
基于数据挖掘和K-Means算法的高校学情数据集成研究
2022-08-18 08:28李凤英许洪光
黑龙江工程学院学报 2022年4期
李凤英,许洪光,周 方,李 培
(1.河北东方学院 人工智能学院,河北 廊坊 065000;2.中国地质科学院地球物理地球化学勘查研究所,河北 廊坊 065000)
学情分析是整个教学系统的基础,是遵循因材施教原则的关键,是教学设计的起点,其目的就是更好地了解学生,从而提高教学效果。以大学生为研究对象进行学情分析是对学生精准分类指导的重要一步,更是有效的课程教学设计的重要依据。
随着大数据的发展,数据分析得到了广泛的应用,其中,数据挖掘是数据分析常用的方法,但是其对学情分析的应用相对较少。姚远[1]提出基于分层线性模型的教育数据挖掘方法。根据学生能力的官方评价报告,分析学生能力指标的自变量;采用北京市学生2011年和2014年的中高考成绩为数据基础,构建学生能力评价指标;基于分层线性模型分析和预测学生成绩的影响因素。Natek等[2]通过数据挖掘技术分析小型学生数据集,根据小型学生数据集的特点,使用决策树算法对学生数据进行分类;分析学生的学习特征,预测学生的学情和成绩。Aher等[3]利用数据挖掘技术从Moodle(模块化面向对象的开发学习环境)等课程管理系统收集学生行为数据。结合聚类技术-简单K均值和Apriori算法分析学生的学习特点并进行分类,根据学生和课程的匹配程度向学生推荐合适的课程。
