所有像素点分配到其距离最近的匹配像素点;
步骤 8.根据式(9)建立超定方程组求解所有匹配像素点的仿射变换参数;
步骤 9.通过式(8)进行由稀疏到稠密插值计算初始稠密运动场;
步骤 10.将初始稠密运动场代入式(11)中能量泛函进行全局优化迭代,输出最终的稠密光流结果.
3 实验与分析
3.1 光流评价指标
分别采用MPI-Sintel 和KITTI 评价标准对本文方法光流估计效果进行综合测试分析,光流计算结果评价指标如下:
MPI-Sintel 评价标准采用平均角误差(Average angular error,AAE)和平均端点误差(Average endpoint error,AEE)对光流估计结果进行量化评价,其中,AAE 反映估计光流整体偏离光流真实值的角度;AEE 反映估计光流整体偏离光流真实值的距离.

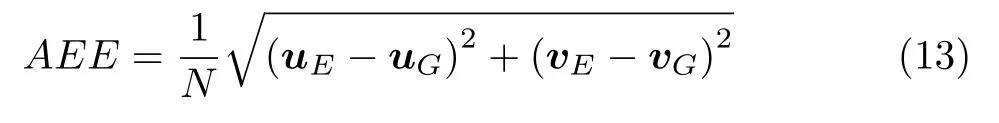
式中,(uE,vE)T表示光流估计结果,(uG,vG)T表示光流真实值,N表示图中像素点数量.
KITTI 评价标准采用平均端点误差(AEE)和异常值百分比(Percentage of outliers)对光流估计结果进行量化评价,异常值百分比表示光流估计值偏离真实值超过一定阈值的离群像素点占整幅图像的百分比:

其中,NOC和ALL分别表示非遮挡区域与整幅图像中像素点个数,P(AEE1>3)表示光流平均端点误差大于3 个像素的像素个数,outnoc和outall分别表示非遮挡区域和包含遮挡区域光流异常值百分比.
3.2 对比方法
为了验证本文方法对大位移光流的估计精度,分别选取Classic+NL[7]、DeepFlow[18]、EpicFlow[21]和FlowNetS[12]等代表性光流计算方法进行量化对比与分析.其中Classic+NL 是典型的变分光流计算方法,其在光流估计过程中采用加权中值滤波消除金字塔分层光流计算产生的异常值,本文实验设定其金字塔分层数为6 层.DeepFlow 是基于特征匹配与金字塔变形策略相结合的光流计算方法,本文在对比实验中设定金字塔采样系数为0.95.Epic-Flow 采用基于匹配像素点数量的分段刚性插值模型为光流初始化提供准确的先验知识,本文实验选取各匹配像素点的200 个邻域匹配像素点计算插值参数.FlowNetS 是基于卷积神经网络的深度学习光流计算模型,在具有大量训练数据的情况下能够获取较好的光流估计效果.
3.3 参数设置与分析
本文方法关键参数主要包括图像初始化网格划分数量N 和阈值权重系数α.本节以KITTI 数据集000016 序列和000017 序列的AEE 误差为例,分别讨论图像网格划分和阈值权重系数对光流估计结果的影响.
图4 分别展示了不同图像网格划分数量和阈值权重系数时本文方法光流估计结果的AEE 误差变化.从图4(a)中可以看出,随着图像网格划分数量的增加,本文方法光流误差AEE 呈现先减小后增加的趋势,这是由于随着网格划分数量的增加,网格框架对图像的划分变得更加细致,使得邻域支持优化模型更贴合局部运动平滑假设.但是当网格划分数量过多时,由于难以准确统计匹配像素点周围的邻域支持匹配像素点,导致光流估计精度下降.因此,本文设置图像初始化网格划分数量为14×14.从图4(b)中可以看出,本文方法对阈值权重系数的变化并不敏感,仅当阈值权重系数过大时,会导致部分正确匹配像素点被误判断为错误匹配点,导致光流估计精度下降.因此,本文设定阈值权重系数α=10.
