
基于双缓冲的分布式爬虫调度策略的设计与研究*
2022-09-28 01:40:18卢照张耀午
计算机与数字工程 2022年8期
卢照 师 军 张耀午 王 琦
(1.运城学院数学与信息技术学院 运城 044000)(2.陕西师范大学计算机科学学院 西安 710100)
1 引言
网络信息以指数级的速度增长,面对如此海量的数据信息,如何保证数据采集的完整性与实时性将是一个很大挑战。目前主流开源爬虫框架在网络通信开销上优化甚少,缺乏一个有效的方案减少网络开销问题。大量的通信开销不但给服务器带来巨大的压力,也在很大程度上限制了并行系统,使之性能无法得到充分的发挥。
刘爽等[1]针对分布式搜索引擎的任务调度及负载均衡问题,提出了基于GNP 算法的分布式爬虫调度策略和负载均衡的方法,利用网络延迟建立GNP 坐标,通过测量选择合适的通信节点进行通讯。这不但提高了集群灵敏度,还减轻了对服务端的请求压力。黄志敏等[2]提出了一种基于Kademlia的全分布式爬虫集群方法。该方法基于Kademlia 构建出了爬虫集群底层的通信机制,不仅继承了Kademlia的多种优良性质,还设计出了具备高扩展性、强鲁棒性的全分布式爬虫集群模型。董禹龙等[3]提出了一种主动获取任务式的分布式网络爬虫方法,通过评估节点负载及运行状况,主动向中控节点申请任务队列。马蕾等[4]采用Nutch 爬虫框架和Zookeeper 分布式协调服务,运用提取页面信息算法优化提取页面信息流程,关键词匹配优化算法抓取相关数据。本文以减少通信开销为突破点,结合对等式架构任务被消费的特点,提出了任务在尽量在本地执行的优化方向。让原本需要远程处理的任务尽量在本地执行,从而减少任务调度上的通信开销。
2 分布式框架介绍
2.1 开源爬虫框架介绍
Scrapy 是一个快速、高层次的屏幕抓取和Web抓取框架,该框架耦合度低,任何人均可依据自己的需求进行扩展,属于目前最为火爆的开源爬虫框架之一。Redis 是一个完全开源免费,遵守BSD 协议的高性能Key-Value 数据库[5]。Scrapy-Redis 是就是通过利用Redis 实现共享任务队列与URL 去重集合,使得Scrapy单机爬虫项目能够轻松扩展到多台机器上,从而实现较大规模的爬虫集群。但是由于Scrapy-Redis 框架内部访问的设计问题通信访问十分频繁,从而导致爬取效率低下,网络延迟成为了该框架的性能瓶颈。
2.2 分布式爬虫架构
