
基于类别主题词集的加权相似度短文本分类
2022-09-16 06:49王小楠黄卫东
计算机技术与发展 2022年9期
王小楠,黄卫东
(南京邮电大学 管理学院,江苏 南京 210003)
0 引 言
在互联网快速发展的信息时代,各主流平台每天都会产生数以万计的信息,其中短文本的数量更是数不胜数。因此对短文本的研究有非常长远的意义和广阔的前景。对于文本处理的技术也越来越先进。
短文本分类是自然语言处理的一部分,广泛应用于数据挖掘、知识检索、情感分类等领域。针对短文本分类的方法,有统计的方法和机器学习的方法,深度学习近年来在自然语言处理领域也发挥了强大的作用。但是短文本分类最大的问题在于长度短,特征数量少,特征稀疏,提取短文本有用的特征才是对短文本分类最大的挑战[1]。针对这个问题,有很多的学者进行探索,都试图去扩展短文本的特征来进行短文本分类。该文在词层面上,没有对短文本进行扩展,而是充分利用词向量来计算词语间的语义信息,对短文本进行分类。
1 相关研究
对于短文本的分类,包括传统意义上的统计学习方法和深度学习方法。
赵晓平用TF-IDF提取短文本中频率为前N的词语进行Word2Vec向量表示,再计算文本空间距离进行分类[2];TF-IDF算法解决了短文本分类中外部语料依赖的问题,但在计算文本特征时存在权重集中和文本区分度低的问题。因此,Duan提出了一种基于卡方统计和TF-IWF算法的短文本分类方法,在准确率、召回率、F值上均有提高[3]。Zhou提出了一种基于语义扩展的短文本算法,通过涉及Word2Vec和LDA模型,以提高经常因语义依赖和特征稀缺而恶化的分类性能[4]。盖璇计算分词权重,提出构建邮件的特征空间,将邮件特征量化[5];霍光煜用LDA主题模型和K-means聚类算法构建模型,对于新的短文本则采用fast-text深度学习进行档案数据的智能分类[6]。余本功提出一种结合主题模型和词向量的方法构建SVM的输入空间向量,并融合集成学习的方式提出的nBD-SVM 文本分类模型[7]。
Zhang针对短文本分类数据不足的问题,提出了一种基于TextCNN的中文短文本分类模型,利用回译实现数据增广,弥补了训练数据的不足[8]。段丹丹利用BERT模型表示短文本的特征向量,再输入softmax模型进行回归训练和分类[9]。付静提出改进的BERT模型,把词向量和位置向量作为模型的输入,通过多头注意力机制获取长距离的语义关系来提取短文本特征,其次利用Word2Vec融合主题模型来拓展短文本的特征表示[10]。张斌艳提出基于半监督图的神经网络模型,在模型构建中引入了词项和文档之间的关系来增强短文本的表示[11]。