
基于交替训练融合模型的COVID-19的CT影像辅助诊断
2022-09-08 02:10孔锐庄峻贤梁冠烨
暨南大学学报(自然科学与医学版) 2022年4期
孔锐,庄峻贤,梁冠烨
(1.暨南大学 智能科学与工程学院,广东 珠海 519070;2.暨南大学 信息科学技术学院,广东 广州 510632)
2019年底开始新型冠状病毒肺炎(COVID-19)疫情在全球大规模暴发并危害着人类的健康,病毒检测必不可少[1],而CT检查为其主要辅助诊断手段。CT检查由于其便捷性、可重复性、阳性率高等优点,在COVID-19患者的影像学辅助检测中起到重要作用[2]。近年来,人工智能(AI)在医学各个领域发展迅猛,基于AI的CT影像辅助诊断系统具有重要临床意义,例如甲状腺结节CT诊断AI系统、肺结节良恶性疾病筛查等[3],而对COVID-19的CT辅助检测的AI方向探索仍然是当下研究的热点。
深度学习技术尤其是卷积神经网络在医学影像上的应用越来越广泛,基于AI的COVID-19的CT辅助检测,按照是否借助分割技术可以分为直接进行分类任务训练以及借助图像分割技术进行分类任务训练[4]。在借助图像分割技术的分类任务训练中,通常将图像分割作为预处理部分,Wang等[5]使用肺部分割模型3D UNet++对CT图像进行预处理,并对预处理图像进行随机翻转、平移、放大等数据增强,最后用ResNet-50模型对处理后的图像进行分类。Wang等[6]提出了一种专门为COVID-19设计的深度卷积神经网络COVID-Net,对包含13 870个病人的13 975张胸部X射线检查的COVIDx数据集进行三分类任务训练,对比VGG-19和Resnet-50的效果,发现在较少的模型参数和乘加累积操作数(multiplyaccumulate operations,MACs)的情况下COVIDNet具有更高的准确率。
有监督学习依赖高质量人工标注的标签信息,一方面,在医学领域中需要专业的人员去对训练样本进行标注,这需要耗费大量的时间和精力;另一方面,在训练集中样本数量较少的情况下,通过有监督学习训练的模型缺少泛化性。然而,自监督学习依赖的是样本数据来提供监督信息,并不依赖人工标注的标签信息,能够有效提高模型的泛化性[7]。自监督学习的其中一种方法是令网络学习到关于目标的一个良好的特征表示,最大化正负样本的距离,而且负样本的数量越多自监督学习的效果越好,譬如He等[8]提出动量对比(momentum contrast,MoCo)用于无监督表征学习,能很好地用于下游任务;Chen等[9]提出表征对比学习框架SimCLR,在特征表示和对比损失之间加入了非线性变换等使模型性能极大提升。
多任务学习(multi-task learning,MTL)中假设不同任务数据分布之间存在一定的相似性[10],在分类任务中引入相关任务(related task)训练模型,可以有效利用相关任务训练信号包含的领域特定信息来提高模型的泛化能力[11]。MTL有很多形式,如联合学习(joint learning),自主学习(learning to learn),借助辅助任务学习(learning with auxiliary tasks)等,这些只是其中一些别名[12]。本研究利用模型融合技术将MoCo[8,13]引入到借助辅助任务学习中并在此之上提出交替训练模式(alternate training mode,ALTM)算法。
