
基于转移的快速精准的语义依存图分析
2022-08-15 07:10周仕林龚晨李正华张民
山西大学学报(自然科学版) 2022年4期
周仕林,龚晨,李正华,张民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
语义依存图分析[1]的目标是得到句子的语义信息,并以语义依存图的形式来表示。语义依存图借鉴依存句法树的表示方法,以句中的每个词作为节点,不同的是它打破了原先树结构的限制,即一个节点可以有多个父亲节点。另外,相较于依存句法分析关注词之间的语法关系,语义依存图分析更关注词之间的语义关系,它引入了语义角色标注(Semantic Role La⁃beling)[2]中的如“ARG1”“ARG2”“Time”“Lo⁃cation”等语义标签来表示词对间的语义关系,形成语义图结构。可以通过对图中节点与边分析,来回答“谁在什么时间、什么地点,对谁,做了一件什么事情”这样的语义问题。SemEval 2015第18评测任务[3]发布了英语语料上的三种语义依存图表示,分别是DM(DELPH-IN MRS-Derived Bi-Lexical Dependencies)、PSD(Prague Semantic Dependencies)、PAS(Enju Predicate-Argument Structures),图1(a)、1(b)、1(c)分别展示了“He declined to comment”这句话的DM、PSD、PAS表示。
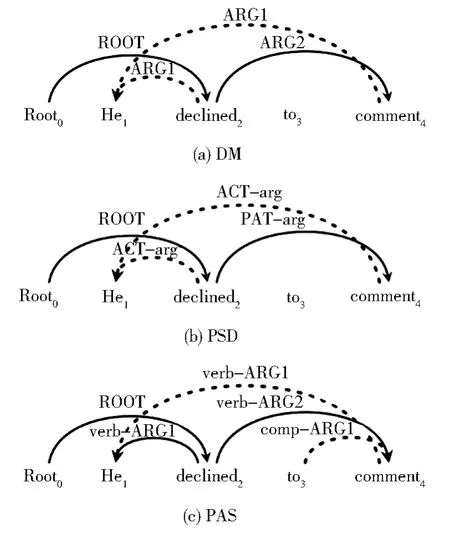
图1 “He declined to comment”的DM、PSD、PAS表示,虚线边指向的词有多个头节点Fig.1 DM,PSD and PAS presentation of the sentence "He declined to comment".The words pointed by dotted edges have multiple heads
因为语义依存图和依存句法树的结构相似,所以现有的方法大多是从依存句法分析的算法扩展而来,主流方法可分为基于图和基于转移的方法。基于图的方法的目标是从句子对应的所有可能的图结构中确定得分最高的图。Dozat和Manning[4]对他们之前提出的依存句法分析器 Biaffine Parser[5]进行扩展,把语义依存图的得分定义为图中边得分之和,将语义依存图分析问题转化为局部地判断句中词对之间是否存在边,他们的系统具有较高的效率和不错的准确率。Wang等[6]在Dozat和Manning的基础上进一步引入了二阶信息,即语义依存图的得分不仅仅由图中每条边的得分组成,而且还要考虑图中兄弟结构、祖孙结构以及双父亲结构的得分,二阶信息的加入,进一步提高了基于图方法的性能。
相比较于基于图的方法寻找得分最高的图,基于转移的算法通过在每一步贪心地选择最好的转移动作,逐步构建语义图,基于图的方法在O(n2)的空间中寻找正确答案,基于转移的方法拥有较低的复杂度O(n)。一般来说,转移系统通常包括一个栈σ,来存储处理过的词;一个缓冲区β,来存储待处理的词;一个记忆区A,来保存已经生成的边;并定义了一个转移动作集合S。在每一步,模型综合根据σ、β以及A的状态从S中选择下一步的转移动作,之后根据转移动作修改状态。不断重复这个过程,直到β为空,即处理完了句中的所有词。本文主要研究基于转移的方法。
