
基于Q学习的异构多智能体系统最优一致性
2022-09-28 08:38:14程薇燃李金娜
辽宁石油化工大学学报 2022年4期
程薇燃,李金娜
(辽宁石油化工大学信息与控制工程学院,辽宁 抚顺 113001)
近年来,多智能体系统由于具有较好的鲁棒性、灵活性和可扩展性,在工程、社会科学和自然科学等领域被广泛应用[1]。其中,多智能体系统的最优一致性问题[2]作为多智能体系统协同控制中的典型问题,在群集、智能电网、卫星群和无人机等各种领域应用广泛。多智能体系统的最优一致性问题的本质是通过设计最优的控制协议,使多智能体系统中所有的智能体都达成一致,并使性能指标最小化[3]。众所周知,在解决最优一致性问题中需要求解耦合HJB方程,而这种耦合HJB方程在许多情况下无法解析求解。因此,分布式最优一致性是一个极具挑战性的问题,近年来众多研究者一直致力于寻求有效的方法来解决这一问题。
强化学习(Reinforcement Learning,RL)是机器学习的一个分支,其主要思想是智能体通过与未知环境交互并对累计奖励进行优化,在线学习得到最优的控制策略,实现累计回报最大化[4]。其中,自适应动态规划(Adaptive Dynamic Programming,ADP)是强化学习算法中重要的方法之一。不同于传统的动态规划,自适应动态规划提供了一种可行的解决方案[5]。这种方法在解决系统模型不可知的优化控制问题中具有独特的优势。因此,基于强化学习的自适应动态规划方法已被广泛地应用于解决系统模型部分已知或完全未知的最优控制问题[6-7]。随着多智能体系统研究更加深入,强化学习也被用于求解多智能体系统最优一致性的控制协议问题[8-10]。文献[8]提出了一种无模型Q学习算法,此方法利用测量数据可规避对系统动态的依赖。文献[9]在此基础上提出了一种非二次形式的性能函数结合强化学习算法来处理输入的饱和限制问题的方法。文献[10]提出了一种Q学习算法,此算法只利用系统数据解决离散多智能体系统最优一致性问题。
以上这些研究成果都假设多智能体系统中的智能体具有相同的状态和维度。但是,在实际控制应用中,智能体的状态和维度是不同的,这种也被称为异构多智能体系统。相对于同构多智能体,异构多智能体系统无法得到分布式邻居误差变量的动态表达式,求解更加困难。针对异构多智能体系统的最优一致性问题,文献[11]提出了一种利用自适应分布式观测器的分布式控制方案,解决了线性多智能体系统的协同输出调节问题;文献[12]利用设计的分布式观测器与策略迭代算法相结合的方法,在不了解领导者或跟随者动态的情况下,学习每个智能体的最优控制协议。然而,文献[11-12]的研究方法都需要构造一种状态观测器,因此增加了计算的复杂度。本文通过构造全局邻居误差系统动态,提出了一种基于数据驱动的Q学习算法,通过此方法可解决具有完全未知系统动力学方程的异构离散时间多智能体系统的最优一致性问题。所提方法无需设计领导者的状态观测器,不要求系统模型参数已知,可完全利用数据自学习最优一致性协议,实现异构多智能体系统以近似最优的方式跟踪领导者轨迹,并给出多智能体系统一致性和纳什均衡理论性证明。
1 问题阐述
首先介绍图论的基本概念,其次阐述有领导者的异构多智能体系统的一致性问题,并通过建立的增广变量得到多智能体全局邻居误差动态表达式。
1.1 图论
图论是一种表示多智能体之间交互信息的工具。G=(V,ε)表示一个由N个多智能体组成的系统的网络拓扑图。其中,V={v1,v2,v3,…,vN}表示图的顶点集;ε⊆V×V表示图的边。E=[aij]为图G邻接矩阵。(vj,vi)∈ε表示从顶点vi到顶点vj的一条边,如果(vj,vi)∈ε则aij>0,否则aij=0。D=diag(d1,…,dN)为度矩阵,其中定义网络拓扑图的拉普拉斯矩阵L=D-E[13-14]。
1.2 一致性问题阐述
考虑具有N个智能体的线性离散时间异构多智能体系统。每个智能体i的动态形式为:

式中,k为离散系统的采样时间,k=0,1,2…;xi(k)∈Rn为智能体i的状态;ui∈Rm(i=1,2,…,N)为智能体i的控制输入变量;Ai、Bi分别为完全未知的不同矩阵。
给定领导者的动态为:

式中,x0(k)∈Rn为领导者的状态;A0为适当维度的矩阵。
现提出如下假设。
假设1:(Ai,Bi)是完全可控的。
假设2:图G是完全连通的,并且拓扑图中至少存在一个跟随者节点与领导者节点连通。
定义智能体i的局部邻居误差变量为:
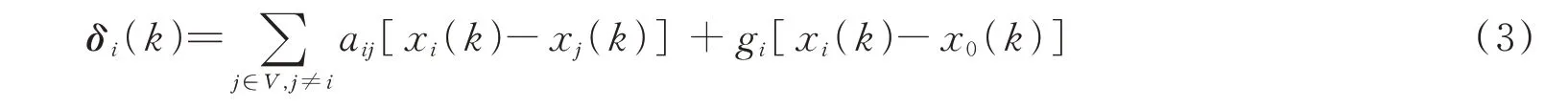
式中,如果智能体i与领导者之间是连通的,则gi=1,否则gi=0[15]。
令ξ(k)=x(k)--x0(k)为 全 局 一 致 性 误 差 ,其 中则所有跟随者节点的整体邻居误差变量为:

式中,δ(k)=[δ1(k),δ2(k),…,δN(k)]T;G=diag(g1,g2,…,gi);In为维度为n的单位矩阵。
由式(1)-(2)和式(4)可得:

定义W=(L+G)⊗In。由假设2可知,(L+G)是非奇异矩阵[14],因此W为非奇异矩阵。由式(4)可以得到x(k)=W-1δ(k)+(k)。因此,由式(5)可得整体邻居误差变量的动态表达式为:
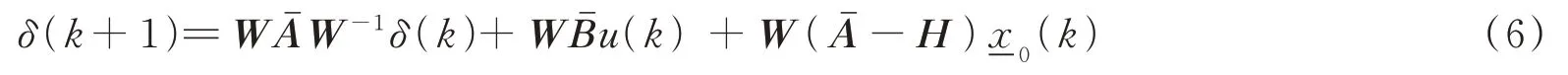
定义一个新的增广的系统状态变量,z(k)=[δT(k),-xT0(k)]T。由式(2)和式(6),有:

注释1新的增广系统(7)包含所有智能体邻居节点误差和领导者状态。控制协议u(k)的设计是为了保证异构多智能体系统(1)在拓扑图G中所有智能体的状态与领导者的轨迹一致,即
2 基于多智能体博弈框架的最优一致性
为了实现多智能体系统的最优一致,首先将值函数转化成二次型的形式;其次,通过求解多智能体系统最优一致性的耦合HJB方程,得到多智能体图博弈的纳什均衡解,并且给出最优解的稳定性和纳什均衡的理论证明。
定义如下性能指标:

式中,u-i={uj|j∈V,j≠i}。智能体i的效用函数为:

式中,Qii、Rii、Rij分别为正定矩阵。
定义1(纳什均衡)[3,8,10]对于具有N个最优控制策略的N个智能体的动态图形博弈,如果对所有智能体都有一个全局纳什均衡解,则认为该博弈具有全局纳什均衡解,并且满足:
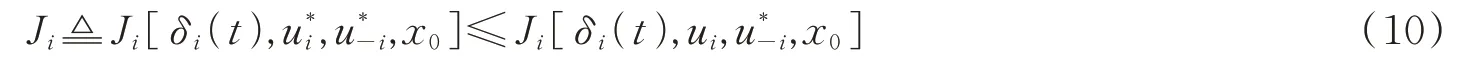
式中,i∈N且∀ui,u-i。
根据性能指标(8),每个智能体i的值函数为:

假设ui=-Ki z(k),其中Ki为控制增益。根据增广系统(7),值函数可以为二次型函数,即Vi=zT(k)Pi z(k),其中Pi为正定矩阵[8-9]。
利用自适应动态规划理论和值函数(11)及二次型Vi=zT(k)Pi z(k),可以得到如下所示的贝尔曼方程:

将增广系统(7)代入式(12)得到哈密顿函数:
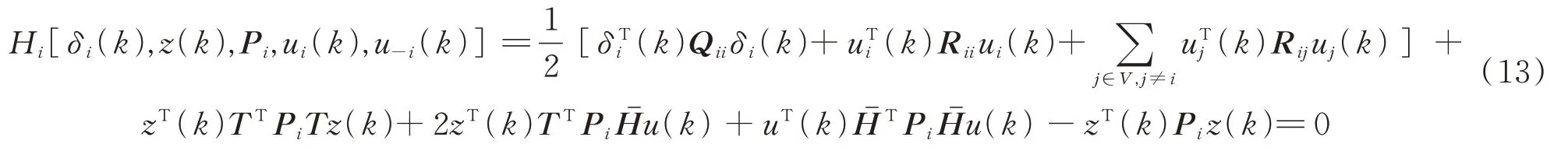
根据极值的必要条件,智能体i的最优解通过得到[16]。因此:

将最优解(14)代入贝尔曼方程(12)中,得到耦合的HJB方程为:
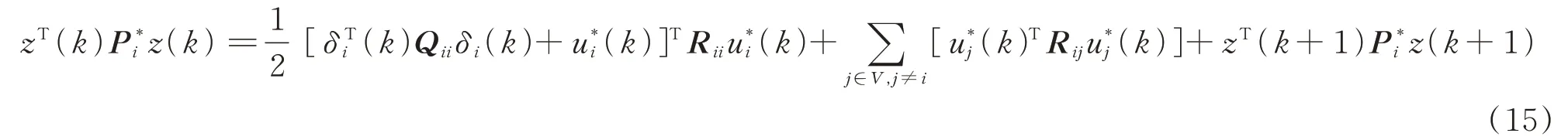
定理1如果P*i为HJB方程(15)的解,并将控制策略设计为式(14),那么有如下结论成立:
(1)系统(3)是渐近稳定的,所有跟随者与领导者达成一致;
(2)在控制策略{u*1,u*2,…,u*N}下,多智能体系统达到全局纳什均衡。
证明稳定性。定义如下李雅普诺夫函数:

式中,Pi为HJB方程的解。那么,李雅普诺夫函数之差为:
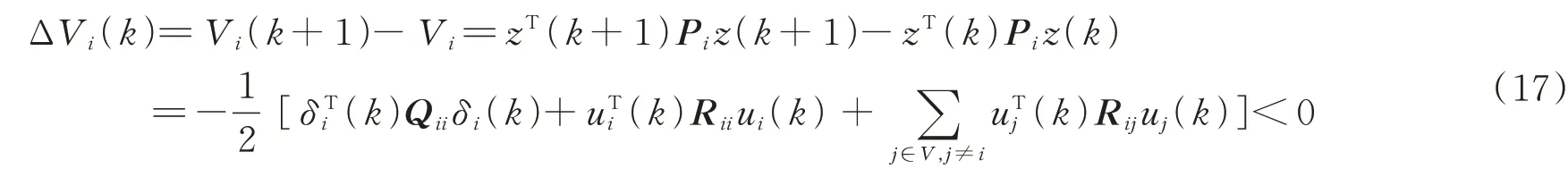
稳定性证毕。
证明纳什均衡。根据哈密顿函数式(13),有:
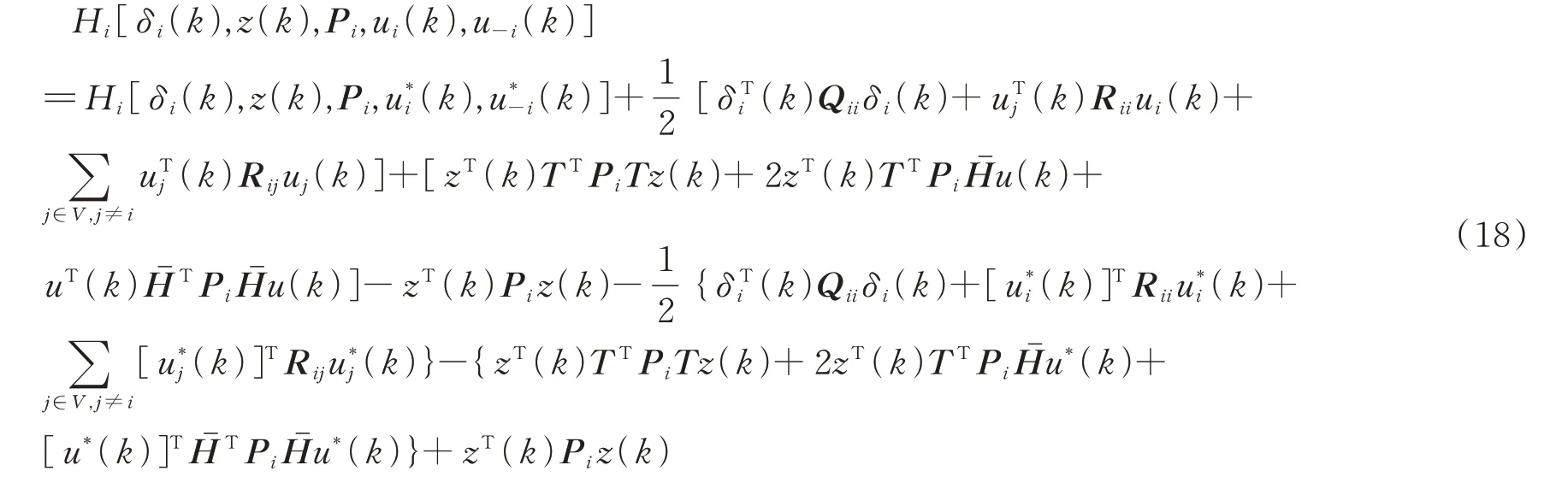
并且,式(18)可以重写为:

式(19)可以写成:

根据哈密顿函数式(13),将式(20)可改写为:
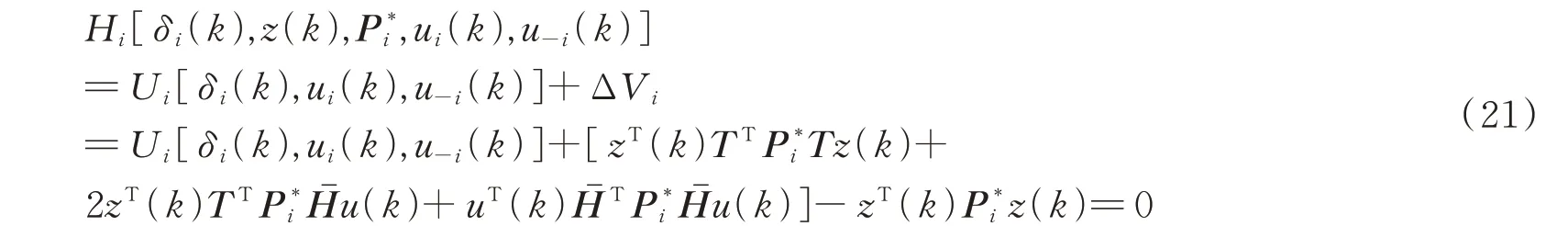
同时,最优控制输入下的哈密顿函数为:

由式(20)-(22)可得:
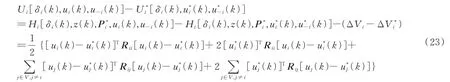
设l为任意的采样时刻,l=0,1,2…。根据性能指标(8),有:

由式(23)和式(24),有:
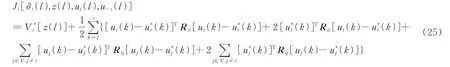
式(24)对任意控制策略都为正,因此:
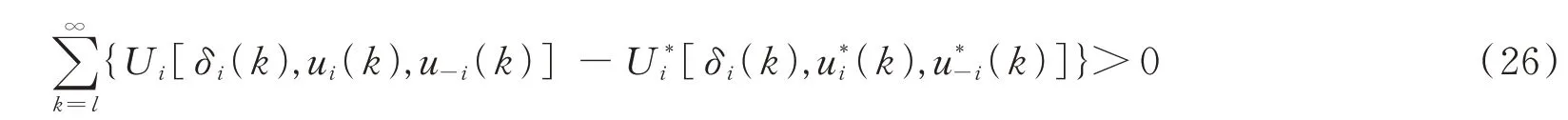

由式(25)-(27),有:
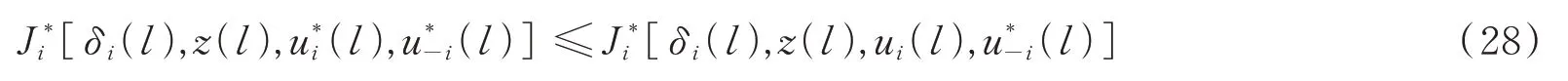
因此,在u*1(k),u*2(k),…,u*N(k)控制策略下,本文所研究的离散时间的异构多智能体系统可以达到全局纳什均衡。证毕。
3 非策略强化学习算法设计
首先,提出了非策略Q学习算法来求解最优一致性问题的控制策略。其次,利用批判神经网络结构和梯度下降法实现了所提出的非策略Q学习算法。
3.1 非策略Q学习算法
根据值函数(11),定义最优Q函数:
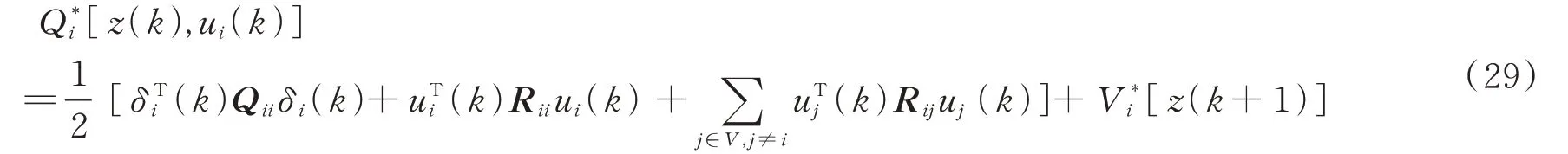
如果有:

那么,基于Q函数的贝尔曼方程为:
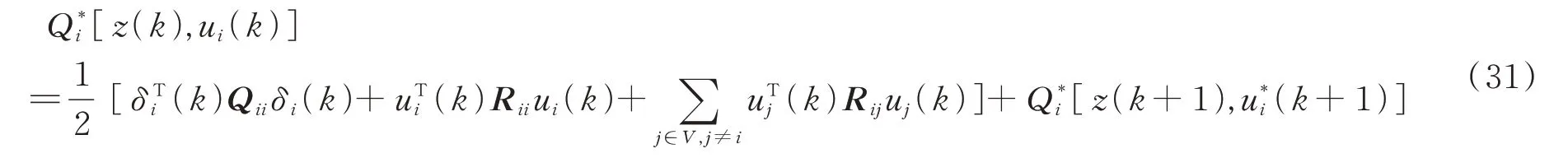
通过控制输入ui(k)、领导者状态x0和所有智能体的误差状态δ(k),Q函数可表示为:
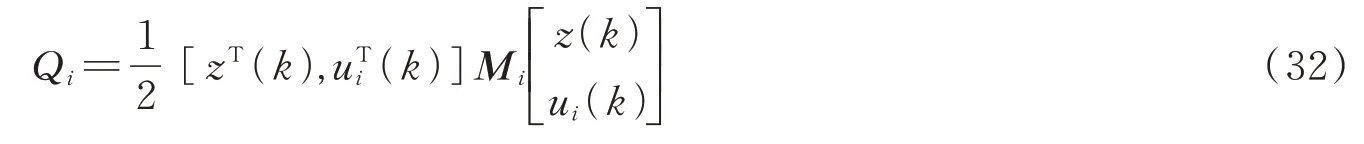
其中,

