
一种面向实体关系联合抽取中缓解曝光偏差的方法
2022-09-06 07:30范红杰柳军飞
计算机研究与发展 2022年9期
王 震 范红杰 柳军飞
1(北京大学软件与微电子学院 北京 100871)
2(中国政法大学科学技术教学部 北京 102249)
3(北京大学软件工程国家工程研究中心 北京 100871)
(wang.zh@pku.edu.cn)
知识图谱中的关键要素是实体和实体之间的关系[1].关系事实由有语义关系连接的实体对组成,其一般形式为(主语,关系,宾语),称为实体-关系(entity-relation)三元组(triplets).从无结构文本中抽取具有关系的实体对是自然语言处理(natural language processing, NLP)中信息抽取的一项基本任务[2-4],也是知识图谱构建(knowledge graph construction, KGC)的关键步骤[5-6].
现有的实体和关系抽取方法主要分为2类:流水线(pipeline)方法和联合抽取方法.流水线方法将任务分解为2个独立的子任务:命名实体识别[7-9]和关系抽取[10-12].该方法首先识别命名实体,然后为抽取的每一对实体选择一个关系.流水线方法的优点是简单、灵活、易于执行,可以自由地替换其中一个抽取组件而不需要考虑另一个抽取组件.然而,流水线方法忽略了这2个子任务之间潜在的相关性和相互作用[13-14],从而导致命名实体任务中的错误信息会传播到关系抽取任务中,或者来自一个任务的有用信息却未被另一个任务利用,进而影响关系抽取的效果.
近年来,越来越多的研究致力于在单个抽取组件中同时实现实体和关系抽取.这种抽取方式通常称为联合抽取方法.与流水线方法相比,联合抽取方法整合了实体和关系的信息,有效地减少了误差传播,取得了更好的抽取性能[15-16].最初的联合抽取方法严重依赖特征工程[17],需要较为复杂的预处理过程,导致引入额外的错误信息.为了减少对特征工程的依赖,许多研究者将神经网络应用到关系抽取任务中[18-19].
Miwa等人[20]提出了一种基于循环神经网络(recurrent neural network, RNN)的联合抽取方法,该方法使用双向长短期记忆(bi-directional long-short term memory, Bi-LSTM)网络先对实体进行编码,并在此基础上使用Tree-LSTM建模词对之间的语法依赖.Adel等人[21]利用卷积神经网络(convolutional neural network, CNN),结合线性链条件随机场同时预测实体和实体之间的关系.Ren等人[17]结合远程监督(distant supervision)和弱监督(weakly supervision)学习方法对文本中的实体和关系进行联合抽取.
理想的联合抽取系统应能自适应地处理多种情况,特别是在实体重叠情况下的三元组抽取,即多个关系共享一个公共实体,而这些方法无法处理实体重叠问题.最近出现了一些针对该问题的研究[22-23].Fu等人[22]采用图卷积网络(graph convolutional network, GCN)对单词图进行建模.Takanobu等人[23]应用分层强化学习框架来增强实体之间的交互.尽管目前基于神经网络的三元组抽取方法可以在一定程度上解决实体重叠问题,但是这些方法都将三元组抽取任务分解成存在内部依赖性步骤的方法.这使得任务易于执行,但同时引入了曝光偏差(exposure bias),即模型对于频繁出现的标签组合出现过拟合,从而影响模型的泛化性能.
当前解决实体重叠三元组(entity overlapped triplet, EOT)抽取问题的方法存在训练和推理搜索空间不一致的问题.在训练时采用真实标签作为输入,搜索空间源自数据的静态分布,而推理时采用模型的前一步输出作为输入,搜索空间来自模型的分布.此外,由于模型当前的解码输出依赖于前一时刻的解码结果,从而导致误差累积.特别是当实体重叠现象比较严重和句内三元组数量较多时,解码序列会随之加长,所产生的误差累积问题也会更加严重.
针对曝光偏差和误差累积的问题,本文提出了融合关系表达向量(fusional relation expression embedding, FREE)的先验特征提取方法,丰富了先验特征的语义表达,弥补了训练与推理搜索空间不一致的问题,缓解了曝光偏差.此外,本文提出的条件层规范化方法相较于传统加和与拼接的特征嵌入方法,可以更加有效地进行特征嵌入.方法在公开的实体关系抽取数据集上进行了大量的实验评估.实验结果表明,相较于现有最强基线模型,本文提出的模型分别获得了91.7%和92.5%的F1值,并在诸多性能指标上优于现有抽取模型.同时,对结果的深入分析表明该方法能够更有效地适应多种三元组抽取任务.
本文的主要贡献包括3个方面:
1) 提出了一种融合关系表达向量的先验特征提取方法,丰富了先验特征的语义表达,弥补了训练与推理搜索空间不一致的问题,缓解了曝光偏差;
2) 提出了更有效嵌入和融合特征的条件层规范化层,并将先验特征融入到宾语抽取的参数表示中;
3) 在NYT和WebNLG数据集上的实验评估表明提出的方法可以有效地解决三元组抽取问题,特别是面向实体重叠的三元组抽取.
1 相关工作
早期的关系抽取工作一般采用流水线方法,即先对非结构化文本进行命名实体识别(named entity recognition, NER)[7-9]任务,再进行关系抽取(relation extraction, RE)[10-12,24]任务,即先抽取实体再确定实体对之间的关系,例如Nadeau等人[7]和Zelenko等人[24]的工作.但这些方法忽略了子任务之间的相关性和联系[25-26],且存在着误差传递问题.实体识别的错误会导致后续三元组整体抽取结果的错误.此外,由于采用先对抽取的实体两两组合再确定其关系的方法,导致无意义关系的实体较多时会出现冗余计算.