基于以上研究成果,从多维度对某校物联网专业近4 a的学生进行学情分析,并提出RET模型,同时采用K-Means聚类[4]方法查看学生成绩的规律并可视化,实验结果表明文中方法对提高教学效果有重要的现实意义。
1 研究对象
以某校物联网专业近4 a的学生为研究对象,对其专业课程的成绩进行整理分析。
2 数据预处理
收集的学生数据是某校2016—2019年4个学期的成绩数据,包括学号、姓名、性别、平时成绩、模考成绩以及综合成绩等信息。
2.1 去除冗余列
由于存在重名情况,而学号是唯一的,因此,删除姓名列。数据集部分结果如图1所示:
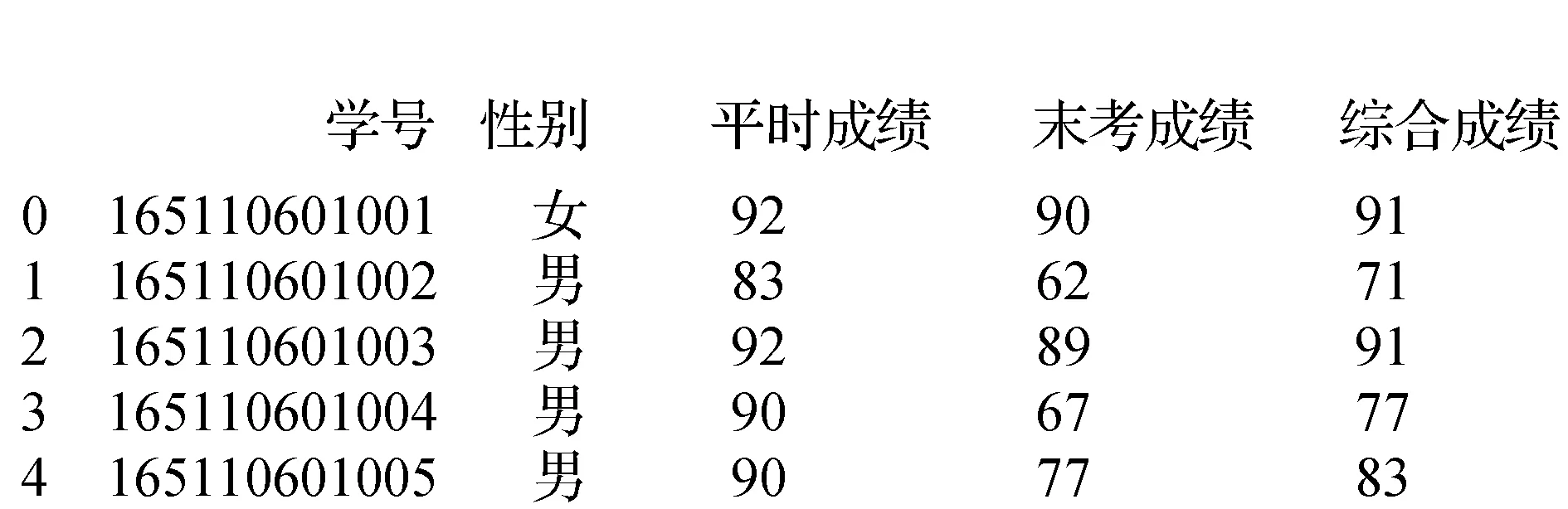
图1 学生数据集
2.2 去除异常值
如图2所示,此成绩数据中存在缺考或缓考的学生,对学情分析没有价值,属于异常值,因此,将其删除。

图2 异常值
3 研究方法
3.1 基于Python可视化分析学生数据
利用Python的正则表达式根据不同年级学号的特点将数据集分为4个子集,选取2017—2019年的学生子集分别对其进行研究,得到不同性别对平时成绩、末考成绩及综合成绩的影响规律并进行可视化。
3.2 基于Python研究平时成绩和末考成绩的相关关系
针对不同年级,通过散点图对比平时成绩和末考成绩的相关关系。
