
基于自动机器学习的游戏产业简要分析
2022-09-21 07:55周泽先
电脑知识与技术 2022年24期
周泽先
(吉林大学,吉林长春 130000)
所谓自动化机器学习(AutoML,Automatic machine learning),指的是通过处理已有数据、经过自动调参,针对目标更方便地选择最优算法,从而省去复杂的工作,极大地促进了机器学习在各个领域的应用。本文旨在通过对电子游戏进行分类和回归算法,在挖掘电子游戏的用户评价、媒体评价和市场销售三者之间联系的同时,展现不同平台(EasyDL、Google Cloud、Azure)自动化机器学习的情况。
游戏产业作为当今价值百万的巨大产业,渐渐成为一股不容小觑的力量。它已经深入人们的生活。根据市场研究机构Newzoo 的报告[1],2021 年游戏产业展现出了惊人的体量,甚至超过了1800亿美元,即便在疫情的阴影下,依旧呈现出强劲的发展势头。同其他产业一样,观众的偏好是一个影响产品成功的重要因素,而销量,则是其影响力的重要标志。因此笔者对于游戏产业的分析也围绕产业和销量展开。
本文中,笔者准备了三个数据集分别在EasyDL、Google Cloud、Azure三个平台上进行模型训练。其中分类训练使用了两个数据集。而用于回归算法的数据集则加入了市场销售的要素。
1 不同自动机器学习平台的比较
目前,EasyDL、Google Cloud、Azure 是相对重要的三个自动机器学习平台。EasyDL 从2019 到2020 年在中国机器学习平台占据主要份额。而Google Cloud作为国内机器学习市场份额较大且具有自动调参功能的平台,在国外市场中具有不可或缺的位置。Azure 跟Google Cloud 一样是基于云处理的机器学习平台,但与前者运用了完全不同的技术。
EasyDL 采用了迁移学习技术[2],也就是说不重新搭建模型,而是去寻找已有训练中相似的情况。这样就大大节约了时间。Azure还用自动混合精度训练来降低硬件要求。
Azure 平台上主要应用概率矩阵分解(PMF,Probabilistic Matrix Factorization)和贝叶斯优化技术[3]。实际上是将特征和目标通过矩阵匹配,并用线性组合来描述两者间的关系。在实验中发现Azure 对于某些数据集进行回归,R2 Score 会出现负数,而其他平台则不会,这或许跟Azure 这种默认线性关系的特点有关。至于贝叶斯优化方法,它在建立概率模型时,参考之前的结果,选出最有可能的超参数,从而大大节省了时间。
Google Cloud AutoML 通过神经网络搜索模型(NAS,Neural Architecture Search)来探索数据集的特点[4],结合策略梯度加以引导,辅以分布式训练等方法缩短训练模型的时间。也就是说,Google Cloud AutoML 不从特征列入手,而从循环神经网络得出的子网络开始,这点与Azure 平台不同。循环神经网络的特点在于当前结果与之前的结果相关。
2 实验准备与数据处理