对转移状态建模是每个转移算法都要考虑的问题,状态的表示好坏与否很大程度上影响着模型能否做出正确的决定。现有的方法(Wang 等[6],Che等[7])大都使用 Stack-LSTM(Stack Long Short-Term Memory)[8]或 者 Tree-LSTM(Tree Long Short-Term Memory)[9]单独对栈、缓冲区进行表示。这些方法充分考虑了栈、缓冲区内部的结构信息,但是单独对栈、缓冲区进行建模的方法割裂了句子语义上的前后完整性。另外,使用Stack-LSTM、Tree-LSTM在转移过程的每一步需要大量计算得到状态的新的表示,这限制了模型的训练和解码的速度。所以,针对上述问题,本文设计了一个基于原子特征来表示转移状态的简单有效的模型,模型对每个句子只需要进行一次编码,不需要额外的计算来得到状态的表示。
基于转移的方法在每一步贪心地选择当前最优的转移动作,这难免会造成错误传播问题。错误传播就是模型在预测时在某一步做出了错误的决定,那么在之后的预测中模型可能会做出更多的错误决定。特别是当模型仅使用唯一的转移动作序列训练时,这个问题会更为严重。这是因为在训练时,模型是直接从训练数据中得到下一步的转移动作,而在真正分析时,模型却是根据自己的判断来选择下一步的动作,这种来源的差异性也叫作暴露偏置(ex⁃posure bias)[10]。所以若是模型在预测时做出了错误的决定,进入到在训练时未见过的状态,这可能会使得模型之后的决定更不合理。当测试数据与训练数据的分布差异较大时,如训练数据和测试数据来自不同领域时,模型的性能会进一步降低。针对基于转移的语义依存图分析的错误传播问题,本文借鉴Goldberg and Nivre[11]在依存句法分析上的工作,首次在语义依存图分析中使用动态Oracle训练模型,来提高模型的准确率。
另外,虽然基于转移的方法在理论上拥有O(n)级别的低复杂度,但是转移系统在对每个语句建立语义依存图时所需要的转移动作的数量不同,且在转移的每一步针对每个句子所执行的转移动作也不尽相同,这都对转移系统的批量化处理造成了困难,限制了转移模型的效率。而且,如果模型要使用动态Oracle训练,这会使训练模型需要耗费更长的时间。所以针对上述问题,本文基于掩码技术,通过将每个批次转化为多个动作批次,实现了基于转移方法的批量化训练和解码,大幅度提高了模型的效率。
本文针对语义依存图分析任务,基于Wang等[6]的转移算法,设计了一个更加简单有效的神经网络模型,在每一步用原子特征对状态进行表示而不需要额外的计算,并且实现了对数据的批量化处理。本文首次在语义依存图分析的训练阶段采用动态Oracle来缓解基于转移方法的错误传播问题。另外,还利用预训练语言模型BERT(Bidirectional Encoder Representations from Transformers)[12]进一步增强模型的性能。在SemEval-2015-task18数据集上的实验表明,利用原子特征和动态Oracle的方法大幅度提升了基于转移方法的性能和解码速度,达到了与目前最佳模型相当的结果。代码将会发布在https://github.com/zsLin177/FAT-sdp。
1 研究方法
1.1 转移系统
转移系统通常包括一个栈σ,来存储处理过的词;一个缓冲区β,来存储待处理的词;一个记忆区A,来保存已经生成的边;并定义了一个转移动作集合S。给定输入句子X,基于转移的语义依存图分析在每一步根据当前的转移状态c,从转移动作集合S中选择正确的转移动作t,再根据挑选的转移动作得到新的转移状态t(c)。不断重复这个过程,直到得到一个终结状态,此时的A就是X对应的语义依存图。本文使用的是Wang等[6]的转移系统,系统除了拥有栈σ、缓冲区β以及记忆区A外,还有一个临时双端队列δ用来存储临时从σ中弹出、在之后还需要放回σ的词。系统用一个四元组(σ,δ,β,A) 表示一个状态,初始状态为([0],[],[1,…,n],∅),终结状态为(σ,δ,[],A)①用下标k表示输入句子X的第k个词wk,w0表示人为设置的根节点Root,n是X的长度。系统定义了以下七种转移动作(为方便描述各个转移动作执行的操作,我们把状态记为 ([σ|k],[δ],[j|β],A),其中k和j分别表示栈顶和缓冲区第一个词):


