
小训练样本下齿轮箱故障诊断:一种基于改进深度森林的方法
2022-09-07 01:53:36邵怡韦陈嘉宇林翠颖万程葛红娟石智龙
航空学报 2022年8期
邵怡韦,陈嘉宇,林翠颖,万程,葛红娟,2,石智龙
1. 南京航空航天大学 民航学院,南京 211106 2. 南京航空航天大学 民航飞行健康监测与智能维护重点实验室,南京 211106 3. 南京航空航天大学 电子信息工程学院,南京 211106 4. 北京飞机维修工程有限公司 杭州分部,杭州 310000
在航空领域,齿轮箱作为各类大型复杂装备的重要传动部件,广泛应用于大功质比、大减速比的机械传动系统中,其可靠性对保障装备稳定运行至关重要。然而,工作在复杂工况下的齿轮箱容易受到各类复杂载荷的影响,诸如,航空发动机的附件齿轮箱工作在高温、高压与高转速的恶劣环境中,受到离心载荷、气动载荷和热载荷等复杂交变载荷作用,容易发生各类故障。而在运行过程中发生故障将会导致高昂的维护成本,甚至引起重大安全事故。因此,实施有效的齿轮箱故障诊断是保障航空装备健康运行的关键技术。随着计算机技术与人工智能技术的不断发展,基于数据驱动的智能诊断技术应运而生,并已逐渐成为当前航空机械装备故障诊断与健康管理的重要一环。
然而,由于齿轮箱一般是由齿轮、轴承与轴等关键零件组成,其故障呈现出多种类混合故障的特点。相较于轴承的3类典型故障,齿轮箱故障包含多达7类故障模式。同时,齿轮箱故障往往包含两类以上零件的混合故障,诸如轴承内环与齿轮断齿混合故障、齿轮偏心与输出轴不平衡等混合故障。此外,实际工业采集的多种类混合故障振动信号具有较强的非平稳性,导致其可分性差。这些问题制约了基于少故障模式与单点故障开发的传统数据驱动智能诊断方法的有效应用。由于特征自提取与深度架构的优势,深度学习能够满足航空装备故障诊断的特征自适应提取要求,不仅减少了对专家经验和信号处理技术的依赖,而且降低了由人工设计提取特征引入的不确定性,被广泛应用于装备的智能诊断中。因此,基于深度学习的故障诊断方法凭借其强大的特征学习能力,是应对齿轮箱多种类混合故障诊断的有效途径,并已成为航空装备智能诊断的研究热点。
当前,基于深度学习的故障诊断研究主要集中在深度神经网络上。尽管此类方法在航空装备智能诊断中取得了较好的成果,但是其诊断性能依赖于大量高品质的训练样本。大多数基于深度神经网络的诊断方法是在大训练样本条件下开发和验证的。然而,由于标记成本高与故障数据采集难度大等问题,许多实际工业应用中仍然缺乏足够的标记数据,使得此类智能诊断方法必须面临小训练样本(训练-总体样本比例不超过50%)下的故障诊断。在此条件下进行模型训练时,过拟合问题严重影响诊断精度,即模型能够很好的分类和识别训练数据中的各类故障,却无法有效提取故障特征来识别测试数据中的各类故障。常用的解决方式是通过对超参数调优,例如增加网络层数和隐藏神经元个数等,从而达到理想的结果。然而,深度神经网络的超参数过多,其学习过程严重依赖于对参数的仔细调整,成倍增加了模型的训练时间。同时,不同超参数下训练的模型结构各不相同,其诊断性能差异较大。例如,同样使用卷积神经网络(Convolutional Neural Networks, CNN),但是由于卷积层结构等超参数的不同选择,实际上使用的是不同的学习模型。由于有太多几乎无限构型组合的干扰,不仅使得深度神经网络的训练十分棘手,而且还使其理论分析变得十分困难。综上,深度神经网络的性能依赖于超参数选择,使其调优过程类似于人工进行特征提取,本质上降低了深度学习模型的智能性。因此,如何解决深度学习模型中的过拟合问题,实现小训练样本下的准确诊断成为了领域内的研究热点。
为了解决这个问题,一种基于决策树的非神经网络深度学习方法——深度森林,应运而生。源于以下两个机制,该方法具有对训练数据量要求较低的特点:一方面,由于深度森林的基础特征提取器——随机森林,采用引导聚集(Bootstrap Aggregating,Bagging)策略对数据进行学习,使模型本身具备良好的抗过拟合特性。另一方面,该模型中的级联森林在层数扩展和验证时,采取的-折交叉验证方式,也是解决过拟合问题的重要手段。此外,该方法具有超参数少、模型受超参数的影响小以及可解释性强等优点,是当前解决小训练样本分类问题中有前途的深度学习方法。目前,深度森林已经广泛用于图像处理、时间序列预测等领域,并取得很好的研究成果。Xia等将深度森林应用于多源遥感数据的融合,将提出的方法应用于从日本多摩森林获得的数据集,并与其他方法进行比较,实验表明,深度森林可以比其他方法获得更好的分类效果,并且与深度神经网络相比,在超参数调整方面耗费了很少的时间,并且大大降低了计算的复杂度。