为了克服误差累积弊端,逐渐有学者提出了联合抽取模型.它是指只用一个模型即可抽取出文本中的实体关系三元组,增强了实体抽取和关系抽取2个子任务间的联系,缓解了误差传递的问题[15-16].目前主流的联合模型分为基于语法分析的模型[27]、基于特征工程的模型[17]和基于神经网络的模型[18-19,27].Ren等人[17]使用包括词性和实体层级以及知识库在内的多种特征约束,并且运用了文本集的信息和句子级别的局部信息将实体识别和关系抽取联合起来.Roth等人[26]使用信念网络建模句子内实体与关系间的语义和句法依赖,结合贝叶斯推断模型得到实体关系标签组合.Miwa等人[28]提出一种基于历史的结构化学习方法,通过合并全局特征并选择合适的学习方法和搜索顺序取得了优于流水线方案的结果.Liu等人[29]提出综合利用依赖解析树、核心谓词和词嵌入特征来优化支持向量机等传统机器学习模型的性能.Jiang等人[30]使用汉语句法特征作为启发式规则扩充和过滤基于规则建立的三元组数据.Hasan等人[31]提出将词性标记、依赖关系和语义类型等传统特征与词向量特征结合的方法进一步提升模型性能.在基于神经网络的模型方面,Zeng等人[32]和Xu等人[33]使用基于卷积神经网络的方法来解决关系分类问题,其F1值比以往的机器学习模型具有明显的提升.叶育鑫等人[34]针对远监督关系抽取任务中的标记噪声,构建了基于噪声分布和带噪观测层的新型关系抽取模型.Zheng等人[15]采用基于长短期记忆网络的实体关系联合抽取模型,将三元组抽取任务创新性地定义为序列标注任务,采用基于就近原则的关系链接序列标注方法抽取实体关系三元组.作为改进,Miwa等人[20]提出了一种基于循环神经网络的联合抽取模型,该模型使用双向长短期记忆网络先对实体进行编码,并使用考虑基于依赖树信息的Tree-LSTM对实体之间的关系进行建模.然而该模型无法处理实体重叠三元组,即一个实体可能参与到多个三元组的构成中.
当前处理实体重叠三元组抽取任务的模型可分为2类:基于解码器优化和基于分解策略.基于解码器优化的模型通常采用编码器解码器结构,解码器一次抽取1个单词或1个完整三元组.Zeng等人[35]基于序列到序列(sequence-to-sequence, Seq2Seq)的思想提出了融合拷贝机制的联合抽取模型,但其模型解码器只拷贝实体的尾字节,导致了多字节实体不能完整抽取.Nayak等人[36]采用Seq2Seq框架一次解码一个完整实体.由于句内多个三元组的存在,Zeng等人[37]认为三元组抽取顺序会影响抽取结果,并使用强化学习模型学习抽取顺序.基于分解策略的模型首先抽取所有可能与目标关系相关的头实体,然后为每个抽取的主语标记相应关系和尾实体.Yu等人[38]提出采用头实体和关系尾实体抽取双阶段的序列标注方法.Wei等人[39]提出了一种基于级联二进制的标注框架,即首先采用指针标注主语识别起始和终止位置,抽取句子中所有可能的主语实体,再采用指针标注识别主语的所有可能关系和宾语.
然而这些方法中普遍存在严重的曝光偏差现象.Zhang等人[40]从三元组解码顺序和解码长度问题入手,通过无序树解码方式并将解码长度限制为3步来解决顺序依赖问题,同时输出句内包含的多个三元组.Wang等人[41]针对模型训练时的阶段性问题,设计了一种称为握手的数据标注方式将头实体和尾实体序列标注问题转换为1阶段的序列标注问题,缓解曝光偏差的同时可以处理嵌套实体,但由于引入了更多的标签,从而导致训练较为困难.Sui等人[42]同样认为传统的序列到序列框面临三元组生成顺序对最终抽取结果的影响,设计了多任务学习框架,采用非自回归解码策略并行生成顺序无关三元组,并设计了基于2部图匹配的集合损失函数来衡量模型输出集合与真实集合的差距.
2 方法描述
2.1 模型整体结构
如图1所示,本文的融合关系表达向量联合抽取模型包括5部分,分别是表示层、头实体向量抽取层、关系表达向量抽取层、条件层规范化层及关系尾实体抽取层.模型接收输入文本后,根据句子抽取主语,通过头尾字向量的平均得到主语向量,然后将该先验信息通过条件层正则化嵌入到文本表达中;在此之后,基于该文本表达预测得到各文本参与到当前主语关系表达的概率,并依概率相乘得到关系表达向量;在此基础上,通过门控机制控制来自主语向量和关系表达向量信息的比例,主语向量和关系表达向量加和得到最终的融合关系向量表达;最后再将该先验信息通过条件层正则化嵌入到文本表达中,预测该主语关系表达类别及对应的宾语.
