
基于改进GhostNet模型的表情识别研究
2022-08-23 07:16张文海陈春玲
计算机技术与发展 2022年8期
张文海,陈春玲
(南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210023)
0 引 言
通过深度学习方法提取表情特征信息是目前最广泛使用且有效的方法[1],但随着深度神经网络模型的不断发展,网络模型越来越复杂,参数和计算量不断变大,导致模型的使用只能在特定的应用场合,很难应用到移动设备和嵌入式设备上。为解决这个问题,Howard等于2017年提出MobileNet[2]模型,通过将一个标准卷积拆分成逐通道卷积和逐点卷积的方法大幅减少了计算量;Sandler等提出倒残差模块和线性瓶颈层,并以此设计了MobileNet V2模型[3];2019年,Howard等提出MobileNet V3模型[4],在倒残差模块中引入了SE注意力机制,并修改MobileNet V2中计算量偏大的开头和结尾两层,该模型在分类和检测等任务上准确率和速度都优于前几版;2020年,针对生成的特征图中存在大量的冗余信息,Han等提出GhostNet模型[5],使用恒等映射的方式直接生成这些冗余的特征图,大幅减少了参数量和计算量。但这些模型当中,即便是最小的图像输入分辨率也是96×96,而人脸表情识别任务则可以使用更低的分辨率。
目前卷积神经网络大都采用Softmax交叉熵损失函数来优化类间的特征差异,并未考虑到人脸表情信息中类内的特征差异。为解决这个问题,Wen等提出中心损失函数[6],使样本均匀分布于类中心周围,减小类内差异;Cai等在中心损失函数的基础上提出Island损失函数[7],优化类中心的位置,增大类间差异。事实上,基于Softmax交叉熵损失函数改进得到的各种损失函数都是在做减小类间相似性、增大类内相似性的工作。但是这样的优化方式将正负样本都以相同方式优化,不够灵活,于是Sun等提出Circle损失函数[8],引入相似性权重因子,对类内相似性和类间相似性给予不同的惩罚强度,从而使优化更加灵活。
基于上述内容,该文主要工作有以下两点:
(1)针对现有的轻量级神经网络的缺点和表情数据的特点,提出一个输入图像分辨率为48×48的改进GhostNet模型——M-GhostNet。该模型不仅大幅减少了参数和计算量,并且更加符合人脸表情识别任务的特点,更加符合移动端和嵌入式设备的使用场景。在FERplus数据集[9]上取得了较高的识别准确率和识别速度。
(2)针对Softmax交叉熵损失函数不能压缩类内空间,优化不灵活等问题,结合Circle损失函数和Island损失函数,提出基于余弦相似性的损失函数,在FERplus数据集上获得了不错的效果。
1 改进的GhostNet网络模型
1.1 Ghost模块
