
基于轻量化重构网络的表面缺陷视觉检测
2022-09-30 12:43余文勇姚海明
自动化学报 2022年9期
余文勇 张 阳 姚海明 石 绘
传统的机器学习方法可以有效解决多种工业产品质量检测问题,比如轴承[1]、手机屏[2]、卷材[3]、钢轨[4]、钢梁[5]等,这类方法通过人为设计特征提取器来适应特定产品图像样本数据集,将特征输入分类器和支持向量机[6]、神经网络[7]来判别产品是否有缺陷.但当被检测产品的表面缺陷出现诸如复杂背景纹理(包括规则的和非规则的)、缺陷特征尺度变化大、缺陷区域特征和背景特征相似等问题时(如图1 所示),传统的机器学习方法依赖人工特征对产品图像样本的表示能力,不适应这类复杂的检测需求.图1(a)为暗缺陷,图1(b)为明缺陷.图1(c)为覆盖图像的大尺度缺陷.图1(d)为微小缺陷.图1(e)为色差小的缺陷.图1(f)~ (g)为与纹理相似的缺陷.图1(h)为模糊缺陷.

图1 各种表面缺陷Fig.1 Various surface defects
自从AlexNet[8]被提出后,以卷积神经网络(Convolutional neural network,CNN)为基础的深度学习方法成为表面缺陷检测领域的主流方法[9-12].卷积神经网络不仅可以自动学习图像特征,而且通过多个卷积层的叠加,可以抽取更抽象的图像特征,相对人工设计的特征提取算法具有更好的特征表示能力.根据网络输出的结果,以深度学习方法做缺陷检测的算法可以分为缺陷分类方法、缺陷识别方法和缺陷分割方法.
基于缺陷分类的算法通常使用一些经典的分类网络算法对待检测样本进行训练,学习后的模型可以对缺陷和非缺陷类别进行分类.Wang 等[13]提出使用2 个CNN 网络对6 类图像进行缺陷检测;Xu等[14]提出一种融合视觉几何(Visual geometry group,VGG)和残差网络的CNN 分类网络,用来检测和分类轧辊的表面缺陷;Paolo 等[15]和Weimer等[16]亦借助CNN 的图像特征表示能力来判别缺陷.这类方法通常不涉及缺陷区域的定位.
为了实现对缺陷区域的准确定位,一些研究者将计算机视觉目标识别任务中表现优异的网络改进并应用于表面缺陷检测,这类算法多基于区域卷积神经网络[17]、单激发多盒探测器[18]、一眼识别(You only look once,YOLO)[19]等网络.Chen 等[20]将深度卷积神经网络应用于紧固件缺陷检测.Cha 等[21]在建筑领域中使用区域卷积神经网络(Region-CNN,R-CNN)做结构视觉检测.
为了实现像素级检测精度,一些研究者使用了分割网络,例如Huang 等[22]用U 型网络(U-Net)构建的检测网络将缺陷检测任务转化为语义分割任务,提高了磁瓦表面检测的准确率.Qiu 等[23]采用全卷积网络(Full convolutional network,FCN)对缺陷区域进行检测.
这类方法都依赖一定数量的训练数据.在许多工业场合中,产品缺陷类型是不可预测的,并且只发生在生产过程中,很难收集到大量的缺陷样本.针对这些问题,研究者开始关注小样本或无监督学习方法,如Yu 等[24]利用YOLO V3 网络在少量缺陷样本训练条件下,实现较高准确率的检测结果.在自编码器基础上进行改进的多种方法被用到表面缺陷检测,例如卷积自编码器(Convolutional autoencoder,CAE)[25],基于Fisher 准则的堆叠式降噪自编码器[26],鲁棒自编码器[27],融合梯度差信息的稀疏去噪自编码网络[28]等.Mei 等[29]提出多尺度卷积去噪自编码器网络(Multi-scale convolutional denoising autoencoder network,MSCDAE)重构图像,利用重构残差生成检测结果,相比较于传统的无监督算法如纯相位变换(Phase only transform,PHOT)[30]、离散余弦变换[31],MSCDAE 在模型评价指标上有较大的提升.Yang 等[32]在MSCDAE 基础上使用特征聚类提升了纹理背景的重构精度.以上重构网络均采用加入正则项的均方误差(Mean square error,MSE)损失函数,数据样本多为规则表面纹理.
除自编码器外,生成对抗网络[33]也应用于无监督缺陷检测.生成对抗网络通过学习大量正常图像样本,让网络中的生成器能够学习出正常样本图像的数据分布.Zhao 等[34]结合生成对抗网络和自编码器,对无缺陷样本制作缺陷,训练生成对抗网络使之具有恢复图像的能力.He 等[35]使用半监督生成对抗网络和自编码器训练未标记的钢材表面缺陷数据,抽取图像细粒度特征并进行分类.Schlegl 等[36]提出异常检测生成对抗网络网络解决无监督条件下的病变图像的异常检测.在实际应用中,生成对抗网络亦存在性能不稳定、难以训练等问题[37].
考虑到工业应用场景缺陷样本的复杂性和稀缺性,本文提出一种基于重构网络的缺陷检测方法(Reconstituted network detection,ReNet-D),该方法以少量无缺陷样本作为网络模型学习的对象,对样本图像进行重构训练,使得网络具备对正样本的重构能力,当输入异常样本时,训练后的网络模型可以检测出样本图像的异常区域.本文对ReNet-D 方法的网络结构、训练块大小、损失函数系数等影响因素进行详细的实验分析和评价,以同时适应规则纹理和不规则纹理的检测需求,并与其他经典算法进行对比实验.
1 ReNet-D 方法
在实际的工业应用中,存在缺陷样本稀缺、特征差异大和未知缺陷偶然出现等因素,导致以大量数据样本驱动的监督算法难以适用.本文提出的无监督算法,解决缺少缺陷样本数据可供模型学习的问题.算法分为图像重构网络训练阶段和表面缺陷区域检测阶段2 个训练阶段.通过全卷积自编码器设计重构网络,仅使用少量正常样本进行训练,使得重构网络能够生成无缺陷重构图像;缺陷检测阶段以重构图像与待测图像的残差作为缺陷的可能区域,通过常规图像操作获得最终检测结果.ReNet-D 算法模型如图2 所示.
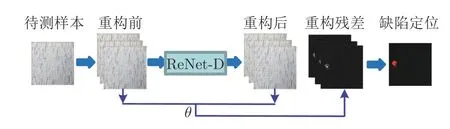
图2 ReNet-D 算法模型Fig.2 ReNet-D algorithm model
1.1 重构网络
工业产品表面缺陷存在多尺度、与背景纹理相似、形状复杂等特性,对检测算法的准确率和运行耗时要求较高.因此重构网络设计有3 个要求: 1)网络能够适应不同尺度大小的缺陷区域;2)网络需要辨识出样本区域是否存在缺陷特征;3)重构网络模型的参数量尽可能少.
重构过程通常分解为编码变换φ和解码变换γ,定义如下:

式中,I∈RW×H表示图像样本的空间域,通过函数φ映射到隐层空间,F表示隐层空间中对应的图像样本特征,函数φ由编码模块实现.函数γ将隐层空间对应的图像样本特征F再映射回原图像样本的空间域,该函数由解码模块实现.
令z=φ(I)∈F,编码和解码过程分别描述为:
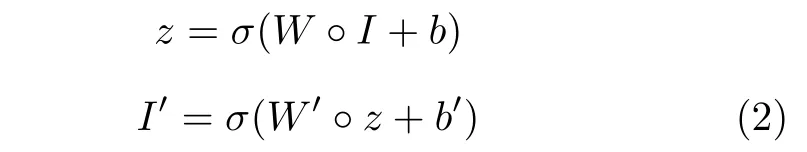
式中,I'表示重构图像,◦表示卷积,σ表示激活函数,W和W'分别表示编码卷积核和解码卷积核,b和b'分别表示编码偏差和解码偏差.
ReNet-D 的网络结构如图3 所示,为适应较大图像,将原图划分成若干图像块,通常大小为16×16、32×32 和64×64 作为网络的输入.ReNet-D利用1×1、3×3 和5×5 三种卷积核来获得多尺度特征,并将多尺度特征输入编码模块,解码模块输出的结果再输入3 个不同尺度的反卷积层,获得最终的重构图像,相比于MSCDAE[29]的高斯金字塔采样模型,同样可以得到多尺度特征,但降低了计算成本.ReNet-D 的CAE 模块包含4 个卷积模块和4 个反卷积模块.每一个卷积模块包含一个卷积层、一个批标准化(Batch normalization,BN)层[38]和非线性激活层,前3 个卷积模块还包含能够改变图像尺度的池化层.激活函数采用Relu.前3 个卷积层使用5×5 卷积核,最后一层使用3×3 卷积核.
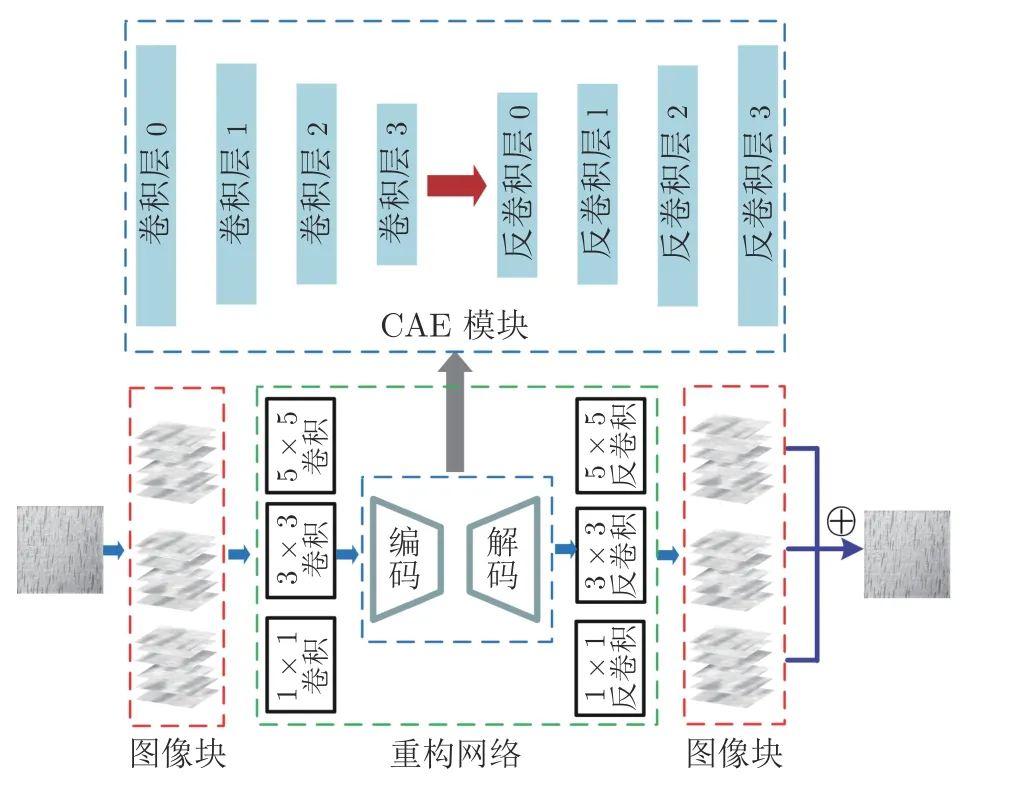
图3 ReNet-D 网络结构Fig.3 ReNet-D network structure
自编码器用于缺陷检测的机理在于: 基于对无缺陷背景的高敏感性完成对无缺陷背景的重建,以及对有缺陷区域的低敏感性完成不完善的重建,以此实现对缺陷的检测.自编码器是一个输入和学习目标相同的神经网络,网络层次的深浅也决定了自编码器对输入图像的复现能力,若采用网络结构复杂的模型,可以提高对样本特征复现能力,但是同时也造成了对于缺陷区域复现能力的提高,进行残差操作时,会导致因缺陷部位差异不够明显而检测失败.ReNet-D 采用轻量化的结构设计,轻量的模型重建能力有限,但通过多尺度特征和损失函数的设计,既能使网络能充分学习到正常纹理的特征,又能对缺陷区域不完善的重建获取缺陷部位的信息.
1.2 损失函数
在ReNet-D 的训练阶段,以原始图像和重构图像之间的重构误差作为损失函数,促进网络收敛.以下分析并改进现有的评估重构误差的损失函数.
1)均方误差损失
均方误差损失是评估算法模型的重构图像和原图之间差异的常用损失函数,定义为L2:

式中,Isrc表示输入的原图,Irec表示模型重构的图像,ω表示重构网络中的权重矩阵集,λ表示正则化项的惩罚因子,0<λ <1.以MSE 为损失函数的重构算法模型适用于规则纹理背景的图像样本,比如纺织品[29,32].
2)平均绝对误差损失
大多数工业产品的纹理背景并不规则,异常特征易融入纹理背景,且异常特征和正常纹理背景特征差异较小.定义L1 为平均绝对误差损失:

与L1 损失相比,L2 损失对异常值更敏感,会过度惩罚较大的损失误差,如MSCDAE[29]方法,因而ReNet-D 引入L1 损失来优化网络训练.
3)结构损失
在评价重构网络模型的效果时,L1 损失和L2损失采用逐像素比较差异方式,并没有考虑图像的区域结构等特征.对于一些非规则纹理图像样本的检测,ReNet-D 引入结构相似性因子(Structural similarity index,SSIM)[39-40]构建损失函数,使网络能适用复杂多变的纹理背景样本,重构出更好的效果.SSIM 损失函数从亮度、对比度和结构3 个指标对模型进行优化[41],结果比L1 或L2 损失函数更能反映图像细节.对于模型输入和输出的图像对 (x,y),SSIM 定义为:

式中,α> 0,β> 0,γ> 0,l(x,y)表示亮度比较,c(x,y)表示对比度比较,s(x,y)表示结构比较.μx和μy分别是x和y的平均值,σx和σy是x和y的标准差.σxy是x和y的协方差.C1、C2、C3是非0 常数,通常α=β=γ=1,C3=C2/2.
SSIM 的损失函数定义为:

重构网络用SSIM 损失函数评价最后一层的输出结果和原图的差异,还可以抽取多个不同尺度的反卷积层结果与对应的卷积层结果同时使用SSIM损失函数,从而构建多尺度SSIM[42](Multi-scale SSIM,MS_SSIM).对于M个尺度,MS_SSIM 损失函数定义为:
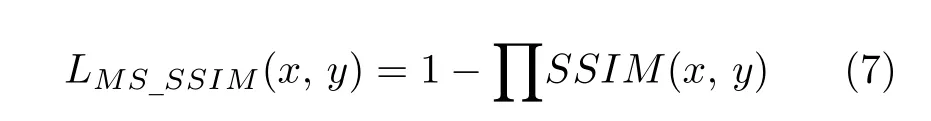
4)ReNet-D 使用的损失函数
L1 损失与MSE 损失相比,对像素级误差的惩罚更弱,适合不规则纹理样本,而LSSIM可以训练重构网络去关注样本图像的亮度改变和颜色偏差,从而保留图像的高频信息即图像边缘和细节.为同时解决规则和无规则纹理图像样本缺陷的检测问题,本文设计L1 损失和LSSIM结合的损失函数作为ReNet-D 网络模型的损失函数,如下:
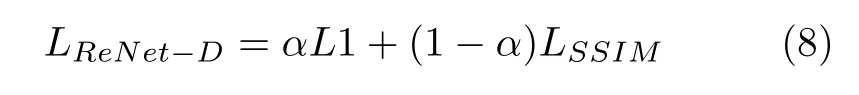
式中,α是权重因子,取值范围为(0,1),用来平衡L1 损失和LSSIM的比重,本文将通过实验比较不同权重因子和损失函数对ReNet-D 检测结果的影响.
1.3 缺陷区域定位
在检测阶段,缺陷图像输入训练好的重构网络后,网络会输出近似无缺陷图像,即重构网络将有缺陷的区域 “修复”成正常区域,而保持无缺陷的区域,根据这一特性,对输出图像与输入图像的像素级差异,经过常规图像处理技术,便能精确的定位缺陷区域,处理流程如下:
1)残差图获取
将输入图像(如图4(a)所示)与ReNet-D 重构图像(如图4(b)所示)利用式(9)做差影,得到重构网络对缺陷区域的重构误差,获得的残差图如图4(c)所示,图中包含了异常区域的位置信息.其中,图4(a)为输入模型的原图,图4(b) 为ReNet-D 重构图,图4(c)为由式(9)得到的残差图v,(i,j)为像素位置.图4(d)为残差图滤波,图4(e)为缺陷定位.

2)去噪处理
残差图图4(c)呈现出很多噪点,形成伪缺陷,影响对真实缺陷区域的判断,使用均值滤波做去噪处理得到图4(d).

图4 残差图处理流程Fig.4 The residual graph processing flow location
3)阈值化分割与缺陷定位
4)使用自适应阈值法得到最终结果图4(e).
2 实验
本文对提出的检测算法ReNet-D 在工业产品的表面数据上进行广泛的评价.首先介绍实验所用的数据集,其次介绍模型评估的关键指标,然后通过对ReNet-D 算法检测效果的影响因素包括损失函数、网络结构、图像块,以及对于同类材料的不同类型缺陷的检测效果等方面做了详细的实验分析.最后,对提出的检测算法和其他同类无监督算法做比较.
2.1 数据集介绍
为了客观评估所提出的检测算法,本实验建立了由多种材料的纹理样本组成的验证数据集,如图5所示,其中图5(a)来源于AITEX[43]数据集,该数据集来源于纺织业,样本为规则纹理,正负样本数149/5,图5(b)~ (e)样本来源于DAGM2007[44]数据集,该数据集有纹理不规则和缺陷区域与图片尺度对比大两个特点,缺陷隐藏在纹理中并且结构与纹理很相似,其中图5(b)的正负样本数100/29,图5(c)的正负样本数100/6,图5(d)的正负样本数101/6.图5(f)样本来源于Kylberg Sintorn 数据集[45],正负样本数50/5.除图5 所示的数据集外,还增加了MVtech 无监督数据集[37]的样本做比较实验.

图5 实验采用的表面缺陷数据集Fig.5 Surface defect data set used in the experiment
2.2 模型评价指标
本文通过像素级度量来评估算法的性能,采用了3 个评价指标: 召回率(Recall)、精确率(Precision)和二者的加权调和平均(F1-Measure),定义如下:

式中,TPp为前景中分割正确的缺陷区域比例,FPp为背景中分割错误的缺陷区域比例,FNp表示缺陷区域中未检测到的缺陷区域的比例.F1-Measure评估召回率和精确率.所有测试都在一台配备图形处理器的计算机上进行的,具体配置如表1 所示.

表1 计算机系统配置Table 1 Computer system configuration
2.3 损失函数对比实验
ReNet-D 分别选取损失函数MSE、L1、SSIM以及三者的组合做对比实验,以评估式(8)所提出的损失函数在缺陷检测任务中的性能.该实验中,ReNet-D 网络参数设置如表2 所示.

