
基于深度学习模型的MOOC视频依赖关系识别方法
2022-08-18 07:06白友恒陈智军
郑州大学学报(理学版) 2022年5期
白友恒, 肖 奎, 张 , 陈智军
(湖北大学 计算机与信息工程学院 湖北 武汉 430062)
0 引言
随着教育技术日渐发展,出现了以大规模在线开放课堂(massive open online courses, MOOC)为代表的线上学习平台。MOOC视频具有主题广泛、学习方式灵活的特点。然而,学习者在MOOC平台进行自主学习时,普遍存在的问题是应该如何组织学习资源的顺序,这些学习资源包括MOOC视频、讲义、作业等。两个MOOC视频的学习顺序可以描述为MOOC视频的依赖关系。MOOC视频的依赖关系说明了学习者在进入下一个视频学习前,需要先学习的视频。例如,对于两个 MOOC视频A和B,如果学习者开始学习视频B知识点以前,必须事先掌握视频A的知识点,则称这种关系为B依赖于A。如何针对学习者不同的需求与知识背景,使用依赖关系自动推荐个性化的学习顺序,是教育数据挖掘领域的热门研究问题。
在以往的研究中,MOOC视频依赖关系识别通常采用专家知识建立课程间依赖关系来推荐学习顺序[1-3]。MOOC视频依赖关系的研究点主要聚焦在对MOOC视频的主要知识点(概念)依赖关系进行研究[4-5]。最早的概念依赖关系研究聚焦于提取一组特征进行有监督学习[6-11]。Chaplot等[12]利用MOOC视频的日志信息使用无监督学习的方法预测概念间的依赖关系。Pan等[13]使用从MOOC视频中提取的一组特征,包括概念出现的时间、顺序和频率来识别课程概念之间的依赖关系。Shen等[14]提出了一种生成MOOC视频序列图的方式提供给学习者查询,作者提出的预测课程依赖关系方法覆盖了较多同类型的课程。Manrique等[15]使用多种特征(图特征、语料特征、链接特征、层次特征)和机器学习方法预测概念依赖关系,通过概念依赖关系来计算MOOC视频的依赖关系,采用手工标注MOOC视频字幕来获取概念依赖关系,这种方法需要专家知识和人工投票完成,比较耗时且不易推广。如何实现自动预测课程依赖关系亟待解决。
现有研究的一大问题就是需要手工设计一些MOOC视频的用户行为特征,并从特征信息中识别依赖关系,但是特征工程的跨领域表现效果较差。因此,本文提出一种基于词向量和深度学习模型的方法自动识别MOOC视频依赖关系,通过提取MOOC视频的字幕,使用词向量抽取字幕的特征信息,并使用这些特征输入至深度学习模型进行MOOC视频依赖关系预测。实验结果表明,我们提出的方法在4个不同领域的MOOC视频都取得了不错的效果。
本文的主要贡献包含两个方面。
1)使用Word2vec、fastText和双向编码器的表示技术(bidirectional encoder representations from transformers,BERT[18]),能快速从视频字幕中获取有效特征表示,并结合深度学习长短期记忆(long short-term memorg,LSTM)模型或门控循环单元(gated recurrent units,GRU)完成MOOC视频依赖关系识别。
