
耦合PSO与扩展RBF神经网络估计NWM模型ZTD计算精度
2022-09-28 07:54陈西宏王庆力
测绘学报 2022年9期
张 爽,陈西宏,刘 强,刘 赞,3,王庆力
1. 空军工程大学防空反导学院,陕西 西安 710051; 2. 93305部队,辽宁 沈阳 110000; 3. 93567部队,河北 保定 074100
精准的对流层天顶延迟估计对导航定位授时和甚长基线干涉测量有重要影响[1-3]。基于NWM和折射率积分法可获取全球任意位置ZTD,具有计算精度高、可用范围广、不受时空限制等优点,是目前分析ZTD时空分布、构建和验证ZTD经验模型的重要手段之一[4-10]。同时,随着全球气象同化观测资料的不断丰富和同化手段的进步,NWM时空分辨率和数据质量在不断提高。以2019年欧洲中期天气预报中心(European Centre For Medium Range Weather Forecasts,ECMWF)发布的ERA5气压分层产品为例,其空间分辨率可达0.25°×0.25°,时间分辨率为1 h,可提供高质量的气象数据。NWM将全球气象观测数据通过物理模型基于数据同化原理生成[11],其数据精度优于气象经验模型,但仍存在一定误差。目前常用的精度评估方法是利用GNSS ZTD产品进行外部评估。文献[8,12—15]利用全球或区域性GNSS测站ZTD产品对诸如ECMWF提供的ERA-interim和ERA5气压分层产品、美国国家大气研究中心(National Center for Atmospheric Research,NCAR)的WRF中尺度数值气象预报模型、美国国家海洋和大气管理局(National Oceanic and Atmospheric Administra-tion,NOAA)的GDAS数值气象模型进行精度评估。这种评估方法依赖于GNSS站点分布,只能给出测站点处的ZTD精度,对GNSS站点未配置区域只能以区域性平均值代替,误差较大。
考虑到NWM误差主要来源于同化观测资料的空间分布、同化观测资料数据的时间演变及局部天气变化引起的不确定性[16],而局部天气变化一方面可通过NWM自身气象数据部分反应,另一方面又与地理环境特征存在相关性,因此本文以ECMWF发布的ERA5气压分层产品为研究对象,通过NWM自身气象数据和地形特征数据构建特征向量,并基于粒子群算法和扩展的RBF神经网络构建ZTD精度估计模型,再以我国大陆构造环境监测网络(Crustal Movement Observation Network of China,CMONOC,简称“陆态网络”)的GNSS测站ZTD产品作为参考获取ZTD参考精度,结合特征向量训练网络模型,实现不依赖外部数据的ZTD精度估计。
1 数据集生成与划分
1.1 数据来源
数值气象模型采用ECMWF提供的ERA5气压分层产品(空间分辨率为0.25°、时间分辨率为1 h),截取2016—2020年我国及其周边区域(70°E—140°E,0°N—55°N)气压、温度、比湿度和位势作为基础数据。ZTD参考值使用中国地震局GNSS数据产品服务平台(http:∥www.cgps.ac.cn)提供的CMONOC的GNSS测站对流层天顶延迟产品(时间分辨率为1 h[17],部分测站精度经验证可达4 mm[14]),从260个GNSS基准站中选取月数据完整度高于60%的246个站点开展模型训练和算法验证,测站分布如图1所示。本文用于构建地形特征的高程数据来源于NASA提供的SRTM3全球数字高程数据模型经重采样生成的分辨率为0.25°×0.25°的数字高程地图。
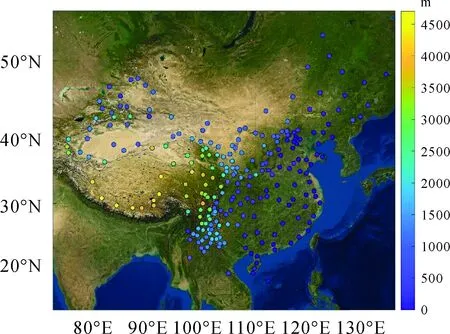
图1 246个GNSS测站分布与海拔高度Fig.1 Distribution and altitude of 246 GNSS stations
1.2 气象特征集
ZTD可分天顶静力学延迟(zenith hydrostatic delay,ZHD)和天顶湿延迟(zenith wet delay,ZWD)两部分分别计算。ZHD是气压和温度的函数,现有研究表明无论是数值气象模型还是基于其构建的经验模型,ZHD精度均可达到较高水平[10,18]。ZWD是温度和水汽压的函数,其中水汽压分布随机性强,难以准确捕获,是目前公认的影响ZTD计算精度的主要因素。因此气象特征集选择地表温度、地表水汽、ZTD月均值和ZTD月标准差作为特征向量,同时考虑到大部分地区ZTD精度存在季节性周期变化,因此将月份也作为气象特征向量之一。
本文使用的ERA5气压层产品提供37层等压面气象数据,不直接提供地表数据,对地表气压、温度和水汽压采用插值或外推方式获取。当地表位置在等压面最底层以上时,水平方向均采用双线性插值,垂直方向上温度和比湿度采用线性插值,气压使用指数模型插值,公式为[6]
(1)
式中,P为目标点处气压,单位为hPa;P0、T0、q0分别为邻近网格点处气压、温度(K)和比湿度;Tv为虚温;g0为重力加速度标准值(9.806 65 m/s2);dh为目标点与网格点高程差;dMtr为干空气摩尔质量(28.965×10-3kg/mol);Rd为气体常数(8.314 3 J/K·mol)。当地表位置在等压面最底层以下时,此时垂直方向无法直接插值计算,为获取相关参数信息,温度值计算借鉴构建全球气象模型的通用方法,假设温度以恒定温度梯度-0.006 5℃/m[19]线性变化;比湿度则根据ERA5使用手册推荐方法认定其在最底层等压面以下保持恒定不变[11];气压仍利用式(1)通过指数模型计算。上述计算方法获取的底层等压面以下的气象数据使用了平均经验值和经验模型,算法简单易用,但计算精度较插值法低,考虑到一般在地表海拔低于海平面高度时会出现需要计算最底层等压面以下气象数据的情况,因此在低海拔地区需注意该方法可能带来的额外计算误差。
ZTD采用折射率积分法与Saastamoinen模型相结合方式,沿天顶方向分层积分至等压面最顶层,顶层以上至对流层顶(海拔86 km)采用Saastamoinen模型计算
(2)
(3)
式中,P、q和T分别为对应位置处的气压(单位为hPa)、比湿度和温度(单位为K);k1、k2、k3为大气折射系数(77.60 K/hPa、69.40 K/hPa、370 100 K2/hPa)。
1.3 地形特征集
地貌地形对气候影响体现在两方面:一是占据巨大空间范围或特殊的空间分布的大尺度宏观地貌,如山脉、高原、盆地等,使区域内形成独特的气候类型;二是中小尺度地形,如海拔高度、地面起伏度等,气象要素分布随地形而变化,形成局部复杂气候。NWM采用网格化方式存储气象要素,在复杂或特殊地形条件下,其数据质量势必受到挑战,因此须从局部和宏观两个层面构建地形特征向量。
为确定局部地形和宏观地貌最佳量化范围,以高程标准差为例,分析不同范围下高程标准差与ZTD精度相关系数。高程标准差描述了地形起伏变化情况,采用矩形窗口法计算一定区域内的高程标准差,即获取以目标点为中心的等边矩形所覆盖区域地形高程标准差,并计算其与ZTD精度相关性。图2为矩形窗口边长1000 km以下和1000 km以上时高程标准差与ZTD年均RMS相关系数。ZTD年均RMS由式(4)获取

