
面向多方对话的中文多模态情感语料库构建
2022-09-24 10:29:06徐洋蒋玉茹梁矗黄丁韫赵凯杨超宇张明嘉
北京信息科技大学学报(自然科学版) 2022年4期
徐洋,蒋玉茹,梁矗,黄丁韫,赵凯,杨超宇,张明嘉
(北京信息科技大学 智能信息处理实验室,北京 100192)
1 引言
具有智能的机器正成为现代生活不可或缺的一部分,而如何使聊天机器人等智能机器具备共情能力则是当前研究中面临的挑战。构建供机器自动学习识别情感、表达情感的语料库是基于有监督机器学习方法的情感分析研究得以展开的前提。
目前学术界中对于情感的分类没有统一的标准,不同的数据集都有着不同的情感/情绪分类标签。其中非常著名的当属1982年美国心理学家Ekman[1]提出的6大基本情绪:生气、快乐、惊讶、厌恶、伤心和害怕。除了情绪表达以外,在对话中发言人所说话语的情感极性(积极、中立、消极)也是衡量情感的方式之一。
话语是人与人之间表达情感最普遍的方式。但仅仅从话语文本中难以准确识别出说话者的真实情感。将文本、语音、图像3种模态蕴含的信息加以融合,能对其做出更准确的识别。Zadeh等[2]构建了CMU-MOSI语料库,收集了YouTube上关于电影评论的视频,标注了从-3到+3的7类情感倾向,但其数据集规模较小。2018年Zadeh等[3]又构建了CMU-MOSEI语料库,从YouTube收集了长达约66 h的独白视频,标注了情感标签和情绪标签。Soujanya等[4]构建了MELD语料库,数据来源于经典的电视剧《老友记》。Yu等[5]构建了CH-SIMS语料库,包含2 281个经过精炼的中文视频片段。徐琳宏等[6]构建了一个俄语多模态情感语料库,将情感分为喜、怒、悲、恐和愧5大类别和15个小类,共标注了181个场景。可以看出,目前公开的面向中文的多模态情感分析语料库资源不足。同时由于地域文化的差别,不同国家、不同母语的说话者的情感表达方式不尽相同,所以,将英文的多模态情感分析语料库翻译成中文,用于汉语母语说话者的情感分析也是不恰当的。因此,本文将构建一个面向中文剧集的多模态语料库,制定情感/情绪标注方案,并开展多模态情感识别研究。
