
改进型Cascada R-CNN 的行人检测算法的研究*
2022-09-28 01:40贾叙文刘庆华刘东华李杨黄凯枫
计算机与数字工程 2022年8期
贾叙文 刘庆华 刘东华 李杨 黄凯枫
(江苏科技大学 镇江 212003)
1 引言
行人检测是计算机视觉中的一个重要命题,有着悠久的发展历史。其中比较经典的算法有NAVNEET D 等提出的梯度直方图特征(Histogram of oriented gradient,HOG)的特征描述法再加支持向量机进行行人检测[1],这使得行人检测在计算机视觉领域获得重大突破,之后此方法获得进一步改进,出现了可变形部件模型(Deformable part models,DPM)方法、聚合通道特征(Aggregation channel feature,ACF)方法等,此类方法虽然在发展过程中解决了部分问题,如局部遮挡等,但其缺点也是尤为突出,需要大量人工设置的参数,这导致这类算法很大程度只能应用到一些固定的场景环境当中。随着神经网络、深度学习不断应用到图像识别和目标检测当中,人们找到了另外的行人检测思路。目前深度学习中的目标检测可以大致分为两大类,一类是以Faster R-CNN[2]这类为代表的目标区域建议的目标检测算法;另一类是YOLOv3[3]这类基于回归算法为代表的算法,比较常见出名的有SSD[4]、RetinaNet[5]等算法。前者的这类算法具有较好的精确度,但需要大量的计算机资源,后者主要用于实时检测,但检测性能还是存在很大的改进潜力。而本文通过对Faster R-CNN 和Cascada R-CNN[6]的学习研究,改进了原有Cascada R-CNN模型,本文称之为改进型Cascada R-CNN 算法模型。
2 Cascada R-CNN算法
Cascada R-CNN 算法本身是以Faster R-CNN为基础多次优化算法,其可以解决因IoU 值的设置问题而导致出现小样本训练时的mismatch 等问题。Faster R-CNN 的传统做法是将IoU 值设置为0.5 以兼顾准确性和mismatch 和过拟合等问题,为此Zhao-wei等[7]还设计出了muti-stage 的结构,用来在不同的阶段设置不同的IoU 值,也就是通过级联的方式逐级提高IoU 值,以此来提高检测的准确性。这种方式的本质就是前一个阶段的输出作为后一个阶段的输入,在这个过程中IoU 值逐级提高,这样的好处是在小样本情况下可以有效的防止过拟合现象并提高检测的准确性。IoU值级联回归问题构架公式[8]为
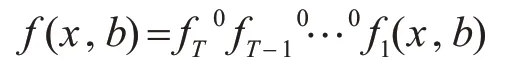
其中T为级联阶段数,ft为预优化的项,x表示本阶段你输入的图片,b表示本阶段图片对应的检测框。Cascada R-CNN 模型的实现过程就是对Faster R-CNN 实现多联级的扩展。Cascada R-CNN 模型是由一个用于生成候选区的RPN 阶段和三个检测阶段组成,本文改进型Cascada R-CNN 的结构如图1,其IoU分别设置为0.5,0.6和0.7。其流程大致可以理解为H0 对输入图片进行处理产生候选区RPN,之后的阶段对第一阶段的RPN进行处理完成分类和边框模块选择。原来的Cascada R-CNN 模型还存在一些问题,比如用于行人检测时对小尺度行人检测会导致误测,检测准确率低,其模型的候选框是对多类目标进行检测,而本文的目标只是让其对行人目标作出准确的检测和识别,在此基础上能够达到快速准确的检测结果,所以本文就此对模型可以提高的地方进行了改进。