图2 不同矩形窗口边长的高程标准差与ZTD年均RMS相关系数Fig.2 Correlation coefficient between elevation standard deviation of different rectangular window side lengths and ZTD mean annual RMS
(4)
由图2可知,随窗口面积增加,相关性呈现出先升高后降低,而后再升高再降低的趋势,印证了局部地形和宏观地貌对ZTD计算精度的多重影响,且局部地形在矩形边长230 km、宏观地形在矩形边长4700 km时相关性最高,因此本文以矩形边长230 km和470 km作为构建地形特征向量的基础。
地形地貌难以通过单一指标准确度量,因此将高程标准差、地形切割深度、地形起伏度、地表粗糙度和高程变异系数的230 km和4700 km矩形窗口值,以及高程、经度等多个指标综合起来构建地形特征集。
1.4 输出目标集
模型的输出目标是基于ERA5气压分层产品计算的ZTD月精度,即以CMONOC的GNSS对流层天顶延迟产品为参考基准评估在GNSS测站位置处获得的基于ERA5气压层产品的ZTD误差月平均RMS,月平均RMS计算方法参考式(4),其中N=720,为月样本点个数(每小时一个样本点,每月按30 d计)。完整的样本结构如下:
(1) 输入特征集(气象特征)包括:地表月平均温度、地表月平均温度std、地表月平均水汽、地表月平均水汽std、月平均ZTD、月平均ZTD std、月份。
(2) 输入特征集(地形特征)包括:230 km高程标准差、4700 km高程标准差、230 km地形切割深度、4700 km地形切割深度、230 km地形起伏度、4700 km地形起伏度、230 km地表粗糙度、4700 km地表粗糙度、230 km高程变异系数、4700 km高程变异系数、高程、经度。
1.5 数据预处理

