
学习投入的智能视频研究综述
2022-09-19 09:27罗德凤方雨洁邓洁瑞谢从华
常熟理工学院学报 2022年5期
罗德凤,方雨洁,邓洁瑞,汪 洋,谢从华
(1.重庆三峡学院 外国语学院,重庆 404100;2.常熟理工学院 计算机科学与工程学院,江苏 常熟 215500)
0 引言
学习投入又称学习参与,是学习活动心理和体力投入行为的总和[1].学习投入有多种分类体系:Martin[2]认为包含认知和行为维度;Fredricks[3]将其分为行为、认知和情感维度;而Anderson等人[4]认为可分为行为、学术、认知和心理维度.在情感计算等技术推动下,从行为向情感与认知维度扩展趋势发展演进.学习投入度量是精准教育的重要依据,一方面能帮助学生反思其学习,另一方面帮助教师掌握学生投入情况并及时干预,以促进学生参与学习过程.
学习投入度量的人工智能分析方法有两类:一类是在线学习大数据分析法,用网络学习时长、学习资源使用、测试结果等度量学习投入行为.大数据智能分析法突破了传统方法的瓶颈,具有科学性和客观性[5].但缺乏学生面部与肢体等“真实场景”信息,可能导致“路灯效应”[6].另一类是基于视频信息的方法,采用人工智能技术对学习视频图像、语音、文本,以及融合生理、心理等模态数据建模计算,分析不同学习场景下学生的学习投入度.
本文对学习投入度量的人工智能视频分析界定为依托于不同学习情景空间理论,借助视频处理和图像识别技术定位、检测、识别和跟踪学生个体或群体的脸部、面部、头部和身体部位,融合图像、语音、文本、生理和心理等模态信息人工定义和机器学习学生面部表情、手势、步态、精神状态、情感等特征,使用分类器等方法自动度量学习投入,服务于描述或解释学习投入行为及其特征规律的计算机应用技术.相关研究目前产出了大量理论、方法、应用和工具等成果,具有广泛的应用前景.
本文以文献内容分析法为主,依据视频单模态和多模态数据从学习情景、发展历程、特征提取、自动度量方法和结果应用等方面定性和定量地分析相关研究成果,以期能为后续学者研究提供参考和借鉴.
1 基于视频图像的学习投入度量研究
情感信息55%来自面部[7],所以现阶段多数方法用摄像头采集视频数据,定位和识别学生面部以分析学习投入度.按照不同学习场景学生人数多少分为个体和群体两种情况.
1.1 个体学习投入度分析
基于人脸面部表情的学习投入分析可追溯到2004年Kaliouby等人[8]针对个体学生在不同学习场景的视频图像分析,至今依然是研究热点.多种学习投入度量方法对比如表1所示.

表1 基于视频图像的学生个体学习投入分析对比表
多数方法用人工定义特征,包括头部空间位置和Ekman面部肌肉运动定义的表情[8,11]、计算机表情识别工具提取特征和纹理特征[12,16]等,使用三层动态贝叶斯网络[8]、GentleBoost[9]和多类逻辑回归方法[11]自动分类学习投入.但是视频中学生行为动作是特定场景下的表演行为,很少有不投入学习的学生,不符合真实学习环境下的自然学习行为.针对文本和图片理解学习或学生打字写作等特殊任务,基于表情识别工具CERT,Chen等人[13]和Monkaresi[15]使用WEKA库的朴素贝叶斯、逻辑回归、K-mean、随机森林、Dagging等分类器自动度量学习投入度,以解决面部表情有限、频繁低头姿势导致头部倾斜和人脸非正面等挑战.针对在线学习环境图像变化少、时间短且情感识别准确率较低等问题,Zhu[16]提出了时空几何形状和面部双模态特征学习的混合深度神经网络自动识别学习面部表情,长短期记忆网络(LSTM,Long Short-Term Memory)学习人脸表情演化.
1.2 群体学习投入分析研究
群体学习投入分析需要探测多目标学生,挑战度较高.Qin[17]和韩丽[18]用人脸探测和跟踪技术从视频中自动识别学生群体看黑板或教师或记笔记等行为,分析人脸特征点与学生心理状态的关系,评价参与度、疑难度以及关注度等指数.基于DLIB[19]工具,贾鹂宇[20]用SVM算法分类表情并量化全班学生学习活跃度.Zeng[21]用多任务分级卷积网络(MTCNN)模型定位人脸、FaceNet模型识别人脸、ResNet-50模型识别个体和群体学生情感变化细节.从表2的对比中可见,群体学习投入度量的特征提取和分类方法从传统人工转向深度学习.