3.3 构建学生标签
通过对学生成绩的深度挖掘,构建学生标签体系,从而在教学中准确高效地获得学生情况,实现因材施教。从平时成绩、末考成绩和综合成绩3个方面构建学生标签体系,并提出RET模型评价标签。
3.3.1 高成绩标签
在综合成绩的基础上,结合人工经验,对学生成绩进行计算或归类,如定义是否为高成绩,需要人为设置阈值。文中选取85分作为阈值,如果学生的综合成绩大于该阈值,则将学生定义为优秀学生。
3.3.2 不及格标签
因材施教的另一个目标是督促“休眠”学生,即成绩不合格的学生。“休眠”学生主要缺乏学习兴趣,因此,唤醒“休眠”学生对因材施教具有重大意义。选取60分为阈值,如果学生的综合成绩小于该阈值,则定义为“休眠”学生。
3.3.3 规则类标签:RET模型的计算及可视化
综合整理学生平时成绩、末考成绩和综合成绩3个维度的信息,并对此进行分析,有助于全方位了解学生。文中依据这3个维度提出RET模型,该模型显示一个学生的全部学习轮廓,为师生的个性化沟通提供了依据。
RET模型3个要素分别是:平时成绩Regular_grade、末考成绩Endterm_ grade和综合成绩Total_ grade。根据3个要素将学生数据进行四等分,得到不同指标的评分阶梯,然后计算学生的RET总得分。计算方法如下:
1)将平时成绩进行降序排列,前25%标记为4,25%~50%标记为3,50%~75%标记为2,75%~100%标记为1。
2)将末考成绩进行降序排列,前25%标记为4,25%~50%标记为3,50%~75%标记为2,75%~100%标记为1。
3)将综合成绩进行降序排列,前25%标记为4,25%~50%标记为3,50%~75%标记为2,75%~100%标记为1。
4)将每个学生对应的3个评分标记相加,作为学生RET的总得分score。
将每个总得分的取值作为一个类别进行分组,统计不同总得分下RET的取值分布情况,并实现可视化。
3.4 利用K-Means聚类分析学生数据
1)算法描述。该算法具有速度快、伸缩性强等特点[5-6],因此,选用该算法对学生成绩进行聚类分析[7-9]。
2)实现流程。①由于数据集中的数值范围不同,所以采用sklearn模块中的preprocessing函数将数据规整化处理。②数据建模。导入sklearn模块中的K-Means模块,随机生成K值并进行评价,如图3所示,当K取值大于5时,基本趋于稳定,所以K取值定为5。③使用K-Means算法生成实例myKmeans,之后利用.fit()方法对数据集进行模型拟合[10-12]。④预测模型,并将聚类结果进行可视化。
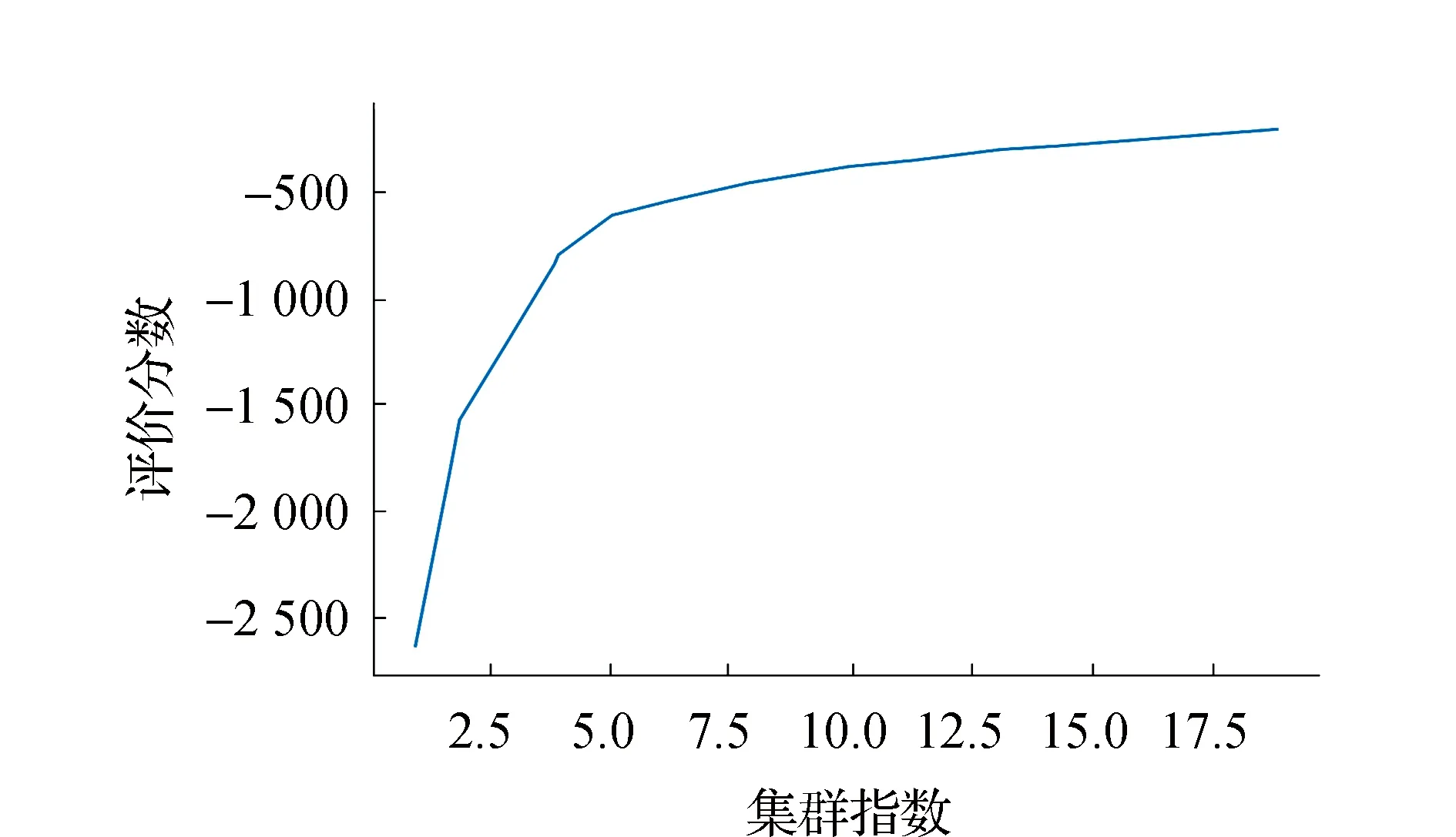
图3 误差评价
4 实验结果及分析
