
叶分量分析(LCA)在静态图像识别中的应用①
2022-08-23 12:12崔莹
佳木斯大学学报(自然科学版) 2022年4期
崔 莹
(铜陵职业技术学院信息工程系,安徽 铜陵 244000)
0 引 言
在具有较高维数的数据中,子空间方法通过一组基向量生成的子空间来表征结构化信息[1]。子空间方法可以分为主分量分析法(PCA)、叶分量分析(LCA)以及独立分量分析法(ICA)等[2,3]。PCA,ICA和LCA是并列的三种提取分量的方法,有一定区别的,例如PCA要求观测样本集合的协方差矩阵所得特征基必须是正交的[4];而ICA的特征基则为非正交的,同时这几种方法也就一定的联系。比如,在白化零均值空间下,叶分量分析方法可以视为一种增量式的ICA方法[5]。LCA算法是一种新的算法,目前应用较少,基于LCA算法的特性可以应用于图像分割、图像特征提取、图像去噪(利用了高阶累积量对高斯噪声不敏感的特点,通过对图像数据计算其高阶累积量,从而达到去噪的目的。)以及高光谱图像的压缩(通过以统计独立为优化目标,通过寻找分离矩阵,从观测信号中估计出源信号。)等[6,7]。基于此,通过对一组人脸图片降维并提取样本特征,然后利用LCA算法对样本进行增量式(在线)学习来实现LCA的人脸识别。
1 叶分量分析方法概述
1.1 叶分量分析方法定义
叶分量分析法是一种增量式子空间学习方法[1]。该方法是通过某高维空间中时间上顺序得到的一组随机观测样本来估计该高维空间的概率密度的分布情况。叶分量分析适用于经过白化和中心化处理后的样本空间,既该样本空间在个维度上具有零均值和单位方差。在自然图像中,样本的分布往往是集中在几个方向上的,每个方向上集中分布的样本构成一个叶,样本空间中有c个这样的叶,它们将样本空间划分为c个互不相交的叶区域。在每个叶区域中,能够找到一个具有代表性的单位向量来表征该区域的所有向量,该分量称为叶分量,如图1。
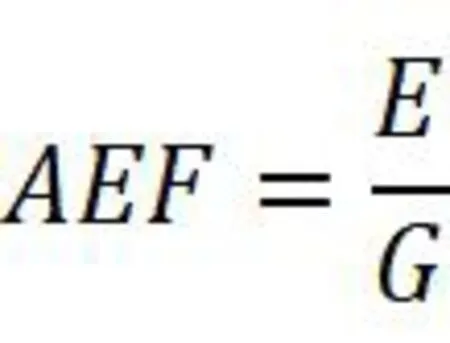
图1 两维白样本空间内叶区域及叶分量
1.2 叶分量的提取过程
每个叶分量之间不需要满足正交性和线性独立性,假设所有叶分量组成的空间为[8]:
K=samples{v1,v2,…,vc}
(1)
每个叶分量均为单位向量,那么该空间中的任意向量表示为
(2)
l为x在所有叶分量上的响应向量,既x在vi上的投影。
根据叶分量的定义,每个叶区域可由一个具有代表性的向量vi表示,因为样本空间中的每个叶区域中的向量是集中分布在某个方向上的,因此vi在该方向上应具有较大的方差。因此,假设X样本空间的协方差矩阵的最大特征值为λi,1,则vi作为与λi,1对应的特征向量应当满足:
(3)
经λi,1缩放后的vi可以被估计为属于该叶区域的样本加权平均值,每个样本的权值即为vi对该样本的响应。具体提取叶分量的方法如下:1)样本去均值,既计算样本每列向量均值,再用每列向量里的数减去该均值;2)计算协方差矩阵;3)计算特征值、特征向量;4)选取特征值最大的一组特征向量作为投影向量;5)对该组特征向量转置;6)将转置后的特征向量与样本空间矩阵进行矩阵乘法。最终得到的矩阵的每一列代表一个叶区域,既每一列为一个叶分量。
1.3 模式识别过程
LCA算法的增量式学习过程可以提供模式分类的有效信息,只需要在叶分量分析的初始化过程中将训练样本的类标号赋给该叶分量,通过训练样本的叶分量和测试样本的叶分量进行对比,将训练样本的叶分量类标号赋予与其最为接近的测试样本的叶分量,从而判定测试样本对应的具有标号的类,从而可以达到模式识别的目的。模式识别过程如图2所示。
图2 本文模式识别过程
2 人脸图片样本识别结果
2.1 样本来源与分类
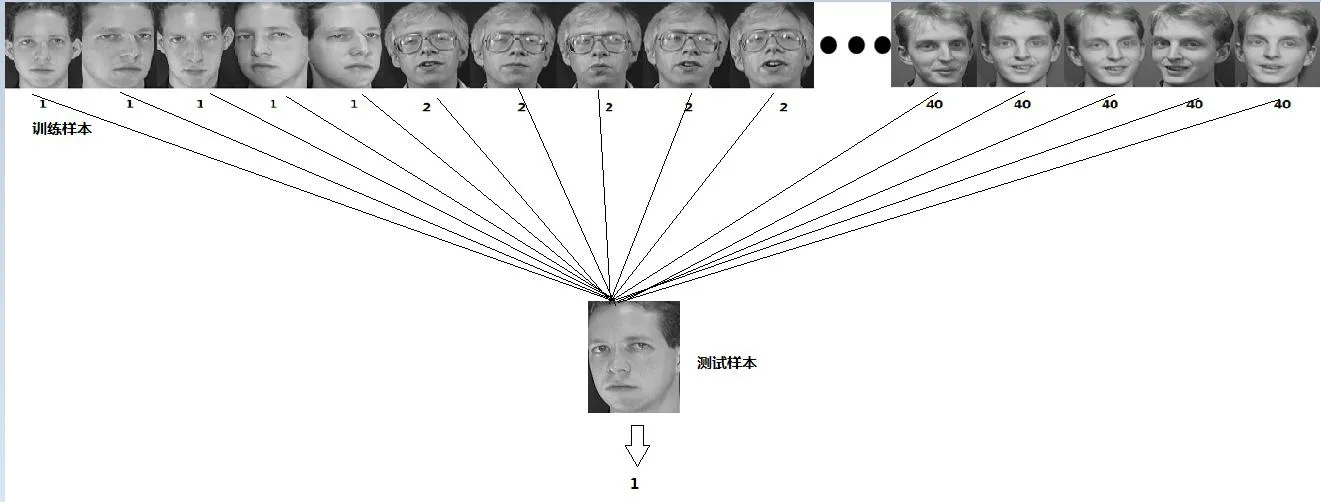