(5)

2 模型构建
本文以RBF神经为基础构建模型。RBF神经包含输入层、隐藏层和输出层3层。从输入层到隐含层使用具备径对称特性的激活函数,实现非线性变换,从隐含层到输出层使用线性函数,实现线性变换[20]。相较于其他神经网络,RBF神经网络结构简单,训练速度快,逼近能力强,易于解决高维问题[21-22],但其性能受网络结构和规模影响较大,需合理设置网络参数和神经元个数,因此针对本文所提问题,在2.1节对RBF网络结构进行扩展,而后针对网络结构规模问题在2.2节利用聚类算法确定神经元个数和激活函数中心向量,最后2.3节利用粒子群算法优化网络权值。
2.1 扩展RBF神经网络
扩展后的RBF神经网络模型结构如图3所示,模型由气象RBF子网络、地形RBF子网络和线性变换子网络3部分组成。气象和地形RBF子网络分别由n和m个输入节点与f和g个高斯神经元组成,线性变换子网络由f·g个线性神经元和1个输出节点组成。输入节点仅用于传输信息,模型运算时输入样本被拆分为气象特征和地形特征两部分,分别输入相应的RBF子网络,RBF子网络利用高斯函数作为基函数
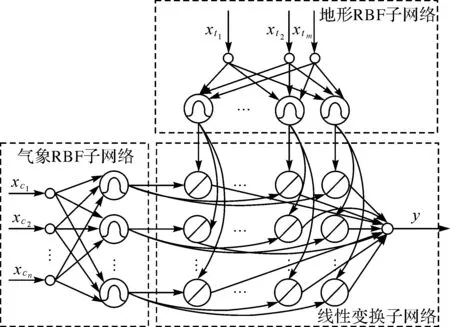
图3 扩展RBF神经网络结构Fig.3 Extended RBF neural network structure
(6)
式中,ui(x)为RBF神经元的输出;x为输入样本;ci为高斯函数中心向量;σi为该神经元的标准化常数。输入样本经高斯函数非线性变换后输出结果到线性变换子网络。线性变换子网络中,每一个气象RBF神经元与每一个地形RBF神经元的输出各通过一个线性神经元经线性加权输出结果到线性变换子网络输出层,输出节点对输入数据线性叠加并输出结果。
基于高斯函数的RBF神经元将输入样本与高斯函数中心向量的欧氏距离映射到(0,1)区间,距离越小,输出越接近1,反之则接近0,因此模型工作原理是利用RBF神经网络分别针对气象特征和地形特征进行分类,将不同大小的ZTD精度认定为不同类型的气象条件和地形环境共同作用的结果。
2.2 结构参数优化
气象RBF子网络和地形RBF子网络中神经元个数决定了模型的结构规模,因而确定合理的神经元个数对模型至关重要,同时这也是应用RBF神经网络的难点之一[23-24]。本文采用层次聚类法和聚类有效性指标分别对气象特征集和地形特征集作聚类分析,将最佳聚类数作为神经元个数。层次聚类采用欧氏平均距离度量样本间相似度,采用自下而上的聚合算法生成层次聚类,再通过聚类有效性指标选择最佳聚类数。聚类有效性指标考虑簇内数据点分布的紧凑度及簇间的分离度,采用式(7)计算[25]
(7)

