
基于RoBERTa_WWM和Bi-LSTM的短文本情感分析①
2022-08-23 12:12吴铁峰
佳木斯大学学报(自然科学版) 2022年4期
王 恒, 吴铁峰
(佳木斯大学信息电子技术学院,黑龙江 佳木斯 154007)
0 引 言
情感分析又被称为意见挖掘,随着网络技术的发展,社交媒体上用户间的文本交互信息越来越多。通过文本挖掘出用户的情感倾向已成为自然语言处理的热门任务之一。文本情感分析主要分为两种任务:文本特征提取和表示、文本语义分析和分类。第一个任务常用的方法是用Mikolov等[1]提出的Word2vec模型来表示文本,但是它得到的文本表征是静态的,不能考虑到上下文的信息,针对这种情况Peters等[2]提出ELMO模型,虽能考虑到上下文的语义信息但是不能并行计算。Devlin[3]等人提出的BERT模型不仅能获得文本的动态表征计算过程也是并行的。目前在BERT模型的基础之上研究者们又提出了很多改进的模型,如 ERNIE[4],Xlnet[5],Roberta[6],alBERT[7]等。
对于第二个任务,常用方法主要是机器学习和深度学习的方法。前者虽取得了好的效果[8][9],但也存在诸如复杂人工特征工程、泛化能力较弱等缺点。目前深度学习成为该任务的主流技术,如S.Kai[10],LSTM,Kim[11]等利用CNN解决情感分析问题,使分类效果明显提升。目前将BERT及其改进模型应用到情感分析的任务中并成为了主流方法,如谢润忠[12]、谌志群[13]等人利用BERT和GRU,BERT和LSTM来进行文本情感分类。
考虑到目前常用文本表征方法仍采用静态表征方法且BERT模型主要是在字级别上进行预训练,而中文文本更希望在词或短语级别上进行建模,所以提出利用全词掩盖技术的预训练语言模型RoBERTa_WWM来获取文本动态表征,利用Bi-LSTM来提取文本语义特征进行情感分类并获得更好的分类效果。
1 相关技术
1.1 预训练语言模型及WWM技术
相比于如Word2vec等静态的词向量模型,利用预训练模型如BERT能获得考虑到上下文语义信息的动态词向量。预训练语言模型BERT有两种训练方式:MLM(Masked Language Model)即遮住几个字预测这几个字、NSP(Nextsentence Prediction)即预测上下两句关系,通过两种训练方式从文档中学习语义知识。但是BERT中的MLM任务是对字级别进行随机掩盖,然后预测掩盖掉的字,对于中文语料来说这种训练方式得到的只是局部的语言信号,缺乏对句子全局的建模,难以学到短语、实体的完整语义。
