
基于关联特征传播的跨模态检索
2022-09-06 07:31梁新彦钱宇华
计算机研究与发展 2022年9期
张 璐 曹 峰 梁新彦 钱宇华
1(山西大学大数据科学与产业研究院 太原 030006)
2(计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006)
3(山西大学计算机与信息技术学院 太原 030006)
(moon_lu123@163.com)
随着信息大数据的快速发展和增长,图片、文本和音频等不同模态的数据大量产生,且对数据的加工、处理和利用越来越普遍,因此促进了信息技术的发展,尤其是推动了信息检索技术的进展.在进行信息检索时,我们通常会使用一种模态的数据去检索另一种不同模态的数据,而这些不同模态的数据尽管数据的存在形式不同,但描述的是同一物体或同一事件,即它们的语义是相同的,这种检索方式称为跨模态检索.例如:利用有关“放风筝”的文本检索相关的“放风筝”图片,或者利用有关“蝴蝶”的图片检索相关的“蝴蝶”文本等.跨模态检索就是寻找不同模态数据之间的相关关系,最终实现利用某一种模态数据检索语义近似的另一种模态数据,本文研究的是图片与文本之间的跨模态检索.传统模态检索与跨模态检索对比如图1所示:
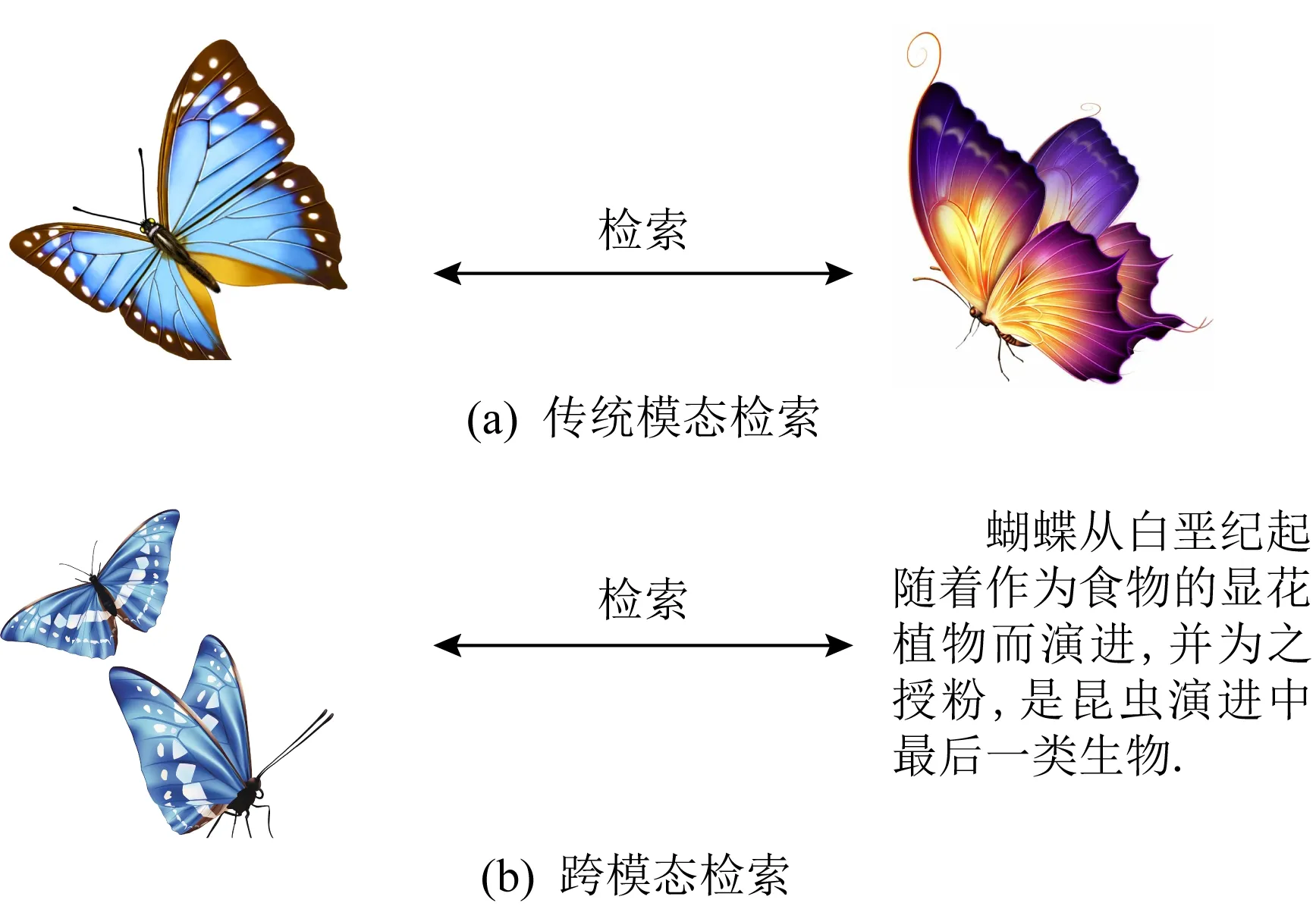
Fig. 1 Comparison between traditional-modal retrievaland cross-modal retrieval图1 传统模态检索与跨模态检索对比
不同模态的数据具有各自不同的底层特征,如图片具有纹路、色彩等,文本具有字、词、句等以及音频具有音调、频率等.显而易见,不同模态数据的底层特征之间存在异构问题,但有时不同模态数据之间的高层语义具有相关性,都是描述同一个语义主题.由此可见,跨模态检索的研究目的是找到使2种不同模态数据具有关联性的特征子空间来解决底层特征上的异构问题,并且在该特征子空间中进行检索.
