
基于智能视觉感知的车内孩童监控预警系统*
2022-09-28 01:40:40张雪翔史训昂郭鹏宇姚广华
计算机与数字工程 2022年8期
张雪翔 史训昂 郭鹏宇 姚广华
(上海工程技术大学机械与汽车工程学院 上海 201620)
1 引言
在现代社会经济迅猛发展、汽车工业成熟、人民生活水平稳步提高的今天,私家车已经成为大部分公民出行的日常工具。随着汽车技术的进步和发展,车厢的密封性能越来越好,但这样的密封性同时也阻碍了车厢内外空气的流通,使得车厢在车门紧闭时形成相对密闭的空间,导致车厢内二氧化碳浓度升高。当车厢内二氧化碳浓度高于氧气浓度时不仅会对人体健康造成负面影响,还会造成乘客和司机疲劳、嗜睡和行动反应迟钝的情况。
在汽车乘员中,有很大一部分是孩童,而孩童的自主能力差,是易受忽视和伤害的群体。当驾驶员离开车时,特别是当孩童熟睡时,驾驶员极有可能忽视或忘记车内还有乘员,而夏天温度极高,车内温度会骤升,孩童在密闭的车内很有可能在短时间内因高温闷热而窒息死亡。而窒息的最大缘由,在于车内二氧化碳浓度的升高,这就需要在司机离开车后车辆能自动检测车内是否有孩童的存在,并结合孩童的当前评估状态和车内二氧化碳浓度,对车主分级报警,并及时做出相关处理,避免悲剧的发生。
本文设计的基于视觉感知的车内智能预警系统主要由以下三部分组成:1)人脸识别模块:本文在基于Dlib 库实现人脸面部检测和关键点定位的基础上,提出采用ResNet 模型和KNN 算法对人脸进行特征提取和分类,从而进一步提高车内滞留孩童面部识别的实时性和精度;2)姿态估计模块:在车内滞留孩童的姿态估计上,本文考虑到因车内空间狭小而存在的遮挡问题,创新性的提出了一个多尺度监督模型,其模型不仅能有效的推断出被遮挡的部位,而且能有效提高人体关键点定位的精度,间接地为车内滞留儿童的状态评估(包括熟睡、玩闹等)提供依据;3)分级预警模型:为了更好地保障车内遗留孩童的生命安全,本文基于人脸识别、姿态估计和CO2浓度检测建立车内监控分级预警机制,该机制会根据车内的环境恶化程度和滞留孩童的当前状况选择相应的预警等级,并及时通知车主或降下车窗进行通风换气。
2 方法
2.1 人脸识别模块
在车内疑似滞留孩童的面部识别上,本文设计的人脸识别模块主要包括人脸检测、人脸定位,面部特征提取和人脸识别[1]。图1中显示了人脸识别的整个网络框架和训练所用的数据集,其主要分为三个阶段:ResNet训练,KNN 训练和KNN 测试。人脸识别的步骤和具体细节如图1所示。

图1 人脸识别网络框架
2.1.1 人脸检测和定位
