
基于Sqoop 的异构环境数据迁移方法研究
2022-09-14 06:56:40王正迅
经济技术协作信息 2022年26期
◎王正迅
引言
基于传统关系型数据库的稳定性,目前还有很多企业将数据存储在关系型数据库中,但是关系型数据库的数据模型较简单,不适合表达复杂的数据关系,在处理大量数据、半结构化和非结构化数据,以及系统容错和系统扩展性方面受到了一定的限制,Hadoop 下的系列工具则有较大优势,早期由于工具的缺乏,Hadoop 集群与传统数据库之间的数据传输非常困难。基于这些方面的考虑,需要一个能在传统关系型数据库和Hadoop 之间进行数据迁移的工具,Sqoop 应运而生,Apache 提供的Sqoop 工具,能实现自动化数据迁移,依托于数据库相关的schema 描述信息,迁移的过程则使用MapReduce(后面都简写为MR)来进行。Sqoop 作为一个跨平台抽取和输出数据的工具,在关系型数据库(MySQL、O-ralce 等)和大数据平台(HDFS、Hive、HBase)之间常用。作为ETL 过程中重要的一环,加载作业的性能也是需要关注和优化的。本文将主要阐明如何在异构环境中使用Sqoop 方法进行数据迁移。
一、认识Sqoop
Sqoop 是一款用于在Hadoop 和关系型数据库之间高效迁移大批量数据的开源工具,类似于其他ETL 工具,Sqoop 使用元数据模型来判断数据类型,并在数据从数据源转移到Hadoop 时确保传输安全的数据处理,专为大数据批量传输设计,能够分割数据集并创建Maptask 任务来处理每个区块。以RDBMS 和HDFS 之间数据传输为例,Sqoop 借助于MR 导入和导出数据,用户可以轻松地以命令行模式从RDBMS 如MySQL 或 Oracle 中导入数据到 HDFS 中,通过 Hadoop 的MR 模型计算完之后,将结果导回RDBMS,Sqoop 能够自动完成整个过程中的大部分,并提供容错和并行化操作。
二、Sqoop 工作机制
Sqoop 本质就是迁移数据,用户在使用Sqoop 在异构环境间迁移数据时,Sqoop Client 提供了CLI 和浏览器两种方式提交请求,然后Sqoop Server 收到请求后,授权MR 执行。这个过程它高度依赖Hadoop 并行导入数据,充分利用了MR 的并行特点,以批处理的方式加快数据的传输,同时也借助MR 实现了容错。
1.从关系型数据库导入数据到hadoop 上。
Sqoop 把关系型数据库(以mysql 为例)的数据导人到HDFS 中,主要分为两步:一是得到元数据(mysql 数据库中的数据),二是提交Map。在这个过程中,sqoop 会通过jdbc来获取需要的数据库的元数据信息,例如:导入的表的列名,数据类型。这些数据库的数据类型会被映射成为java 的数据类型,根据这些信息,sqoop 会生成一个与表名相同的类,用来完成序列化工作,最后使用Java 类进行反序列化,MR并行写数据到Hadoop 中,从而保存表中的每一行记录。在导入数据时,如果不想取出全部数据,可以通过类似于where 的语句进行限制。
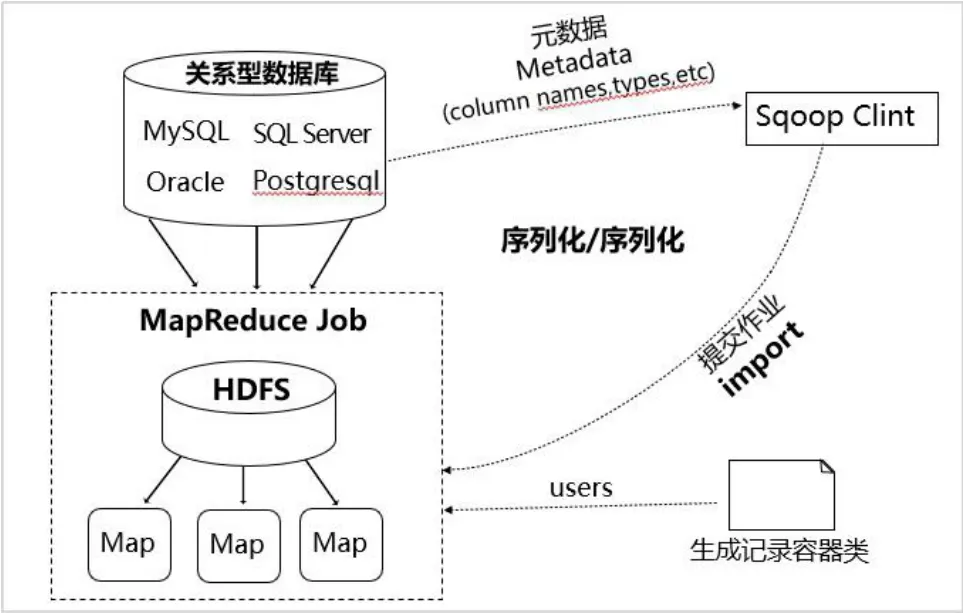
图1 Sqoop 数据导入机制
2.从Hadoop 上导出数据到关系型数据库。