分布式爬虫系统通常分为主从式与对等式这两种架构形式。主从式架构通常由一台性能强劲的Master 主服务器与多台Slave 从服务器构成,主服务器负责分配待抓取的URL 任务到每台从服务器上,并协调各个Slave节点的任务负载,由于主节点通常对硬件要求苛刻,往往会成为分布式系统的瓶颈。对等式架构所有爬虫节点在分工与运作逻辑是一致的,去中心化的设计使得分布式系统具有更强的处理能力和可靠性,服务器对硬件的要求比主从架构要求低。
2.3 负载均衡策略
依据负载能否在运行前被事先划分,负载均衡可分为静态与动态两类[6]。若负载划分比例能够事先被确定,则属于静态负载均衡,常见的静态负载均衡有简单轮询法、加权轮询法、一致性哈希法。若负载划分比例仅在运行时才能被确定,则属于动态负载均衡,为了避免去中心化方法带来的通信负载高、难以扩展等问题,“紧邻法”被广泛应用于解决同构网络下的动态负载均衡问题[7]。由于分布式系统可能由性能差异很大的主机构成,且网络通信延迟不可预测,都使得负载难以被事先估计,静态负载均衡算法难以再起作用[8]。本文采用梯度法作为本分布式爬虫系统的动态负载均衡算法,它能够动态均摊各个节点多余的负载,拥有较强的扩展性。
3 双缓冲的分布式调度设计
3.1 设计思想
考虑到广域网上延迟对爬虫效率带来的严重影响,又由于无法改变网络延迟这一硬性条件,所以如何减少远程服务器的访问次数是提高效率的关键。分布式爬虫主要的网络通信开销在“URL判重”、“任务调度分配”上。所以想要以减轻通信开销的方式提高集群的运作效率,应最主要从“URL判重”与“任务调度分配”这两个通信开销下手。针对“对等式分布式爬虫”,每个爬虫节点同时扮演着既是任务的生产者又是任务的消费者这一特点,可以通过“自产自销”的方式来减少任务调度的通信开销,节点依据自己的消费能力,通过动态负载均衡算法,将多余负载压缩为大粒度任务进行传输,来能有效的降低通信频次。结合互联网结构特点与同站点网页结构相似性,URL在短时间内很可能会被反复判重,可以通过本地缓存,记录URL 判重查询的结果,当同以URL 被再次查询时,就可以不通过远程访问完成URL 判重任务,从而减低远程服务器访问压力,进而提升去重的效率。
3.2 设计架构
基于Scrapy-Redis 框架进行二次开发,采用Python 语言作为编码语言。系统采用对等式架构设计,每一个爬行器都是一个逻辑独立的个体,没有主从角色之分[9]。每一个节点都能够独立实现任务的爬取、网页的解析、内容的存储以及任务与状态信息的共享。利用Zookeeper作为爬行器之间状态信息交换的媒介,采用Redis 作为分布式爬虫的判重信息与任务信息交换的媒介[10]。