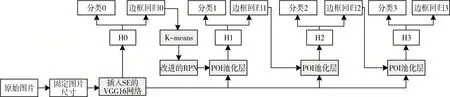
图1 改进型的Cascada R-CNN模型
3 Cascada R-CNN改进思路
通过对Cascada R-CNN 模型网络结构的学习了解,本文是以改进整个网络中的几个模块网络来提升Cascada R-CNN 模型的整体性能,在第一个共享卷积层时本文改进了原本的VGG16 网络,在对原本的RPN 分析了原本的一些问题原因,针对这些问题尤其是小尺度行人检测作出了一些改进方法,具体分析如下文。
3.1 共享卷积层改进
Shared convolution 层使用的是VGG16[9]网络,而VGG16 网络是由5 个最大池化层、3 个全连接层、13 个卷积层组成的网络结构,这样的结构中就可以引入SE嵌入模块和K-means聚类网络[10]。SE模块中包含的基本操作是池化和全连接,所以可以在VGG16 网络中的每一层的最大池化层中加上一层SE 网络层用来处理池化层之前的卷积特征集,这样在处理遮挡和小尺度行人[11]检测时,能够有效地提高准确度。
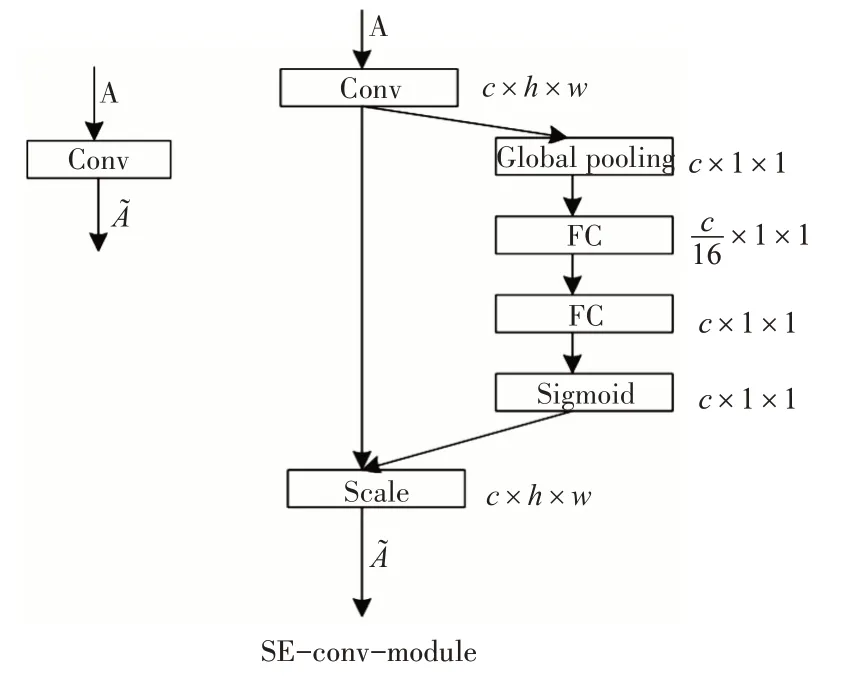
图2 SE-conv-moudle模块
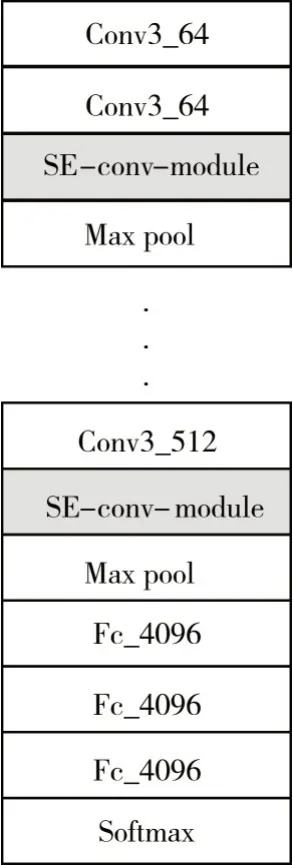
图3 改进的VGG16网路模块
3.2 RPN改进
首先可以固定RPN 中的Anchor 的宽高比,因为用于行人检测的候选框通常可以看成是瘦长直立型的,其宽高比一般为0.41[12]和以及一些其他相近的数值,具体参数根据训练集进行设置,这个参数需要设置固定好;其次在POI 池化层中原来的Cascada R-CNN 模型中存在两次浮点取整操作,该网络将原图的ROI 坐标(左上角与右下角的坐标值)进行池化操作,使其缩小为原图的十六分之一[13],其过程需要两次取整,导致的问题是RoI pooling提取的特征图与原图不对齐,所以在这个过程中可以采用双线性插值来对齐RoI pooling 提取出的特征图,改进过程就是在RoI pooling 过程中不进行取整运算而保留小数,然后通过双线性插值[14]对每个采样点进行估值,插值完成对每个区域进行Max Pooling,整个过程避免了取整操作,这样有效地保留了提取出的特征图的对应位置,并且在进入RPN 之前引入了K-means 聚类算法,K-means 聚类算法可以加速候选区域的收敛速度,K-means聚类方法测量两点间距离使用的是欧式距离测量法,其作用是聚类单位网格长与候选框宽高比例。K-means的聚类函数为
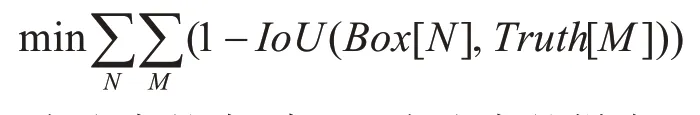
其中N为聚类的类别;M为聚类的样本;Box[N]为候选区域的宽和高;Box[M]为实际的人的区域的宽和高。
下面说明双线性插值方法:在图像提取特征图之坐标都为原来的十六分之一,我们以特征图的中心点为坐标原点设为P(x,y),图中各点的坐标为Q11(x1,y1),Q12(x2,y1),Q21(x1,y2),Q22(x2,y2),p=x-[x],q=y-[y],x1=[x],y1=[y],[n]为取整操作,是不大于n的最大整数。双插值操作就是先在X方向上插值一次,由Q11(x1,y1)、Q12(x2,y1)得到R1(x,y1)的灰度值为