文献[5]对ResNet50的某层输出进行可视化分析,发现训练过程中的特征图中存在着大量重复、冗余的特征图。因此可以定义其中一张特征图为本征图,与其相似的特征图则可以被定义为Ghost图。既然Ghost图与本征图相似,那么就不需要使用占用内存多,计算复杂等高成本的卷积操作,直接使用低成本的线性变换或者其他廉价的操作得到。
图1(a)是常规卷积操作,图1(b)是Ghost模块的具体操作。可以看出Ghost模块主要由三部分组成:第一步,将输入图像通过常规卷积得到本征图;第二步,对本征图做线性变换或其他廉价操作生成Ghost图;第三步,将本征图与Ghost图拼接作为输出。假设每张本征图都存在着与之对应的s张Ghost图,这s张Ghost图仅需通过线性变换方式获得,那么从整体上来看,Ghost模块相较于常规卷积操作会减少大约s倍的参数量和计算量。
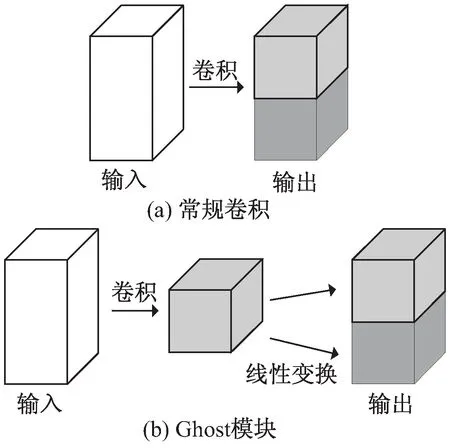
图1 常规卷积和Ghost模块
1.2 改进的GhostNet模型
ReLU激活函数凭借着其低计算复杂度和快速的收敛效果,成为大部分卷积神经网络模型首选的激活函数,GhostNet也不例外。但是其函数曲线不平滑,并且在模型训练的时候,容易导致部分神经元“坏死”。所以在改进的GhostNet中摒弃了ReLU函数,改用函数曲线更为平滑,可以保留部分负值信息的Mish函数[10]。Mish函数表达式为:
Mish(x)=x·tanh(ln(1+ex))
(1)
Mish函数性质同ReLU函数一样无上界,有下界,但是Mish函数保留了少量的负值信息,避免了ReLU函数可能产生的Dying ReLU现象,即部分神经元在反向传播时可能不起作用的现象[11]。并且Mish函数更为平滑,这样随着网络的深度增加,样本的信息也能传递到更深的网络层中,整个模型更加容易优化,最终的模型也能有更好的泛化效果。
参照ResNet中的残差结构[12],使用Ghost模块,可以堆叠出Ghost瓶颈层。使用Mish函数作为新的激活函数的改进Ghost瓶颈层结构如图2所示。
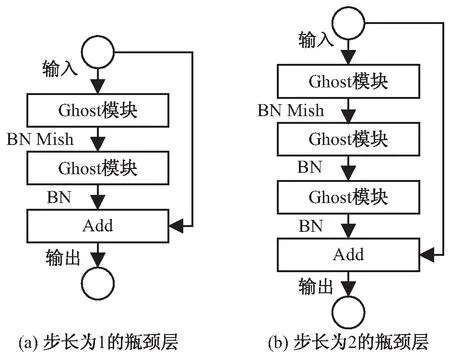
图2 改进Ghost瓶颈层
结合人脸表情数据的特性,在保持高准确率的前提下,尽可能地减少网络模型的参数量和计算量,该文设计出一个基于改进Ghost瓶颈层,输入尺寸为48×48×3,适用于七分类表情识别任务的改进GhostNet网络模型M-GhostNet,其详细网络结构如表1所示。
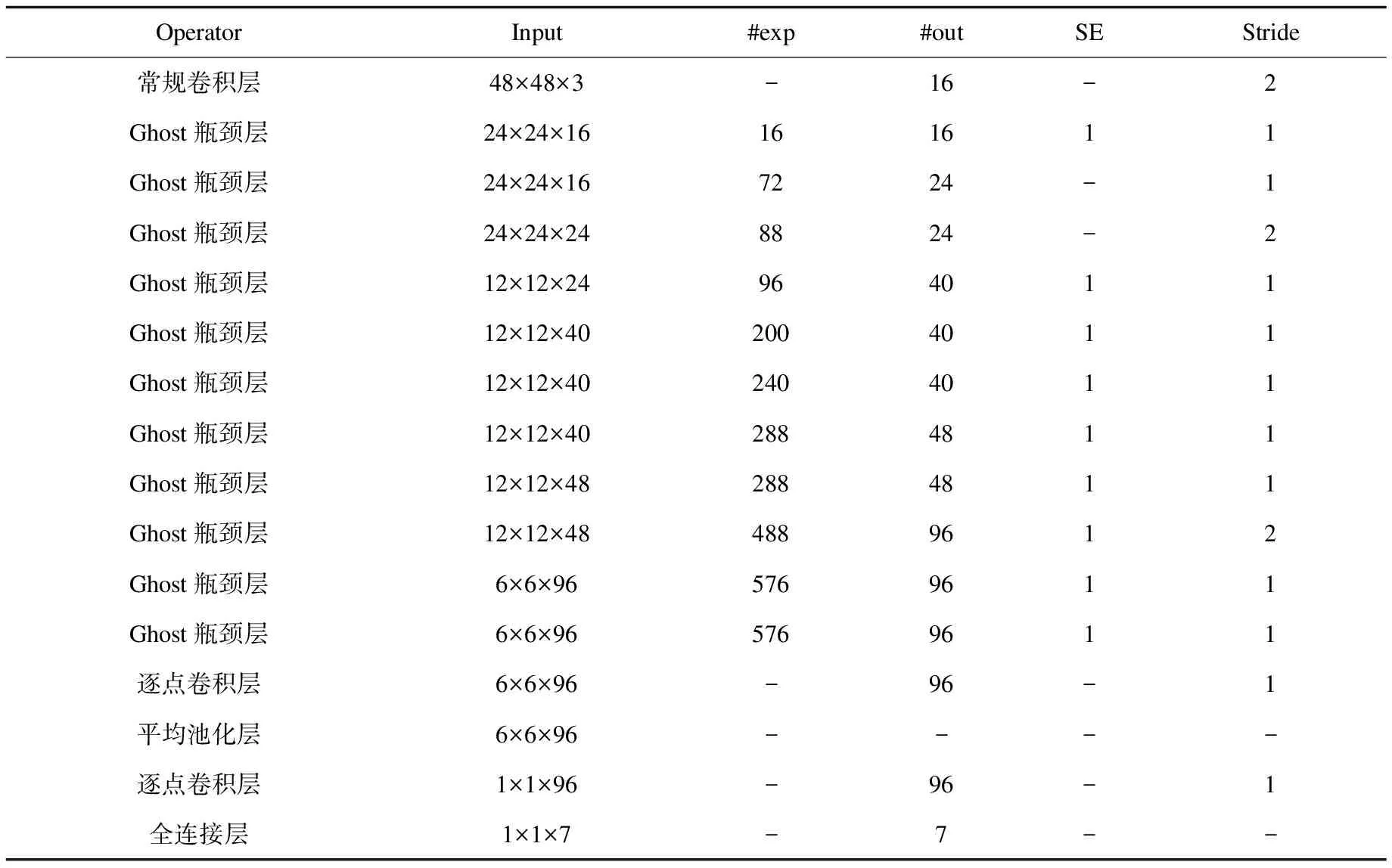
表1 M-GhostNet网络结构
其中#exp表示改进Ghost瓶颈层中经过第一个Ghost模块处理过后的通道数,#out表示该层输出的通道数,SE为1表示该层使用了注意力机制,Stride表示步长。采用Mish函数作为每层的激活函数。
经过理论和实验验证,M-GhostNet的参数量和计算量比MobileNet V2、MobileNet V3和GhostNet有着大幅的降低,并且在表情识别任务上保持着较高的准确率。具体参数量和计算量的对比见表2。