这样的设计的好处是节约成本、扩大应用范围,当爬行器数量增多时,中心交换可能沦为性能的瓶颈。为了解除瓶颈,只需将Redis 与Zookeeper改用集群模式而不用改变爬虫的配置,如此松耦合的设计为部署带来极大的便利。通过对Scheduler进行扩展来实现分布式,Scheduler主要由智能队列模块、去重模块、集群通信模块构成,其中“集群通信模块”负责收集与传递节点的状态信息,为动态负载均衡提供前提条件。“智能队列模块”由一个本地缓冲队列与远程队列访问接口组成,爬取的任务在本地缓冲队列中“自产自销”,通过负载均衡算法将多余负载压缩传递到其他节点中。Scheduler 功能结构图如图1所示。
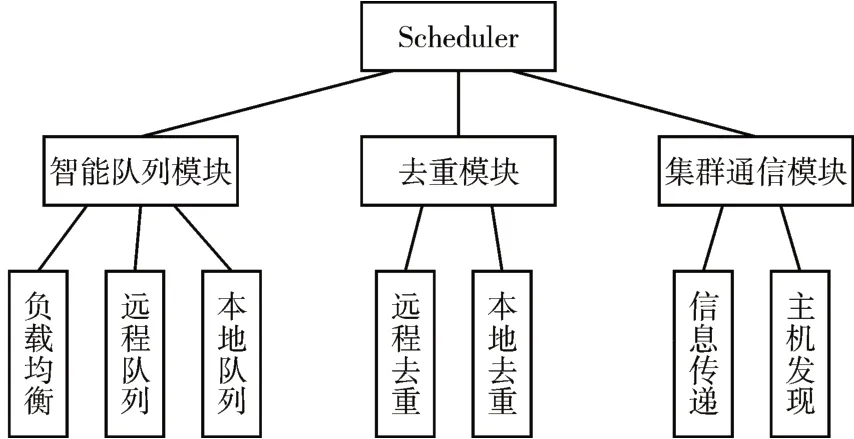
图1 Scheduler功能结构图
“集群通信模块”通过固定访问频率来进行节点之间状态信息交换,这能使得远程频率较为均匀,不会使服务端出现访问压力大幅度波动,有利于提高分布式系统的稳定性[11]。
由于访问延迟不可预测,所以“任务吞吐量”参数应该被动态测量。但由于动态测量值抖动现象比较严重,不利于集群的稳定性,因此通过一个固定长度的队列来对采集到的吞吐量信息进行收集,之后再对收集到的信息求平均值,从而获得较为稳定的值。通过这样的方法,既能够动态的采集状态信息,又能够输出稳定可靠的值,还能通过控制队列的长度的方式调整采集的灵敏度。同时集群通信模块采用“观察者设计模式”实现节点数量发现功能,利用Zookeeper的临时节点概念,当客户端连接上Zookeeper 的时候就会持续发送心跳,从而保持这个节点存在[12]。通过对Zookeeper 进行分析,就能得知有多少个爬虫正处于上线状态,节点状态转换图如图2所示。
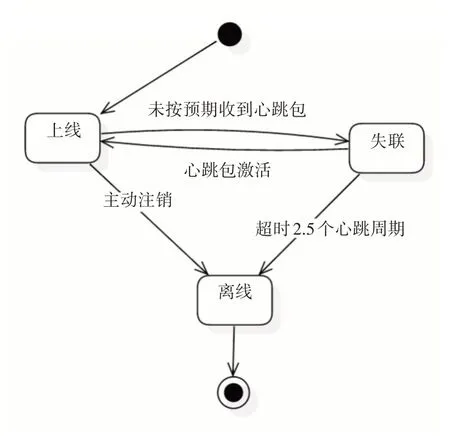
图2 节点状态转换图
3.3 大粒度传输与缓存辅助去重
并行系统看起来就像管道系统,当你将不同横截面积的管道(吞吐量)连接起来,直观上总系统的吞吐量会受限于最窄的管道(最小的吞吐量T)并且与其摆放位置有着重要关系。所以应该着重在最窄的管道上进行性能优化,否则吞吐量提升效果几乎是微乎其微的。
智能队列模块采用“策略设计模式”,它会通过固定访问频次来分析其他节点的状态进行负载量计算,通过连通器水平衡原理计算出运载量[13]。当运载量为正值时,从本地队列尾部获取任务后压缩为一次请求上传到远端队列上,当运载量为负值时,从远端队列获取任务并放入本地队列尾端,负载转移流程如图3所示。

图3 负载量转移流程图