2)采用多人投票的方式,设计了一个MOOC视频依赖关系数据集,并在数据集上完成MOOC视频依赖关系识别实验。
1 研究背景
词向量能够在缺少大规模标签数据的情况下,抽取字幕有效特征表示,提高模型的泛化能力。本文分别使用Word2vec、fastText和BERT对MOOC视频字幕特征提取。
对MOOC视频字幕进行特征提取后,下一步是处理特征输入至深度学习模型。本文使用LSTM和GRU接收特征输入,进一步发掘隐性特征,其输出用以识别MOOC视频的依赖关系。
1.1 词向量
1.1.1Word2vec。Google在2013年提出了Word2vec[16],作为使用最广泛的词向量模型,它使用双层神经网络表述词向量。Word2vec训练结束后,可以视为一个函数fvocab,这个函数将语料库vocab的一个单词w映射为一个向量v∈Rd,形式化为
fvocab:w→v,
Word2vec对相似的单词进行分组,并且训练方式简单、易于上手,但对于不在语料库的单词(稀有词)无法提供矢量表示。
1.1.2fastText。fastText是Facebook AI团队2015年发布的开源自然语言处理(natural language processing, NLP)库,可以实现生成词向量和文本分类。它的准确性通常与深度学习分类器相当,但训练和评估的速度比其快多个数量级[17]。其主要思想是:单词内部字符结构通常包含单词相关含义的信息。这种方法将词汇w和子字符串序列(c1,c2,…,ct)的元组映射到一个词向量v,表示为
fsubword:(w,(c1,c2,…,ct))→v,
fastText依靠连续词袋(continuous bag of words,CBOW)模型和分层分类器来加快训练速度。此外,即使是稀有词,fastText也能生成词向量,这解决了Word2vec中稀有词无法使用矢量表示的问题。
1.1.3BERT。2018年,Google AI团队发布了基于Transformer的BERT方法,由于其出色的扩展性和性能表现,现在已经应用在许多自然处理领域的任务中。
在基于上下文方面,BERT相较于Word2vec和fastText方法有着明显的优势。BERT的主要思想是:特定文本中特定单词的意思不仅取决于单词的本身,还取决于当时围绕它的单词。对于单词集合或句子(w1,w2,…,wN)中的一个单词wi∈W,语言的上下文表示是一个函数fcontextual,BERT为序列中的每个单词分配一个向量表示。可以形式化为
fcontextual:(w1,w2,…,wN)→(v1,v2,…,vN),
BERT的创建者将训练阶段与算法应用于特定任务所需的调整阶段分离开来,该算法必须整体进行一次训练,然后针对每种情况进行专门的微调。
1.2 深度学习模型
