
多分支混沌变异的头脑风暴优化算法
2022-08-19 08:23衣俊艳施晓东
计算机工程与应用 2022年16期
衣俊艳,施晓东,杨 刚
1.北京建筑大学 电气与信息工程学院 计算机系,北京 100044
2.中国人民大学 信息学院,北京 100872
优化问题是指在一定约束范围内,寻找一组参数值,使得目标函数得到最优。优化问题在通信、交通、国防、管理、计算机等众多领域都有着广泛的应用[1]。考虑到实际工程中优化问题的特点,需要寻找一种简单高效的优化方法。因此,群智能优化算法开始进入人们的视野。
群智能(swarn intelligence,SI)[2]算法主要是模拟昆虫、兽群、鸟群等群体进行觅食、求偶等群体行为而提出的自适应优化算法。该类算法是一种随机搜索方法,具有灵活应对群体内部和外部搜索环境变化的能力,即当搜索条件多变或自身的某些个体搜索失败时,能够自组织逃离并找到更优的位置[3-4]。基于群体智能的思想,国内外学者提出了多种优化算法,例如蚁群优化(ant colony optimization,ACO)[5]算法、粒子群优化(particle swarm optimization,PSO)[6]算法、人工蜂群(artificial bee colony,ABC)[7]优化算法、布谷鸟搜索(cuckoo search,CS)[8]算法等,这些算法具有较强的鲁棒性和搜索能力,易于并行实现,在许多优化问题中得到了广泛的研究和应用。
大多数的经典群智能算法都来源于低等生物的群体行为,直到2011年,史玉回[9-10]基于人类思维方式和行为,提出了头脑风暴优化(brain storm optimization,BSO)算法。该算法的重点在于模拟人类使用头脑风暴解决问题,是受人类群体行为启发的群智能优化算法。头脑风暴优化算法将收敛与发散操作同时嵌入到算法的每一次迭代中,具有很强的鲁棒性和搜索能力。
群智能优化算法普遍存在易陷入局部最优,导致早熟收敛的问题,BSO算法也不例外。为此,许多研究者提出了改进算法。文献[11]使用k-medians聚类替换BSO算法中的k-means聚类,提高了算法的搜索效率。文献[12]提出了基于讨论机制的头脑风暴优化(discussion mechanism based brain storm optimization,DMBSO)算法,通过控制组内、组间讨论次数,初期加强全局搜索,后期加强局部搜索,有效地避免了算法陷入局部最优。文献[13]提出了目标空间的头脑风暴优化(brain storm optimization in objective space,BSO-OS)算法,通过将解集合分为精英类和普通类来代替BSO 中复杂的聚类操作,极大地提升了算法搜索效率,降低了算法的复杂度。文献[14]提出了一种改进的头脑风暴优化(modified brain storm optimization,MBSO)算法,使用简单分组方法(simple group method,SGM)替换k-means 聚类,并用差分变异替换BSO 算法中的高斯变异,提高了算法的搜索效率和寻优精度。
针对BSO寻优精度不高、易陷入局部最优的问题,本文提出一种多分支混沌变异的头脑风暴优化(brain storm optimization based on multi-branch chaotic mutation,MCMBSO)算法。该算法利用混沌序列的遍历性、多样性和随机性,通过混合多种混沌序列,扩大算法的搜索空间,增强其全局搜索能力。当BSO 算法陷入局部最优时,使用多分支混沌变异算子,生成新的解集合,平衡算法搜索时的收敛和发散操作,提高算法跳出局部最优的能力。
本文介绍了原始BSO 算法的流程和原理、多分支混沌变异的流程以及选取的8 个混沌映射的解分布情况,并给出了MCMBSO 算法的步骤和流程图。实验部分将MCMBSO 与BSO 算法在10 个经典测试函数上进行了3 个维度的对比实验,并将MCMBSO 与多种算法进行了实验对比分析。实验结果表明,新算法提高了BSO跳出局部最优的能力,进而提高了算法的寻优精度。
1 头脑风暴优化算法
头脑风暴优化算法是一种新兴的群智能优化算法,其灵感来自于人群求解问题时集思广益的群体行为,即头脑风暴过程。头脑风暴过程的核心思想是召集一群不同背景的人,对需要解决的问题提出大量的解决方案,最后通过解决方案的沟通和整合,共同解决问题。当面临个人难以解决的问题时,通过不同背景的人的大量设想、大胆假设、观点融合,最终能有效提升找到最优解决方案的概率。
BSO 算法将头脑风暴过程中产生的想法抽象为优化问题解空间中的个体,每个个体都是待求解问题的一个解,所有个体视为待求解问题的解集合,通过个体的融合变异产生新的个体。算法流程如下:
(1)初始化n 个个体。
(2)使用k-means 将n 个个体聚类,并计算n 个个体的适应度值,选择每个类中适应度值最好的个体作为该类的聚类中心。
(3)根据概率选择是否随机生成一个个体代替随机选择的一个聚类中心。
(4)通过以下四种方式更新个体,当一个新个体生成后,与当前个体相比,适应度好的个体作为下次迭代的新个体。
①随机选择一个类的聚类中心,添加随机值生成新个体。
②随机选择一个类的普通个体,添加随机值生成新个体。
③随机选择两个类的聚类中心,合并后添加随机值生成新个体。
④随机各选择两个类中的一个普通个体,合并后添加随机值生成新个体。
(5)重复进行(4)操作,直到n 个个体全部更新完毕,此时产生n 个新个体,完成一次算法迭代。
(6)回到操作(2),再进行下一次迭代,直到达到最大迭代次数后算法停止。
在BSO 算法中,新个体通过一个或两个类中的中心或普通个体添加随机值生成。当新个体基于一个类生成时,算法倾向于收敛,当新个体基于两个类生成时,算法倾向于发散。算法通过类内、类间的交互融合来实现个体的更新,这些操作确保了算法的种群多样性和生成新个体的质量。此外,BSO添加随机值生成新个体的方式如式(1)所示:

式中,Xdnew是生成新个体的d维值,Xdselect是选中个体的d维值,N(μ,σ) 是均值为μ方差为σ的高斯随机函数,ξ是高斯随机函数的系数,用来控制扰动的幅度,表示为:
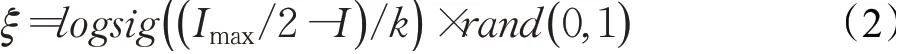
式中,logsig( )是S形变换函数,Imax是最大迭代次数,I是当前迭代次数,k是改变logsig( )函数的斜率,rand产生一个0到1之间的随机数。
2 多分支混沌变异的头脑风暴优化算法
2.1 新解生成分析
在大多数群智能优化算法中,种群中的所有个体都只趋向于最优解。而在头脑风暴优化算法中,每个个体不仅是目标问题的解,而且是解集合中的一个样例。类似于人类头脑风暴过程,BSO算法通过对解集合中每个个体进行融合和变异来生成新的解集合。因此新个体的生成在BSO算法中具有重要的作用。
传统的BSO算法使用添加高斯随机值来进行新解的生成。根据正态分布特性,在式(1)中,当μ和σ固定时,N(μ,σ)的取值几乎全部集中在(μ-3σ,μ+3σ)内。如图1所示,是μ=0,σ=1 时的高斯分布曲线,概率密度集中在分布的中心,并以指数形式向两边递减,其99.73%的面积集中在平均值左右3个标准差3σ的范围内。而logsig( )∈( 0,1) ,可知系数ξ∈( 0,1) 。因此,高斯变异由系数ξ和随机函数N(μ,σ)乘积所得的变异量始终在一个固定的范围内。

图1 高斯分布图Fig.1 Gaussian distribution
根据正态分布的特点,高斯变异侧重于搜索原个体周围的局部区域,局部搜索能力较强,但引导个体跳出局部最优的能力较弱,容易导致种群搜索停滞。为了增强BSO 算法跳出局部最优解的能力,本文在算法陷入局部最优时加入多分支混沌变异算子。
2.2 多分支混沌变异算子
2.2.1 混沌与混沌解
混沌是指确定性系统中出现的一种貌似无规律的复杂运动形态,其行为复杂且类似于随机,因此可用来进行随机搜索。对于确定性非线性系统,具有内在随机性的解称为混沌解。不同于确定性解和随机解,混沌解具有遍历性、随机性、初值敏感性、长期不可预测性等自身独有的特性[15]。
在优化领域,混沌映射生成的混沌解常用于种群初始化,个体的选择、交叉、变异等操作,而且通常能取得比随机数更好的结果。混沌映射不断迭代后产生混沌序列,每一次迭代即是实现一次搜索,通过不断迭代,即可实现对混沌空间的遍历搜索。
2.2.2 多分支混沌变异
本文选取8个混沌映射,设计了一种多分支混沌变异算子,当原始BSO算法搜索陷入局部最优时,使用多分支混沌变异生成新个体,增强算法跳出局部最优解的能力。
对于m维优化问题,f(X)=f(x1,x2,…,xd,…,xm),xd∈[a,b],a和b分别是个体的上下界。多分支混沌变异算子的流程如下:
(1)从8个混沌映射中选取一个映射用来生成m维混沌变量,选取公式如下:

其中,p∈( 1,8 )是选取的混沌映射序号,i是混沌序列的迭代次数。
(2)在( 0,1) 之间产生m个随机数作为m维混沌变量c(p)1各分量的初始值。
(3)根据所选取的混沌映射,通过K次迭代产生一个长度为K,包含K个m维混沌变量的混沌序列
(4)通过载波映射[16],将混沌特性引入到选中个体周围,表达式如下:


式中,Xselect是选中个体的d维值是原个体所在簇的簇中心的d维值。
(5)使用式(4)生成K个在原个体周围具有混沌特性的m维搜索点后,将这些点带入到测试函数中进行检验,选取其中适应度值最小的搜索点Xmin作为待更新个体。
(6)比较最小搜索点Xmin与第idx个原个体Xidx的适应度值,其中idx∈[1,n] 。如果满足f(Xmin)<f(Xidx),即可将Xidx更新为Xmin。
多分支混沌变异算子中,混沌映射的选取采用随机选择的策略,这样既保证了混沌搜索的多样性,更避免了算法复杂度的增加。此外,算法陷入局部最优是指当算法在迭代一定次数后,全局最优适应度值始终不变。此时种群中的个体大都聚集在局部最优处,因变异量有限,算法失去跳出局部最优解的能力,且种群整体的群体多样性过低。因此,通过使用多分支混沌变异算子,对个体嵌入不同的混沌映射序列。这样不仅扩大了混沌搜索的空间,给个体带来更大的变异,增加了个体信息的多样性,而且增强了算法跳出局部最优的能力,进而提高了算法的全局搜索能力和寻优精度。
2.2.3 具体混沌映射
不同的混沌映射所产生的混沌序列是完全不同的,其分布或遍历性质有很大的差异。由于混沌序列的不重复性和遍历性,使用不同混沌映射的搜索模式在搜索范围和提高算法精度上都优于使用单一的混沌映射。通过研究多种混沌映射所产生的序列分布情况,本文选取了8个典型的具有独特分布特性的混沌映射,用于构成多分支混沌变异算子。经过大量实验测试,这8个混沌映射能有效增强算法跳出局部最优解的能力,其描述如下所示:
(1)Cubic 映射。Cubic 映射[17]是处理各种应用(如密码学)中最常见的混沌映射之一,表达式为:

其中,ρ=2.59。图2显示了Cubic映射迭代500次后混沌序列分布的散点图和频率直方图。

图2 Cubic映射生成的混沌序列分布散点图和直方图Fig.2 Scatter diagram and histogram of chaotic sequences generated by Cubic map
(2)Sine映射。Sine混沌映射是以正弦函数为基础的混沌映射[17-18],表达式为:

其中,μ∈[0,1] 是控制参数,当μ越趋近于1时,混沌性越强,此处取μ=1;c( 2)i∈(-1,1) ,此处取c( 2)i的绝对值,使得c( 2)i∈( 0,1) 。图3显示了Sine映射迭代500次后混沌序列分布的散点图和频率直方图。
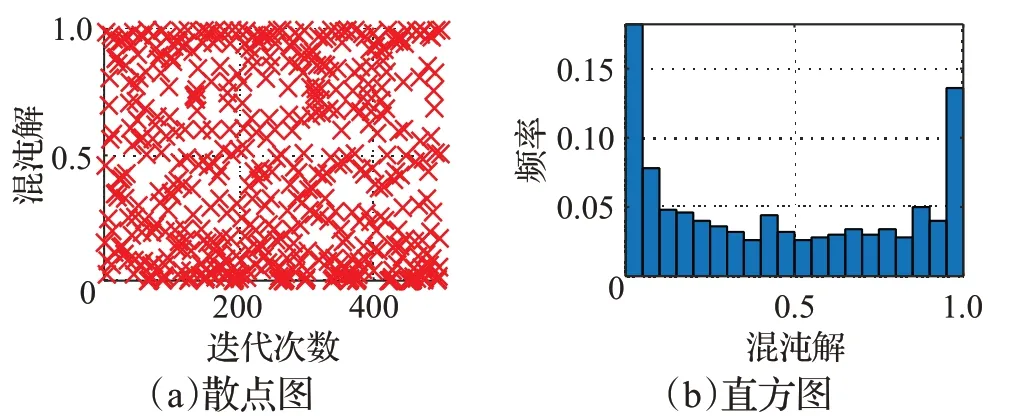
图3 Sine映射生成的混沌序列分布散点图和直方图Fig.3 Scatter diagram and histogram of chaotic sequences generated by Sine map
(3)Logistic 映射。Logistic 映射[17-18]是研究动力系统、混沌等复杂系统行为的一个经典模型,可以用来模拟生物种群的生长行为,因此也叫“虫口模型”,表达式为:

其中,μ∈( 0,4 ]是控制参数,当μ=4 时,系统处于全混沌状态,具有混沌性;c( 3)i∈( 0,1) 且初始值c( 3 )1≠0.25,0.50,0.75。图4 显示了Logistic 映射迭代500 次后混沌序列分布的散点图和频率直方图。
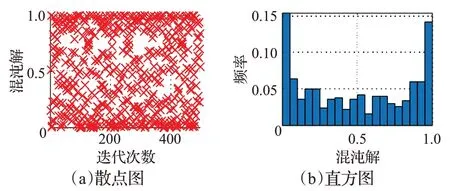
图4 Logistic映射生成的混沌序列分布散点图和直方图Fig.4 Scatter diagram and histogram of chaotic sequences generated by Logistic map
(4)无限折叠混沌映射(iterative chaotic map with infinite collapses,ICMIC)[17,19]。ICMIC的表达式为:

其中,μ∈( 0,+∞),研究表明μ对表达式的影响很小,此处取μ=100;c( 4)i∈(-1,1) ,此处取c( 4)i的绝对值,使得c( 4)i∈( 0,1) 。图5 显示了ICMIC 映射迭代500 次后混沌序列分布的散点图和频率直方图。

图5 ICMIC映射生成的混沌序列分布散点图和直方图Fig.5 Scatter diagram and histogram of chaotic sequences generated by ICMIC map
(5)分段线性混沌映射(piecewise linear chaotic map,PWLCM)[17-18]。PWLCM 是多段构成的混沌映射,表达式为:

其中,λ为控制参数,当λ∈( 0,0.5 )时,c( 5)i∈( 0,1) 。系统具有以下特性:(1)Lyapunov指数大于0,系统为混沌状态。(2)具有一致的不变分布密度函数和较好的遍历性。图6显示了PWLCM映射迭代500次后混沌序列分布的散点图和频率直方图。

图6 PWLCM映射生成的混沌序列分布散点图和直方图Fig.6 Scatter diagram and histogram of chaotic sequences generated by PWLCM map
(6)Neuron映射。Neuron映射[17]是具有非线性反馈的映射,由双曲正切函数和指数函数组合构成,表达式为:

其中,η∈[0,1] 是衰减系数,此处取η=0.5;γ是比例因子,此处取γ=5;c( 6)i∈(-1.5,0.5 ),此处取c( 6)i的绝对值,并舍去大于1 的值,使得c( 6)i∈( 0,1) 。图7 显示了Neuron 映射迭代500 次后混沌序列分布的散点图和频率直方图。

图7 Neuron映射生成的混沌序列分布散点图和直方图Fig.7 Scatter diagram and histogram of chaotic sequences generated by Neuron map
(7)Sinusoidal映射[17-18]。Sinusoidal映射的表达式为:

其中,μ是控制参数,此处取μ=2.3。图8显示了Sinusoidal映射迭代500次后混沌序列分布的散点图和频率直方图。

图8 Sinusoidal映射生成的混沌序列分布散点图和直方图Fig.8 Scatter diagram and histogram of chaotic sequences generated by Sinusoidal map
(8)Berboulli Shift 映射。Berboulli Shift 映射[17]是分段线性函数,表达式为:

其中,λ为控制参数,此处取λ=0.4。图9显示了Berboulli Shift 映射迭代500 次后混沌序列分布的散点图和频率直方图。

图9 Berboulli Shift映射生成的混沌序列散点图和直方图Fig.9 Scatter diagram and histogram of chaotic sequences generated by Berboulli Shift map
图2~图9展示了8个混沌映射迭代500次后的混沌序列分布散点图和频率直方图。从图中可以看出,这8个混沌映射具有不同的分布特性。例如Logistic、Sine、Cubic映射产生的混沌解大多分布在0和1周围;PWLCM映射产生的混沌解分布趋向于0;而ICMIC映射产生的混沌解分布则趋向于1;Neuron映射产生的混沌解分布倾向于0.3 到0.5;Sinusoidal 映射产生的混沌解范围仅在0.5 到0.9 之间。这些不同的混沌映射产生的不同分布的混沌解,提供了比单一混沌解更大的混沌空间,同时利用混沌序列的高随机性,增加了个体的变异量,从而有效扩大了算法的搜索范围,增强了算法跳出局部最优解的能力。
2.3 算法步骤
MCMBSO算法步骤如下:
步骤1 初始化:在解范围内随机生成n个个体。
步骤2 聚类:用k-means 将n个个体聚类,并计算适应度值,找出每类最优个体作为聚类中心。
步骤3 中心替换:根据概率随机生成一个个体替换随机选取的聚类中心。
步骤4 根据概率在一个簇中选择中心个体或普通解作为Xselect,或两个簇中各选择一个中心个体或普通解组合作为Xselect。
步骤5 判断算法是否陷入局部最优:若算法重复迭代20次,最优适应度值不变,执行步骤6,否则转步骤7。
步骤6 根据式(3)、(4)、(5),使用多分支混沌变异算子更新个体,完成转步骤9。
步骤7 根据式(1)、(2),用高斯变异生成新个体。
步骤8 若新个体适应度值优于原个体,存储适应度好的个体作为新个体进入下次迭代。
步骤9n个个体全部更新完转步骤10,否则转步骤4。
步骤10 若达到最大迭代次数,输出最优个体适应度值,算法结束,否则转步骤2。
MCMBSO流程图如图10所示。
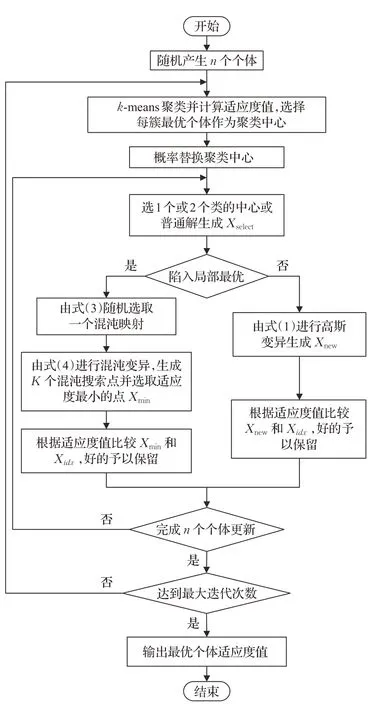
图10 MCMBSO算法流程图Fig.10 Flowchart of MCMBSO algorithm
3 实验测试与结果分析
为了验证MCMBSO 算法解决优化问题的有效性和可行性,本文从两方面进行仿真对比实验。(1)将MCMBSO 与标准BSO 算法在不同的维度下进行仿真对比;(2)将MCMBSO 与遗传算法(genetic algorithm,GA)、粒子群优化(PSO)算法和布谷鸟搜索(CS)算法进行仿真对比。
为了便于对比分析,实验使用10 个经典的测试函数[20],如表1 所示。其中f1~f5属于单峰函数,f6~f10属于多峰函数。单峰函数在定义域中只有一个严格局部极大值或极小值,多峰函数是指在区间中有多个相同或不同极值点的函数。

表1 10个测试函数Table 1 10 test functions
所有算法的实验在同一平台上运行,实验平台为Windows 10(64 bit)操作系统下的MATLAB R2018b,硬件条件为Intel®CoreTMi5-9300 CPU 2.40 GHz,16 GB内存。
3.1 聚类数分析
在BSO和MCMBSO算法流程中,分类策略的目的是将解集合收敛到若干较小的范围,优化搜索区域。在算法多次迭代之后,搜索空间不断减小,所有解大概率被聚集到一个小范围中,增加了算法的收敛能力。因为本文主要探讨添加多分支混沌变异算子后对BSO算法的改进,所以MCMBSO 参照原始BSO 算法,使用kmeans聚类对解集合进行分类操作。k-means算法是一种经典的聚类算法,算法本身需经过多次迭代才能将解集合分组,并且聚类数需要事先指定。
表2展示了BSO 和MCMBSO 算法在单峰函数f1和多峰函数f7上,聚类数分别为2、5、10、20下的寻优实验结果。其中,BSO算法的各参数和聚类数为5时的平均值来源于文献[9],MCMBSO 算法陷入局部最优的判断条件为重复迭代20 次,最优适应度值不变。实验的种群规模为100,最大迭代次数为2 000,优化问题维度为30。算法对每个函数独立运行50 次,记录它们的平均值。其中加粗行代表2、5、10、20 聚类数下能获得平均值较优的一个。
由表2可以看出,无论是BSO还是MCMBSO算法,在处理单峰函数f1和多峰函数f7上,都在聚类数为5时获得了相对更优的平均值,并且MCMBSO算法在4个聚类数下均获得了优于BSO的平均值。根据文献[21],聚类个数的多少会影响BSO算法的种群多样性。如果聚类数过小,会弱化算法的收敛能力,降低局部搜索的速度和精度。如果聚类数过大,会让算法搜索后期不停增加种群信息的多样性,产生许多无效空簇,导致算法难以收敛。因此,为了检验使用多分支混沌变异算子的有效性,参照文献[9],本文在之后的实验中,将BSO 与MCMBSO的聚类数设定为统一值5。