爬虫负载任务量的多少决定了节点的负载压力。当爬取速度达到吞吐量顶峰时,负载的压力几乎不影响任务处理的吞吐量。负载均衡主要工作是分摊各节点的多余负载量,所以对算法收敛速度要求不会太苛刻,重点在减少通信交互次数。本文通过一个双向队列实现块状运输,负载均衡模块会伴随心跳对任务量进行计算,将多余的任务量从队列的尾端取出后压缩为一次请求放入远程队列中。去重查询属于I/O问题,在操作系统中,通常通过缓存的方式来解决快速设备与慢速设备速度不匹配的问题。可以用爬虫系统面临的网络延迟问题来类比此问题,通过将远端服务器的查询结果存储在本地缓存中,当本地需要再一次查询去重结果的时候,会在本地缓存中找到上一次访问记录,从而避免再一次通过远程访问获得结果,加快了查询速度。
当进行判重查询时,会先对BuerFilter(本地去重)进行询问,当本地无法判断的情况下将内容继续发送给BloomFilter(远端去重)进行去重[14]。在内存中构建本地去重库,能提升判重的速度,但是内存的资源也是很有限的,通过借鉴操作系统中的LRU(最近最少使用算法)来限定条目数量,让内存控制在一个合理的范围,虽然降低了判重命中率,但节省了大量的存储空间[15]。
LRU算法通过采用有序字典来实现,通过维护一个列表,在列表中存放URL,URL 经过HASH 后对应的地址存放True/False,当查询一个URL 的时候,会进行反向遍历查找并删除,并在列表的尾部重新放入,如此列表的尾部始终为最新查询信息,列表首部始终为最旧的查询信息[16]。当列表内存放长度到达限定值时,每次都从列表首部删去最旧的信息,腾出空间来存放最新的查询信息。
4 双缓冲分布式爬虫的实验
4.1 实验平台介绍
实验采取模拟网络延迟,对模拟站点进行爬取来确保结果尽量客观,减少无关项的干扰。在MacOS 系统下通过“NetworkLinkConditioner”软件来对网络延迟进行模拟,它能调用MacOS 底层,能让整个网络环境十分贴近真实的网络延迟。
4.2 数据分析
在带宽限制为10Mpbs,网络延迟满足线性增长的环境下进行访问测试。每次的测试任务量固定为100 个,延迟增长函数为10ms+N*20ms,其中N 范围(0~4),共计5 次测量,将测量结果绘制如图4所示。
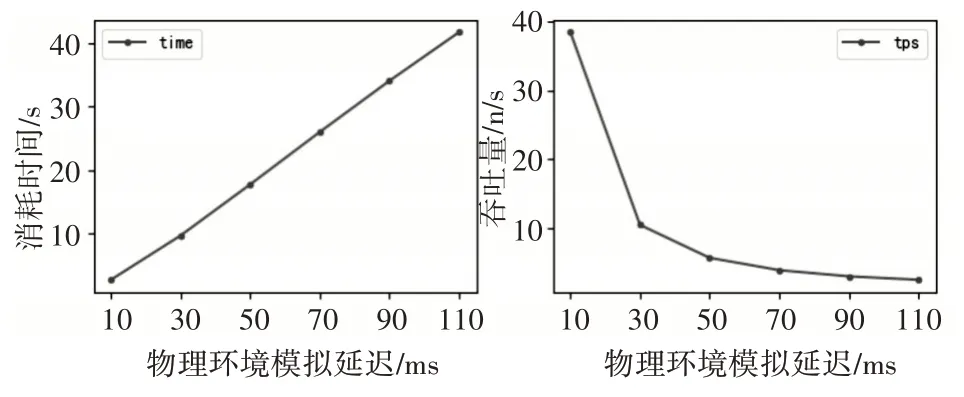
图4 不同延迟对吞吐量的影响图
通过这组测试,可以观察到当访问延迟随着时间呈线性增长时,吞吐量呈明显的非线性快速下降,网络访问延迟极大的限制了吞吐量,如此低的吞吐量会使得URL 去重效率低下、任务调度缓慢,无法充分发挥分布式系统的优势。若能越多的抵消访问延迟的影响,爬取速度收益就越会显著的提升。
在带宽限制为10Mpbs,网络延迟约为50ms 的环境下进行访问测试,每次的测试任务量固定为1000 个,运载粒度增长函数为10+N*10,其中N 范围(0~19),共计20 次测量,将测量结果绘制如图5所示。
