
突发重大公共卫生事件情境下的微博文本情感分析
2022-09-16 08:25董婧范全润张顺吉
内蒙古师范大学学报(自然科学汉文版) 2022年5期
董婧,范全润,张顺吉
(1.曲靖师范学院信息工程学院,云南 曲靖 655011;2.曲靖师范学院信息与教育技术中心,云南 曲靖 655011)
随着世界信息总量每月以超过100 PB的数量增长[1],文本情感分析已成为自然语言处理领域的研究热点之一[2-4]。网络文本内容通常体现了作者的立场、观点、看法、情绪、好恶等主观信息,文本情感分析即通过计算技术对文本的主客观性、观点、情绪、极性的挖掘和分析,对文本的情感倾向做出分类判断[5]。研究者一般将主观本文的极性分为褒义和贬义,分类思路一般分为基于情感知识的方法和基于特征分类的方法[6]。互联网用户在微博平台发表的言论往往带有强烈的主观倾向性[7]。新浪微博作为国内领先的社交媒体平台,如果能从微博文本中挖掘潜在的舆情情感信息,提供舆情预警,政府和相关部门便能够做出快速有效的处理应对[8],促进舆情平复,降低突发公共卫生事件的负面效应。
国内外学者对社交媒体时代的文本情感分析研究较为成熟。王树义等[9]提出一种基于情感分类的主题挖掘方法,有助于企业聚焦自身与竞争对手的主要优势与问题;李涵昱等[10]提出了一种基于商品属性提取与过滤算法、情感词判别算法,实现商品评论的情感倾向性分析;黄发良等[11]提出一个基于多特征融合的微博主题情感挖掘模型,实现了微博主题与情感的同步推导;朱鹤等[12]针对金融文本的情感分析任务,提出基于金融领域的全词覆盖与特征增强的BERT模型;谭旭等[13]通过构建情感值测度算法并利用LDA-ARMA模型,实现多维情感分析与演化预测。以上研究都利用各领域的民众评论数据挖掘出了有价值的舆情情感信息,但针对边境地区突发公共卫生事件舆情的情感分析研究还较少,尤其对具有长时间序列和话题延续性的疫情特征,须考虑民众情感在不同阶段的变化。
1 研究设计
本文通过抓取较长特定时间窗口内云南省特定大V微博内容,从可视化分析和机器学习两个方面分析重大突发公共卫生事件情境下社交媒体用户的话题关注焦点,通过微博情感分析发现民众情感在不同阶段的变化趋势,挖掘舆情潜在的情感取向,也从侧面反映出疫情的发展和对人们生产生活造成的影响。对舆情的监测分析并做出及时有效的舆论引导具有一定的理论参考意义。
1.1 研究方法
通过文献研究了解文本情感分析的方法和技术路线,然后对爬取到的微博数据预处理后进行情感挖掘和主题建模,包括可视化分析、情感分析、时间序列分析、统计分析和LDA主题分析。基于SnowNLP中文情感词汇本体库,构建优化情感分类词典,进行情感特征识别;结合研究时间窗口内每日微博情感指数进行长时间序列分析;采用LDA模型进行主题分类,依据困惑度最小确定主题个数,利用卡方检验结果赋予主题权重,结合每日疫情实时通报,分析了民众的情感变化趋势。具体研究思路如图1所示。
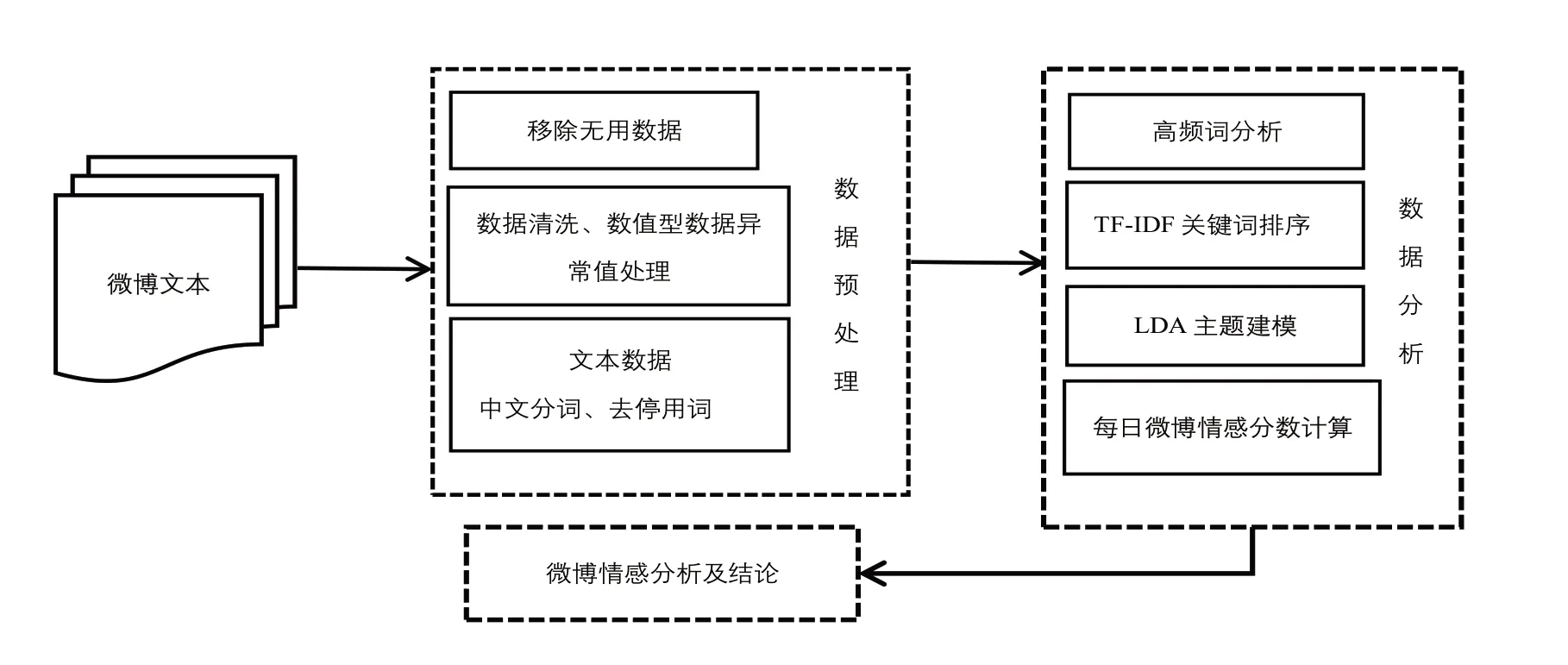
图1 全球战疫情微博热点话题研究框架Fig.1 Global coronavirus pneumonia epidemic microblogging hot topic research framework
