
基于机器阅读理解的商品属性识别
2022-08-15 07:10张飞宇马进贾昊张世奇陈文亮
山西大学学报(自然科学版) 2022年4期
张飞宇,马进,贾昊,张世奇,陈文亮
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
随着互联网、云计算、大数据等信息技术的发展,全球数据量呈现爆炸式增长。如何将大量非结构化数据转化为结构化数据,是一项值得思考的工作。在本文中,属性抽取定义为:给定一个实体及其属性类别列表,从一个非结构化文本中抽取出该实体的各个属性值。
属性抽取的应用非常广泛。一方面,属性抽取是构建知识图谱的关键子任务,可用于知识图谱的补全和纠错。另一方面,属性抽取可用于辅助各领域任务,例如,事件抽取[1]任务中用于提供事件的特有属性,以及对话系统[2]中用于抽取对话状态,进行槽填充。
商品属性在电子商务平台上常用于推荐系统,产品排名以及后端检索。通常,商品属性也是用户评估商品价值和做出消费决定的重要依据。在大型且复杂的电子商务系统中,商家擅长堆叠属性值突出其产品品质,平台规范制定不严谨,导致商品属性嘈杂且不完整。在电商知识图谱构建过程中,属性抽取从电商平台商品文本或社交媒体数据中获得属性和属性值对,以达到扩充电商知识图谱的目的。由于相关数据源源不断地产生,如何高效地从电商数据中抽取出与商品相关的属性信息是一个很有挑战的课题。
本文专注于商品属性抽取,即从非结构化数据中(例如标题和评论)抽取出商品属性对应的属性值。如表1所示,给定关于实体“连衣裙”的商品标题文本,以及属性类别列表“材质”“风格”和“颜色”,属性抽取系统从标题信息中抽取出对应的属性值。

表1 商品属性识别示例Table 1 Example of product attribute recognition
现有常见属性抽取方法利用循环神经网络[3](Recurrent Neural Network,RNN),或其变体 如 长 短 期 记 忆 网 络[4](Long Short-Term Memory,LSTM)和门控神经网络[5](Gated Re⁃current Unit,GRU)等作为基础构建序列标注模型捕捉特征进而识别属性值。然而,在实际场景应用中上述方法存在以下问题:
(1)可扩展性差。这些方法在面对大规模属性的时候性能会大幅下降。属性数量越多,相对于模型属性之间会越缺乏差异性,导致无法给识别出的实体分配恰当的属性标签。
(2)可泛化性差。新产品和新属性不断产生,这些方法只能处理出现过的属性类别,而对新属性类别没有兼容能力。同时商品的属性值通常会有未登陆词(Out of Vocabulary,OOV),即超出词表外的属性值,序列标注模型只能识别少量未登陆词。
本文提出一种结合机器阅读理解进行属性识别的模型——MPAR(MRC framework for Product Attribute Recognition)。机器阅读理解在给定文本和问题的场景下,要求模型在文本中找到回答问题的跨度(Span)。该方法可加强属性在文本中的主导作用,由此帮助抽取模型识别出对应实体并过滤其他属性。本文的贡献总结如下:
(1)提出一种基于机器阅读理解的属性抽取策略,每种属性类别被转换为一种自然语言问句,然后根据文本回答问句来得到属性值。例如,抽取句子“春夏促销蓝色棉麻卫衣”中“颜色”的属性值“蓝色”作为问题“文本中涉及的颜色属性”的答案。该方法为每种属性构造独立的问句,可帮助属性抽取系统有效应对属性类别增多的情况,提高模型的可扩展性。
(2)针对不同询问策略效果不一的问题,研究把属性转换为问题的不同构建方法。同时针对传统提取跨度的解码器低效的问题,探究不同解码器对性能的影响。最后本文提出全新的问句和解码器组合,在通用的评价指标上该组合效果最优,并且能有效地识别未登录词,增强模型的可泛化性。