表2 k-means不同聚类数下的实验结果比较Table 2 Comparison of experimental results under different k-means clustering numbers
3.2 MCMBSO与BSO算法对比
为了研究MCMBSO 算法的优化性能,将表1 中的10 个测试函数分别用MCMBSO 和BSO 算法在10 维、30 维、50 维的维度下进行30 次独立寻优,记录30 次寻优的最优值、最差值、平均值和方差。实验种群规模为100,最大迭代次数为20 000,BSO 的参数参考文献[9],MCMBSO陷入局部最优的判断条件为重复迭代20次,最优适应度值不变。实验统计结果如表3和表4所示。
表3和表4分别给出了MCMBSO和BSO算法在不同维度下的单峰和多峰测试函数上寻优的实验结果。表中的最优值和最差值体现了算法单次的寻优能力,平均值体现了算法运行30 次后达到的寻优精度,方差则体现了算法的稳定性。其中,加粗数字表示两算法中较优的平均值。加下划线数字代表两算法中较优的最优值和方差值。
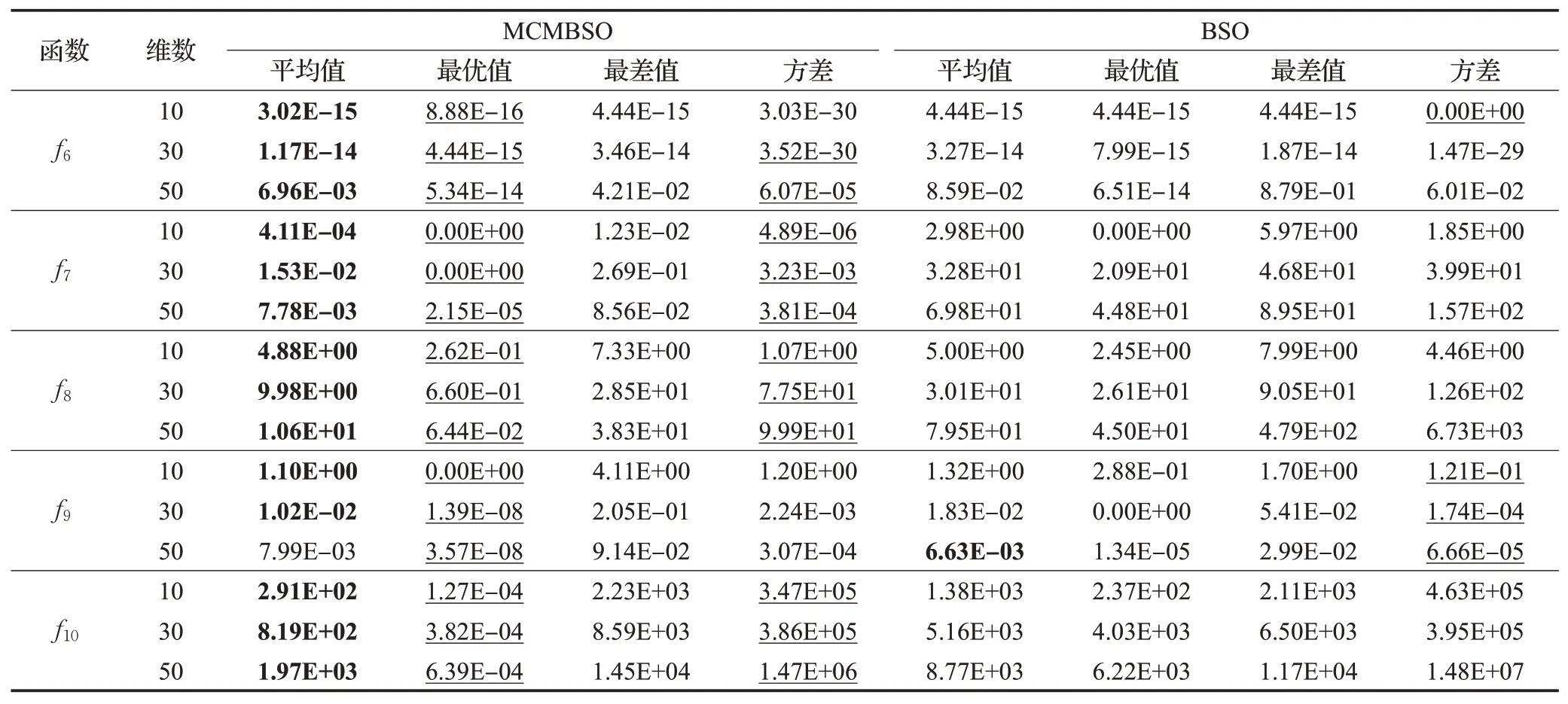
表4 MCMBSO与BSO不同维数下的多峰函数实验结果比较Table 4 Comparison of experimental results on multimodal functions between MCMBSO and BSO in different dimensions
从表3 中可以看出,对于5 个单峰函数,MCMBSO和BSO算法得到的最优解都非常接近理论最优值。除去f2的10维,MCMBSO在5个单峰函数上3个维度下的平均值均优于BSO。特别的,对于函数f5,MCMBSO在3个维度上都找到了理论最优值0,而BSO只在10维上找到了理论最优值。对比两算法的稳定性,在函数f3、f4、f5上,MCMBSO 算法的方差在3 个维度上都达到了10-4及以上,高于BSO算法最少3个数量级。
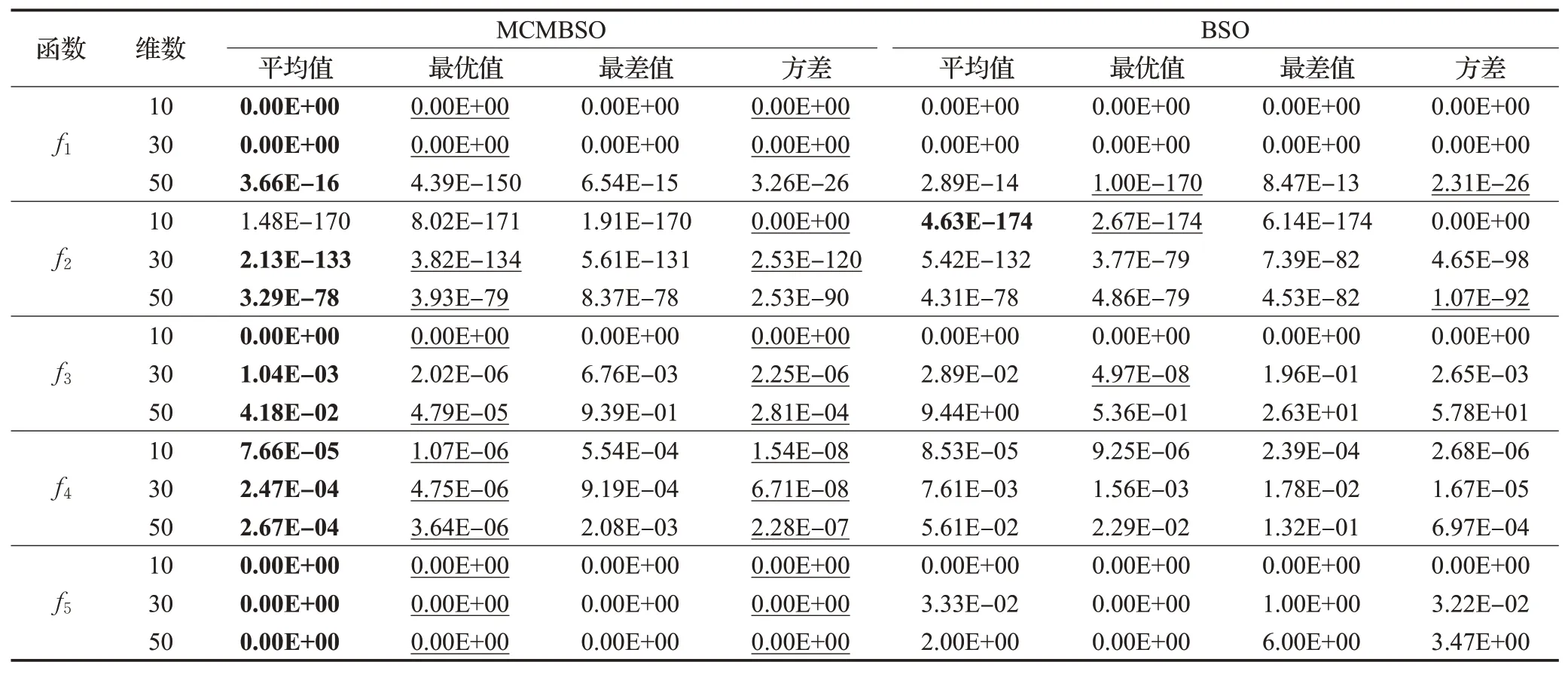
表3 MCMBSO与BSO算法不同维数下的单峰函数实验结果比较Table 3 Comparison of experimental results on unimodal functions between MCMBSO and BSO in different dimensions