针对以上情况, Turc I[14]等人在训练BERT模型的过程中使用了一个新的技术WWM(Whole Word Masking),在进行MLM任务时将一个短语或者实体掩盖,比如“哈尔滨是一座冰城”这句话是将“哈尔滨”和“冰城”进行掩盖,并预测出这两个实体并且能够学习到这两个实体之间的关系。
1.2 Bi-LSTM模块
鉴于传统的RNN模型在训练过程中存在梯度消失和爆炸的问题,Hochreiter等[15]提出LSTM模型,LSTM中的每个单元包含输入门it,遗忘门ft,输出门ot和记忆单元ct。利用这些门控机制来控制当前时刻要保留多少上一时刻的信息,有多少信息要加入到当前时刻。四个门的计算公式如式(1)-(6)所示:
it=σ(wi[ht-1;xt]+bi)
(1)
ft=σ(wf[ht-1;xt]+bf)
(2)
ot=σ(wo[ht-1;xt]+bo)
(3)
gt=tanh(wc[ht-1;xt]+bc)
(4)
ct=it⊙gt+ft⊙ct-1
(5)
ht=ot⊙tanh(ct)
(6)
xt表示t时刻的词向量;ht表示隐层向量;wi,wf,wo,wc为权重矩阵;bi,bf,bo,bc为训练过程中的偏置项;σ为sigmod激活函数;tanh表示激活函数;⊙表示点乘。
Bi-LSTM其实是利用两个LSTM来获取上下文信息,前项LSTM从前往后获取上文信息,后项LSTM从后往前获取下文信息。
2 本文模型
采用RoBERTa_WWM[16]来表示文本特征,得到能够考虑到上下文的动态词向量,然后将RoBERTa_WWM的输出作为双向LSTM的输入,得到最终的情感极性。模型如图1所示。
2.1 词嵌入层
词嵌入是将自然语言转换成深度学习网络能够识别的向量,采用BERT的变种RoBERTa_WWM预训练词向量模型,来表示文本的词向量。RoBERTa_WWM主要是对BERT的参数进行了优化,采用了更大的BatchSize,能够输入更长的文本序列;证明了BERT中的NSP任务对模型的性能有影响,所以去掉了NSP任务;对于BERT的静态掩码的问题,它采用动态掩码的方式让模型更加有效;此外它采用BPE字符编码,可以处理自然语言语料库中常见的词汇,比BERT拥有更大的语料。
对于一条短文本语句S={x1,x2,x3…xn}构建出对应的字符向量(Token Embedding)、位置向量(Position Embedding)和分段向量(Segment Embedding),并将这些向量在行维度上进行拼接得到输入文本的词向量矩阵Ib×s,其中b为batchsize,s为句子的长度(seq_length),经过RoBERTa_WWM之后得到文本的动态词向量表示E= {e1,e2,e3…en},E的维度大小为:E∈Rb×s×e,其中e为词向量的维度(embedding_dim)。