1 相关工作
1.1 属性抽取
属性抽取早期采用基于规则和机器学习的方法。基于规则需要手动构造领域特定的特征模板,Chiticariu等[6]设计并实现高级语言,并简化了构建,理解和定制基于规则的复杂注释器的过程。李红亮等[7]构造一系列规则进行百科人物属性抽取。Hearst等[8]构建一系列模式在自由文本中获取下位词词汇关系。该方法虽然可以高效地完成属性识别任务,但是模式构造难度大、维护代价高,而且构造的模型领域黏性高,难以移植到其他领域。基于机器学习的方法分为无监督和有监督方法,该方法在有部分实例和模式的情况下,迭代地生成新的实例和模式。Gopalakrishnan等[9]提出无监督匹配算法,利用Web搜索引擎对齐来自不同数据源的产品标题。Ghani等[10]将提取隐式和显式属性表述为分类问题,提出单视图和多视图半监督方法对大量未标记数据进行挖掘,从而在产品说明中准确提取属性值对。
近年来,随着深度学习技术的发展,很多研究人员将深度学习技术用在属性抽取任务上。马进等[11]利用条件随机场(CRF)和双向长短时记忆-条件随机场(BiLSTM-CRF)两种基线模型进行百科人物属性抽取。Zheng等[12]将注意力(attention)层添加在双向长短时记忆(BiL⁃STM)层和条件随机场层之间,可加强对属性值的关注,并为模型的决策提供可理解的解释,该方法可有效地进行开放域属性抽取任务。为了解决Zheng等[12]的工作不能解决大规模属性抽取的问题,Xu等[13]将商品标题和属性分别通过 BERT[14](Bidirectional Encoder Rep⁃resentations from Transformers)层和双向长短时记忆层获得各自的编码表示,再使用交叉注意力层融合标题和属性的编码表示,最后使用条件随机场层产生输出。程梦等[15]提出融合情感词的交互注意力机制来辅助双向长短记忆网络定位文中包含的属性值。Wang等[16]采用类问答机制将属性加在问句之中,将问题回答,蒸馏的屏蔽语言模型和无答案分类组合在一个多任务框架里。Karamanolakis[17]等构建层级的产品类别网络,通过分类条件的自注意力和多任务学习让模型同时判断数据中的产品类别,以实现在数千产品类别中抽取属性值。
1.2 机器阅读理解
机器阅读理解方法的思想是从需要提取知识的文本中提取出想要的文本知识跨度。该任务可归纳为两个多分类任务,两个分类器分别预测短语的开始位置和结束位置。目前在非结构化文本上机器阅读理解最先进的方法是神经网络方法和注意力机制。Wang等[18]提出了一种端到端的神经体系结构处理文本的机器理解任务,该体系基于匹配-长短时记忆(match-LSTM)网络和指针网络。Seo等[19]用多阶段的分层过程代表不同粒度级别的上下文,并使用双向注意力流网络生成问题敏感的上下文表示,能够通过关注给定段落中的正确位置来回答复杂的问题。Shen等[20]提出推理网络来辅助机器阅读理解任务,利用多回合机制来有效地利用查询,从而对查询文档和答案之间的关系进行推理,并通过强化学习在认为得到答案时终止阅读。Chen等[21]使用wikipedia作为唯一的知识源来找寻开放域问题的答案,将文档搜索和机器阅读理解相结合。
最近部分工作尝试融合机器阅读理解的方法到各自领域中,Levy等[22]首次将关系抽取问题转化为问答问题处理。Mccann等[23]将10个不同的任务统一用问答的结构处理,提出了一个多任务问答网络,该网络表现出了良好的转移学习,领域自适应和零次(zero-shot)功能。Li等[24]将实体关系抽取看作是多轮次问答问题,多轮次设置不仅编码了任务关注的实体或关系信息,而且也提供联合抽取实体和关系的自然方法。Li等[25]将命名实体识别任务构造为机器阅读理解任务,提出一个统一的框架同时处理嵌套和非嵌套命名实体识别任务。