随着深度森林模型研究的不断推进,研究人员发现在深度森林模型的数据传递与处理中,由于每一级的输入都是原始变换特征向量与级联森林生成的增强特征向量拼接生成的向量,且输入级联森林的向量必须经过一级一级的森林,会造成计算冗余并且严重影响运行效率。为了减轻该机制的影响,Shen等扩展了深度森林的理念,对决策树的节点做出概率路由决策,不仅增加了模型的灵活性,还可以为每棵树进行非贪婪优化,使得性能增加,并使模型复杂度大大降低。Fan等提出了一种基于小数据集分类的深度森林模型,将一些最主要特征的标准偏差构成在下一级传输的新特征,该方法在五个数据集上进行验证,实验表明与小数据集的其他分类模型相比,该方法具有更好的分类效果。Ding等提出了一种基于多粒度扫描的加权级联森林,提出了一种加权策略来计算级联结构中每个森林的权重而无需额外的计算成本,从而提高了模型的整体性能。
在旋转机械故障诊断领域中, Liu等将深度森林应用在水轮机的智能故障诊断中,提出了一种基于深度森林的水轮机智能故障诊断方法,对噪声具有很好的鲁棒性。Zhang等提出了一种基于深度森林的铁路道岔系统故障诊断新方法,并且在数据有限的情况下验证了该方法的性能。Hu等提出了一种结合深度玻尔兹曼机和深度森林的故障诊断方法,使用深度玻尔兹曼机将要处理的数据的所有特征转换为二进制再输入深度森林中,能有效进行基于大数据的工业故障诊断。当前,深度森林模型在航空装备智能诊断中的研究较少。作为一种非神经网络的深度学习模型,它具有强大的特征学习能力,是解决小训练样本下多种类混合故障诊断难题的有效手段。但是,为表达齿轮箱的复杂故障状态,在智能诊断中一个振动数据样本往往包含超过1 000个数据点,甚至超过4 000个数据点。深度森林在处理这类长数据类型时,由于计算复杂度的问题,内存消耗和特征冗余严重,极大地影响了深度森林的诊断效率。同时,在级联森林结构中,高维变换特征向量在与低维增强特征向量拼接时,巨大的维度差异引发特征淹没现象,使得模型的特征学习不完善,降低深度森林的诊断性能。因此,如何增强模型内数据特征代表性与运行效率问题,是实现小训练样本下齿轮箱多种类混合故障准确诊断的关键主题。
主成分分析算法(Principal Component Analysis, PCA)是一种常见的多元统计分析算法,也是模式识别中常用的一种线性映射方法,是基于数字信号二阶统计特性的分析方法。该方法将多个相关变量简化为几个不相关变量的线性组合,在保证数据信息丢失最少的原则下,经线性变换和舍弃一部分信息,以少数新的变量取代原来的多维变量,从而实现对高维变量空间到低维空间的映射。主成分分析算法的应用最早是在机器学习中利用其良好的降维能力,将多维特征降维到少数几维,进行数据的可视化处理。但由于主成分分析算法在模式识别的特征提取研究中展现出的优秀性能,其特征提取机制可以避免由于人工设计特征提取带来的不确定性,越来越多的研究学者将主成分分析算法应用于故障诊断的研究中。Yan等提出了一种基于PCA的故障特征提取方法,用PCA从高维故障数据中提取有效的低维故障特征来进行发电机的故障诊断。Berbache等采用贡献图来计算所有过程变量对故障检测统计量的贡献,然后用主成分分析算法进行独立潜在变量提取,建立多种类型的监视统计信息以增强故障检测能力。Cartocci等利用主成分分析算法作为过程监控工具,并提出了一种具有时间相关性的主成分分析算法,提取出与事件相关的重要特征,实现实时的故障诊断。
针对深度森林在齿轮箱故障诊断中的缺陷,利用上述主成分分析算法在特征提取上的优势,分析深度森林中多粒度扫描与级联森林的数据处理与传递机制,明确特征冗余问题,设计基于主成分分析算法特征提取的深度森林模型,将主成分分析模型与深度森林的级联森林部分进行级联集成,提出了一种基于改进深度森林的齿轮箱故障诊断方法,实现小训练样本下高效准确的故障诊断。通过开展实验案例分析,与其他基于深度学习的齿轮箱故障诊断方法进行对比,验证所提方法的有效性与优越性,为保障航空装备的可靠持续适航提供技术支持。
1 深度森林
深度森林包括多粒度扫描和级联森林两个部分。一方面,多粒度扫描通过不同采样窗口增强深度森林的特征表达能力。另一方面,级联森林是一个具有层叠结构的随机森林团,使得深度森林具有表征学习的能力。
1.1 多粒度扫描结构
多粒度扫描框架如图1所示,滑动窗口用于扫描原始特征。假设一个数据样本有400个原始特征,并使用100个特征大小的窗口,对于序列数据,将通过滑动一个窗口来生成100维的特征向量,在步长为1的情况下,总共产生301个特征向量。经过窗口扫描生成的类向量将输入随机森林和完全随机森林生成变换特征向量。如图1所示,假设是个3分类问题,并使用100维的窗口。每个森林将会产生301个3维类向量,最后对两个森林产生的类向量进行拼接,输出对应于原始400维特征向量的1 806维变换特征向量。