情感分析模型大致分为两类,一类是基于传统的情感词典(lexicon-based)的方法,另一类是基于现代深度学习(deeplearning-based)的方法,前者主要依赖于情感词典构造的完善程度,后者更多依赖于标注语料。Matsumoto等[7]使用传统情感词典的方法,将情感词进行加权以达到优化模型性能的目的。Herzig等[8]使用支持向量机(support vector machines,SVM)模型,结合对话的单轮和整体的特征,对对话信息进行情感分类。Poira等[9]提出了BC-LSTM模型,这是首个基于长短时记忆网络的一种对话情感识别方法,它的关键在于对对话之间的时序关系进行建模,充分学习到对话上下文情感特征,不足之处是没有用到对话中的发言人特征。CMN[10]很好地解决了这一不足,它提出了一种对话记忆网络,将发言人信息与对话信息同时建模,显著提升了对话情感识别的性能。DialogueRNN[11]增强了对话和发言人的建模方式,采用了3个门控循环单元分别对发言人、上下文和情感进行建模,并利用注意力机制更新不同范围的上下文状态,增强了对话中的情感表达。
以上都是基于序列建模的情感识别方法。由于对话具有天然的图结构,DialogueGCN[12]基于图的神经网络构建了新的建模方式,用对话中的句子作为节点,以发言人和对话时序关系构建边,取得了当时的最好结果。DAG-ERC[13]是一个有向无环图神经网络,与先前的图结构相比,构建边时仅考虑了过去的信息,而不是简单地将每个话语与固定数量的周围话语连接起来,有效地提升了模型的性能。
3 中文语料库的构建
本文基于中文情景喜剧《天真派武林外传》构建了一个中文语料库。首先进行前期准备,制定待标注数据标准并对语料库进行合理切分,接着制定标注模板,并按照客观性、一致性和常识性的标注规范,多位标注人员遵循所制定好的标注流程进行标注,完成语料库的构建。
3.1 前期准备
3.1.1 待标注数据标准
