
基于多方向特征融合的动态人脸微表情识别方法*
2022-09-28 01:40:44徐胜超叶力洪
计算机与数字工程 2022年8期
徐胜超 叶力洪
(广州华商学院数据科学学院 广州 511300)
1 引言
人脸面部表情中包含十分复杂的丰富情感,同时也是人和人之间的重要交流途径,并且是人机交互和模式识别等研究领域的重要内容[1~2]。由于目前人类社会的不断发展和复杂的社会关系,造成人类的情感变得十分敏感,表情也因此更多地呈现在日常生活中。为了更好地采用计算机技术对人类行为进行模拟,从而有效对更丰富的人类情感进行识别,研究动态人脸微表情识别具有重要的意义。
目前有关于人脸微表情的研究依旧处于发展阶段,相关领域学者对微表情识别进行了研究,并取得了一定的研究成果。在当前已有的表情识别研究中,卷积神经网络的优化应用较多,也较为经典。深度神经网络已经被证明在图像、语音、文本领域具有挖掘数据深层潜在的分布式表达特征的能力。例如:文献[3]提出基于空洞卷积核的微表情识别方法。将空洞卷积核和人脸自动校正方法两者相结合,对人脸特征提取过程进行完善,以实现人脸微表情识别。该方法具有较好的泛化能力,但微表情识别效果较差。微表情的发生只牵涉到面部局部区域,持续时间短。现有微表情识别的全局区域方法会提取这些无关变化的时空模式,从而降低特征向量对于微表情的表达能力,进而影响识别效果。为改善该问题,文献[4]提出基于局部区域的微表情识别方法。优先对动态人脸微表情所在单元区域进行划分,在此基础上,结合序列构造相应的特征向量,以实现人脸微表情识别。该方法具有较高的识别性能,但存在识别时间较长的问题。文献[5]提出了一个残差多任务学习框架来同时完成人脸特征定位和表情识别。根据与以往的多任务学习方法直接训练具有额外分支和损失的深层多任务网络不同,提出了一种新的剩余学习模块来进一步加强两个任务之间的联系。设计剩余学习模块,一个任务可以从另一个任务中学习互补信息,从而提升绩效。多任务学习的另一个问题是缺乏具有多任务标签的训练数据,优化表情识别结果。但是该方法未考虑多方向融合动态人脸特征,导致人脸微表情识别耗时较长。
针对上述问题,提出基于多方向特征融合的动态人脸微表情识别方法。通过去噪处理动态人脸图像,采用决策层融合算法,多方向融合全部特征,实现动态人脸微表情识别,该方法能够有效提升识别率,能够快速、精准完成动态人脸微表情识别。
2 动态人脸微表情识别方法
2.1 动态人脸图像去噪处理
针对加入噪声的动态人脸图像而言,需要采用Bayes 最大后验概率进行估计,对于动态人脸图像而言,大部分的图像都是尺寸比较大的图像,如果直接使用分块的形式,需要分别对各个图像块进行稀疏表示,但是获取的去噪图像十分容易形成方块效应。而动态人脸图像去噪的关键就是处理好图像块和整幅图像之间的关系[6]。为了有效避免出现块效应,需要优先对动态人脸图像进行重叠取块的处理。