在面部关键点的定位上,本文依赖于Dlib库中经过预训练的面部关键点定位检测器[2],该检测器会预测出68 个绘制面部轮廓的关键点。而在本文中,首先仅使用12 个点来对齐面部图像,其中6 点代表左眼轮廓,6 点代表右眼轮廓,这样我们就可以通过6 点的坐标得到眼中心的坐标。然后在获取两只眼睛的中心坐标(两只眼睛的中心是面部图像中旋转的中心)之后,并通过旋转,缩放和平移对人脸图像进行归一化处理,从而实现人脸关键点定位[3]。图2 展示了人脸归一化处理步骤,其是将具有倾斜角度的人脸原始面转换为没有倾斜角的对齐面。

图2 人脸归一化处理
2.1.2 面部特征提取
本文主要是基于ResNet[4]深度神经网络架构来提取人脸面部特征。由于ResNet 在物体实例分类,检测和分割方面的出色表现和其模型易于训练的特点,它在ILSVRC(ImageNet大规模视觉识别竞赛)和COCO-2015 竞赛中获得了第一名。在本文中,我们使用3 层ResNet 网络架构,一层内含有两个卷积层,如图3 所示。ResNet 网络的输入是归一化处理后的人脸图像和其相对应的标签,然后通过预训练好的ResNet 来提取人脸面部特征,其中中间层和L2 归一化层的输出都是人脸面部的特征向量。最后将所获的面部特征向量(也称为嵌入)作为KNN分类模型的输入。
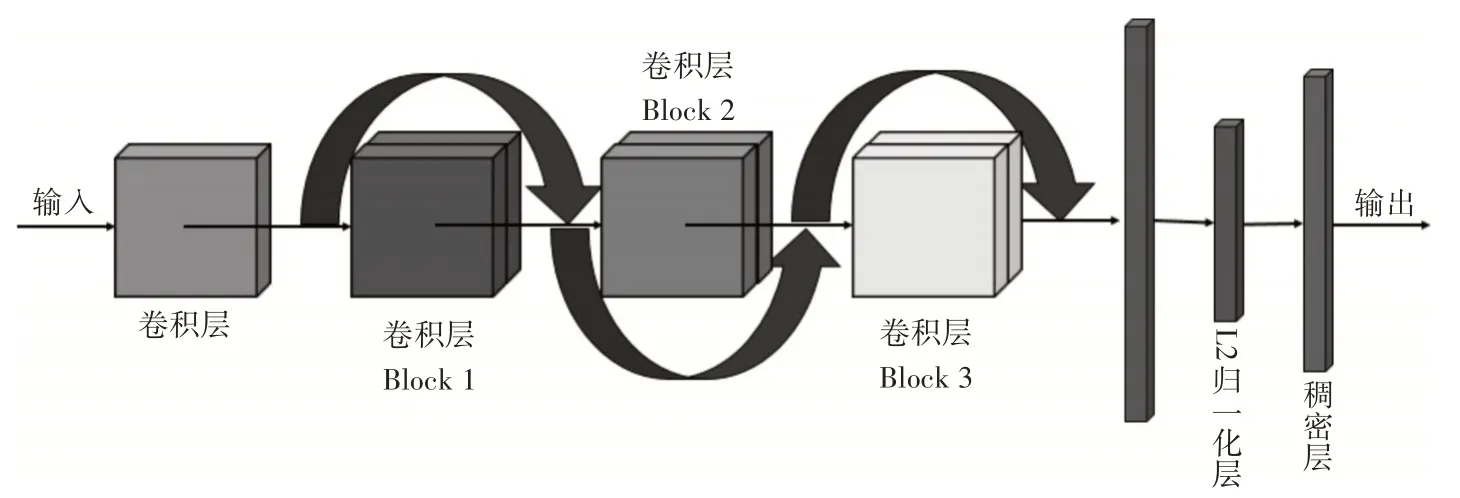
图3 3层ResNet网络架构
2.1.3 人脸识别
针对于人脸数据集很大的场景,考虑到识别算法的实时性和对噪声的鲁棒性,我们选择K最近邻分类算法(KNN)去计算要分类的对象与数据集中每个对象之间的欧式距离。在数据集训练之前,首先定义K 的值,然后从数据集中选取要分类对象的K 个邻居。每个邻居都有一票,该对象的邻居的多数票决定了该对象的分类属性。在本文中,我们将ResNet 嵌入层的输出用作KNN 分类模型的输入。在此步骤中,将使用来自其他数据集标注好的人脸图像来训练分类模型。在人脸识别模型的测试验证中,将测试人脸未标记图像,从而验证模型识别分类的精度和实时性。
2.2 姿态估计模块
为了更好地对车内孩童的当前状态进行评估,我们还需对车内孩童的姿态进行估计,从而实现预警等级的有效划分,并及时做出相应的处理。本文考虑了车内姿态估计时存在的遮挡问题,为了有效消除人体关键点在匹配时的歧义,包括左右身体部位的不匹配,并更好地推断出被遮挡的部位,本文提出了一个多尺度的监督网络模型,其模型组成部分如图4所示。
本文提出的孩童姿态估计模型的新颖之处主要在以下两个方面:1)首先,在基于卷积-反卷积现有姿态估计作品中[5~6],准确的人体关键点的对应关系很大程度上取决于多尺度匹配的一致性,针对此我们将中间监督扩展为在训练期间明确覆盖反卷积层的多级监督,这大大提高了在不同尺度上提取更一致且更具代表性特征的能力;2)其次,由于每个人体关键点热图(对应于关键点的位置可能性)是在卷积-反卷积步骤期间独立估算的,因此各个关键点之间的结构关系未在卷积-反卷积模块中建模。为此,我们最后使用全局关键点回归网络在热图的顶部对关键点之间的关系进行建模。在不同场景下,这种回归网络结构能有效提高全局姿态估计中身体结构的一致性。