本文所用的原始数据来源于情景喜剧《天真派武林外传》,为了便于标注人员进行标注,需要对原始数据进行转换,使其转换为易于提取相关信息的待标注数据。本文依照的待标注数据标准为:1)一致性原则,即在同一条待标注数据里只允许有一个说话者发言且中途情感不会发生任何变化;2)待标注数据若出现同一说话者发言过短或过长的情况,对其进行适当的合并或分割;3)音画同源,即画面上出现的人物必须包含说话者,否则过滤掉该数据。待标注数据一定要指向清晰、目标明确,这样才便于标注人员进行标注,同时也有利于后续的人物性格特点分析。
3.1.2 数据预处理
从网络上下载《天真派武林外传》剧后,根据前文所述的数据处理标准,利用剪辑软件对原始数据进行逐句剪辑。最后将剪辑完成的片段按照剧集次序分模块导出,并标记为待标注数据交给标注人员。
3.2 标注规范
本文所设计的标注模板包括场景信息、发言人信息、话语文本、话语对应的语音和视频片段、情感和情绪标签。
一个剧集包含多个场景,将一个场景视作一个对话单元,其中包含多条话语。
发言人即台词文本对应的剧本角色,主要为佟湘玉、白展堂、郭芙蓉、吕秀才、李大嘴、邢捕头、莫小贝这7位主角。其他配角所占比例较小。
话语文本表示待标注数据里当前发言人所叙述的内容对应的文本。情感和情绪信息是标注的重点,其中情感信息是发言人的内在情感表达,分为积极、消极和中性3类;情绪信息是发言人呈现出来的外在情绪表达,参照Ekman提出的6大基本情绪类型加上中立情绪共7类进行标注。
标注过程中每个标注人员可同时看到一条已经切分好的数据的文字、声音和视频信息,同时标注该条数据的情感标签和情绪标签。
3.3 标注流程及质量监控
经过预处理的数据,按照标注模板进行组织之后,按照集编号进行分组。标注同一组数据的两名标注人员在标注期间不能互相讨论,必须独立完成标注。标注后,将结果交给第三人进行一致性统计计算和校验。如果二人标注不一样,交由第三人进行裁决。标注流程如图1所示。
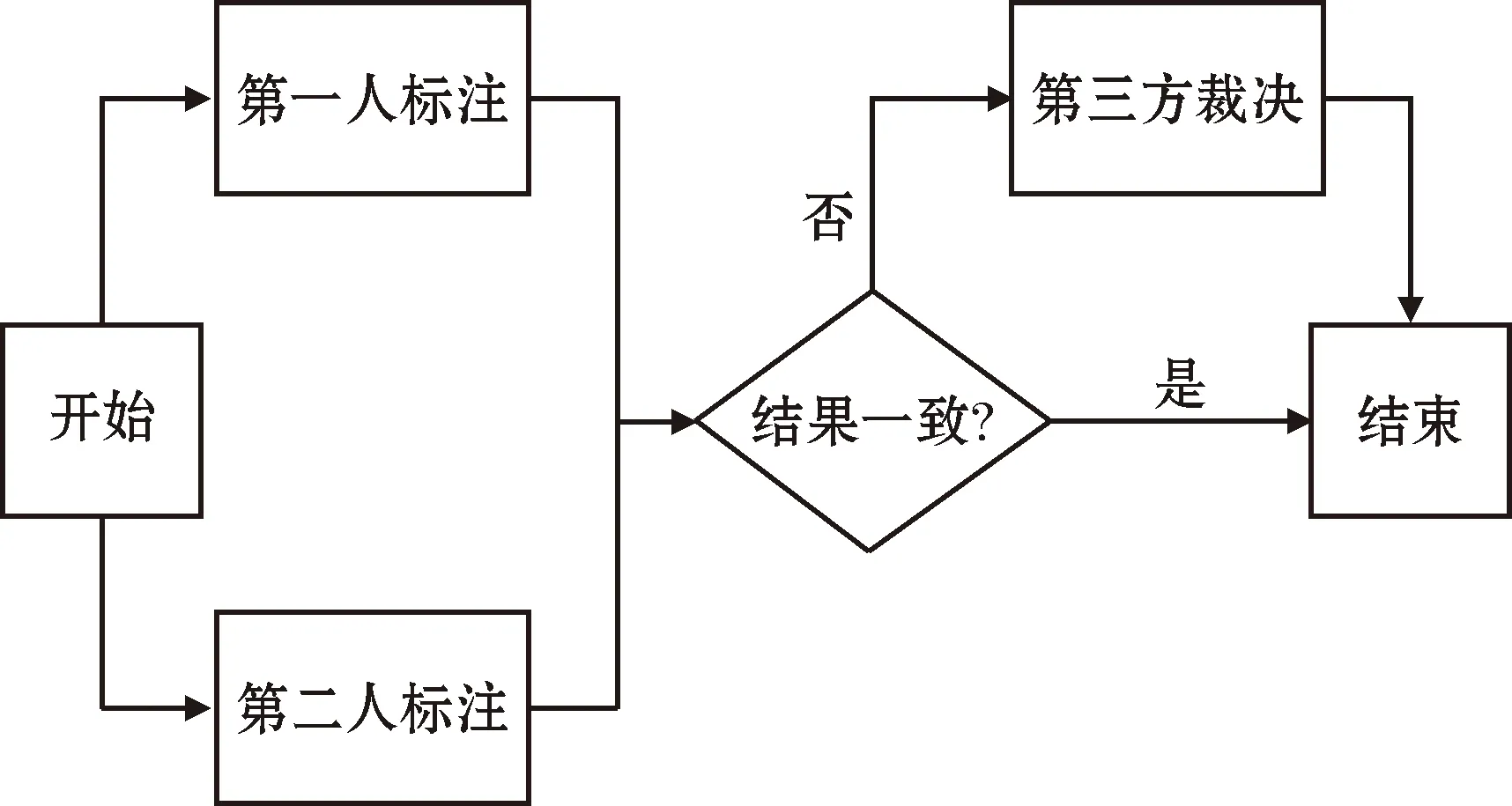
图1 多人协作标注流程
