
融合self_attention 的词级交互文本分类模型研究*
2022-09-28 01:40吴思怡吴陈
计算机与数字工程 2022年8期
吴思怡 吴陈
(江苏科技大学计算机学院 镇江 212100)
1 引言
在互联网和大数据时代,人人既是数据的接收者也是生产者,数据之间的互联互通给我们带来了便利,但同时也产生了限制。因为每个人的注意力是短暂的,精力也是有限的,如何在纷繁复杂的数据海洋中高效准确地找到所需的信息,似乎是一个难题。这也显示出准确有效地将文本分类管理是具有重大意义的。
文本分类是自然语言处理研究中的任务之一,其目的就是将一段文本内容分类为一个或多个类别。它的应用也非常广泛,比如:垃圾过滤,新闻分类,词性标注等[1]。
深度神经网络已成为文本分类的有效解决方案。深度神经网络一般是学习输入文本的单词级表示,输入文本通常是矩阵,每行/列作为文本中单词的嵌入[2]。然后,将字级表示压缩成具有聚合操作的文本级表示。然后通过最后一层(全连接层)作出最后的结果判断。虽然已经取得了很大的成功,但是这些基于深度神经网络的解决方案忽略了细粒度的分类线索,因为它们的分类是基于文本级表示。这样,文本属于某个类的概率很大程度上取决于它的整体匹配分数,而不是字级匹配信号,然而这些字级匹配信号将提供用于分类的显式信号(例如,原子弹强烈地指示军事的主题)[3]。
因此,为了解决上述问题,本文提出了一种新的融合自注意力机制的词级交互模型,该模型主要分为三层:自注意力层,交互层,聚合层。
2 相关介绍
2.1 Self_Attention机制
受人类注意力观察机制的启发,注意力机制在20 世纪90 年代就被视觉领域作为一种理论思想,即人们在观察一个事物时,是无法一次性观察到整个事物细节形态,而是将注意力集中在某个部分,然后根据我们所观察学习到的特征去寻找注意力应该集中的位置。直到2014 年,谷歌团队发表了文章《Recurrent Models of Visual Attention》之后,注意力机制才真正被相关学者关注。次年,该机制被应用到自然语言处理当中的机器翻译研究领域,其采用Seq2Seq+Attention 模型来进行机器翻译,提高了现有模型准确率[4]。而在2017 年谷歌公司发表的《Attention is All You Need》文章中,其翻译模型中只采用了注意力机制就取得了很好的结果[5],从此,对于注意力机制的研究和应用被推上了更高层次。注意力机制又分为层次注意力、循环注意力、多头注意力等,因为本文主要针对长文本进行分类研究,所以在文中我们采用了注意力机制中的自注意力机制模型,该模型特点就是能够使文本中的组成长句子的随机两个词语产生联系,所以即使是距离较远的特征也能够被充分利用。
2.2 Word2vec词向量