此以ORL人脸数据(http://download.csdn.net/detail/kyszp123/1583590)作为研究对象,包括400幅不同脸部姿态和表情的人脸图像。每幅图片的大小一致且均为灰度图像,其中每10幅图像为1个人的脸,每10幅图中取前5幅图片为训练样本,后5幅图片为测试样本,如图3,这样可以将400幅图片分为两部分,既200幅训练图片组成的训练样本和200幅测试图片组成的测试样本。在训练样本中,取单个图片的像素为行数,图片总个数为列组成一个二维矩阵X,该矩阵称为由200个叶区域组成的训练样本空间。测试样本用同样的方法,得到一个二维矩阵,该矩阵为由200个叶区域组成的测试样本空间,这两个空间维数相同。
图3 训练样本和测试样本
2.2 提取叶分量与识别
训练样本空间需要进行预处理,因为叶分量分析适用于去均值和白化后的样本空间,既需要对训练样本去均值和计算协方差矩阵。具体步骤如下:1)对样本矩阵的每一列取平均值。2)矩阵的每一列减去当前列均值。3)对去均值的矩阵计算协方差。而图像识别分为训练过程和识别过程。对于本文来说,就是取测试样本叶分量集中的一个叶分量与训练样本的每个叶分量进行比较,找到两叶分量欧氏距离最小的那个训练样本中的叶分量对应的标号,将其赋予该测试样本叶分量。训练过程:1)初始化m个叶分量和类标号,并将叶区域内样本数设置为1。而识别过程:1)测试样本X(t)视为t时刻到达的样本。通过叶分量分析的执行过程,与训练样本进行比较,找到与测试样本X(t)有最大响应的叶分量vj1≤j≤m,既两向量欧氏距离最小,最终得到测试样本对应的实际类别;2)将测试样本的实际类别与原类别进行比较,找到相同部分,即为识别出的图片。3)统计识别率,将识别出的图像的路径及名字输出到txt文档。
2.3 人脸识别结果
叶分量分析作为一种子空间学习方法,具有特征学习的能力,只需要在叶分量分析方法的初始过程中,初始化叶分量的同时将观测样本的类标号赋给该叶分量。假设记训练样本中有c个叶分量vi,1 如图4所示,为训练样本集叶分量标号示意图,每幅图片经提取叶分量后,可以找到一个叶分量与之对应,由于ORL人脸数据库为40组人脸照片,每10张为1人的人脸照片,取前5张作为训练图片,第一组测试人脸照片标号1,以此类推。 图4 本文训练样本集叶分量标记过程 在对测试样本进行识别的过程是这样的,经过投影后的测试样本矩阵,其每一列为一个叶分量,表示一幅测试图像,共200幅测试图像,每次取出一张测试样本对应的叶分量与训练样本叶分量集的每一个叶分量进行欧式距离比较,找出两个叶分量之间距离最小的那个训练样本中的叶分量,将此训练样本叶分量的标号,赋予对应的测试样本叶分量,具体过程如图5。 图5 测试样本标记过程 全部标记后,每个测试样本将拥有一个标号,将此标号与对应的训练样本标号进行相减,若为0,则表示该测试图片被识别。最终,在200张测试图片中,有171张被识别,识别率为85.5%。 以LCA方法为特征子空间提取方法,通过提取训练样本中每幅图片的叶分量,找到训练样本的特征子空间,通过将训练样本和测试样本分别投影到特征子空间,从而达到特征提取的过程,再通过LCA的在线学习过程,将训练样本进行标号处理,对比训练样本和测试样本,将最接近的训练样本标号赋予测试样本,这样做的好处是可以快速对样本进行一次性分类,通过标号相减,找出被识别的图像,既节省了时间又达到了识别的效果。
3 结 语
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
读者·校园版(2020年19期)2020-09-16
数学学习与研究(2019年21期)2019-12-25
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
英美文学研究论丛(2018年1期)2018-08-16
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