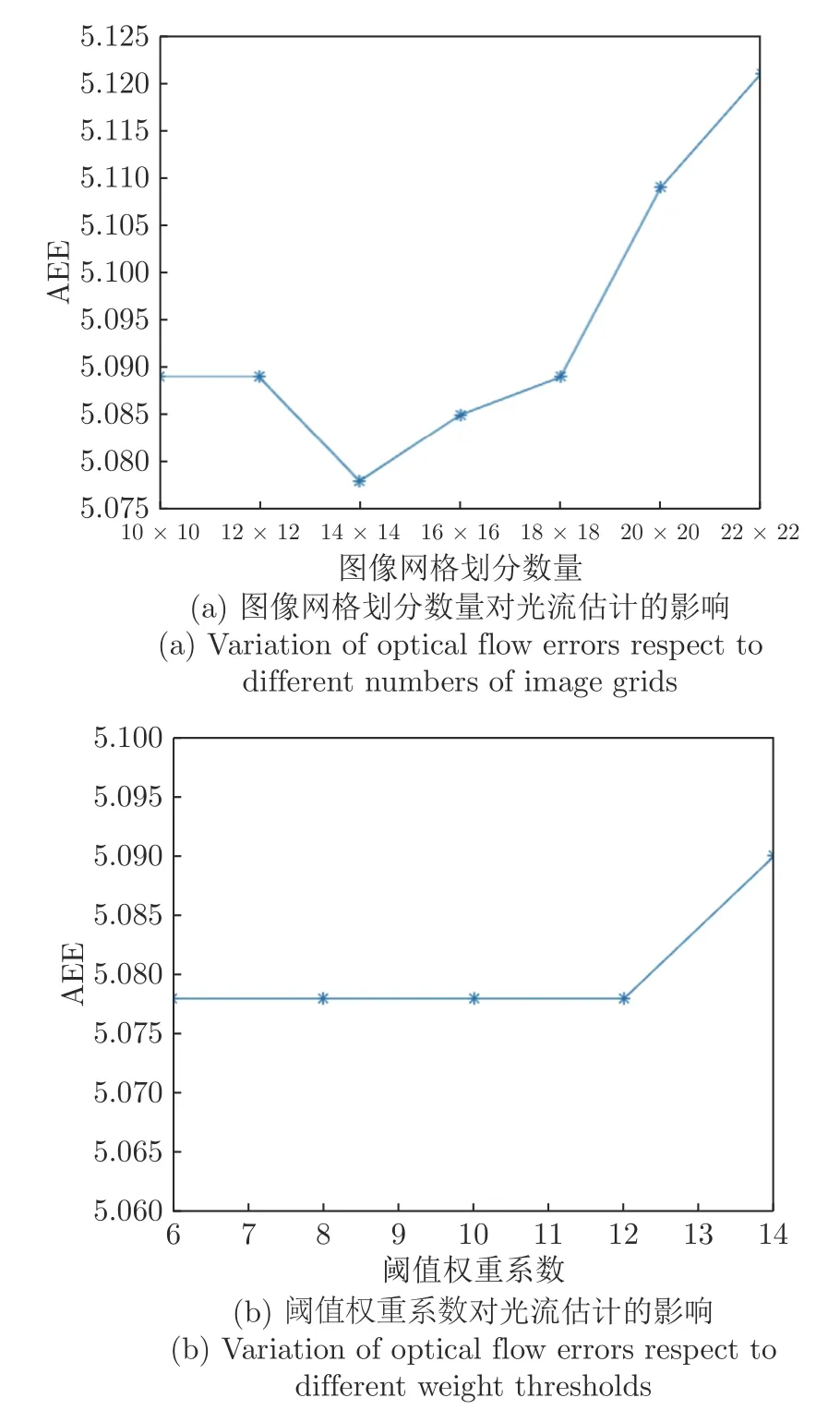
图4 不同参数设置对本文光流估计精度的影响Fig.4 Variation of optical flow estimation results respect to different parameters
3.4 MPI-Sintel 数据库实验
MPI-Sintel 数据库测试图像集包含非刚性形变、大位移、光照变化、复杂场景以及运动模糊等困难场景,因此是光流估计领域最具挑战的评价数据库之一.为了验证本文方法针对非刚性形变和大位移运动等困难场景光流估计的准确性与鲁棒性,利用MPI-Sintel 数据库提供的23 个标准测试序列对本文方法以及各对比方法进行综合测试.
