
基于LightGBM-SVR-LSTM的停车区车位预测
2022-08-24 05:52杨培红哈元元余智鑫赵建东
科学技术与工程 2022年20期
杨培红, 哈元元, 余智鑫, 赵建东*
(1.青海省高速公路运营管理有限公司, 西宁 810008; 2.北京交科公路勘察设计研究院有限公司, 北京 100083; 3.北京交通大学交通运输学院, 北京 100044)
中国汽车保有量处于持续增长的状态,停车难和交通拥挤的现象愈演愈烈。停车区附近的诱导指示牌上会显示当前时刻的剩余车位信息,但停车信息随时间动态变化,剩余车位信息时与车辆到达停车地点后的实际剩余车位可能存在差异[1]。此外,驾驶员在寻找泊车位时的无效巡游会产生无效交通[2],进而可能增加拥挤程度,制约城市的发展[3]。准确地预测停车区剩余空车位,可以为驾驶员提供更加全面的诱导信息,从而协助他们做出合理的停车判断,缩短无效交通时间,改善交通状况。
针对停车区剩余车位的预测,目前主要有基于数理统计的方法和基于非线性理论的方法。基于数理统计的方法是指采用统计理论对历史数据进行分析,从而预测未来的可用停车位数据。此类模型预测方法步骤简单,然而难以精确拟合历史的复杂非线性数据。Caicedo等[4]提出了基于自回归移动平均(autoregressive integrated moving average,ARIMA)模型的停车区剩余停车位预测模型,但停车位占用率较高时,预测精度较低。张雷等[5]提出了基于向量自回归预测的泊位预测算法,以重庆市为实验对象,验证了算法的可行性。汤俊钦[6]根据停车区间的不确定性关系,建立了多元线性回归模型,通过对厦门市不同停车区的停车需求研究验证了算法的可行度。
非线性预测模型指以神经网络、决策树等理论为基础,建立相应的预测模型。此类预测模型能够很好地拟合停车区空闲停车位与时间的非线性特征,但计算过程非常复杂。裘瑞清等[7]用长短时记忆神经网络(long short-term memory neural network,LSTM)循环神经网络,对区域内泊位需求进行预测,能够比传统方法在结果上更加接近实际值,并且精度较为满意,表明该预测方法可行有效。韩锟等[8]通过关联积分法(cross-correlation,C-C)进行相空间重构,并利用遗传算法优化小波神经网络,实验证明,该方法具有良好的预测精度。刘东辉等[9]提出了一种利用粒子群优化算法(particle swarm optimization algorithm,PSO)优化LSTM的剩余车位预测模型,在不同场景下,精度均优于LSTM模型。Mei等[10]将傅里叶变换(fourier transform,FT)的思想与机器学习方法中的最小二乘支持向量回归(least squares support vector regression,LSSVR)相结合进行剩余车位的多步预测,效果优于传统的LSSVR模型。
由于深度学习和机器学习领域的发展,相关模型在智慧交通领域应用变得更加广泛。对于停车区剩余车位的预测,目前主要是通过单个模型或者利用启发式算法优化单个模型进行预测,但是这些预测方式存在一定的不足:一是难以找到合适的特征,模型效果不能充分发挥;二是容易受噪声点的影响,难以准确拟合停车区剩余车位在不同场合的变化情况;三是对预测过程中产生的数据未能有效利用。