图1 多粒度扫描流程Fig.1 Process of multi-grained scanning
为了提高模型特征多样性,多粒度扫描通常使用多个不同的窗口对样本进行多尺度采样,生成尺度不一的特征向量,从而获得更多的样本信息。经过实验对比验证,深度森林模型规定了默认多粒度扫描结构参数,对于具有维特征的原始数据,将使用大小分别为16、8和4的特征窗口进行扫描,在保证生成的样本的多样性的情况下,使计算效率最大化。
1.2 级联森林结构
级联森林结构框架如图2所示,级联森林的每一层级都由若干个随机森林组成。每个森林都包含若干个决策树,每个决策树都输出一个以类向量为形式的结果,然后对每个决策树的输出类向量结果取均值,假设是个3分类问题,则生成一个3维类向量,即为每个随机森林的最终输出结果。然后再对每一级中所有森林决策出的3维类向量取均值,最后取最大值对应的类别作为预测结果,并输出一个3维类向量。每一级输出的3维类向量会作为增强特征向量,与多粒度扫描输出的变换特征向量叠加,并作为下一级的输入。

图2 级联森林结构Fig.2 Structure of cascade forest
考虑到深度结构常常有过拟合问题,每个森林产生的类向量都是经过K-折交叉验证的。具体来说,每个实例将被用作训练数据-1次,生成-1个类向量,然后对其进行平均,以生成最终类向量作为下一级级联的增强特征。扩展一个新的级联层之后,整个级联的性能将在验证集上进行估计,如果没有显著的性能增益,则训练过程将终止,因此,级联森林的级数将自动确定。深度森林能够通过自动确定深度结构的复杂度来适应不同大小的数据集,这使得它与大多数模型复杂度固定的深度神经网络相比,不仅仅局限于大规模的训练数据。
1.3 深度森林结构
图1和图2分别展示深度森林的多粒度扫描流程和级联森林结构。假设原始输入包含400个原始特征,并在多粒度扫描中使用3个不同大小的窗口。对于个训练样本,100个特征的窗口将生成包含301×个100维训练样本的数据集。这些数据将用于训练1个随机森林和1个完全随机森林,每个森林包含若干棵树。如果要预测3个类别,则将获得1个1 806维的变换特征向量,如1.1节所述,转换后的变换特征向量将用来训练第一级级联森林。
类似地,大小为200维和300维的滑动窗口将分别为每个原始训练样本生成1个1 206维和606维的变换特征向量。将200维和300维窗口转换后的变换特征向量与每一级级联森林的上一级生成的类向量结合,分别训练第二级和第三级级联森林,其中级联森林中的每一级由若干个随机森林组成,每一级对应一个扫描粒度,如图2所示。综上所述,给定一个测试实例,通过多粒度扫描得到其对应的变换特征向量,然后通过级联森林训练直到验证性能收敛。最后的预测将通过在最后一级聚合4个3维类向量,并取聚合值最大的类来获得。
2 主成分分析
PCA是应用最广泛的特征提取方法之一,它是一种统计学方法,在信号处理、模式识别、数字图像处理、故障诊断等领域已经得到了广泛的应用。

将数据集中心化,即分别求出每个特征的平均值:

(1)
式中:为第维特征在个样本上的平均值;为数据集中第个样本的第维特征值。
然后对于所有的样例,都减去对应的均值,得到中心化后的数据集矩阵:

(2)
计算中心化后的数据集矩阵的协方差矩阵:

(3)
用奇异值分解(Singular Value Decomposition,SVD)的方法求出协方差矩阵的特征值及其对应的特征向量:
=
(4)
式中:为×的方阵,内部向量是正交的,且称为左奇异矩阵;为×的实对角矩阵,称为奇异值矩阵,对角线上的元素称为奇异值;为×的矩阵,里面的向量也是正交的,称为右奇异矩阵。
对特征值从大到小排序,选择其中最大的个,然后将其对应的个特征向量分别作为行向量组成特征向量矩阵。
将原始数据转换到个特征向量构建的新空间中,得到经PCA处理后具有维特征的数据集:
=
(5)
3 基于改进深度森林的故障诊断方法设计
3.1 改进的深度森林模型原理
3.1.1 基于PCA特征提取的深度森林模型
故障诊断作为一个分类问题,级联森林的结果为正常和故障的概率,每个森林中属于正常的概率和属于故障的概率之和为1,即级联森林生成的增强特征向量是线性相关的,因此,直接将级联森林生成的增强特征向量聚合到原始变换特征向量作为下一级的输入特征向量会造成特征向量的冗余,增加算法的空间复杂度,降低算法的运行效率。并且原始变换特征向量的维数远远大于级联森林生成的增强特征向量,而随机森林学习特征采用的是Bagging策略,即对样本特征进行放回采样学习,会在一定程度上造成对级联森林生成的增强特征向量的特征掩盖,导致模型甚至没有学习到增强特征向量,从而降低算法的精度,使得基于深度森林的齿轮箱故障诊断方法往往无法发挥深度森林的全部优势。
针对上述问题,将PCA模型与级联森林的每一级进行集成,提出了一种基于PCA特征提取的深度森林模型,如图3所示,其中“RF”为随机森林,“ERF”为完全随机森林。PCA凭借其优秀的特征提取能力,广泛应用于各类机械的故障诊断研究中,常常与支持向量机、神经网络等非统计故障诊断数据驱动方法联合使用。PCA可以有效的解决齿轮箱故障诊断中的两个技术难点,即减少故障特征模式中故障特征的个数以及克服故障特征的多重共线性带来的不良影响。将PCA与级联森林进行级联集成,对级联森林的每一级输入进行相应的特征提取,可以很好的解决深度森林在处理具有长特性的单样本数据时的特征冗余、算法运行效率低等问题,发挥深度森林的全部优势。

图3 改进级联森林的结构Fig.3 Structure of improved cascade forest
基于PCA特征提取的深度森林模型将级联森林的每一级与PCA进行集成,即各个粒度的原始变换特征向量将经过PCA的特征提取再输入下一级级联森林。假设有400维原始特征,经过多窗口的多粒度扫描得到了对应原始特征向量的1 806维、1 206维和606维的变换特征向量。针对如此高维度的原始变换特征向量,在级联森林中,首先将三部分原始变换特征向量进行拼接,为了与深度森林的工作原理更类似,再将其与经过PCA特征提取的第1部分原始变换特征向量进行拼接,输入4个随机森林中。随机森林将输出4×3维的增强特征向量,将其再与经过PCA特征提取的第1部分原始变换特征向量进行拼接,用于训练下一级级联森林。第2部分、第3部分经过PCA特征提取的原始变换特征向量与上一级生成的增强特征向量相结合,分别训练第2级和第3级级联森林。此过程将重复,在每扩展一个新的级联层后,整个级联的性能将在K-折交叉验证的每个验证集上估计,取整个级联在所有K-折交叉验证的验证集上的诊断精度的平均值作为整体诊断精度,如果整体诊断精度与上一级相比没有增益,则验证性能收敛,训练过程将终止。
改进后的深度森林通过对每一级的输入原始变换特征向量进行PCA特征提取,再与前一级输出的增强特征向量进行拼接,可以解决原始深度森林模型存在的特征冗余问题,并且与上一级输出类向量拼接的原始变换特征向量维数减少,改善了原始特征向量一定程度上遮盖增强特征向量特征的问题,提高了模型的诊断精度。
3.1.2 PCA的最优主成分个数选择
PCA的原理是为了将数据从维降低到维,需要找到个向量,即个主成分,用于投影原始数据,使得投影误差最小:

(6)
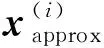
在上述原理下,通过绘制降维后各成分的方差之和随着主成分个数的变化而变化的曲线,选取最优主成分个数。实际应用中,通常选择能使误差小于0.01(99%的信息都被保留)的主成分个数。假设原始数据包含1 024维的故障特征,经过计算不同降维维度下的投影误差得到如图4所示的曲线图,可以看到,当方差和约为99%时,即降维后的特征保留了原始维特征99%的信息,的取值约为280,这样就完成了1 024维特征数据的PCA最优主成分个数选取。在实际应用程序中,可以直接在程序中指定需要保留的方差和99%,获取相应的最优主成分个数,避免因为人工带来的不确定性。
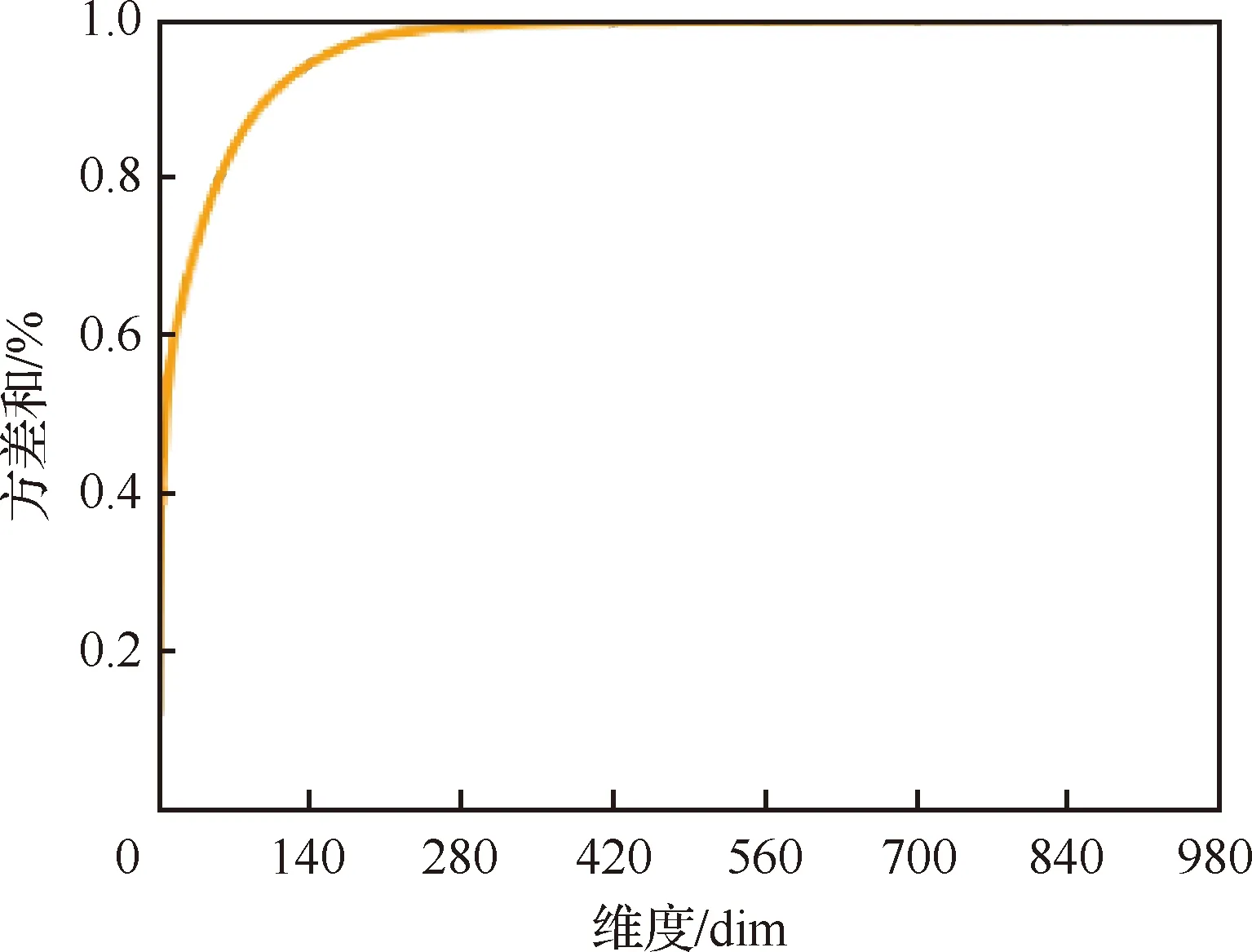
图4 方差和与主成分个数关系曲线Fig.4 Curve of relationship between the sum of variances and the number of principal components
3.2 基于改进深度森林的齿轮箱故障诊断方法
根据基于PCA特征提取的深度森林模型的工作流程,基于改进深度森林的齿轮箱故障诊断方法框架如图5所示。

图5 基于改进深度森林的齿轮箱故障诊断方法框架Fig.5 Framework of gearbox fault diagnosis method based on improved deep forest
多粒度扫描
首先采集一维振动信号,获得故障特征维数为维的故障数据集,并分解获得包含训练数据和测试数据的数据集。再将训练数据输入多粒度扫描模型。多粒度扫描部分对具有维故障特征的原始一维时间序列进行多窗口的扫描,并通过随机森林进行特征变换,最后对变换特征向量进行拼接,获得高维度的变换特征向量。
PCA特征提取
多粒度扫描输出的高维度变换特征向量输入级联森林之前先进行数据归一化、PCA最优主成分个数选取,再根据SVD选取最优主成分,最后进行特征空间转换获取降维后的变换特征向量。
基于PCA的级联森林扩展
步骤2中PCA提取的特征将与原始变换特征向量拼接输入级联森林的第一级进行决策,之后级联森林的每一级的输出结果将与经过PCA特征提取的各粒度变换特征向量拼接输入下一级的级联森林,依此类推。
故障诊断性能测试
级联森林每生长一级都要使用-折交叉验证对其诊断性能进行测试,若性能不收敛则回到步骤二开始进行新一级级联森林的生长,直到诊断性能收敛,级联森林停止生长。再将测试数据输入训练好的模型中,进行分类预测并输出诊断结果。
改进的深度森林通过将PCA模型与级联森林的每一级进行集成,在深度森林生长的过程中,对每一级输入的原始变换特征向量进行特征提取,可以有效地解决原始深度森林因为每一级级联森林都输入高维变换特征向量而造成的特征掩盖和特征冗余问题,从而提高深度森林的诊断精度。并且PCA通过对高维变换特征向量进行特征提取,可以有效的解决原始故障特征的多重共线性对随机森林带来的影响,在对深度森林模型本身进行改善的情况下,减轻原始故障特征因为多重共线性对齿轮箱故障诊断带来的影响,从而提高齿轮箱故障诊断的精度。
4 实验分析与讨论
4.1 实验数据
如表1所示,数据来源于2009年PHM数据挑战赛。数据采集自一个二级标准圆柱直齿轮减速器。减速器包括输入轴、惰轮轴和输出轴。一级减速比为1.5,二级减速比为1.667。数据采集采用的输入轴转速为30 Hz。采样的频率为66.7 kHz,采样时间为4 s,共采集了8种健康状态的振动信号。在本次实验中,数据集包含如表1所示8类齿轮箱的健康状态,8类健康状态包括正常状态以及7类故障状态,其中7类故障状态为齿轮、轴承、轴等零件的混合故障,如健康状态2为32齿齿轮碎裂故障与48齿齿轮偏心的混合故障,具有混合故障和多种故障模式的特点。数据集共4 000个 样本,即每类状态包含500个样本,每个样本长度为1 024。

