
基于Spark的数据分析可视化平台设计与实现
2022-09-21 07:55周正宇康华夏刘文军陈晨
电脑知识与技术 2022年24期
周正宇,康华夏,刘文军,陈晨
(1.苏州工业职业技术学院软件与服务外包学院,江苏苏州 215104;2.苏州砺行信息科技有限公司,江苏苏州 215151)
1 引言
随着物联网、云计算、大数据等信息技术与传统产业的不断融合,无论是企业内部的经营管理数据还是供应链数据都呈现爆炸式增长。通过对行业相关数据的深入分析,可以直观掌握其业务运营状况,为战略决策、业务调整提供依据;另一方面,供应链协同使得需求预测、产能分析、协同研发等成为可能,产业数据的融合显著提高了企业应对风险的能力。大数据时代,数据作为企业的核心资产,加以分析利用成为提升企业核心竞争力的关键[1-2]。
传统的数据统计、分析挖掘已经显露短板,特别是随着数据量不断攀升,离线的数据分析效率低下的瓶颈日益凸显。相较之下,基于B/S 架构的数据分析可视化平台在大数据分析技术的支持下更加适合挖掘数据潜在价值,提供可靠的辅助决策信息,能促进企业核心竞争能力的建立,确保企业的可持续发展[3-7]。
本文针对该问题,给出了一种适用于海量数据下,基于Spark和前端技术实现快速定制化数据分析的平台设计和实现方案。利用数据仓库、线上分析处理等技术对客户数据进行系统的存储和管理,通过各种数据统计分析工具对业务数据进行分析并进行可视化展示,从而实现企业对数据进行有效的管理和整合。
2 关键问题
2.1 运算性能
如今,企业业务的复杂度越来越高,所产生的数据量也越来越大,想要对这些数据进行快速而有效的处理是一个庞大的工程。传统C/S 架构的数据分析工具多使用单机CPU 进行运算,在业务数据量庞大的今天已经难以满足实际需要。使用分布式系统的数据分析可视化平台对系统的运行效率有着巨大的提升,同时采用B/S架构的交互技术带来良好的用户体验。
2.2 数据可视化
传统的数据分析工具需要用户懂得SQL操作,通常需要用户和技术人员反复讨论,选择特定的字段生成目标图表。这一过程中往往有交流和理解上的困难,给用户带来不佳的操作体验。本系统使用Vue.js的draggable组件,实现了对数据字段的直接拖拽生产分析结果的功能,并且用户可以根据业务需求和逻辑自定义图表来呈现精确的可视化效果,大大便捷了用户的操作。
2.3 分析模型
数据的价值在于通过模型分析后为行业管理者提供参考决策。一方面需要选择合理的数据可视化的图表,科学有效地展示给用户;另一方面,需要确定与业务匹配的数据分析算法模型进行支撑。平台自主选择数据源,并且集成主流的分析模型供用户选择。由于用户的业务不尽相同,需要的算法模型难以通用,因而要求平台具有二次开发能力,支持横向拓展算法模型。
3 系统设计
3.1 系统架构