表1 分别列出了本文方法与其他对比方法针对MPI-Sintel 测试图像集的光流误差对比结果.从表中可以看到,由于Classic+NL 算法仅采用金字塔分层策略优化变分光流能量泛函,因此对非刚性形变和大位移运动较敏感,导致其光流估计误差较大.DeepFlow 和EpicFlow 算法相对Classic +NL 算法在光流计算精度上有明显提升,说明基于匹配策略的光流计算方法在非刚性形变与大位移运动场景具有更好的估计效果.受益于MPI-Sintel 数据库提供了较充足的训练样本,能够满足深度学习光流计算模型FlowNetS 的训练需求,该方法光流估计精度较高.本文方法光流估计精度最高,说明本文方法针对非刚性形变与大位移运动具有更好的光流估计准确性与鲁棒性.

表1 MPI-Sintel 数据库光流估计误差对比Table 1 Comparison results of optical flow errors on MPI-Sintel database
为了对比分析本文方法和各对比方法针对非刚性大位移和运动遮挡场景的光流估计效果,表2 中分别列出了不同方法针对Ambush_5,Cave_2,Market_2,Market_5 和Temple_2 等包含大位移、运动遮挡和非刚性形变等困难运动场景图像序列的光流误差对比结果.从表中可以看出,Classic +NL 算法针对五组测试序列的平均误差较大,说明该方法针对困难运动场景的光流估计效果较差.FlowNetS 方法的平均AAE 和AEE 误差均最大,主要由于该方法在Ambush_5 和Cave_2 序列的误差大幅高于其他方法,说明FlowNetS 算法针对非刚性大位移运动的光流估计效果较差.Deep-Flow 与EpicFlow 算法光流估计AEE 误差较小,说明该类方法采用像素点匹配计算策略对大位移运动具有很好的定位作用.本文方法的平均误差最小,仅针对Temple_2 序列的AEE 误差略大于Deep-Flow 算法,但本文方法针对Cave_2,Market_5序列的AEE 误差大幅小于DeepFlow 算法,且本文算法在其他所有测试序列均取得最优表现,说明本文方法针对非刚性大位移和运动遮挡场景具有更好的光流估计精度与鲁棒性.