Sqoop 的导出通常是将 HDFS、HBase、Hive 中的数据导出到关系型数据库中,关系型数据库中的表必须提前创建好。底层方面,同样是通过jdbc 读取HDFS/HBase/Hive 数据,生成Java 类(这个类主要作用是解析文本中的数据),用于序列化,最后export 程序启动,通过Java 类反序列化,同时启动多个Map 将相应值插入表中。
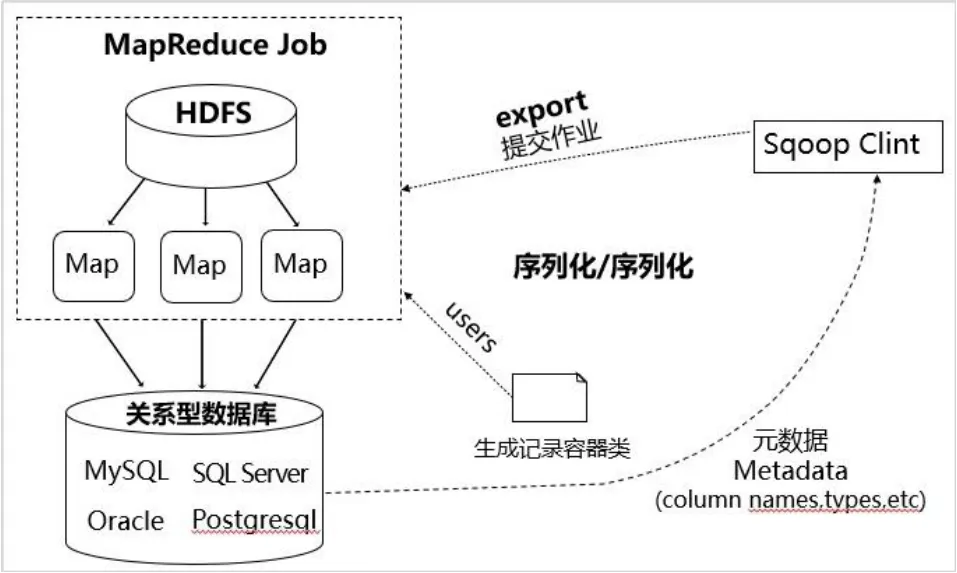
图2 Sqoop 数据导出机制
三、Sqoop 数据迁移方法介绍
1.Sqoop 数据导入。
数据导入分全量导入和增量导入。
(1)全量导入数据。全量数据导入就是一次性将所有需要导入的数据,从关系型数据库一次性地导入到HDFS 中(也可以是HBase、Hive 等)。全量导入形式使用场景为一次性离线分析场景。用sqoop import 命令,具体如下:

(2)导入数据库中的部分数据。导入部分数据可以在行与列的选取上添加参数完成,列选取上添加一个--columns参数,指定数据库中需要导入的列,如添加--columns id,name,age,sex;行选取上添加 --where 参数,增加 where 条件筛选满足条件的行,如--where "age >= 20" ;还可以使--query 参数查询筛选需要导入的数据,同时实现行、列的选取,如 --query"select id,name,age,sex from t_user_info where age>=20 and$CONDITIONS"。
(3)增量导入数据。在实际生产环境中,系统可能会定期从与业务相关的关系型数据库向Hadoop 导入数据,导入数据仓库后进行后续离线分析。数据量比较大,有的前期数据已经被用于项目分析了,我们此时不可能再将所有数据重新导一遍,此时我们就需要增量数据导入这一模式了。增量数据导入分两种,一是基于递增列的增量数据导入(Append方式)。二是基于时间列的增量数据导入(LastModified 方式)。在--incremental 参数后通过指定Append 方式或LastModified 方式。
2.Sqoop 数据导出。
export 是HDFS 里的文件导出到关系型数据库的工具,不能直接从hive、hbase 导出数据。如果要把hive 表数据导出到关系型数据库,需先把hive 表通过查询写入到一个暂存表,临时用文本格式,然后再从该暂存表目录里导出数据。
执行数据导出前,数据库中必须已经存在要导入的目标表,默认操作是从将文件中的数据使用INSERT 语句插入到表中,也可选择更新模式(Sqoop 将生成UPDATE 替换数据库中现有记录的语句)或调用模式(Sqoop 将为每条记录创建一个存储过程调用)。
默认情况下,sqoop export 将每行输入记录转换成一条INSERT 语句,添加到目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果INSERT 语句失败,导出过程将失败。此模式主要用于将记录导出到可以接收这些结果的空表中。通常用于全表数据导出。使用如下命令可完成:

更新模式导出,仅仅更新已存在的数据记录,不会插入新记录,该模式用于更新源表与目标表中数据的不一致,即在不一致时,将源表中的数据迁移至目标表(如MySQL、Oracle 等的目标表中),这种不一致是指一条记录中存在的不一致,比如HDFS 表和MySQL 中都有一个id=1 的记录,但是其中一个字段的取值不同,则该模式会将这种忽视差异。对于“你有我无”的记录则不做处理,通过指定update-key 并在—update-mode 参数后指定是updateonly 模式。调用模式导出,会更新已存在的数据记录,同时插入一个新记录,实质上是插入一个update+insert 的操作,同样是通过指定update-key 并在—update-mode 参数后指定是allowinsert模式。
四、Sqoop 常见问题及解决办法
Sqoop 作为一种重要的数据迁移工具,在使用过程中需要遵守数据库约束、数据库连接机制,考虑空值、并行度、分隔符等原因导致的传输列数和表的列数不一致等问题。
1.空值问题。
空值问题常见于Hive 与MySQL 数据迁移过程中发生。Hive 中的 Null 在底层是以“N”来存储,而 MySQL 中的 Null在底层就是Null,这就导致了两边进行数据迁移时存储不一致问题,Sqoop 要求在数据迁移的时候严格保证两端的数据格式、数据类型一致,否则会带来异常。
为了保证数据两端的一致性,数据迁移的过程中遇到null-string,null-non-string 数据都转化成指定的类型,通常指定成"N"。依赖自身参数在导入数据时采用--null-string“\N”和--null-non-string“\N”,在导出数据时采用--input-null-string“\N”和 --input-null-non-string“\N”两个参数,在使用这些参数过程中,需要正确地将值N 转义到\N。
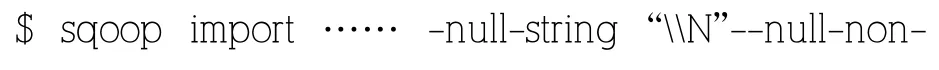

2.数据一致性问题。
(1)任务失败导致数据不一致。由于Sqoop 将导出过程分解为多个事务,因此失败的导出作业可能会导致将部分数据提交到数据库。在某些情况下,这可能会导致后续作业由于插入冲突而失败,或者在其他情况下导致重复数据。如这样一个场景:export 到 Mysql 时,使用 6个 Map 任务,过程中有3个任务失败,那此时MySQL 中存储了另外三个Map任务导入的数据,此时会生成一个不完整的报表数据。继续调试问题并最终将全部数据正确的导入MySQL,会再次生成一个报表数据,而这个报表数据与之前的报表数据是不一致,这在生产环境是不允许的。这种情况下,可以通过--staging-table 参数指定一个staging 表来克服这个问题,指定的这个staging 表在单个事务中,暂存数据,等到事务完全处理完毕再移动到目标表。为了使用暂存功能,必须在运行导出作业之前创建暂存表,该表必须在结构上与目标表相同,这个表应该在导出作业运行之前为空,所以需要--clear-staging-table 这个参数配合起来使用。

(2)分隔符问题导致数据不一致。Sqoop 默认字段与字段之间是用“,”分隔开,Hive 默认的列分隔符是 ^A(001),行与行之间的分隔符是“
”,当然,在创建这些表(包括MySQL表)的时候也可以自己指定分隔符。在数据迁移过程中,由于分隔符的不一致会导致数据迁移失败,由于导入的数据中有'