2.2 语义提取层
如图1所示,将RoBERTa_WWM的最后一层输出,即2.1中的E作为双向LSTM的输入A=(a1,a2...at...an),其中at表示t时刻的LSTM的输入,其计算公式如式(7)所示:
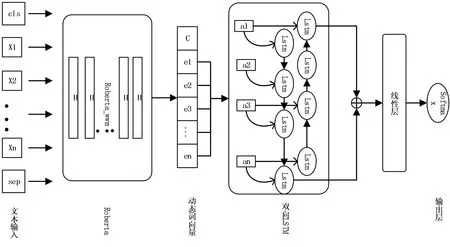
图1 本文模型结构
at=σ(WheEt+ba)
(7)
σ为激活函数sigmoid,Whe∈Re×h为权重矩阵,ba为偏置项。
(8)
Whh∈Rh×hLSTM前一时刻ht-1到当前时刻ht的权重矩阵,bh为当前时刻的偏置,ht∈Rb×2h,同理后项LSTM的计算与前项LSTM一致。
将前项LSTM的最后一个时刻的隐层和后项LSTM最后一个时刻的一层进行拼接后输出,计算公式如式(9):
(9)
Obilstm∈Rb×4h,是双向LSTM的输出。
2.3 情感分类层
将双向LSTM的输出经过一个线性层之后再经过softmax函数得到最终的分类结果,计算公式如式(10):
P=softmax(linear(ObilstmU+bo))
(10)
U∈R4h×2是线性层的权重矩阵,bo为偏置项。由于本模型是一个二分类问题,所以采用的loss为二元交叉熵损失函数。公式如式(11):
(11)

3 实验结果及分析
3.1 数据集
采用两种数据集(数据集1:ChnSentiCorp和数据集2:NLPCC14-SC),这两种数据集都是作为句子级的文本情感分析数据,其中数据集1包含酒店、笔记本和书籍三个领域的评论,数据集2包含书籍、DVDS和电子产品的评论文本,数据集1训练集大小9600,开发集大小1200,测试集大小1200,数据集2训练集大小9000,开发集大小1000,测试集大小2500。
由于数据集中的评论文本中包含很多无意义的词,所以对于这两种数据集先进行去停用词,如表1所示。

表1 文本预处理示例
3.2 参数设置
为保证实验结果的准确性,对比实验与本文实验均在相同环境下进行,试验过程中的超参数配置如表2所示。

表2 模型参数设置
3.3 对比实验设置及结果分析
通过对比其他5个主流模型,来评估所提出的模型的效果,并且证明了所提出的方案能够很好的分析出文本的情感极性,相对于其他模型具有优越性,各个模型的具体情况如下:
1)CNN模型:词向量采用word2vec,然后利用CNN来提取文本特征,采用三种尺寸的卷积核,它们的大小分别取3,4,5,通道数设置为50。
2)LSTM模型:词向量同样采用word2vec,LSTM设置为两层,隐藏层的单元数设置为100。