为了能够更方便地进行管理,数据被分为待标注、待审查、冲突、已审查4个类别。通过对不同组的状态进行监控,可以清晰地了解每组的标注进程,以便对语料库标注的总体完成情况进行调度。数据在各个状态之间的转换如图2所示。
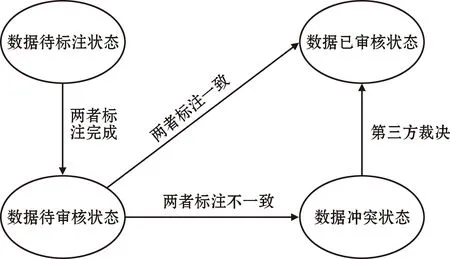
图2 数据标注状态迁移情况
由于情感和情绪标注属于主观性较强的标注任务,本文沿用此类语料库的评价方法,采用Kappa系数[14]计算背对背标注的一致性。本文统计了两名标注人员对情感和情绪标注的一致性情况。二人情感标注的一致性为0.504,情绪标注的一致性为0.484。该指标略优于现有的英文多模态语料库标注的一致性。
3.4 语料库数据统计
语料库中的部分数据如表1所示。
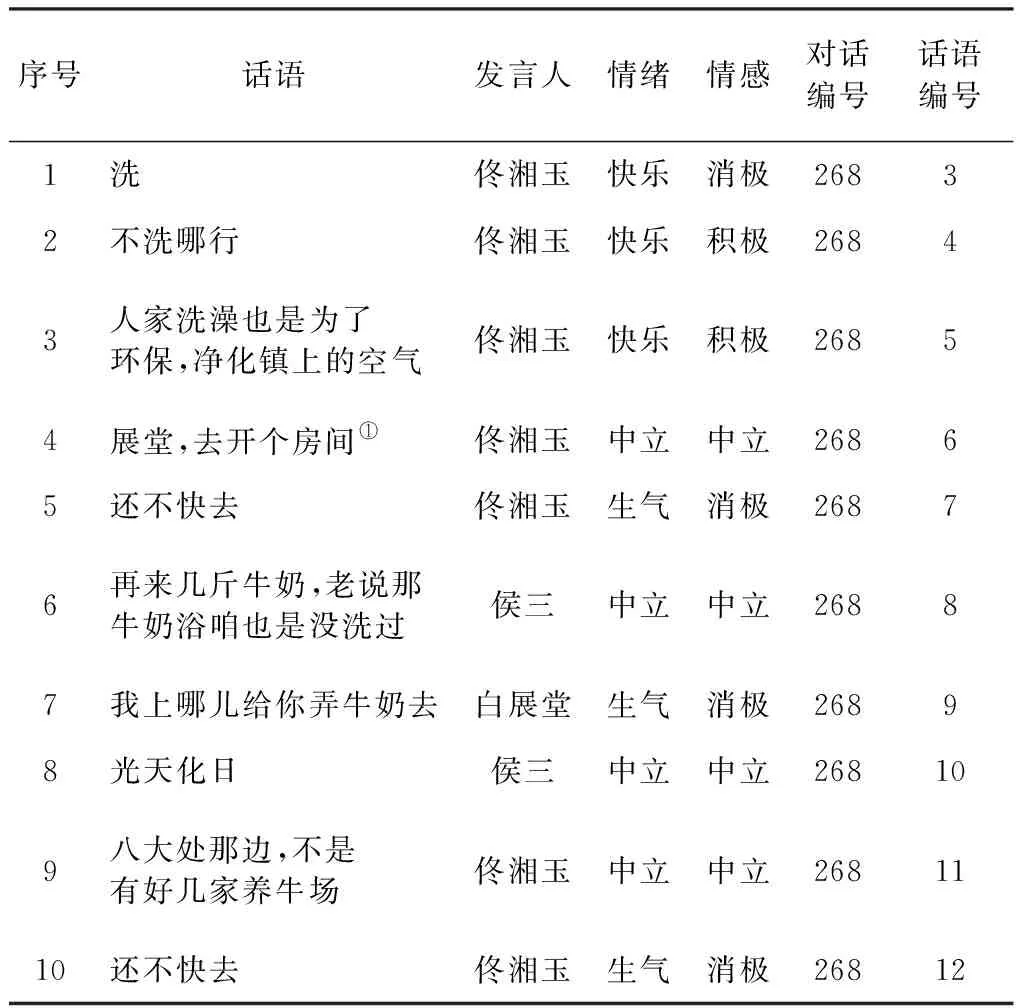
表1 语料库中的典型数据示例
这是客栈掌柜被威胁时发生的对话,掌柜既不得不满足侯三无理的要求,同时又只能强装出高兴的表情,但实际上内心气愤不已,是一种消极的情感。这部分内容侧面印证了讲话者表现出来的情绪和其内心的真实情感有时会出现巨大差异,甚至可能完全相反。这在一定程度体现了本文所提出语料库的特点。
语料库及其中对话的相关信息统计如表2、表3所示。由表可知,语料库总体规模达到5 541条语句,330个场景,25个角色。其中平均每轮对话包含16~17个句子和3~4个发言人,平均每句话长度为10~11个字,比较符合日常对话特点。

表2 语料库信息统计

表3 对话信息统计
每种情感类型和每种情绪类型所占的比例如图3、图4所示。从图3可以看出,中性和消极是占比最大的两种情感,分别占比39.57%和38.84%。从图4可以看出,中性和开心是出现频率最高的两种情绪,分别占到了整体的34.50%和19.19%。
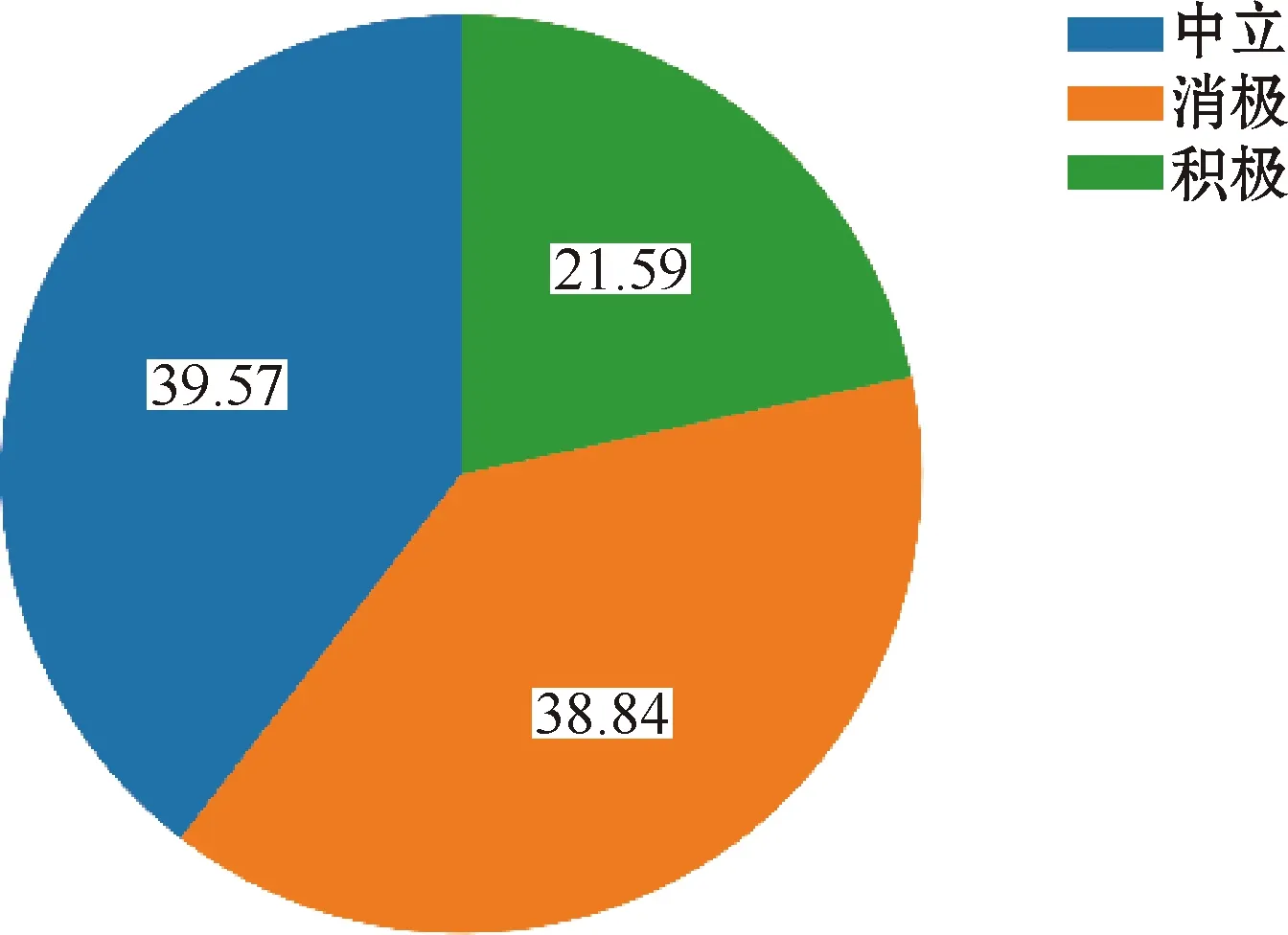
图3 情感占比分布
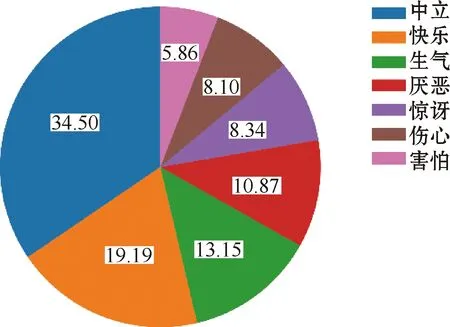
图4 情绪占比分布