',hive 会认为一行已经结束,后面的数据被分割成下一行,也会导致数据不一致。这时可以使用--lines-terminated-by和--fields-terminated-by 这两个参数来自定义行分隔符和列分隔符进行解决。但是hive 只支持'
'作为行分隔符,所以在关系型数据库与Hive 进行数据迁移时,还需要加上--hive-delims-replacement
--hive-delims-replacement
--hive-drop-import-delims:将分隔符中的/0x01 和/r/n去掉
3.数据倾斜问题。
在生产环境中,由于数据量巨大,数据结构复杂,Sqoop导入数据报内存溢出以及抽数时间过长,日志显示有个别的reduce 执行时间过长,卡在99%那个位置,例如有25个Map 中有24个Map 是在20 秒内执行完成,只有1个Map用了6 分多钟,这种Map 分布不均匀,就是数据倾斜现象。导致数据倾斜的原因有可能是数据本身就不均匀,或是分隔符问题,或是数据类型不一致等。这时需要设置--split-by、--num-Mappers 和--split-Mappers 这三个参数。
在import 时,指定--split-by 参数,Sqoop 根据不同的split-by 参数值来进行切分,然后将切分出来的区域分配到不同Map 中。每个Map 中再处理数据库中获取的一行一行的值,写入到HDFS 中。split-by 根据不同的参数类型有不同的切分方法,最好使用较简单的int 型。
通过设置Map 的个数来提高吞吐量,-num-Mappers后面设置的Maptask 数目大于1 的话,那么-split-by 后面必须跟字段,因为-num-Mappers 后面要是1 的话,那么-split-Mappers 后面跟不跟字段都没有意义,因为,他只会启动一个Maptask 进行数据处理。一般来说数据量与Map 的数量是相关的,一般建议在500w 以下使4个Map 即可,如果数据量在500w 以上可以使用8个Map,Map 数量太多会对数据库增加运压力,造成其他场景使?性能降低。在使用并行度的时候需要了解主键的分布情况是否是有必要的。
五、结语
随着大数据、云计算、物联网的不断发展,信息系统产生的数据规模与日俱增,以Hadoop 平台为代表的海量数据处理平台通过对海量数据进行并行处理成为一种有效的解决方案,基于Sqoop 实现的在关系型数据库与Hadoop 平台之间进行数据迁移,它可以高效、可靠地完成数据传输任务,是数据分析处理及挖掘前的重要一环。本文从Sqoop 工作机制、迁移方法介绍、Sqoop 常见问题及解决办法等方面进行分析,解决了Sqoop 使用过程中的简单问题,在实际使用过程中,还需要结合项目实际需求对Sqoop 做更进一步的优化。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
数码世界(2020年5期)2020-06-23 00:14:36
财经(2017年2期)2017-03-10 14:35:35
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
图书馆建设(2015年10期)2015-02-13 03:48:27
新世纪图书馆(2014年7期)2014-09-19 12:20:40
图书馆建设(2014年3期)2014-02-12 15:41:35