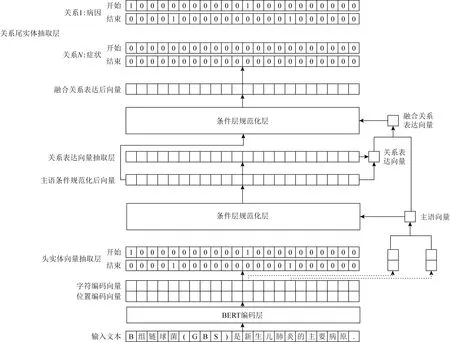
Fig. 1 The structure of joint extraction model with fusional relation expression embedding图1 融合关系表达向量的联合抽取模型结构
本文继承Wei等人[39]提出的基于CasRel三元组抽取模型设计思路,依照Seq2Seq模型先抽取主语,再跟据主语先验信息和关系表达抽取三元组中所对应关系和宾语.Seq2Seq模型解码为
P(Y1,Y2,…,Yn|X)=P(Y1|X)P(Y2|X,Y1)…
P(Yn|X,Y1,…,Yn).
(1)
式(1)中,给定先验句子X对标签序列Y建模,使其生成Y1,Y2,…,Yn序列的概率最大似然.模型从输入的X得到第1个Y1标签,再将X和Y1标签作为特征再输入到Seq2Seq模型解码出Y2,以此类推,依次解码出Y3,Y4,…,Yn.由此可以类比得到三元组抽取式(2):
P(s,p,o|X)=P(s|X)×P(t|X,s)×
P(o|X,s,t).
(2)
式(2)中,给定输入句子X,抽取主语s并获取融合先验向量,再基于先验信息和句子X解码出关系p和宾语o.为抽取实体重叠三元组,本文采用分层标注方法,即在抽取主语时采用二进制序列标注方式,在抽取p和o时,每层标注序列产生的p和o都对应一种提前设定好的关系,保证最终生成的标注序列和预定义关系数量相同.
2.2 标注策略
本文在头实体和尾实体抽取过程中采用相同的头尾标注策略,结合标签信息进行解码抽取.图1的表示层和头实体向量抽取层是抽取主语时经过序列标注生成标签序列的一个示例.给定句子“B组链球菌(GBS)是新生儿肺炎的主要病原”,模型输出的主语开始序列中“新”对应的开始标签为1,代表其是主语的开头字符,然后从主语结束标签序列中的对应位置开始向后搜寻下一个字符对应的标签是否为1.如果对应标签为1,说明当前字符是主语的结束字符,主语提取完毕.最终从输入文本中提取出来的主语为“新生儿肺炎”.图1的关系表达向量抽取层、条件层规范化层及关系尾实体抽取层则是结合抽取的主语“新生儿肺炎”与关系表达的融合先验特征.模型再对句子序列进行标注并生成与主语关系表达相关的宾语标签序列,其标注方案同样采用头尾标注策略.基于宾语标签序列,采用相同的解码方法提取出输入文本对应的句子宾语“B组链球菌”,再根据宾语标签序列确定对应的关系类别“病因”,最终抽取出三元组(“新生儿肺炎”,“病因”,“B组链球菌”).从代表某一关系类别的宾语标签序列中提取的宾语表示该宾语和先验主语之间的关系为该类别.如果“B组链球菌”被判断为主语,模型会重复以上操作抽取出对应的三元组.由于该模型作用于限定域关系抽取,因此事先预定义的关系类型是固定的.
2.3 BERT编码层
本文使用bert_base_cased[43]作为预训练模型编码获得句子语义向量.先将输入文本的原始句子序列按字节对进行编码和分段标记.BERT模型处理后的输出是单词的上下文语义向量.通过词向量表将文本转换成包含语义信息的向量再输入到下层.例如对于“B组链球菌(GBS)是新生儿肺炎的主要病原”的样例文本,经过编码分段后得到每个字在词典中的序号和分段标号.此后,可以通过查询模型的词向量表得到对应位置的语义向量表示.
2.4 融合先验信息
受高速网络[44]启发,融合先验信息fusione由主语向量subjecte和关系表达向量triggere两部分组成,由H控制信息来源比例.获取融合先验信息时,各部分的计算为
subjecte=average(ehead+etail),
(3)
其中,ehead与etail分别表示主语头尾位置处的字向量,average()函数表示取平均.
pi=σ(Wsubject·xi+bsubject),
(4)
其中,pi表示序列中各个字参与到主语关系表达中的概率,xi表示文本各处的字向量表示,Wsubject表示主语变换向量,bsubject表示主语变换偏置.
(5)
H=sigmoid(W1·subjecte+W2·triggere),
(6)
其中,W1表示主语的变换向量,W2表示关系表达的变换向量.
fusione=(1-H)·subjecte+H·triggere.
(7)
式(3)用于获取主语向量,式(4)中的pi可以作为当前主语关系表达“触发词”的概率,式(5)用于获取关系表达向量,最终得到式(7)所示的融合先验信息fusione.
2.5 条件层规范化层
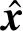
Fig. 2 The structure of conditional layer normalization图2 条件层规范化层的结构
由于BERT等预训练模型已经采用了层规范化层,使用了无条件的β和γ,且都是长度固定的向量.本文可以通过2个不同的变换矩阵,将输入条件变换到与β和γ一样的维度,然后将2个变换结果分别与β和γ相加.实现公式分别为:
Δγ=Wγ·fusione,
(8)
Δβ=Wβ·fusione,
(9)
γnew=γ+Δγ,
(10)
βnew=β+Δβ,
(11)
(12)
其中,Wγ和Wβ分别为γ和β维度对应的变换矩阵,用于先验向量维度转换;ε为辅助常量.