2 研究方法
本文构建了基于BERT框架的属性识别系统。解码层设置和问句构建是其最重要的两个部分,分别于2.2节和2.3节介绍。
2.1 模型结构
本文提出一种基于机器阅读理解的属性识别方法MPAR,模型框架图见图1。模型由三层组成:对输入标记进行编码的词向量层,捕捉输入序列内部复杂语义关系的编码层,以及得到最终结果的解码层。
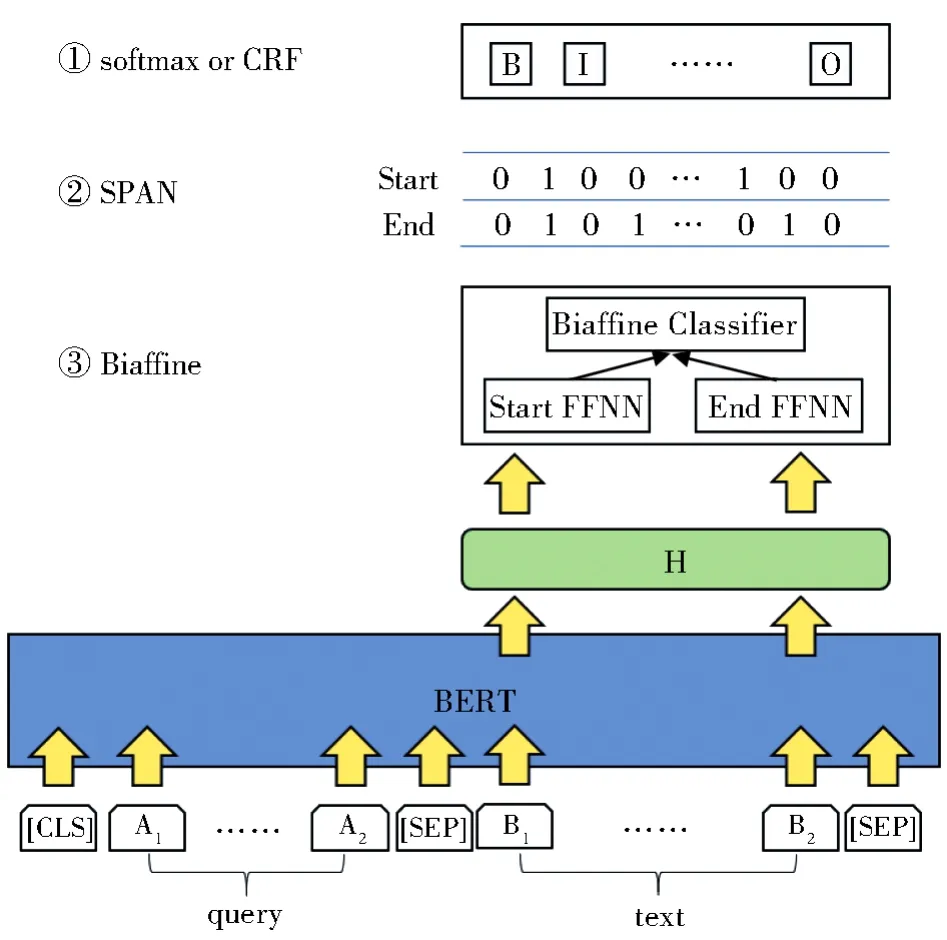
图1 MPAR模型框架图Fig.1 Frame diagram of MPAR model
词向量层将输入问句和商品文本按照固定形式输入:[CLS]+问句+[SEP]+文本+[SEP],其中[CLS]和[SEP]分别用于标识输入的开头和间隔两个句子。输入表示由三层词向量相加构成 :WordPieceEmbedding[26]构建 的每个标记的词向量(Token Embeddings),区分两个不同句子的段词向量(Segment Embed⁃dings),以及突出标记位置的位置词向量(Posi⁃tion Embeddings)。
编码层使用BERT来编码输入的词向量表示。BERT采用堆叠双向Transformer架构,对输入序列中的每个标记生成特定的语义表示E∈Rn×d,其中d为BERT最后一层输出向量的维度。为了更适应属性抽取的场景,编码层对BERT采取微调(finetune)策略,并且只取商品文本的输出向量。
解码层解码层将编码层输出的词序列隐层表示作为特征,并提取出答案。由于传统MRC模型采用提取跨度的解码器用于识别嵌套实体的场景,在本任务上识别属性值能力差,所以本文深度探究不同输出层对模型性能的影响。
2.2 解码层
解码层设置对最后提取出对应的属性值十分关键,本节主要讨论SPAN解码器、SOFT⁃MAX解码器、CRF解码器以及Biaffine解码器。
SPAN 基于指针网络的解码器训练三个分类器,分别是:1.预测所有位置是否是识别实体开始位置的二元分类器;2.预测所有与位置是否是识别实体结束位置的二元分类器;3.预测所有开始位置和结束位置是否匹配的二元分类器。预测出实体后,问句所对应的属性即为该实体所对应的标签。
SOFTMAX (Cui等[27]、Li等[28]、Xu 等[29])使用多层感知机+softmax将序列标注任务转化为多分类问题。该层为所有属性分配全局标签,即不为每个属性设置独立的B、I标签,而是所有属性采取统一的B、I标签。解码时,识别实体具体的标签类型为问句所对应的属性类别。
CRF 序列标注模型将条件随机场[30]当作是解码器的最佳选择之一,常用在CNN层[31-32]或LSTM层[33-34]之上,该层采用与softmax层相同的全局标签设置。假设标签个数为m,对于输入序列X=(X1,X2,…,Xn),计算可得维度为n×m的分值矩阵P,矩阵中元素Pi,j代表第i个输入状态标注为第j个标签的得分。对一组预测标签序列Y=(Y1,Y2,…,Yn),定义它的得分Score如式(1)所示:
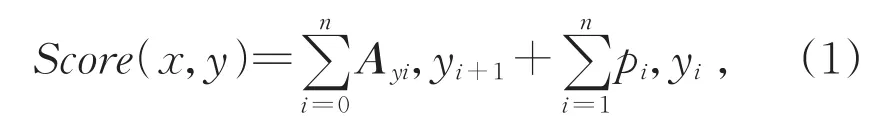
其中A是转移得分矩阵,Ai,j代表从标签i转移到标签j的得分。y0和yn是标签序列中的起始和结束标签。经归一化可得标签集合Yx的条件概率P,如式(2)所示:

在训练过程中,最大化式(2)中正确标签序列的对数似然概率。测试时,选取满足式(3)的结果y*作为最佳预测标签序列:
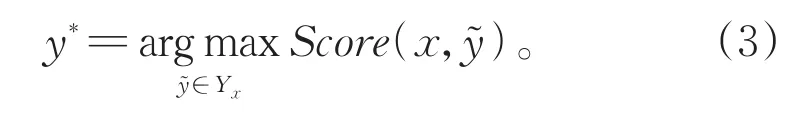
BIAFFINE 双仿射注意力模型在依存句法分析领域[35]中被广泛使用,Yu 等[36]首次将其运用到命名实体识别任务中。Biaffine解码器使用两个前馈神经网络(Feedforward Neural Net,FFNN)生成两个句子级表示,用于学习跨度的开始信息和结束信息。给定BERT的输出矩阵E∈Rn×d,对于每个可能成为开始索引的,使用一个前馈神经网络生成跨度的开始表示,见式(4):
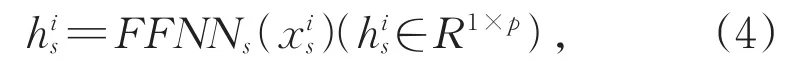
其中,p是前馈神经网络的隐层维度,跨度的结束表示使用另一个前馈神经络生成,见式(5):

之后使用双仿射注意力模型对所有的开始表示和结束表示生成分数矩阵S∈Rn×n×c,其中n是商品文本的长度,c是属性实体的数量加一,加一为了表示不属于任何属性(NA)。对于每个开始表示和结束表示,计算分数矩阵,见式(6):
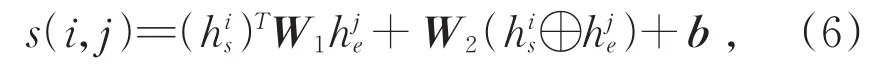
其中W1∈Rp×c×p,W2∈R2p×c,b∈Rc是偏差向量。解码时,按照属性类别得分对所有除非属性(NA)之外的所有类别的跨度进行排序,之后两条规则成立时,判断为实体边界冲突:对于实体 A(sa,ea)和实体 B(sb,eb),如果sa≤sb≤ea≤eb或者sb≤sa≤eb≤ea,判定为边界交叉;如果sa≤sb≤eb≤ea或者sb≤sa≤ea≤eb,判定为实体包含。当跨度边界冲突时,选取得分高的实体。模型的学习目标是为每个有效跨度分配一个正确的属性,即多分类问题,因此使用soft⁃max交叉熵优化模型,损失函数计算见式(7)和式(8):
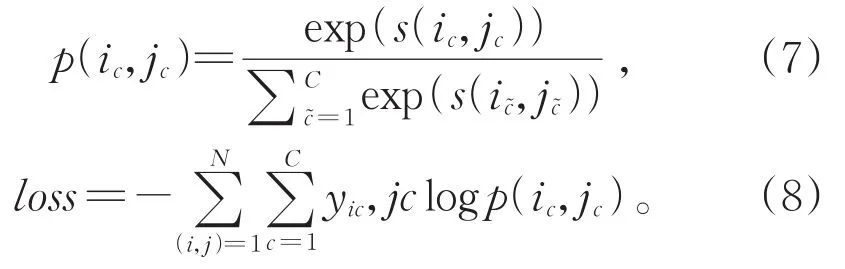
2.3 问句构建
传统的序列标注模型仅将属性当作区分不同类别的标签,属性信息不参与模型训练的过程。机器阅读理解方法的优势是在模型训练的过程中加入属性类别信息,让模型理解所要识别的属性。所以问句对于模型理解任务和融入其信息到文本表示中进而推理出答案具有重要意义。显然只采用属性类别本身作为问句不能融入足够的先验信息,实验也证明该问句方式难以达到最好效果。本节构建了几种问句方式,见表2。

表2 不同类型问句示例Table 2 Example of different types of queries
首先使用属性类别本身构造问句,例如属性“颜色”构造问句为“颜色”;其次考虑使用属性类别语义信息相似的同义词,例如使用词典构造属性“颜色”的同义词问句为“色彩”;之后考虑将属性和同义词连接起来,目的是比较其与单独属性问句或者同义词问句的性能,例如属性“颜色”构造的问句为“颜色和色彩”。
本文继续研究复杂问句,首先使用规则模板生成问句,该问句包含较为完整的语义信息,例如属性“颜色”构造问句为“文本中涉及的颜色属性”;其次考虑将属性类别语义信息用通俗语言来表达而不包含属性本身,使用维基百科或百度百科知识对于属性的官方定义构造问句,例如属性“颜色”对应的问句为“眼,脑和我们的生活经验对光的颜色类别描述的视觉感知特征”;之后使用注释准则构造问句,注释准则是为了指导注释者标注数据集的说明,它要求对属性类别有尽可能通用并且尽可能大区分度的描述,便于注释者毫无遗漏的标注出属性值。如果模型能够理解注释准则,那么会对模型识别属性提供巨大帮助,例如属性“颜色”对应的问句构造为“商品颜色属性的属性值例如红色,蓝色,透明,墨绿色,胡萝卜色等”。