7位主要发言人的情感和情绪分布情况如图5、图6所示,可以看出不同发言人的情感和情绪占比情况不同,这说明在对话中,不同发言人的性格特征也是影响话语情感或情绪的关键因素。同时也可以看出,不同角色的发言数量差异较大。经统计,佟湘玉、郭芙蓉和白展堂的发言频率最高,分别占到了22.78%、18.03%和16.96%,这与情景喜剧中的角色地位相符合,主角发言较为频繁。
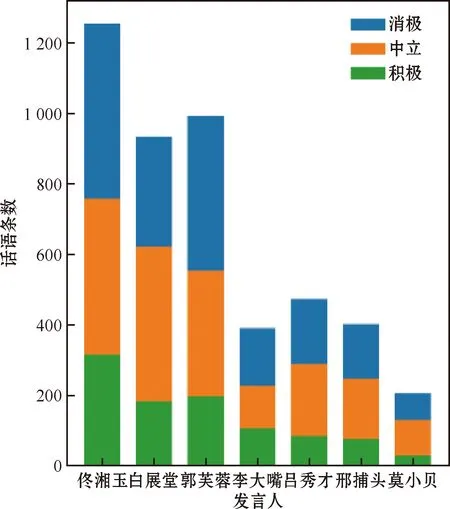
图5 发言人情感分布
图6 发言人情绪分布
4 情感分析模型
在权衡比较了现有多模态情感分析工作之后,选择先进的特征抽取方法和多模态对话情感分析模型,设计了一个情感分析模型,整体架构如图7所示,分两个阶段:第一阶段搭建单模态情感特征抽取模块,用于抽取话语级的情感特征;第二阶段搭建多模态情感分析模型,用于抽取多模态的话语表示和对话表示,最后经过对话情感分类器获得话语情感标签。
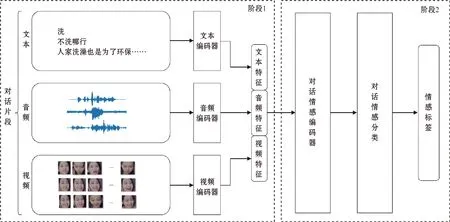
图7 情感分析模型整体架构
4.1 话语级特征抽取
4.1.1 文本特征抽取
采用预训练语言模型基于transformer的双向编码器表示(bidirectional encoder representations from transformers,BERT)进行文本特征提取。话语级数据经过BERT进行深度编码后,取[CLS]位置的向量视为话语级别的特征表示,最后使用全连接的方式对文本特征进行降维,获得300维的文本情感特征向量。
4.1.2 音频特征抽取
采用Opensmile自动化工具进行语音特征提取。首先抽取出384维的话语级语音情感特征,其中包括韵律特征、频谱特征等,随后使用标准归一化(Z-Score)方法对音频特征进行归一化。并使用全连接的方式对音频特征进行降维,获得300维的语音情感特征向量。
4.1.3 视频特征抽取