在NLP中,最细粒度的对象是词语。我们最常使用的词性标注方法是贝叶斯等传统算法,即利用样本数据(x,y),其中x表示词语,y表示词性,然后找到x→y的映射关系。但在自然语言中,我们所使用的文字、图标等都是符号化的,要将这些信息加入到数学模型当中,就必须将其转换为数值形式进行处理。这个过程也可以理解成将符号信息对应地嵌入到数学空间中,即词嵌入(word embedding)。Word2vec 是词嵌入的一种,其是用一层的神经网络(即CBOW)把one-hot 形式的稀疏词向量映射成为一个n维稠密向量的过程[7]。其优势在于能够利用词的上下文信息,使语义信息更加饱满,较于传统NLP 的高维、稀疏的表示法(One-hot Representation),Word2vec训练出的词向量是低维、稠密的[8]。Word2vec常应用两个方面:
1)使用训练出的词向量作为输入特征,提升现有系统,如应用在情感分析、词性标注、语言翻译等神经网络中的输入层。
2)直接从语言学的角度对词向量进行应用,如使用向量的距离表示词语相似度、query相关性等[9]。
3 模型实现
在本文中,我们提出的模型如图1 所示,主要包含以下几层:自注意力层,交互层,聚合层。
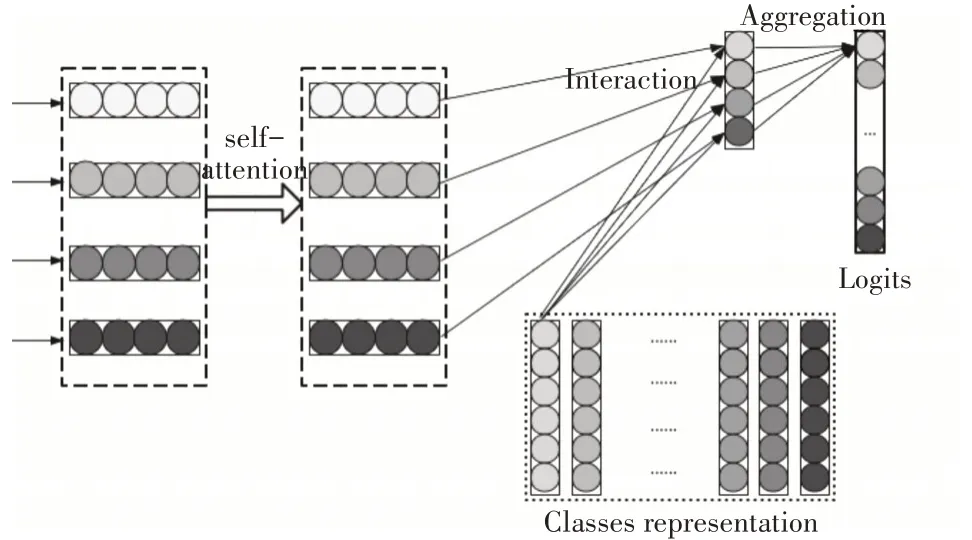
图1 基于自注意力机制的显式交互文本分类模型
3.1 自注意力层
这一层主要是从输入文档的词向量矩阵中获得相互联系的特征向量矩阵。将文档D={x1,x2,…,xn},n代表的是文档中词的个数,xi代表是文档中第i个词的词向量,其维度为d。将文本D通过全连接,再激活得到新的矩阵Q,Q∈Rn×d。公式即为
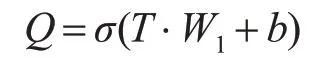
其中σ代表激活函数,激活函数有tanh 函数,sigmoid 函数,relu 函数等,此处选择relu 函数作为激活函数。
如图2所示,原词向量矩阵D激活后得到矩阵Q,通过D矩阵与Q的转置矩阵做点乘运算:
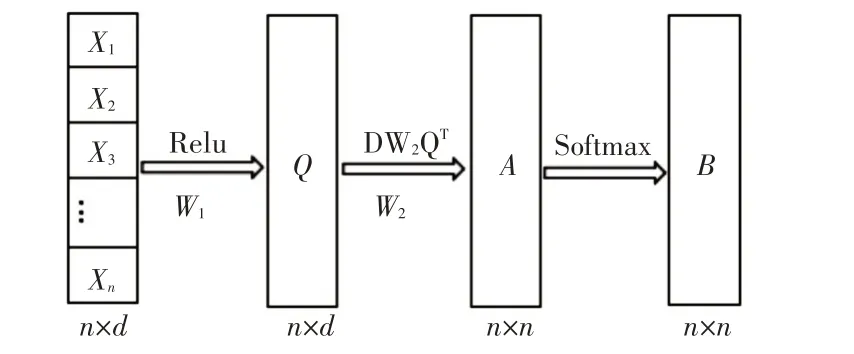
图2 词向量处理
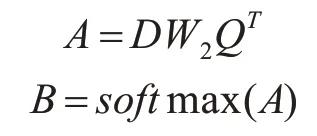
自注意力矩阵B(B∈Rn×n)中每一个元素是矩阵A(A∈Rn×n)中的每一行通过softmax 函数分类所得:
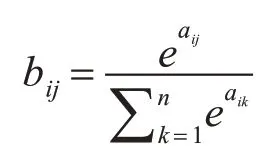
其中aij表示矩阵A中的第i行第j列元素,bij代表B矩阵中第i行第j列元素。
将矩阵B与原词向量矩阵D进行如下计算得到自注意力矩阵C(C∈Rn×d):
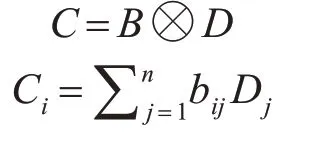
其中U代表B矩阵中每一行元素bij与D矩阵中每一行Dj向量相乘累加得到C矩阵中的一行Ci。
3.2 交互层
交互机制的关键思想是使用小单元之间的交互特征(例如文本内容中的单词)来推断两个内容是否匹配的细粒度线索[10]。受基于编码的方法的交互机制以匹配文本内容的方法的成功启发,我们将交互机制引入到将文本内容与其类(即文本分类)匹配的任务中。本文设计一个交互层,主要用来计算单词与类之间的匹配度。使用可训练的表示矩阵T∈Rk×d来编码类(其中每一行表示一个类),k表示类的数量,d是维度,等于单词的大小。通过点积作为交互函数来估计目标词i与类j的匹配程度,公式如下:
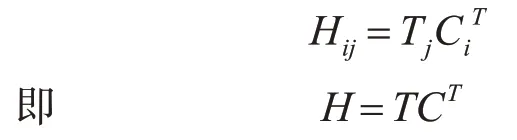
其中C∈Rn×d是自注意力层处理过得到的关于文本的字级表示,其中n代表文本的长度。经过以上这种方式我们可以得到交互矩阵H∈Rk×n。
3.3 聚合层
该层被设计为将每个类是s的交互特征聚合成logits Ois,其表示类s和输入文本xi之间的匹配数。聚合层可以使用CNN 或者LSTM,但是,为了保持模型的简单性和高效性,这里我们只使用具有两个FC 层的MLP,其中relu 是第一层的激活函数。形式上,MLP聚合类s的交互特征Hs,并计算其关联的logits如下:
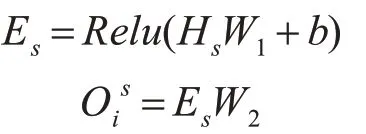
其中W1和W2是可训练参数,b是第一层中的偏差。然后,我们将logits oi=归一化为概率pi,根据前人的实验,我们使用sigmoid 函数对新闻文本进行多标签分类。
4 实验研究
4.1 实验方案
本文是采用的是对比实验,在数据集下,通过跟不同的文本分类模型对比文本分类准确度和召回率等。我们采用的两个数据集,中文数据集有复旦中文文本分类数据集,此数据集中一共有19637篇文档,其中测试语料有9833 篇,训练语料9804篇,分为20 个类别;英文数据集有DBpedia 两个数据集,其中DBpedia数据集中包含14个不重叠的类别,含40000个训练样本和5000 个测试样本。
4.2 评估标准
在分类模型中,有很多用于评估模型的标准,本文中主要用到的有准确率,召回率和F1 函数。准确率是指正例判断正确的个数与模型预测输出的正例的总个数之比[11]。模型预测为正例的情况有两种:一种是将正例预测为正例(TP),另外一种是将负例预测为正例(FP)。准确率计算表达式如下:
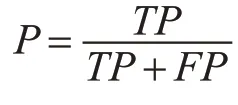
召回率是指正例判断正确的个数与真正的正例样本的总个数,这其中也有两种预测情况,一是将样本中的正例预测为正例(TP),二是将样本中的正例预测为负例(FN)[12]。召回率计算公式如下:
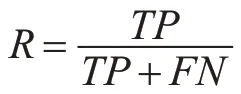
理想情况下,精确率和召回率两者都越高越好。然而事实上这两者在某些情况下是矛盾的,精确率高时,召回率低;精确率低时,召回率高[13]。综合考虑之下,我们引入F1 函数,F1 值是精确率和召回率的调和均值,具体公式如下:
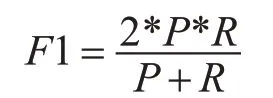
4.3 实验结果分析
