
《Spark大数据处理技术》课程教改探究
2022-09-21 07:55李天格许鹏
电脑知识与技术 2022年24期
李天格,许鹏
(郑州财经学院,河南郑州 450000)
习近平总书记在中共中央政治局第二次集体学习时强调“审时度势精心谋划超前布局力争主动,实施国家大数据战略加快建设数字中国。”[1]毫无疑问,大数据时代已经到来,新一轮的科学技术变革正在快速推进,而大数据技术就是这一变革的核心推动力之一。实施国家大数据战略离不开大数据人才。而高校承担了培养大数据人才的主要责任。
截止目前,各大高校相继开设了数据科学与大数据技术专业。大数据课程遍地开花,Spark大数据处理技术作为一门实践性、应用性较强的课程,被广泛选为高年级学生的专业提升课。
数据科学与大数据技术专业最早于2016 年在国内开设,专业历史较短,相应地,关于该专业课程的教学研究也相应较少,课程无相对成熟体系。本文针对数据科学与大数据专业的重点课程Spark 大数据处理技术进行了教学探究,以期提升该课程的教学效果。
1 概述
1.1 大数据技术
大数据技术指大数据的应用技术。大数据是指利用常用软件工具捕获、管理和处理数据所耗时间超过可容忍时间的数据集。大数据具有数据体量大(Volume)、数据类型繁多(Variety)、处理速度快(Velocity)、价值密度低(Value)等特征(简称4V特征)。
大数据的基本处理流程,主要包括数据采集、数据存储、数据处理、结果可视化等环境。因此,从数据分析的过程来看,大数据技术主要包括:数据采集、数据清洗与预处理、数据存储和管理、数据处理分析、数据挖掘、结果可视化、数据隐私安全等几个层面的内容。
此外,大数据技术及其代表性软件类型繁多,不同的技术有不同的适用场景。目前,大数据的代表产品有Spark、MapReduce、Storm、Flume、S4、Streams、Pregel、Hive、HBase、Flink、Beam等。这些技术主要对应着4 种大数据计算模式:批处理计算、流计算、图计算和查询分析计算。其中,Spark技术由于其快速的发展成为了高校讲解大数据处理技术的首选案例。
1.2 Spark大数据处理技术
Spark 诞生于2009 年美国加州大学伯克利分校的AMP 实验室,是一个可应用于大规模数据处理的快速、通用引擎,隶属于Apache 组织,是目前Apache 最活跃的项目之一,被标榜为“快如闪电的集群计算”。
Spark提供了一个一站式大数据解决方案。既可以提供基于内存的计算框架,又可以满足即时查询(Spark SQL)、流计算(Spark Streaming)、机器学习(Mllib)、图计算(GraphX)等场景。因此,Spark所形成的生态系统可以同时支持批处理计算、流计算、图计算、交互式查询分析计算等计算模式。
虽然Hadoop 已成为大数据技术的事实标准,但其本身存在诸多缺陷,Spark 在借鉴Hadoop 的计算模型MapReduce 优点的同时,很好地解决了MapReduce 的一系列问题。2014 年Spark 打破了Hadoop 保持的基准排序记录,使用206 个节点在23 分钟内完成了Hadoop 需要2000 个节点于72 分钟内才能完成的100TB的数据排序任务。Spark俨然成为大数据计算平台的后起之秀。该记录的诞生,使得Spark 收获了更多欢迎和声望。因此,各大高校相继开设了以Spark 技术为基准的大数据处理课程。