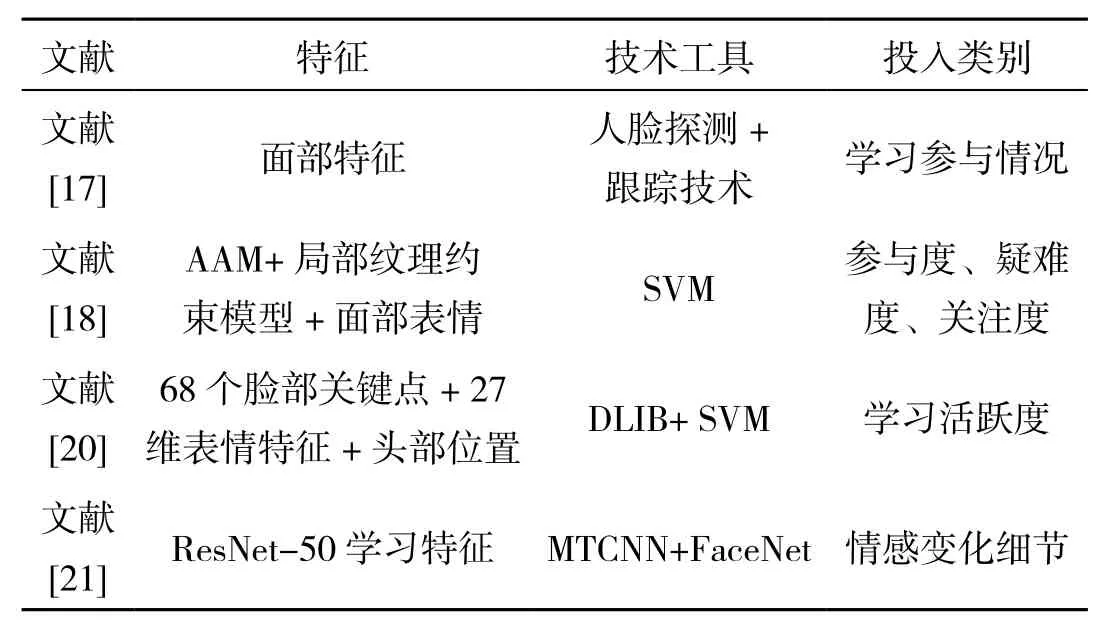
表2 课堂环境中学生群体学习投入分析对比表
综上,人工智能视频图像技术让最复杂的学生学习行为分析自动化、常态化、规模化成为可能.技术层面,成熟的人脸定位跟踪、面部表情计算等技术和工具能捕捉教学视频中个体和群体学生的眼睛、嘴巴、眉毛、身体、手部等动作,浅层或深度机器学习在面部动作、学习表情、学习情绪和感情之间建立起了关联.在线或课堂教学环境下精准采集全体学生的全过程学习中面部或身体动作、学习活动等数据,定义和提取学生个体和群体学习投入指标用于精准评价教学质量,再根据学生学习过程大数据提供个性化学业的精准帮扶.目前智能视频学习投入度量还存在以下几个难点问题.
首先是健壮性和普适性问题.教学场景包括交互和非交互学习、一对一和一对多师生、在线教学和课堂教学、个体和群体学生等不同场景,教学视频还有学生非正面、遮挡、表情干扰等问题.例如在一个大教室有70多人,YOLO 3检测到28人,如图1所示.北京旷视科技有限公司的Face++检测到29人,如图2所示.二者对于远离镜头的小目标人员漏检情况比较严重,箭头所指距离镜头最近的2个人也有遗漏.

图1 基于YOLO 3检测结果

图2 基于Face++模型的教室多目标人脸检测结果
其次是表情分析不足问题.学习情感投入分析的类别多、区别小、训练样本少、表情捕捉和自动识别困难.现有多数面部表情研究都是基于美国心理学家Paul Ekman提出的面部行为编码系统(Facial Action Coding System,FACS).人脸可能有10 000种表情,其中 3 000种表情具有一定情感意义.而现有的学习情感系统只是粗略地用到了其中的几种,多数研究缺乏对微表情、微情绪、微情感的分析,更缺乏研究表情与教学过程、教学效果和影响因素关联.课堂环境多目标表情识别挑战度更大,如图3所示的2个人脸,Face++检测到左眼睛状态出现了明显错误,且表情仅提供了微笑程度.