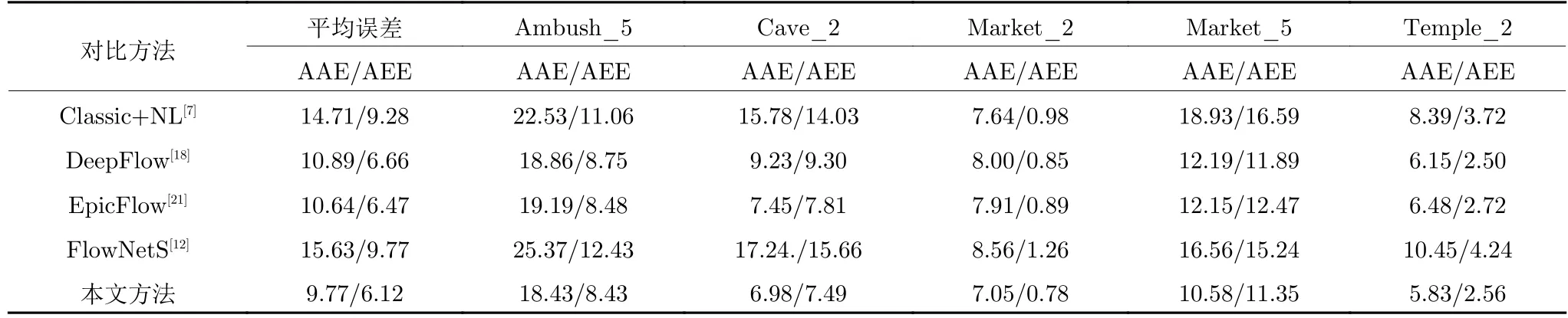
表2 非刚性大位移与运动遮挡图像序列光流估计误差对比Table 2 Comparison results of optical flow errors on the image sequences including non-rigidly large displacements and motion occlusions
图5 分别展示了本文方法和各对比方法针对Ambush_5,Market_2,Market_5,Cave_2,Temple_2 等包含非刚性大位移与运动遮挡场景的图像序列光流估计结果.从图中可以看出,Classic+NL 算法在背景区域的光流计算效果较好,但是在非刚性形变和大位移运动区域光流估计结果存在明显错误.EpicFlow 和DeepFlow 算法在大位移运动区域的光流估计效果优于Classic+NL 算法,但是由于这两种方法的匹配模型均是建立在刚性运动假设下,导致其在非刚性运动区域光流估计结果不准确.虽然FlowNetS 算法的光流估计精度较高,但该方法光流结果存在明显的过度平滑现象,难以准确反映目标与场景的边界.从图中不难看出,本文方法光流估计效果较好,尤其在ambush_5 序列人物的头部和手臂,market_2,market_5 人物的腿部,cave_2 序列人物的腿部和武器,temple_2序列飞行龙的翅膀等非刚性形变和大位移运动区域光流估计结果明显优于其他对比方法,说明本文方法针对非刚性形变和大位移运动等困难场景具有更高的光流估计精度与鲁棒性.

图5 非刚性大位移与运动遮挡图像序列光流估计结果Fig.5 Optical flow results of the image sequences including non-rigidly large displacements and motion occlusions
3.5 KITTI 数据库实验
KITTI 数据库由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,用于评测立体匹配、光流、场景流、目标检测、目标跟踪等各类计算机视觉算法在车载现实场景下的表现性能.由于KITTI数据库由包含强烈光照变化和大位移运动的真实场景图像序列组成,因此是目前最具挑战的光流评测数据库之一.为了进一步验证本文方法在现实场景下的光流估计准确性与可靠性,采用KITTI 数据库提供的测试图像序列对本文方法和各对比方法进行综合测试分析.
表3 分别列出了本文方法与各对比方法针对KITTI 数据库测试图像序列的光流计算误差统计结果.其中,AEEnoc表示图像中非遮挡区域像素点的AEE 结果,AEEall表示图像中所有像素点的AEE结果.可以看出,由于FlowNetS 算法没有针对KITTI数据集进行训练,导致其误差较大.DeepFlow 与EpicFlow 算法由于添加了像素点匹配信息,整体结果优于Classic+NL 算法,但是由于部分区域存在像素点匹配不准确的原因,导致其精度低于本文方法.本文方法针对KITTI 测试序列各项评估指标均取得最优表现,说明本文方法具有更好的光流估计精度与鲁棒性.