3)BiLSTM_attention:使用双向LSTM,层数设置为两层,同时加入注意力机制,将隐层输出经过tanh激活函数之后与权重矩阵相乘,得到注意力分数,注意力分数经过softmax之后,再与隐层输出相乘,然后再经过全连接层进行分类。
4)BERT模型:利用预训练语言模型BERT来进行微调,直接在BERT输出中的CLS这个token上作二分类。
5)BERT_Bi-LSTM模型:利用bert预训练模型得到文本的特征表示,然后将其作为Bi-LSTM的输入进行分类。
6)RBL:即本文模型。
模型的分类标准采用准确率作为模型的评估标准,各个模型准确率如下表3所示。
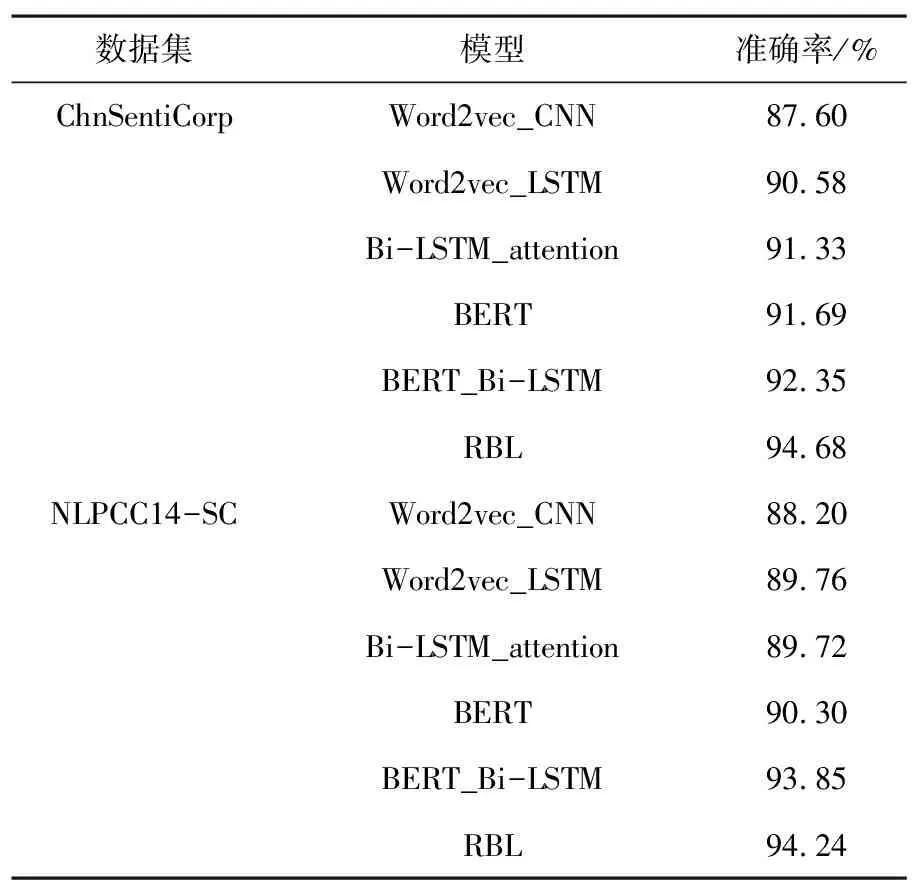
表3 各模型的情感分析结果
为了直观的观察所提出的模型在两个数据集上相对于其他网络在性能上的优势,以及模型的收敛情况,将各个模型在这两个数据集上的准确率(Acc)和损失(Loss)随步长(Step)的变化情况展示出来,如下图2至5图所示。

图2 各模型在数据集1的Acc趋势图
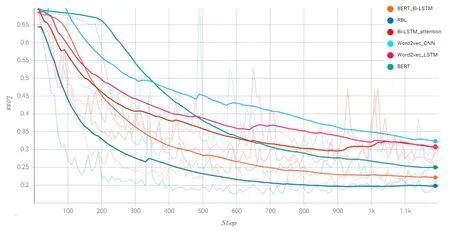
图3 各模型在数据集1的Loss趋势图
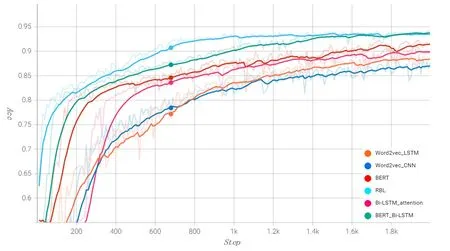
图4 各模型在数据集2的Acc趋势图
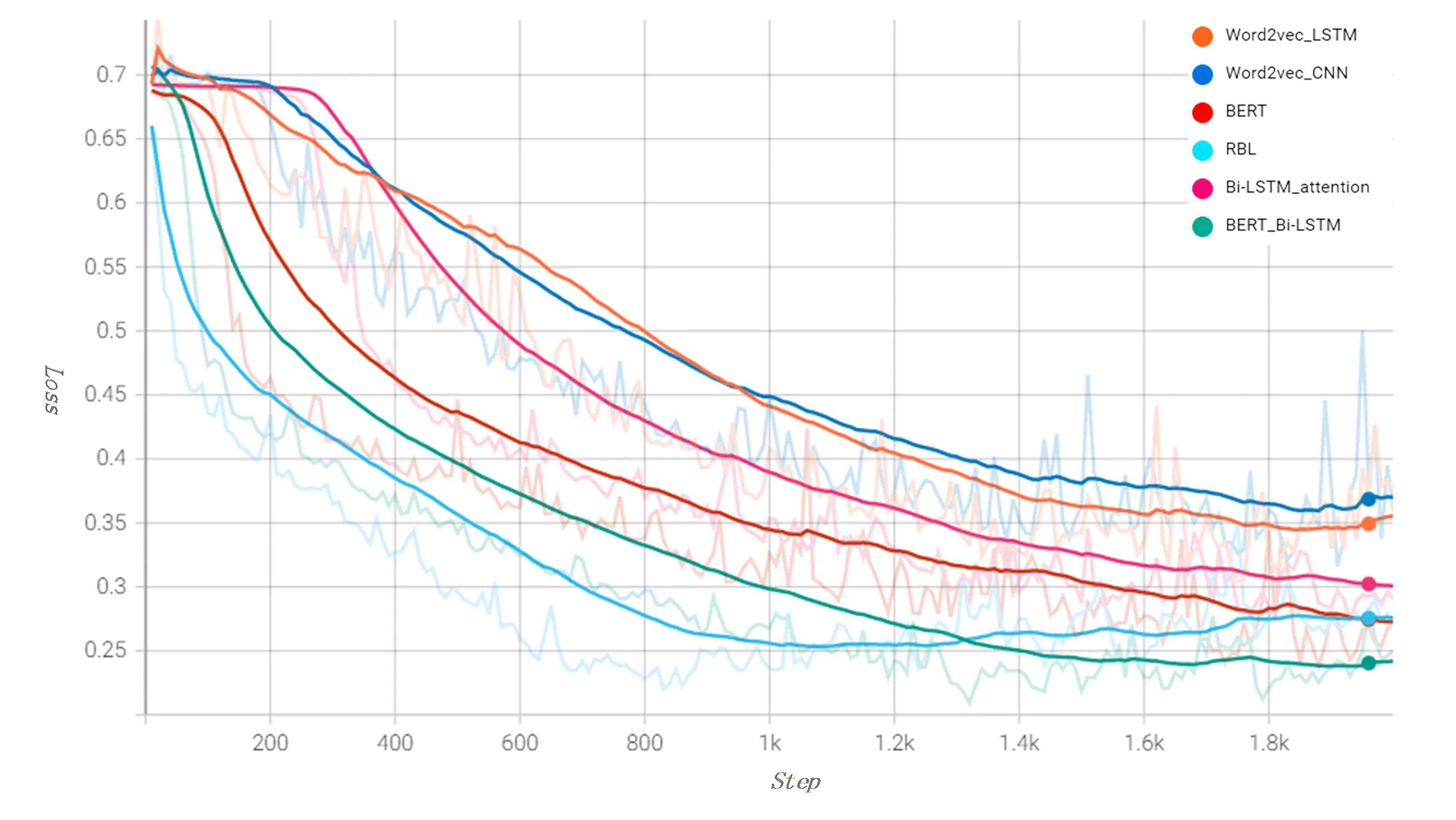
图5 各模型在数据集2的Loss趋势图
对于ChnSentiCorp数据集,从图2,3可以看出模型在330步左右Acc和Loss有所波动,但是之后逐渐趋于平稳,同时可以看出本文模型较其他模型的Loss一直是最小的,表明了其收敛效果更好,Acc较其他模型的提高也是有明显的提升,体现出本文模型较其他模型的优越性。在NLPCC14-SC数据集上,从图4,5中可以看出本文模型在1000步之后Acc开始趋于平缓且较其他模型有更高的值,同时Loss也是最快趋于平缓,说明模型收敛较快。
4 结 论
基于RoBERTa_WWM和双向LSTM来进行文本情感分析。以往的短文本情感分析任务中采用例如Word2Vec的静态词向量的方式来表示文本,这种方式虽然能够考虑到文本上下文的关系,但是这种方式不能够解决一词多义的问题,尤其是中文文本中一个词在不同语境下的语义是不同的,本文采用的是RoBERTa_WWM预训练模型来表示文本,并在情感分析任务中得到的较好的效果。主要对文本评论的极性进行二分类,在此基础上对中文文本的情感极性进行多分类及情感原因分析是以后研究的重点。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
小学阅读指南·高年级版(2014年2期)2014-05-27