表2 默认网络参数Table 2 Default network parameters
图6(a)和图6(b)是两类不同的产品表面缺陷样本在多种损失函数下的实验结果,其中图6(a)为不规则纹理样本,图6(b)规则纹理样本;图6(c)为样本(a)在不同损失函数下的收敛测试,图6(d)为样本(b)在不同损失函数下的收敛测试;图6(a)采用不规则表面纹理的缺陷图像样本.从残差结果对比可以看出,MSE 作为算法损失函数得到的残差结果除真实缺陷区域外,其他区域噪声点较多,形成伪缺陷;而单独使用SSIM 作为损失函数,检测出的缺陷区域略小于真实缺陷区域;相比于其他损失函数,结构损失函数SSIM 和L1 损失函数的组合获得了较好的效果.
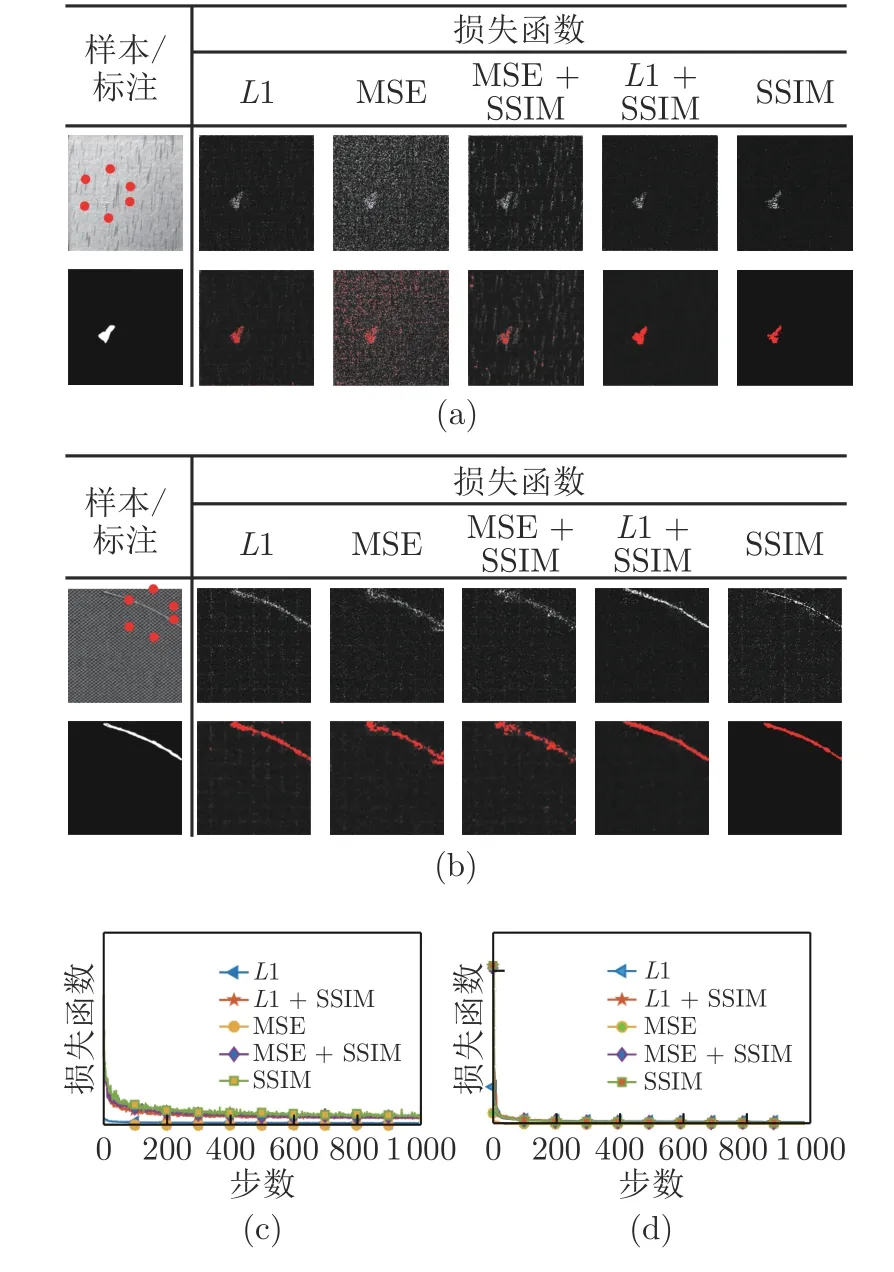
图6 不同损失函数下ReNet-D 的检测结果Fig.6 ReNet-D detection results under different loss functions
图6(b)采用规则表面纹理的缺陷图像样本,从残差结果对比可以看出,使用MSE 损失函数得到的缺陷区域的完整性较差,与MSE+SSIM 组合的检测结果相似.结构损失函数SSIM 和L1 损失函数的组合获得了较好的效果,而且检测结果与仅使用L1 损失函数相似.图6(c)和图6(d)为不同损失函数下ReNet-D 的收敛趋势比较.
从表3 中对比结果可以看出,对图6(a)中的不规则表面纹理的缺陷样本,结构损失函数SSIM和L1 损失函数的组合在召回率以及加权调和平均获得了较好的效果,在精确率上略次于损失函数SSIM;对图6(b)所示的规则表面纹理的缺陷样本,仅使用L1 损失函数达到的召回率最高,SSIM 和L1 损失函数的组合其次;仅使用结构损失函数SSIM 达到的精确率最高,SSIM 和L1 损失函数的组合略次之;对于加权调和平均,L1 损失函数表现最好.