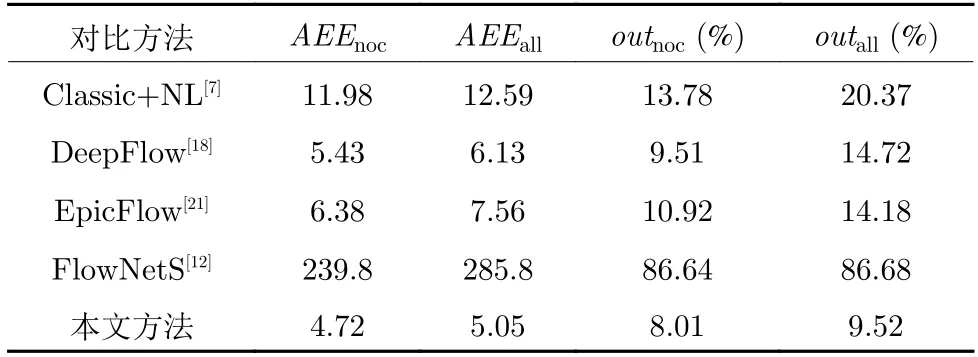
表3 KITTI 数据库光流估计误差对比Table 3 Comparison results of optical flow errors on KITTI database
图6 分别展示了本文方法和各对比方法针对000008、000010、000023、000043、000059、000085等KITTI 数据库测试图像序列的光流误差图,图中蓝色到红色表示光流误差由小到大.从图中可以看出,由于缺乏真实场景训练样本,FlowNetS 算法误差最大,说明基于深度学习的光流计算模型目前还难以应用于没有真实值的现实场景.Classic +NL 算法在背景区域的光流计算效果较好,但是针对发生大位移运动的车辆区域,光流估计效果较差.DeepFlow 和EpicFlow 算法相对Classic+NL 算法在大位移运动区域的光流计算精度有明显提升,说明基于匹配策略的光流计算方法在大位移运动场景具有更好的估计效果.本文方法与其他方法相比,红色的大误差区域最少,光流估计效果最好.尤其在包含大位移运动的车辆区域,光流估计结果明显优于其他对比方法,说明本文方法针对包含非刚性形变和大位移运动的真实场景具有更高的光流估计精度与鲁棒性.

图6 KITTI 数据库测试图像序列光流误差图Fig.6 Optical flow error maps of KITTI dataset
3.6 消融实验
为验证本文方法提出的网格化邻域支持匹配优化、基于边缘保护距离的由稀疏到稠密插值以及光流计算全局优化对非刚性大位移和运动遮挡场景光流计算效果的提升作用,本文分别采用MPI-Sintel 数据库提供Alley_2,Cave_4 和Market_6 图像序列对本文方法进行消融实验测试.表4 分别列出了本文方法和不同消融模型的AEE 误差对比结果,其中,无匹配优化表示本文方法去除网格化邻域支持匹配优化模型、无稠密插值表示本文方法去除基于边缘保护距离的由稀疏到稠密插值模型、无全局优化代表本文方法去除全局能量泛函优化模型.从表4 中可以看出,去除匹配优化、稠密插值以及全局优化模型后会导致本文方法的光流估计精度出现不同程度的下降,说明本文提出的网格化邻域支持匹配优化策略、基于边缘保护距离的由稀疏到稠密插值模型以及光流计算全局优化方法对提高非刚性大位移运动和运动遮挡场景光流估计精度均有重要作用.