利用上述转移系统可以得到图1(a)所示例子的完整的转移过程见表1。

表1 图1(a)所示语义依存图的完整转移动作序列Table 1 Entire transition sequence corresponding to the graph in Fig.1(a)
1.2 模型结构
图2展示了模型的总体结构。Dyer等[8]和Wang 等[6]使用 Stack-LSTM 或 Tree-LSTM 来分别对每个结构进行建模,这种方式破坏了句子语义的前后完整性,且在解析的每一步都需要进行大量的计算才能得到状态的表示。与之不同,本文直接使用传统的3层BiLSTM(Bidi⁃rectional Long Short-Term Memory)一次性编码完整的一句话。此外,在按照转移算法人工地去决定每一步的转移动作时,更多关注每个结构的关键位置,即栈σ的栈顶词、双端队列δ的第一个词、缓冲区β的第一个词以及上一步的转移动作t−1,所以本文通过抽取每个结构的关键位置的特征来表示当前状态,并把这种特征叫作原子特征。

图2 模型结构图Fig.2 Architecture of our model
模型使用3层BiLSTM作为编码器,编码器的输入是句子X中每个词wi对应的词嵌入向量ei,输出是经过BiLSTM的隐藏向量hi。输入向量ei是由字符向量、词向量、词性向量和词根向量拼接组成,如公式1所示。
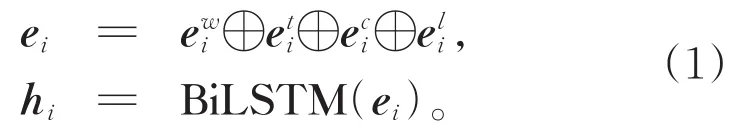
每一步的状态表示由栈σ的栈顶词k、双端队列δ的第一个词i、缓冲区β的第一个词j所对应的隐藏向量以及上一步的转移动作所对应的向量表示拼接而成。

其中,hk、hi、hj分别表示σ的栈顶词、δ的第一个词、β的第一个词对应的隐藏向量,ep表示上一步执行的转移动作对应的向量表示。
图2显示的是表1中第3步对应状态为([0],[1],[2,3,4])情形:栈顶词为根节点Root,双端队列的第一个词为输入X中第一个词“He”,缓冲区第一个词为X中第二个词“de⁃clined”,上一步的转移动作为LEFT-PASS,所以这一步的状态表示z=h0⊕h1⊕h2⊕eL-P。
受基于图的biaffine parser将边预测和标签预测分为两个阶段启发,解码器也用两个多层感知机MLPa、MLPl分别预测转移的动作和标签。对于没有标签的动作:SHIFT、REDUCE、PASS,设置了一个空标签NULL来表示该动作没有标签,这也为批量化操作提供了方便。
1.3 训练
在模型的最后的一层,通过softmax函数得到在给定输入Xm,且当前状态表示为zi时,转移动作t的概率和标签l的概率Pθ(t|zi,Xm),Pθ(l|zi,Xm),通过在每一步最大化正确转移动作及其标签①根据训练时所使用的Oracle不同,正确的目标也不同的概率来训练模型。目标函数可以表示为:

其中,N表示训练集中实例的数量,nm表示对第m个句子分析所需要的转移动作的总数,θ表示模型的参数。根据转移动作的来源,训练可以分为使用静态Oracle训练和使用动态Ora⁃cle训练。
1.3.1 使用静态Oracle训练
首先,根据 Goldberg and Nivre[11]的定义,可以认为Oracle是一个函数O,该函数在给定当前状态c和句子的正确语义依存图G的情况下,返回下一步应该执行的转移动作t。从初始状态开始,到终结状态结束,得到每一步执行的转移动作,构成一个转移动作序列T。

