
基于PSO-CNN的验证码识别算法研究
2022-09-16 07:15李建平
计算机技术与发展 2022年9期
李建平,王 钊
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
验证码是分辨用户是机器还是人的一种公共全自动算法程序。作为互联网领域保证网络安全的常用手段,验证码技术的产生极大程度上阻止了非法用户暴力破解用户密码、频繁登录与注册等恶意行为,有效地保证了网站内部数据的安全,避免了大量僵尸用户的产生[1]。但是对于在机器人流程自动化领域,为实现自动化处理业务就必须实现验证码自动化识别。然而数量巨大且抽象的验证码,人工识别都很难达到高的准确率,更何况使用机器识别。这就间接导致了实现自动化处理业务似乎变成了一个无法实现的难题。
传统的验证码识别方法一般基于OCR技术。OCR即光学字符识别,其实现原理是利用电子设备检查图形的亮暗的形状来翻译成计算机字符的过程。OCR识别验证码之前需要对源数据进行预处理。例如二值化、行切分、连通域分析等。虽然对于比较规整的字符序列采用OCR技术也会取得较好的识别效果,胡晓辉[2]利用Tesseract光学字符识别引擎实现了对验证码的识别,并取得了较好的识别效果。但是随着大量具有抽象、粘连、噪点等特征图像验证码的出现,OCR技术识别效果却收效甚微[3]。其缺点表现如下:(1)对于复杂验证码图像二值化处理会造成信息缺失;(2)人工干预过多。对方法参数的设定完全依赖于当事人实践经验;(3)OCR识别灵活性差,导致对复杂验证码图像处理修改空间急速变小;(4)大量的电子识别设备需要高额成本;(5)英文字母识别率低下。
直至本世纪初卷积神经网络理论的逐步成熟使得验证码自动化识别有了新的突破。相比于其他的验证码识别技术,卷积神经网络拥有更加强大的容错能力、自学习能力、泛化能力和并行处理能力[4]。改变全连接层神经元个数所构建的基于深度卷积神经网络AlexNet多任务验证码识别模型[5]以及通过Inception模块替换Google-net的卷积层所构建的基于端到端的验证码识别模型[6]等都取得了不错的识别效果。故针对传统验证码识别技术上的不足,该文提出了一种基于PSO-CNN的验证码识别技术。验证码识别模型的建立通过四个部分来完成,分别为验证码源数据预处理、搭建卷积神经网络识别模型、寻优识别模型参数、评价验证码识别效果。
1 相关理论
针对合同管理系统的验证码识别,采用粒子群优化算法与卷积神经网络相结合的方式。即利用卷积神经网络作为训练识别模型的基础,而粒子群寻优算法则是为了找出最优的识别模型参数。故为获得优化后的验证码识别模型,该文以卷积核大小和网络层数作为粒子群寻优的问题域,将验证码识别的准确率作为寻优算法的标准,并最终返回某一迭代范围内的最优的卷积大小和网络层数大小参数。进而得到优化后的验证码识别模型。
1.1 卷积神经网络(CNN)
卷积神经网络作为一种前馈神经网络是进行大型图像处理的利器,其网络层级结构由数据输入层(原始图像预处理)、卷积层(卷积神经网络中最重要的一层,完成提取特征的过程)、ReLU激励层(将输出结果做非线性映射。ReLU函数具有收敛快、计算梯度快的特点)、池化层(用于压缩数据和参数的量,减少过拟合现象的发生)和全连接层(“分类器”的作用)依次构成[7]。
1.2 粒子群算法(PSO)
基于上述卷积神经网络虽然为验证码图像识别提供了新的思路,但是在卷积神经网络训练参数的设置完全取决于技术人员的实际经验,这就直接导致不同的参数将会得到不同的验证码识别准确率。甚至有时因为参数设置的原因,不同的验证码识别模型预测准确率相差甚大。故从卷积核与卷积神经网络层数这两个方向入手,该文利用粒子群优化算法在卷积神经网络构建验证码预测模型的过程中寻找出适合于当前验证码识别模型的最优参数。
为解决实际工程中的最优化问题,智能算法应运而生。遗传算法(GA)、退火算法(SA)、粒子群优化算法(PSO)等都是智能算法中的代表算法。其中粒子群优化算法因简单易行、收敛速度块、设置参数少的优势备受学界的青睐[8]。该算法思想是受鸟类或鱼类觅食的行为的启发。该文将寻优的参数视为粒子群优化算法中的“粒子”,将这些“粒子”置于解空间中进行迭代搜索,在搜索的过程中利用“粒子”之间的协作与信息共享来最终得到验证码识别模型的参数最优解。
在粒子群优化算法中,每一个寻优粒子赋予记忆功能。其具有两个属性,分别为速度与方向。速度代表的是寻优粒子在解空间中活动的快慢。寻优粒子后续状态由自身的飞行经验和同伴的飞行经验共同决定。寻优粒子的速度不宜过快,速度过快将很可能导致错过全局最优解。方向代表寻优粒子在解空间中活动的方向[9]。每一个粒子所处位置与最优解或满意解之间的偏差通过测度函数来进行衡量。其中寻优粒子的速度更新公式为:
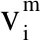
粒子i的位置更新公式为:
(2)