式中,(Mi[z(k),z(k)])2nN×2nN、(Mi[z(k),ui(k)])2nN×m、(Mi[ui(k),ui(k)])m×m为Mi的分块矩阵。因此,最优控制策略可表示为:

有:
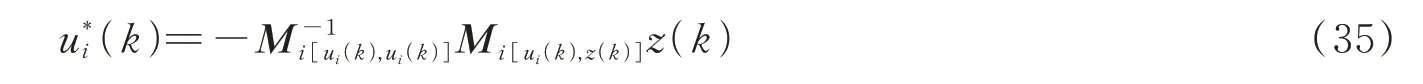
算法1数据驱动的非策略Q学习算法。
步骤1给定控制策略u0i(k)(∀i=1,…,N),并设置迭代指标s=0;
步骤2每个智能体i通过贝尔曼方程求解Qsi:
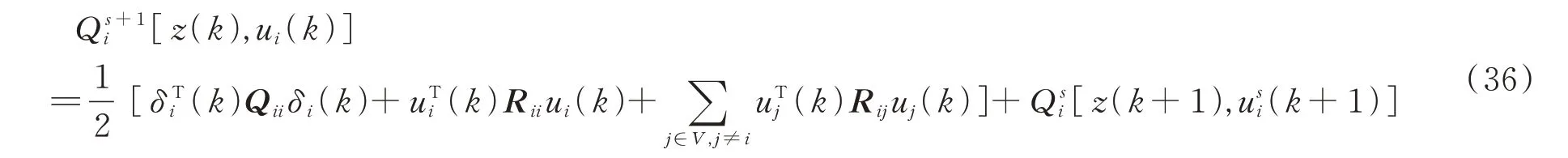
步骤3通过式(37)求解最优控制策略:

步骤4令s=s+1,重复步骤2-3,当||Qs+1i-Qsi||<γ,停止迭代。其中,γ为一个极小的正整数。
注释2相比于常规方法需要构造观测器的求解方式,非策略Q学习算法无需异构多智能体动力学知识就能学习HJB方程的解。同时,算法1的解是收敛的[8]。
3.2 基于批判神经网络的非策略强化学习
使用critic-only神经网络找到最优同步协议。其基本思想是构造批判神经网络来逼近改进的Q函数,然后利用梯度下降法训练批判神经网络的权值,最后估计最优同步控制协议。
对所有跟随者构建如下所示批判神经网络


根据式(35),迭代的目标控制策略为:

进一步,根据式(38)有:

设ϑz(k)为批判神经网络的目标Q函数,有:
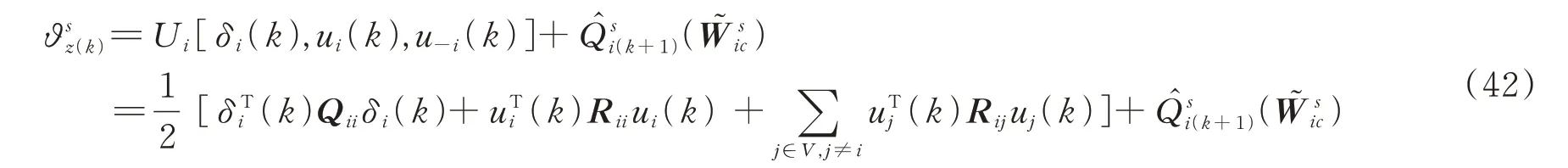
计算神经网络的逼近误差:
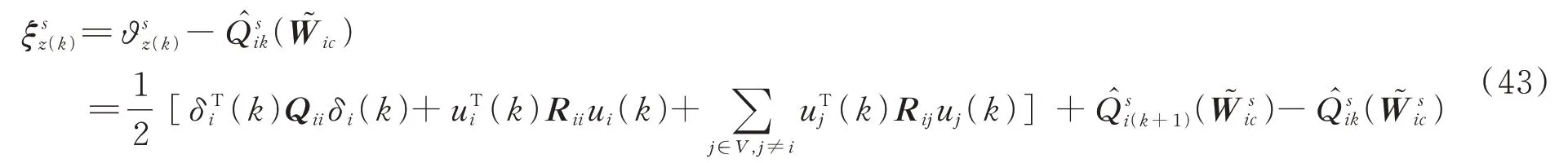
设Erri为跟随者(智能体)i的神经网络逼近误差的平方和,则有:
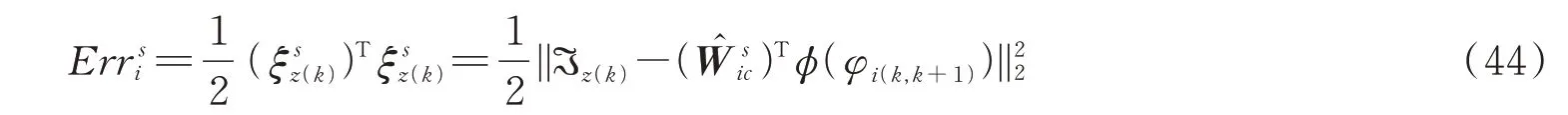
进一步,有:
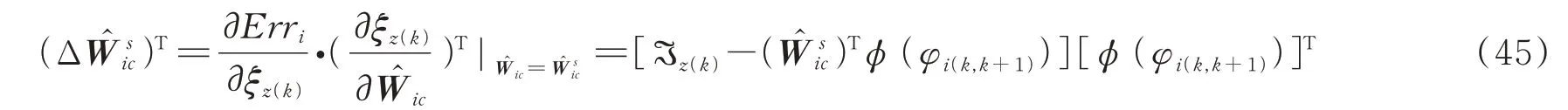
则批判神经网络的权值更新的学习方程为:
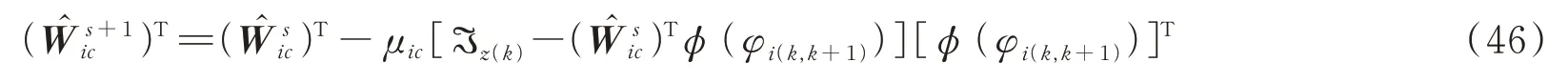
式中,μic为批判神经网络的权值更新的学习率。
算法2数据驱动的异构多智能体图博弈非策略强化学习。
步骤1为每个智能体系统给定一个行为策略,通过式(1)收集系统状态数据,通过式(7)收集邻居误差状态数据;
步骤2初始化批判网络权值;
步骤3通过收集数据计算,按批判神经网络权重更新规则式(46),进而更新批判神经网络权重,通过式(40)计算最优的控制协议;
4 仿真试验
考虑一个具有4个跟随者和1个领导者的异构多智能体系统。设跟随者的系统模型参数为:。领导者的系统矩阵
多智能体系统拓扑如图1所示。从图1可以看出,领导者与跟随者4相连。因此,g4=1;gn=0,n=1,2,3。假设每条边的权值为1。选取学习率iic=1,2,3,4。设性能指标的权重矩阵Q11=Q22=Q33=Q44=I4,R11=R22=R33=R44=1,R12=R23=R13=R42=0,R24=R14=R43=R31=0。