1.2.1LSTM 在深度学习领域,使用循环神经网络(recurrent neural network,RNN)处理时序性的信息已成趋势[19]。RNN包含链式结构和隐藏状态机制,其输出相互关联,擅长处理序列信息。然而,链式结构也导致了并行化处理困难,并且可能会在许多隐藏状态更新之后丢失信息。为此,长短期记忆(LSTM)网络[20]是RNN的一种改进形式,解决了RNN的梯度消失问题。LSTM非常适合给定未知时滞的时间序列的分类、处理和预测问题,其有3个门控单元,模型结构如图1所示。

图1 LSTM模型结构
1)输入门。用来决定输入中哪些部分用于修改存储值。sigmoid(σ)函数决定是否让部分值通过。tanh函数对所传递的值进行加权,以决定下一步更新内容,添加新信息替换旧信息完成对细胞状态的更新。所用公式为:
it=σ(Wi·[ht-1,xt]+bi),
it=σ(Wi·[ht-1,xt]+bi),
2)遗忘门。处理细胞中需要丢弃的状态信息。由sigmoid函数决定,其依赖于前一个时刻隐藏层状态ht-1和当前输入xt,单元状态Ct-1中的输出为0(省略)和1(保留)之间的数值。
ft=σ(Wo·[ht-1,xt]+bo)。
3)输出门。输入和细胞用于决定输出,sigmoid函数决定让哪些值通过,tanh函数对所传递的值进行加权以决定其重要性级别(从-1到1),并乘以sigmoid的输出。所用公式为
输入门、遗忘门、输出门的设计解决了RNN梯度衰减的问题,可以高质量地捕捉时间序列中时间跨度较大的依赖关系,适合用来进一步挖掘MOOC视频的隐藏特征与依赖关系。
1.2.2GRU 尽管LSTM可以解决大多数长时序列问题,但这种复杂的结构设计可能会增加计算成本,并且难以训练[20]。如图2所示,门控循环单元(GRU)[21]是LSTM的一种变体,但仅使用更新门zt、遗忘门rt两个结构,它们决定了应将哪些信息传递给输出。更新门zt可帮助模型确定需要将多少来自先前的时间步长的过去信息传递给当前状态,zt使用sigmoid激活函数压缩在0和1之间,值越大代表传递信息越多。遗忘门rt是用来决定要忘记多少过去的信息,值越小代表忘记过去信息越多。
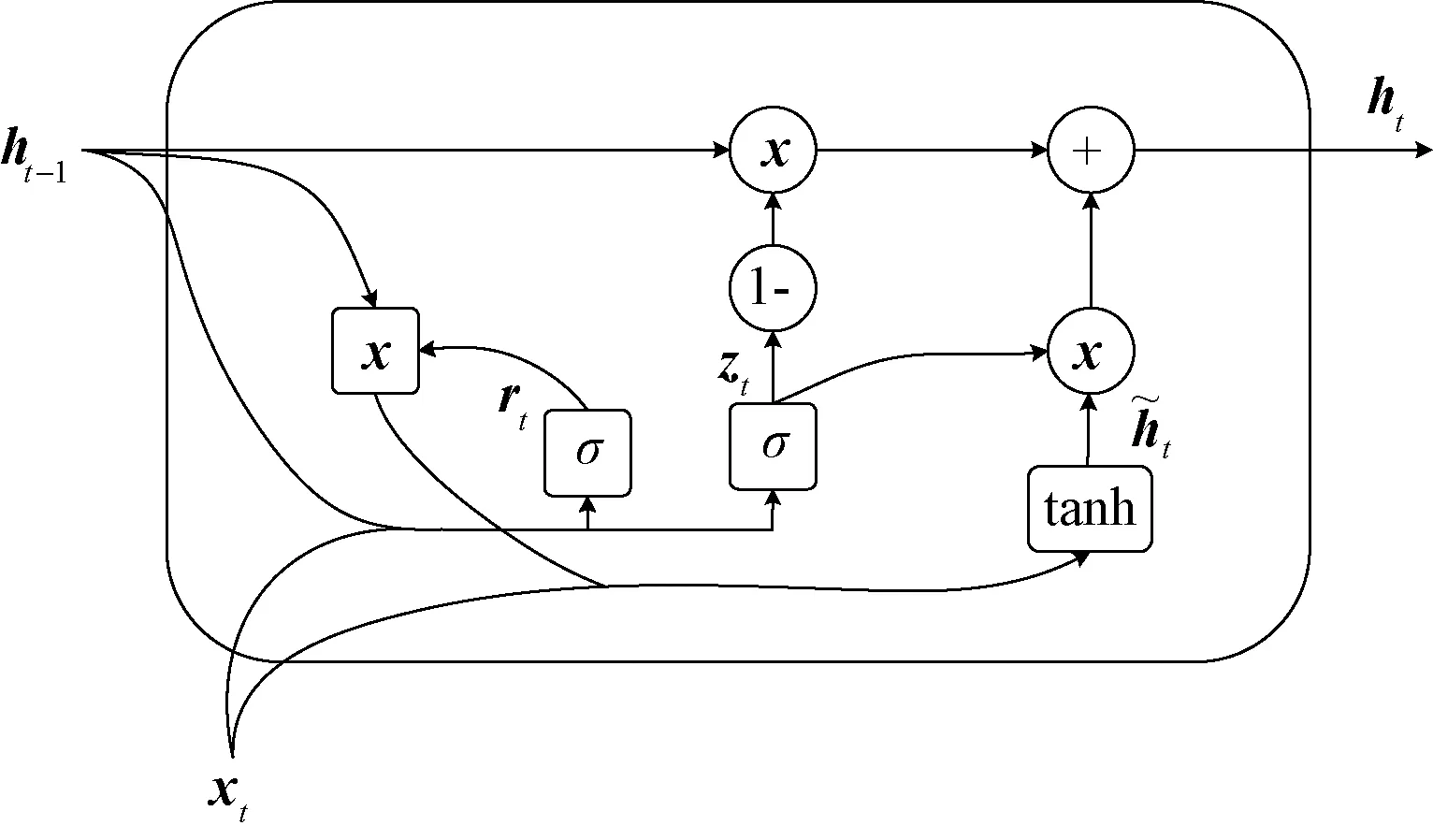
图2 GRU模型结构

zt=σ(W(z)xt+U(z)ht-1+bz),
rt=σ(W(r)xt+U(r)ht-1+br),

2 MOOC视频依赖关系识别方法
基于词向量和深度学习模型,本文提出了6个MOOC视频依赖关系识别模型。分别是Word2vec-LSTM/GRU、fastText-LSTM/GRU和BERT-LSTM/GRU。
2.1 基于词向量的MOOC视频依赖关系识别
对于MOOC视频对(A,B),本文使用视频字幕完成特征抽取,为每个视频字幕抽取Word2vec/fastText词向量。为了便于模型接收两个视频字幕的等长序列和减少计算量,本文选取阈值k来设定MOOC视频字幕的最大序列长度。我们设定每个课程领域的90%的MOOC视频的字幕长度需要大于k。
