
预训练语言模型探究
2022-09-28 10:48:58李景玉
科技资讯 2022年19期
李景玉
(北京电子科技职业学院电信工程学院 北京 100176)
1950 年,图灵发表了论文《计算机器与智能》,提出著名的图灵测试,通过一个模仿游戏来测试机器是否能够像人类一样思考、对话,而让测试者无法分辨在对面进行对话的是人类还是机器。图灵测试可以用来检验机器是否像人类一样智能,它也被称为是人工智能的开端。从1950年至今,人工智能已经有六十多年的发展历程,被誉为“人工智能皇冠上的明珠”的自然语言处理技术更是在近几年得到了飞速发展,自然语言处理相关应用也是随处可见,分别有基于机器翻译的翻译软件、基于信息检索的搜索引擎、基于问答系统的智能客服等。而自然语言处理的广泛应用离不开深度学习等技术,可以说,深度学习等技术为自然语言处理带来了一场革命,尤其是2017年Transformer 模型的提出,此后大规模预训练语言模型的诞生和使用,基于“预训练+精调”的模式俨然已经成为了研究自然语言处理的新范式。
1 预训练语言模型
1.1 预训练语言模型概述
语言模型(Language Model,LM)是指描述自然语言概率分布的模型,它在自然语言处理任务中一个非常基础和重要的。在自然语言处理的任务中,常用的说法是N 元语言模型,具体任务是指当给定词序列w1w2...wt-1时,需要根据给定序列判断下一个时刻t可能出现的词语wt,也就是计算条件概率P(wt|w1w2...wt-1)。N 元语言模型推动了自然语言处理技术的发展,但它本身也有自己的局限性,N 元语言模型容易受到数据稀疏的影响,因此平滑技术往往必不可少。随后出现的神经网络语言模型,通过引入神经网络架构和词向量,在一定程度上克服了这一局限,极大地缓解了数据稀疏的问题。这也是自然语言处理领域里面早期的预训练方法,随着技术的革新,更多优秀的预训练语言模型被挖掘出来。
广义上来讲,预训练语言模型是指基于大规模数据训练的语言模型,具体包括静态词向量模型如Word2vec[1]、GloVe[2],动态词向量模型如CoVe[3]、ELMo[4],基于深层Transformer 的表示模型如GPT[5]、BERT[6]。其实,预训练这一做法最早源于计算机视觉领域,学者们会采用以ImageNet[7]为代表的大规模图像数据对模型进行一次预训练,再根据具体领域进行参数精调。而预训练语言模型被更多人熟知和应用,则是从以BERT为代表的基于大规模数据的预训练语言模型的提出开始的。
1.2 使用预训练语言模型的优势
预训练语言模型相较于传统的文本表示模型,其具有大数据、大模型和大算力“三大”特点[8]。大数据是指预训练语言模型在训练时采用的数据规模较大,训练数据规模的增大能够提供更多丰富的上下文信息,同时也能够降低较差质量的语料对预训练语言模型的影响;大模型是指预训练语言模型的参数量大,要求的并行程度高;大算力是指要实现基于大规模文本的预训练语言模型所必备的硬件条件,也就是被大家熟知的GPU算力。
预训练语言模型的三大特点是预训练语言模型能够得到广泛使用的原因。一方面,大数据时代是信息爆炸的时代,传统的自然语言处理方法、深度学习技术都过分依赖大规模的有标注语料,而预训练语言模型的大规模数据可以采用无标注语料,这恰好可以解决对大规模有标注语料的依赖性问题。另一方面,预训练语言模型通过大算力来训练模型的大量参数,大算力意味着对GPU算力有要求,大量参数意味着训练的时间会很长,高速GPU算力当然可以有效减短训练时间,然而高速的GPU算力并不是每一个机构或个人都能拥有的,通过采用权威机构预训练的语言模型,可以直接进行后续网络构建、参数调优。
预训练语言模型也没有让人失望,它的出现与发展帮助自然语言处理不断突破,在自然语言处理的众多方向或领域中都取得了大幅度提升。