表2 模型参数量、FLOPs对比
可以看出,M-GhostNet的参数量比MobileNet V2和GhostNet减少90%左右,比Mobile V3减少80%左右。浮点运算量比MobileNet V3少了62%左右,比GhostNet少了90%左右,比MobileNet V2更是少了93%左右。
2 基于余弦相似性的损失函数
2.1 Softmax交叉熵损失函数
Softmax交叉熵损失函数是卷积神经网络常用的损失函数。在一个拥有N个嵌入式表示实例集合的分类任务中,xi是神经网络全连接层输出的第i个样本的特征向量,wj、bj是第j类对应的全连接层的权重和偏置。Softmax交叉熵损失函数的计算公式为:
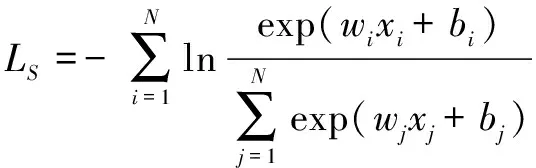
(2)
2.2 Island损失函数
Island损失函数是基于中心损失函数改进得来的,中心损失函数的计算公式为:
(3)
其中,ci是第i类的中心,λ用于调节两项的比例。但是由于中心损失函数只考虑到了样本向其类中心分布,缩小了类内的差异,没有考虑类间的差异,故Island损失函数在式(5)的基础上优化了类中心之间的欧氏距离,计算公式为:
(4)
其中,λ1超参数用于调节新增项和中心损失函数的比例。式(4)中的尾项惩罚了类与类之间的相似性,从而增大了类间距离。
2.3 基于余弦相似性的Island损失函数
虽然Island损失函数可以很好地增加类间距离,缩小类内距离,但由于Softmax交叉熵损失函数本身并不能减少类内差异性,所以Island损失函数的性能依旧受限于Softmax交叉熵损失函数,影响最终分类的准确率。大部分以Softmax交叉熵损失函数为基础的一系列改进的损失函数,比如:Triplet损失函数[13]、AM-Softmax损失函数[14]等,本质上都是在最大化类内相似度sp,最小化类间相似度sn,即优化式(5):
min(sn-sp)
(5)
如果直接优化sn-sp,那么网络模型最终将收敛并得到这样一个决策边界:
sn-sp=margin
(6)
这些损失函数在优化的时候会对sn、sp做相同力度的惩罚。比如,当sn已经是一个十分小的值,但sp却是一个相对较大的值时,虽然此时模型已经可以很好地聚合相同的类,但由于sp是个较大值,需要受到一个较大的惩罚力度,而sn却因此也需要受到相同的惩罚力度,这显然是不合适的。
鉴于该问题,引入两个独立的非负权重参数αn、αp,分别控制sn、sp以不同的速率进行优化。又因为sn、sp分开进行优化,边界值margin不再是它们共同的边界值,所以需要为它们引入两个不同的边界值,类间边界值Δn和类内边界值Δp,则新的决策边界为:
αn(sn-Δn)-αp(sp-Δp)=0
(7)
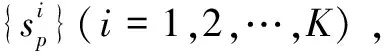
(8)