表1 两级直齿轮减速器健康状态Table 1 Health status of two stage spur gear reducer
4.2 消融实验
消融实验将对基于原始深度森林的齿轮箱故障诊断方法和基于改进深度森林的齿轮箱故障诊断方法进行对比,探究将PCA特征提取与级联森林进行集成的部分对基于原始深度森林的齿轮箱故障诊断方法改进的必要性和有效性。由于每个故障样本的样本长度为1 024,即原始特征维数为1 024维,因此选取多粒度扫描窗口大小分别为64维、128维和256维。多粒度扫描结构的随机森林数量为2,每个随机森林的决策树数量为10。级联森林结构的随机森林数量为4,每个随机森林的决策树数量为100。本文实验中的原始深度森林和改进深度森林的结构参数设置均为上述值。
实验分别在训练-总数据比例为10%、20%、30%、40%、50%、60%和70%的情况下对两种齿轮箱故障诊断方法进行实验,得到的结果如图6、图7和图8所示。图6中展示了7种训练-总数据比例下两种方法的诊断精度对比。10%和50%的训练-总数据比例对于一个齿轮箱故障诊断问题来说,无疑是一个小训练样本的问题。从图6中可以看出,在50%的训练-总数据比例下,基于改进深度森林的齿轮箱故障诊断方法的诊断精度为97.3%,相对于基于原始深度森林的齿轮箱故障诊断方法的95.15%的诊断精度有2.15%的提升。并且在10%的训练-总数据比例下,如此小的训练集样本往往使得齿轮箱的故障诊断难以展开,因此可以看到在此条件下的基于原始深度森林的齿轮箱故障诊断方法的诊断精度为76.36%,难以满足一般的齿轮箱故障诊断的需求。而在如此小的训练集样本条件下,本文提出的方法仍然可以达到80%以上的诊断精度。结合以上分析,可以得出结论,本文方法在小训练样本条件下可以很好的提升原始深度森林的诊断精度,并且训练集比例越小,提升的空间越大。

图6 10%~70%训练-总数据比例下基于改进深度森林和原始深度森林的诊断方法的诊断精度对比Fig.6 Comparison of diagnosis accuracy between methods based on improved deep forest and original deep forest with 10%-70% training-total dataset ratio
图6中,当训练-总数据比例为70%时,已经达到实际应用中齿轮箱故障诊断的训练集比例上限,基于原始深度森林的齿轮箱故障诊断方法的诊断精度达到98.17%,在如此高的诊断精度下,本文提出的改进深度森林方法仍然将方法的诊断精度提升了1.33%,达到99.5%的诊断精度。可以看出,即使在训练集比例较大的情况下,本文的方法也能一定程度提升原始深度森林的诊断精度。并且可以从图6中看出,在训练集比例减小的情况下,基于改进深度森林的齿轮箱故障诊断方法相对于基于原始深度森林的方法可以保持更稳定的诊断性能。
图7和图8是2类故障诊断方法在50%训练-总数据比例条件下的混淆矩阵。其中,“Predicted labels”是预测的健康状态类别,“True labels”是实际的健康状态类别,图中0~7分别表示表1中第1~8类健康状态。可以看到基于改进深度森林的齿轮箱故障诊断方法对每一类健康状态的诊断精度均高于基于原始深度森林的齿轮箱故障诊断方法,诊断性能更优越。

图7 50%训练-总数据比例下基于改进深度森林的齿轮箱故障诊断方法的混淆矩阵Fig.7 Confusion matrix of gearbox fault diagnosis method based on improved deep forest with 50% training-total dataset ratio