表3 不同损失函数下检测结果的比较Table 3 Comparison of test results under different loss functions
进一步地,通过对本研究采用的样本库的检测效果对比,损失函数有如下规律:
1)对于规则表面纹理样本,采用以上4 种损失函数都能检出缺陷,其中仅用MSE 和MSE+SSIM损失函数的结果相对较差,其他两种损失函数结果差别细微.
2)对于不规则表面纹理样本,采用L1+SSIM的组合损失函数获得的检测结果较好.
2.4 损失函数在不同权重系数下的对比实验
上述实验表明,ReNet-D 模型使用L1+SSIM组合损失函数,能同时适用规则和不规则表面纹理的缺陷检测.对于规则纹理样本,仅使用L1 损失,即权重系数α=1,便可得到较理想的检测结果;而对于非规则纹理样本,不同权重系数会产生不同的检测效果.本实验使用图6(a)中不规则纹理样本,权重系数α的范围从0 到1,步长设为0.1,用于调节SSIM 损失和L1 损失的比重,对比实验如图7所示,其中图7(a)为残差热力图对比.图7(b)为训练损失曲线比较.
根据式(8),当α增大时,结构性损失SSIM 影响逐步减小,由图7 和表4 可以看出,残差图发生明显变化,其中当α=0.15 时,缺陷检测效果较好,信噪比最低,召回率和加权调和平均表现最好.通过多个样本的实验,本文给出的经验建议是: 对于规则纹理样本,设置权重α=1,即只用L1 损失作为训练模型的损失函数;对于不规则纹理样本,设置α=0.15,使结构损失影响权重偏大,以获得最佳的结果.

表4 不同权重系数下的检测结果比较Table 4 Comparison of test results under different weight coefficients

图7 不同权重系数下ReNet-D 性能比较Fig.7 Comparison of ReNet-D performances under different weight coefficients
2.5 网络层结构对比实验
网络层的深度和类型影响重构网络的训练结果,本研究将ReNet-D 的特征提取网络CAE 与经典网络如FCN[46],U-Net[47]做对比实验,实验结果如图8 所示.

图8 不同特征提取网络下ReNet-D 的残差图对比Fig.8 Comparison of residual maps of ReNet-D under different feature extraction networks
基于CAE 网络的缺陷检测任务不同于其他低层像素视觉任务如图像超分和降噪,降噪一般要求很深的网络如FCN 和U-Net,然而这类网络特征提取能力很强,容易将缺陷区域仍重建为缺陷区域,导致重构图和原图的残差几乎等于0,无法检测缺陷.采用轻量化结构设计重构网络时,既能充分学习到正样本的纹理特征,又能将缺陷区域重构为近似正常纹理,形成明显的重构误差.因此,ReNet-D无须过多的网络层数,也无须使用构建网络的技巧,比如全局残差学习[48]、亚像素层[49]、残差连接[50].
2.6 图像块尺寸对比实验
输入图像的尺寸通常会对重建结果有较大影响.在ReNet-D 网络的训练阶段,考虑到处理器的内存和处理速度,将较大的图像训练样本划分为若干图像块,本实验中,图像块尺寸分别设置为16×16像素,32×32 像素,64×64 像素,图9 给出3 种不同图像块大小下的检测结果,其中图9(a)为不规则纹理样本,图9(b)为规则纹理样本,图9(c)为不规则纹理收敛趋势比较,图9(d)为规则纹理收敛趋势比较.
对于如图9(a)所示的不规则背景纹理图像,样本尺寸为512×512,当图像块尺寸等于16×16 时,虽然缺陷区域检测效果较好,但会产非缺陷噪点,此时的召回率最好,但精确率最低;当图像块尺寸较大时取64×64 时,缺陷区域的有效检出尺寸变小,缺陷检测的精确率会降低.
对于如图9(b)所示的规则背景纹理图像,样本尺寸为256×256,当图像块尺寸等于16×16 时,缺陷区域呈现块状化,与理想收敛效果差别较大,此时的召回率最高,但是准确率很低;而当图像块尺寸等于64×64 时,检测结果出现明显漏检现象,检测的精确率下降.
如表5 所示,当图像块尺寸设置为32×32 时,对于图9(a)和图9(b)对应的2 种不同种类背景纹理的图像精确率与加权调和平均达到最高.进一步地,对数据集中多种规则和不规则纹理缺陷样本,图像尺寸从256×256 到1 024×1 024,经测试,ReNet-D 的图像块尺寸设置为32×32 时检测结果最好.