2.6 解码器

(13)
(14)
(15)
(16)

2.7 目标函数
对于数据集D和预定义关系集R,式(2)展开为
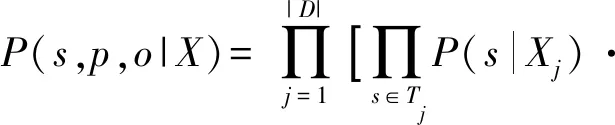
(17)
抽取头实体时采用句子原始向量,抽取头实体对应的关系和尾实体时采用先验信息融合的句子向量.
模型训练的目标函数为最大似然:
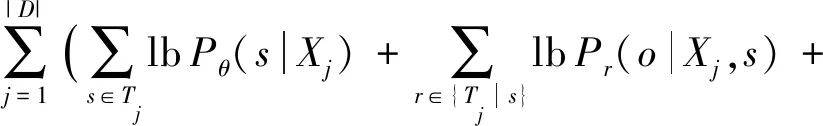
(18)
头实体和尾实体抽取时采用相同的头尾标注方式,其中头尾位置标记为1,其他标记为0.
其中Pθ(s|Xj),Pr(o|Xj,s),PØr(o|Xj,s)可展开为:
Pθ(s|Xj)=
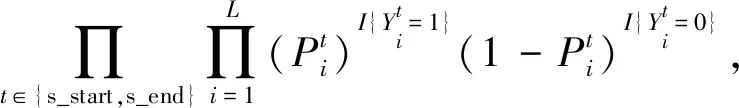
(19)
Pr(o|Xj,s)=PØr(o|Xj,s)=
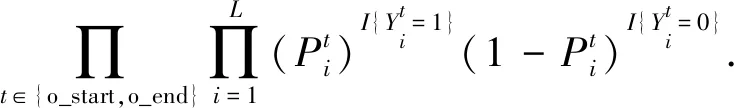
(20)
3 实验与结果
3.1 实验准备与实验背景
本文采用NYT[48]和WebNLG[49]数据集进行实验评估.其中,NYT数据集采用远程监督方式抽取自1987—2007年期间的118万个新闻句子,包含了24个预定义关系类型;WebNLG数据集最初为自然语言理解任务所创建,之后被改编在三元组抽取任务中,采用人工标注方式涵盖了171个预定义关系类型.NYT和WebNLG句子通常包含多个实体重叠三元组,因此采用这2个数据集作为基准,非常适合用于评估实体重叠三元组抽取的模型性能.
NYT和WebNLG数据集统计信息如表1和表2所示.实体三元组重叠类型包括常规实体(normal entity)、单实体重叠(single entity overlapping, SEO)和完全实体重叠(entity pair overlapping, EPO)三种类型.各类别示例如表3所示.值得说明的是,由于部分句子既包括单实体重叠又包括完全实体重叠,因此最后得到的所有类别实体总数会略小于以上3种类型之和.
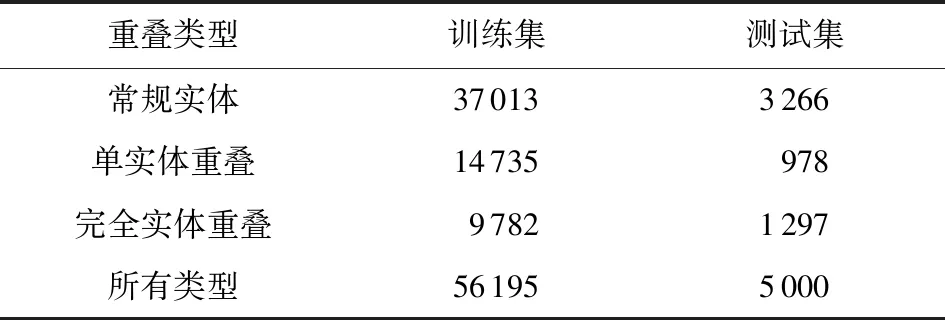
Table 1 Information of NYT Dataset表1 NYT数据集信息

Table 2 Information of WebNLG Dataset表2 WebNLG数据集信息
本文使用精确率(precision,P)、召回率(recall,R)和F1值(F1 score)三个指标验证模型的有效性,其中F1值是综合性评价指标.评价过程采用精确匹配,因此当且仅当预测产生的三元组与真实三元组的实体名称和类别完全匹配时,才看作正确识别的三元组预测.
本实验采用小批量梯度下降方式训练模型,批大小为6,使用Adam[50]优化器,学习率设置为10-5,在验证集上确定超参数,通过训练100轮,选取在验证集上效果表现最好的模型.使用的预训练BERT模型为[bert-base_cased],包含1.1亿个参数.概率阈值设置为0.5,句子最大长度设置为100,其CPU为8核Intel Core i9-9900k,内存为96 GB,GPU为GeForce GTX 2080Ti.

Table 3 Types of Entity Overlapping Examples表3 各类实体重叠示例
3.2 与其他三元组抽取方法的比较
由于本文着重解决联合抽取方法中的曝光偏置问题,因此将对比提出模型与各联合抽取模型的性能差异.基于此进行了3个实验验证模型的有效性.
第1个实验是对比所提出模型与其他模型在NYT和WebNLG上的整体性能评估来验证模型的有效性.实验结果如表4和表5所示.