为此,提出了一种LightGBM-SVR-LSTM的预测模型,[轻量级梯度提升机(light gradient boosting machine,LightGBM)、支持向量回归模型(support vector regression,SVR)、LSTM]。首先利用小波分析对异常数据进行识别,并利用KNN模型修复异常值;然后相比于传统的单变量预测或者通过经验设置特征的方法增加预测精度,采用LightGBM模型,将叶子节点的值作为新的特征,放入次级的SVR模型进行预测;针对组合模型预测产生的误差,利用LSTM进行误差修复;最后利用某停车区数据验证模型的有效性。
1 数据预处理
采集的数据中存在一些噪声数据,需要其进行修复处理。采取小波分析与K最近邻(K-nearest neighbor,KNN)模型结合,将数据进行降噪处理。
小波分析(wavelet denoising, WD)是由Donoho等[11]提出的方法发展而来,其原理是抑制信号中的噪声部分,保留原始特征。通过小波分析可以让样本的非平稳特征得到很好的保留;用小波变换对信号进行去相关的操作,得到的噪声将趋于自噪声,从而得到更精确或理想效果。小波分析的理论中,一维噪声模型可表示为
zst=ort+et,t=1,2,…,n
(1)
式(1)中:zst为噪声信号;ort为原始信号;et为高斯噪声;n为信号长度。
将小波分析得到的高频滤波全部置为零,则低频分量即为重构后的数据序列。将原始数据序列与重构的数据相减,得到残差数据序列。为了尽可能多的保留原始数据特征,对于残差序列,采用3σ原则进行异常数据识别(距离均值3倍标准差外的数据均视为异常值)。为了提高异常数据修复效果,进一步改善数据质量,结合KNN法对噪声数据的敏感度较低的特性,构建基于KNN的异常数据修复模型。
2 空车位数量预测模型搭建
构建时间序列预测的模型时,需要考虑其对整体数据的周期性、连续性和趋势的拟合程度,还要具备一定的泛化能力,以便减小异常值对模型拟合峰值的影响。基于此,构建了基于LightGBM-SVR-LSTM的组合模型。
2.1 LightGBM
LightGBM是梯度提升决策树(gradient boosting decision tree,GBDT)的一种新的框架[12],相比于GBDT,LightGBM做了多个优化:使用直方图加速、使用leaf-wise的叶子生长策略代替level-wise、支持类别特征等。LightGBM解决了GBDT原始模型面对大量数据时,计算速度慢的问题,在训练过程中,LightGBM的目标函数可表示为
(2)
(3)
(4)
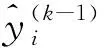
2.2 SVR
SVR是一种基于统计学习的理论,进行回归计算的机器学习算法。该方法在理论上可以得到问题的全局最优解,且计算过程复杂程度与样本维数无关,在函数逼近、回归预测等方面能够达到较好的效果,其原理可表示为
(5)
式(5)中:ε为拟合精度;约束条件中的w为权值向量;b为偏移常量;x′i为输入向量。
2.3 LSTM
LSTM是RNN的一种改进[13],在内部增加了门结构:输入门、遗忘门和输出门。通过这结构,调整输入与隐藏层的值[14],计算过程如下。
ft=σ(Wf[ht-1,xt]+bf)
(6)
it=σ(Wi[ht-1,xt]+bi)
(7)
(8)
(9)
ot=σ(Wo[ht-1,xt]+bo)
(10)
ht=ottanh(Ct)
(11)

2.4 组合模型
