
一种基于网络表示学习的网络安全用户发现方法*
2022-08-23 06:49刘向宇孟星妤侯开茂
网络安全与数据管理 2022年7期
刘向宇,燕 玮,孟星妤,侯开茂
(华北计算机系统工程研究所,北京 100083)
0 引言
发现社交媒体中的网络安全用户可以有效追踪网络安全动态,对网络安全防护具有重要意义。实际上,识别社交网络中的网络安全用户也是对社交网络节点进行分类发现。
现实生活中,人们倾向于与类似的人发展社会关系,所以社交用户的好友会分享更多的属性,如种族、民族、宗教和职业——这就是所谓的“同质性原则”[1]。这导致了在Twitter上相互关注的人通常有共同的话题兴趣,可以通过相互关注关系来推断社交媒体用户的属性。另外,社交用户还具备其他可以获取的数据,如社交文本和用户资料,这些资料构成新的用户属性,也有助于推断用户的兴趣或者职业,与用户的社交关系形成互补。
当前已经有大量的用户分类工作都是基于网络拓扑结构进行节点的分类。比如,网络表示学习方法直接对网络结构特征进行学习提取,将得到的特征用于分类可以取得不错的效果。然而,现有的网络表示学习方法缺乏对社交文本和社交基本资料特征的学习,极大地限制了其分类效果。相对于单纯利用社交网络结构对用户进行分类,当前主流的图神经网络算法创新性地融入了网络节点的其他属性特征,获得了更高的分类准确率。本文针对网络表示学习方法缺乏社交文本特征的问题,通过改进Node2vec[2]方法,使其融合多种网络属性特征而更加有利于分类,从而识别出社交媒体中的网络安全用户。
本文的创新性工作包括:
(1)利用网络表示学习模型Node2vec来进行网络节点的特征表示,将结构特征向量和相应用户节点的文本特征向量进行拼接,形成社交用户节点的向量表示。
(2)标注了部分网络安全用户,初步形成网络安全用户资料库。对于每个用户节点,生成其网络安全文本特征。
(3)利用自监督学习方法进行分类模型的训练样本扩充,提升了分类效果。
结果表明,在已经收集的Twitter数据集上,所提方法的平均识别准确率为96.37%,比现有常用的算法平均高出0.48%~3.67%。
1 相关工作
本文通过对社交媒体用户进行分类来发现网络安全用户。首先,基于好友的特点进行分类,随着自然语言处理的兴起,出现了基于社交文本的分类方法[3-4]。而近年来,结合社交网络拓扑和社交用户属性的方法逐渐引起关注,比如[5-6]等。
2014年Bryan Perozzi等人根据Word2vec对词的嵌入方法,提出Deepwalk[7]模型。此模型将节点看作是自然语言处理中的单词,利用随机游走采集节点的方式,将得到的序列看作是语句,采集到节点语句后用自然语言处理中的Skip gram模型进行向量的学习,得到每一个节点的向量表示。2016年斯坦福大学的Grover和Leskovec提出Node2vec,对Deepwalk模型进行了改进,可以支持有向图的表示学习,并且提出了新的游走方法。通过调节游走的参数,取得比较好的节点表示效果。同样在2016年,Kip提出了GCN[8]模型,将卷积神经网路的理论应用到图结构上。2019年Pan[9]等人将GCN理论应用到社交用户职业分类上,分类效果好于众多的网络表示学习的方法。随着图神经网络的兴起,2017年Graph-Sage[10]和GAT[11]模型被提出。GraphSage通过聚合邻居节点特征的方式来生成目标节点的特征,相对于GCN,这种方法可以显著提升特征生成灵活性。同时,利用batch-training的方法,提升了训练效率。GAT模型的创新之处是加入attention机制,给节点之间的边不同的权重,帮助模型学习网络的结构信息。Cao等人于2018年提出基于自编码器的社区发现算法,分别对网络拓扑和节点属性进行向量表示然后拼接进行分类。2019年提出的NOCD[12]模型基于GCN和伯努利泊松分布,学得节点和类别的隶属关系矩阵,矩阵中的每个元素表示节点属于某个类别的概率,当概率值大于0.5即判定其属于此类别。此方法是一个多标签分类方法,最终每个节点属于多个不同的类别,在重叠社区发现方面取得不错的效果。
除社交关系和文本信息外,2014年Huang[13]等人将社交网络其他信息(如简介信息和转发信息等)加入进行分类。2017年Liao[14]等人将结构信息和其他属性信息同时输入深度神经网络,实现非线性特征抽象,相对于传统的图神经网络模型,有较大性能提升。具体的向量表示方式如表1所示。