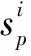

(9)
其中,[·]+表示取非负数操作。将式(7)与式(9)结合,可以得到新的决策边界:

(10)
为了简化参数,可以设Op=1+m,On=-m,Δp=1-m,Δn=m,这样新的决策边界就变成:
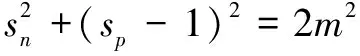
(11)
综上,最终的Circle损失函数可以表示为:
(12)
该文提出的基于余弦相似性的损失函数的中心思想就是使用Circle损失函数替换Island损失函数中的Softmax函数,新的计算公式可以表示为:
(13)
新的损失函数不仅弥补了Softmax交叉熵损失函数无法更好地聚合同类样本的缺陷,而且可以让各类样本更加灵活地朝着更加合适方向收敛。同时,第二项可以约束每个样本分布在其类中心周围,缓解类内差异,增大类间差异。
图3是Softmax交叉熵损失函数、AM-Softmax损失函数和基于余弦相似性的损失函数在某一分类任务中类xi的决策边界。
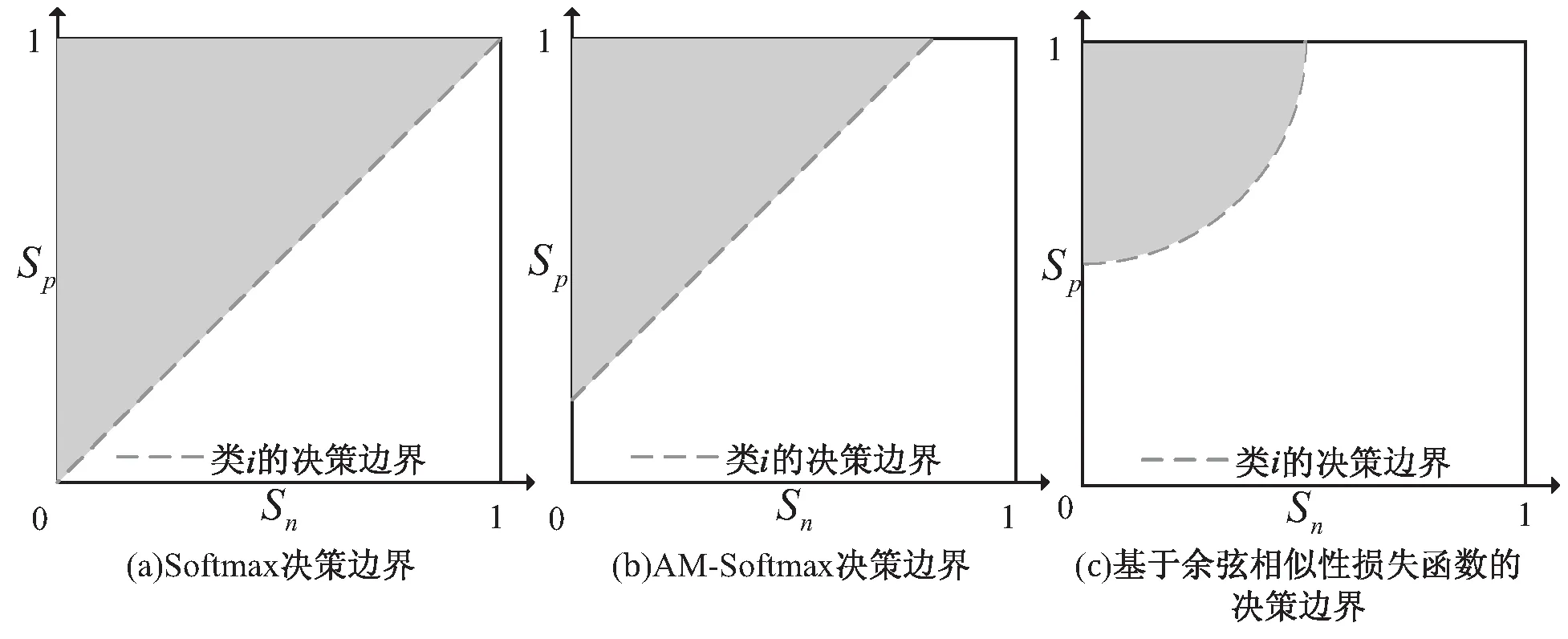
图3 Softmax、AM-Softmax和基于余弦相似性损失函数的决策边界
如图3(a)所示,Softmax交叉熵损失函数的决策边距为0,并不能更好地区分类与类,减少类内的差异性。图3(b)中AM-Softmax损失函数引入了余弦距离margin,可以更好区分类,并压缩类内空间。图3(c)中基于余弦相似性的损失函数的决策边距则与超参数m相关,由式(12)可以得出,当m≤0.5时,两个类之间就不会相交,当m越来越小时,两个类的决策边距也就越来越大,从而更好地放大类间距离,压缩类内空间。由于图3(c)是圆形边界,样本在收敛过程会比图3(b)拥有更明确的收敛方向。实验中m取值0.35,缩放因子γ取值2,Island损失函数的超参数λ、λ1分别设置为0.01和10。
特别地,当K=1时,即样本中只有一个正样本,其余均为负样本,基于余弦相似性的Island损失函数就退化成了文献[15]中的基于余弦距离的损失函数。
3 实 验
3.1 实验环境与设置
实验以TensorFlow 2.4框架为基础,编程语言为Python 3.7。实验训练都在GPU上进行,GPU的型号为Nvidia GeForce RTX 2060,6 GB显存。实验中采取SGD优化器,动量为0.9,学习率初始设置为0.01,随着训练轮数的增加,通过余弦退火策略降低学习率[16]。实验模型在数据集上训练100轮。批大小为16。对输入的图片在归一化的前提下,进行随机旋转30度、上下左右移动、缩放和剪切等数据增强手段处理[17]。
该文所涉及的方法分别在FERplus数据集上进行七分类对比实验。FERplus数据集是针对FER2013数据集中数据标注错误和冗余等问题而重新标注的数据集[18]。原数据集总共有十类表情,而实验选取七类,去除掉“轻蔑”、“未知”和“非人脸”三个标签,总共35 493张图片。然后按照8∶1∶1的比例将数据随机拆分为训练集、验证集和测试集。训练好的模型用测试集来测试识别准确率。