近年来,为消除不同模态数据之间的底层特征异构问题,大量的跨模态检索方法被提出,其中大多数的研究方法主要是特征子空间的学习[1-3],即利用不同模态数据对的共有信息学习投影矩阵,通过学习得到的投影矩阵将不同模态数据的底层异构特征投影到1个特征子空间中,然后可以在该子空间中度量不同模态数据的相似性,从而实现跨模态检索.在这些方法中,常用的经典方法是典型相关分析(canonical correlation analysis, CCA)算法[4],该算法是用来学习1个子空间,使2种模态数据的投影向量之间的相关性最大化.由于其简单有效,出现了很多基于CCA算法的扩展方法[5-6].另一个经典方法是偏最小二乘(partial least squares, PLS)算法[7],该算法是利用潜在变量对观测变量集之间的关系进行建模的一般方法.上述CCA和PLS两种算法学习到的特征子空间虽然具有一定的关联性,但是该特征子空间缺乏语义解释.为解决该问题,Rasiwasia等人[8]进行了不同模态数据的语义映射,该方法采用多元逻辑回归来生成相应图片和文本的语义特征子空间.还有一些其他的方法也可以用于处理跨模态检索问题,如基于散列变换的检索方法[9-11],是将不同模态数据的特征映射到1个汉明(Hamming)二值空间中,然后在该空间实现快速的跨模态检索.
上述有关特征子空间与语义映射的相关方法都已取得不错的结果,然而,其中现有的典型相关分析学习方法[12]主要只通过单个相关性约束将不同模态数据的特征映射到具有一定相关性的特征空间中.表征学习表明,不同层次的特征在帮助模型最终性能的提升上都会起作用.所以,利用这种方法学习到的特征空间的关联性可能是较弱的.为解决这些缺点,提出了基于关联特征传播的跨模态检索模型.
本文为找到使2种模态数据关联性更强的特征子空间,将深度学习和关联学习技术进一步展开了研究,创新性地提出关联特征传播的模型.
1 相关工作
本节简单回顾了关联学习和深度学习的基本概念及应用.
1.1 关联学习
关联学习是研究数据对之间的关联关系,从给定的数据对中学习关联模型,使其能对新的输入数据进行关联关系识别.钱宇华等人[13]定义的关联学习问题,数据集T={(u1,g1),(u2,g2),…,(uN,gN)},其中ui=xi,yi是输入空间中的观测值,gi是输出空间中的观测值,由输入空间到输出空间的映射过程称为关联学习.
关联学习在跨模态检索中通常是指找出基于不同模态数据之间的对应关联关系.不同模态的数据存在底层特征异构问题,需要通过关联学习的相关方法找到它们之间的关联关系.如通过典型关联分析CCA算法或者共享表示层等类似的方法,可以将不同模态的数据映射到一个共享的特征子空间中,从而在该子空间中进一步利用某种距离度量函数测出不同模态数据之间的相似性.
Rasiwasia等人[8]提出将典型相关分析CCA算法应用到文本与图片间的跨模态检索中,即将文本特征和图片特征分别作为不同的特征空间,通过最大化投影向量的相关性,最后学习得到投影后的共享子空间;之后,Galen等人[12]对该方法进行了扩展,提出深度典型相关分析(deep canonical correlation analysis, DCCA)算法,该算法将深度网络和典型相关分析CCA算法进行结合,先用深度神经网络分别求出2个视图经过线性变化后的向量,然后再求出2个投影向量的最大相关性,最后得到具有最大相关性的特征子空间;Hwang等人[14]提出核典型相关分析(kernel canonical correlation analysis, KCCA)算法,KCCA是常用的非线性CCA算法,把核函数引入到CCA算法中,其基本思想是把低维的数据映射到高维的特征空间中,并在高维的特征空间中利用CCA算法进行关联分析;Yu等人[15]提出基于类别的深度典型相关分析,不仅考虑了基于实例的相关性,还学习了基于类别的相关性.目前依然有许多跨模态检索领域的研究者一直在研究关联学习的相关方法及扩展,并且都取得了不错的检索效果.
1.2 深度学习
由于深度学习强大的特征表示能力,它在跨模态检索研究中也取得了很好的成果.利用深度学习,在跨模态检索中不仅可以在底层提取出不同模态数据的有效特征表示,而且还可以在高层建立不同模态数据的语义关联.
Ngiam等人[16]提出采用深度学习的方法来处理多模态任务,特别地进行了跨模态特征表示学习和不同模态数据之间的共享表示学习;之后,Wang等人[17]提出基于监督的多模态深度神经网络,该网络由处理图片的卷积神经网络和处理文本的语言神经网络构成,并通过5层神经网络将不同模态数据映射到共同的语义空间,然后在语义空间中进行不同模态数据的相似性度量;Wei等人[18]提出深度语义匹配(deep semantic mapping, DeepSM)方法来解决带有1个或多个标签样本的跨模态检索问题,该方法通过利用卷积神经网络和全连通网络将图片和文本映射到标签向量中来学习不同模态数据间的相关性;Hua等人[19]提出基于生成对抗网络的深度语义关联学习方法.深度学习的相关方法在跨模态检索领域中得到了广泛的应用,也取得了很好的成果.
目前,基于典型相关分析的扩展方法已取得不错的结果,但这些方法主要只通过单层的关联约束生成关联空间.显然忽略了不同层特征间的相关性,这可能带来一个问题,虽然模型学习了大量丰富的层次特征,然而只有单个层次是与检索任务相关的特征,进而浪费了其他层次特征中的信息,只能学习关联性较弱的关联空间.为解决该问题,得到使2种模态数据关联性更强的关联空间,本文主要对深度网络和关联关系进行研究,创新性地提出基于关联特征传播的跨模态检索模型.
2 基于关联特征传播的跨模态检索模型
本节将对提出的基于关联特征传播的跨模态检索模型进行详细的介绍,包括模型的结构和相关性计算.