表5 不同尺寸像素块的检测结果比较Table 5 Comparison of test results under different patch sizes texture samples
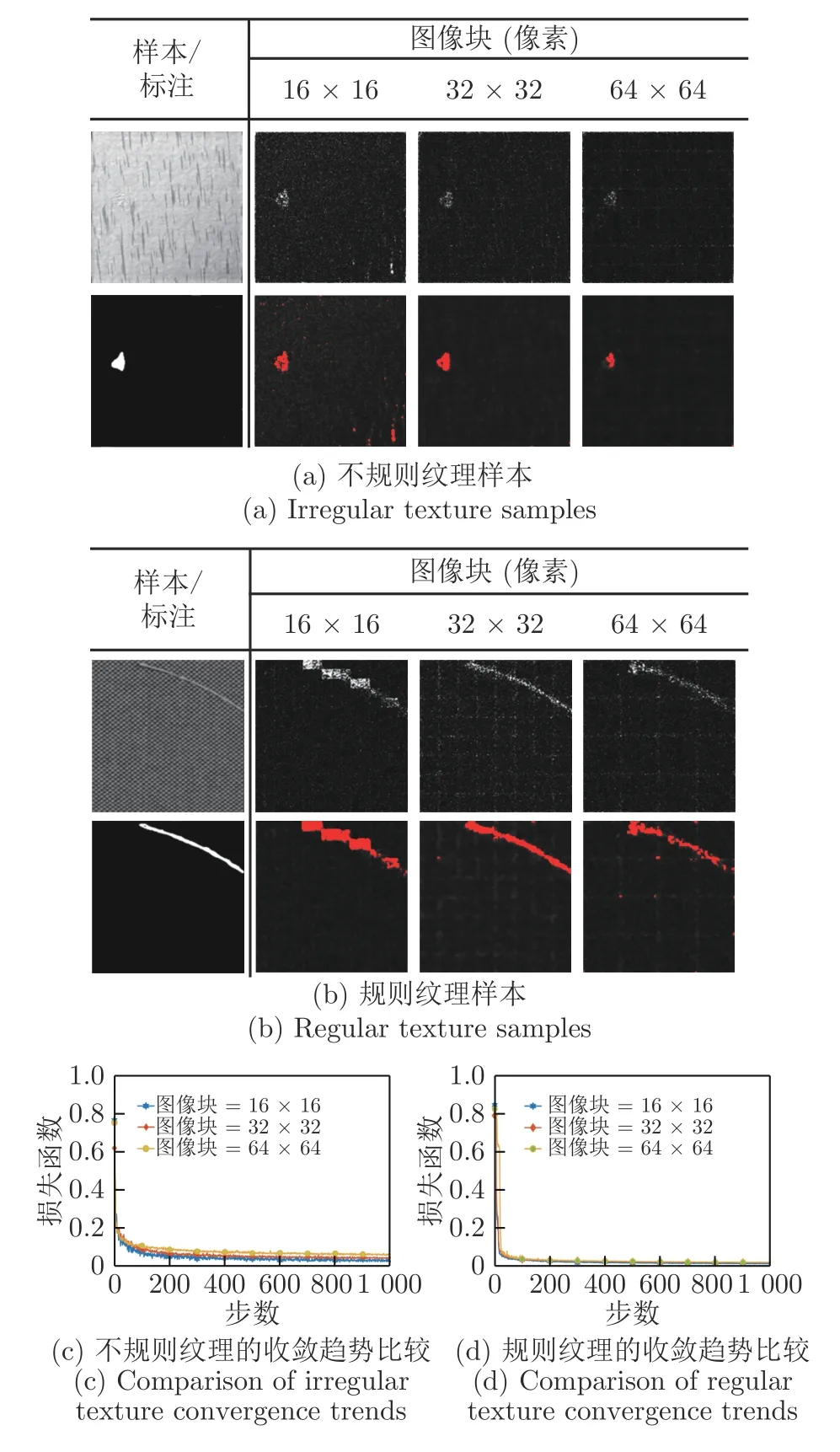
图9 不同图像块下ReNet-D 的残差图和检测结果对比Fig.9 Comparison of the residual image and detection results of ReNet-D under different patch sizes of texture samples
2.7 同种材料不同种类缺陷的检测实验
无监督数据集[37]中的表面纹理缺陷类包括皮革、木材、地毯、网格和瓷砖,其中瓷砖类纹理最为杂乱,其训练集包括了230 张无缺陷的不规则纹理正常类型图像;测试集包括了5 类缺陷,其中有17张破损类缺陷,18 张胶带类缺陷,16 张灰色涂抹类缺陷,18 张油污类缺陷,15 张磨痕类缺陷.本文实验采用默认的网络参数对Tile 数据集进行了训练,并得到了5 类缺陷的检测结果如图10 所示.

图10 无监督样本的测试结果Fig.10 Test results of unsupervised samples
如表6 所示,ReNet-D 方法能适应在Tile 数据集中的不同种类的缺陷的检测,其中油污、破损与磨痕类缺陷表现较好,其检测精确率与召回率与加权调和平均较好,但在检测涂抹和胶带类缺陷时,能检出颜色及纹理与背景有差异的缺陷区域,但生成的缺陷总体形状与理想检测结果有差异,导致像素级的评价指标较低.