针对函数f1和f2,仅在处理50维问题上MCMBSO的方差略大于BSO,其余两个维度上MCMBSO 的方差均优于BSO。针对50维问题,MCMBSO的方差大于BSO的原因是:随着问题维度的升高,算法寻优的难度也逐渐增加。由于MCMBSO中8个混沌映射采取随机选择的策略,混沌搜索空间具有一定的随机性。并且针对不同的函数问题,算法具有不同的适应性。对于函数f1和f2的50 维,虽然在方差上略大于BSO,但MCMBSO在这两个问题上均获得了优于BSO 的平均值,且最优值精度也达到了1E-150 和1E-79,非常接近理论最优值。说明MCMBSO在处理这两个函数的50维上,稳定性略低于BSO,但具有更高的寻优能力。
因此,对于处理5 个单峰函数,两算法均能找到非常接近或等于理论最优值的解。针对所测试的15个单峰问题,MCMBSO算法求得的平均值有14个优于BSO算法,方差值有13个优于BSO。由此可见,相较于BSO算法,MCMBSO 算法具有更强的寻优能力和较好的稳定性。
从表4 中可以看出,对于5 个多峰函数,MCMBSO在5个多峰函数的3个维度上,平均值基本均优于BSO,仅在函数f9的50 维上,MCMBSO 的平均值略低于BSO,且差值在同一个数量级内。特别是在函数f7上,MCMBSO 在3 个维度上都获得了比BSO 高3 个数量级及以上的寻优精度。在稳定性方面,对于函数f7、f8、f10,MCMBSO 在3 个维度上均获得了优于BSO 的方差;在函数f6上,MCMBSO 的方差仅在10 维上略大于BSO,但平均值和最优值仍优于BSO。
因此,在处理5个多峰函数的15个问题时,MCMBSO求得的平均值有14个优于BSO算法,方差值有11个优于BSO。这说明,在5个多峰函数上,MCMBSO可以找到比BSO更优的解,稳定性也优于BSO,仅在处理f9这个比较复杂的问题时,稳定性略低于BSO。
综上所述,在处理10 个测试函数上,MCMBSO 在f1~f10上都取得了优于BSO 的寻优平均值,说明了MCMBSO具有更好的寻优能力。在稳定性上,MCMBSO在f1~f8和f10上均获得了优于BSO 的方差,说明了MCMBSO 具有更高的稳定性。尤其在函数f3、f4、f5、f7、f8、f10上,MCMBSO 在3 个维度上的平均值和方差均优于BSO。由此可见,使用多分支混沌变异算子的MCMBSO,有效避免了BSO易陷入局部最优的问题,寻优能力更强,具有更高的稳定性和全局搜索能力。
3.3 MCMBSO与其他算法对比
表5展示了MCMBSO 算法与PSO、GA、CS 算法在表1 的10 个函数上的寻优实验结果。四种算法的种群规模为100,最大迭代次数为20 000,优化问题维度为30,算法对每个函数独立运行30次,记录它们的平均值和方差。