1.2 微博文本情感分析关键技术
1.2.1 特征项选择及文本向量化TF-IDF算法通过计算文档中词语的词频和衡量特定词语在该文档中的重要程度来选择特征词并得到特征项的权重,从而建立文本向量空间模型,因其特征项具有较好的类别区分能力广泛应用于自然语言处理领域[14-15]。本文首先计算出微博短文本中词语的TF-IDF值,建立特征词矩阵,得到最终的特征项矩阵,特征项ωij的TF-IDF值Fωij计算如公式(1)-(3)。

其中:ωij表示第i日微博文本数据中出现的第j个词语;C(ωij)表示词语ωij出现的次数;D为每日微博文本数据中的文档总数;|Di|为文档Di中词语的数量;I(ωij,Di)函数取1或者0,1表示文档Di中包含词语ωij,反之取值为0。
1.2.2 LDA主题模型LDA主题模型由Blei等[16]基于贝叶斯模型实现。模型中包含文档、主题和主题词三个层次,输出为任一篇文档的主题分布和主题中词的分布。现有M篇文档,主题数目为K个,对应第t个文档中有Nt个词语,首先假设文档-主题和主题-词的先验分布是Dirichlet分布,α和γ为分布的超参数,第t个文档的主题分布为θt,得到其主题编号的多项式分布Z;对于任一主题k,其词分布为β,得到该词的概率分布ω,从而组成Dirichlet-multi共轭,得到任一篇文档中词的主题编号和任一篇文档中词所属的主题编号下该词的概率分布,然后通过Gibbs采样算法或者变分推断算法不断迭代,使得超参数不断收敛,得到特定文档的主题分布特定主题中的词分布。
1.2.3 情感分析模型训练使用Python库SnowNLP进行情感分析,添加网络词汇中较新的中文褒义词和负面词汇,删除重复词汇,优化情感词典。将目标文本分为积极和消极,返回值表示该文本所蕴含情绪的概率,取值区间[0,1],值越接近1越积极,越接近0越消极。为提高情感预测准确度,需要重新训练情感分类模型,主要步骤如下:
(1)读入人工准备好的正样本和负样本;
(2)调用sentiment类中的handle方法分词、去停用词;
(3)调用贝叶斯模型的训练方法训练情感分类器;
(4)调用Bayes类中的classify方法预测情感分类,测试模型精度;
(5)保存新训练完成的模型。
输入每日微博文本集合D={d1,d2,…,dm},变量m表示每天抓取的微博条数,利用新训练好的情感分析模型,得到每条微博的情感分数sdj,本文在实际判定时,为了使可视化结果更直观,将sdj数值整体下调0.5,即返回值在[-0.5,0]区间内时文本的情感概率值判定为负向情感,在(0,0.5]之间时文本情感概率值判定为正向情感。每日微博文本情感分数SD计算公式为

2 云南省网民情感实证分析
2.1 数据来源
本文使用八爪鱼爬虫工具爬取了自2020年2月20日至2020年4月22日的云南省政务、媒体蓝V微博以及在本土具有影响力的大V微博,如“云南发布”“都市条形码”和“918云南交通之声”等博主的相关微博文本,共获取16056条原发微博文本,包括用户ID、用户名称、粉丝数、简介、发布时间、发布内容、转发数、评论数和点赞数等信息。删除无意义和少于10个字符的微博,得到10314条原发微博文本作为研究数据。