笔者的实验分别应用分类算法和回归算法,并根据其算法特点筛选数据。
分类,即根据所给数据,提炼对象的特点,从而使机器能够判断新的数据的类别。这里以用户评分为目标,通过游戏的其他特点来得出一个游戏是否能令用户满意。
回归,指的是通过提炼各个变量之间的联系并建立模型,从而达到通过所给条件,预测某一特定情形的目的。与分类不同的是,分类得出的结果是一种判断,即一个对象是什么。而回归的结果则以真实情况为标准,力求减少模型结果与真实情况的误差。回归模型的建立可以帮助预测游戏用户的满意程度。在这一过程中,还可以分析游戏评分与各地区销量、发售平台和游戏类型的关系。
2.1 分类算法的数据准备
2.1.1 数据来源
对于分类算法,本文准备了两组数据。分别是评论网站Metacritic上2011年和2019年第八世代游戏机上的电子游戏信息,和2000 年到2021 年所有平台上电子游戏的信息,记为“数据集1”和“数据集2”。具体包括游戏的基本信息和游戏的整体媒体评分和用户评分,以及各自正面、负面、中性的打分人数。
两组数据相比,因为后者时间上范围更广,涉及平台更多,因此数据量更大。另一方面,因为用户的评论是动态的,所以两组数据内容上也有所不同。本文设置两种数据,分别考察数据集不同时的模型情况。
2.1.2 数据预处理和定义特征
首先,为了保证模型准确性,不受其他因素干扰,将原始数据集中的无关信息剔除,最终留下15 个特征。如表1 所示,这些大致可以分为游戏基本信息、媒体评分情况和用户评分情况三种,分别是:游戏名、发售平台、开发商、发售日期、游戏类型、游戏分级、玩家数量;媒体评分和好、中、差三种评论数;用户评分和好、中、差三种评论数。

表1 用于分类的处理后数据集特征列
其次,因为Metacritic 网站上的整体游戏评分从0 到10 不等。为了能使数据符合分类算法离散性的要求,这里将用户评分这一目标列按其众数,并结合一般评分习惯划分为推荐、不推荐、中性三类。笔者注意到,尽管10分制的打分习惯上以5分或6分为分界线,但实际上5分以下的评论,在第一个数据集中只占总评论数的9%,而在第二个数据集占17%。而两个数据集7.5分均为整体评分的众数,分别为2858个和1833个。这就说明得到7.5分以上的评分是相对少有的、优秀的作品。因此,这里将7.5分及以上设为“推荐”游戏。由图1所示,两组数据的评分集中在6~8分,据此笔者将6分及以下设为“不推荐”。
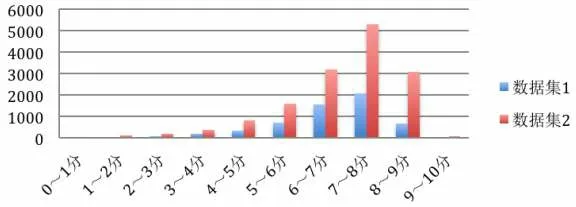
图1 数据集1和数据集2的用户评分比较情况
再次,需要注意的是,原始数据集中存在部分数据缺失,比如某些小众游戏评论过少因此没有用户评分或者媒体评分。由于各大AutoML 平台均具有数据清洗的功能,且缺失数据占比较小,这里不再进行处理。
2.2 回归算法的数据准备
2.2.1 数据来源和预处理