从表4和表5中可以观察到,相较于现有的针对重叠三元组抽取模型,提出的模型在NYT上取得了最高的精确率、召回率及F1值,且在不损失或少损失精确率的前提下,模型在WebNLG上取得了目前最高的召回率和F1值,这表明本模型有更好的泛化能力.由于WDec模型只在NYT上进行了测试,故在WebNLG上缺失实验结果.
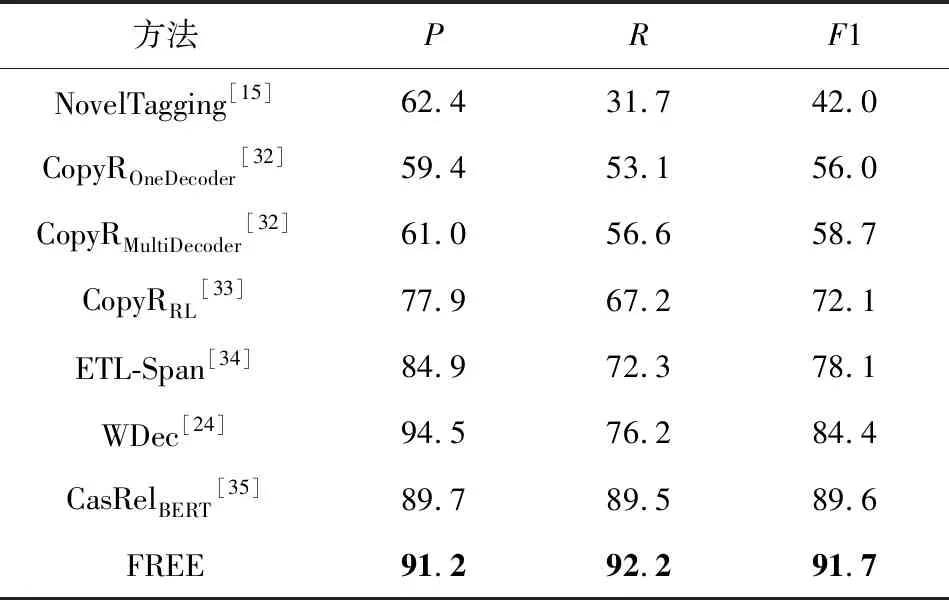
Table 4 The Overall Evaluation Results of Different Methods on NYT表4 不同方法在NYT上的整体性能评估 %

Table 5 The Overall Evaluation Results of Different Methods on WebNLG表5 不同方法在WebNLG上的整体性能评估 %
第2个实验是评估模型在应对不同实体重叠情况下的表现.进一步分析了模型在曝光偏差更为严重的实体重叠和句内存在若干个三元组情况下带来的性能影响.从图3~5可以发现,模型在3种不同三元组重叠情况下都取得了最高的F1值.
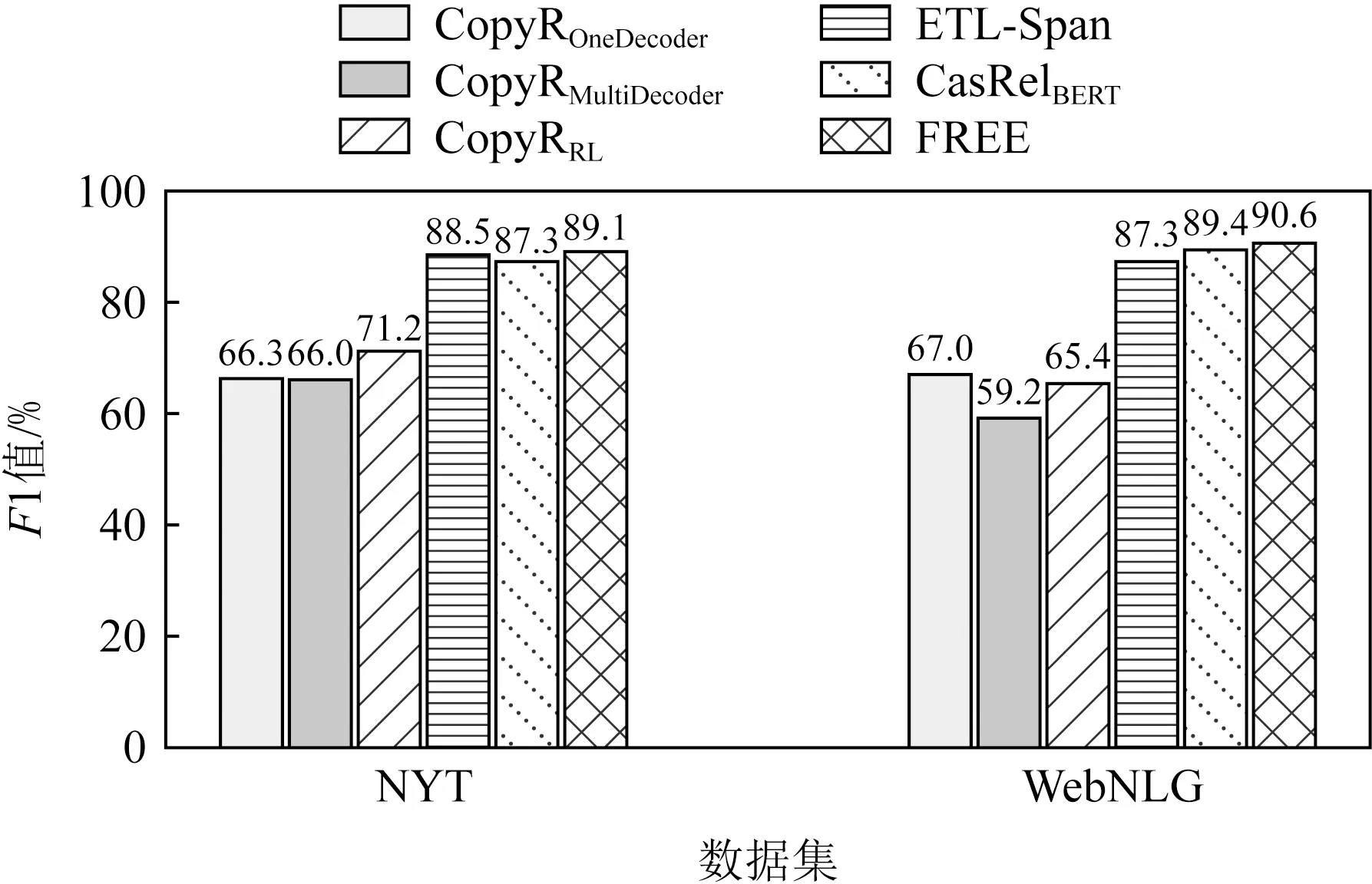
Fig. 3 F1 score of different methods on normaltype entities triplets图3 不同方法在常规实体三元组上的F1值

Fig. 4 F1 score of different methods on SEO type entities triplets图4 不同方法在单实体重叠三元组上的F1值

Fig. 5 F1 score of different methods on EPO type entities triplets图5 不同方法在完全实体重叠三元组上的F1值
通过实验分析,可以发现模型在不重叠的常规实体三元组上,分别带来了1.8%和1.2%的F1值提升.此外,模型基于单实体重叠和完全实体重叠也有较高的性能提升.相比目前最优的CasRelBERT模型,本文模型在单实体重叠情况下分别获得了2.2%和0.7%的F1值提升,在完全实体重叠情况下分别获得了2.3%和1.8%的F1值提升.由此可以观察到在实体重叠情况下的性能提升要高于常规情况.由于实体重叠时正确抽取三元组对模型的性能要求更高,这表明FREE能有效缓解曝光偏差,抽取出更加准确和完整的三元组.