选取合适的特征以及模型,可以最大限度地将预测值逼近真实数据。在特征选择时,如果添加的特征不足,会造成模型预测精度不高,产生欠拟合的情况;如果添加的特征过多,一方面,可能引入一些无关的变量,降低模型的预测效果;另一方面,当模型输入维数过高,可能产生过拟合的现象,降低模型的精度以及鲁棒性。按照经验来添加特征变量,很容易产生上述问题。对于决策树模型,在进行预测时,会首先生成叶子节点,由叶子节点的值,得到最终的预测值。采用LightGBM模型,通过训练,获得叶子节点值,作为特征向量,以解决传统的按照经验确定特征可能带来的不利因素。
将LightGBM模型的叶子节点输出后,数据维度较高,为了避免因为过拟合,降低模型效果,本文选择使用SVR进行预测。SVR模型可以有效地适应高维数据,且方法简单,不容易产生过拟合。为了进一步提升模型精度,采用网格搜索,对各模型的超参数进行寻优,确定最佳超参数。
LSTM拥有长时记忆功能,能够有效地识别数据的周期性、趋势性,对于处理时间序列数据有良好的效果。因此将LightGBM-SVR的预测值输出后,将其与真实数据的残差序列提取出来,利用LSTM模型进行误差修复,并通过网格搜索,确定最佳的超参数,提升模型的预测精度。
3 实例分析
选取某停车区在2017年10月—2018年2月的数据进行实验,数据为每小时统计一次。将数据集按照6∶2∶2划分为训练集、验证集和测试集。
3.1 数据预处理
对于停车区剩余车位数据,更好的时频特性是主要的,为了保持数据良好的光滑性,选择常用的db4小波进行去噪,效果如图1所示。
s=d1+d2+d3+a3
(12)
式(12)中:s为原始信号;a3为低频信号;d1、d2、d3为高频信号。

图1 小波分析结果Fig.1 Results of wavelet analysis
将分解获得的3层高频分量置零,低频分量a3即为重构后的数据序列。根据3σ原则对残差值进行识别异常值,利用KNN算法进行异常数据修复。部分结果如图2所示。

图2 异常数据修复结果对比Fig.2 Comparison of abnormal data repair results
3.2 预测效果对比
为了检验模型的效果,主要采用均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)、平均百分比误差(mean absolute percentage error,MAPE)3种指标来量化预测误差,其计算公式分别为
(13)
(14)
(15)

将处理后的数据进行训练,并通过网格搜索确定各预测模型的最佳超参数。其中,LightGBM超参数如下:行采样设置为0.7, 每4次迭代执行装袋操作,列采样设置为0.9, 每棵树的叶子数量设置为25,树的数量设置为300。SVR的超参数如下:惩罚系数设置为100,径向基函数的系数设置为0.01;考虑到数据有限,LSTM中间层只设置一层,其余超参数设置为:训练次数设为50,神经元个数设置为35,训练的批大小设置为16。
将提出的组合模型,与选择常见的交通流预测模型SVR、LSTM、LightGBM、门控神经网络(gate recurrent unit,GRU)进行预测效果对比。选取正常时间段,以及节假日(新年)期间,两种场景进行验证。
3.2.1 正常时段
从图3中可以看出,所提出的模型相比于其他单个模型,具有更好的拟合效果。从表1中可以看出,在正常时间段,相比于常用的单个模型,LightGBM-SVR组合模型在RMSE上,提升了3.6%,MAE提升了19.6%,MAPE提升了30.5%;加入LSTM进行误差修复后,相比于原始组合模型,RMSE又提升了19.3%,MAE提升了11.9%,MAPE提升了14%。因此,提出的LightGBM-SVR-LSTM模型具有较高的精度。