最后本文利用数据集中的类目信息构造问句,见3.1节的数据文件样例。由于一级类目对部分商品无区分度,而二级类目可提供细粒度的商品划分,该类目可帮助模型理解文本围绕讨论的主题。所以使用二级类目和属性类别构造问句,例如属性“颜色”和二级类目“衬衫”对应的问句为“衬衫的颜色是什么”。
3 实验数据和基准系统
3.1 数据集
本文使用的数据来自某电商平台提供的数据资源,主要是标题数据(来自电商网站中商品的标题文本),共有265 401条,平均长度为32,数据文件的格式如表3所示。

表3 数据文件示例Table 3 Example of data file
商品文本是围绕某一特定商品的描述,后面跟有商品所属类目,分别为一级类目和二级类目,二者是上下位关系;以及一份类目属性词典,词典包含有1 910种类目,1 124种属性和25 519种属性值。词典以三元组的方式表示:<类目名称,属性类别,属性值>,属性类别多方面描述类目的特点,每个类目的属性都对应一个或多个属性值。如三元组<衬衫,颜色,蓝色>、<衬衫,风格,潮流> ,“颜色”和“风格”是类目“衬衫”的属性类别,属性值分别是“蓝色”和“潮流”。对不同属性类别出现的不同二元组<属性类别,属性值>进行统计,结果见表4。
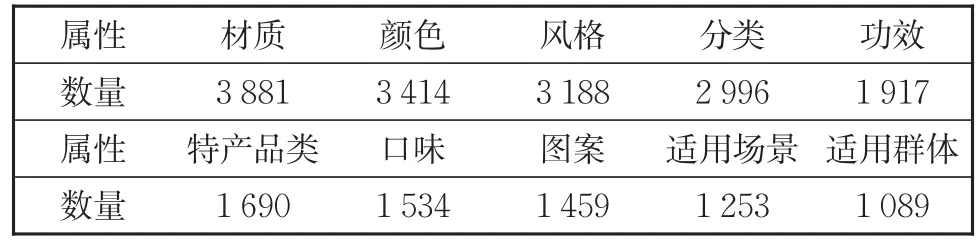
表4 属性二元组统计(只列出前十个)Table 4 Counts on attribute two-tuples(only the top ten are listed)
本文使用类目属性词典运用远程监督的方法构造出两份数据集。两份数据集中,小数据集data-3attr数据量有18 000条,并且只对“材质”“颜色”“风格”三种属性类别进行讨论。为了探索模型在更多属性场景下的能力,提供大数据集data-10attr,数据量达到100 000条,属性类别扩展到十个:“颜色”“风格”“材质”“图案”“功效”“适用群体”“口味”“适用场景”“分类”“特产品类”,并且按照8∶2的比例将两份数据集切分为训练集和开放集。此外,两份数据集中存在1/10的不包含任何属性的句子作为负例,增加模型的鲁棒性。由于远程监督标注数据存在漏标和错标问题,为了精准评估系统性能,由人工标注出一份2 000条的标题数据作为测试集,该数据集中只标注了“颜色”“风格”“材质”三种属性。为了使数据集适合模型处理,将每句按照属性类别分别标注,即一句只含有一种属性的标注信息,例如小数据集的每条数据按照三种属性类别各标注一句共三句,并且对数据进行了筛选。处理后两份数据集的属性值频数分布情况见表5。
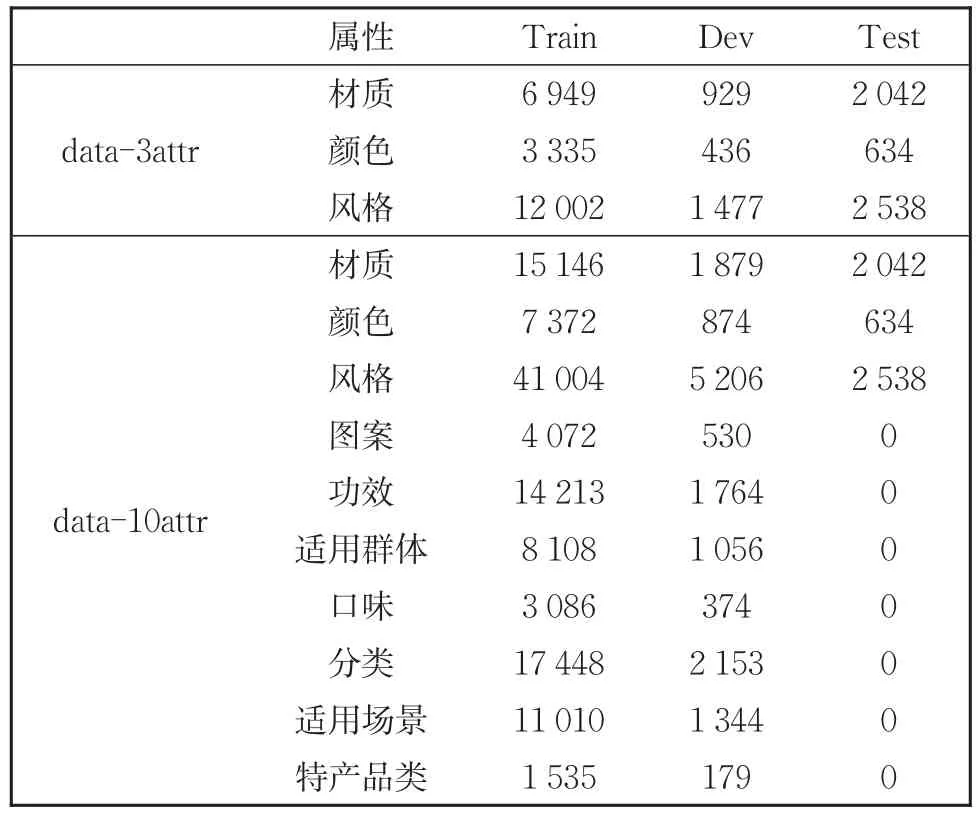
表5 data-3attr和data-10attr属性值统计Table 5 Counts on attrubutes value in data-3attr and data-10attr
3.2 基线模型
BiLSTM--CRF该模型共三层,第一层是词向量层,该层将输入序列的字序列映射成词向量的输入表示。本文使用随机初始化字向量作为词向量层。第二层是BiLSTM层,该层将词向量输入双向LSTM层来捕获序列历史和未来的上下文信息。第三层是CRF层,对BiLSTM层输出的隐层表示进行结构化预测,不同的是对每个属性采用独立的B、I标签。
OpenTag[12]在BiLSTM层和CRF层之间添加了注意力机制。
BERT-Tagger该实验参考Devlin等[14]的工作将属性抽取看作序列标注任务。模型采取单句输入的形式,通过预训练语言模型中层叠的Transformer层学习每个字的上下文表示,最后使用softmax层对输出的隐层表示进行解码。
SUOpenTag(Scaling Up OpenTag)[13]分别使用BERT加上BiLSTM层生成文本和属性的隐层向量表示。在文本隐层向量和属性隐层向量之间采用交叉注意力层连接输出,最后是CRF层。