1 MoCo算法原理
MoCo[8,13]是一种无监督方法,该方法编码器由两部分组成,分别是特征表示编码器fq和动量编码器fk。对一个训练样本分别进行两种不同的数据增强生成一对查询(query)样本xq和键(key)值样本xk。查询样本和键值样本分别通过特征表示编码器和动量编码器生成一对编码查询q=fq(xq)和编码键k=fk(xk)。特征表示编码器fq和动量编码器fk网络参数的更新方式有所不同(图1),θq和θk分别为fq和fk的参数,通过对比损失分别对比编码查询与作为负样本的字典的相似性和编码查询与作为正样本的编码键的相似性,并利用反向传播进行更新θq,θk在θq更新后通过动量跟随进行更新(其中m为动量系数,通常取0.999):

图1 MoCo更新过程Figure 1 The update process of MoCo

为了增加对比学习中负样本的个数,MoCo创建一个样本容量大并且编码键相差不大的字典用于训练特征表示编码器,字典是数据样本的动态序列。由于θk依靠动量跟随进行更新,且动量系数m接近于1,这种更新方式令字典在增加负样本个数的同时,字典中由同一样本产生的键值的变化相差不大。图2为字典Di:{k0,k1,……,kK}更新示意图,字典长度为K+1,简单起见一般设置为Batch大小的倍数。当一个Batch的键值样本通过动量编码器生成键值序列}后,字典Di淘汰最早一批长度为大bs的键值序列并添加新生成的键值序列组成字典Di+1:,其中bs为Batch大小。除此之外,MoCo还提出了shuffling BN等技巧[8],使得该方法能够很好地解决负样本特征由于模型更新导致的前后不一致问题,并有效增加负样本的个数。经过MoCo训练的模型能够很好地用于下游任务。

图2 MoCo动态序列Figure 2 The dynamic queue of MoCo
2 基于模型融合的交替训练模式
本文基于模型融合方法将MoCo[8,13]引入到借助辅助任务学习中,在有监督学习的过程中使分类任务受益于辅助任务。在此基础上,本文提出一种有利于该融合模型的训练模式:交替训练模式(alternate training mode,ALTM),并通过实验验证该算法在分类任务中的可行性。同时探索了ALTM中辅助任务在损失函数中的权重和字典的长度之间的关系。
2.1 融合模型
本研究提出的融合模型由两个DenseNet[14](以下简称Model0和Model1)组成,融合模型(图4)在两个DenseNet的原本结构(图3)DT Block i之间加入了注意力(attention)机制,超参数为λ。Model0和Model1在Combined DT Block 1前的相关层共享参数。