图8 50%训练-总数据比例下基于原始深度森林的齿轮箱故障诊断方法的混淆矩阵Fig.8 Confusion matrix of gearbox fault diagnosis method based on original deep forest with 50% training-total dataset ratio
综上所述,基于改进深度森林的齿轮箱故障诊断方法相比基于原始深度森林的齿轮箱故障诊断方法在各个训练集比例、各个健康状态下都有更高的诊断精度,因此可以得出结论,将PCA特征提取与级联森林进行级联集成可以有效解决原始深度森林特征冗余、特征掩盖的缺点,并且可以改善齿轮箱故障诊断因为故障特征的多重共线性带来的影响,具有有效性和必要性。
为了对比基于PCA特征提取的改进深度森林模型与原始深度森林的空间复杂度,通过监控两个模型运行过程中的CPU占用内存值,选取运行过程中的一部分进行对比,如图9所示。可以看到改进的深度森林模型的占用CPU内存更少。验证了PCA特征提取与级联森林的集成部分在空间复杂度上对于原始深度森林改进的有效性。
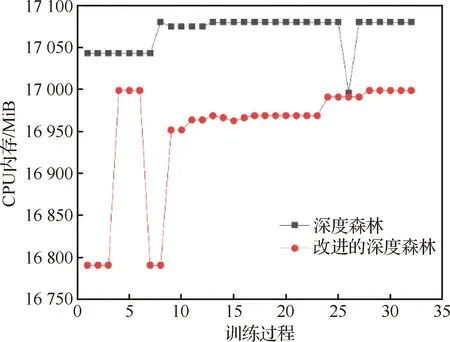
图9 基于改进深度森林和原始深度森林的齿轮箱故障诊断方法的运行CPU占用内存值对比Fig.9 Comparison of CPU memory consumption between gearbox fault diagnosis method based on improved deep forest and original deep forest
4.3 不同特征提取方法对比
特征提取是故障诊断模式识别中的重要技术,特征提取通过特征之间的关系得到新的特征,改变原来的特征空间。常用的特征提取方法包括PCA、线性判别分析(Linear Discriminant Analysis,LDA)、t-分布领域嵌入 (t-distributed Stochastic Neighbor Embedding,t-SNE)、核主成分分析(Kernel Principal Components Analysis,K-PCA)等。为了验证本文选用PCA作为级联森林的集成算法的优势,将分别与基于LDA、t-SNE、K-PCA与级联森林进行集成的模型进行对比。实验采用的训练-总数据比例为50%。
实验的诊断结果如图10所示,可以看到基于t-SNE改进的深度森林方法是4种方法中诊断精度最低的,基于LDA改进的深度森林方法与本文方法的诊断精度接近,但是在算法的运行过程中,发现基于LDA改进的深度森林方法在每一级LDA的特征提取步骤时需要花费近一个小时的时间,不能满足齿轮箱故障诊断的实时性,而PCA进行特征提取只需要几秒的时间,能满足齿轮箱故障诊断在实际应用中对于实时性的要求。K-PCA是PCA的一个改进版,它将非线性可分的数据转换到一个适合对其进行线性分类的新的低维空间上。可以看到,在齿轮箱故障诊断问题中,基于K-PCA的改进深度森林方法的诊断精度与基于PCA 的改进深度森林的方法诊断精度接近,但K-PCA相对于PCA来说,需要选择核函数的类型以及设置相应的参数,比PCA具有更多的参数需要选择。然而在输入数据具有多重共线性且无约束条件可利用时,往往对参数难以抉择。基于深度森林具有少超参数的特性,以及二者的诊断精度接近,PCA无疑是比K-PCA更优的选择。

图10 基于4种特征提取方法改进的深度森林的 诊断精度对比Fig.10 Comparison of diagnosis accuracy of improved deep forest based on four feature extraction methods
4.4 小训练样本下与主流深度学习方法对比
为了验证本文方法在小训练样本下的优越性,与基于目前主流深度学习方法的齿轮箱故障诊断方法进行比较,包括:卷积神经网络和长短期记忆网络(Long Short-Term Memory Networks,LSTM)。CNN作为目前最流行的深度神经网络,凭借其强大的容错能力、并行处理能力和自学习能力,广泛用于机械装备的故障诊断研究中。LSTM作为循环神经网络(Recurrent Neural Networks,RNN)的重要改型,克服了RNN诸多缺点,如梯度消失问题,凭借其全局化处理能力和门机制,处理时间序列等一维序列数据时有着一定的优势,在机械装备的故障诊断研究中也有着广泛的应用。实验中采用试错法的参数选择方法,并结合CNN和LSTM参数选择的一般规律选择模型参数。其中, CNN模型深度为11层,Dropout率为0.5,优化器为adam,初始化学习率为0.001,epoch为60,batch_size为64。LSTM模型深度为2层,隐藏神经元数为128,层与层之间Dropout率为0.25,优化器为adam,初始化学习率为0.001,epoch为50,batch_size为64。由于深度森林采用K-折交叉验证的方法防止过拟合,因此本实验的CNN模型和LSTM模型在训练过程中也采用K-折交叉验证法,并且设置的取值为5。实验分别在训练-总数据比例为10%、20%、30%、40%、50%、60%和70%的情况下对3种齿轮箱故障诊断方法进行实验,得到结果如图11所示。