4.1 基于Python针对不同年级的学生分析结果
1)17级不同性别的学生平时成绩、末考成绩以及综合成绩分布如图4所示。从图中可以看出,男生的成绩波动范围比较大,末考成绩和综合成绩总体低于女生成绩。
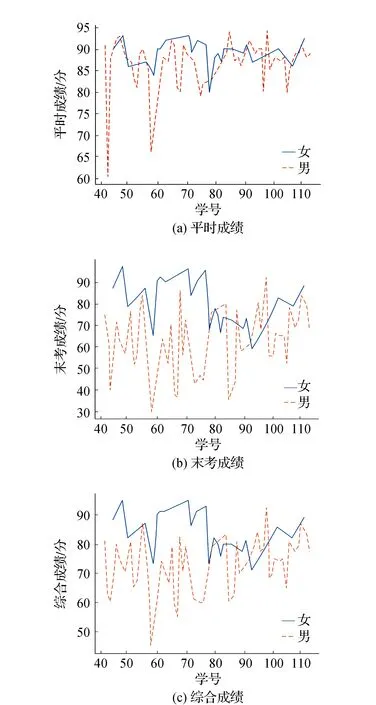
图4 17级学生成绩分布
2)18级不同性别的学生平时成绩、末考成绩以及综合成绩分布如图5所示。图5结果表明男生和女生的成绩波动都较大。
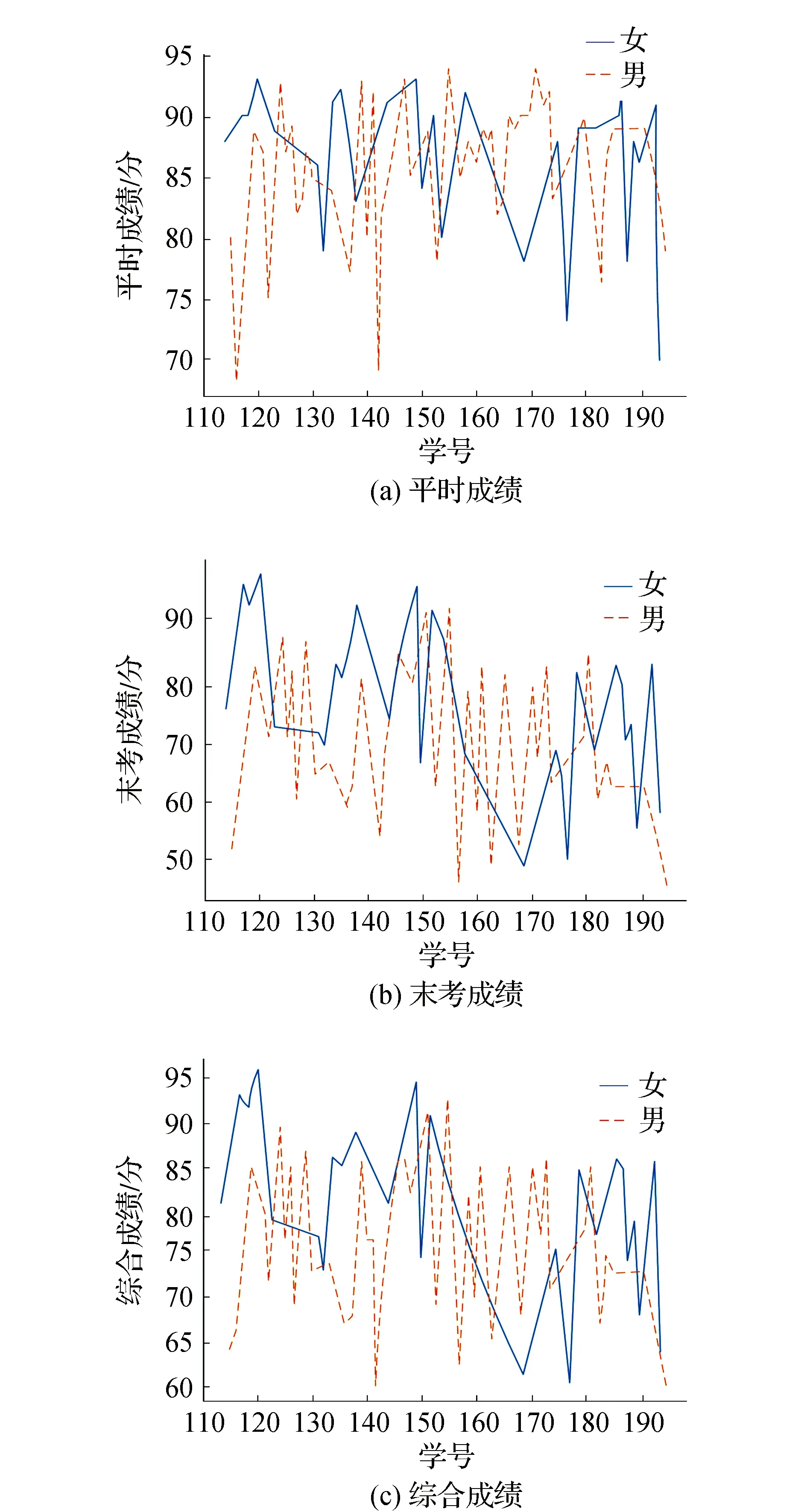
图5 18级学生成绩分布
3)19级不同性别的学生平时成绩、末考成绩以及综合成绩分布如图6所示。
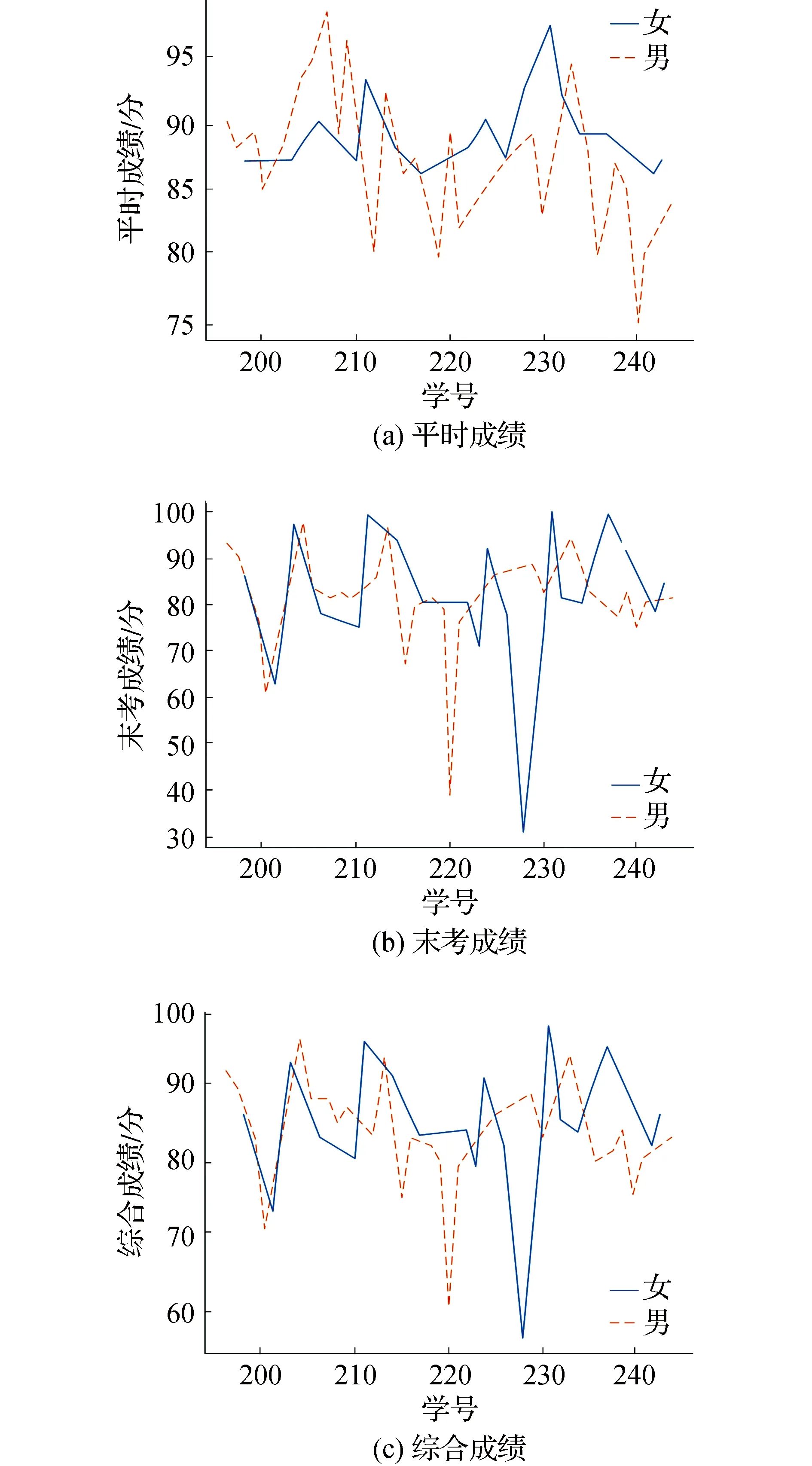
图6 19级学生成绩分布
如图6所示,虽然在平时成绩上男生和女生存在差别,但是末考成绩和综合成绩男生和女生的成绩波动范围大致相同。
综上所述可得出如下结论:17级学生接受的是传统教学方式,对于男生的学习兴趣影响不大,以致男生成绩低于女生成绩。从18级开始,采用任务驱动、问题激发的教学方式,对男生的学习状态有较大的激励作用。对于19级男生同样有较好的教学效果。
4.2 基于Python研究平时成绩和末考成绩的相关关系
为了进一步研究平时学习状态和期末考试的相关性,绘制散点如图7所示。图7中从左到右、从上到下分别是16级学生、17级学生、18级学生、19级学生成绩分布散点,横轴为平时成绩,纵轴为末考成绩。