图3 基于Face++ 模型的课堂多目标表情分析
最后是数据不均衡和标注问题.分析方法从机器学习转向深度学习,需要大数据驱动,但现有研究的数据存在样本不平衡、内容多样性不足、缺少学习行为语义标注等问题.
2 融合视频图像、语音和文本多模态学习投入分析
融合视频图像、语音和文本多模态分析方法对比如表3所示.在线学习场景下,个体学生目标检测、人脸定位和表情识别的准确率较高,但群体学生的多目标检测容易出现漏检.针对在线学习场景,Poria[22]使用Luxand FSDK、JAudio和SenticNet引擎分别提取视频图像、语音和文本多模态特征,开发了智能情感分析系统.针对课堂学习场景,Yang[23]使用工具MTCNN[24]定位人脸,语音识别引擎把语音转换成文本, FudanNLP工具实现文本分词和去停用词等预处理, LDA(Latent Dirichlet Allocation)主题模型分析文本内容,融合视频图像、语音和文本特征识别学生抬头或低头等行为,分析学生对教师或学习内容的关注度,挖掘学生对课程主题的关注度与语音特征的关系.

表3 融合视频图像、声音和文本多模态学习投入分析对比表
融合视频图像、语音和文本多模态数据,适合大规模、全方位和全过程分析学生学习行为与讲课内容之间的关系、师生之间的语言行为和非语言行为特征和关联,且不需要增加硬件成本.三种模态时间同步、内容互补,具有更好的应用前景.但是,多模态数据特征融合方法相对简单,只是简单组合后输入机器学习或深度学习算法,缺乏在什么时间和空间以何种形式对不同模态的特征配准和融合规则.目前实现多模态特征的时空一致性学习较难.
3 融合视频、心理和生理等多模态的学习投入分析
融合视频、心理和生理多模态分析方法的对比如表4所示.面向真实学习环境,Kapoor[25]综合蓝眼相机和压力传感器,Mello[26]综合对话线索、身体语言和面部表情特征,用高斯混合模型或线性判别法识别学习情感.为了解决视觉图像遮挡、专注闭眼冥想时容易造成的误判等问题,曹晓明等人[27]提出了多模态数据的ResNet深度网络自动分析法.刘清堂[28]系统总结了视频图像、语音、生理信号和其他多模态数据采集与存储、行为建模.中国乂学教育-松鼠Ai联合提供了包含学习日志、视频和EEG脑电波的多模态数据集MUTLA[29],并于2019年在澳门举办了人工智能分析和理解现实世界教育环境中的人类学习会议.综上,融合多模态数据的学习投入分析主要针对个体学生,以人工定义特征为主,分析方法从机器学习转向深度学习.