第3个实验是评估了不同模型在处理句内存在多个三元组时的性能差异.如表6和表7所示,随着三元组数量的增多,所有模型的F1值都呈现了先升高后下降的趋势.但是本文所提出的模型在多数情况下表现出了最好或次好的性能.随着句内三元组个数的增多,模型表现稳定,特别是句内三元组个数大于4时带来了明显的性能提升.相比目前最优的CasRelBERT模型,本文模型分别取得了6.9%和1.4%的F1值提升.这表明本文通过引入关系表达信息使得模型可以更好地应对句内存在多个三元组的情况,具有更强的泛化能力.

Table 6 F1 Score of Different Methods on Different Triplet Number N in NYT表6 不同方法在NYT中不同三元组数量N上的F1值 %
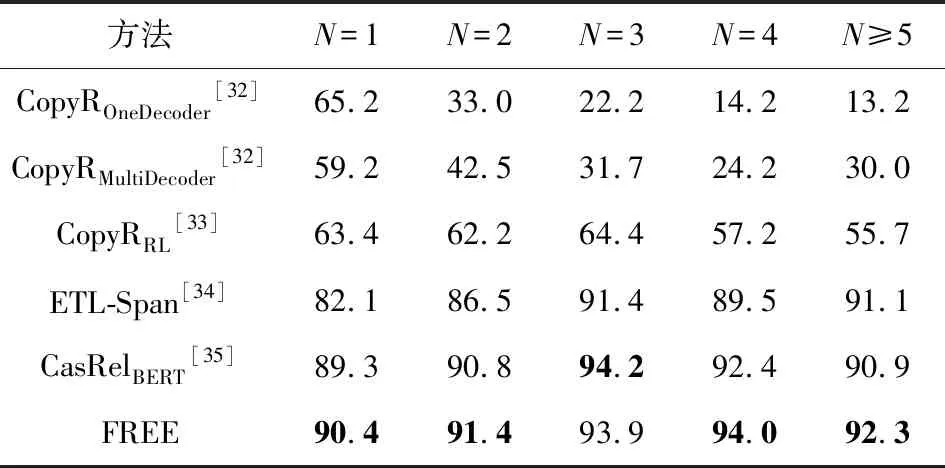
Table 7 F1 Score of Different Methods on Different Triplet Number N in WebNLG表7 不同方法在WebNLG中不同三元组数量N上的F1值 %
3.3 消融实验
为了分析模型各部分所起的作用,本文分别在NYT和WebNLG上进行了消融实验.实验结果如表8和表9所示:

Table 8 Ablation Experiment Evaluations of Different Methods on NYT表8 不同方法在NYT上的消融实验评估 %
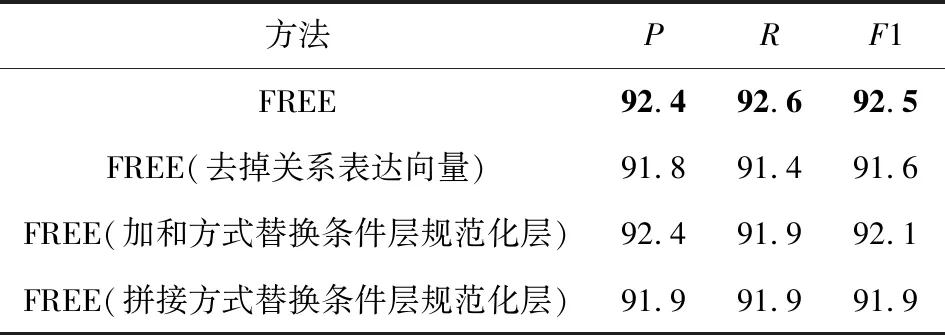
Table 9 Ablation Experiment Evaluations of Different Methods on WebNLG表9 不同方法在WebNLG上的消融实验评估 %
从表8和表9中可以看出,所提出的完整模型在2个数据集上都取得了最高的精确率、召回率和F1值.本模型由于添加关系表达向量,在2个数据集上的F1值分别提升了0.8%和0.9%.因为采取了条件层规范化层,F1值分别提升了0.8%和0.6%.这表明关系表达向量的引入可以进一步提高模型的召回率和准确率,条件层规范化层的引入可以更有效地实现特征融合,表明了模型有效地减少曝光偏差的影响,具有更好的泛化能力,可以抽取更多的三元组,同时进一步说明了模型各模块的有效性.