对于回归算法,我们试图通过电子游戏的媒体评分,结合销量情况,来预测用户评分。电子游戏的销量情况来自网站VGChartz,评分情况来自网站Metacritic。具体来说,销量分为北美地区、欧洲、日本和其他地区三种情况。而Metacritic 上的数据内容,分类的数据来源部分已经介绍,这里不再赘述。笔者以用户评分为目标列,具体特征列见表2。
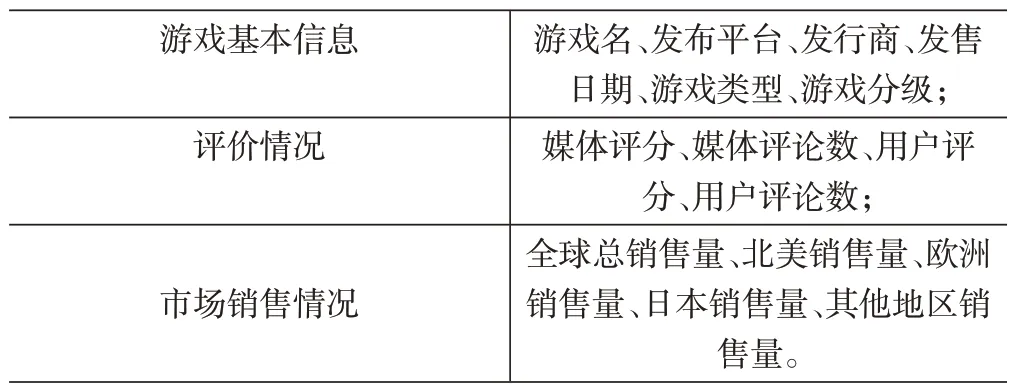
表2 用于回归算法的数据集3的特征列
时间跨度上,原本笔者打算对2017、2019、2020年的销量情况进行考察。但在实验中,笔者发现2019和2020年的实验结果显示的关联性特别弱,EasyDL 平台的r2 score 分别为0.272 和0.135,而Azure平台R2 Score小于零(如表3所示),但2017年的数据情况则相对正常。也是说,对于2019和2020年的实验近乎是无意义实验。通过对2019和2020的数据集进行分析,笔者发现,两个数据集中同时具有完整评分情况和销售情况的电子游戏不超过500个,均不到整体的10%。而2020年符合要求的比2019年更少,这就可以解释为什么2020年的实验结果更差。

表3 2019和2020电子游戏评分和销量数据集实验结果
因此,笔者决定仅对1976 到2017 的电子游戏媒体评分和销量情况进行具体考察,记为“数据集3”。同时这也从侧面说明,目前的自动机器学习平台虽然可以接受无监督学习的情况,允许数据集存在部分缺失,但如果要得到较好的实验结果,仍要求大部分数据集是完整的。从电子游戏市场分析的方面看,近些年部分游戏销量和评论的缺失,可能说明一个电子游戏的销售需要数年的积累。或者可以结合独立游戏和小众风格越来越多的情况,这些游戏往往缺乏正式的商业的宣传和媒体的关注。
除此之外,笔者注意到Google Cloud 在回归算法上对数据要求更严格,需要保证目标列不能有缺失。笔者以用户评分为目标列,因此通过EasyDataTransform来去除原始数据集中用户评分缺失的列。
2.2.2 模型训练
在分类算法上,笔者分别将数据集1 和数据集2 在Easy-DL、Google Cloud、Azure三个平台上运行,并对比不同自动机器学习平台得出的结果。不同平台本质上是不同的模型训练方法。但三者都是先生成数个模型,然后选择最优的模型。其中Google Cloud 和Azure 平台会将其他模型的效果也呈现在结果中。回归算法上,将数据集3也在上述3个平台进行运行,综合评价数据结果,并对比不同平台下的训练效果。
另外,Azure 平台需要用户自己选择配置,笔者选择的是4核CPU,28GB内存的机器。
3 实验结果与模型评估
3.1 评估标准解释
3.1.1 分类算法的模型评估
分类算法上,笔者通过F1-score、精确率(Precision)、召回率(Recall)和运行时间来评估。
其中,精确率(Precision)指实际上为正占被判定为正的比例。以EasyDL 对于数据集1 的混淆矩阵为例,数值1 表示“推荐”类型的游戏,数值0表示“中性”,数值-1表示“不推荐”。就划分为“推荐”的电子游戏来说,(1,1)为实际上为正且判定也为正(公式上写为TP),(1,1)、(0,1)、(-1,1)之和表示被判定为正类(公式上写为TP+FP)。精确率用来表示对于某一样本预测的准确程度。