静态Oracle定义了从初始状态到终结状态的唯一正确路径Ts=t1,t2,…,tn,并得到了从初始状态到终结状态的一个状态序列Cs=c1,c2,…,cn+1,其中c1,cn+1分别为初始状态和终结状态,且ci=ti−1(…(t2(t1(c1))))。静态 Oracle只能针对Cs中的状态ci,给出下一步正确的转移动作ti,对于不在C中那些错误状态,静态Oracle并没有给出定义。所以若是在第i步执行了Ts之外的转移动作t*,从而进入一个陌生的状态t*(ci),静态Oracle就不能给出应执行的转移动作。
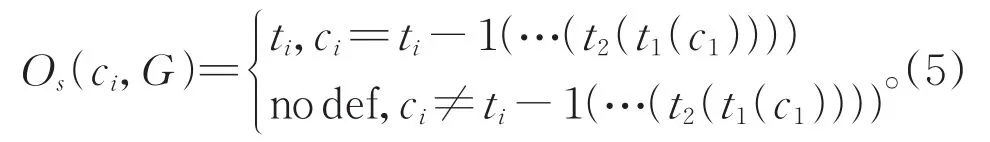
通常基于转移的系统(Wang等[6],Lai等[13])都是使用静态 OracleOs来训练模型,在训练的时候强制模型沿着静态Oracle的唯一正确路径Ts=t1,t2,…,tn去学习,第i步的正确目标就是ti,对应公式3中tic=ti。模型总是在训练集上做着正确的决定,这不可避免地会造成模型在训练集上过拟合,在预测时若是在某一步模型做出了错误的决定,那在之后的步骤中模型可能会做出更多错误的决定,使最终得到的语义依存图和预期越来越远。
1.3.2 使用动态Oracle训练
使用静态Oracle训练时,模型都被强制沿着单一的一条正确路径学习,而在预测时模型可能采取错误的转移动作,所以为了提高模型预测的准确率、缓解错误传播问题,本文首次在语义依存图分析中使用动态Oracle训练策略。动态Oracle最直接的想法就是让模型在训练的时候适当地模拟预测时场景,降低因为暴露偏置而导致的错误累积问题。这就要求在训练时能给出在任何状态下模型的优化目标。也就是说,若是在某一步模型执行了一个错误的转移动作t*,因此进入了一个错误的状态t*(c),要做的就是让模型之后不再做出更多错误的决定,不让损失继续扩大。这是传统的静态Oracle所做不到的,需要使用更强大的动态Oracle。
动态Oracle对转移过程中的所有状态都进行定义。转移系统在当前状态c执行转移动作t*达到一个陌生状态t*(c),这也许得不到正确的语义图G,从而造成一定的损失。直觉上,需要之后执行的转移动作能够降低造成的损失,或者至少不能使损失扩大。所以,在给出动态Oracle之前,需要先引入两个损失函数,分别是图与图之间的损失L(A,G)和在当前状态$c$执行某一转移动作所造成的损失L(t,c,G)。对 于L(A,G),沿 用 Goldberg and Nivre[11]中 的Hamming loss,这与最终的评价指标F1值是直接相关的,且也较为方便。对于在当前状态c执行某一转移动作t所造成的损失L(t,c,G),将在L(A,G)的基础上定义,即:
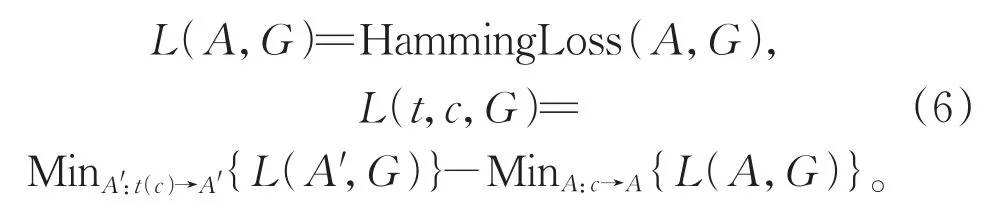
MinA:c→AL(A,G)表示从状态c所能得到的最优图A与正确图G之间的损失。默认转移动作没有撤销操作,即已经造成的损失不能被挽回,所以L(t,c,G)都大于等于 0。定义动态 Or⁃acle返回的是不会造成损失的动作集合,即:

因为在每一步都需要根据当前状态返回Od(ci,G),所以需要高效快速的计算方法。注意到在具体实验操作中,需要关注的是在当前状态采取哪些转移动作不会造成进一步的损失,即当前状态下哪些转移动作t满足L(t,ci,G)=0,并不需要关注执行某个转移动作造成的损失具体是多少。比如在表1第3个状态c=([0],[1],[2,3,4]),且标准语义图 G为图1(a)时,需要判断REDUCE动作是否属于Od(c,G),先假设执行动作REDUCE,那么根节点“Root”就会被永久地删除,这也意味着之后的转移操作中不会再有与“Root”节点有关的边,而标注语义图G存在着一条由“Root”指向“declined”的边,若是执行REDUCE动作将“Root”删除了,这使得在之后都不可能产生造成损失,所以REDUCE不属于Od(c,G)。具体对所有转移动作的损失计算见表2,记当前状态为([σ|k],[δ],[j|β],A)。

表2 动态Oracle的具体计算方法Table 2 Specific computations of dynamic oracle
最直接使用动态Oracle的方法就是探索式训练(Training with exploration),在训练的前q个循环中采用静态Oracle训练,在之后的循环中在让模型在每一步以p的概率去执行模型预测的转移动作。本文对算法进行略微的修改,使得其支持神经网络模型的训练,见图3。①我们也尝试过优化Od(c,G)中所有的目标[36],但是最终的结果并没有只优化Od(c,G)中最佳的转移动作好。
1.4 批量化训练与解码
基于转移的语义依存图分析通过在每一步执行不同的转移动作来达到终结状态。根据输入句子的不同,所需要的转移动作的总数不同,且在每一步执行的转移动作也不尽相同。这就给转移方法的批量化训练和解码造成了困难。