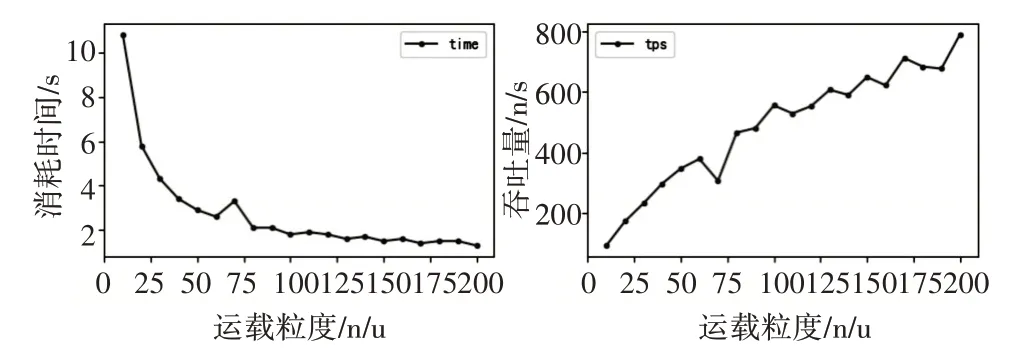
图5 运载粒度对吞吐量的影响图
通过这组测试,可以了解到随着运载粒度增大,完成1000 个URL 爬取所消耗的时间呈现反比例下降,这使得吞吐量提升呈现类抛物线提升,所以运载粒度并不是越大越好,应根据情况选择适合的运载粒度。
4.3 实验结果分析
在带宽限制为10Mpbs,网络延迟约为10ms 的环境下,采用三个节点构成的集群进行访问测试。采用集群监视器实现每秒钟对爬虫结果进行一次统计,共计120 次测量。通过调用Python 的matplotlib库对120次测量数据分析,绘制成图。该图x轴为爬取时间(单位:s),y 轴为标签上的所对应的信息值,实验结果图如图6所示。
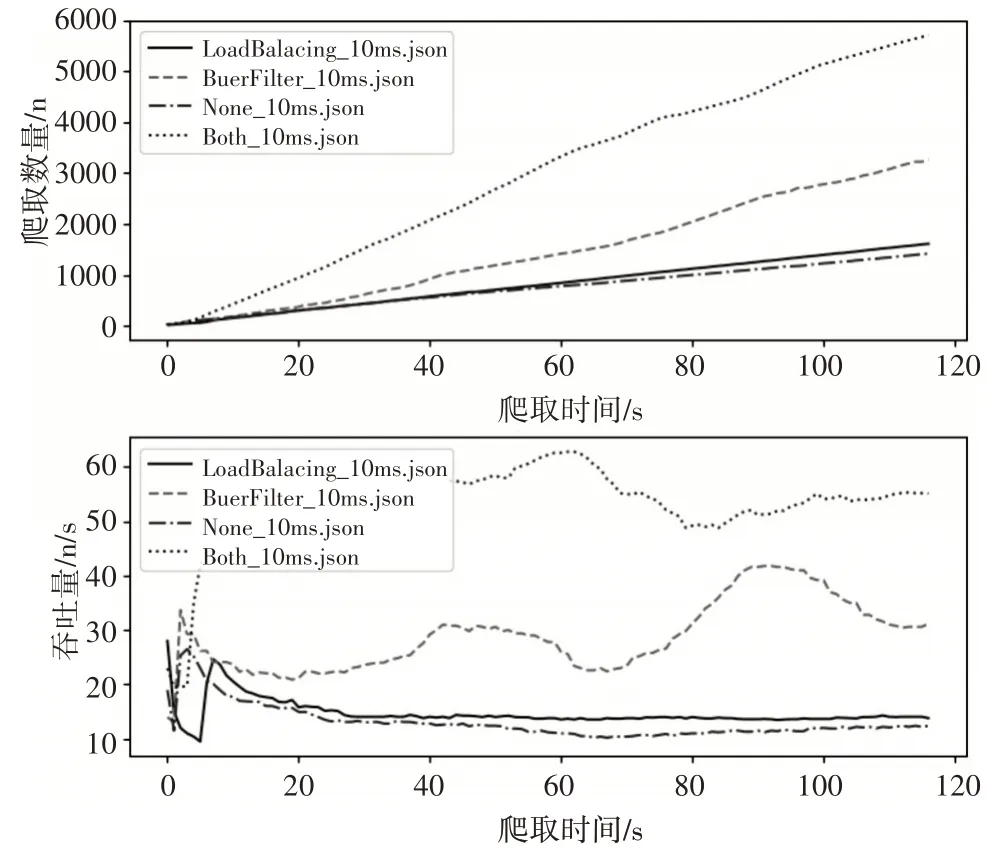
图6 实验结果图
LoadBalacing_10ms.json 为仅启动了负载均衡优化,BuerFilter_10ms.json 为仅启动了缓存去重优化,None_10ms.json 为没有优化的结果,Both_10ms.json 为同时采用了负载均衡与缓冲去重优化的结果。结果表明,URL 去重通信开销的最大,其次是任务调度的开销。在采用缓冲去重的状态下,再采用动态平衡大粒度传输任务,能使集群获得近4 倍的吞吐量提升。
5 结语
传统上几乎是通过类似多线程或是异步并发等方式[9],设法避开网络延迟带来的阻塞影响,这是一种提高吞吐量的可行方法,但是无法做到低成本。本文以降低通信开销为优化方向,通过“基于双缓冲的大粒度任务传输策略”与“基于高速缓存原理的本地缓存辅助去重方案”对分布式爬虫进行优化。采用这种方式的最大价值是它与传统方法并不冲突,甚至是可以与传统方法协同工作的。我们依然能利用多线程或是异步并发方式,使得吞吐量得到更进一步的提升。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
制造技术与机床(2019年4期)2019-04-04 12:22:06
测控技术(2018年7期)2018-12-09 08:58:00
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
集装箱化(2016年11期)2017-03-29 16:15:48
集装箱化(2016年12期)2017-03-20 08:32:27
信息通信技术(2015年6期)2015-12-26 01:16:54
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:45