3.4 误差因素分析
通过3.2节和3.3节所述的实验分析,发现本文模型针对知识三元组抽取问题具有更好的性能.为了进一步探究影响模型提取关系三元组的因素,本文分析了模型针对三元组(E1,R,E2)中不同元素的预测性能,其中E1代表头实体,E2代表尾实体,R代表头尾实体之间的关系.
从表10可以观察到随着元素抽取复杂程度的提高,其精确率、召回率和F1值都呈下降趋势,这意味着在构建头实体、关系及尾实体三者间的交互中还有较大的提升空间.此外,相比CasRelBERT模型,本文模型通过引入关系表达信息,在不损失或较少损失精确率的前提下,召回率明显提升(>2.7%,>2.5%),从而取得了更高的F1值(>1.7%,>0.7%),即模型可以抽取出头实体所参与表达的更多关系.这表明模型减少了曝光偏差影响,具有更好的泛化能力.

Table 10 Results of Different Methods on Triple Elements Extraction表10 不同方法在三元组元素抽取上的结果 %
3.5 与其他模型的对比分析
本文选取了2个具有代表性的模型TPLinker和SPN,从采取的策略、模型表现和参数量以及训练和推理效率等方面进行了对比和分析.由于Seq2UMTree模型使用Bi-LSTM作为编码器,且使用了不同的评价指标,故本文并未将其纳入比较对象.如表11所示,本模型在这2个数据集上都取得了较好的表现.
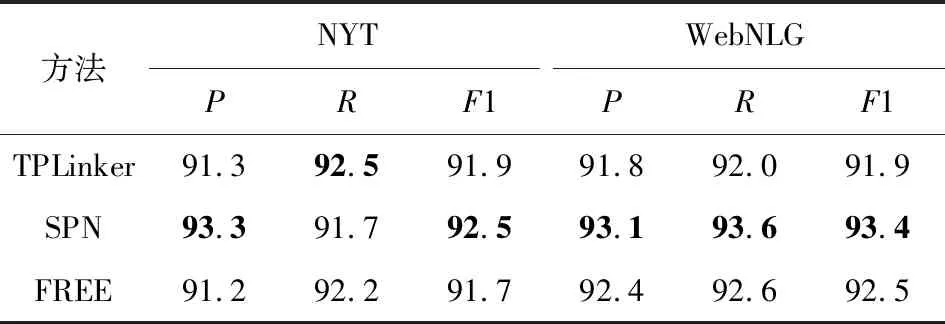
Table 11 Results of Different Methods on Triple Elements Extraction表11 不同方法在三元组元素抽取上的结果 %
从图6和图7中可以观察到,本文所提模型在验证集上取得了与SPN模型相当的性能,模型收敛速度也基本保持一致,且均优于TPLinker模型.
此外,从表12和表13中可以观察到,本文所提模型FREE的参数用量最少,在训练时效率也最高,而且并不需要额外的、复杂的预处理工作.
3.6 实例分析
本文挑选了3个具有代表性的例句进一步观察和说明本文模型与CasRelBERT[24]模型在2个数据集上对三元组的抽取结果差异,如表14所示.