模型结构如图3所示,模型接受两个MOOC视频长度为k的字幕的词向量集合,分别输入至两个带有32个单元的LSTM或GRU神经网络,其输出分别为O(A)和O(B)。对两个输出进行拼接O(A)⊕O(B),拼接的结果作为MOOC视频对(A,B)的自动特征,输入带有sigmoid激活函数的全连接层,完成MOOC视频的依赖关系识别。

图3 Word2vec/fastText词向量与深度学习模型
2.2 基于句向量的MOOC视频依赖关系识别
此外,本文还使用BERT句向量对MOOC视频字幕进行特征提取。在一些NLP任务中,句子含义的表示能够表征句子意图,而无须单独计算词向量。
MOOC视频字幕由多个句子构成,具有丰富语义信息,适合自动进行特征抽取。但是,为了解决两个视频的字幕长度k相同但句子数量不同导致输入序列信息不一致的问题。我们采取了一种“截取-补充”的方法,该方法能处理等长的序列信息输入,且最小限度减少上下文信息损失和计算量,方法如图4所示。对于某个MOOC视频,选取长度为k的视频字幕,生成k/l个长度为l的句子集合。具体而言,本文将MOOC视频对(A,B)长度为k的字幕S划分为多个长度为l的句子集合{s1,s2,…,sk/l},为了不丢失句子间的上下文信息,每个长度l的句子后20%的单词对其进行复制,补充在下一个句子头部,依次复制和补充,生成k/l个等长句子,对等长的句子集合生成k/l个BERT句向量集合。生成的BERT句向量集合输入两个带有32个单元的LSTM或GRU神经网络中,输出O(A)和O(B),拼接为O(A)⊕O(B),输入至带有sigmoid激活函数全连接层,实现MOOC视频依赖关系识别。模型结构如图5所示。

图4 “截取-补充”方法

图5 BERT句向量与深度学习模型
3 实验与结果分析
3.1 数据集
本文采取多人投票方式创建MOOC视频依赖关系数据集,创建数据集的工作如下。首先使用coursera-dl在Coursera下载4个不同领域(食物与健康、算法、微积分、世界历史)的视频和字幕,随后按照每门课程的顺序(v1,v2,…,vn),生成了(v1,v2),(v1,v3),…,(vn-1,vn)的4个领域的MOOC视频对集合。随后,为了获取MOOC视频对依赖关系数据集的标签,本文邀请3位硕士研究生观看视频,对MOOC视频资源对进行依赖关系投票。对于一个MOOC视频对(A,B),其依赖关系分为3种:1)B依赖于A(“1”);2)B不依赖于A(“0”);3)不知道(“N”)。如果出现了平票,或者选项3获得了多数票,则视频对将被丢弃。最终获得的视频对数量和具有依赖关系对数量如表1所示,详细投票信息和MOOC视频字幕已发布在GitHub(https:∥github.com/Morganbyh/course-vote)上。
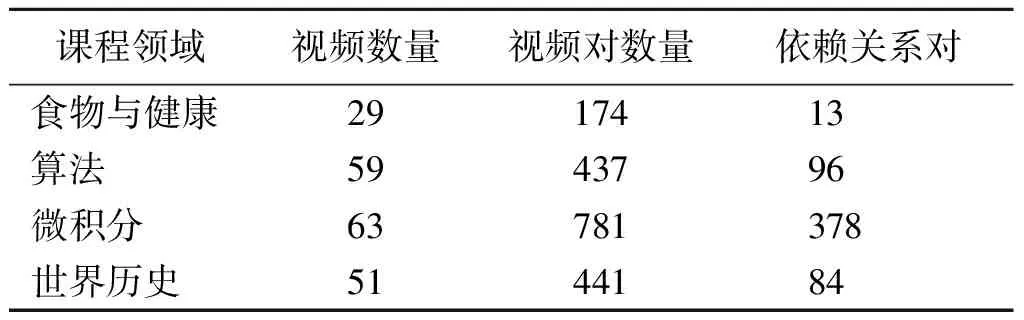
表1 MOOC视频依赖关系数据集
3.2 词向量模型
生成词向量和句向量集合的预训练语料库如下。