平台的架构设计如图1所示。从右到左分为存储层、数据处理层和展示层。存储层主要用Greenplum分布式数据库存储用户所连接的数据库数据,可供服务器更快地进行数据处理,而不必等用户操作时再去读取用户数据。这一模式大大提高了运行效率。数据处理层使用Spark 并行查询读取数据库数据,再充分利用Spark内存计算的优点,将数据通过基于内存的分布式文件系统Alluxio缓存进内存,通过内存计算来快速处理数据,返回处理结果。展示层采用Vue.js+Element.ui 技术实现前端可拖拽页面的呈现,使数据分析结果按照用户的想法进行直观展现。
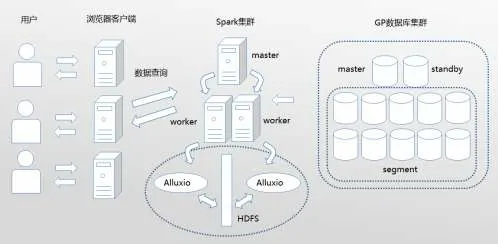
图1 系统架构图
3.2 数据存储
本系统使用Greenplum-Spark Connector 连接器(GSC)以打通GreenPlum 数据库和Spark。GSC 是由Drive 节点和Executor节点构成,本质上是一个Spark application,其工作机制如图2所示。当系统使用GSC读取GreenPlum数据时,其中Drive节点先通过JDBC 的请求方式访问GreenPlum 的master 节点来获取关于被读取数据元数据的信息。GSC将根据这些元数据,让多个Executor 节点并行地读取GreenPlum 数据库中所需要的数据,来提高读取数据的效率,以提升用户的体验。
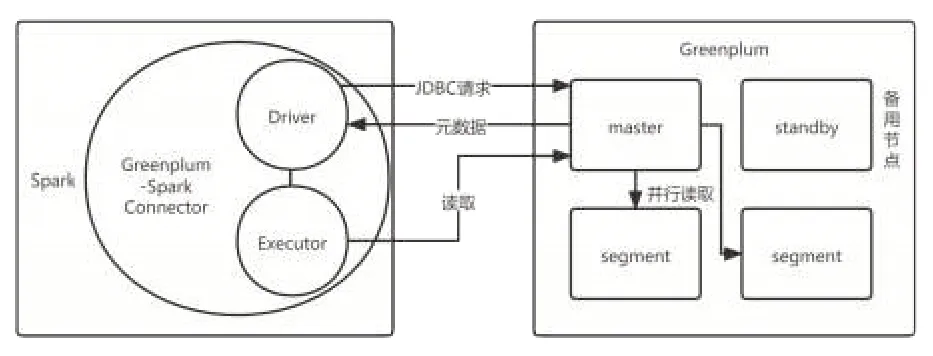
图2 GSC工作机制图
3.3 数据读取
Spark 用户通常使用Saprk RDD Cache 将数据以RDD 的结构存储在Spark Executor 中,以后每次对这个RDD 进行操作时就无需重新计算,直接从内存或者磁盘中提取持久化的RDD数据。但是存储RDD 所需的内存可能会非常大,进而导致Spark Executor的计算内存相对变小,甚至有可能因计算内存不足导致Spark 作业崩溃,致使数据没有被持久化到内存中。本系统为解决这类问题将RDD 数据存储在Alluxio 中,这样Spark Executor 就不需要配置存储数据需要的内存,只需配置计算所需内存。Alluxio 提供了RDD 数据所需的内存,即使Saprk 作业崩溃,数据也会被Alluxio 持久化到内存中。Spark 仍然可以从内存读取数据,将数据提供给web 前端,极大地提高了系统的稳定性和运行效率。该机制下的数据流转如图3所示。
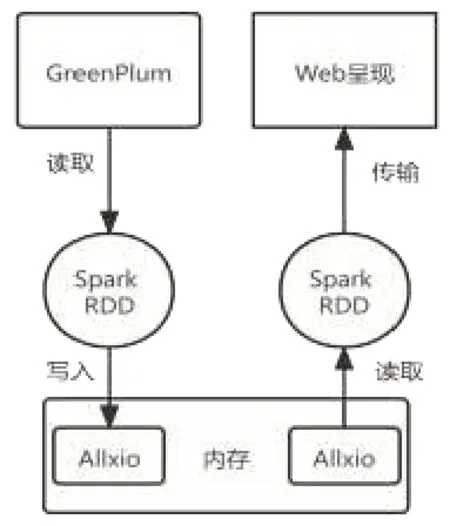
图3 数据流转图
3.4 拖拽式可视化
系统的可视化是基于Vue.js+Element.ui技术实现的。其中可拖拽的功能实现主要引用了Vue 的相关draggable 组件。其中涉及的主要事件和执行时机包括:
1)ondragstart:在拖动开始时执行。
2)ondragover:被拖动的对象在进入另一容器范围内时执行。
3)ondragenter:在被拖动的对象进入该容器范围内时执行。
4)ondragleave:在被拖动的对象离开其容器范围内时执行。
5)ondragend:拖动完成时执行。