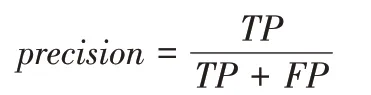
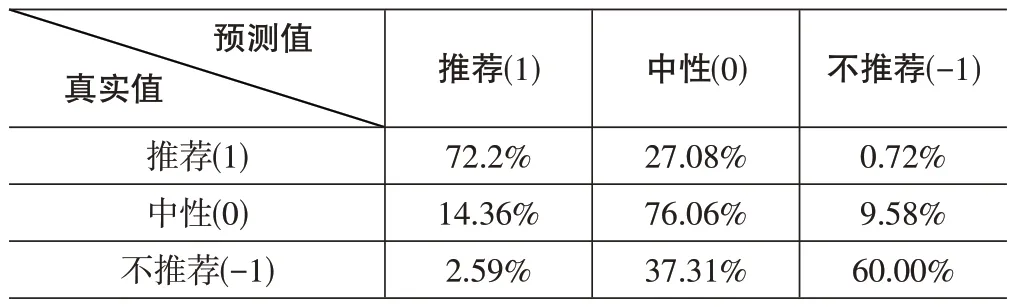
表4 EasyDL对于数据集1生成模型的混淆矩阵
召回率(Recall)指被判定为正占所有实际上是正的比例。同样以图2 为例,就划分为“推荐”的电子游戏来说,(1,1)为TP即实际上为正且判定也为正,(1,1)、(1,0)、(1,-1)之和为所有实际上为正的情况(公式上写为TP+FN)。召回率表示对某一项判定的全面程度。
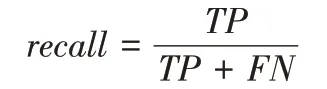
F1-score 表示精确率和召回率的调和平均数,其值越高表示模型越好。
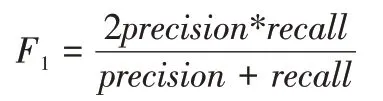
运行时间表示训练开始运行,直到得出最优模型所用的所有时间。
3.1.1 回归算法的模型评估
回归算法上,笔者通过平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方误差(MSE)和R2 Score来评估模型效果。
平均绝对误差(MAE)表示预测值减去真实值结果的绝对值,进行累加再除以项数。越接近0,表示模型效果越好。
平均绝对百分比误差(MAPE)表示预测值减去真实值的结果,除以真实值之后的绝对值,进行累加再除以项数,再乘100%。越接近0越好,超过1则意味着模型极差。
均方误差(MSE)表示预测值减真实值结果的平方,进行累加再除以项数,与上述相同,值越小越好。
R2 Score 表示自变量能通过回归关系解释因变量的程度,通常越接近1越好,当小于0时表示模型选择不当。
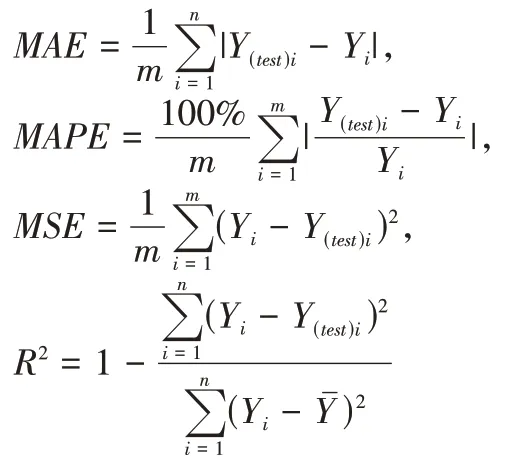
3.2 结果分析
3.2.1 用于分类的实验
由表5可以看出,以电子游戏基本信息和媒体评分以及正面负面及中性评论数为特征列,可以有效建立将电子游戏分成对于用户“推荐”“不推荐”和“中性”的模型。其中EasyDL 和Azure的F1-score均在70%以上,而Google Cloud的值均在69%左右。精准率上,三个平台的结果不相上下,而Google Cloud的召回率略低。训练时间上看,EasyDL的训练时间最短,而Azure和Google Cloud 用时依次增加,也就是说基于云处理的自动机器学习速度更慢。另一方面,这也可能与EasyDL 所用的迁移技术和自动混合精度训练对其速度的提升有关。
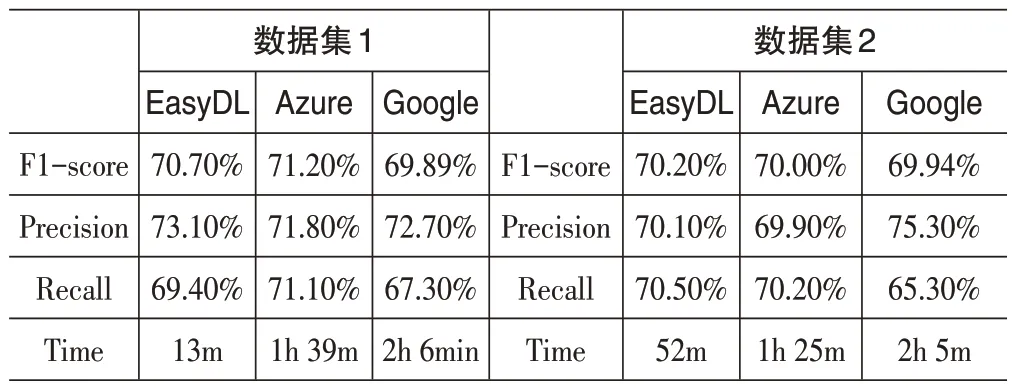
表5 分类算法模型结果