2 主流技术与方法
近年来,随着预训练语言模型的发展,在大规模无标签的语料上训练通用模型成为一种趋势。人们利用已经训练好的模型对文本中的语句进行向量化的表示,再利用这些向量在具体的问题中进行参数调优、计算。目前,比较具有代表性的预训练语言模型包括GPT[5]、BERT[6],以及其他进一步优化的预训练语言模型。
2.1 GPT
GPT(Generative Pre-Training)[5]是由OpenAI 公司于2018年提出的一种生成式预训练模型,通过在大规模文本上训练深层的神经网络模型,来获取更丰富的语义信息,从而提升自然语言处理任务的效果。GPT是一个基于深层Transformer 的单向语言模型,也就是说,GPT 只会采用目标词的上文来进行计算。GPT 采用的是12 层深度神经网络,在随后的研究中,GPT 的升级版本GPT-2,则是采用48 层深度神经网络,更大规模的语料库,参数高达15亿个[9]。
2.2 BERT
BERT(Bidirectional Encoder Representation from Transformers)[6]是Devlin 等人于2018 年提出的一种基于深层Transformer 的预训练语言模型,它可以利用大规模无标注语料,获取其中丰富的语义信息。BERT一经问世,就在多个自然语言处理任务中表现优异,刷新了当时11项自然语言处理的任务记录。
BERT 模型是由多层Transformer 构成的,可以分为两个预训练任务:一是掩码语言模型,二是下一句预测任务。其中,掩码语言模型是BERT 预训练语言模型的核心,它通过随机掩码的训练方式,让机器获得还原掩码部分词语的能力,这种方式类似“完形填空”。下一句预测任务则可以构建两段文本之间的关系。那么通过采用BERT模型,可以得到上下文语义表示,这时就可以根据下游任务进行参数调整。
2.3 其他预训练语言模型
因为BERT 模型的优异表现,学者们也将视线逐渐投向BERT,并对BERT 进行改进,比如K-BERT[10]、ALBERT[11]、ERNIE[12]等,而基于BERT模型的改进模型的不断诞生,也证实了BERT 模型本身的优越性。目前,具有代表性的、被进一步优化的预训练语言模型有XLNet[13]、RoBERTa[14]、ALBERT[11]和ELCETRA[15]等。
2.3.1 XLNet
XLNet(Extra Long Net)[13]是一种基于Transformer-XL 的自回归语言模型,也是GPT、BERT 模型的延伸。XLNet预训练语言模型的训练过程引入双流自注意机制,同一个单词具有两种不同表示:内容表示向量h和查询表示向量g,同时XLNet 提出一种排列语言模型(Permutation Language Model),对句子的词序列的建模顺序做出更改,从而实现了双向上下文的建模方式。
2.3.2 RoBERTa
RoBERTa(Robustly Optimized BERT Pre-training Approach)[14]是对BERT 的扩展和延伸,在RoBERTa 中引入了动态掩码技术,舍弃了NSP任务,同时采用了更大规模的语料进行预训练,设置了更大的批次以及更长的预训练步数,通过改进BERT的每个细节,并进行详尽的实验,从而提升RoBERTa预训练语言模型在多个自然语言处理任务中的表现。
2.3.3 ALBERT
ALBERT(A Lite BERT)[11]针对BERT 模型在预训练时会占用大量计算资源以及训练速度较慢的问题,通过词向量参数因式分解和跨层参数共享两项技术,来降低训练模型时的内存消耗,同时提高ALBERT 模型的训练速度。
2.3.4 ELCETRA
ELCETRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)[15]是由谷歌与斯坦福大学共同研发的预训练语言模型,因其小巧的模型体积以及良好的模型性能受到了广泛关注。ELECTRA 的预训练框架是由生成器和判别器两部分构成的。生成器相当于一个小的掩码语言模型(Masked Language Model,MLM),能够在[MASK]的位置预测原来的词,判别器则采用替换词检测(Replaced Token Detection,RTD)代替任务代替了掩码语言模型,来判断生成器采样后的句子中的每个词是否被替换。
3 预训练语言模型的应用
经过大规模语料的预训练后,对预训练语言模型如何应用在下游任务中,通常的做法是将预训练语言模型作为下游任务模型的基底,然后利用预训练语言模型得到文本对应的上下文语义表示,再参与到下游任务中。也就是说,预训练语言模型在下游任务的训练中,会不断地更新自身参数。这种预训练语言模型的应用方法也被称为模型精调。模型精调基于预训练语言模型的大量参数,训练下游任务的模型,这样可以使得预训练语言模型的大量参数与下游任务的匹配度提高。目前,以GPT[5]、BERT[6]、XLNet[13]等为代表的预训练语言模型,采用预训练加微调的自然语言处理基本流程已经成为进一步研究和发展的主导方向[16-18]。
3.1 文本分类
文本分类任务是自然语言处理任务中较为常见的一种任务,以BERT 预训练语言模型为例,基于BERT完成单句文本分类任务的网络结构如图1 所示,其由输入层、编码层和输出层这3个部分构成。
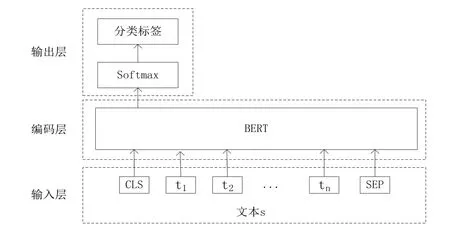
图1 基于BERT的文本分类任务网络结构
输入层的初始输入为文本s 和句子开头标识[CLS]、结尾标识[SEP],其中文本s根据词表划分后的字符串,记为ti,i ∈N,由此得到,文本s 可以表示成字符串的集合s={t1,t2,…,tN}。原始输入文本记为X。
X=[CLS],t1,t2,...,tn,[SEP]
输入文本X由字嵌入向量、分段嵌入向量、位置编码向量组合而成后,得到BERT 输入表示V。在BERT构成的编码层,输入表示V 经过由多层Transformer 构成的编码层后,得到BERT 模型的输出向量Tn,n ∈N。与BERT 预训练阶段的下一句预测任务类似,文本分类任务也使用[CLS]位进行预测。因此,利用输出向量Tn中的首位元素,经过Softmax 操作后,得到对应类别的概率分布。
在具体应用中,张宇豪[19]基于BERT 的base 版本完成新闻短文本分类,同时针对BERT 模型存在的问题,提出改进的N-BERT 模型完成新闻短文本分类任务。针对短文本分类任务,郭腾州[20]提出S-BERT 模型,即将BERT模型和支持向量机分类器进行融合,从而有效提升短文本分类的效果。刘豪[21]将BERT 与GSDMM 融合完成聚类指导的短文本分类任务。陆晓蕾[22]基于BERT 预训练语言模型,构建BERT-CNN 模型应用于文档分类任务,并在专利文献分类领域中取得一定进展。
3.2 阅读理解
机器阅读理解(Machine Reading Comprehension,MRC)任务一直是自然语言处理众多任务中的一个重要任务。近年来,因深度学习技术的发展,机器阅读理解任务称为自然语言处理领域热门的研究方向之一。根据数据集的不同,也就是问题和答案的不同表现形式,机器阅读理解可以被分成不同的任务形式:填空式、选择式、抽取式、生成式、会话式、多跳推理。以抽取式阅读理解为例,阅读理解任务就是给定篇章P、问题Q,要求机器在读取篇章P 和问题Q 后,能够给出答案A,也就是在篇章P中抽取出部分文本片段作为答案A。以BERT 预训练语言模型为例,基于BERT 的抽取式阅读理解模型的网络结构如图2所示,由输入层、编码层和输出层这3个部分构成。