作者简介:林舒虹,女,龙岗区机关幼儿园,幼教一级,龙华区优秀教师,甘露名园长工作室学员,本科学历,研究方向:学前教育。
2.2.1 多尺度监督
我们建议在各个反卷积层中强制执行多个监督步骤(如图4 所示),以通过学习更丰富的多尺度特征,来实现更好的人体关键点定位。随着卷积-反卷积块堆叠深度的增加,梯度消失将成为训练过程中的关键问题。为了解决模型训练期间梯度消失的问题,我们在两个卷积-反卷积块间增加中间监督层[7](图4 中的浅色层),其可以在某种程度上有效解决梯度消失的问题。
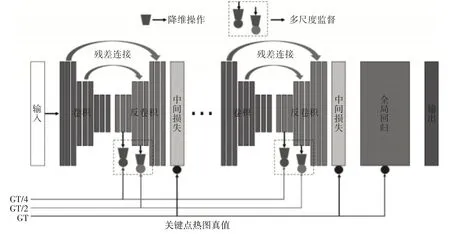
图4 多尺度监督网络模型
虽然多尺度监督方法是对原始中间监督的扩展,但是我们提出的多尺度监督的实现方式与以往是不同的。我们的实现方式是通过在图4 的每个反卷积层上计算与下采样的人体关键点真值热图(记为GT/4,GT/2,GT)相关的多尺度残差[8]来进行的。具体来说,我们通过计算各个尺度上的关键点真值热图残差来保持特征图通道的一致性,并使用1×1卷积核(图4中的梯形)将高维的反卷积特征图转换为人体关键点的单独热图。这样,我们就可以使用均方误差(MSE)对人体关键点的降维特征图和其相对应尺度的真值进行监督。在此过程中,我们发现提出的多尺度监督方法可以有效提高人体关键点热图预测(在人体关键点上有更集中的分布)的准确性。
本文在描述监督损失时,将l2损失[9]作为人体关键点热图预测的损失函数。为了提高人体姿态估计的精度,我们采样了人体的16 个关键点(包括头部,颈部,骨盆,胸部,肩膀,肘部,腕部,膝盖,脚踝和臀部等相关部位),每个卷积-反卷积块都会生成N个关键点热图。在第i个尺度上,人体所有关键点预测的热图与其真实热图之间的Li损失如下所示:

其中Pn(x,y)和Gn(x,y)分别表示第n个人体关键点的像素位置坐标(x,y)的预测值和真实值。模型总的损失函数为L=∑iLi,其表示为中间监督损失和多尺度监督损失的组合。
2.2.2 全局关键点回归
在卷积-反卷积块之后,我们使用一个全卷积回归网络[10]来细化人体多尺度关键点热图,以提高姿态估计时人体结构的一致性。手臂和腿、头部和躯干之间的相对位置作为有用的先验知识,其可以从回归网络[11]中学习,并与多尺度特征图相结合来进行人体姿态细化。我们的卷积-反卷积块首先会根据人体的姿态/活动提取关键点热图,如图5(B)所示,然后回归网络会将多尺度热图作为输入,并在相应的尺度下匹配真值图像。通过这种方式,回归网络可以有效地监督所有尺度的热图,以便进行细化。