如图7所示,16级学生中平时成绩和末考成绩都不及格的有2名,仅末考成绩不合格的有3名。17级学生末考成绩较差。18级学生成绩分布较均匀。19级学生有2名平时表现很好,但是末考成绩不理想。综上所述,如果学生末考成绩好,代表他的平时表现较好,但是平时表现并不决定末考成绩。
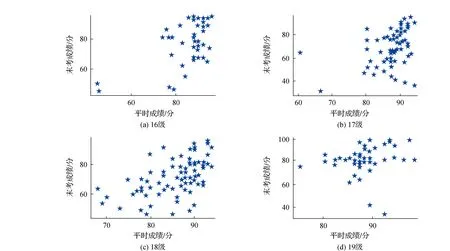
图7 平时成绩-末考成绩分布散点
4.3 构建学生标签结果分析
1)构建高成绩标签,结果如图8所示。将原始数据中的学号number、平时成绩regular_grade、末考成绩endterm_grade、综合成绩total_grade保存到学生标签表student_features中,并提取出高成绩标签high_score。可以看出综合成绩高于85分,high_score标签为1,否则为0。
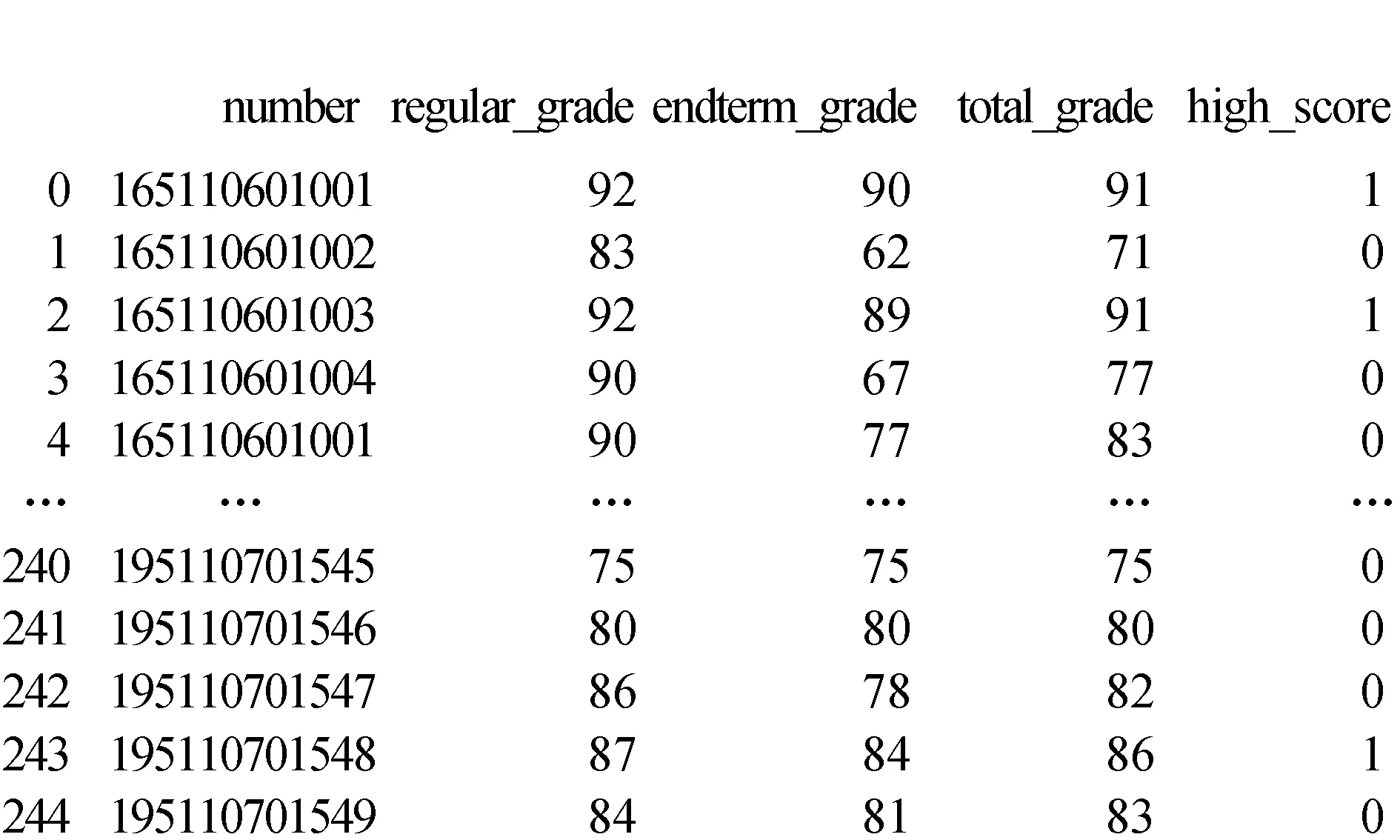
图8 学生标签表
2)构建及格标签,结果如图9所示。同上所述,其中,fail列就是所提取的是否不及格标签。可以看出,综合成绩低于60分,fail标签为1,否则为0。
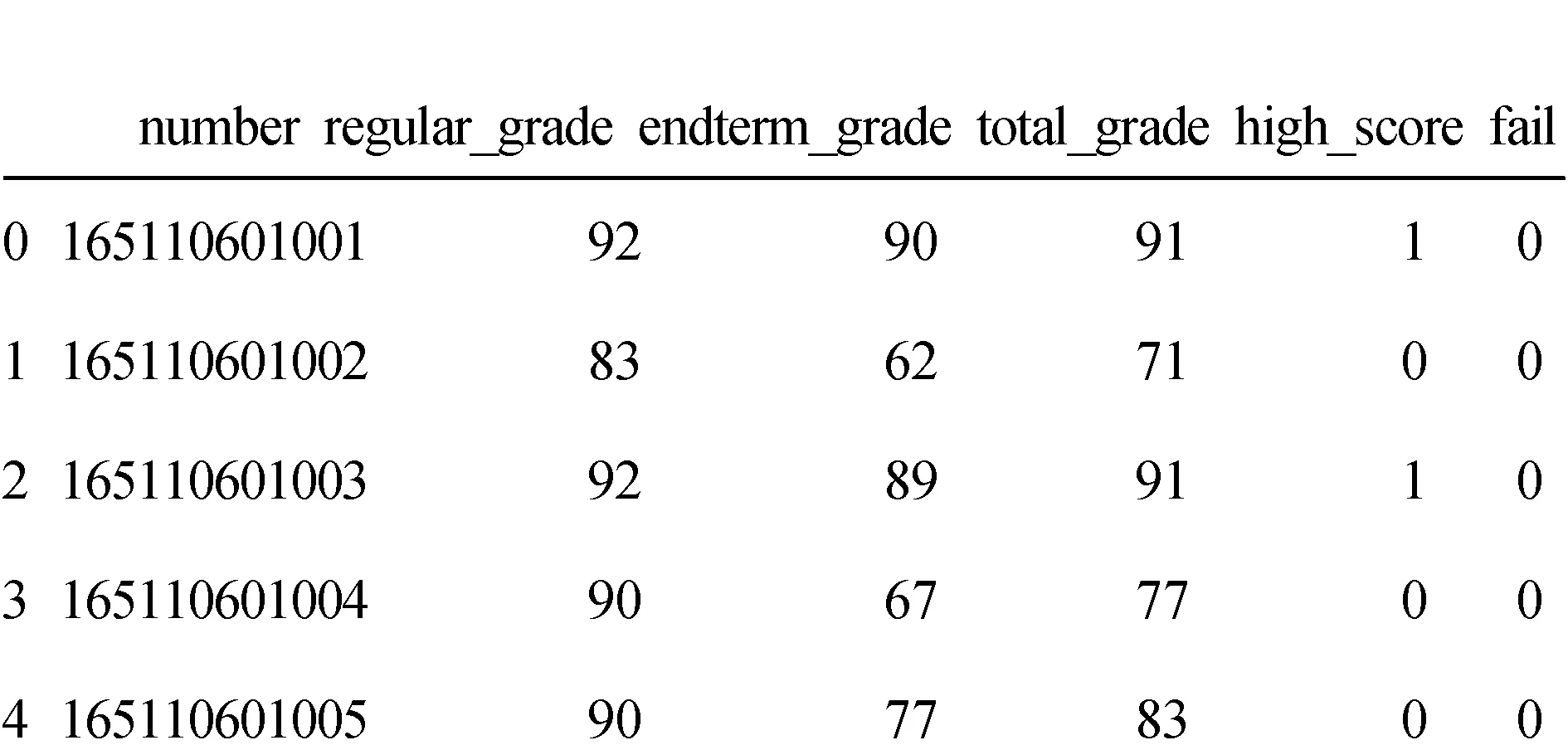