图11 10%~70%训练-总数据比例下3种不同齿轮箱故障诊断方法的诊断精度对比Fig.11 Comparison of diagnosis accuracy between three gearbox fault diagnosis methods with 10%-70% training-total dataset ratio
可以看到在各个训练-总数据比例下,本文方法诊断性能均优于基于CNN和LSTM的齿轮箱故障诊断方法。基于LSTM的齿轮箱故障诊断方法的诊断性能较差,且在训练-总数据比为70%的情况下诊断精度仍然不超过90%,这反映了具有多种类混合故障特点的齿轮箱故障诊断确实具有一定的难度。并且可以从图11中观察到,相较于训练-总数据比例较大的情况下,当训练-总数据比例不超过50%时,即小训练样本条件下,本文方法的诊断精度与其他2种方法的差距更大。这符合深度神经网络的性能依赖于大量训练数据的理论特点。而且当训练样本数量减少的时候,3类方法的诊断精度都有所下降。然而,本文方法在训练样本减少的情况下,诊断性能的下降幅度远低于其它两种深度学习方法。并且其它两种方法在训练数据量小的情况下,呈现训练数据量越小,下降幅度越大的趋势。验证了本文方法在小训练样本下诊断的稳定性与优越性。
4.5 与不同齿轮箱故障诊断方法对比
为了验证本文方法的优越性,在2009年PHM挑战赛的数据集上,与使用该数据集验证的前沿故障诊断模型的诊断性能进行对比,包括:域自适应卷积神经网络(Domain Adaptive Convolutional Neural Networks,DACNN)、深度卷积神经网络(Deep Convolutional Neural Networks,DCNN)、傅里叶变换深度卷积神经网络(Fourier-Deep Convolutional Neural Networks,Fourier-DCNN)、深度卷积组合模型(Combined-Deep Convolutional Neural Networks,Combined-DCNN)、二维卷积神经网络(2-Dimensional Convolutional Neural Networks,2DCNN)。不同模型的诊断精度对比见表2,表中包含了该模型在研究中诊断的健康状态数量、训练样本数量和诊断精度。

表2 不同诊断方法与本文方法诊断性能对比
从表2分析得出,在诊断相同8种健康状态的情况下,由于齿轮箱故障具有多种类混合故障的特点,给诊断带来了难度。因此,当使用的训练样本数量分别为720、780和250时,Fourier-DCNN、Combined-DCNN、2DCNN模型的诊断精度分别为88.61%、91.15%和85.1%。而本文提出的方法,在训练样本为250的条件下,可以达到97.3%的诊断精度,诊断性能优于其余模型。在诊断6种健康状态的模型中,两种模型的诊断精度为99.33%和91.21%,训练样本数量分别为400和800。将本文方法与诊断精度为99.33%的模型比较,发现在训练样本数量近似的情况下,本文的方法诊断精度为99.5%,而本文方法诊断的健康状态为8种,在诊断性能上优于该方法。
综合上述对比分析,所提基于改进深度森林的齿轮箱故障诊断方法,在2009年PHM数据挑战赛的数据集上诊断性能优于已有的前沿故障诊断方法,在机械故障诊断中有重要的应用前景。
5 结 论
1) 所提基于改进深度森林的故障诊断方法考虑了原始深度森林在级联森林生长过程中因为数据传递机制造成的特征冗余、运行效率差等问题,并结合齿轮箱故障由于多重共线性带来的难点,提出了将PCA特征提取与级联森林的层级部分进行集成的模型,改善了上述问题对基于深度森林的齿轮箱故障诊断问题带来的难点。
2) 对比了目前主流的特征提取方法,如LDA、t-SNE、K-PCA,从诊断性能、诊断效率、实际应用的时效性等方面综合考虑,验证了选取PCA作为集成的特征提取算法的必要性。
3) 在小训练样本条件(训练-总体样本比例不高于50%)下,比较了所提基于改进深度森林的故障诊断方法和基于CNN与LSTM的故障诊断方法,验证了在小训练样本条件下,所提方法的优越性和诊断的稳定性。
4) 通过开展针对2009年PHM数据挑战赛齿轮箱故障数据集的比较实验,所提基于改进深度森林的诊断方法分别在训练-总数据比例为70%、50%以及10%的条件下,实现了99.5%、97.3%和82.8%的平均诊断精度,在验证其小训练样本下诊断能力的同时,表明了该方法能够有效解决齿轮箱的多种类混合故障问题,诊断性能优于DACNN、Fourier-DCNN和2DCNN等同类齿轮箱诊断方法,在航空机械故障诊断中具有重要的应用前景。
5) 在对原始深度森林的数据处理与传递机制进行分析时,发现原始深度森林的多粒度扫描结构因为其采样机制和特殊的数据传递机制,会在一定程度上增加算法的内存消耗和运行时间,这使得该模型仍然存在改善的空间。因此,在未来的工作中,将针对多粒度扫描结构的缺陷,对本文方法进行进一步的优化。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
山东冶金(2022年3期)2022-07-19 03:24:36
保定学院学报(2022年2期)2022-04-07 02:26:50
许昌学院学报(2018年4期)2018-05-02 12:27:37
制造技术与机床(2017年4期)2017-06-22 11:17:44
中华建设(2017年1期)2017-06-07 02:56:14
电子制作(2016年15期)2017-01-15 13:39:09
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
风能(2016年12期)2016-02-25 08:45:56
电测与仪表(2014年1期)2014-04-04 12:00:34