雷明珠在reslCNN模型的基础上,引入神经主题模型,将信息存储在记忆网络中,加入序列因素,最后,将其输入具有残差结构的卷积神经网络以及双向GRU中,提取局部以及全局的语义特征进行分类[12]。王渤茹在对短文本的特征提取阶段,对比了三种方法,其中基于字词向量的双路卷积神经网络比单一的卷积神经网络效果更好,在此基础上,提出了深度神经决策森林的分类算法[13]。
尽管深度学习在自然语言处理方面效果惊人,但是现有的传统方法利用外部知识来处理短文本的稀疏性和歧义性,由于忽略了上下文相关的特征,准确率仍有待提高。Liu针对这个问题将上下文相关特征与基于时间卷积网络(TCN)和CNN的多阶段注意力模型相结合,并证实了方法的有效性[14]。Cheng针对卷积神经网络(CNN)和双向长短期记忆(BiLSTM)无法区分重要性词的问题,提出一种改进的基于ERNIE_BiGRU模型的分类方法,提高了计算速度和分类效果[15]。
针对短文本特征稀疏,分类困难的问题,该文提出一种基于类别主题词集的加权相似度的短文本分类。选择出最能代表各类别的词语组成类别主题词集,通过计算关键词到主题词的加权相似度来选择短文本的类别。解决了短文本特征稀疏、特征抽取难度大的问题。
2 基于类别主题词集的加权相似度分类
针对短文本存在的数据稀疏和特征选择难度大的问题,提出的模型和传统的特征拓展不同,而是计算短文本的关键词和类别主题词之间的加权相似度来对短文本进行分类。该文提出的基于类别主题词集的加权相似度算法,其核心思想是通过TF-IDF选取各类别下的类别主题词,保留各词语的TF-IDF值,使用Word2Vec训练出词向量模型,将短文本预处理之后的关键词与各类别下的主题词的相似度进行加权求和,选择相似度最大的类别作为短文本的类别。
基于主题词集的加权相似度短文本分类算法主要分为四个模块:关键词提取模块,对短文本关键词进行分词、去停用词处理;类别主题词模块,选择最能代表本类别的词语构成类别主题词集;词向量训练模块,基于内部数据语料使用Word2Vec训练词向量,得到词向量模型;算法分类模块,将短文本关键词和类别主题词相似度进行计算,融合主题词的权重,以进行分类。框架设计如图1所示。
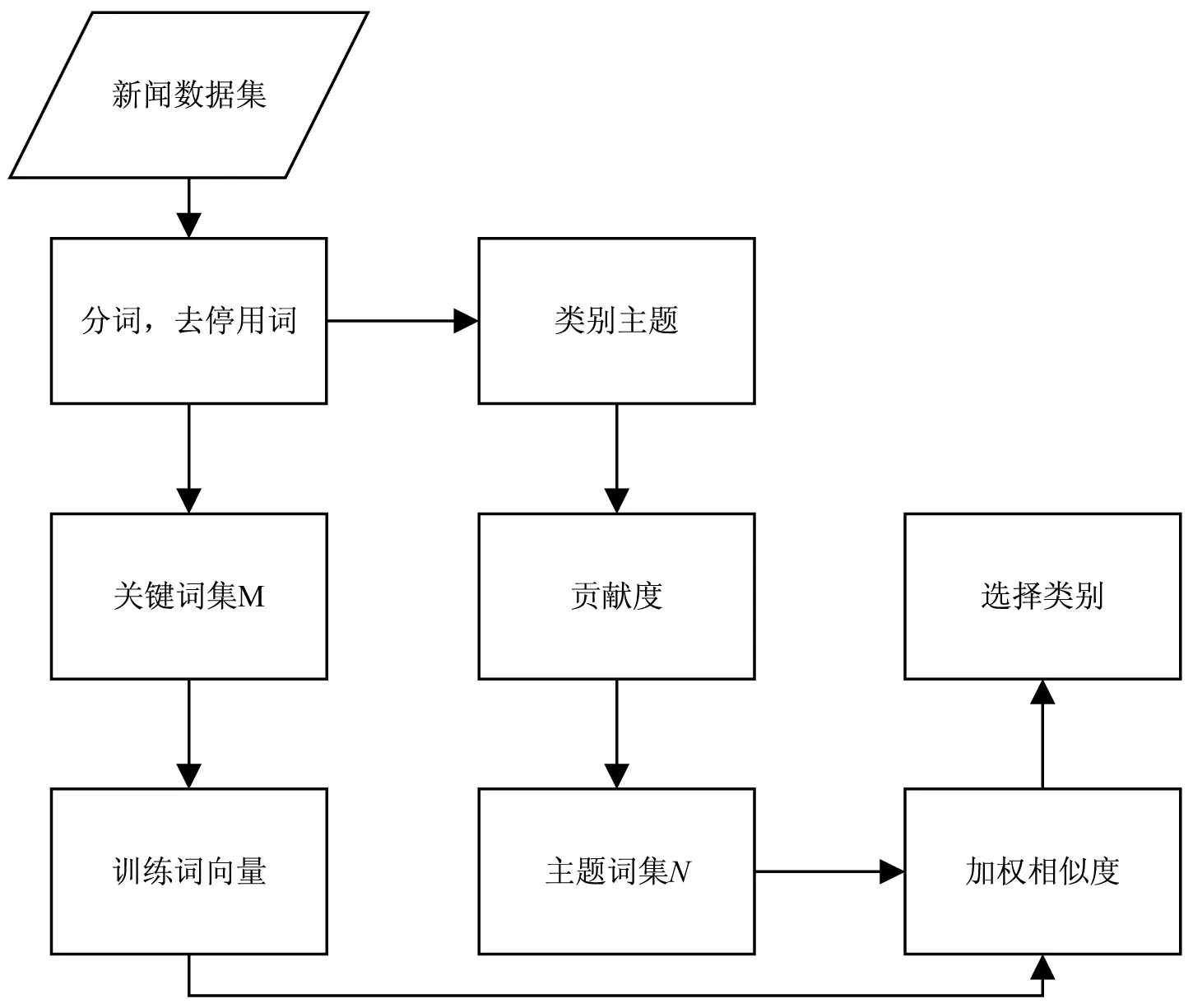
图1 框架设计
2.1 word2vector模型
word2vector是词语向量化表示的升级。从传统的独热编码发展到根据上下文语义更好地表示词语。word2vector也叫词嵌入,词向量是神经网络算法进行N-gram语言模型训练过程中的一个副产品,并能够在训练过程中得到词的向量化表示。语言模型训练时的目标函数为:
其中,m表示文档的数量,n表示每篇文档的单词数,p((wij|contextij))表示在上下文为contextij的条件下wij出现的概率。词向量就是最大化上述目标函数时的产物。word2vector提供了两种经典的语言模型进行训练,分别是CBOW和Skip-gram模型。CBOW是根据上下文词语来预测中间词语。Skip-gram模型与CBOW模型不同,是利用当前词推测上下文中的相关词汇。在训练过程中,两种架构又各有侧重:CBOW在词向量的训练速度方面表现出色;Skip-gram虽然在训练速度上较慢,但是其训练低频词的效果较好。在该文的模型中需要训练全部的特征词,所以选择Skip-gram模型。
2.2 类别主题词集和贡献度
主题词要能最大程度地反映类别信息。将各个类别下的词语按照TF-IDF值来对词语进行降序排序。选取前TOP-N个词语作为类别的主题词集Ni。主题词反映类别的不同程度用贡献度来表示,并将主题词的TF-IDF值作为主题词对类别的贡献度。在对新闻标题文本进行分词,去停用词之后,将所有文本用作语料库。TF表示短文本中词语出现的频率,IDF表示出现这个词语的类别数。则TF-IDF的计算方法如公式2:
(2)
其中,wij表示某一类别中的特定词语出现的次数,∑wj表示特定类别的词语总数,n表示类别总数,wi表示含有这一词语的类别数。为了防止对数的真数和分式的分母为零,用上述公式进行修正。
2.3 关键词到类别的相似度
短文本的关键词为Mi,主题词为Ni,短文本中的关键词到主题词的相似度用余弦公式(公式3)来计算。并且考虑到各类别下的主题词的TF-IDF值差距过大会对结果产生影响,所以每个类别下相同顺序的词语权重值取平均值作为第TOP-N词的权重。用主题词的TF-IDF值来代表主题词对类别的贡献度。每个关键词与类别的相似度用模型f(xi)表示(公式4),xij表示的是短文本的第i个关键词与第j个主题词的相似度。贡献度体现在模型的权重w中。
(3)
f(xi)=w1xi1+w2xi2+…+wixij+…+wnxin
(4)
因此,短文本到类别的相似度为g(x),如公式5所示。
(5)
选择短文本相似度最大的类别作为短文本的类别。
3 实验结果与分析
3.1 数据集以及数据预处理
实验在内存为16G的windows10系统上进行,使用的编程语言为python3.6,编译器为jupyter notebook。