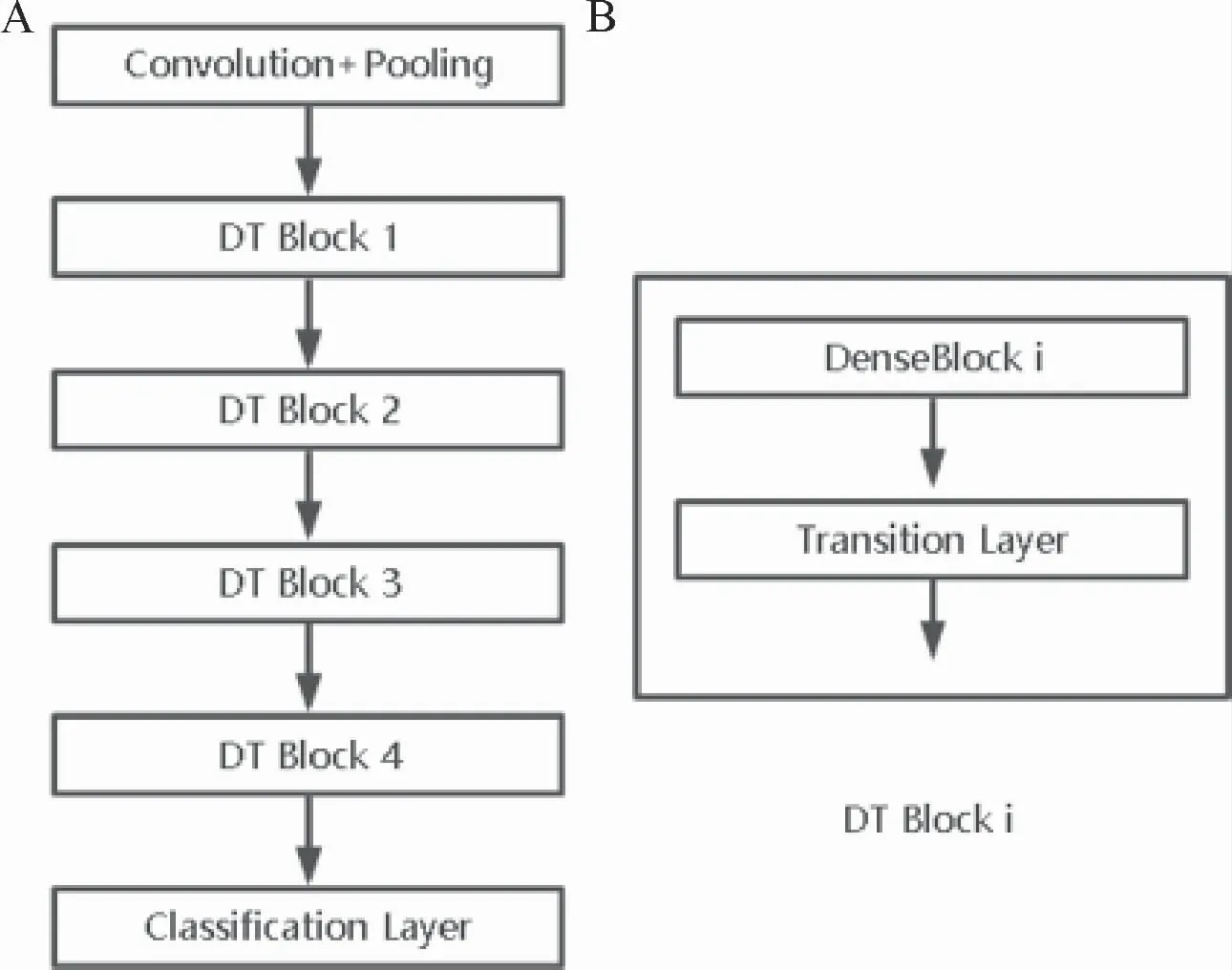
图3 Ensemble DenseNet结构Figure 3 The struction of Ensemble DenseNet

图4 Ensemble DenseNet结构Figure 4 The struction of Ensemble DenseNet
2.2 交替训练模式
基于融合模型的ALTM分为两个阶段。
(1)借助辅助任务学习阶段:图5为借助辅助任务学习阶段中,输入一批训练样本{I0,I1,…,Ibs-1}的示意图。与[8]的处理类似,本阶段Model1中参数θ1不具有梯度,参数的更新依靠动量跟随。一批训练样本分别进行两次不同的数据增广后得到查询样本和键值样本对并输入到融合模型中。

图5 借助辅助任务学习Figure 5 Learning with Auxiliary Tasks
该阶段的前向传播的步骤主要如下:查询样本通过 Model0的卷积池化层和融合模型Combined DT Block1~4得到查询样本的高层特征图,高层特征图通过Model0的分类层和特征表示线性层分别输出分类概率预测和查询样本的特征表示;而键值样本通过Model1的卷积池化层和DT Block1~4得到键值样本的高层特征图,最后通过Model1的特征表示线性层输出键值样本的特征表示。
该步骤的反向传播的步骤主要如下:对于查询样本的特征表示来说,键值样本的特征表示作为正样本而动态字典中储存的特征表示作为负样本,利用InfoNCE计算辅助任务损失。同时,根据Model1分类层输出的分类概率预测和查询样本的标签计算分类损失。最终计算多任务学习损失函数计算梯度对Model0的参数θ0进行更新,而Model1参数,依靠动量系数进行更新。最后,利用本次计算的键值样本特征表示更新动态字典。
本阶段为借助辅助任务学习,在进行学习分类任务的同时,希望融合模型中能够学习良好的特征表示。仿照MoCo v2[13]和SimCLR中的设计,在特征表示层前增加一层线性层优化网络的性能。本阶段的使用的多任务损失函数为(γ为辅助任务损失函数的权重):
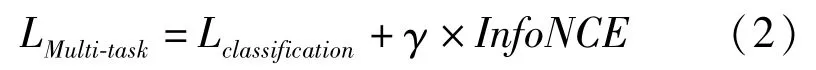
反向传播时,Model0的参数θ0依靠多任务损失函数(式1,γ>0)进行更新,而Model1的参数θ1依靠θ0和动量系数m进行更新:
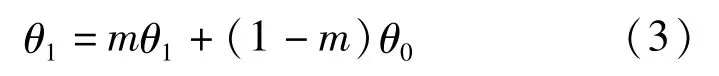
由于Model0和Model1在Combined DT Block 1前的相关层共享参数,在Model1参数进行更新时,这部分层参数不参与动量跟随更新,而是与Model1相关层参数保持参数共享。
(2)分类任务训练阶段:本阶段为分类任务学习,输入一批训练样本{I0,I1,…,Ibs-1},分别进行两次不同的数据增广后得到查询样本和键值样本,将查询样本输入到融合模型中,融合模型利用多任务损失函数(式1,γ=0)进行训练,而键值样本通过Model1的前向传播,在Model1的特征表示层输出键值样本的特征表示,最后利用键值样本的特征表示对动态字典进行更新。