2.1 模型概述
本文提出的基于关联特征传播的跨模态检索模型的结构如图2所示.该模型主要由关联特征传播(correlation feature propagation, CFP)模型和语义映射(semantic mapping, SM)模型2部分组成.
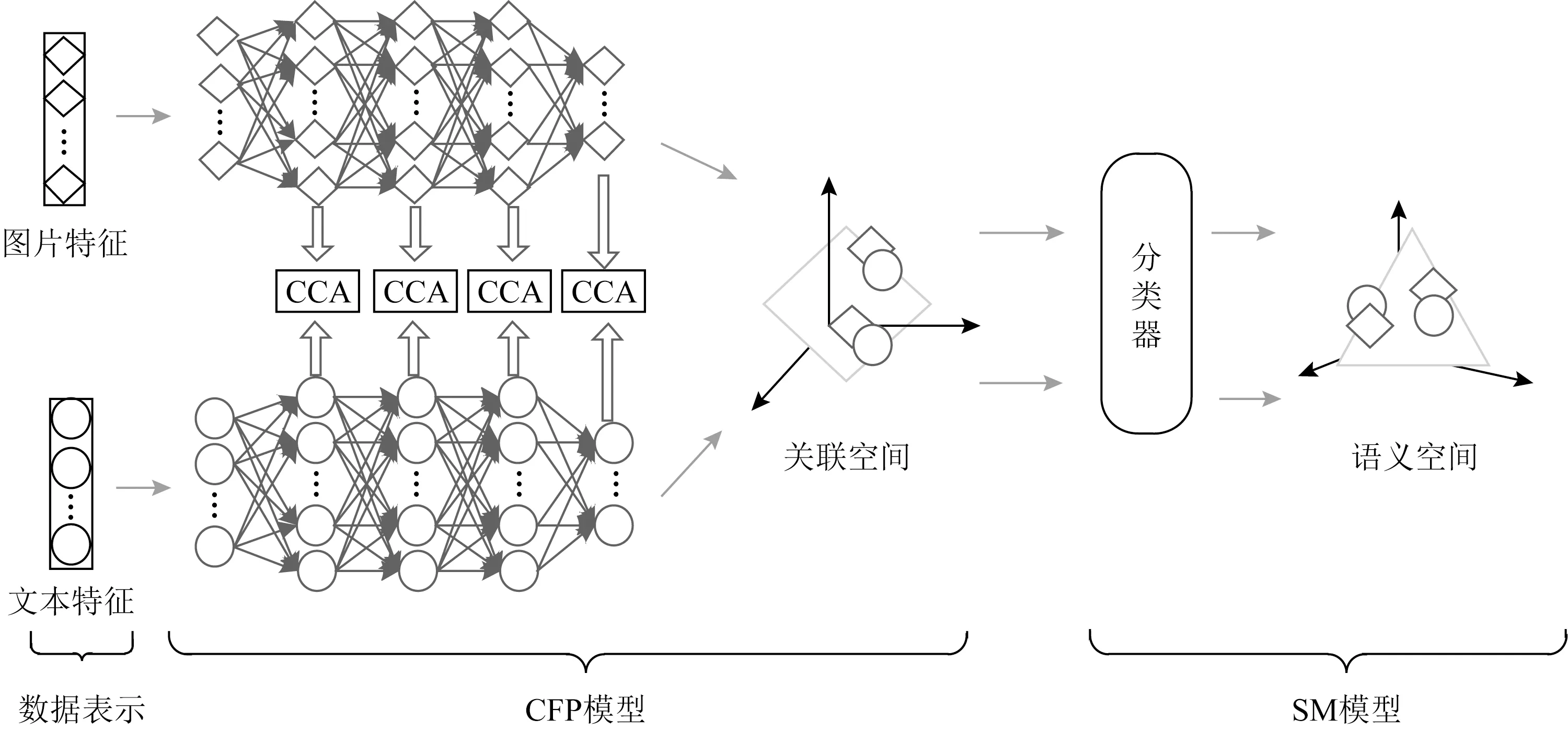
Fig. 2 Cross-modal retrieval models with correlation feature propagation图2 基于关联特征传播的跨模态检索模型
图2的CFP模型结构包含2个不同模态数据的分支网络,每个分支都包含1个输入层和若干个隐藏层,且2分支之间的各个网络层特征都进行了CCA算法的关联约束.
CCA算法[20]被广泛应用于表示2组数据间的相关关系,它的基本思想是:寻找2组数据X,Y(2组数据的个数和所表示的内容可以是不同的)对应的2个线性变换对a,b,使得通过线性变换后的2个线性组合(也称1对典型变量)aTX,bTY(即X′=aTX,Y′=bTY)之间的相关系数ρ(X′,Y′)最大:
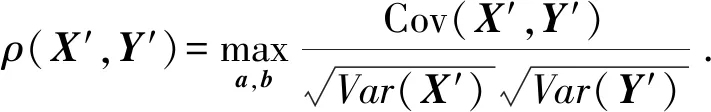
(1)
式(1)中,Cov(X′,Y′)是X′和Y′的协方差,2组数据间的协方差为
Cov(X′,Y′)=
E[(aTX-aTE(X))(bTY-bTE(Y))]=
aTCov(X,Y)b.
(2)
式(1)中,Var(X′)和Var(Y′)分别是X′和Y′的方差,每组数据的方差为
Var(X′)=E[(aTX-aTE(X))2]=aTCov(X,X)a,
Var(Y′)=E[(bTY-bTE(Y))2]=bTCov(Y,Y)b.