对于整幅大尺寸的图像而言,需要使各个图像小块满足设定的稀疏模型[7~8],方便模型的进一步转化。对于图像而言,在完全重叠的情况下需要考虑全部图像小块,同时设定一个图像小块代表一个像素,图像的大小是由图像中的局部图像小块决定的。
针对于模型而言,模型含有两个未确定的量,其中一个为局部稀疏系数,另外一个为输出去噪后的图像。在实际求解的过程中,需要将任务最小化,同时提取大量的动态人脸图像小块进行分解。结合上述,通过稀疏表示进行去噪的详细操作步骤如下所示:
1)对动态人脸图像块中的系数进行求解;
2)对含有噪声的动态人脸图像分别进行分块以及平均处理,再对动态人脸图像进行重构,完成动态人脸图像去噪处理。
2.2 基于多方向特征融合的动态人脸微表情识别
当动态人脸图像经过去噪处理[9~10],对人脸变化产生显著影响的就是光照。Retinex 理论的核心就是避免外界因素对图像产生的影响,保留图像自身的反射特性,增强动态人脸图像。其中,最基本的单尺度Retinex算法计算过程如式(1)所示:
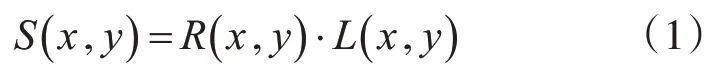
式中,L(x,y)代表动态人脸入射图像;R(x,y)代表位于高频部分的动态人脸反射图像;S(x,y)代表经过处理最终获取的图像。
在上述分析的基础上,结合香农定理[11~12],设定离散随机变量(x1,x2,…,xn)的发生概率为p(x1),p(x2),…,p(xn),则可求得变量对应的信息熵。在上述分析的基础上,结合AAM 模型对人脸图像中的眉毛以及眼睛等关键区域特征进行定位[13],得到动态人脸表情关键区域的具体形状变化特征以及相对位置运动特征。当人脸微表情发生变化时,相同一个人两个眼角之间的距离d是不变的。通过对d进行归一化处理能够得到对应的距离特征,同时确保人脸之间的特征差异得到有效消除。
粗糙集是一种全新的数学工具,主要负责模糊、不完整以及不确定等相关信息的处理。通过信息约简方式,获取全新的知识库分类,同时确保算法的识别能力不发生任何改变。
结合粗糙集方法特有的优势,通过AAM 模型对动态人脸图像中的距离特征信息进行提取,同时采用粗糙集方法对其进行约束,这样能够有效简化特征提取流程,获取含有更多细节信息的几何特征,同时也能够全面提升识别结果的准确性[14~15]。
在上述分析的基础上,采用决策层融合算法对识别结果进行融合。针对识别率贡献程度比较大的特征赋予其较大的取值。以下分别针对五种典型的微表情进行动态权值分配,具体的计算公式如下:
1)生气wi(1 )的权值分配计算式为
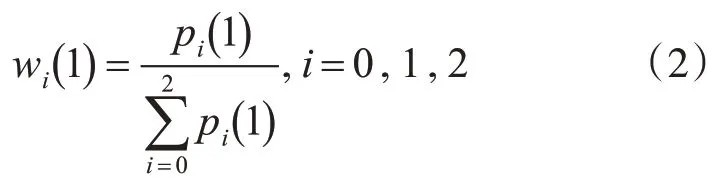
2)厌恶wi(2)的权值分配计算式为
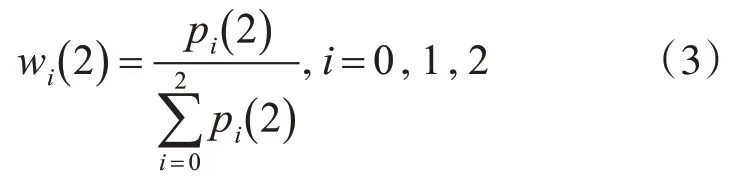
3)恐惧wi(3) 的权值分配计算式为
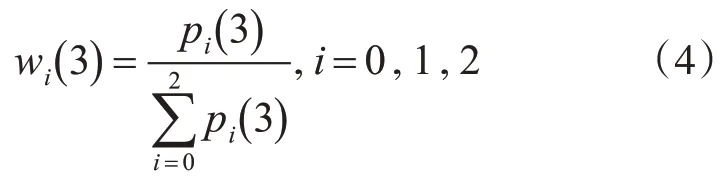
4)高兴wi(4)对应的权值分配计算式为
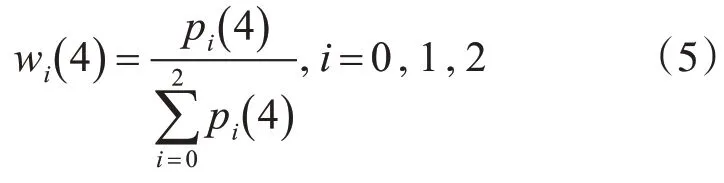
5)惊讶wi(5) 对应的权值分配计算式为
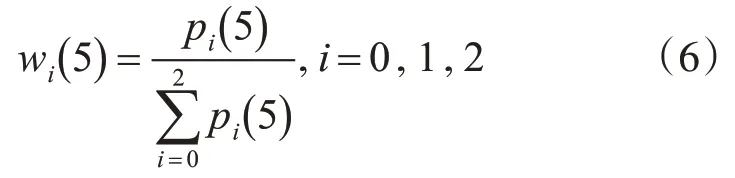
通过以上识别率的权值能够获取不同特征表情识别率对应的权值大小,为后续的识别奠定基础。详细的操作步骤如图1所示。
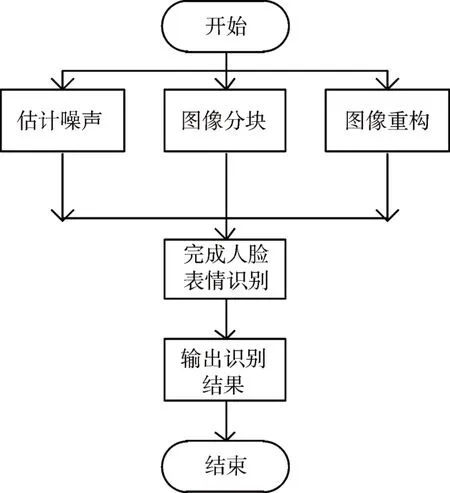
图1 动态人脸微表情识别流程图
对于动态人脸微表情识别最后的识别,结合贡献度计算人脸微表情对应特征的权重值,采用决策层融合算法,对全部特征进行多方向融合。然后对动态人脸关键区域和特征信息分别进行不同的操作,同时借助支持向量机分类器对融合特征进行训练和识别,完成动态人脸微表情识别。
3 仿真实验
为了验证所提基于多方向特征融合的动态人脸微表情识别方法的有效性,在Matlab仿真软件平台中,选取JAFFE 和Cohn-Kanade 数据库中的动态人脸微表情图像数据作为实验对象,分别采用所提方法、文献[3]方法和文献[4]方法进行对比实验测试。测试指标为人脸微表情识别率、人脸微表情识别平均准确率以及微表情识别的平均耗时。
人脸微表情识别率K、人脸微表情识别平均准确率Q的计算公式如下:
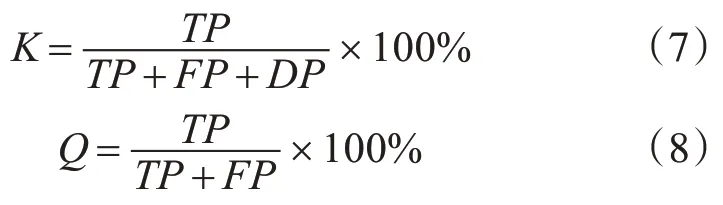
式中,TP表示人脸微表情正确识别的图像数量,FP表示人脸微表情错误识别的图像数量,DP表示人脸微表情未被识别的图像数量,
为了验证所提方法的性能,选取15 个测试对象,优先分析单一特征和多方向特征融合的人脸微表情识别率变化情况,详细的实验对比结果如表1所示。
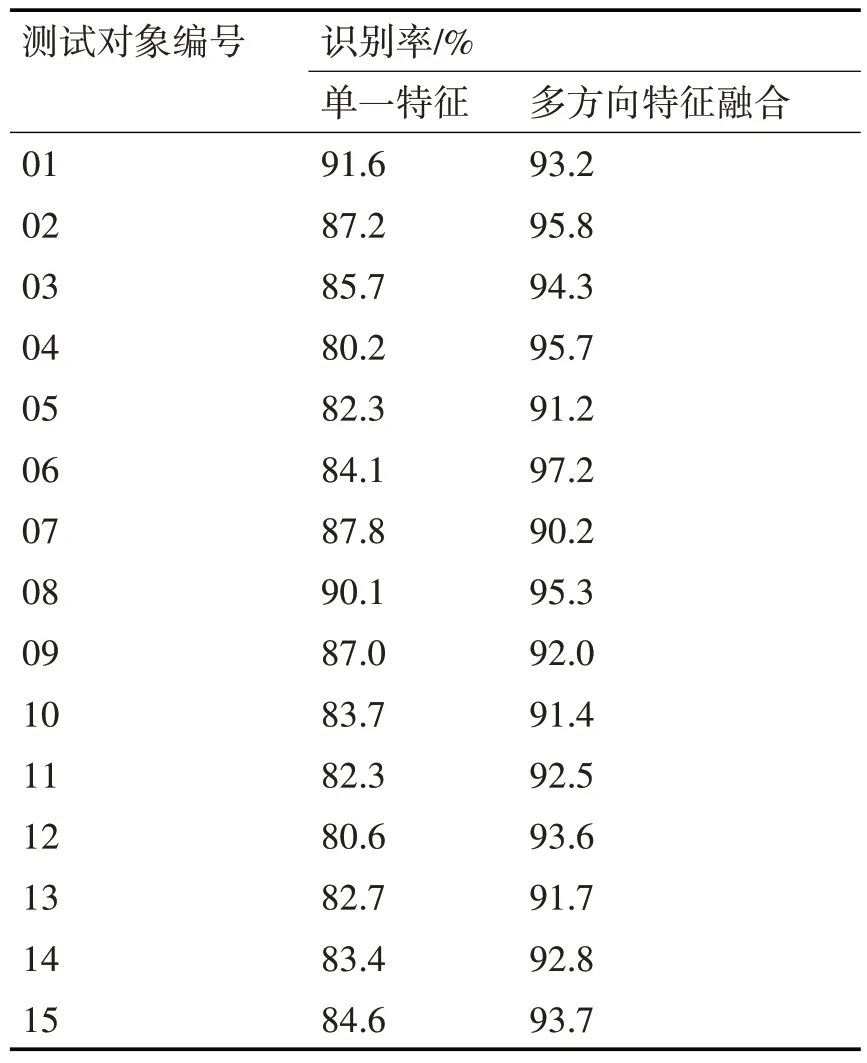
表1 单一特征和多方向特征融合的人脸微表情识别率对比结果
分析表1中的实验数据可知,针对15个测试对象,采用单一特征的平均人脸微表情识别率为84.9%,而采用多方向特征融合的平均人脸微表情识别率为93.4%。由此可知,采用多方向特征融合人脸微表情识别率较高,而采用单一特征进行动态人脸微表情的识别率明显更低,充分验证了所提方法采用多方向特征融合进行识别的有效性。