3.2 实验结果与分析
文中模型与其他算法模型在FERplus数据集上的对比实验结果如表3所示,损失函数为Softmax,×表示模型的缩放因子,每个模型的缩放因子设置参考了文献[5]的分类实验设置。

表3 各模型在FERplus数据集上的准确率
从表3可以看出,使用了Mish激活函数替换ReLU激活函数的M-GhostNet,在参数和计算量均少于GhostNet、MobileNet V2和MobileNet V3的前提下,依旧保持了较高的准确率,比GhostNet高了1.008%,比MobileNet V2高了7.628%,比MobileNet V3高了0.614%,可以看出选用Mish函数能够在表情分类任务中提高识别准确率。
为了控制变量,损失函数的对比实验均使用M-GhostNet模型,在FERplus数据集上进行。其中AM-Softmax的超参数margin设置为0.35。
从表4可以看出,基于余弦相似度的损失函数比传统的Softmax交叉熵损失函数准确率高了3.222%,比Island损失函数高了2.431%,比AM-Softmax损失函数高了2.177%,比Circle损失函数高了0.904%,比基于余弦距离的损失函数高了0.512%。实验结果表明基于余弦相似性的损失函数可以学习到更具有区分力度的表情特征,更好地区分类,提高表情识别任务的准确率。

表4 各损失函数在FERplus数据集上的准确率
表5是各模型预测一张图片所需时间对比,模型均运行在CPU上,CPU型号为Intel Core i7-9750H 2.60 GHz。可以看出改进GhostNet模型预测所需时间更少,从而可以得出预测速度更快、实时性更好。

表5 各模型预测所需时间对比
4 结束语
该文设计了一种基于改进的GhostNet神经网络模型,用于人脸表情的特征提取和分类任务。该模型不仅拥有轻量级网络的参数少、计算复杂度低、训练快等特性,还解决了ReLU函数可能导致的信息丢失的问题,保持了较高的识别准确率。同时,针对表情数据的特性,提出了基于余弦相似度的损失函数,可以更好地增加类间差异,减小类内差异,提高模型的识别准确率。实验结果表明,改进GhostNet模型和基于余弦相似性的损失函数可以在人脸表情识别任务上有着较高的识别准确率和速度优势。下面将继续研究表情样本分布不均的问题,提高模型的准确率,实现表情识别的自动化和智能化。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
计算机辅助工程(2018年2期)2018-06-03
中国新通信(2017年9期)2017-05-27
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
智能制造(2015年7期)2015-11-20