图3 探索式训练算法Fig.3 Algorithm of training with exploration
这个问题在使用静态Oracle进行训练的时候,可以通过预处理策略很好地解决。按照静态Oracle的规则,预先处理得到数据集中每个输入的转移动作序列和状态序列。用空状态和空操作分别填充状态和动作序列,使一个批次中每个输入的转移动作序列和状态序列长度相同。这样,在训练时可以直接并行化对批次中的输入状态进行建模,并用对应的正确的转移动作指导模型的训练。
但是在预测解码和使用动态Oracle训练时,因为预先不知道要执行什么转移动作,所以不可以如静态Oracle那样使用预处理策略。为了让模型能够支持批量化动态Oracle训练和解码,本文通过使用掩码技术,根据转移动作的数量,设置了相同数量的转移动作过滤器。通过使用转移动作过滤器,将数据级的批次转化为操作级的批次,即将一个批次中的输入样例分成了多个小批次,每个小批次中的样例执行相同的转移动作。如图4所示,在每一步,先通过一个是否结束过滤器(finish filter)来得到批次中还未完成的输入(unfinishx),然后再根据各个输入在当前步骤要执行的转移动作②各样例要执行的动作来自模型的预测(解码时)或者动态Oracle(训练时)。,用对应的转移动作过滤器,将该批次的数据分为操作级批次,如通过LEFT-PASS(LP)、RIGHT-PASS(RS)过滤器分别得到需要执行这两个动作的批次need LPx、need RSx,相同的操作批次中的数据可以并行化操作。
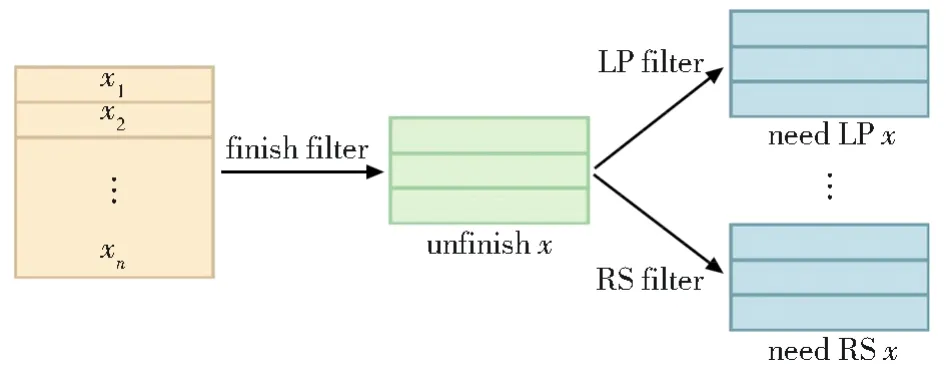
图4 批量化处理Fig.4 Framework of batch process
2 实验
2.1 实验数据和设置
本文在SemEval-2015-task18数据集上进行实验。该数据集包括对相同语料的三种不同语义依存图表示,分别是 DM[14]、PSD[15]、PAS[16]。本文沿用前人工作的数据分割方法[17-18],将来自华尔街日报(WSJ)[19]0 到 19 部分的33 964条句子作为训练集,第20部分的1 692条句子作为开发集,第21部分的1 410条句子作为领域内(in-domain)测试集,另外还有1 849条来自布朗语料库(Brown Corpus)的句子作为跨领域(out-of-domain)测试集。和之前的研究工作一样,本文使用边级别LF1值(La⁃beledF1-score)来作为评价指标。
本文基于SuPar①https://github.com/yzhangcs/parser来实现模型,并使用Adam优化器[20]来训练模型。将训练集中出现次数低于7次的词设为未知词,使用100维的GloVe预训练词向量[21]与随机初始化的词向量相加作为词向量,并使用随机初始化的词性向量(Pos embedding)、词根向量(Lemma embedding)和根据BiLSTM得到字符向量(Char embed⁃ding)作为额外输入信息。本文并没有过多地去调试模型的参数,而是沿用了Dozat and Man⁃ning[4]的大部分参数设定。对于探索式训练中的参数q和p的选择,根据 Goldberg and Nivre[11]的结论,q越小、p越大往往得到的效果越好,所以设置q=10,p=0.8。另外,也使用预训练语言模型bert-base-cased②https://github.com/huggingface/transformers来得到词的上下文表示作为固定的额外输入信息(并没有在任务或者数据上微调),来提高模型的性能。具体的参数设置见表3。

表3 实验参数Table 3 Detailed parameters used in experiments
2.2 结果与分析
2.2.1 与前人工作的对比
表4给出了本文工作与前人工作的比较,其中AVG表示在DM、PAS、PSD三种语义依存图表示上的平均结果,ID(in-domain)、OOD(out-of-domain)分别表示在领域内和跨领域测试集上的结果。为了公平地与前人的工作比较,表4分成了三块,分别是只使用词性(pos)信息作为额外的输入;使用词性(pos)、词根(lemma)、字符(char)信息;在词性、词根、字符的基础上再使用预训练语言模型BERT或者Flair[22](一个字符级上下文表示)。 用 Gb(Graph-based)表示该方法是基于图的、Tb(Transition-based)表示基于转移的、O(Other)表示其他混合方法③关于混合方法具体见3.1的介绍。。ID、OOD分别表示同领域和跨领域测试,MT、Ens分别表示使用多任务学习框架和使用集成模型。