Spark 大数据处理技术作为一门新开设的专业核心课程,对动手能力、实践能力、应用能力要求较高。传统的教学模式已经不再适用于该课程的教学。
2 授课现状
2.1 学生先修课程掌握不扎实
Spark大数据处理技术作为数据科学与大数据专业的进阶课程,需要一定的理论基础和实践基础。学生应掌握大量相关的大数据基础知识以及各种大数据软件的安装和使用方法,包括Hadoop、HDFS、MapReduce、HBase、Hive 等。除了这些入门级的大数据基础知识之外,学生还需要具备Linux 系统及应用课程的相关知识,熟悉Linux系统的常用操作和命令,深入了解一门编程语言,如Python、Java 等,掌握有关面向对象编程的一些基础特性。
其中,有些先修课程是学生在低年级所学,重点知识有所遗忘。如果直接开始Spark 大数据处理技术的学习,学生会出现适应性差,接受能力弱的现象。
2.2 学生水平参差不齐
经过三年的大学学习,学生的水平已经慢慢拉开差距。有些积极上进的学生甚至已经超前学习,所具备的大数据处理功底已经远高于班级的大部分学生。而有些学生由于没有初高中的升学压力,加上懒散的学习态度,学习积极性和学习兴趣都有所下降。从而导致了学生之间的学习能力、学习水平、大数据综合素养差别较大,如何保证课程难度能适应班级大多数同学的情况,保证课程内容能够吸引学生的注意力和兴趣点,成为这门课程教学的首要难题。
2.3 实验环境搭建较为麻烦
Spark大数据处理技术这门课程需要在机房进行实验课教学。课程所需软件环境众多,包括但不限于Hadoop、Java、Hive、MySql、Spark等,环境部署较为麻烦,尤其是搭建Spark环境的集群模式时,需要同时开启三台虚拟机。实验室机房电脑配置较低,网络传输较慢,影响了实验课的顺利进行。另外,机房的电脑一般都设置了重启后自动恢复模式,在电脑关机后,之前对电脑的所有更改都不会保存,导致下次上课时,学生又要从头开始。这不利于学生复习学习上次保存的案例代码。这两方面的原因导致学生无法适应现代企业的开发和生产环境,综合应用能力较差。
2.4 教材落后最新技术
教材的编写一般都需要一个过程周期,从教材的撰写到初稿、定稿、出版、上市需要一定的时间。而技术更新换代非常快速,计算机大数据技术行业尤其如此。以Spark为例,截止目前Spark 的最新版本是3.2.0。而市面上的大多数教材都是基于Spark2.*的版本撰写的。教材目录章节设置有些甚至不符合Spark 的最新架构设计。以厦门大学林子雨老师的Spark 大数据处理技术Scala版教材为例,该教材第7章Spark Streaming 讲解的是以Spark Streaming 组件为基础的流计算,而在Spark 的最新技术中,Spark启动了一个基于Spark SQL 的全新流计算引擎Structured Streaming,目前Structured Streaming已经被广泛使用,而这个技术在该教材中并没有体现[2]。
2.5 教师项目经验较弱
Spark大数据处理技术课程需要教师有较深厚的理论基础和丰富的实战经验。而高校的老师虽然教学经验丰富,但是企业实习经历稍有欠缺,实践技能较弱。容易出现照本宣科,脱离生产实际的现象。甚至,有些实验内容单一,目标不明确,操作不具备代表性,从而使得学生的学习效果在一定程度上打了折扣。