从下面的对比结果表1 中可以看出,本文模型在基于词级的新闻文本分类中显示出了一定的优势;图3 为不同模型下的分类指标的柱状对比图,从准确率和F1 两方面来看,相对于CNN、RCNN 两个模型,我们的模型有了显著的提高。在现有的文本分类性模型中,主要分为两类:一种是基于特征的模型,另外一种是深度神经网络分类模型[14]。前者比较偏向为人工特征,采用机器学习算法作为分类器。后者深度神经模型,利用神经网络完成数据模型学习,已成为文本分类的很有前景的一种解决方案。目前已经提出的深度网络学习模型有很多,例如,Iyyer 等提出深度平均网络(DAN)和Grave 等提出了FastText,两者都很简单但效率很高[15]。为了获得文本中单词之间的时间特征,一些模型如TextCNN(Kim 2014)和Char-CNN(Zhang,Zhao 和LeCun 2015)利用卷积神经网络,还有一些模型基于递归神经网络(RNN)[16]。约翰逊等研究了剩余架构并建立了一个名为VD-CNN 和Qiao 等的模型。后来又有人提出了一种用于文本分类的区域嵌入的新方法。但是,如简介中所述,所有这些方法都是文本级模型,而本文所提出的模型是在单词级别进行匹配。交互机制在自然语言处理中应用很广泛,它的关键思想是使用小单元之间的交互特征(如句子中的单词)进行匹配[17]。王等提出了一个“匹配-聚合”框架来执行自然语言推理中的交互。再后来Munkhdalai 等提出了一个密集交互式的推理网络,使用DenseNet 来聚合密集的交互功能[18]。我们的工作与他们的研究有所不同,因为他们主要将这种机制应用于文本匹配而不是分类。
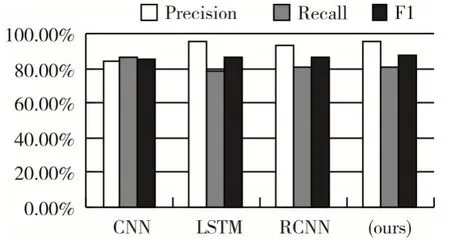
图3 不同分类模型下的分类指标柱状图
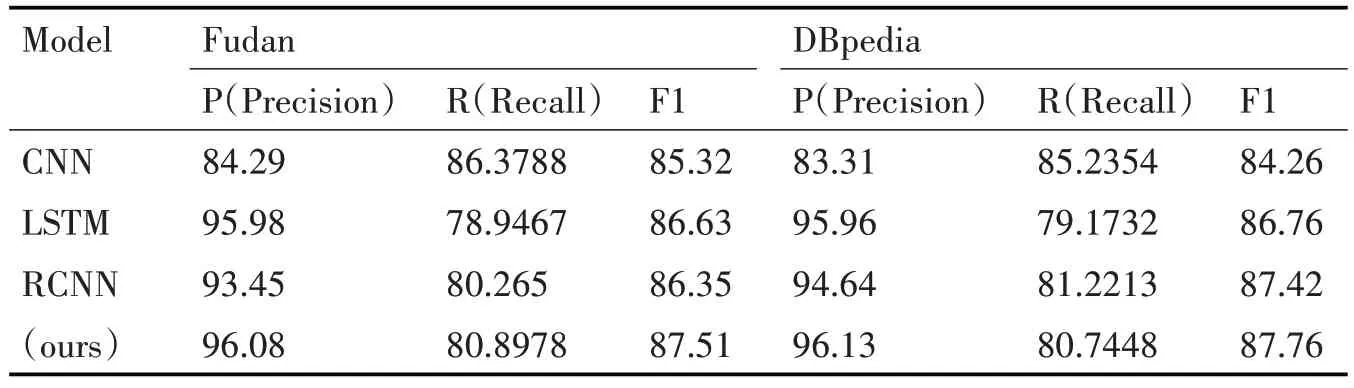
表1 中英文数据集下各个模型的准确率
5 结语
在本文的模型中,我们为了充分利用长文本中两个词向量之间的依赖特征,而选择采用了注意力机制中的自注意力模型,其能将两个长距离的词之间的关系直接计算出来,并从中了解句子的内部结构,使模型中得到更为精准的词向量特征。我们将这种处理机制融合到交互分类模型中,应用交互机制来明确地计算文本分类的单词级交互信号。本文在中英文文本数据集上面测试模型性能,该模型优化了当前已有模型中的基于文本级匹配而忽略词级匹配的缺点,通过具体计算词与类之间的匹配度,充分利用词与类的关系来完成更精细的分类问题。在未来的研究工作中,我们将会在准确度以及运行耗时方面进一步优化模型。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
新高考·高一数学(2022年3期)2022-04-28
煤气与热力(2022年2期)2022-03-09
读与写·教育教学版(2017年10期)2017-11-10
软件(2017年6期)2017-09-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