BiLSTM-CRF、OpenTag和 BERT-Tagger模型都是序列标注模型,它们为每个属性训练单独的模型,因此缺乏可扩展性。SUOpenTag模型被设计用于补充OpenTag以处理大规模属性抽取。本文使用pytorch框架复现四个基线模型。
3.3 参数设置
本文对基线模型的参数设置见表6。本文的模型采用pytorch框架实现,模型超参数通过验证集选择得到,训练时采用批训练方法,批次大小为64,每一隐层输出维度为768,句子最大长度为60。模型的优化使用AdamW方法对参数进行微调和更新,初始学习率为1×10−5,FFNN中的隐层单元的值设置为50。对每个实验取5个随机种子取平均值作为最终实验结果。
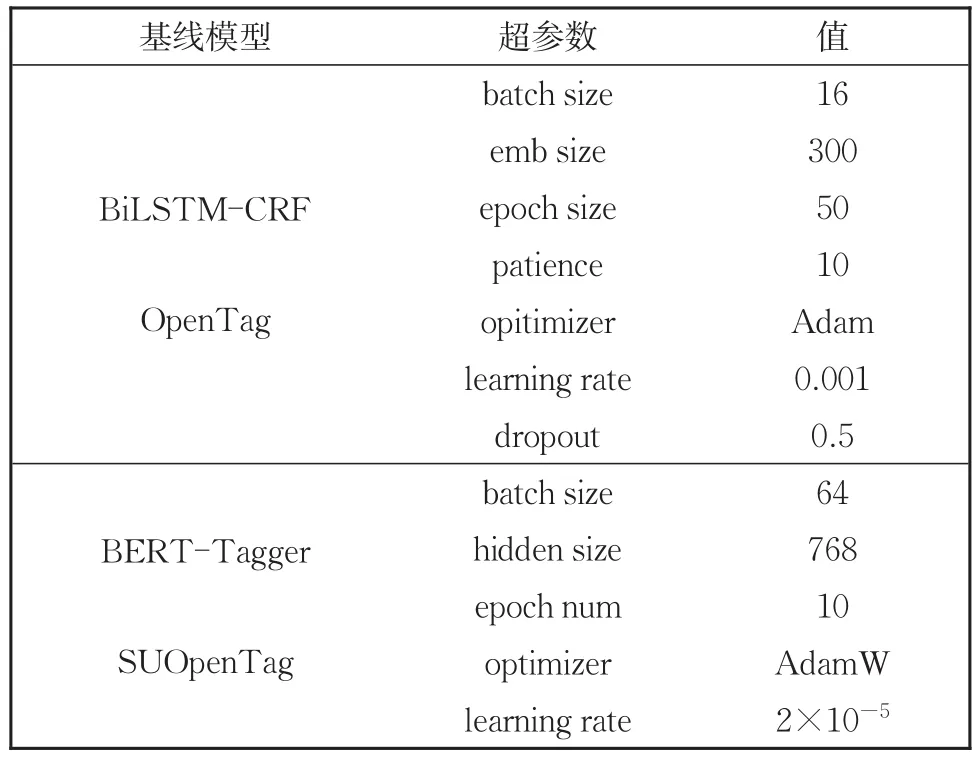
表6 基线模型参数设置Table 6 Parameter settings of baseline models
3.4 评价方法
实验结果采用识别准确率(P)、召回率(R)和两者的调和平均值(F)作为评价标准。对于每一属性,识别准确率是指正确识别的属性占总计识别出的属性的百分比,R指正确识别的属性占测试集中所有属性的百分比,F值是准确率和召回率的调和均值,可以综合考量模型的性能。准确率(P)、召回率(R)和F1值(F)的计算方法如下:
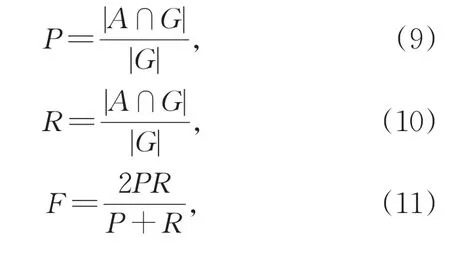
其中,|A|代表识别出的属性值总数,|G|代表测试集的属性值总数,|A∩G|代表识别出的属性与测试集完全匹配的属性值总数。
此外,属性识别任务的目标是发现实体三元组,尤其是发现当前知识库中没有的实体三元组。在本文中,模型发现新实体的能力尤为重要,也是评判模型可泛化性的依据。对于未登录词(OOV),采用识别准确率(P_oov)、召回率(R_oov)和二者的调和平均F1值(F_oov)作为评价标准,计算方式如下:
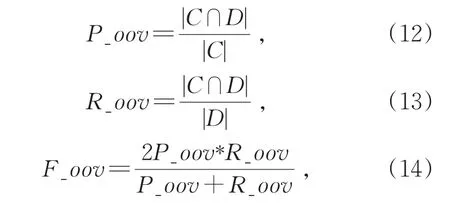
其中,|C|代表识别出的属性值且没在训练集中出现过的总数,|D|代表测试集的属性值且不在训练集中出现过的总数,|C∩D|代表满足两个集合交集中的属性值个数。
4 结果和讨论
本文在不同场景设置下进行了一系列实验,4.1节介绍不同问句方式和不同解码器对模型性能的影响;4.2节介绍MPAR与基线模型在两种数据集上的性能比较;4.3节介绍MPAR与基线模型识别未登陆词的性能比较。
4.1 问句和解码器
实验在data-3attr数据集上进行,比较了不同解码方式及不同问句对模型的影响,表7到表10分别对应 SPAN、softmax、CRF 以及 Biaf⁃fine解码器的结果。
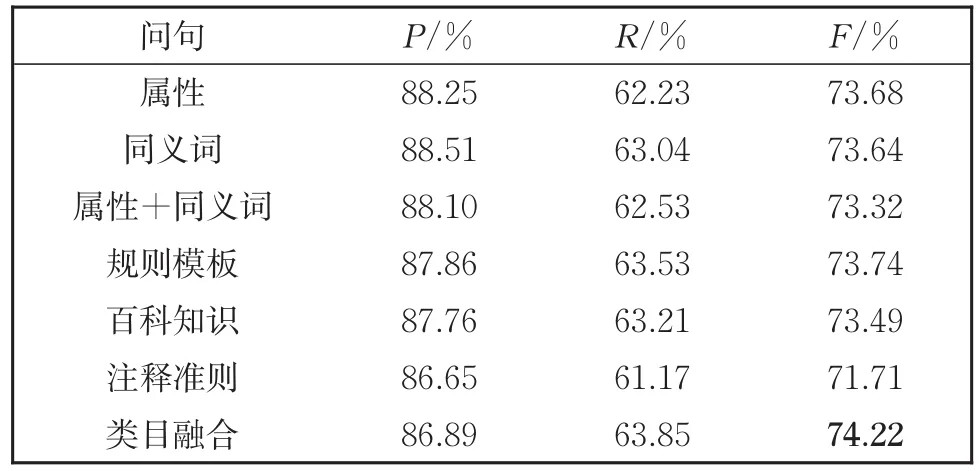
表7 SPAN解码器在不同问句类型上的结果Table 7 Results of SPAN Doceder in differernt types of queries
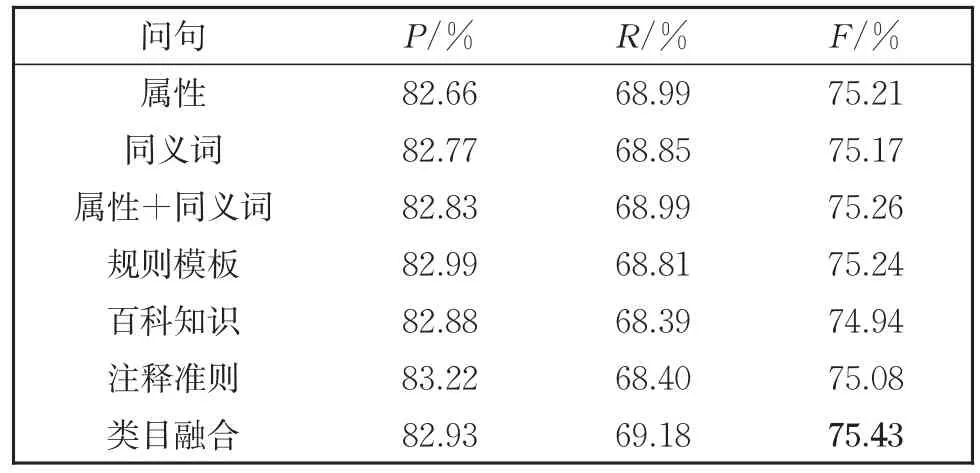
表8 softmax解码器在不同问句类型上的结果Table 8 Results of softmax Decoder in different types of queries
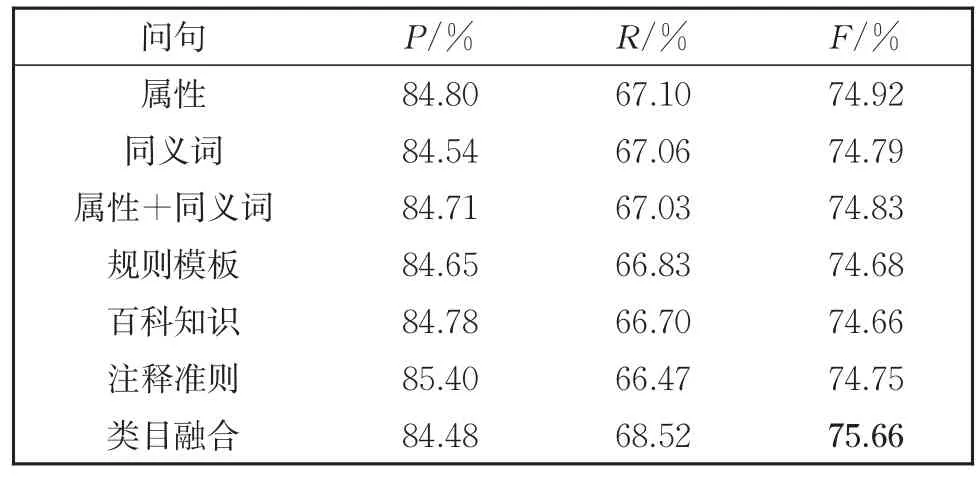
表9 CRF解码器在不同问句类型上的结果Table 9 Results of CRF Decoder in different types of queries