实验目的是为了测试基于类别主题词集的加权相似度算法的分类效果。该文使用公开的THUCNews语料库。THUCNews语料库是新浪新闻RSS订阅频道2005年—2011年的数据,共有74万篇新闻文档,14个类别。选取其中房产、股票、教育、社会、时政、体育、游戏7个类别的文本进行实验。其中每个类别训练集为18 000条数据,测试集为1 000和2 000条,并将1 000条和2 000条数据结果进行对比。具体实验数据如表1所示。

表1 新闻数据集
首先将所有数据进行分词和去停用词处理。选取每个类别下TF-IDF值为前TOP-50的特征词作为类别主题词,如教育类的TOP-30主题词和TF-IDF值,如图2所示,‘考研’一词对教育类别的贡献度最高。

图2 教育类别主题词集
考虑到各类别下的主题词的TF-IDF值差距过大会对结果产生影响,所以每个类别下相同顺序的词语权重值取平均值作为第TOP-N词的权重,因此选取各类别下TOP顺序在同一位置的特征词的TF-IDF值进行平均,得到TOP-50个主题词的权重,如图3所示。
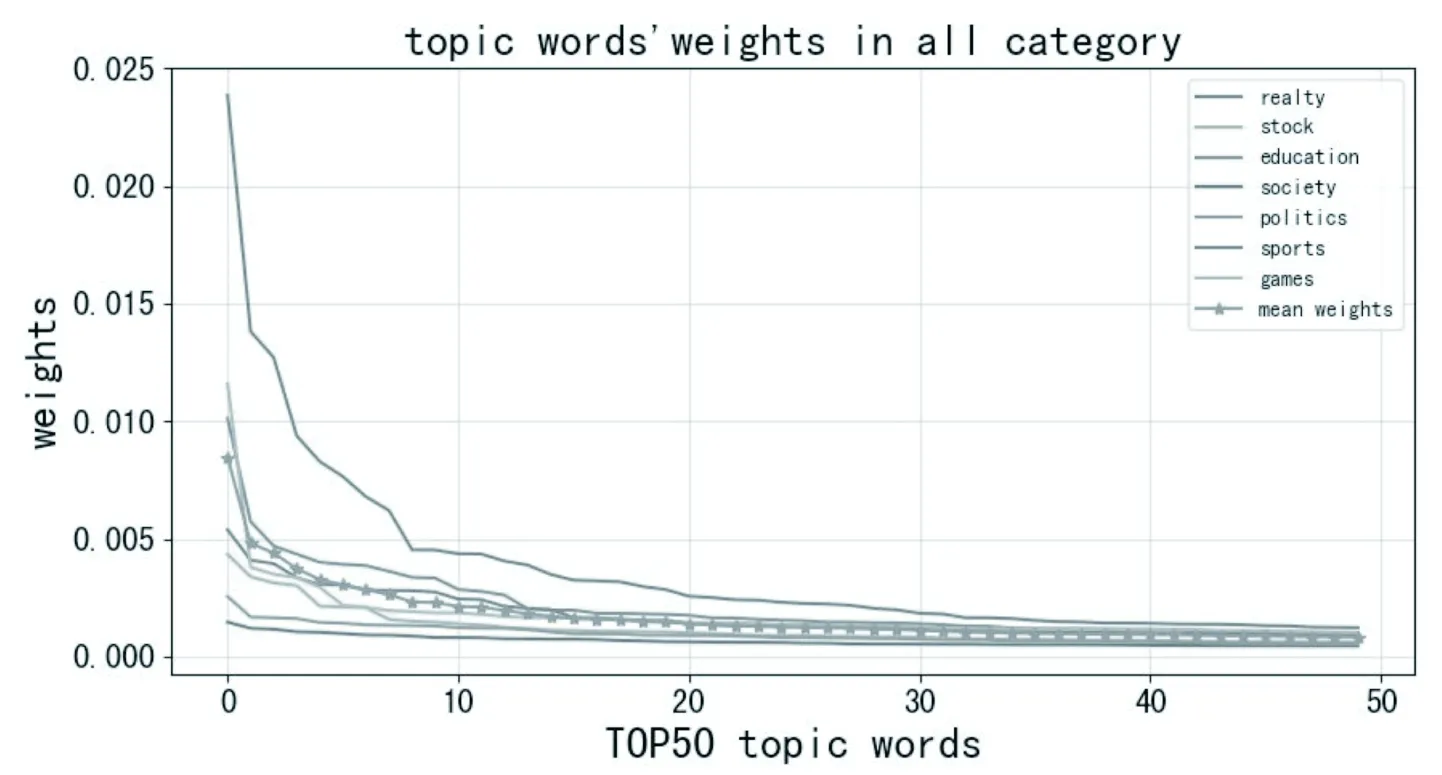
图3 各类别平均权重
3.2 评价指标
实验中采用精确率(PR)、召回率(RC)、调和平均值(F1)来评价模型的分类效果,其计算方法如下。三个指标分别来评估测试集为1 000和2 000时的精确率、召回率和调和平均值。
(6)
(7)
(8)
其中,TP是正确地预测为正例,FP是错误地预测为正例,FN是错误地预测为反例。精确率(公式6)是正确地被预测为正例(TP)占所有实际被预测为正例(TP+FP)的比例,召回率(公式7)是正确地被预测为正例(TP)占所有应该被预测为正例(TP+FN)的比例,F1是PR和RC的调和平均值(公式8)。
3.3 词向量模型对召回率的影响
使用Python环境下的Gensim库训练词向量模型,Skip-gram模型中,window表示窗口大小,size表示词向量的维度。通过不断增加size的大小,分类召回率在不断变化。当window设置为8,size大小为15时,达到曲线的拐点,此时的召回率最高,达到了88.9%,在此基础上通过调节参数window的大小,当window为16时,达到最高召回率91%,如图4所示,选用此时的Skip-gram模型训练并计算关键词与各类别词的相似度。

图4 召回率随size的变化情况
3.4 基于类别主题词集的加权相似度分类算法
如第一条测试集数据为[词汇 阅读 关键 考研 暑期 英语 复习 指南],类别标记为教育类别,标签数字为2,短文本到各类别的相似度分别为[0.319 846 16,0.287 555 1,0.475 932 26,0.334 259 93,0.296 793 82,0.294 998 77,0.323 647 86],由此判断此条新闻标题属于教育类别,分类正确。图5展示了社会类别数据的分类结果,社会类别标签为3,预测正确的是类别3,预测错误的是3以外的其他标签数字。