2.2 数据预处理
以周为单位划分研究时间窗口,将所爬取数据分为9个周窗口。抓取到的数据存在部分列值丢失、数值异常和微博文本包含特殊符号等现象。首先对这些现象补充完整或滤掉无意义的词语。采用Jieba分词工具进行文本分词处理,对于疫情涉及的高频词和人名建立自定义词典,并导入专有名词词典,得到规则的分词结果作为模型的输入数据。
2.3 结果分析
2.3.1 微博高频词分析读取数据统计词语频次,得到前15个高频词,分别是疫情、防控、病例、出院、工作、治愈、展开、确诊、肺炎、发布、企业、新增、新冠、复工和累计,可以看出疫情防控是研究时间窗口内云南省主流微博媒体话题涉及最多的内容,云南省各州、市除以新冠肺炎防控与诊治为首要任务外,企业的复工复产也是最受关注的民生。从行政区划来看,词频最高的3个地名是云南、昆明、曲靖,这也和确诊人数相符。
2.3.2 TF-IDF关键词排序基于TF-IDF算法降低信息含量低的高频词的影响,抽取文本向量空间中最能代表话题内容的特征词,前25个TF-IDF关键词分别是人流量、边境地区、边民、疫情、减少、成效、边境、取得、明显、通告、入境、畅通、全文、切断、云南省、本土、货物、输入、途径、前提、云南、人数、展开、保证、降低,其中人流量、边境地区、边民、疫情、减少、成效的TF-IDF值最高,说明最能代表云南省主流微博媒体话题内容的特征词集中在边境地区的疫情防控成效和人员货物的出入境等问题,这也符合针对云南所处的独特地理位置,需要制定合理的边境疫情防控政策。
2.3.3 微博情感分析调用优化后的SnowNLP情感分析器,训练新的情感分类模型,使用抓取到的云南省主流微博博主博文文本,得到了研究时间窗口内的每日微博情感分数并将其可视化,结果如图2-3所示。

图2 微博情感分析Fig.2 The daily weibo sentiment analysis
首先将每日微博文本内容作为样本输入,利用训练好的情感分类模型计算得到每条微博文本的情感分数,然后将其累加求平均得到每日微博情感分析指数图。2月25日的微博文本包含正向情感72条,负向情感37条,日微博平均情感分数为0.158;4月21日的微博文本包含正向情感84条,负向情感31条,日微博平均情感分数为0.184。图3以时间顺序,显示了研究时间窗口内的每日微博情感分类结果。从整体来看,日均正向情感的微博文本数量明显更多,且大部分情感分析的结果极性不强;日均负向情感的微博文本数量相对较少,但情感取值明显负向背离0值,且大部分集中出现在3月6日至3月21日之间,总体分类结果按时间序列具有明显聚集性。

图3 微博情感极性预测结果Fig.3 Microblog sentiment polarity prediction
2.3.4 LDA主题分析选取转发数、评论数和点赞数三种评价指标,对九个周窗口的微博信息传播影响力进行评价分析,然后赋予微博话题内容主题权值。卡方统计检验结果显示,微博点赞量的中位数(279205.500)显著大于转发量(34847.500)和评论量(35378.833),微博受众群体对点赞行为偏好更多;微博转发量的卡方值明显较大,转发量、评论量、点赞量的P值分别为0.057、0.444和0.173,均大于0.05,九个周窗口时期的微博转发、评论和点赞均无显著差异性,说明微博网民对疫情的关注度一直在持续,因此对于九个周窗口的主题赋予相同的权值。