具体来看,就数据集1 而言,EasyDL 构建模型时前4 个重要特征是媒体评分、中立媒体评论数、开发商和游戏名。而Azure的前4个重要特征是正面用户评论数、负面用户评论数、媒体评分和正面媒体评论数。Google Cloud 前4个重要特征是正面用户评论数、负面用户评论数、发布平台和媒体评分。
至于数据集2,EasyDL 构建模型时前4 个重要特征是媒体评分、多人游戏类型、游戏类型和正面媒体评论数。而Azure的前4 个重要特征是媒体评分、正面媒体评论数、正面用户评论数和中立用户评论数。Google Cloud 前4个重要特征是正面用户评论数、负面用户评论数、正面媒体评论数和发布平台,而媒体评分则是其第五个重要特征。
根据以上影响各个模型的重要特征,可以看出媒体评分在两个数据集各个模型中均发挥重要作用。由此可以推测,用户评分与媒体评分有一定的关联性。从大众社会理论的角度看,这一关联可以解释为大众的观感相对容易被媒体或少数群体所控制。
3.2.2 用于回归的实验
由表6 可以看出,以电子游戏基本信息、媒体评分和全球及各区域销售情况为列,预测用户评分情况,可以建立效果一般的模型。三个平台的R2 Score均略大于0.5,表明此模型效果不差,但并不优秀。其中Google Cloud 的R2 Score 的值最大。另一方面,从表5其他几项和平均绝对百分比误差(MAPE)可以看出,模型尽管关联性较低,但误差较小。
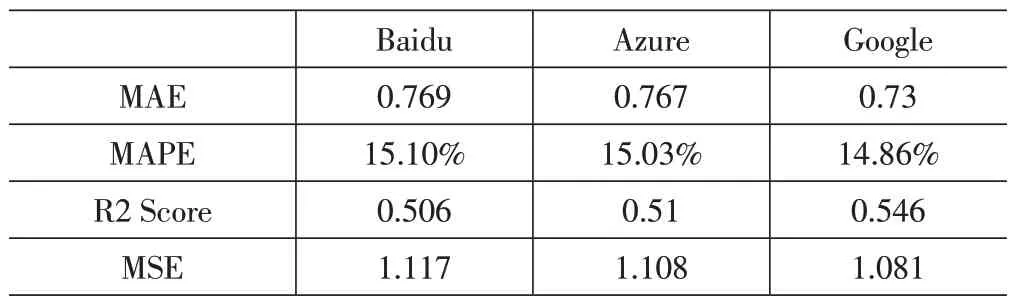
表6 数据集3分类算法模型结果
结合三个平台重要特征来看,三个平台的第一重要特征均是媒体评分。这再次印证了媒体评分与用户评分的关联性。至于市场销量,在EasyDL平台中,北美销量、欧洲销量、日本销量则分别占据第2至第4重要性。但其他两个平台生成的模型中,市场与用户评分的关联则微乎其微。在Google Cloud 生成的模型中,北美销量稍微起到了一定作用。考虑到三个模型中Google Cloud 的模型更好,这说明市场存在与用户评分的可能性,但关联不强。
4 结论
总的来说,就数据内容上看,实验说明电子游戏的用户评分和媒体评分关联较大,市场销量与游戏评分没有必然联系。从EasyDL、Google Cloud、Azure 三个自动学习平台的训练成果来看,EasyDL的训练速度整体上更快;Google Cloud对于数据要求更严格,在数据较完整的情况下表现较好,更容易受数据缺失影响。从模型的特点上看,Google Cloud和Azure的模型重要特征相似度更高,而EasyDL的模型虽然性能表现较好,但与其他两种的模型重要特征差别较大。
猜你喜欢
快乐语文(2020年30期)2021-01-14
英语文摘(2019年5期)2019-07-13
玩具世界(2017年3期)2017-10-16
商用汽车(2016年11期)2016-12-19
飞碟探索(2016年11期)2016-11-14
作文大王·笑话大王(2016年8期)2016-08-08
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
创业家(2015年5期)2015-02-27