图9 学生标签表中fail标签
3)RET模型的计算及可视化结果分析
如图10所示,RET模型三要素对应的评分标记列为R_score、E_score、T_score,模型的总得分对应的列为score。根据总的得分可以把学生分为4类,对每类学生进行分析,然后做出精确的教学决策。
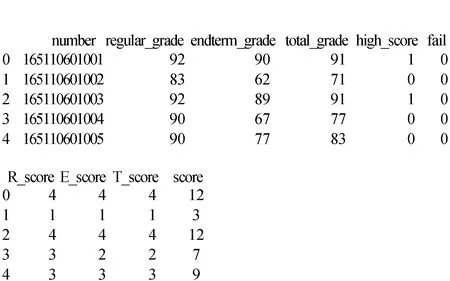
图10 RET模型评分
为了更直观地分析成绩规律,对RET模型进行可视化,如图11所示。3个子图的纵轴标签分别为每组学生平时成绩、末考成绩、综合成绩的平均值,横轴为总得分score。
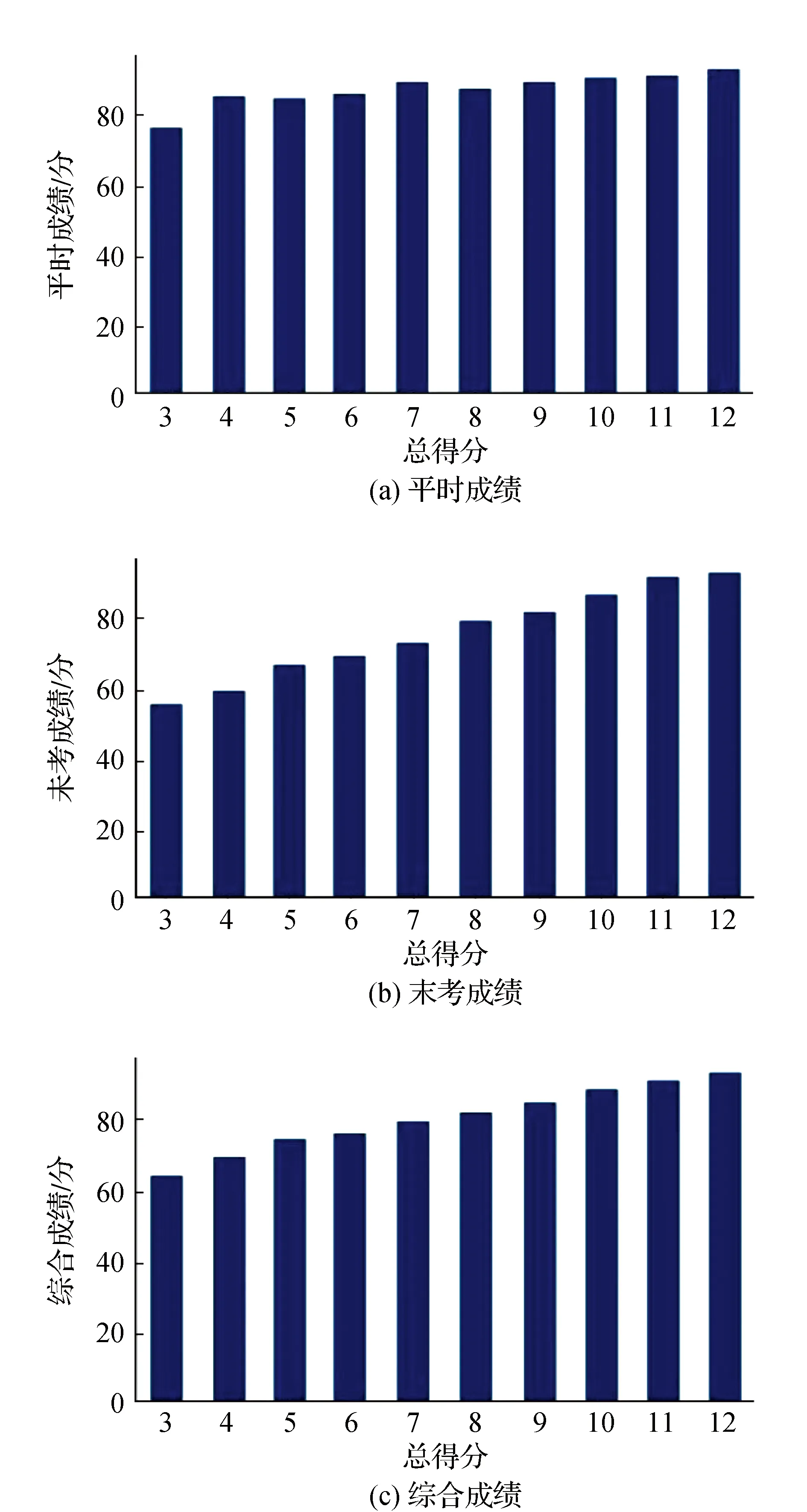
图11 RET模型可视化
从图11可知,随着总得分的增大,平时成绩、末考成绩、综合成绩的平均值逐渐增大,证明越优秀的学生成绩越高。
4.4 利用K-Means进行聚类分析的结果
为了更直观地观察聚类结果,设置标签为label,如图12所示。将聚类结果进行可视化展示,如图13所示。
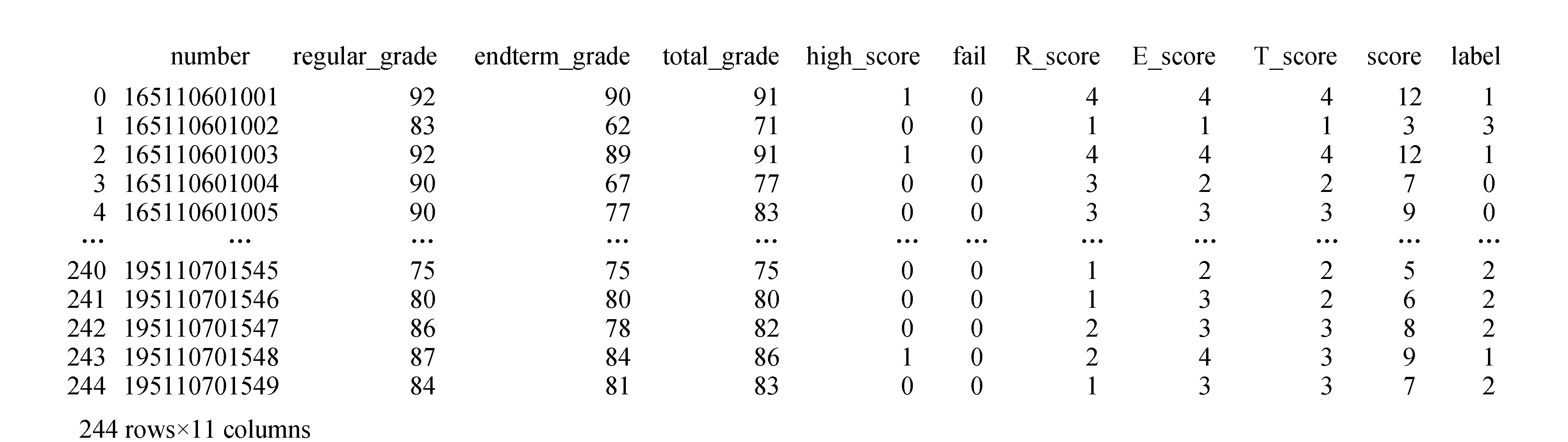
图12 聚类模型
从图13可知,学生被聚类为4类,边界比较清楚,聚类效果较好。从聚类结果可以看到,学生成绩大部分集中在70分和90分左右。据此教师可以及时调整教学策略,更好地因材施教,从而提高教学效果。