Fig. 6 F1 score of different methods on NYT图6 不同方法在NYT上的F1值
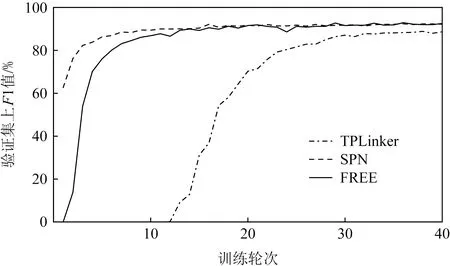
Fig. 7 F1 score of different methods on WebNLG图7 不同方法在WebNLG上的F1值
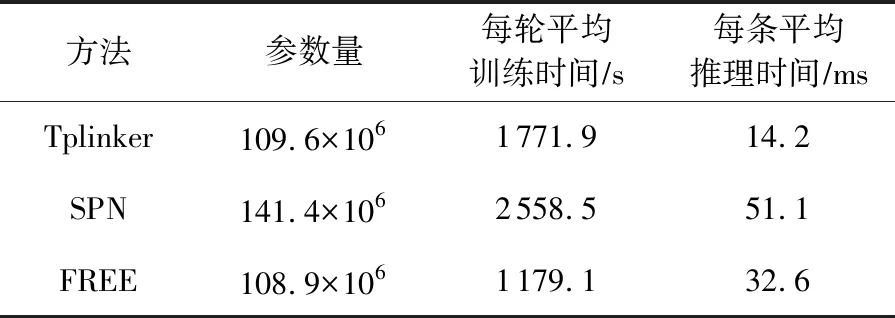
Table 12 Number of Parameters and Training Inference Time of Different Methods in NYT表12 不同方法在NYT上的参数量及训练推理时间
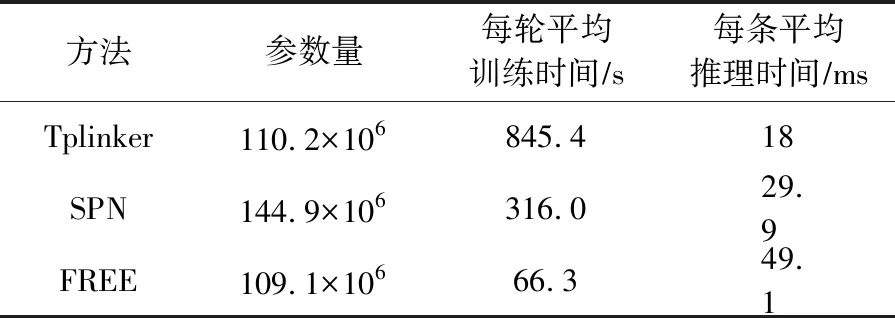
Table 13 Number of Parameters and Training Inference Time of Different Methods in WebNLG表13 不同方法在WebNLG上的参数量及训练推理时间
针对例句1,CasRelBERT模型由于存在曝光偏差所带来的误差累积和过拟合于频繁出现的标签组合问题,导致存在主语Dancer的抽取错误进而引起整体三元组的抽取错误,同时也无法抽取所有三元组.而本文模型由于融合了关系表达向量,可以正确地抽取所有头实体,并基于此抽取出正确的三元组.

Table 14 The Case Study Results表14 不同方法实例结果
例句1:English is the language in Great Britain and United States. A Loyal Character Dancer was published by Soho Press in the United States.
(language,spokenIn,Britain),(Dancer,publisher,Press),(States,language,language),(Press,country,States)
例句2:Cornell University in Ithaca,New York is the publisher of Administrative Science Quarterly. The University is affiliated with the Association of American Universities.
(University,city,York),(University,state,York),(University,affiliation,Universities),(Quarterly,publisher,University)
例句3:Elliot See was born in Dallas,which is a country in Texas. He attended the University of Texas at Austin,which is affiliated to the University of Texas system. The University of Texas at Austin will be part of the Big 12 Conference competition.
(See,birthplace,Dallas),(See,almaMater,Austin),(Austin,compete in,Conference),(Dallas,partsType,Texas)
在例句2中,由于单词University涉及到多个三元组,且city与state这2个关系较难区分,CasRelBERT模型只能考虑主语的先验信息,故此只能抽取部分三元组.而本文模型引入的关系表达信息进一步丰富先验信息,使得模型可以完整地抽取出所有的三元组.
从例句3的结果中可以发现,所提模型虽然弥补了部分CasRelBERT模型中头实体识别不完全的问题,识别出了正确的头实体和尾实体,但由于错误识别二者所属关系类别,因此得到了最后一行错误的三元组.本文认为导致该错误的原因,一方面是由于句子表达信息的缺失,另一方面是由于没有将包含尾实体约束的双向约束考虑在内.未来可以考虑构建双向约束,进一步提升模型的鲁棒性和泛化性能.
4 总 结
现有的联合抽取模型往往采用阶段式的联合抽取方法,存在严重的曝光偏差现象,同时倾向于过拟合频繁出现的标签组合,进而影响泛化性能.本文提出了一种名为融合关系表达向量(FREE)的新方法,通过融合关系表达信息来有效缓解曝光偏差问题.此外,提出了一种称为条件层规范化层的新特征融合层来有效地融合先验信息.本文在2个公开的实体关系抽取数据集上进行了大量实验.实验结果表明,在NYT和WebNLG数据集上分别取得了91.7%和92.5%的F1值.对实验结果深入分析表明,FREE相较于当前的基线模型具有显著优势,可以有效地缓解曝光偏差.本文与其他模型的对比分析发现,本模型在训练参数用量最少且训练时间最少的情况下,取得了较好的表现.同时,针对3个具有代表性的例句,进一步观察和分析本模型与其他模型在三元组抽取结果中的差异.综上表明,本文方法FREE能够有效地适应多种三元组抽取任务.
未来将探索词性、句法依存等额外特征对联合抽取的影响,同时深入研究头尾实体的双向约束以及关系之间的约束机制来进一步提升模型性能.
作者贡献声明:王震完成本研究的实验设计和执行,完成数据分析与论文初稿的写作;范红杰指导实验设计,完成论文写作与修改;柳军飞指导实验设计与数据分析.全体作者都阅读并同意最终的文本.
猜你喜欢
中国音乐学(2022年1期)2022-05-05
新高考·高一数学(2022年3期)2022-04-28
客联(2021年9期)2021-11-07
考试与评价·高一版(2020年2期)2020-10-29
疯狂英语·新阅版(2019年11期)2019-09-10
成都理工大学学报·社会科学版(2017年4期)2017-09-08
新高考·英语进阶(高二高三)(2016年11期)2017-07-07
岁月(2016年5期)2016-08-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