1)Word2vec词向量。使用Wikipedia2vec[22]提供预训练的100维词向量模型,训练的语料库来自2018年4月20日备份的所有英文维基百科词条。
2)fastText词向量。使用Facebook提供的wiki-news-300d-1M.vec词向量集合,其在Wikipedia 2017,UMBC Web base语料库和statmt.org新闻数据集上训练了100万个300维的词向量。
3)BERT句向量。使用Bert-as-service生成句向量,它可以根据预先训练好的BERT模型将不定长度的MOOC字幕映射到大小为768维的句向量。
3.3 参数设置和评价指标
为了MOOC视频依赖关系模型接收等长输入,经过计算,句子长度划分单位长度l设置为100,4门课程设定的阈值k分别为:食物与健康为1 500;算法为3 600;微积分为3 600;世界历史为7 000。
本文使用的实验平台为25 G RAM的Google Colab,采用Keras深度学习框架,对不同的模型调整超参数进行验证以获取性能最佳模型。采取5折交叉验证,70%数据训练集,10%交叉验证集,20%数据测试集。交叉验证集用来选择超参数防止过拟合,测试集评估模型的性能,模型的参数设置如表2所示。
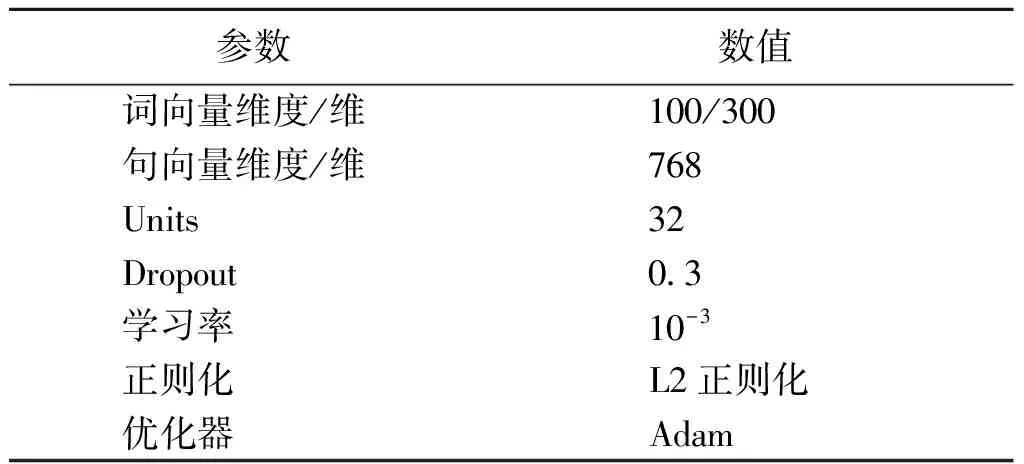
表2 模型参数选择
本文采用Accuracy、Precision、Recall和F1值来评价不同词向量与深度学习模型组合在MOOC视频依赖关系识别任务的性能表现。Accuracy表示预测正确(TP+FP)的视频对占总视频对的比例,所用公式为
Precision表示预测有依赖关系的视频对(TP+FP)中正确识别有依赖关系视频对(TP)的比例,所用公式为
Recall表示在所有预测有依赖关系的视频对(TP+FN),被正确识别(TP)的比例,所用公式为
F1值综合考虑Precision和Recall,是它们两者的调和平均值,所用公式为
3.4 实验结果与分析
表3给出了使用Word2vec、fastText和BERT作为自动特征输入,结合LSTM和GRU深度学习模型的MOOC视频依赖关系识别的实验结果。

表3 MOOC视频依赖关系识别模型在4个数据集上的实验结果
从实验结果来看,Word2vec-LSTM平均F1值要优于fastText-LSTM 3%左右。可能的原因是fastText词向量是由包含在其中的单词的子字符串向量构成的,这可能导致模型为无实义的子字符串构建词向量。由于选用视频的字幕罕有稀缺词,Word2vec词汇表已经足够表征字幕的单词,表现更佳。
BERT-GRU平均F1值比Word2vec-GRU高7%,主要是因为视频的字幕信息量较多,且前后联系紧密,基于BERT的句向量自动提取了上下文的语义特征信息,表现更好。
使用Word2vec、fastText词向量的效果要低于BERT句向量。因为BERT对视频资源的文本信息进行了序列化处理,捕捉字幕单词上下文信息,以便更好识别两者之间的依赖关系。但是,LSTM模型的训练时间相较于GRU要长得多。