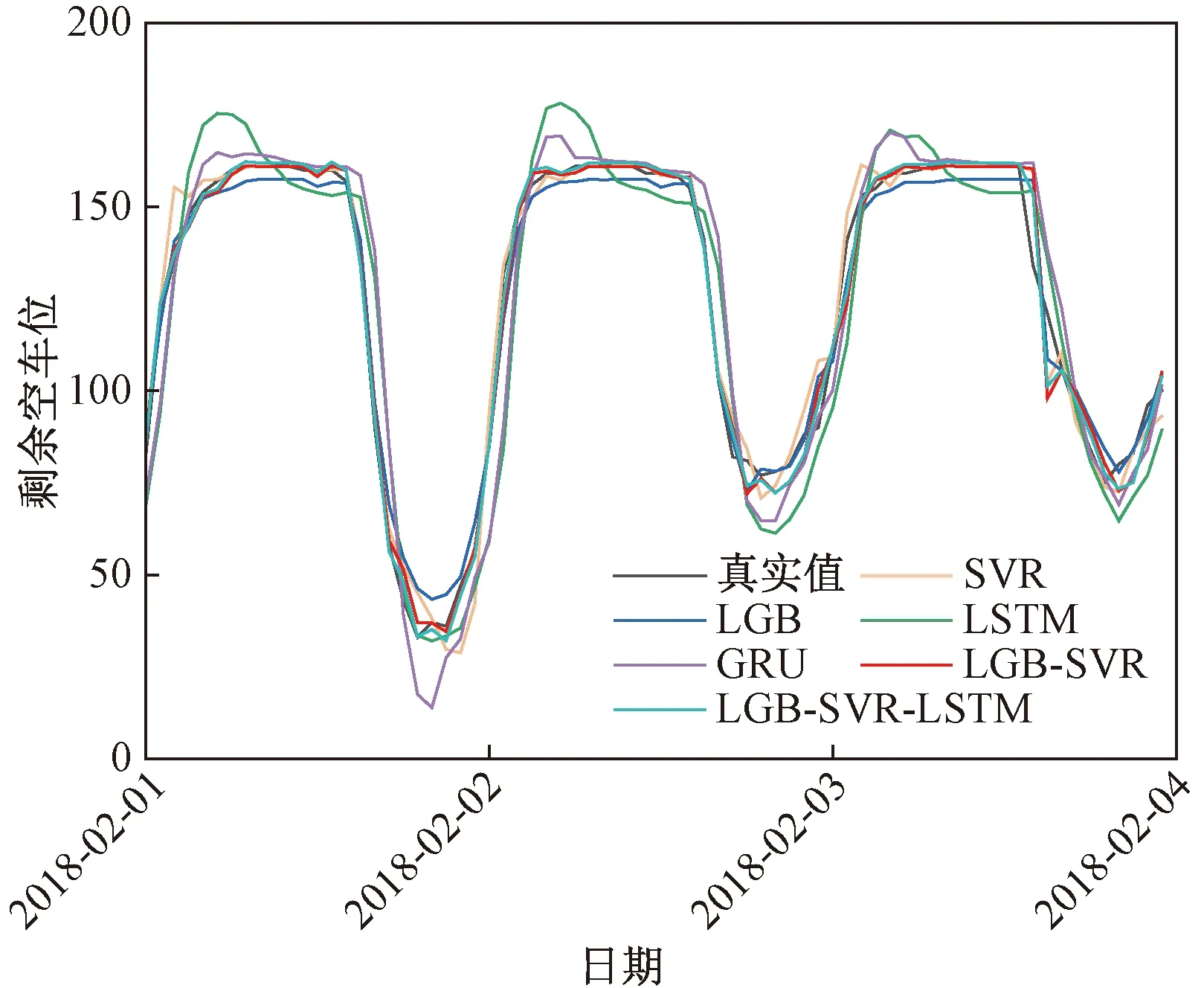
轻量级梯度提升机(light gradient boosting machine, LGB)图3 正常时间段预测效果对比Fig.3 Comparison of prediction results in normal conditions
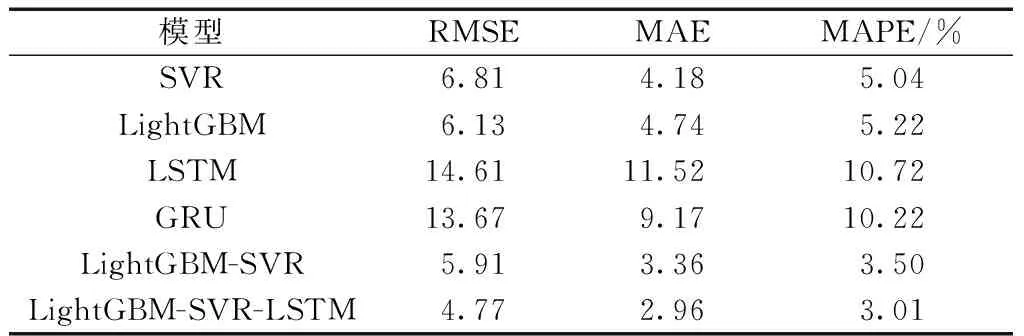
表1 正常时间段预测效果对比Table 1 Comparison of prediction results in normal conditions
3.2.2 节假日期间
从图4可以看出,所提出的模型相比于其它单个模型,具有更好的拟合效果。从表2中可以看出,在节假日时间段,相比于常用的单个模型,LightGBM-SVR组合模型在RMSE上,提升了5.5%,MAE提升了10.6%,MAPE提升了0.9%;加入LSTM进行误差修复后,相比于原始组合模型,RMSE提升了20.0%,MAE提升了21.7%,MAPE提升了25.0%。因此,在节假日期间,提出的LightGBM-SVR-LSTM模型也具有较高的精度。

图4 节假日时间段预测效果对比Fig.4 Comparison of prediction results during holidays

表2 节假日时间段预测效果对比Table 2 Comparison of prediction results during holidays
4 结论
提出了一种基于LightGBM-SVR-LSTM的停车区剩余车位短时预测组合模型,并利用某停车区历史数据进行验证,根据实例分析结果,得到以下结论。
(1)通过小波分析结合3σ原则可以进行数据清洗,并保留原始数据特征;再结合KNN模型对噪声数据敏感性低的特点,可以用其来进行异常数据修复。
(2)相比于手动构造特征,LightGBM可以有效地进行特征提取,将提取的特征放入SVR模型,可以提升预测精度。在正常时间段,相比于常用的单个模型,LightGBM-SVR组合模型在RMSE上,提升了3.6%,MAE提升了29.1%,MAPE提升了30.5%;在节假日时间段,相比于常用的单个模型,LightGBM-SVR组合模型在RMSE上,提升了5.5%,MAE提升了10.6%,MAPE提升了0.9%。
(3)利用LSTM进行模型预测误差修复,能够提升模型的预测精度,在正常条件下,相比于组合模型,RMSE提升了19.3%,MAE提升了11.9%,MAPE提升了14%;在节假日条件下,相比于组合模型,RMSE提升了20.0%,MAE提升了21.7%,MAPE提升了25.0%;该组合模型的预测精度高于其他模型,并具有较好的鲁棒性。
猜你喜欢
汽车画刊(2020年5期)2020-10-20
今日农业(2020年13期)2020-08-24
祝您健康·文摘版(2020年3期)2020-04-09
劳动保护(2019年3期)2019-05-16
现代家长(2018年11期)2018-01-05
意林(2017年8期)2017-05-02
新东方英语(2016年11期)2016-11-11
噪声与振动控制(2015年4期)2015-01-01
中国药业(2014年21期)2014-05-26
振动、测试与诊断(2014年4期)2014-03-01