6)ondrag,ondrop:分别为拖动时执行和释放鼠标时执行。系统根据这些事件实现了根据拖拽的字段生成对应维度和数值的图表;实现了对图表大小和位置的编辑等自由度高的功能。
3.5 数据分析模型
平台通过Spark中可拓展的机器学习库Spark MLlib进行数据分析模型搭建,特别使用其包含的算法依赖实现了线性回归、逻辑回归等预测模型。Spark MLlib 的算法工具包括聚类、回归、分类、协同过滤、降维等,同时可以进行底层优化,其算法还可以进行扩充。系统通过Spark MLlib 可快速实现数据分析模型的横向拓展。可供用户更好地进行业务逻辑和算法模型匹配,提高分析结果的质量,便于用户更好地进行决策。
4 系统实现
4.1 图表生成
网站界面设计遵循简约风格。如图4所示,给出了一个航班分析应用示例。用户在左上角选择数据源,然后拖动兴趣字段名放入中间的维度或者数值,即可自动生成折线图。用户可以根据具体需求,在右下角切换图表类型,可以对字段进行排序和筛选。示例中,折线图所显示的是对航班的数据进行数据处理的结果。x轴为航班号,y轴为航班人次。可以看出各个航班的当日人次,反映出客流量的差异。所生成的图表可以保存,并支持下载成图片作为素材提供给用户。平台支持对字段进行统计操作,如求和、平均值、方差、标准差、聚类等多种计算方式和分析功能。同时也支持数据分析模型的拓展。
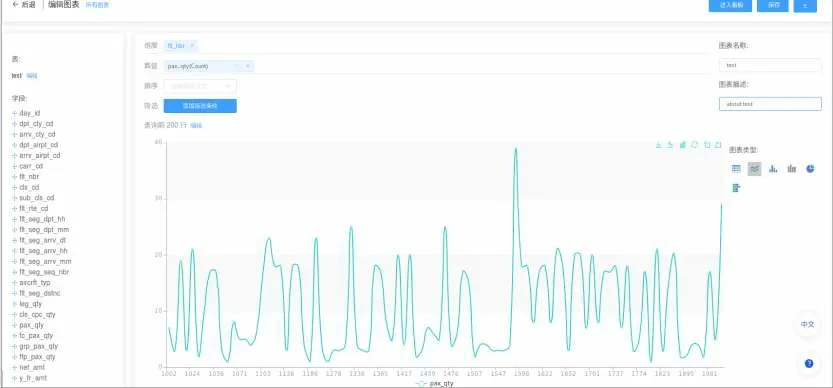
图4 图表生成图
4.2 图表组合
前端页面中可以新建可视化图表,并支持将保存过的图表添加进来,通过对图表进行拖动、拉伸,并按照用户意愿自定义图表大小和位置,最后组合为可视化大屏。如图5 所示,通过拖拽方式构建了一个航班数据可视化大屏。此外,用户点击分享能够生成链接,把生成的链接发送给其他用户进行共享。
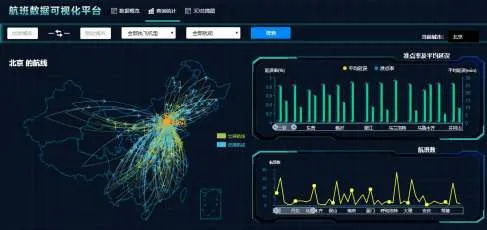
图5 报表生成图
5 结论
信息技术迅猛发展的今天,业务产生的数据量是非常庞大的,这些数据流转快速、类型多样、价值密度低。其中蕴含的商业价值很难被挖掘利用,这也成为现阶段企业的难题。本文设计的大数据分析可视化平台通过Spark内存计算、GreenPlum分布式数据库、可拖拽式的页面呈现等技术,对该类型问题提供了一种有效的解决方案。特别地,本方案支持大数据算力,并且服务器可以进行横向和纵向拓展,为问题的解决提供了一种有益的尝试。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
高技术通讯(2021年5期)2021-07-16
海洋信息技术与应用(2020年1期)2020-06-11
当代陕西(2019年13期)2019-08-20
传媒评论(2019年4期)2019-07-13
足球周刊(2016年14期)2016-11-02
足球周刊(2016年15期)2016-11-02
足球周刊(2016年10期)2016-10-08
世界博览(2016年16期)2016-09-27