BERT-LSTM在微积分和世界历史的F1值超过BERT-GRU分别达4.13%和16.2%,平均值超过8%。在食物与健康领域,BERT-GRU的precision优于BERT-LSTM的原因是LSTM比GRU能记住更长的序列,但该门课程视频选取的句子长度k值偏小,GRU参数量少,不容易过拟合。但BERT-LSTM的Recall达到1.0的原因是样本数量偏少,模型对正例可以全部预测正确。总体而言,基于LSTM的词向量输入模型都取得了很好的效果。
同时,从课程内容分析,算法和世界历史整体效果要低于其他两门课程的主要原因一方面是正例偏低,另一个原因是算法的课程内容多次使用一些背景知识,比如迭代器、Java语法知识等,背景知识重叠减弱了自动特征提取的表现能力。世界历史课程视频的授课方式按照时间线展开,时间跨度过大的MOOC视频对之间的依赖关系不强。
3.5 消融实验
为了研究LSTM和GRU提取MOOC视频字幕隐性特征的作用。实验中还将LSTM和GRU替换为一个全连接层(BERT-FC),在4个课程领域进行MOOC视频依赖关系识别对比实验。由图6可知,在食物与健康、算法、微积分和世界历史4个领域的课程上,BERT-LSTM要优于BERT-FC分别达12.02%、5.02%、18.66%和9.14%。这表明使用BERT学习字幕上下文表示的编码层,可以提高LSTM神经网络的性能表现,LSTM和GRU也能进一步学习有效的隐性特征表示。
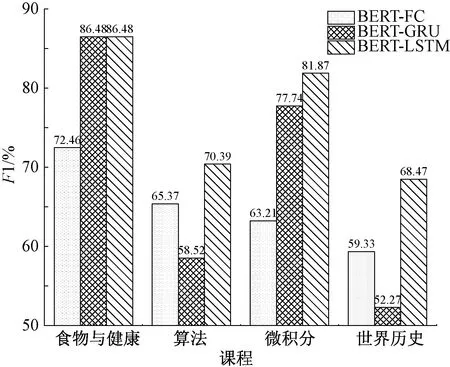
图6 BERT-FC与所提出模型的对比实验
4 总结
基于MOOC视频学习顺序推荐的需求,本文提出了基于词向量和深度学习模型组合的MOOC视频依赖关系识别模型。该模型自动从视频字幕提取多种主流特征嵌入,并结合LSTM和GRU进行MOOC视频依赖关系预测,给学习者提供合适的学习顺序推荐、学习路径规划。在4个领域MOOC视频依赖关系数据集上的实验结果表明,BERT-LSTM模型表现最佳,4个领域MOOC视频的平均F1值超越其他模型达6.19%。未来将从以下两个方面改进原有工作。
1)增加MOOC视频依赖关系对,扩充数据集有助于提升模型的MOOC视频依赖关系识别能力。
2)分析影响MOOC视频依赖关系识别的其他因素,如视频字幕文档长度、词向量维度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
阅读(快乐英语高年级)(2020年8期)2020-01-08
北京广播电视报(2019年8期)2019-03-27
智慧少年·故事叮当(2018年11期)2018-05-14
电脑爱好者(2017年13期)2017-07-31
电脑爱好者(2017年13期)2017-07-31
电脑爱好者(2016年24期)2017-01-05
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