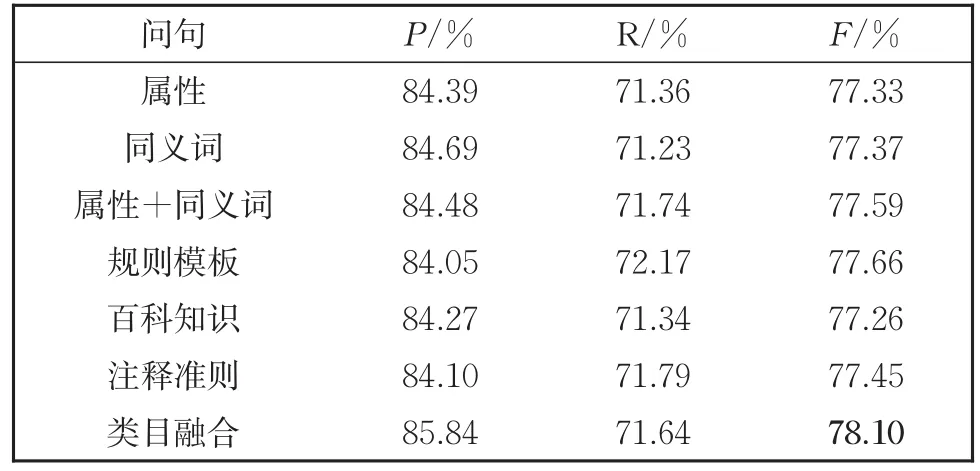
表10 Biaffine解码器在不同问句类型上的结果Table 10 Results of Biaffine Decoder in different types of queries
由实验结果可得以下结论:
(1)以不同解码器为比较对象,原始的SPAN解码器效果最差,来自序列标注的soft⁃max和CRF解码器效果较好,而Biaffine解码器效果最好。
(2)针对由属性、同义词和属性连接同义词构造的问句,同义词的询问方式效果不如直接由属性构造的问句。而属性连接同义词的方式相比于前两种模型性能并没有较大的提升,甚至可能会有所下降。分析是同义词相对于属性本身对语义信息的诠释不够全面,从而干扰到模型学习属性相关知识。
(3)针对复杂问句,规则模板构造的问句呈现出不错的性能,原因是句子较为完整,融入了比较充分的结合属性信息的语义知识。百科知识构造的问句效果不佳,因为百科知识过于宽泛,不能精确地描述出属性的特征。注释准则构造的问句在一定程度上融入了较多的属性信息,但是问句中的特例会影响到模型对其他属性值的判断,因为模型缺少从特殊到一般的学习能力。使用融合类目信息的问句训练模型达到最好的F1值,归结于问句既融入了文本主要提到的商品类目信息,又对需要抽取的属性类别进行提问。
对具体案例进行分析,从表11中列举出的错误案例表明,不同问句方式影响到模型对属性值的识别,属性构造的问句识别能力有限,会出现预测不出实体和预测实体不完整的情况。而类目融合构造的问句融入了文本类目和属性的先验信息,能让模型生成更好的商品文本特征和理解任务语义,从而可以更有效更准确地识别出属性值。

表11 不同问句类型对应的识别结果Table 11 Recognition results corresponding to different types of queries
4.2 性能比较
根据Biaffine解码器和类目融合的问句方式,本文模型MPAR使用该设置。
小数据集上的实验结果见表12。总体上,MPRA在一定程度上表现出优越性,模型在精确率保持稳定的情况下,召回率获得很大提高,F1值也获得比较明显的提升。模型相比于OpenTag模型F1值从70.40%提升到78.10%,相比于SUOpenTag模型F1值提升3.26%。
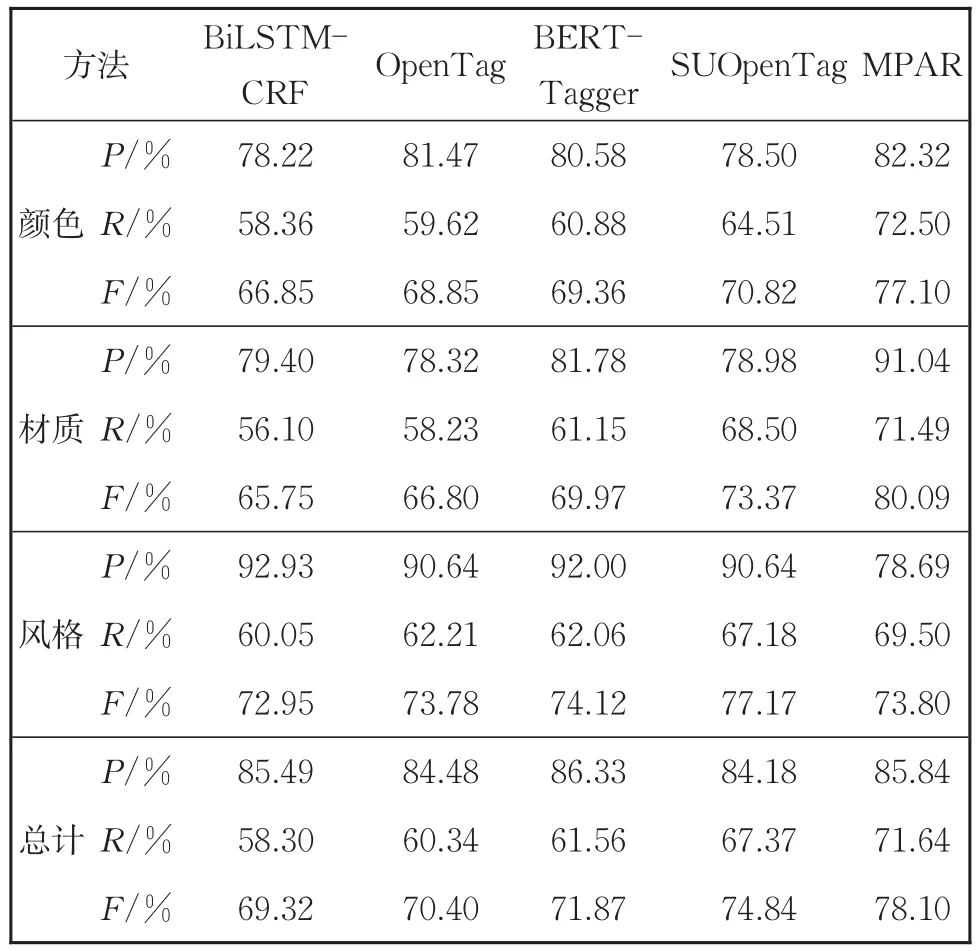
表12 在data-3attr上MPAR和基线模型的结果Table 12 Results of MPAR and baseline model in data-3attr
模型性能的提升来源于两个方面,一是将问句和商品文本一起输入的方式更好地发挥出预训练模型的优势,融合问句给出的先验信息后,编码层通过层叠Transformer层可以学到更好的词嵌入;二是模型的解码层对于预训练模型的隐层向量不局限于序列标注的解码方式,而是采取更为合理的双仿射注意力模型来寻找更为精确的跨度。
在三种属性上,“风格”属性相比于基线模型识别效果持平或有所降低,但是在“颜色”属性上召回率显著上升,在“材质”属性上精确率明显提升,F1值也随之提高。原因是“颜色”“材质”属性特征明显,边界信息易捕捉,所以模型可以识别准确,而“风格”属性语义信息复杂,模型理解困难导致难以识别。
本文在含有更多属性的大数据集data-10at⁃tr上进行了实验,结果见表13。由表13可以发现,5个模型都出现了不同程度的下降,其中,BiLSTM-CRF模型相比于小数据集F1值下降了13.56%,BERT-Tagger模型F1值下降了16.22%,OpenTag模型F1值下降了14.92%,这三个模型由于无法区别不同属性之间的差异而导致模型性能有较大的下降。SUOpen⁃Tag和MPAR因为融入了属性的语义信息,只分别下降了7.92%和9.16%。数据量和属性类别增多后,模型受到的干扰更大,但依然能保持一定的识别准确率和召回率,表明本文模型在面对多属性的情况下依然能保证一定的稳定性。