由图5可知,900 ℃下煅烧的生石灰为原料合成的硬硅钙石明显可见有絮状杂质, 纤维平均直径约为77 nm。1 000 ℃下煅烧的生石灰为原料合成的硬硅钙石纤维平均直径约为82 nm,纤维间搭接规则,相互交织紧密。1 100 ℃下煅烧的生石灰为原料合成的硬硅钙石纤维开始出现板结现象,平均直径增大到160 nm左右,排布混乱。1 200 ℃下煅烧的生石灰为原料合成的硬硅钙石纤维板结现象更加显著,平均直径可达271 nm。
层次聚类还可获得各聚类中心点,即可作为高斯函数中心向量,但层次聚类属于硬聚类,本文所用样本集事实上并无严格的类别区分,不宜使用硬聚类划分确定聚类中心点。因此,在层次聚类获得最佳聚类数的基础上,利用标准模糊C均值聚类法获取聚类中心作为高斯函数中心向量。
2.3 权值优化
模型训练中需调节的权值包括RBF子网络高斯函数标准化常数和输出到线性变换子网络的连接权值。本文利用标准粒子群算法搜索最佳权值,粒子群中每一个粒子都是权值空间的一个解,设气象和地形RBF子网络神经元个数分别为f和g,第i个粒子可表示为Hi=(hi1,hi2,…hi(f+g+f·g)),粒子i的最佳权值表示为Pi=(pi1,pi2,…pi(f+g+f·g)),粒子群的最佳权值表示为Pbest=(bi1,bi2,…bi(f+g+f·g)),粒子群通过式(8)更新速度和权值
(8)
式中,ω为惯性系数;s1、s2分别为自学习率和群学习率;rand1、rand2为[0,1]的随机数。粒子群适应度表示为输出值相对于目标值的均方根。
2.4 数据集划分
由上述模型构建过程可知,模型结构规模、神经元数量和高斯激活函数中心向量等超参数分别通过对训练集进行SVD主成分分析降维、层次聚类和标准模糊C均值聚类确定,不必专门配置验证集调整超参数,因此将数据集划分为训练集和测试集两部分。其中,选择185个测站2017—2019年数据样本作为训练集,185个测站2020年数据样本作为测试集1,余下61个测站2017—2020年的数据样本作为测试集2。测试集1中185个测站地形数据参与了模型训练,用于单方面评估模型通过气象数据估计ZTD精度能力;测试集2地形数据未参与模型训练,用于完整评估模型ZTD精度估计能力。原始数据经预处理完成后各数据集大小分别为:训练集样本5821个、测试集1样本2143个、测试集2样本2441个。
2.5 算法流程
算法流程如图4所示,具体步骤如下。

图4 算法流程Fig.4 Algorithm flowchart
(1) 按照1.5节方法处理样本数据,并划分数据集。
(2) 用2.2节层次聚类和模糊C均值聚类方法处理训练集,获取神经元个数和高斯函数中心值。
(3) 粒子群初始化,确定粒子群规模、最大训练次数和相关常量设置。
(4) 依据粒子群权值和模型结构参数构建并训练神经网络。
(5) 利用训练结果结合训练集的输出目标值求解适应度值。
(6) 判断是否达到最大训练次数,结束训练或依据适应度值更新粒子和群权值信息并转到步骤(3)。
3 模型性能分析
3.1 模型估计结果
训练集层次聚类后获得气象特征最佳聚类数为136,地形特征最佳聚类数为18,粒子群大小设置为200,经1000次迭代后训练误差RMS下降到3.7 mm,测试集1误差RMS为3.8 mm,测试集2误差RMS为4.0 mm。测试集输出结果误差分布如图5(a)所示,误差结果总体呈正态分布,测试集1中82.5%样本偏差小于5 mm,测试集2中79.2%样本偏差小于5 mm。各测站模型估计值与参考值对比如图5(b)所示,测试集1中83.8%测站误差RMS小于5 mm,测试集2中82.0%测站误差RMS小于5 mm。

图5 测试集ZTD精度估计误差Fig.5 The ZTD accuracy error for the test set
3.2 结果分析
测试集1与训练集中的地形数据相同,因此测试集1估计结果反映了模型通过气象特征估计ZTD精度的能力,而测试集2中地形数据未参加模型训练,因此测试集2估计结果完整反映了模型在事先未知地形处基于气象特征和地形特征估计ZTD精度能力。图6分别给出了测试集1和测试集2中误差RMS最大和最小的4个测站。其中,测试集1的HLMH和LNYK、测试集2中的JLYJ和SCGZ误差RMS较小分别为0.9、1.0、1.6和1.8 mm。由图6(a)HLMH和LNYK估计值和参考值对比可知,在不考虑地形特征情况下模型通过气象数据较好地捕获了ZTD精度的数值特征和变化趋势,达到了预期的估计效果。由图6(b)中JLYJ和SCGZ参考值与估计值对比可知,模型输出结果准确估计了ZTD精度大小和周期变化趋势(冬季精度较高,夏季精度较低,变化周期为12个月),模型不仅对已训练过测站具备较好的估计能力,而且对事先未接触过的测站也表现出良好的估计能力,说明模型从数据集中成功提取了相应特征,具备较好的泛化能力。