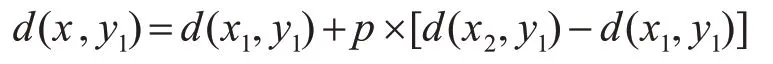
同理再在X方向再进行一次插值得到R2(x,y2),其灰度值为
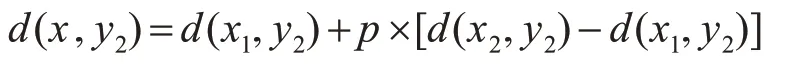
之后再通过R1(x,y1)、R2(x,y2)的灰度值在Y方向进行一次插值得到P(x,y)的灰度值为
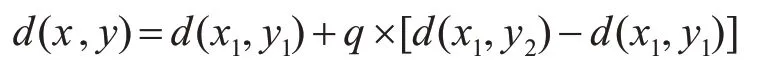
双线性插值避免了特征图坐标的取整操作,保留了高质量的特征图、完整的位置信息。
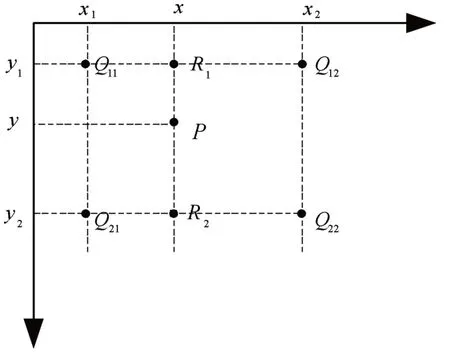
图4 双线性插值法
4 试验结果与分析
本次实验训练采用的是INRIA 数据集[15],INRIA 数据集包含15560 个正样本和6744 个负样本,本次实验训练集选取了该数据集中3000 张正样本和1000张负样本,然后选取300张该数据集的图片和自制的500 张某段街区采集的的行人图片作为测试集。实验环境PyTorch+mmdetection。最终本文的改进型Cascada R-CNN 模型的在行人检测数据集中获得了90.1%准确率的好成绩。在自制的检测集内的检测结果如图5。

图5 自制测试集检测结果
改进型Cascada R-CNN 模型和Cascada R-CNN 模型以及Faster R-CNN 模型检测结果对比如表1。

表1 实验结果对比
由表1 可以知道改型的Cascada R-CNN 模型的准确率比Faster R-CNN 和Cascada R-CNN 具有更高的识别精确度,在性能上也优于原来的Cascada R-CNN模型。
5 结语
本文提出了一种改进型Cascada R-CNN 行人检测模型,在INRIA 数据集进行了训练,并在INRIA 数据集中挑选测试图片和自制的图片制作了测试集并在测试集中取得了的AP 为90.1%的成绩,但是在检测速度上有不足的地方,可以在后续的实验中在保证检测准确率的前提下改善网络结构,尽可能减少网络复杂度提高运行速度;同时在对远处小尺度样本进行检测时,任然会有误测,无法固定行人位置等问题,这些问题可以通过后续改进RPN 中的特征提取方式,将色彩位置信息丰富的低层特征图与具有高级语义信息的高层特征图相结合,让网络获得更加准确的特征图,这样可以对远处的小样本进行更加准确的检测。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
人民黄河(2021年4期)2021-04-27
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
环境与发展(2018年6期)2018-09-17
城市地理(2017年9期)2017-11-02
轻兵器(2017年2期)2017-03-10
电子技术与软件工程(2016年23期)2017-03-06
轻兵器(2016年20期)2016-10-28
轻兵器(2016年9期)2016-05-10
计算技术与自动化(2014年1期)2014-12-12