为了避免Model1更新过快导致键值序列中的特征表示前后变化较大,一般在ALTM中,将序列长度定为upe倍的训练集大小,进行upe个epoch的多任务学习阶段后进行1个epoch的分类任务训练阶段,然后以这个顺序不断进行循环训练。显然,upe和γ的取值在ALTM中起着至关重要的作用。
3 实验与分析
本实验基于pytorch1.7cuda10.2进行,使用NVIDIA Corporation GP104GL[Tesla P4]内存为8G的GPU。评价指标选用机器学习常用评价指标:精确率(precision)、召回率(recall)、F1-score、准确率(accuracy)和曲线下面积(area under curve,AUC)。评价指标的计算如图6所示。交替训练中,Model0和Model1使用独立的Adam优化器,学习率为1e-4,学习率策略采用CosineAnnealingLR,T_max=10。训练参数设置:epoch=100,batch_size=16,分类损失函数采用交叉熵损失函数,动态字典长度为upe倍的训练集大小,动态字典初始化于MoCo相同,使用标准化后的标准正态分布的随机序列。

图6 评价指标Figure 6 Evaluation metrics
3.1 数据集与融合模型
本实验数据集采用COVID-CT-Dataset[15],训练集、验证集、测试集中样本个数分别为425、118、203(表1),包含两类样本(COVID 和NonCOVID)。训练样本来自从2020年1月19日到2020年3月25日在medRxic和bioRxic中关于COVID-19的预印本中的CT图像。COVID-CT数据集部分样本如图7所示,a~d为COVID样本,e~h为NonCOVID样本。受实验结果[16]的启发,实验选用两个 DenseNet169 构成融合DenseNet169(Ensemble DenseNet169,ED169)模型,由于ALTM算法需要融合模型中Model0和Model1参数初始化相同,实验中无论单一模型DenseNet169还是融合模型ED169中的Model0和Model1,均引入ImageNet预训练模型。

图7 COVID-CT数据集示例Figure 7 Example CT images from the COVID-CT-Dataset
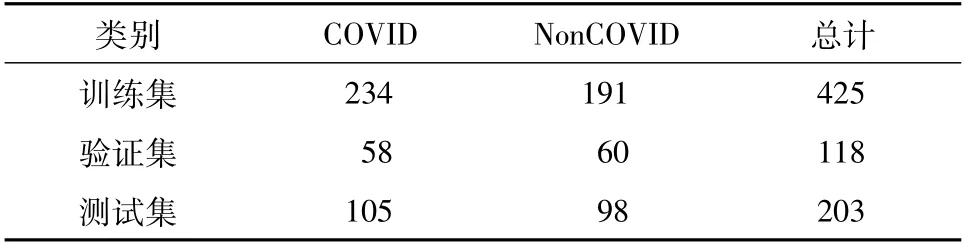
表1 COVID-CT数据集Table 1 COVID-CT-Dataset n
3.2 融合模型实验结果
表2结果显示,无论λ取值为多少,从5个评价指标的结果来看,融合模型ED169整体表现比DenseNet169更优。
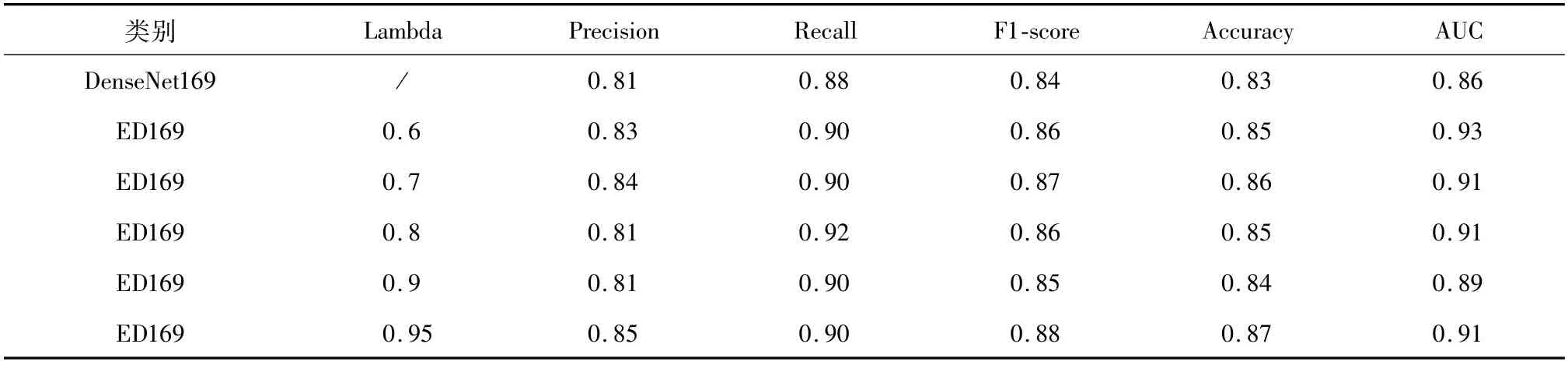
表2 融合模型训练结果Table 2 The result of Ensemble DenseNet169