此外,Spark 大数据处理技术作为数据科学与大数据专业的进阶提升课程,难度较大,层次较高。需要授课老师有综合的大数据素养,不能仅仅局限于该课程的教学,还需要有其他课程比如数据仓库与数据挖掘、大数据可视化的课程基础。这样才能达到大数据技术的融会贯通,从而更好地为学生传道解惑。
2.6 考核方式不具有针对性
目前仍采用“纸质化”考核方式,Spark 大数据处理技术这门课程实践性较强,对学生的实践编程能力要求较高。而这个要求并没有很好地体现在期末纸质试卷当中。一张纸质试卷很难包含一学期的所学内容,几道简单的名词解释题、应用题很难检测出学生的真实水平。
Spark大数据处理技术课程是对实操能力、编程能力、问题解决能力要求比较高的一门课程,因此不能仅仅重视“做题能力”,这样学生很难掌握Spark 的核心技能,从而难以应对将来工作时遇到的实际问题。
3 教改探究
3.1 结合互联网的教学新模式
随着互联网时代的来临,出现了新的教学模式,比如慕课(MOOCs)和翻转课堂[3]。教师可根据情况综合使用传统授课模式和互联网教学新模式。课前安排学生预习读教材的同时,教师可以发布一些课前导学视频、数字材料,供学生理解新概念、新知识。在课堂上,教师在讲授理论知识的同时,还可以通过案例探究、实验、演示编程等多种形式,引导学生与教师互动从而完成对知识的内化与吸收。课后,教师在布置作业的同时,还可以要求学生开展小组练习,以实际项目为驱动,进一步利用网络(包括慕课)资源,完成对知识的进一步消化和应用。
3.2 部署大数据平台
基于前文所述在机房上实验课的种种不便,可以选择在云端部署大数据平台。教师可以在大数据平台网站上创建相关课程,并在网站上传学习视频、课件、案例、实验大纲等资料。学生可随时随地自助登陆大数据平台进行学习和实验上机操作。并且,学生的作业也可以通过大数据平台进行提交,学生有任何关于课程的建议,都可以在大数据平台留言、互动、讨论。
3.3 提升教师综合水平
Spark 大数据处理技术课程对教师的理论功底、实践能力以及大数据综合水平要求较高。为了提升教师的综合水平,首先,教师可通过阅读Spark官方文档的方式了解Spark的最新技术,架构设计。其次,教师可以积极参与大数据行业的资格认证,在考取证书的同时,提升实验动手能力。此外,教师可以参与各大名校的大数据课程教师培训交流班,与来自全国范围内的各大高校大数据老师交流学习,共同探讨Spark 大数据处理课程的教学模式。
除了以上几点之外,教师方面还应树立终身学习的意识。在知识日新月异的大趋势下,大数据技术更新迭代速度尤甚。教师除了具备教学的使命感之外,还应具备一定的危机感,持续更新、完善自己的大数据架构,包括但不限于本门课程,不仅要及时了解、掌握大数据专业理论发展的前沿动态,而且要关注该专业与其他专业的融合以及与本专业密切相关的实践领域发展的最新动态,以形成更坚实、深厚、前沿的知识积淀,更好地为学生传道、授业、解惑[4]。
3.4 改变考核方式
课程最终成绩可分为平时成绩、期末成绩两部分。其中,期末成绩可以以小型上机项目的形式考察学生的问题解决能力、动手能力和编程能力。平时成绩可从多个维度考察学生的综合能力,包括但不限于考勤、作业、课堂表现、实训报告、小测验等[5]。表1是成绩构成的一个示例,供相关读者参考:
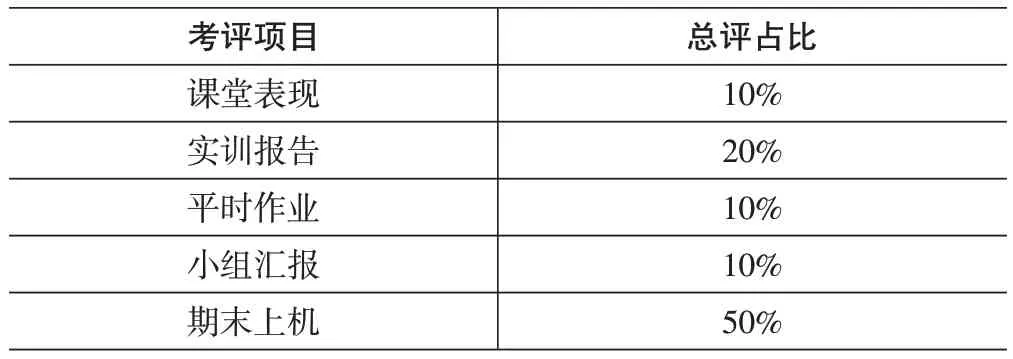
表1 成绩构成
3.5 因材施教,个性化教学