图6 测试集1和测试集2中ZTD精度误差RMS最大和最小的4个GNSS测站Fig.6 The four GNSS stations with maximum and minimum ZTD accuracy error RMS in test set 1 and test set 2
但同时也注意到,测试集中还存在少数误差RMS较大的测站,如图6中测试集1的XJSH和XJDS(11.1 mm、12.7 mm)和测试集2的YNMH和XZBG(7.2 mm、6.4 mm)。由图6可知,模型基本捕捉到了上述测站ZTD精度变化的周期性趋势,但对ZTD精度的数值特征估计偏差较大,测站XJDS和XJSH估计值整体偏小,而测站XZBG的模型估计值则是先偏小后偏大,原因有多方面:一是训练集中地形数据受GNSS测站数量限制,特征提取和分类还不够完备;二是参考值数据质量问题,现有参考文献中对陆态网部分测站对比分析结果表明,其数据精度在4 mm左右[14],但现有比对分析还不够全面,可能存在部分测站精度较差的情况,如测站XJDS,其ZTD精度参考值发生阶梯状变化很可能就是测站自身硬件或软件升级改善引起的。
进一步对比观察图6中不同测站估计值和参考值可以发现,估计结果误差RMS与ZTD精度估计值大小存在一定关系,误差RMS较大的测站ZTD精度估计值也较小,据此分析了输出结果误差绝对值与输出结果的关系,如图7所示,图中每个点代表一个测试集样本,ZTD精度估计结果小于10 mm时,误差整体较小,而当样本估计结果大于10 mm时,出现少数样本误差较大的情况。因此在使用本模型估计ZTD精度时,当估计值小于10 mm时具有较高可信度,而大于10 mm时则需注意存在偏差较大的可能性。
考虑到作为参考值的陆态网ZTD产品本身精度为4 mm左右,本文认为估值误差小于5 mm的结果是合理有效的,结合图6和图7,可以认为在绝大部分地区,模型估计结果是有效的。

图7 测试集输出结果与误差绝对值分布Fig.7 The model output results and absolute error distribution of test set
采用本文构建模型,以2019年3月和8月ERA5气象数据为基础,按照1°×1°水平间隔计算了中国内陆及其周边区域ZTD精度,结果如图8所示,东北及华北平原ZTD精度较高,青藏高原和云贵高原次之,四川盆地和云贵交接处ZTD精度偏低,新疆塔里木盆地和河西走廊及黄土高原沿线以北等地区精度最低;长江中下游以南地区精度大小与季节密切相关,3月较小,8月较大。由上述结果可知,基于NWM模型获取的ZTD在地势平坦地区精度较高,而地形变化剧烈区域精度较低;内陆地区季节性变化较弱,沿海地区季节性变化明显。另须特别注意,本文数据集中缺少海上测站相关信息,因此基于本文模型生成的海上ZTD精度不具备参考价值。

图8 2019年3月和8月的ZTD精度分布Fig.8 The ZTD accuracy distribution for March and August in 2019
4 结 论
本文以NWM气象数据和地形特征数据为特征向量,采用层次聚类法和模糊C均值聚类确定网络规模,使用粒子群算法优化模型参数,构建了耦合粒子群算法与扩展RBF神经网络的ZTD精度估计模型。为验证模型有效性,以ERA5为NWM特例,进行了模型训练和结果验证。研究结果表明:模型可在绝大部分区域有效估计ZTD月平均精度,实现不依赖于外部参考基准的ZTD精度估计,可在未配置GNSS测站的区域提供有参考价值的估值结果。同时也看到,本文所用数据集规模有限,测站数量较小,下一步将研究把数据集规模扩展到全球,进一步提升并验证模型性能。
猜你喜欢
绿色科技(2022年16期)2022-09-15
北京航空航天大学学报(2022年8期)2022-08-31
军民两用技术与产品(2022年1期)2022-06-01
测绘地理信息(2022年2期)2022-04-02
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
全球定位系统(2021年2期)2021-05-24
当代陕西(2020年23期)2021-01-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
消费导刊(2017年8期)2018-01-18