(3)
因此,最终的相关系数为
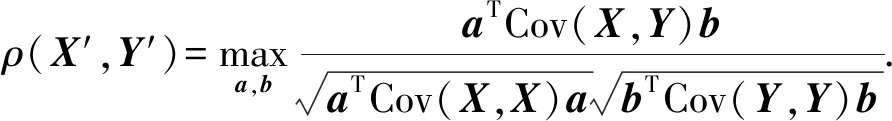
(4)
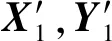
在本文的跨模态检索任务下,在式(4)中,X表示图片特征数据,Y表示文本特征数据,a,b表示线性变换对.式(4)中ρ的结果在[-1,1]范围内,当结果越接近-1时,表示图片特征数据X和文本特征数据Y的相关性越低;相反越接近1,表示两者相关性越高.通过CCA算法学习得到d对典型变量对,表示分别将图片和文本特征数据映射为关联空间中的d维特征向量.
为验证网络的不同层次特征信息对跨模态检索的性能具有提升作用.本文将图片、文本2种模态数据的底层特征向量经过不同网络逐层递增关联约束(共4层),在得到的4个不同关联子空间中分别进行跨模态检索实验,包括图片检索文本、文本检索图片2种跨模态检索任务.在Wikipedia特征数据集中实验结果的平均精度均值(mean average precision,MAP)如图3所示:
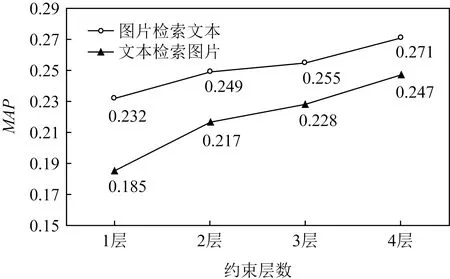
Fig. 3 Layer by layer constraint MAP value图3 逐层约束的MAP值
图3展示随着逐渐增加网络的约束层数,MAP值也逐渐增加,表明本文提出的CFP模型的可行性.
CFP模型提出在深度网络各层间增加约束来强化不同特征间的关联性,且前一层具有一定关联性的特征经过非线性变化传到后一层.这样的好处是特征的关联性从底层开始积累,充分利用了各个层特征中的信息,更有利于找到使2种模态数据关联性更强的特征空间.
在深度网络结构中,该方法实现了逐层、逐渐加强2种模态数据(图片和文本)的关联性.得到图片关联子空间Cimg和文本关联子空间Ctxt,可以在该关联子空间C中进行跨模态检索.
在进行跨模态检索时,具有语义相关的图片和文本对应属于同一组语义概念,CFP模型得到的检索特征表示,虽然具有较强的相关性,但缺乏语义关系.进而为了得到不同模态数据的语义空间,可以进行语义映射,即通过将CFP模型最后得到的关联特征经过分类器进行语义映射,生成相应的图片语义子空间Simg和文本语义子空间Stxt.图片和文本的2个语义子空间S中特征向量都代表了对应图片和文本属于同一组语义概念的概率分布.
相比传统分类器多元逻辑回归、支持向量机等,深度学习强大的特征表示能力使得神经网络发展迅速,并且解决多分类问题效果也很好.因此尝试利用神经网络进行语义映射.
本文采用2支相同的含3层隐藏层的神经网络进行语义映射,该神经网络实际上是用Softmax函数做多分类任务,样本c被分为第j类的概率为
(5)
其中,zci表示第i个神经元的输出值.
由于式(5)中数据的输出为概率值,因此使用交叉熵作为损失函数L来训练模型:
(6)
其中,oi表示各个输出点的目标分类结果,p(ci)表示经过Softmax函数后的输出结果,k表示类别的数量.
通过语义映射得到图片和文本的概率分布特征空间,即图片和文本的语义子空间.在该空间中图片和文本属于概率最大值的分类.因此首先利用CFP模型得到不同模态数据的关联子空间,之后采用SM模型得到不同模态数据的语义子空间,最后在得到的语义子空间中对不同模态数据进行跨模态检索,称这种模型为基于关联特征传播的跨模态检索(CFP+SM)模型.
CFP+SM模型的整体训练过程如过程1所示.
过程1.CFP+SM模型的训练过程.
输入:训练集中图片和文本特征数据X,Y;
输出:Xinp,Yinp.
/*第1部分:CFP模型*/
① 初始化参数;
② 特征数据X,Y在网络前向训练得到:
第1层关联约束为X1,Y1←ρ(X′,Y′);
第2层关联约束同第1层,关联得到X2,Y2;
第3层关联约束同第1层,关联得到X3,Y3;
第4层关联约束同第1层,关联得到X4,Y4;
/*第2部分:SM模型*/
③ 利用Softmax函数对特征数据X4,Y4做多分类得到:
p(Xinp)←X4,p(Yinp)←Y4;
④ 计算损失函数(交叉熵损失函数)得到:
Limg←p(Xinp),Ltxt←p(Yinp);
⑤ 反向更新模型参数,对模型进行微调.
输入图片和文本特征数据的训练集,对CFP+SM模型进行训练,最后可以利用该模型进行跨模态检索实验.
2.2 相关性计算
无论是在关联空间C中还是在语义空间S中进行跨模态检索,都需要进行图片-文本对的相关性计算.如在语义空间中(关联空间同理),本文通过CFP+SM模型可以得到d维的文本语义子空间Stxt和d维的图片语义子空间Simg.在d维子空间S中的图片和文本都是一一对应的,设定向量pimg和ptxt分别是图片和文本在d维同构语义子空间S中的坐标,则在子空间S中图片、文本对的相关性计算为
D=d(pimg,ptxt),
(7)
其中,距离函数d(,)使用归一化相关(normalised correlation, NC)距离[21]来计算图片和文本2个向量之间的相似性,NC距离为
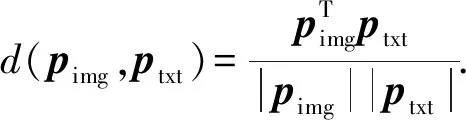
(8)
目前用于距离度量的方法较多,主流方法包括Normalised Correlation距离函数、Ridge Regression距离函数和Lasso Regression距离函数等.