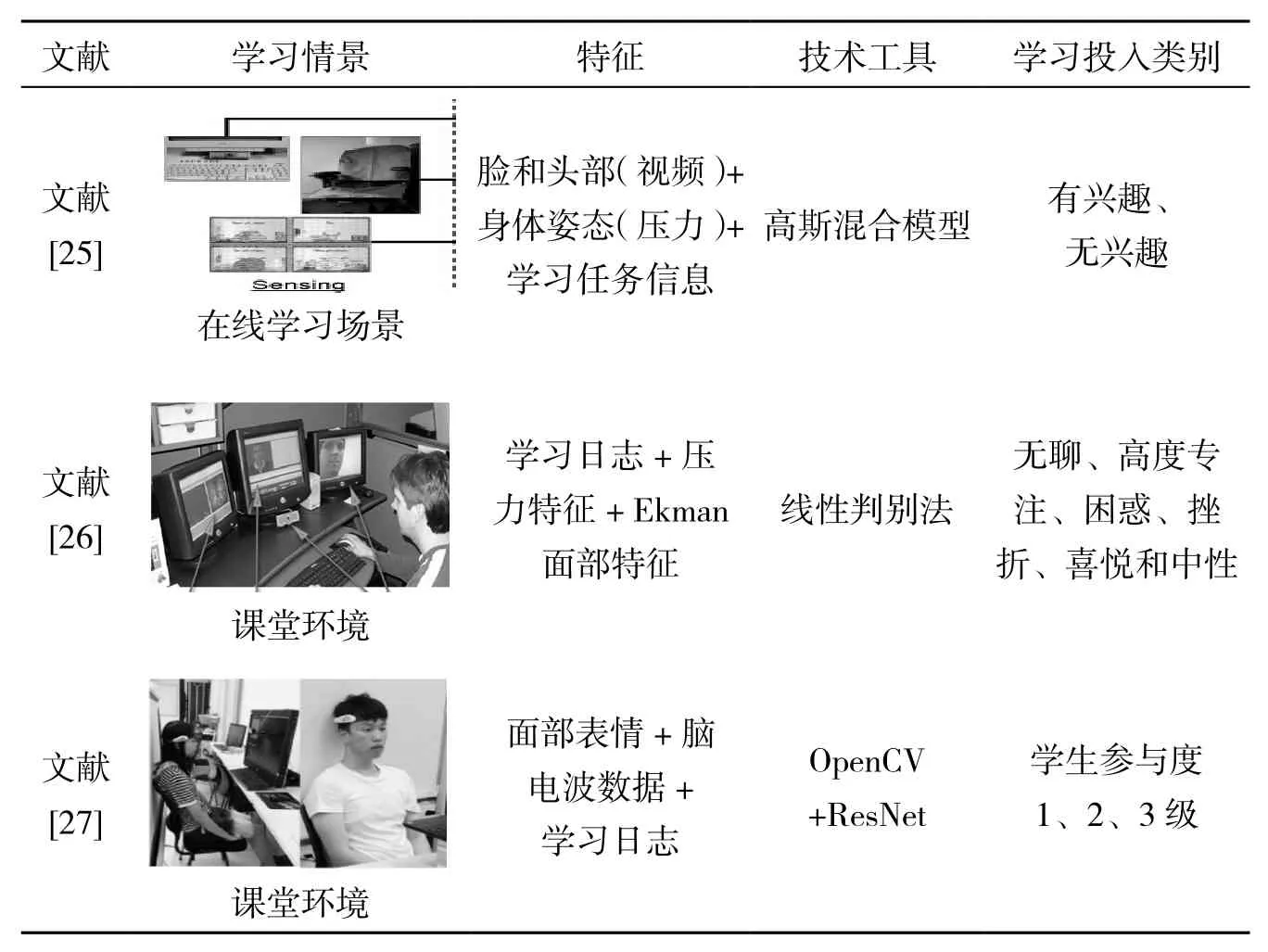
表4 融合视频、心理和生理多模态学习投入分析对比表
智慧学习环境下提供了视频传感器采集言语表达、面部表情、姿态手势、语音、文本数据,心理和神经传感器采集学生EEG(脑电波)、血压、心率或皮肤电反应数据等,从本质上更准确揭示学习行为及其因素分析.学习投入分析方法从机器学习转向深度学习,需要带有标注的多模态学习视频大数据驱动,但现有研究数据集样本不平衡、内容缺乏多样性、缺少学习行为语义标注等问题.训练数据同质化严重,每种学习情感类别的训练数据内容变化不大,准确率严重依赖于学习的具体概念.
融合视频、生理和心理多模态数据,适合智慧学习环境下小规模、多维度和全过程实时性地分析学生学习时的生理和心理之间的特征和关联.研究生理和心理参数与学习行为视频观察到的面部表情、人脸特征、身体姿态和手脚动作之间的关联,需要增加硬件成本.部分传感器会干扰学生学习,采集和分析数据可能不是最自然的学习行为,很难大规模应用.
4 结论
智能视频学习投入度量为教育人工智能背景下学习理论研究和实践应用提供了高效方法,符合当前国家和社会对精准教育的迫切需求.通过梳理人工智能驱动视频分析学习投入度量的理论、方法、应用和工具,发现了几个演变趋势:数据来源从单模态向多模态演变;特征提取从人工定义向深度模型学习转变;分析方法从机器学习向知识驱动的深度学习演变;结果从粗粒度向细粒度发展.
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
上海文化(文化研究)(2022年3期)2022-06-28
昆明医科大学学报(2022年3期)2022-04-19
数学年刊A辑(中文版)(2022年4期)2022-02-16
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
动漫星空(2018年9期)2018-10-26
广西科技大学学报(2016年1期)2016-06-22
中国学术期刊文摘(2016年1期)2016-02-13