故验证码识别模型的寻优参数步骤如下:
(1)设定验证码识别模型寻优种群规模,随机初始化每个寻优粒子以及最大迭代次数。其中种群规模的设定不宜过小,太小则陷入局部最优解的可能性就会加大。粒子群优化算法优化能力强,当种群数数目增至一定数量时,再增长所寻优结果将不会发生太大变化。
(2)根据测度函数计算每一个寻优粒子的适应度。其中将验证码识别模型的准确率作为测度函数的返回值[10]。
(3)更新寻优粒子本身历史最好位置、种群历史最好位置、粒子的速度与位置。
(4)当达到最大迭代次数或者满足设定最小误差时,停止迭代即完成验证码识别模型的建立。否之返回步骤2继续寻找最优解。
2 基于PSO-CNN验证码识别模型构建
验证码预测模型构建的过程大致分为三个部分:(1)向前传播;(2)损失函数值计算;(3)反向传播。识别模型不断调整权重和偏置的值,当误差小于某一个设定误差值时,则停止迭代完成验证码预测模型的构建。验证码预测模型的构建流程如图1所示。

图1 验证码预测模型的构建流程
(1)向前传播。向前传播分为:卷积层向前传播、池化层向前传播、全连接层向前传播。卷积层向前传播指的是通过事先设定的卷积核大小对输入验证码图像进行卷积处理。传播计算公式为:

池化层向前传播。池化层也叫下采样层,该层将卷积层提取的特征数据利用最大池化算法或者平均值池化算法[11],降低特征数据的计算难度,有效防止了过拟合现象的发生。
(4)
全连接层向前传播。经过卷积和池化操作之后将特征数据输入至全连接层进行输入数据的分类,并建立预测模型。
(2)损失计算。损失函数用于衡量计算实际分类结果与标签结果之间的偏差。偏差越大说明模型分类效果越差,反之偏差越小分类结果相对越好。损失函数公式为:
(5)
其中,EP表示预测模型损失偏差的和,aL表示第L层的输出节点,y表示标签结果,P表示有数据的组数。
通过对预测模型损失函数的计算,再利用梯度下降法不断更新权重W和偏置b。参数更新公式为:
(W,b)=argmin(EP(W,b))
(6)
(W,b)(n+1)=(W,b)n-α·grad(EP(W,b)n)
(7)
其中,α表示学习率,学习率表示模型对最优参数W,b寻找的仔细程度。grad表示梯度下降函数。
(3)反向传播算法。当预测值与标签值损误差值大于设定误差时,将误差值一层一层返回,计算出每一层的误差并更新权重参数。
3 数据预处理方法
获取吉林某油田合同管理系统登录页面的验证码数据集。源数据集包含三个特征:(1)抽象。字母、数字并不是规整排列的,而是歪歪扭扭并行排列;(2)粘连。有相当一部分的验证码相邻的字母或数字之间相互连接在一起;(3)含噪点。每一张验证码图片包含了干扰识别准确率大的噪点。其原始图片效果如图2所示。

图2 未处理的验证码
对于原始数据集的处理,该文主要分为灰度化处理、二值化、降噪三步。灰度化指的是将彩色图片转化为灰度图片的过程。由于彩色图像具有R、G、B三个通道,直接用彩色图片进行训练将会导致建模时间过长,既耗时又耗力。故将源数据集进行灰度化操作转化为单色道的灰度图片。灰度化操作一般包含三种算法:最大值法、平均值法和加权平均值法。加权平均值法[12]灵活度高、自定义性好,故使用该方法完成对图像的灰度化操作。其公式如下:
(8)
其中,ω1、ω2和ω3分别为R、G、B的权值。取不同的权重参数可以得到不同的灰度图像。ω1、ω2、ω3分别取值0.299、0.587、0.114。其得到的灰度验证码图片如图3所示。

图3 灰度化后的验证码
为了更好地提取图像中的信息,增加验证码识别的准确率,需要对图片进行二值化处理。二值化[13]处理顾名思义指的是按照某一个灰度阈值将灰度化后的验证码图像像素点划分为白色(0)或者黑色(255)两部分。故经过二值化后的图片只会呈现黑白两种效果。二值化处理的关键点在于灰度阈值的选择。该文选用全局阈值的方法将灰度阈值设定为200。其二值化处理后的效果如图4所示。