图5 人体关键点定位及热图提取
具体而言,本文主要是通过多尺度特征[12]和人体关键点上的回归特征图[13]来细化人体的位姿结构。在结合考虑人体结构先验的基础上,该回归过程可以有效地提高人体关键点位置预测的精度。图5(a)表示人体关键点预测,图5(c)表示人体关键点位置的输出结果,图5(d)则表示回归处理后的关键点热图,从图5(c)、(d)中我们发现模型不仅使得关键点热图峰值更加集中,而且也进一步提高了人体姿态估计的精度。
2.3 分级预警模型
在车内智能监控预警模型的建立上,考虑到滞留孩童在车内熟睡时,其CO2的呼出量相比于氧气增加了一百倍左右[14],如表1 所示,在密闭的车内环境下极易会造成车内人员的窒息,本文利用二氧化碳浓度检测仪(如图6 所示)对车内的CO2浓度进行实时监测,当车内存在滞留孩童的情况下,检测到车内CO2浓度急剧升高时,系统会控制车窗上的步进电机降下车窗,进行通风换气,其车内智能监控分级预警模型如图7所示。

图7 车内智能监控分级预警模型
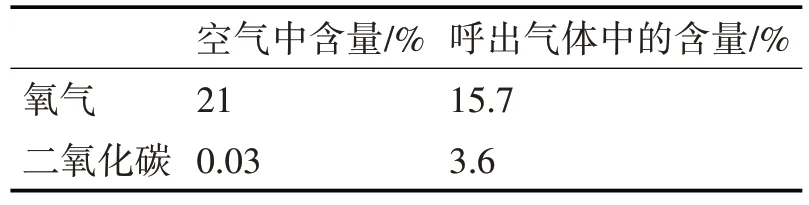
表1 空气及人体呼气中各气体含量

图6 二氧化碳浓度检测仪
3 实验评估
3.1 人脸识别实验
在车内疑似滞留孩童人脸识别模型的训练上,考虑到算法的实时性和人脸识别精度要求,本文主要是使用LFW 数据集来训练3 层ResNet 特征提取网络,该数据集的13233帧图片中总共有1680个人(包括成年人、孩童和老人);而在人脸识别上,我们将采集并标注好的车内孩童数据集和Chokepoint数据集进行融合,融合之后的数据集共有75 人(成年男性19人,成年女性16人,孩童40人)。
在人脸面部特征提取的实验中,本文主要是使用Adam 优化算法来训练ResNet 网络,并使用学习率为0.001的交叉熵损失函数。本文设计的ResNet网络中的残差块是由两个卷积层和两个批量归一化层组成,在提出的人脸特征提取模型中,我们使用三个残差块,相比于两个或四个残差块,其具有最优的性能,如图8 所示。在人脸数据集训练的规模上,相比于FaceNet人脸识别模型,其是通过训练100 万到200 万张人脸图片并将其特征压缩成128维嵌入向量来区分人脸面部的关键特征,而本文模型的训练数据集规模是很小的。因此,我们通过使用ResNet 网络将224×224×3 的人脸输入图像转化为256 维嵌入向量来表示面部特征,与128 维嵌入特征向量相比,256 维的嵌入向量具有人脸更加丰富的信息。在实验中我们发现,当epoch 设置为70 时,模型具有较高的测试精度,当epoch 大于70时,模型的测试精度会下降。图9和图10分别展示了ResNet 特征提取模型训练和测试时随epoch 大小设置的损失和精度变化。