表6 无监督样本的测试结果Table 6 Test results of unsupervised samples
ReNet-D 的特性在于,网络对于与背景相似的成分有较好的重建效果,与背景不相似的成分则重建效果较差,从而利用这种特性来检出与背景有差异的缺陷.对涂抹与胶带缺陷的特征分析发现,缺陷局部区域的颜色与纹理和背景非常接近,甚至与之重合,后果是这类区域重建效果较好,造成了差影不明显,但缺陷局部与背景差异较明显区域的检测效果则不受影响.虽然在召回率等指标上不甚理想,但在工业检测中,局部检出可视为缺陷检出.
2.8 相关算法结果对比
本实验将ReNet-D 方法的性能与传统无监督方法(曲率低通滤波分析(Low pass filtering with curvature analysis,LCA)[51]、PHOT[30])和基于自编码方法的无监督方法(MSCDAE)[29]进行了比较,MSCDAE 由文献[32]已证明性能优于其他自编码方法,如异常检测自编码器[9]、鲁棒自编码器[27].实验采用了6 类纹理样本,包含1 类规则纹理和5 类不规则纹理,每类纹理使用50 张无缺陷样本进行训练,并在相同数量的缺陷图像样本上进行测试.ReNet-D 的网络参数对6 类样本基本一样,差别仅在损失函数的权重系数,规则纹理取α=1;非规则纹理取α=0.15.检测结果如图11 所示.
6 类样本在图11 中按列从左到右依次为图11(a)~(f),图11 第1 行是待测样本图像,第2 行是理想检测结果.
如图11 所示,LCA[51]方法能消除代表背景的高频部分,同时保留代表缺陷的低频部分,在简单纹理上获得了良好的检测效果,如样本图11(a)和图11(f).但LCA 方法不适合检测频域较复杂的不规则纹理,如样本图11(b)~ (d).
对于PHOT[30]方法,只有样本图11(b)检测的效果较好,其他样本中和缺陷区域相似背景区域被当做噪点处理.
MSCDAE[29]方法能检测图11中所有样本的缺陷区域,但是同时也把部分无缺陷区域当成疑似缺陷检出,如样本图11(a)~ (d).
本文ReNet-D 方法,无论在大尺度缺陷样本图11(d),小尺度缺陷样本图11(e)和图11(f),以及复杂纹理样本图11(c)和不规则纹理样本图11(b),在所有类型的缺陷和纹理上获得较好的检测结果.

图11 多种算法测试效果对比Fig.11 Comparison of test results of multiple algorithms
此外,召回率、精准率和加权调和平均3 个指标用于定量分析以上4 种方法的检测效果,如表7 所示.

表7 不同算法的检测效果比较Table 7 Comparison of detection effects of different algorithms
由表7 可以看出,本文提出的ReNet-D 算法模型的3 个指标,几乎在所有类型样本上均优于其他算法模型,适合规则纹理和非规则纹理样本的检测.仅在样本图11(b)上的召回率稍逊于MSCDAE 方法,但从检测结果来看,MSCDAE 方法会同时检出非缺陷区域,产生伪缺陷.
本文对算法效率进行了比较.实验采用1 024×1 024 像素样本图像,在相同的计算性能下,对4 种方法的处理耗时进行比较,如表8 所示.ReNet-D 算法模型经过训练后的大小不到1 MB 字节,检测耗时平均为2.82 ms,可以满足工业实时检测的要求.其他方法耗时较大,限制了其实际应用.

表8 处理耗时的比较 (ms)Table 8 Comparison of processing time (ms)
3 结束语
本文提出了一种利用重构网络进行表面缺陷视觉检测的方法ReNet-D,该方法采用轻量化结构的全卷积自编码器设计重构网络,在训练阶段,仅采用无缺陷样本进行训练,可以解决工业环境中缺陷样本获取困难的问题;在检测阶段,利用训练好的模型对输入的缺陷样本做重构,并通过常规图像处理算法即可实现缺陷区域的精确检测.本文讨论了无监督算法中网络结构、损失函数、图像块尺寸等因素对表面缺陷检测任务的影响,并且提出结合L1 损失和结构损失的组合损失函数用于表面缺陷检测,以同时适应规则纹理和非规则纹理样本的检测问题.本文在多类样本数据上对提出的ReNet-D方法和其他无监督算法做了对比实验,结果证明本文所提出的检测算法取得了较好的效果,并适合移植到工业检测环境.由于网络的轻量化特性,ReNet-D 对于一些与背景纹理相似且颜色接近的缺陷的重构性能较好,导致差影结果不明显,生成的缺陷区域与理想检测结果相比有差异,可以从成像角度做适当改进,使缺陷对比度较为明显,进而达到更好的检测效果.
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
摄影世界(2022年1期)2022-01-21
数学小灵通·3-4年级(2021年5期)2021-07-16
中国生殖健康(2020年7期)2020-12-10
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
今日农业(2019年15期)2019-01-03
商周刊(2017年6期)2017-08-22
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