学生的大数据技术功底、计算机功底、学习能力参差不齐,应定制个性化的教学方法,因材施教。在开课之前可以举行摸底测试,了解班级学生的基础。根据学生的水平有针对性设计教学大纲和教学内容,不能太难,也不能太简单,以期课程难度可以适应班级大多数学生的情况。对于底子较差,学习比较吃力的部分同学,可以课下对其进行个性化的辅导和答疑,鼓励这些学生主动学习、积极思考、充分利用学校教师、网络视频、参考书籍等资源,提升学习能力和学习水平。
3.6 结合教材实际情况,补充新技术
在选定好合适教材后,应结合教材的具体内容和Spark 生态系统的最新技术,在清楚讲授教材内容的同时,应对教材上没有的新技术、新组件、新特性进行额外地补充和讲解。以期让学生在学习教材经典内容的同时,还能掌握Spark 的最新技术、最新特性。在新技术讲授之前,老师应对新技术做充分学习和调研,对新技术的应用、实践案例做充分准备。以期做好新技术补充章节的教学大纲、教案、教学进度表等内容。值得说明的是,在新技术的讲授过程中,教师应同样重视学生的动手能力、应用能力和编程能力的培养。
3.7 改变教学观
传统的课堂教学,是以教师为中心,重理论,轻实操。Spark大数据处理技术课程是一门实践性、应用性很强的课程,教师应转变自己的教学观念,不再充当一个优秀的“演讲者”,而是发挥学生的主体作用、中心作用,教师的引领作用、指导作用,让学生不再是简单的“听众”,提升学生的学习兴趣和学习积极性,让学生充分利用线上线下各种学习资源,提升学生的学习效果[6]。
3.8 增加课程设计
课程设计是大学的综合性实践教学环节,一般较具综合性、应用性、实践性。Spark 大数据处理技术作为一门实践性、应用性很强的课程。可在期末的时候开设为期一周的课程设计。课程设计应遵循以下原则:以解决实际问题为导向;以提升学生综合上机能力为宗旨。课程设计的选题可以包括但不限于下述举例:天气分析,零售交易数据分析,淘宝用户行为分析,租房信息分析,地震数据分析,旅游景区数据分析,信用卡逾期数据分析等。
3.9 引入课程思政
党的十八大以来,以习近平同志为核心的党中央特别重视高校开展思想政治教育工作[7]。2020年,教育部印发的《高等学校课程思政建设指导纲要》指出:全面推进高校课程思政建设是落实立德树人根本任务的战略举措。在高校价值塑造、知识传授、能力培养“三位一体”的人才培养目标中,价值塑造是第一要务。全面推进课程思政建设,就是要寓价值观引导于知识传授和能力培养之中,帮助学生塑造正确的世界观、人生观、价值观。
高校教师在传授学生知识、培养学生能力的同时,还要承担起价值塑造的责任。在培养学生大数据技术的同时,还要帮助学生树立正确的三观,引领学生努力学习科学文化知识,做一个爱国爱党、为社会做奉献的有志好青年。
4 总结
Spark 大数据处理技术作为一门应用性、实践性较强的课程,目前的教学现状有很多不足。本文通过对该课程进行探究,从多个角度分析了教学改革的重点,以期对该课程的教学有所启发。
猜你喜欢
发明与创新(2022年30期)2022-10-03
心理学报(2022年4期)2022-04-12
新世纪智能(英语备考)(2021年10期)2022-01-18
新世纪智能(英语备考)(2021年9期)2021-12-06
水泵技术(2021年3期)2021-08-14
新世纪智能(英语备考)(2021年11期)2021-03-08
新世纪智能(英语备考)(2020年11期)2021-01-04
人大建设(2018年6期)2018-08-16
文理导航·科普童话(2017年5期)2018-02-10
中国惯性技术学报(2015年1期)2015-12-19