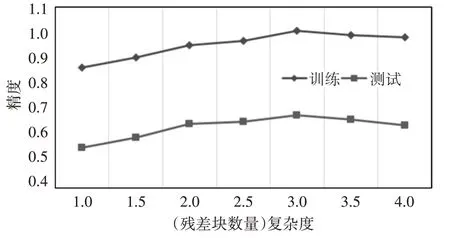
图8 ResNet网络复杂度性能对比
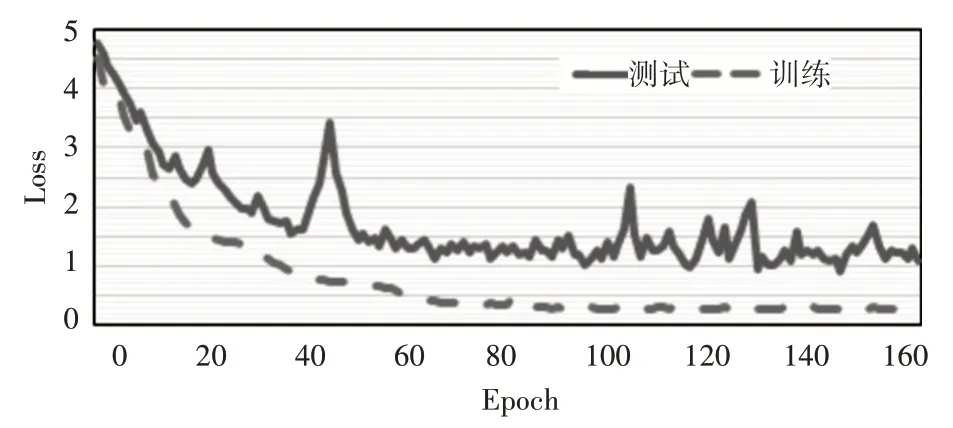
图9 3层ResNet网络损失变化

图10 3层ResNet网络精度变化
而对于人脸面部识别,本文主要是从标注好的人脸融合数据集中随机抽取60人,每个人含有120幅不同视角的人脸图像,其中80 幅图像作为训练图像,40 幅图像则用于测试。因此,本文在人脸分类KNN 模型中总共训练了4800 个人脸图像,其余2400 幅图像用于人脸识别测试。在实验中,我们定义K 的值为5,这就意味着5 个邻近的对象决定了被预测人脸的分类属性。在车内孩童人脸识别率和算法实时性上,该模型每秒可同时处理25 帧图片且平均识别准确率可达94%,其具体识别效果如图11所示。

图11 车内孩童人脸识别效果图
3.2 姿态估计实验
在车内孩童姿态估计实验中,分别依据自身采集的孩童姿态数据集CMP(28K/12K,训练/测试)和公开数据集FLIC(5K/1K,训练/测试)[15]对我们的姿态估计模型进行训练和测试。对于模型中的卷积/反卷积块的训练,不管是CMP或是FLIC数据集,本文都是采用学习率为0.0005 的ADAM 优化算法来降低模型的训练损失,并同时设置训练参数batch_size=64和epoch=100。
在孩童姿态估计算法的评估上,本文主要是从以下两个方面对其性能进行综合评估。
1)模型精度评估:在人体姿态的评估上,本文将人体正确定位关键点的标准百分比PCK(人体关键点定位预测落在其真实值标准范围内的百分比)作为其模型评估的度量指标。对于FLIC 数据集,本文在对人体躯干尺寸大小进行标准化之后,将PCK 设置为被检测的人体关键点与其真实值之间的百分比差异;对于CMP 数据集,这种百分比差异PCKh则是对人体头部尺寸大小进行标准化而形成的。PCK评价指标的公式如下所示:
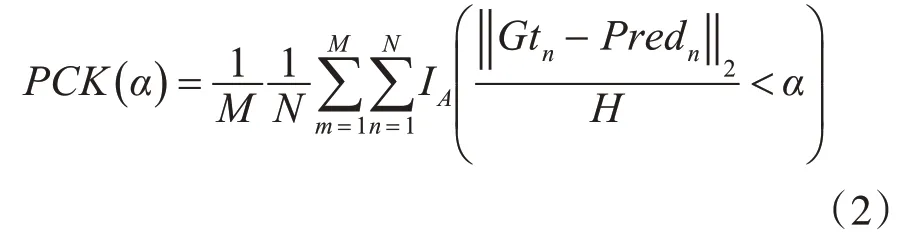
其中M是数据集的尺寸;N是人体关键点的数量;IA(·) 是一个指示函数:如果(·) 里成立则IA等于1,否则IA则是0;‖Gtn-Predn‖2则表示被预测人体关键点n的位置与其真实值之间的欧几里德距离;标准化H则是PCK人体躯干尺寸和PCKh人体头部尺寸的一半;α则是人为设定的阈值,其是为了评估人体关键点是否被正确预测到。