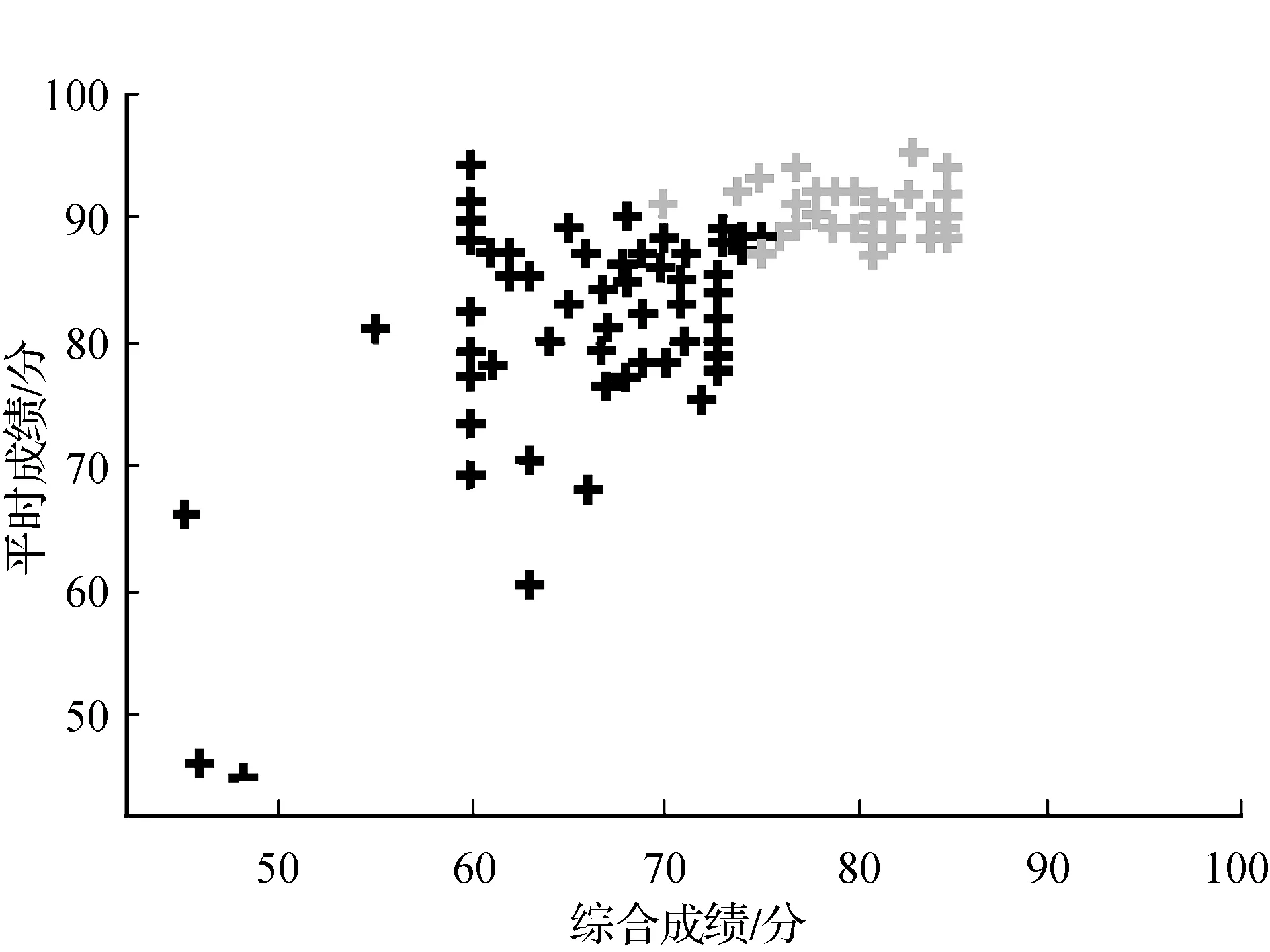
图13 聚类结果
5 结束语
采用上述分析方法对学院近4 a的学生成绩进行学情分析。首先,分析性别与成绩的相关关系。其次,分析平时表现和期末考试成绩的相关关系;利用RET模型对学生进行评分,最后采用K-Means聚类方法分析学生成绩的聚类规律。文中应用了可视化技术,使教师能够清楚地了解并挖掘出结果,做出精确的教学决策。
另外,在未来的研究中可以运用深度学习来分析学生的上课状态,通过摄像头采集学生上课时的图片,对图片进行相关处理,然后用深度学习对其进行情感分析,判断其听课态度,并合理调整教学方式,从而提高教学效果。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
师道·教研(2022年1期)2022-03-12
科教导刊(2020年21期)2020-08-12
海洋信息技术与应用(2020年1期)2020-06-11
体育科技文献通报(2020年4期)2020-04-07
传媒评论(2019年4期)2019-07-13
教学与管理(中学版)(2019年11期)2019-01-01
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
新闻传播(2016年13期)2016-07-19