图1 多智能体系统拓扑图
利用MATLAB软件仿真并实施算法2。智能体的批判神经网络权重曲线如图2所示。领导者和智能体的状态曲线如图3所示。由图3可以看出,所有的跟随者同步跟随领导者的动态。
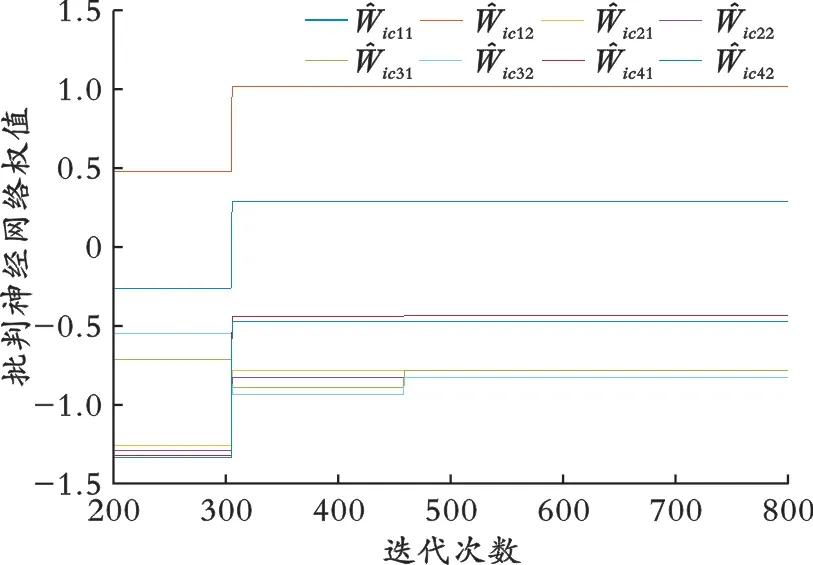
图2 智能体的批判神经网络权重曲线

图3 领导者和智能体的状态曲线
智能体的邻居误差曲线如图4所示。4个智能体的状态曲线如图5所示。从图4-5可以看出,4个跟随者都实现了与领导者的状态一致性。仿真实验表明算法2的有效性。

图4 智能体的邻居误差曲线
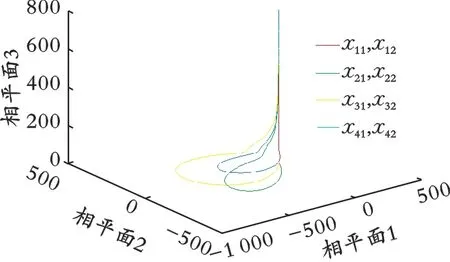
图5 4个智能体的状态曲线
5 结论
鉴于多智能体系统广泛的应用性,探讨了异构的多智能体最优一致性问题。不同于以往研究方法需要构造状态观测器,创新性地提出了通过整体一致性误差动态表达式进行计算,并由此得到了HJB方程和纳什均衡解,同时进行了解的稳定性分析和纳什均衡证明。对纳什均衡解的求解方法,提出了非策略的Q学习算法,并利用critic-only神经网络结构来逼近Q函数,然后利用梯度下降法训练critic-only神经网络的权值。仿真结果验证了所提方法可以实现异构多智能体系统达到最优一致。
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
锦绣·中旬刊(2021年3期)2021-07-14 22:43:08
锦绣·中旬刊(2021年8期)2021-03-15 07:43:30
中国广播(2017年9期)2017-09-30 21:05:19
—— 瓮福集团PPA项目成为搅动市场的“鲶鱼”
当代贵州(2017年24期)2017-06-15 17:47:35
诗潮(2017年5期)2017-06-01 11:29:51
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
中南财经政法大学学报(2015年5期)2015-04-07 03:43:24
汽车零部件(2014年10期)2014-11-11 12:25:04