表5 维度为30时MCMBSO与其他优化算法实验结果比较Table 5 Comparison of experimental results between MCMBSO and other optimization algorithms with dimension of 30
由表5可见,不同于其他三种算法,MCMBSO在函数f1和f5上均能达到理论最优值。对于函数f2、f4、f7,MCMBSO 的平均值和方差均优于PSO、GA、CS 最少2 个数量级,且在函数f9、f10上,MCMBSO 的平均值也略优于其他三种算法。因此MCMBSO在7个函数上均获得了优于其他三种算法的寻优结果。仅在函数f3、f6和f8上,MCMBSO的精度略逊于CS,但优于PSO和GA。综上可知,相比于其他优化算法,MCMBSO 具有更强的全局搜索能力。
4 结束语
本文针对BSO 算法易早熟收敛,寻优精度不高的问题,在BSO 算法的基础上,嵌入多分支混沌变异算子,提出了多分支混沌变异的头脑风暴优化(MCMBSO)算法。当BSO 算法搜索陷入局部最优时,使用多分支混沌变异替换高斯变异来生成新个体,增强了算法跳出局部最优解的能力。实验使用10 个经典测试函数,将MCMBSO 与BSO 算法在3 个维度下进行对比分析,并与PSO、GA、CS 算法进行对比分析。实验表明,MCMBSO算法能有效避免BSO易陷入局部最优的问题,且寻优精度更高,全局搜索能力更强,具有较高的稳定性。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
武汉工程职业技术学院学报(2022年1期)2022-04-13
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
摄影之友(影像视觉)(2018年12期)2019-01-28
初中生世界·八年级(2017年3期)2017-03-24
百科知识(2015年18期)2015-09-10
文理导航(2015年14期)2015-05-22
中学数学杂志(高中版)(2014年2期)2014-05-26