3 实验与结果
本文采用提出的基于关联特征传播的跨模态检索模型进行实验,并在Wikipedia和Pascal特征数据集上进行测试.
3.1 数据集
跨模态检索的实验数据由多种模态的数据构成,如图片、文本、音频等.本文以图片和文本为实验的数据对象.本次实验利用了Wikipedia特征数据集和Pascal特征数据集,如表1所示:
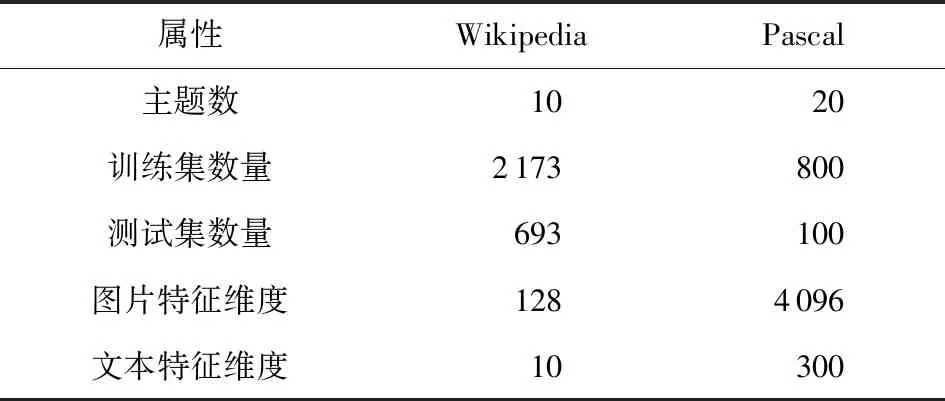
Table 1 Data Sets表1 数据集
2个数据集都包含了图片和文本的特征表示集.Wikipedia数据集中图片表示为128维的特征,文本表示为10维的特征;Pascal数据集中图片表示为4 096维的特征,文本表示为300维的特征.数据集的每个文档中文本都附有若干张语义相关的图片.
1) Wikipedia数据集选取了原数据集中10个最受欢迎的主题,包括art,biology,geography,history,literature,media,music,royalty,sport,warfare.该数据集共包含2 866个文档,随机分割成1个包含2 173个文档的训练集和1个包含693个文档的测试集,且每个文档都由1个“文本-图片”对组成,且属于某一主题.图4显示了Wikipedia中关于“克赖斯特彻奇”大教堂和“威斯康辛号”战列舰的文档一部分以及相关的图片.
2) Pascal数据集有20个主题,包括person,bird,cat,cow,dog,horse,sheep,aeroplane,bicycle,boat,bus,car,motorbike,train,bottle,chair,dining table,potted plant,sofa,monitor.该数据集共包含900个文档,随机分割成1个包含800个文档的训练集和1个包含100个文档的测试集.

Fig. 4 Wikipedia documents图4 维基百科文档
3.2 评价指标
为了评估跨模态检索的性能,我们进行图片检索相关文本以及文本检索相关图片2个任务.采用MAP作为评价指标.
首先要计算每个检索的平均精度(average precision,AP):
(9)
其中,T表示在检索集中与检索相关的数据数量,P(r)表示排名为第r个数据的检索精度,δ(r)∈{0,1}表示指示函数(若第r个数据和检索数据相关则其值为1,否则为0).
然后计算所有检索的平均AP,即MAP值:
(10)
MAP值数值越大,表明检索模型的性能越好.
3.3 实验参数
本文提出的CFP+SM模型采用神经网络相关的参数值,下面具体介绍.
3.3.1 CFP模型参数
CFP模型的2个分支神经网络都具有1个输入层、4个隐藏层和1个输出层,具体层次节点数如表2所示:
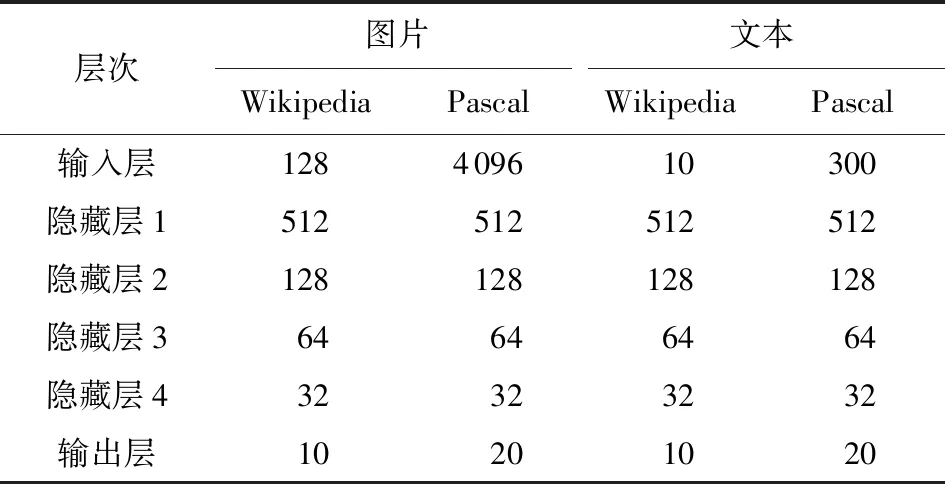
Table 2 Number of Nodes in CFP Model表2 CFP模型的节点数
3.3.2 SM模型参数
SM模型采用2支相同的神经网络作为分类器进行映射,该神经网络采用Softmax函数做多分类,具有1个输入层、3个隐藏层和1个输出层,具体层次节点数如表3所示:
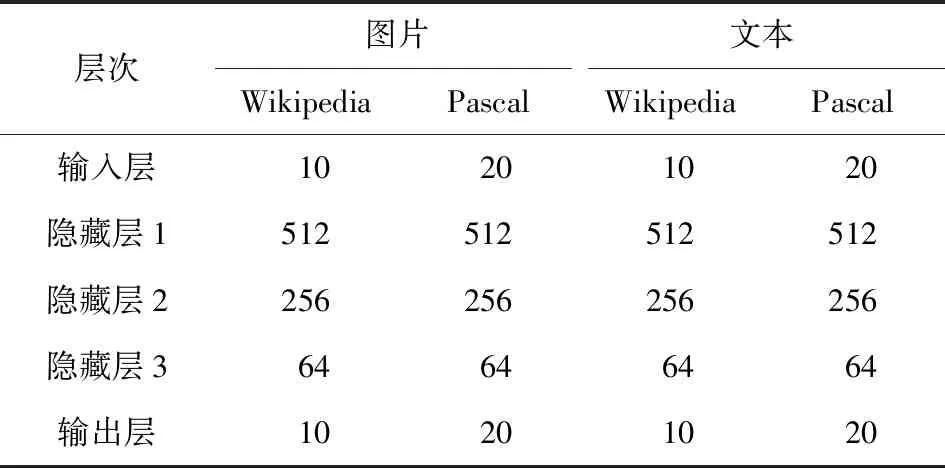
Table 3 Number of Nodes in SM Model表3 SM模型的节点数
3.4 实验结果
以图片特征和文本特征为实验的数据对象,一共进行了4组对比实验来验证所提出方法的有效性.