利用LDA主题模型建模并进行主题挖掘,根据经验确定超参数α=1/K,γ=1/K,变分推断EM算法的最大迭代次数设置为200,结合微博信息传播影响力强度变化给周窗口话题主题都赋予相同的权重。研究发现:2月下旬云南省主流微博媒体话题内容主题均为新冠肺炎疫情防控与诊治;3月份微博话题内容主题除抗击疫情外,还出现企业复产复工和肺炎疫情境外输入二个主题;而4月份的除抗击疫情外,还包括清明节祭扫、森林防火、世界知识产权日活动三个主题,这与实际情况相符(昆明市自2019年被列入7个国家知识产权示范城市(城区)之一)。
2.4 综合实验结果分析
结合云南省卫健委每日疫情实时通报情况,2月中上旬云南省疫情处于爆发期,2月20日确诊人数达到最高峰,此后增长率为0;3月16日云南新增境外输入确诊病例1例,此后境外输入确诊病例呈递增态势。从图3可以看出,研究时间窗口内2月20日至3月5日期间微博情感分数呈现正向情感,说明政府不惜代价投入了前所未有的人力物力,让普通民众看到了国家抗疫的决心和成效;另外随着疫情拐点的到来,广大民众更加相信本次疫情可防可控。3月6日至3月21日微博情感分数出现了负向情感,结合主题挖掘,说明民众对疫情过后的复产复工准备和前景、云南省疫情境外输入情况表示担忧,但3月22日开始微博情感分数基本都呈现正向情感,说明政府采取了卓有成效的应对政策,民众情感又再次趋于稳定。结合4月份的微博主题挖掘结果,民众情绪已经比较平稳,开始步入正常的生产生活。
3 结语
本文构建了社交媒体平台下的重大突发公共卫生事件舆情情感分析及影响因素模型,监测微博内容的主观情感变化趋势对于控制和引导网络舆情具有重要的现实意义。训练改进的SnowNLP情感分类模型得到研究时间窗口内的每日微博情感分数,使用LDA主题模型建模结合微博传播影响力评价指标赋予权重,得到特定时间窗口的主题,并结合每日疫情实时通报,分析微博情感随时间序列变化趋势。结果表明,每日微博的正向情感天数明显更多,且微博情感分类结果具有一定的时间聚集性,其特点为正向-负向-正向,即随着关乎国计民生事件的出现,舆情情感会出现反转,政府须采取及时有效的政策加以应对。本文的局限性在于微博情感分析过程中,未考虑将用户关系和用户性格情绪等特征数据进行融合分析。疫情的持续将会带来更多的海量数据,进一步将使用分布式爬虫技术获取更长时间序列的微博文本,扩大地域特征,利用多视域特征数据建立更优化的微博情感分析模型,更好地帮助舆情分析。
猜你喜欢
客联(2022年3期)2022-05-31
作文大王·低年级(2022年3期)2022-03-19
中国新闻周刊(2021年26期)2021-07-27
小学生作文·小学低年级适用(2018年12期)2018-04-11
消费电子(2016年12期)2017-01-19
信息安全研究(2016年4期)2016-12-01
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
校园英语·下旬(2016年2期)2016-03-18
中国民政(2016年24期)2016-02-11