图5 社会类别分类结果
3.5 实验结果分析
在测试集为1 000条和2 000时,测试文中方法在分类任务上的分类效果,各类别的精确率、召回率以及调和平均值如表2所示。

表2 各类别分类指标
表2显示文中分类方法在数据集各个领域类别均能获得满意的分类效果,是一种有效的分类算法。其中房产领域效果尤其明显,在时政类别效果略逊色于其他类别。可能时政类别新闻标题的内容较短,而这里基于所有标题同样长度来训练Word2Vec所导致的。
将文中方法与三种基于单一模型的分类方法(KNN、Logistic分类、决策树分类)进行比较,表3展示了测试集为1 000时各种算法的精确率(PR)、召回率(RC)和调和平均值(F1)。
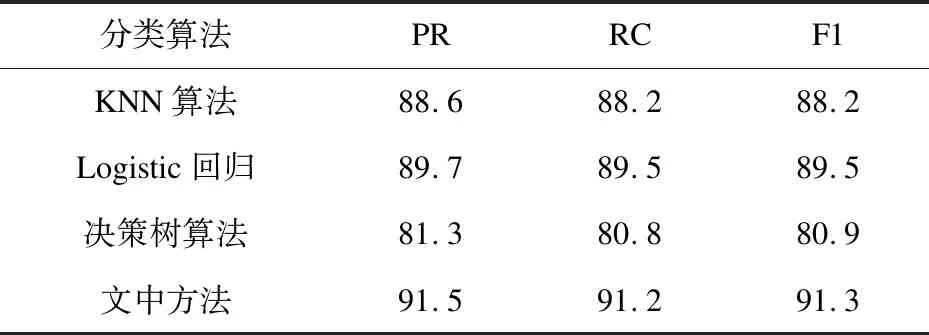
表3 算法对比结果 %
表3显示,前三种基于单一模型的分类方法中,基于决策树的分类算法效果最差,表明决策树分类模型并不适用于文本分类,决策树需要足够多的特征支持,要想取得一个较好的效果,须从数据中构建非常多的特征,做大量的特征工程相关工作,但是短文本特征稀疏,因此决策树并不适合处理高维稀疏矩阵数据;与三种基于单一模型的分类方法相比,文中方法相较KNN算法、Logistic回归算法、决策树分类算法在精确率上分别提高了2.9%、1.8%、10.2%;在召回率上分别提升了3.0%、1.7%、10.4%;在调和平均值上分别提高了3.1%、1.8%、10.4%。用加权相似度算法融合词向量与类别主题词集对短文本进行建模,能够更精细在词层面表示文本的语义信息,从而提高短文本的分类效果。
4 结束语
提出了一种基于类别主题词集的加权相似度算法,在词的层面充分利用词向量和词语之间的相似性来进行文本分类,并且还探索了词向量维度的大小对结果的影响。与其他分类算法相比具有一定的优势,例如和机器学习与深度学习的算法相比,适合数据量不多的情况,无监督学习不需要过多数据进行训练和学习,算法简单,分类速度快。但是该模型中的权重选取过于简单,缺乏依据。后续将重点研究如何通过训练得出最优的权重组合。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
档案管理(2014年6期)2014-10-30
商品与质量·消费研究(2013年7期)2013-08-29
城市建设理论研究(2011年28期)2011-12-31
微型计算机(2009年4期)2009-12-23