3.4.1 不同关联学习方法比较
将提出的CFP模型与CCA模型[8]、DCCA模型[12]等关联学习方法进行比较.在Wikipedia,Pascal特征数据集上的MAP值如表4、表5所示.
从表4、表5可以看出,本文提出的CFP模型在图片检索相关文本和文本检索相关图片任务上都取得了最好的MAP值,这表明对深度网络的每层特征进行关联约束是有效的.
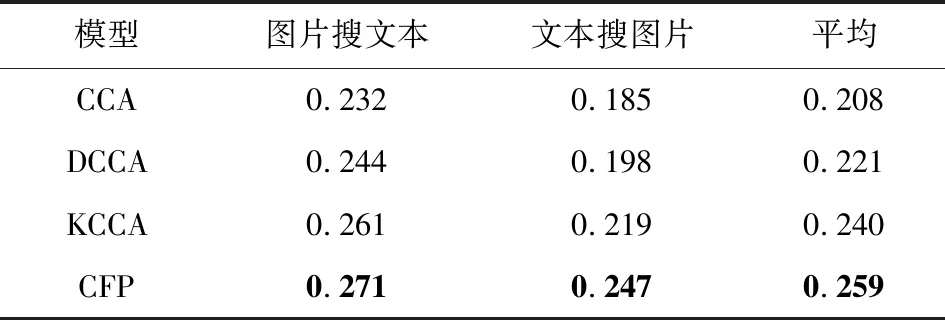
Table 4 MAP Values of Different Correlation LearningMethods in the Wikipedia Data Set表4 Wikipedia数据集中不同关联学习方法的MAP值
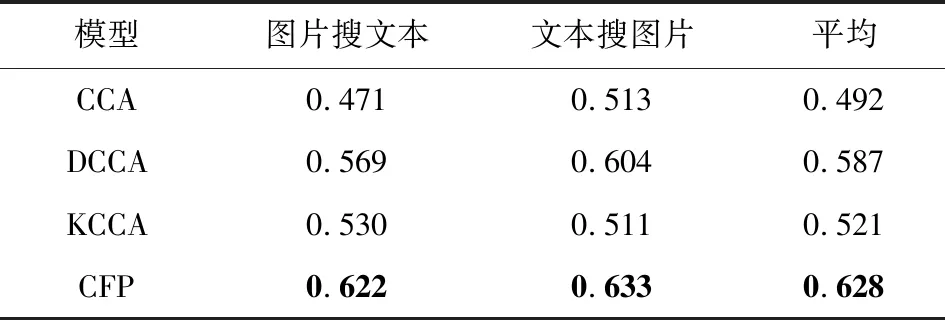
Table 5 MAP Values of Different Correlation LearningMethods in the Pascal Data Set表5 Pascal数据集中不同关联学习方法的MAP值
3.4.2 与共享隐藏层参数方法比较
将提出的CFP模型,即深度网络各层之间增加CCA约束来强化不同模态特征间关联性的方法与让不同模态的数据直接共享深度网络中隐藏层参数(shared hidden layer parameter, SHLP)的方法进行比较.在Wikipedia,Pascal特征数据集上的MAP值如表6、表7所示:

Table 6 MAP Values of Shared Hidden Layer ParameterMethods in the Wikipedia Data Set表6 Wikipedia数据集中与共享隐藏层参数方法的MAP值
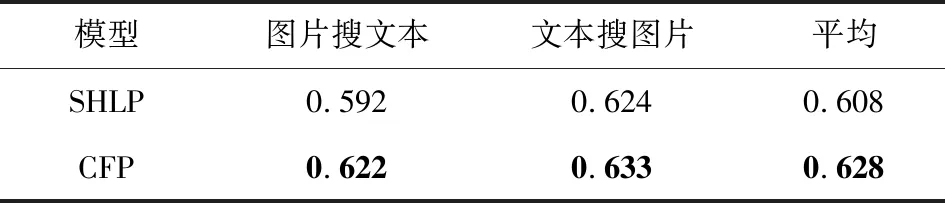
Table 7 MAP Values of Shared Hidden Layer ParameterMethods in the Pascal Data Set表7 Pascal数据集中与共享隐藏层参数方法的MAP值
从表6、表7可以看出,本文提出的CFP模型在图片检索相关文本和文本检索相关图片任务上都取得了最好的MAP值,这表明对深度网络的每层特征进行关联约束是有效的.