在此基础上,实验选取四个不同的人脸微表情图像作为测试对象,分别采取所提方法、文献[3]方法和文献[4]方法对动态人脸微表情进行识别,不同方法的识别结果如图2所示。

图2 不同方法的动态人脸微表情识别结果
分析图2 中的实验数据可知,相比文献[3]方法和文献[4]方法两种方法,所提方法能够有效识别不同动态人脸微表情,其识别效果较好。因为所提方法采用多方向特征融合技术,对动态人脸图像进行了去噪处理,将图像中的噪声全部剔除,能够更加精准识别人脸微表情,获取更加满意的识别结果。
为了更进一步验证不同方法的识别精度,以下实验将平均准确率作为测试指标,其中准确率的值越高,则说明方法识别精度越高。不同方法的平均准确率实验对比结果如图3所示。

图3 不同方法的平均准确率实验对比结果
分析图3中的实验数据可知,当实验次数为50次时,文献[3]方法和文献[4]方法的平均准确率分别为88%和86%,而所提方法的平均准确率为95%。由此可知,文献[3]方法和文献[4]方法的平均准确率一直在90%以下,而所提方法的平均准确率一直在95%以上,且处于十分稳定的状态。由此可见,所提方法具有明显优于另外两种方法的识别性能,能够有效提高动态人脸微表情识别精度。
采用三种不同的方法分别对不同类型的微表情进行识别,将平均识别耗时作为测试指标,不同方法的动态人脸微表情平均识别耗时对比结果如图4所示。
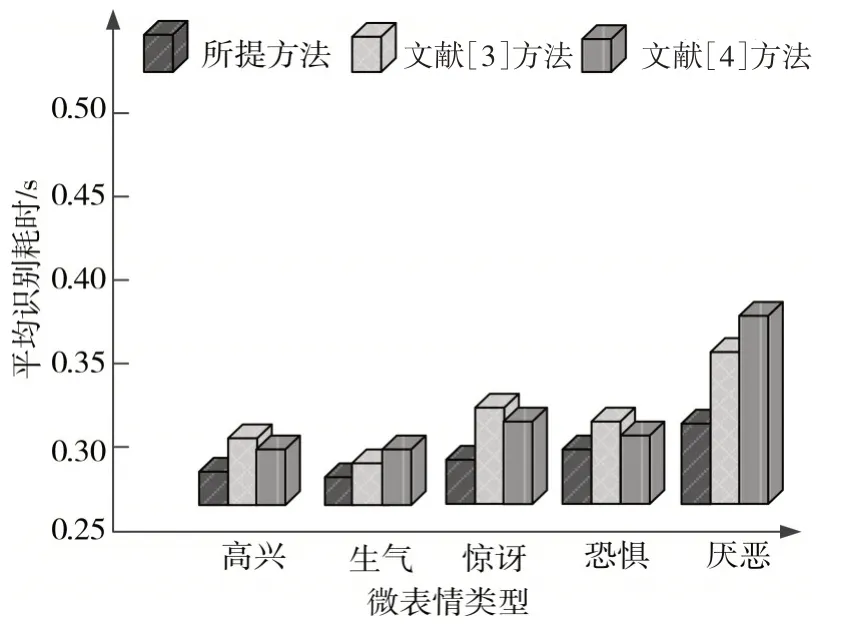
图4 不同方法的动态人脸微表情平均识别耗时对比结果
分析图4 中的实验数据可知,针对不同的微表情类型,文献[3]方法和文献[4]方法的平均识别耗时分别为0.33s 和0.35s,而所提方法的平均识别耗时为0.29s。由此可知,相比另外两种方法,所提方法的平均识别耗时较大,能够以较快的速度完成动态人脸微表情识别,充分验证了所提方法的优越性。
4 结语
为了有效提高人脸微表情识别精度,减小平均识别耗时,确保识别效果,提出基于多方向特征融合的动态人脸微表情识别方法。通过去噪处理动态人脸图像,采用多方向特征融合,实现动态人脸微表情识别,所提方法不仅能够获取较高的识别率,同时能够有效提升识别速度,确保识别效果。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
动漫星空(2018年9期)2018-10-26 01:17:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
中国交通信息化(2018年3期)2018-06-13 03:27:58
中国交通信息化(2016年2期)2016-06-06 07:28:02