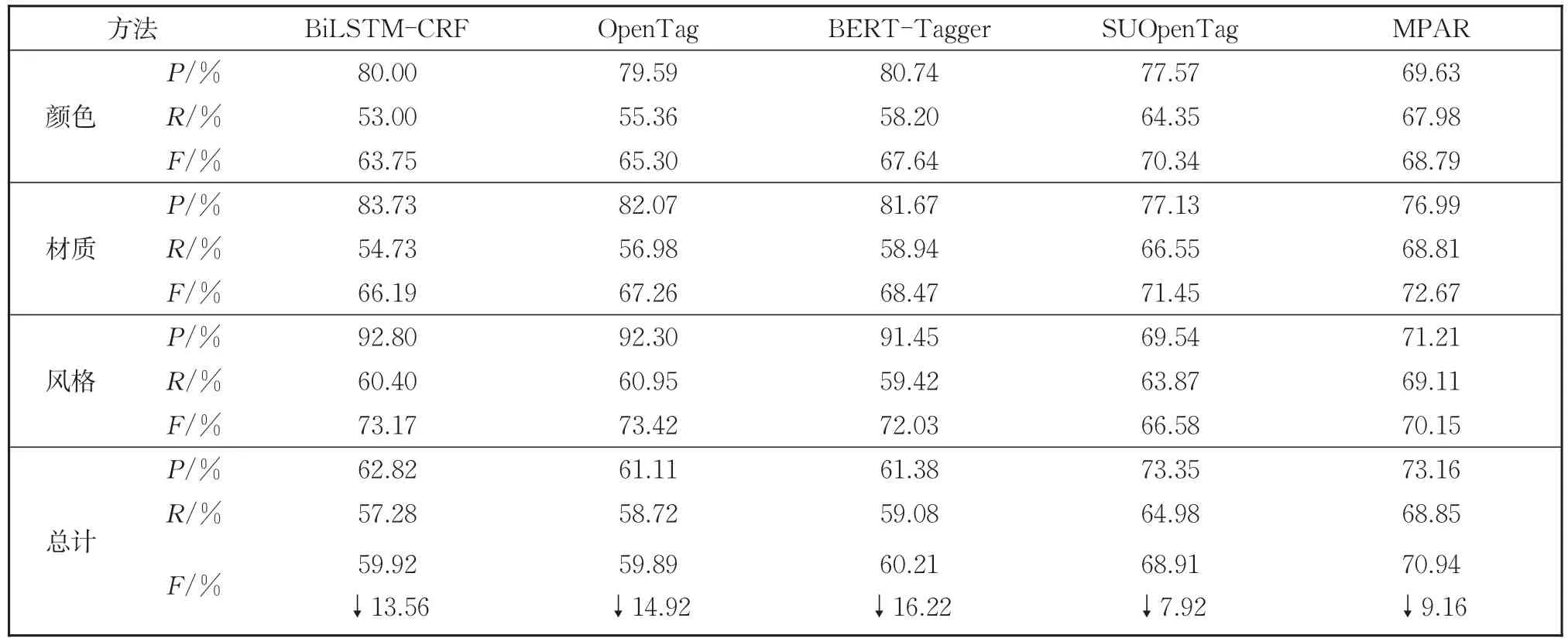
表13 在data-10attr上MPAR和基线模型的结果Table 13 Results of MPAR and baseline model in data-10attr
对具体识别结果进行分析,从表14可以看出,MPAR相比于OpenTag和SUOpenTag模型,可以发现属性特征不明显的属性值,比如句子“大红女款创意超薄保护壳”中的颜色属性值“大红”,句子“贝贝绒加厚夹棉保暖睡衣”中的材质属性值“贝贝绒”,以及句子“细漆皮女士糖果色皮带”中的颜色属性值“糖果色”。由于这些属性值相比于普通的属性值语义信息更为复杂,模型难以理解,导致两个基线模型都不能标注出来,而MPAR结合商品名融合的问句,以及对边界信息敏感的Biaffine,这些属性值都能发现。
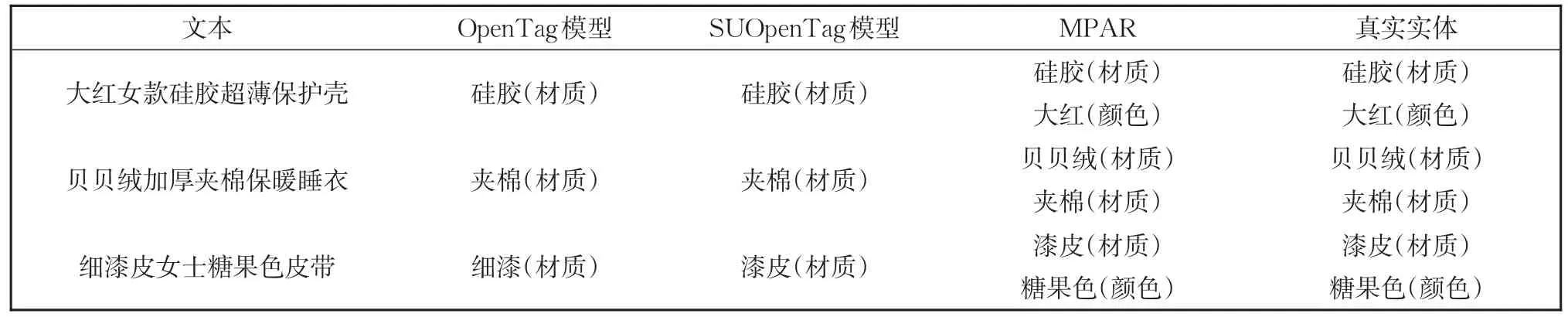
表14 不同模型对应的识别结果Table 14 Recognition results corresponding to different models
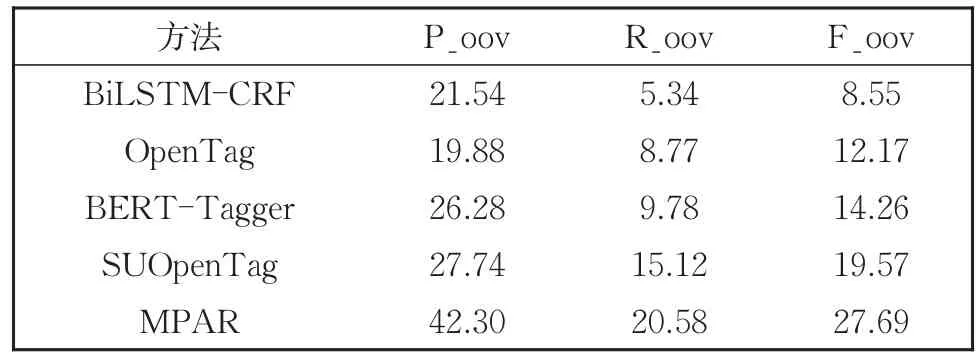
表15 在data-3attr上OOV的结果Table 15 Results of OOV in data-3attr
4.3 识别新实体
为了进一步检验模型发现新实体的能力,使用MPAR和基线模型在小数据集上进行OOV识别能力的比较。
实验结果显示,相比于基线模型,MPAR在未登陆词(OOV)上精确率和召回率都有大幅度的提高,导致F1值(F_oov)也获得相应的提升。模型识别未登陆词的能力来源于两方面,一是Biaffine解码器可帮助模型识别出更多边界信息正确的属性值,二是根据4.2节,模型对具有复杂语义的属性值识别能力更强。由此认为本文模型相比基线模型具有更强的可泛化性。
5 总结和展望
基于电商场景的商品属性抽取往往会面对两个问题,即体量巨大的商品属性和不断涌现的新属性。本文首先提出使用机器阅读理解思路来做属性抽取任务的方法,深度探索不同解码器和不同问句方式对模型性能的影响,并且得到最好的组合方式,即将属性信息融合商品名来构建问句,并使用Biaffine机制为所有可能的跨度分配分数。模型采用唯一的BERT上下文编码器,并在所有属性之间共享。本文的实验结果表明机器阅读理解机制不仅能提高模型性能,也能较好解决模型可扩展性的问题,有理由认为模型具有一定的可泛化性,当遇到以前从未见过的新属性时,模型会从与新属性具有相似语义信息的已有属性中学习知识,由此可以为新属性提取对应的属性值。
未来本文希望可以提高模型在可泛化性上的表现,缓解远程监督带来的错标漏标问题,并且充分利用商品名信息,尝试用多任务学习来训练模型。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
少儿画王(3-6岁)(2020年4期)2020-09-13
家庭影院技术(2019年8期)2019-12-04
东方教育(2018年20期)2018-08-22
卷宗(2016年6期)2016-08-02
中国现代医生(2014年21期)2014-08-27
图书馆界(2011年4期)2011-05-03
微型计算机(2009年4期)2009-12-23