3.4.3 不同语义映射方法比较
将提出的SM模型与多元逻辑回归(multiple logistic regression, MLR)、支持向量机(support vector machine, SVM)等语义映射方法进行比较.在Wikipedia,Pascal特征数据集上的MAP值如表8、表9所示:
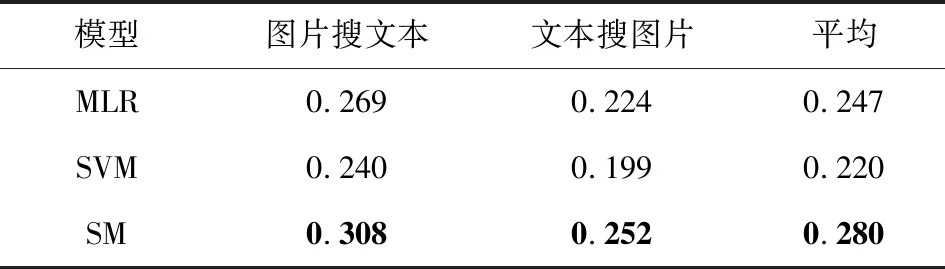
Table 8 MAP Values of Different Semantic MappingMethods in the Wikipedia Data Set表8 Wikipedia数据集中不同语义映射方法的MAP值
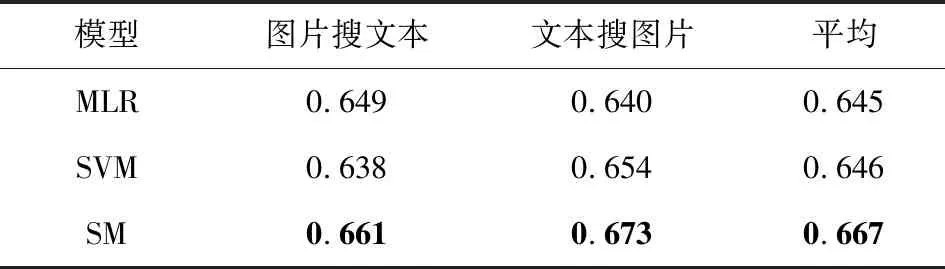
Table 9 MAP Values of Different Semantic MappingMethods in the Pascal Data Set表9 Pascal数据集中不同语义映射方法的MAP值
从表8、表9可以看出,本文提出的SM模型在图片检索相关文本和文本检索相关图片任务上都取得了最好的MAP值,这表明深度学习具有强大的特征表示能力.
3.4.4 与其他跨模态检索方法比较
比较了CFP+SM模型与语义关联匹配(semantic correlation matching, SCM)模型[8]、对应自编码器(correspondence autoencoder, Corr AE)模型[22]、双重动态贝叶斯网络(bimodal dynamic Bayesian network, Bimodal DBN)模型[23]、深度监督跨模态检索(deep supervised cross-modal retrieval, DSCMR)模型[24]和对抗性跨模态检索(adversarial cross-modal retrieval, ACMR)模型[25]等其他跨模态检索方法.在Wikipedia,Pascal特征数据集上的MAP值如表10、表11所示.
从表10、表11可以看出,本文提出的CFP+SM模型在图片检索相关文本和文本检索相关图片任务上都取得了最好的MAP值,这表明本文方法的有效性.
通过图5中的MAP值对比可以看出,在提到的CFP模型、SM模型和CFP+SM模型3种模型中,跨模态检索关联学习之后再加入语义映射得到的跨模态检索方法效果最佳,即CFP+SM模型得到更好的检索性能.
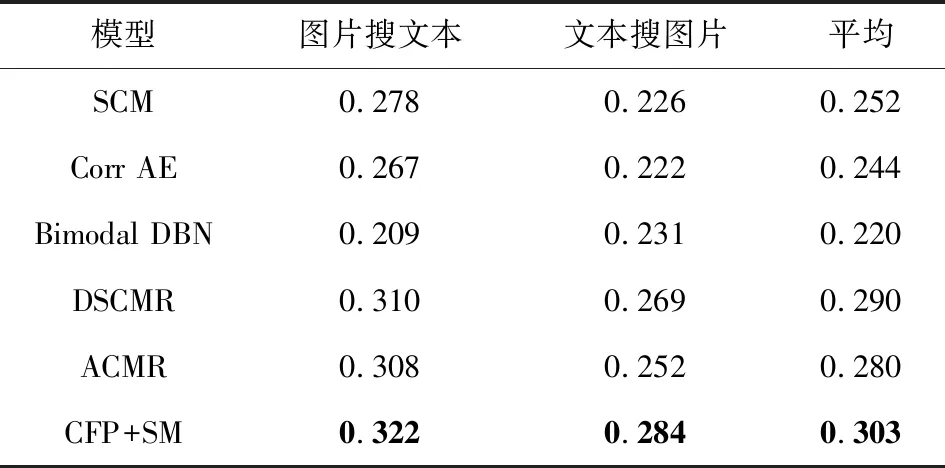