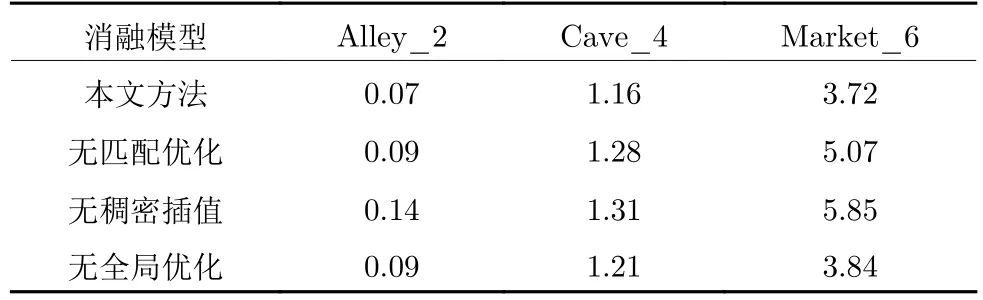
表4 本文方法消融实验结果对比Table 4 Comparison results of the ablation experiment
图7 分别展示了本文方法和不同消融模型针对Alley_2,Cave_4 和Market_6 图像序列的光流计算结果.从图中可以看出,去除网格化邻域支持匹配优化模型后本文方法在大位移运动区域的光流估计效果下降明显,说明网格化邻域支持匹配优化能够显著提高大位移运动光流估计的精度与鲁棒性.此外,去除基于边缘保护距离的由稀疏到稠密插值模型后,光流计算结果存在明显的边缘模糊现象,说明本文提出的边缘保护插值模型能够有效改善光流估计的边缘模糊问题.最后,去除全局优化模型后,本文方法光流估计结果丢失了大量的运动与结构信息,说明全局优化模型能够显著提高光流估计的全局精度与效果.

图7 MPI-Sintel 数据库消融实验光流图Fig.7 Optical flow results of the ablation experiment tested on MPI-Sintel database
3.7 时间消耗与复杂度分析
为了对本文方法与其他方法进行综合对比分析,表5 分别列出了本文方法与其他对比方法针对MPI-Sintel 和KITTI 数据库测试图像集的平均时间消耗对比.

表5 本文方法与其他方法时间消耗对比(s)Table 5 Comparison of time consumption between the proposed method and the other approaches (s)
由表5 中不同方法的时间消耗对比结果可以看出,受益于卷积神经网络的实时计算优势,FlowNetS方法的时间消耗最小,计算效率最高.Classic +NL 算法由于采用金字塔分层变形策略优化变分光流计算,导致其时间消耗最大,计算复杂度最高.DeepFlow 和EpicFlow 算法由于仅采用少量迭代运算对匹配运动场进行全局优化,因此时间消耗低于本文方法.本文方法时间消耗大于FlowNetS,Deep-Flow 和EpicFlow 三种方法,但大幅少于Classic +NL 算法.在本文方法中,由于匹配优化和稠密插值模型仅包含简单的线性计算和逻辑运算,因此计算复杂度较低,时间消耗较小.为避免光流计算陷入局部最优,本文方法采用全局优化模型对插值后的稠密运动场进行迭代更新,虽然全局优化策略能够提高光流估计的整体精度,但是由于采用大量迭代运算更新光流参数,导致时间消耗较大、计算复杂度较高.
4 结束语
本文提出了一种基于深度匹配的由稀疏到稠密大位移运动光流计算方法.首先,使用深度匹配模型求解相邻两帧图像间初始稀疏运动场;然后采用邻域支持模型对初始运动场进行优化获得鲁棒稀疏运动场;最后对稀疏运动场进行由稀疏到稠密插值,并根据全局能量泛函求解全局最优化稠密光流.实验结果表明本文方法具有较高的光流估计精度,尤其针对运动遮挡和非刚性大位移等困难运动场景具有更好的鲁棒性和可靠性.
虽然本文方法针对大位移、运动遮挡与非刚性形变等困难场景图像序列的光流估计精度优于各对比光流计算方法,但是由于本文方法须对稠密光流进行全局迭代优化,因此导致时间消耗较大.为提高本文方法的使用价值,后续将研究GPU 并行加速计算策略,在提高非刚性大位移运动光流估计精度的同时大幅减少时间消耗,尽可能满足工程实际需求.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
农业工程学报(2022年7期)2022-07-09
小型微型计算机系统(2021年12期)2021-12-08
少儿美术·书法版(2021年9期)2021-10-20
逻辑学研究(2021年3期)2021-09-29
导航定位与授时(2020年4期)2020-07-29
计算机应用与软件(2018年12期)2018-12-13
学苑创造·A版(2017年1期)2017-01-19
爆笑show(2014年7期)2014-09-03