融合模型虽然利用了参数共享方法,但是总体来看参数量大致为单模型的两倍,并且融合模型加入了注意力机制,组成更有效的结构,所以即使不使用ALTM时模型表现也比DenseNet169更优。
3.3 ALTM 实验结果
使用ALTM后的融合模型的性能和未使用ALTM的融合模型性能对比实验结果如表3所示,可见无论λ取值为多少,5个评价指标的结果大多数都取得一定程度上的提升,证明ALTM对融合模型各方面都有实质性的提升。

表3 ALTM 实验结果Table 3 The result of ensemble DenseNet169 trained by ALTM
融合模型由Model0和Model1构成,当λ越大时,Model0的对融合模型的影响越大。ALTM在ED169中有所提升,但是在λ=0.95时提升较小,这是由于Model0对融合模型的影响过大,从而削弱了ALTM的作用。此外,研究发现对于每个γ值来说,upe值较大时模型泛化能力有时候虽然不是最优,但是也有一定的提升,研究认为这得益于在表示学习时负样本个数的增加。同时,对于验证集来说,融合模型与单一模型相比有时候出现相差无几甚至有所下降的情况,这可能是由于数据集样本较少导致融合模型过拟合,采用ALTM算法后极大改善这种情况。
3.4 影响ALTM 的因素
针对每一个不同取值λ的融合模型ED169,在upe固定的情况下选取性能表现最佳的模型所对应的γ值。
为了进一步探讨超参数upe和γ对ALTM的影响,本阶段实验采取以下设置:
1)upe=1,2,3,4,5,6;
2)γ=0.01,0.1,0.2,0.3,0.4,0.5,0.6;
3)λ=0.5,0.6,0.7,0.8,0.9,0.95。
如图4所示,图中纵坐标为在λ为固定值,而upe取不同值时,训练性能最好的模型所对应的γ值。可以看出,无论λ取值为多少,结果呈中间高两边低的趋势。
在使用ALTM后,虽然融合模型中超参数λ不同导致融合模型最终的结果有所差异,但是可以看出λ影响的是模型本身的表现能力,对ALTM性能影响更重要的是upe和γ的取值关系。研究认为,当upe取值较小的时候,键值序列长度较小,负样本数目较少,特征学习任务的难度较小,所以γ值较小模型的性能表现会更佳。在键值序列中负样本的数目越多,负样本提供辅助分类任务的相关信息量就越大,越有利于模型进行分类任务的训练,所以当upe值变大时,适当提高γ值能提升融合模型ED169的泛化能力。当upe值较大的时候,键值序列长度较大,负样本数目较多,但是由于upe值和Model1更新次数息息相关,所以此时键值序列中负样本的特征表示与upe值较小时相比变化较大,特征学习任务的难度较大。如果此时γ值较大的话,会导致模型偏向于学习更复杂的特征表示,并不利于分类任务,所以理应选取一个较小的γ值。
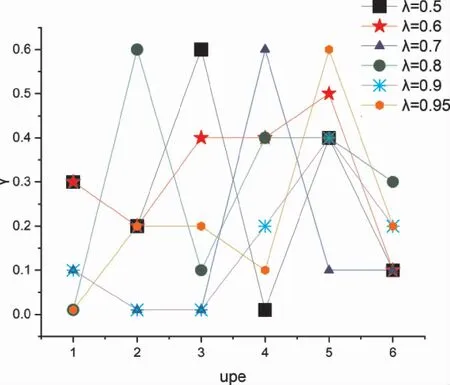
图8 upe和γ对ALTM的影响Figure 8 Effects of upe andγon ALTM
4 结果与讨论