表2总结了模型在CMP数据集上的性能评估,实验发现我们的模型在CMP 数据集上所有关键点定位(肩膀、肘部、腕部等)上都实现了最优的结果。而表3则总结了模型在FLIC数据集上的结果,其中肘部的PCK 达到了99.2%,腕部则是97.3%。综合而言,由于模型在多尺度特征监督和关键点全局联合回归上的改进,其在肩膀、肘部、手腕等关键点的预测和定位上都表现的很好。
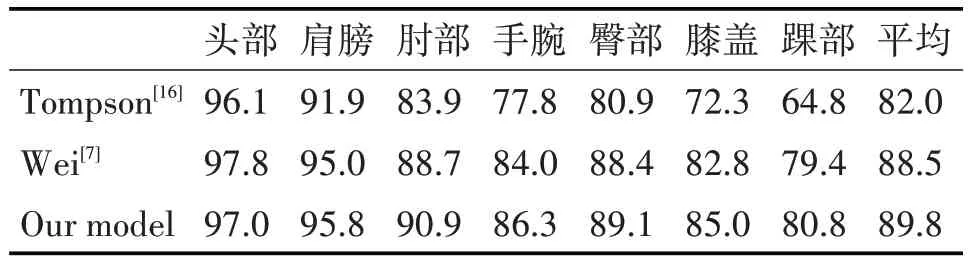
表2 CMP姿态数据集评估结果
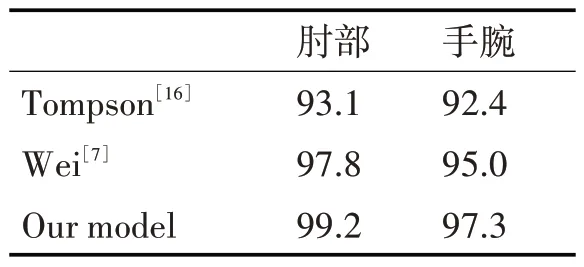
表3 FLIC数据集评估结果
2)模型遮挡处理评估:遮挡问题是人体姿态估计的一个常见挑战。我们在提出的CMP 孩童姿态测试集的一个子集上评估了我们的模型,该测试集具有可用的被遮挡的孩童关键点标签。本文提出的姿态估计模型主要是关注可见身体部位的相连部分,并从中推断出被遮挡的人体关键点,例如,模型可以从可见的肩部和手腕位置恢复被遮挡的肘部关键点。该姿态估计实验可以评估所提出的关键点全局回归网络是如何在多尺度特征监督下实现关键点遮挡的恢复,在PCKh=0.5 和GT、GT/2、GT/4 等多尺度真值的监督下,孩童关键点预测的定位精度是86.7%。相比之下,在模型没有多尺度监督的情况下,精度则是84.3%。
最后,我们对车内孩童的姿态估计进行了实验,其实验效果如图12所示。

图12 车内孩童姿态估计实验效果图
4 结语
为了保障车内疑似滞留孩童的生命安全,在考虑到算法实时性、精度以及车内遮挡等问题的基础上,本文主要是基于卷积神经网络的方法提出了孩童面部识别和姿态估计算法,在孩童的面部识别上,主要是采用ResNet 网络和KNN 算法来实现人脸面部的特征提取和精确识别;在孩童姿态估计上,主要是采用多尺度监督和关键点全局回归的方式来推断出被遮挡的人体关键点位置。最后,再结合孩童在车内的当前状态和车内二氧化碳浓度的变化情况建立车内智能监控及分级预警模型。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
读友·少年文学(清雅版)(2020年5期)2020-09-09 09:40:16
Coco薇(2017年10期)2017-10-12 18:45:27
金色年华(2017年11期)2017-07-18 11:08:40
摄影之友(2016年12期)2017-02-27 14:13:20
家庭百事通(2016年10期)2016-10-11 20:13:59
摄影之友(2016年8期)2016-05-14 11:30:04
家庭百事通(2016年3期)2016-03-14 08:07:17
中国卫生(2014年2期)2014-11-12 13:00:16