Table 10 MAP Values of Other Cross-Modal RetrievalMethods in the Wikipedia Data Set表10 Wikipedia数据集中其他跨模态检索方法的MAP值
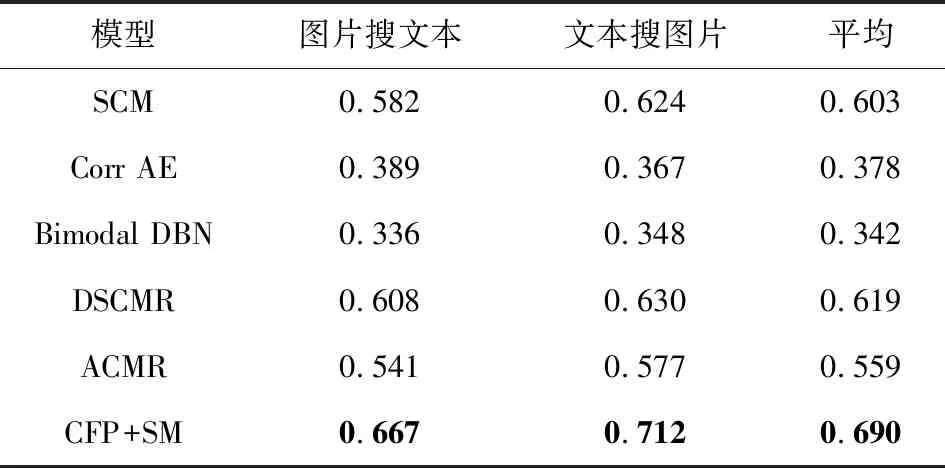
Table 11 MAP Values of Other Cross-Modal RetrievalMethods in the Pascal Data Set表11 Pascal数据集中其他跨模态检索方法的MAP值
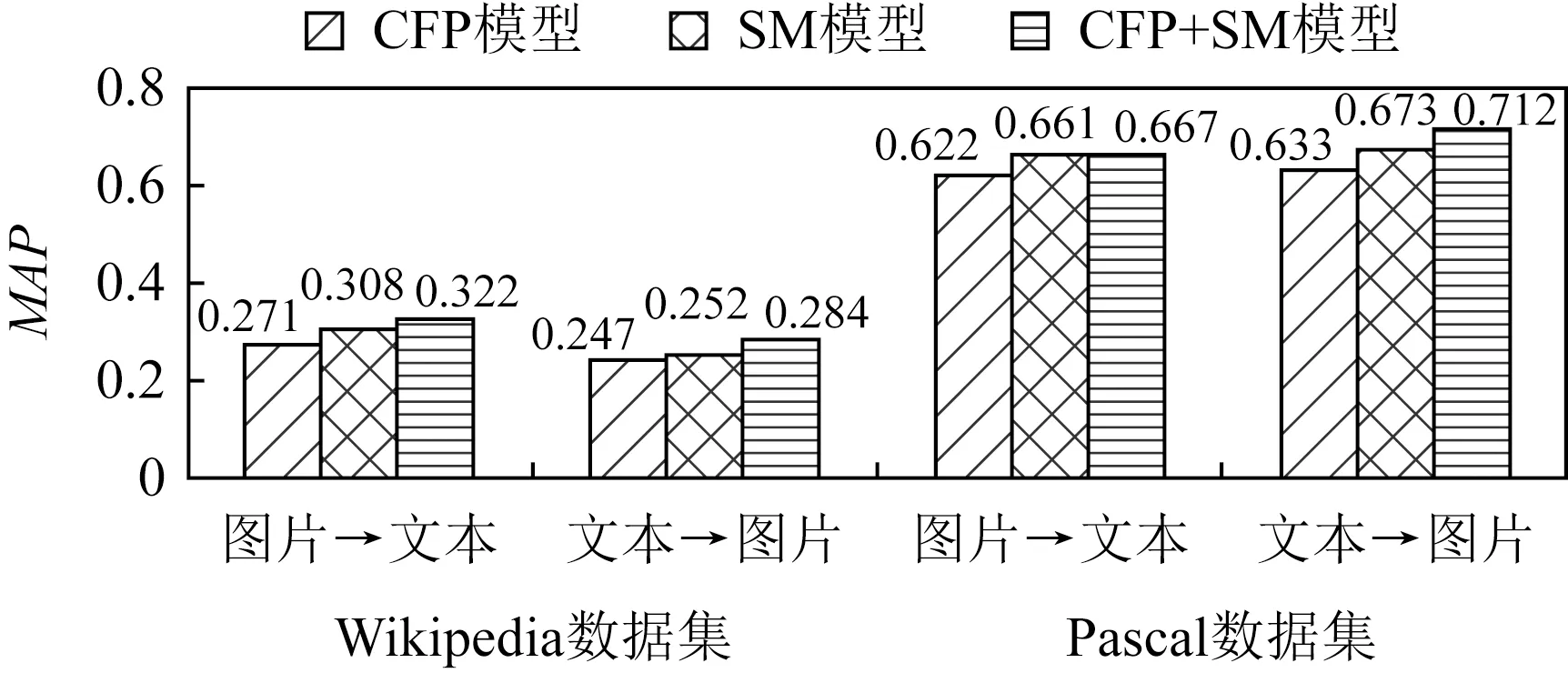
Fig. 5 Comparison of MAP values of three models on two data sets图5 3种模型在2个数据集上的MAP值比较
3.5 结果分析
通过大量对比实验可以得到,提出的CFP+SM模型的基本思想是强化深度网络各层之间的关联性,即前一层具有一定关联的特征经过非线性变化传到后一层,之后再进行语义映射,得到图片和文本属于同一组语义概念的概率分布.这种模型更有利于找到使2种模态关联性更强的特征空间,可以得到更好的检索性能.
4 总 结
本文提出了新的跨模态检索模型,即关联特征传播的跨模态检索(CFP+SM)模型.为了充分利用深度网络各层特征中的信息,得到使2种模态数据关联性更强的特征空间,本文主要是先采用关联特征传播(CFP),强化了深度网络各层之间的关联性,使特征的关联性从底层就开始积累;之后,本文还对2种模态数据进行语义映射(SM),生成语义空间进行跨模态检索.在常用的Wikipedia,Pascal特征数据集上的实验结果表明,本文提出的基于关联特征传播的跨模态检索模型是有效的.
作者贡献声明:张璐负责提出算法思路,完成实验并撰写论文;曹峰提出指导意见;梁新彦参与论文校对和实验方案指导;钱宇华提出方法的指导意见和审核论文.
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年9期)2022-05-20
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
成长·读写月刊(2018年8期)2018-08-30
科学与财富(2017年28期)2017-10-14
长江学术(2015年1期)2015-02-27
计算机辅助工程(2012年5期)2012-11-21