本文在单GPU上利用并探究AI的方法对COVID-19的CT图像进行图像识别,并基于深度学习提出一种交替训练的融合模型。He等[16]运用MoCo对深度卷积神经网络DenseNet169在COVID-CT和LUNA 16的1000个样本组成的数据集上进行自监督学习,在COVID-CT数据集的测试集上准确率(Accuracy):0.86,F1:0.85,AUC:0.94。由于在小数据集上对深度学习模型进行训练容易导致模型过拟合,Loey M[17]等使用深度迁移学习模型的经典数据增强技术以及条件生成对抗网络(CGAN)生成更多的胸部CT图像,用ResNet50对COVID进行分类,模型在COVIDCT测试集上最好的分类表现:精确率(Precision):0.876,召回率(Precision):0.814,F1-score:0.844,准确率:0.829(指标由测试集TP,TN,FP,FN计算得)。本研究提出ALTM算法,融合模型ED169在COVID-CT数据集的测试集上的精确率:0.86,召回率:0.91,F1-score:0.89,准确率:0.88,AUC:0.92,与之前的相关研究相比,本研究提出的算法整体结果较优,能够良好地解决模型在小数据集上的过拟合问题,提升模型的泛化性能。
在多任务学习中,引入特征表示来增加分类任务中模型的泛化能力是分类任务中常用的方法,有多种损失函数来最大化正负样本之间的距离,但是如何选取负样本和负样本的个数一直是研究的重点。本研究结果显示,利用模型融合技术将MoCo引入到多任务学习中也能有效提高模型性能。本研究特别提出了一种适用于融合模型的训练方法ALTM,通过对比DenseNet169,ED169和ED169+ALTM 3种情况在COVID19-CT数据集上的实验,结果证明了ALTM的有效性。同时,对影响ALTM超参数之间的内在关系进行实验和分析,深度分析了ALTM对融合模型训练的影响。
本实验仍有不足之处,在融合模型上ED169仅为两个DenseNet169,各个部分进行加权平均,而在今后的研究中,可基于经典模型例如ResNet,DenseNet等构造出一个高效,分类能力强的融合模型结合ALTM。除此之外,COVID-CT数据集的样本个数较少,今后在扩大COVID-CT的训练样本个数的情况下来继续提高新型冠状病毒辅助检测能力。
作者贡献声明
孔锐:项目指导及负责人,指导论文写作与修改;庄峻贤:提出研究思路和框架,设计实验,撰写和修改论文;梁冠烨:统计数据,修改论文。
利益冲突声明
本研究未受到企业、公司等第三方资助,不存在潜在利益冲突。
猜你喜欢
小学阅读指南·低年级版(2019年11期)2019-07-01
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
小天使·一年级语数英综合(2017年11期)2017-12-05
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
数学学习与研究(2017年3期)2017-03-09
读者(2016年14期)2016-06-29
少儿科学周刊·少年版(2015年3期)2015-07-07