表1 社交网络用户向量表示
以上工作并没有针对某一特定领域进行分类,且学到的社交节点的向量表示没有结合用户文本和基本信息等多种特征。
2 算法描述
为了解决现有用户分类方法在语义特征提取的不足,本文提出了新的社交用户分类方法,包括三个阶段:首先进行网络表示学习学得社交网络节点的结构特征;然后将结构特征与人工提取的语义特征进行拼接得到社交节点的特征向量;最后用逻辑回归模型(Logistic Regression,LR)[15]进行分类预测网络安全用户。具体各阶段介绍如下。
2.1 网络表示学习算法Node2vec
网络表示学习也称为图嵌入是将图网络结构中的节点、边或者整体表示为一个低维度的向量,此向量被称为嵌入向量。Node2vec的节点采样方法比较灵活,结合了两种节点采样方式,如图1所示。
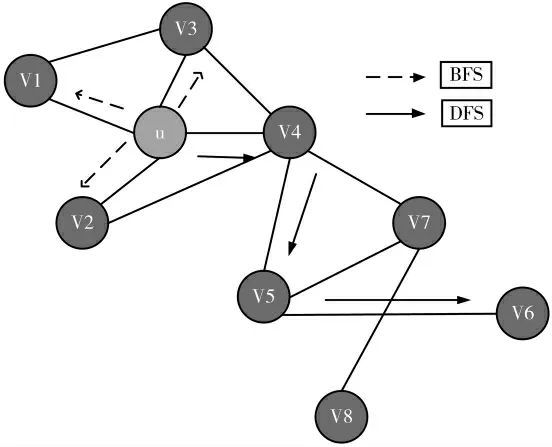
图1 两种节点采样方式
虚线箭头表示广度优先游走BFS,实线箭头表示深度优先游走DFS,是两种极端的节点采样方法,分别适用于提取结构等价性和同质性的网络节点特征。广度优先游走算法能够表达网络节点的同质性,深度优先游走可以表达网络节点的结构对等性[2]。然而,现实中的网络根据结构的不同,需要结合两种游走方法,才可以比较好地提取到特征。
对于Node2vec的游走采样方法如图2所示,上一步在节点u,当前游走在节点v。通过控制游走的参数来控制广度优先和深度优先的比例,根据式(1)计算出下一步游走到节点x1,x2,x3或者回到节点u的概率。
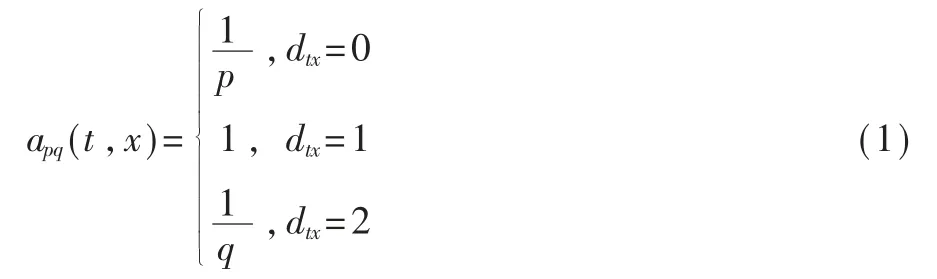
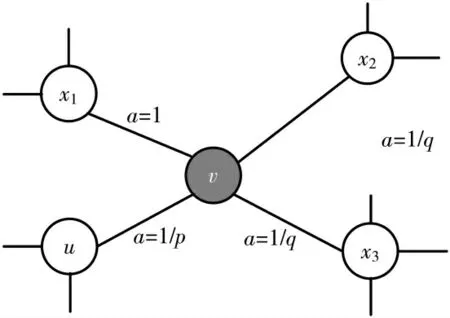
图2 Node2vec游走采样图
式中,p被称为返回参数(return parameter),q被称为进出参数(in-out parameter)。当算法随机游走到节点v时,p越小,下一步走到u的可能性越大,即游走到相邻节点的可能性越大;q越小,Node2vec中深度优先游走成分会更多,则随机游走到远处节点的可能性越大,更能表达网络节点的结构对等性。所以针对不同的网络特性,控制p,q的值可以保留更多网络的特征。
2.2 二分类算法
2.2.1 逻辑回归
逻辑回归是机器学习中的经典分类方法,二项逻辑回归模型是一种二分类模型,模型具体形式如下:

其中,P(yi=1|xi)是第i个样本xi条件下,事件yi=1发生的概率,记作Pi(0<Pi<1)。同理,P(yi=0|xi)也可以求得。LR比较二者的大小,将实例xi判断到概率值较大的那一类。本文使用了Sklearn库中的二项逻辑回归算法进行分类。
2.2.2 支持向量机
支持向量机(Supported Vector Machine,SVM)[16]也是经典的二分类算法。当训练集线性可分时,SVM的目标是构造线性最优解分类超平面w·x+b=0,这个超平面可以将两类数据完全分类,并使分类间隔最大,即使得此平面到两类数据的距离最大。所以,可以表示为一个凸二次规划问题,如式(4)所示。
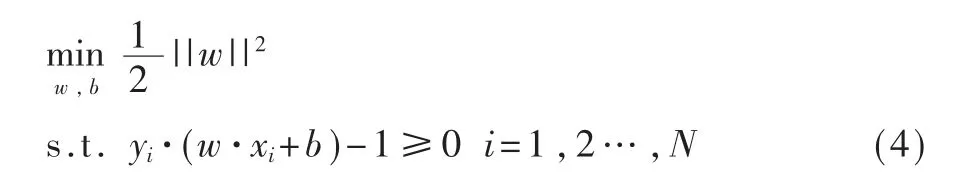
求得最优化问题的解是w*,b*,分离超平面是w·xi+b=0,决策函数是:

现实中训练数据线性可分的情况较少,但是近似线性可分的情况较多,当训练集线性不可分时,一般使用线性支持向量机或者软间隔支持向量机。对于非线性分类问题,可以通过非线性变换将它转化为某个高维特征空间中的线性分类问题。在高维线性特征空间中学习线性支持向量机[17]。
2.3 网络安全特征的处理
本文收集到的社交媒体数据中包括关系数据、文本数据和基本信息数据。将所有用户的文本和基本信息数据进行整理,提取并挑选了256个网络安全词汇,组成一个网络安全词汇向量:

根据向量V对节点进行one-hot编码,组成一个256维的0/1向量。如果一个用户节点的社交文本和基本信息有相应的网络安全单词,则在对应维度上标注为1,没有则为0。此向量即用户节点的网络安全特征向量。将每个用户节点的特征向量和利用Node2vec生成的特征向量拼接,得到用户节点最终的表示向量。利用此节点表示向量进行下游任务完成网络安全用户的分类识别。
2.4 算法时间复杂度分析
算法的时间复杂度与网络节点的数量n有关。Node2vec算法自身引入了别名采样提高采样效率,每次采样的时间复杂度为O(1),采样模块的复杂度为O(rln),r为采样迭代次数,l是随机游走的长度。Skipgram模块特征生成时间为O(nlogn),Node2vec的算法复杂度为O(nlogn)。因为向量拼接和逻辑回归分类的时间复杂度也是线性的,所以算法的时间复杂度为线性时间复杂度O(nlogn)。
3 实验
3.1 实验环境和数据
实验环境采用的服务器配置为CPU:Intel®Xeon®CPU E5-2640 v3@2.60 GHz(8核16线程),采用的操作系统为Ubuntu 16.04 LTS,算法实现的语言及版本为Python 3.9以及PyTorch 2.0。
本文将收集的用户关系数据、文本数据和基本信息数据应用于不同的图神经网络算法(如GCN、GAT、Graphsage)和表示学习算法(如Deepwalk等),来发现网络安全用户。由于网络安全用户在社交媒体上分布较为稀疏,本文根据100个网络安全关键词,选择一部分含有网络安全用户较多的社交媒体,总共收集了30 000个社交媒体用户和相关的用户基本信息。将大型的社交网络分割为3个不同大小级别的社交网络以验证Node2vec和LR结合分类准确率。三种网络的节点规模分别是275,2 005,15 000。不同规模的社交网络如图3所示。