采用人脸识别卷积神经网络FaceCNN结合双向长短时记忆(bi-directional long short-term memory,BiLSTM)模型对视频情感特征进行提取。首先对话语级视频进行等帧切分,然后抽取每一帧图片中的人脸部分。利用FaceCNN结合多层卷积和池化的模块抽取单个人脸图片中蕴含的情感特征之后,利用BiLSTM对每段视频中的多张人脸图片进行时序编码,获取视频中蕴含的情感特征,最后使用全连接的方式进行降维,获得300维的视频情感特征向量。
4.2 对话情感编码器
经过话语级特征抽取编码器抽取后,得到单个话语的不同模态的情感特征。将不同模态的特征向量进行拼接得到当前话语的多模态特征向量,然后输入对话情感编码器。
对话情感编码器采用DialogueRNN。在当前处理多方对话情感识别模型中,DialogueRNN模型是性能出众的模型之一。该模型综合考虑了发言人、对话上下文和情感3方面因素。采用3个门控循环单元(gate recurrent unit,GRU)分别对这3个因素进行建模,并通过注意力机制来建模话语上下文的权重分布,最终获得了较好的融合了上下文特征的话语情感特征表示。
4.3 对话情感分类器
对话情感分类器层采用全连接层+Softmax的方式构建,将对话情感编码器的输出结果直接作为输入,最终得到当前话语的情感分布进而预测出当前话语的情感标签。
5 实验结果分析
采用上述模型,利用本文所构建语料库开展实验,结果使用F1值进行评估。不同模态数据作为模型输入的情况下,单一情感类别的识别结果和所有情感类别的综合识别结果F1值如表4所示。
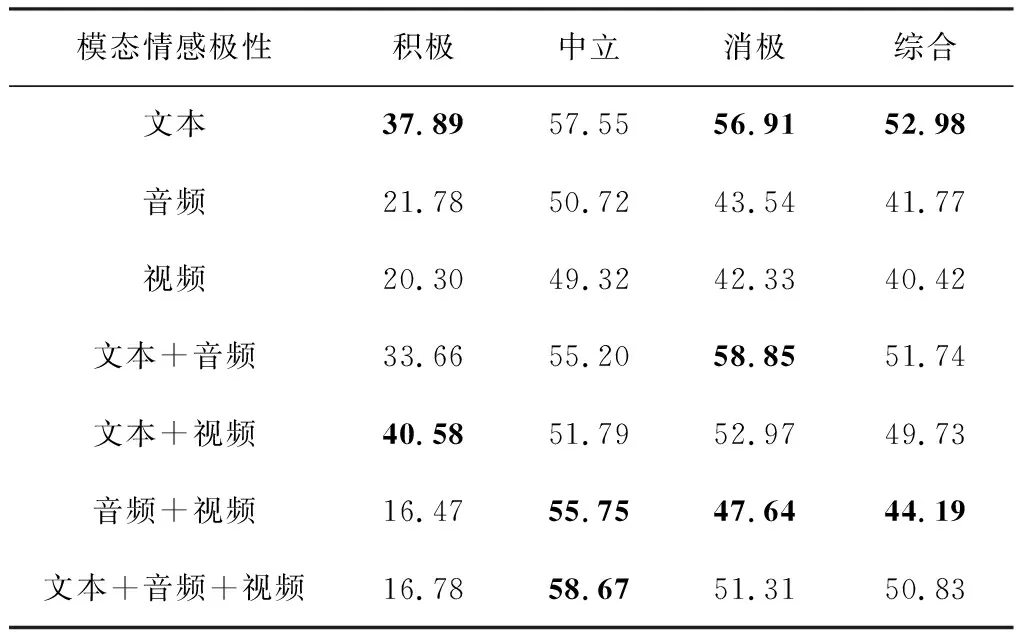
表4 实验结果 %
从综合识别结果上看:1)依据文本、音频、视频单一模态数据进行情感识别的F1值,文本模态>音频模态>视频模态;2)在双模态组合实验中,“文本+音频”模态>“文本+视频”模态>“音频+视频”模态;3)“文本+音频+视频”的综合识别结果F1值为50.83%,说明就本文所构建模型而言,文本模态对情感识别结果起到了关键作用,音频和视频的特征没有起到辅助作用。