图4 二值化后的验证码
降噪操作进一步降低了识别模型的数据计算难度,剔除了大部分二值化验证码图像中的干扰点。即降噪[14]指的是删除图像中的干扰点,保留图像主体特征信息的过程。该文选用非局部均值降噪[15]的方法对二值化图像进行降噪处理。其处理结果如图5所示。

图5 降噪后的验证码
4 实验结果及分析
4.1 实验软硬件环境
硬件环境:Windows 7旗舰版。
软件环境:PyCharm 2018;Jupyter Notebook;Tesseract 5.0.0;Python 3;Pytorch。
4.2 数据集及预处理
数据样本来源:选取吉林某油田合同管理系统登录界面的验证码图片作为数据集。
数据样本类型及构成:数字与字母组合。
样本数量及划分:10 000张,按8∶2分为训练集和测试集。
实验数据、实验的软硬件环境准备就绪后,针对验证码数据集的识别,将对比光学字符识别引擎Tesseract与粒子群优化-卷积神经网络识别这两个方法所建立的验证码识别模型。
首先Tesseract是由HP实验室开发的一款OCR引擎。在不同的实际生产环境,定制不同引擎模板,通过对数据的不断训练来获取验证码图像的识别模型[2]。该实验利用其封装框架PyTesseract完成数据的预处理操作以及识别模型的建立。表1展示的是基于Tesseract识别合同管理登录系统验证码的准确率,表2展示的是数据集处理后不同类别的验证码识别效果。

表1 基于Tesseract的合同管理登录系统验证码识别效果

表2 不同类别的验证码识别效果
表1的实验结果表明,基于Tesseract的合同管理登录系统验证码识别模型在数据预处理后识别准确率有着较大的提升。其数据处理前验证码识别准率为11.3%,经过灰度化、二值化、去噪点数据预处理之后识别准确率可达60.5%。表2的实验表明,Tesseract对合同管理登录系统的纯数字验证码比非纯数字验证码有着较好的识别效果。可以看出无论是数据处理前还是处理后,验证码识别准确率都难以达到令人满意的结果,而且在Tesseract识别的过程中识别出乱码字符、空字符的情况也时有发生。故经过以上的实验,可以得出结论:基于Tesseract实现合同管理登录系统验证码识别的方案是不可行的。
4.3 参数设置及评价指标
利用PSO算法与CNN相结合的方法,找出卷积神经网络识别合同管理系统验证码最优的卷积核和网络层数。在构建验证码预测模型的过程中,基本参数设置如表3所示。

表3 PSO-CNN验证码预测模型基本参数设置
4.4 性能分析
经过168.5小时的模型训练后得到了优化后的验证码预测模型,其平均粒子群优化算法每迭代依次需要花费10小时左右。由于计算机本身的限制,随着程序运行时间的增加其模型每次迭代所花费的时间也在逐步增加。基于PSO-CNN所构建的验证码识别模型的识别效果如表4所示。

表4 基于PSO-CNN的验证码识别效果 %
从表4的实验结果可以看出,不同的卷积神经网络参数所建立的验证码预测模型其识别准确率有着较大的差异。文中初始验证码识别模型参数设置为5*5卷积核以及四层网络结构,即在没有使用寻优算法的情况下单纯利用卷积神经网络识别验证码的准确率为90.01%。经过寻优算法优化后所构建的验证码预测模型其验证码识别准确率最高可达96.26%。就卷积核而言,随着卷积核的增大验证码识别准确率由于无法提取更多的特征信息,导致识别准确率总体趋势是下降的。从网络层数方面来说,随着网络层数的增加识别准确率有了明显的提高,但是当网络层数为5时,其所构建的验证码识别模型出现了不同程度的过拟合状态,导致验证码识别准确率出现了不同程度的下降。基于以上分析,图6展示了Tesseract、CNN、PSO-CNN三种方式的识别准确率的对比结果。

图6 不同验证码识别技术准确率对比
5 结束语
针对传统的验证码识别技术识别粘连化、抽象化、含噪点的验证码识别效果差的情况,提出了一种PSO-CNN的验证码识别方案。该方案依托于卷积神经网络,在此基础之上利用粒子群优化算法找出解空间里面的最优模型参数。针对字母与数字混合的抽象复杂验证码,传统的Tesseract识别经常识别出乱码与空字符,其识别最优准确率仅为59.1%,通过文中方法所构建的验证码识别模型对于复杂验证码的识别最优准确率可达96.26%,相对于传统的验证码识别方法其识别准确率提高了37个百分点,大大提高了复杂验证码识别的准确率。实验结果表明,该方案在验证码识别领域提供了可靠的技术支持,业务构建优化后的图像预测模型提供了一种崭新的思路。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
集装箱化(2021年1期)2021-04-12
健康体检与管理(2021年10期)2021-01-03
经理人(2020年9期)2020-10-12
中国信息技术教育(2020年2期)2020-02-02
上海师范大学学报·自然科学版(2019年5期)2019-12-13