图3 不同规模Twitter网络
3.2 实验结果与分析
将用户的属性特征和网络拓扑特征作为图神经网络的输入,每个图神经网络都经过至少100个epoch训练。Deepwalk和Node2vec的嵌入维度设置为256,游走节点的序列长度为15,Node2vec的p值设置为0.25,q值设置为4。最终,本文所提的算法(Node2vec+LR)与现有常用图模型(GCN、GAT、Deepwalk+LR)的预测准确率对比如表2所示。

表2 不同模型分类准确率 (%)
由表2可知,Node2vec与LR的组合可获得最高的平均分类准确率96.37%。且在网络节点规模为275时,准确率最高。比现有常用的其他网络表示学习算法和图神经网络算法平均高出0.48%~3.67%。可以发现,表示学习加二分类的方法适合用于网络安全用户发现。本文也将SVM用于分类,其结果和LR相近但是耗时较长不适合用于规模较大的网络。
因为用机器学习分类算法进行分类需要标注一部分网络安全数据,本文人工标注了1 000条Twitter数据。找到其中的1 000条用户数据。对于规模相对较大的社交网络,训练量仍然太少,因此本文采取了自训练的方法来进行扩充数据集。先用分类算法在包含标注数据的网络上进行预测。取1 000条数据进行训练,300条数据用于验证,逐渐将训练集扩充到8 000,用2 000条数据进行测试。最后,将结果与不进行训练集扩充的对照组进行精确率和F1-Score的对比。
F1-Score也是分类问题的一个衡量指标,它是精确率和召回率的调和平均数,最大为1,最小为0。定义如式(6)所示:

如图5所示,自训练组精确率最高可以达到90.40%,平均高于对照组3.38%。图6中,自训练组F1-Score明显高于对照组,在所有的实验数据集上F1-Score均高于88%,最高可达89.43%,平均高于对照组4.16%。这充分说明模型的训练集规模的增加有助于提高精确率和F1-Score。在一定的数量下,随着训练节点数量的增多,训练得到的模型更加精确。值得说明的是,在嵌入维度的选择上本文选择256,当嵌入维度减小时精确率会有明显的下降,当超过300后提升效果不明显。
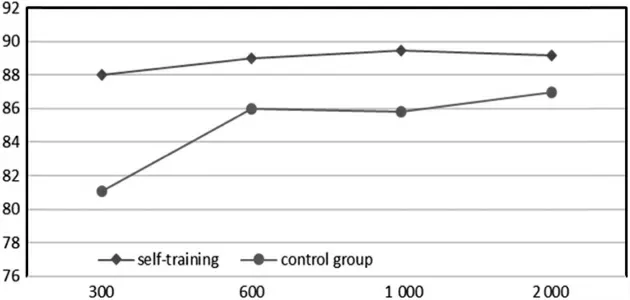
图5 F1-Score对比(单位:%)

图4 精确率对比(单位:%)
4 结论
本文通过人工添加网络安全语义特征,并与网络表示学习结合的方式来生成社交网络节点的特征表示,使得表示向量包含了节点的语义特征和结构特征。利用经典的机器学习二分类方法进行网络安全用户的预测。预测效果优于常用的图神经网络算法,并且验证了通过自训练的方法对于预测效果有积极的影响。未来可以继续扩充语料库,改进语义和网络拓扑两类特征的拼接方式,用更加精确的表示学习或者图神经网络方法进行更多特征的融合,来发现特定领域的社交用户。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
计算机应用与软件(2021年10期)2021-10-15
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
科学大众(中学)(2019年2期)2019-04-08
小学生必读(中年级版)(2018年4期)2018-07-05
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