从双模态融合的实验结果上看,当音频和文本融合时,对消极情感的识别起到了积极作用;视频和文本融合时,对积极情感的识别起到了正向作用;视频和音频融合时,对中立和消极情感起到了正向作用。而当文本、音频和视频三模态融合时,对中立情感识别起到了正向作用。本文所设计模型主体是DialogueRNN模型,其在英文数据集上的F1值达到62.75%,比本文结果高了接近10个百分点。这反映出下一步面向中文多模态多方对话情感分析语料库进行情感分析研究的必要性。具体而言,语音和视频两个模态在和文本模态配合进行情感分析时,仅在特定情感类别中提高了识别性能,这说明模型中的音频和视频情感特征抽取方法还不能满足中文多模态情感分析的需求。进一步,3个模态的信息如何进行交互和有效地互相支撑,也是后续构建模型中需要重点研究的内容。
6 结束语
本文构建了基于电视剧《天真派武林外传》的中文语料库,其中包含330段对话与5 541条语句。每条语句都标注了发言人、发言人的内在情感、外在情绪。该语料库可用于面向中文多方对话的多模态情感/情绪识别任务,以及中文对话发言人特征对情感分析影响的相关研究,推动共情对话技术的发展。同时,构建了一个情感分析模型,利用所构建的语料库进行了实验,实验结果表明:单模态情感分析的效果中,文本模态好于声音模态和视频模态;多模态情感分析的综合效果比单模态文本分析的效果差,但好于声音和视频分析的效果。
猜你喜欢
河北画报(2021年2期)2021-05-25 02:07:18
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
家庭影院技术(2018年11期)2019-01-21 02:20:52
电子制作(2018年19期)2018-11-14 02:37:08
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
电子制作(2017年9期)2017-04-17 03:00:46
人间(2015年8期)2016-01-09 13:12:42
语言与翻译(2015年4期)2015-07-18 11:07:45
浙江人大(2014年6期)2014-03-20 16:20:34
浙江人大(2014年5期)2014-03-20 16:20:20