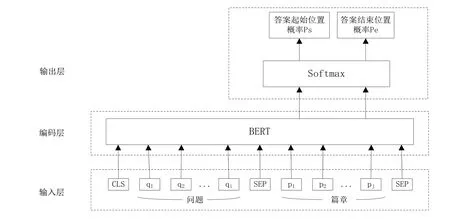
图2 基于BERT的抽取式阅读理解模型的网络结构
在输入层中,将经过分词后的问题Q、篇章P和特殊标记拼接得到编码层的输入序列X,具体如下。
Q=q1q2...qi
P=p1p2...pj
X=[CLS]q1q2...qi[SEP]p1p2...pj[SEP]
其中,i表示分词后问题序列的长度,j表示分词后篇章文本的序列长度,[CLS]表示文本序列开始的特殊标记,[SEP]表示文本序列之间的分隔标记。
输入文本X由字嵌入向量、分段嵌入向量、位置编码向量组合而成后,得到BERT 输入表示V。经过BERT编码层后,可以得到上下文语义表示h。
h=BERT(V)
V=v1,v2,...,vn
h ∈Rn×d
其中,n表示输入序列的长度,d表示BERT的隐含层维度。
将得到的上下文语义表示h作为输入,通过Softmax 函数预测答案起始位置概率Ps 和终止位置概率Pe。当得到起始位置概率和终止位置概率后,可以采用不同答案抽取方法得到最终答案。
2016 年斯坦福大学发布公开数据集SQuAD[23],目前针对SQuAD2.0 数据集面向全世界学者推出机器阅读理解榜单,大力地推动了机器阅读理解技术的发展。目前面向中文的阅读理解数据集主要有抽取式的阅读理解数据集DuReader-robust[24]和CMRC2018[25]等,公开数据集极大地推动了中文阅读理解技术的发展。CUI Y M 等人[26]基于RoBERTa 模型提出MacBERT 模型,在CMRC2018阅读理解数据集上F1值达到60.2%。随后,CUI Y M 等人[27]提出中文预训练模型BERTwwm 模型,该模型在CMRC2018 阅读理解数据集上被证实性能优于BERT 模型。贾欣[28]提出基于迁移学习的BERT-wwm-MLFA 模型,该模型被证实优于BERT模型。CUI Y M 等人[29]提出跨语言阅读理解模型Dual-BERT,该模型在CMRC2018 阅读理解数据集上F1达到了90.2%。
3.3 其他应用
除了自然语言处理的基础任务文本分类和热门任务机器阅读理解,预训练语言模型在自然语言处理的其他任务中也表现优异,极大地推动了自然语言处理技术的发展。比如:朱岩等人[30]将RoBERTa-WWM 模型应用于命名实体识别;方萍等人[31]将改进的BERT模型应用于摘要抽取;ALAPARTHI S[32]将BERT 模型应用于电影评论数据集的情感分析任务。
4 结语
近10 年来,深度学习技术的飞速发展,引发了自然语言处理领域的一系列变革。而预训练语言模型的出现,使得构建模型不用再过度依赖于有标注的语料,预训练语言模型可以从大量无标注文本中学习到丰富的语义信息,这无疑更快速地推动了自然语言处理领域的发展,并取得了一系列的突破。
未来除了进一步改进单一语言的预训练语言模型,如何能够更好地融合多种语言的预训练语言模型,以及如何能够将图像、视频等多种模态的数据与自然语言融合,从而构成多模态预训练语言模型,也将会成为学者们关注的热点。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
通信学报(2019年5期)2019-06-11 03:05:56
通信技术(2018年3期)2018-03-21 00:56:37
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
电子设计工程(2015年20期)2015-01-29 02:58:24