表4 我们的工作与前人工作在SemEval 2015 Task 18测试集上的比较Table 4 Comparison with previous works on SemEval 2015 Task 18 dataset
从表中可以看到本文方法超过了所有基于转移的方法,使用原子特征表示状态的方法与Wang et al.[6]使用 Tree-LSTM 相比,在只用词性信息作为额外输入的情况下平均提升1.8%(ID)、2.7%(OOD),有效提升了基于转移方法的性能,拉近了与基于图方法之间的性能差距。一个可能的解释是原子特征因为是对句子整体进行编码,相比较于使用Tree-LSTM独立编码各个结构,原子特征更注重句子的整体特征,且原子特征在决定转移动作时相比Tree-LSTM更关注影响预测的关键位置,如栈的头部,减少了在预测时的噪声,提高了预测准确率。在只使用词性信息时,本文方法落后于基于图最先进方法0.7%(ID)、0.8%(OOD),而在同时使用词性、字符、词根信息时,这个差距被缩小到了0.3%(ID)、0.4%(OOD)。最后再加上利用BERT得到的上下文词信息后,本文模型达到了与目前最先进模型相当的结果。随着额外信息的增加,与基于图最先进方法的差距逐渐减少,这种现象归因于解码器的差异。因为编码器结构与基于图方法相似,但是在解码器端基于图的方法使用Biaffine attention[5]在同样的表示空间去判断两词之间是否存在边,而直接使用多层感知机从状态空间映射到转移动作空间,不同空间的映射往往比相同空间的映射更难。所以通过使用额外的信息(字符、词根、BERT),增强了模型的解码器,拉近了与基于图方法之间的差距。
2.2.2 动态Oracle和静态Oracle
为了分析动态Oracle对模型性能的提升,本文在仅使用词性、字符和词根信息的模型(Basic)和利用BERT的模型上,比较了使用静态Oracle训练和使用动态Oracle训练的结果,具体结果见表5。可以发现使用动态Ora⁃cle在不同的基线模型上都有提升,这体现了动态Oracle带来提升的稳定性。动态Oracle在BERT基线模型上的提升略微低于普通模型,这是因为在使用BERT增强模型后,模型预测转移动作的准确率更高,相应的错误传播也就更少,动态Oracle的作用也就更低。另外,通过比较领域内和跨领域结果也可以发现,使用动态Oracle在跨领域测试集上的提升高于领域内测试集。这是因为跨领域测试集的数据分布和训练数据有着较大差异,模型在对跨领域数据建立语义依存图的时候更容易发生错误,所以动态Oracle也就更能发挥作用。

表5 动态Oracle与静态Oracle对比Table 5 Comparison between dynamic oracle and static oracle
图5给出了使用动态Oracle训练的模型和使用静态Oracle训练的模型在解码时的一个实例对比,能够更直观地看到动态Oracle相比于静态Oracle带来的提升。可以看到两个模型在c2预测下一个转移动作时都发生了错误,错误地预测出LEFTARG1-REDUCE转移动作,得到了错误状态c3。由于静态Oracle在训练时都是使用固定的正确转移动作序列作为训练的目标,而当前状态c3并未出现在正确转移序列中,这让使用静态Oracle训练的陷入了陌生的状态,导致接下来预测出SHIFT动作,得到了状态sc4而丢失了这条弧。但是使用动态Ora⁃cle训练的模型因为在训练时按照一定概率使用预测出的状态作为输入,且使用由动态Ora⁃cle计算得到的Od(c3,G)作为训练目标,尽可能减少损失,所以在下一步模型预测出的是RIGHTROOT-SHIFT保留了应该存在的这条弧,由此减少了错误的传播。

图5 动态oracle与静态oracle在解码时的一个实例对比Fig.5 An example of comparison between dynamic oracle and static oracle in decoding
2.2.3 批量化对速度的影响
为了比较批量化方法的效果,在DM的ID测试集上进行实验,实验结果是在一块TITAN Xp(12 GB)上三次平均得到的结果。分别比较了模型的训练时间Training Time(mins/epoch)和解码速度Decode Speed(tokens/s)。从表6的第三行中可以看到批量化操作使训练速度提升为原先的6倍,解码速度也变为原先的14倍,大幅度缩短了模型训练所需的时间,提高了模型的解码效率。

表6 模型在DM训练集上的训练时间(mins/epoch)和DM ID测试集上的解码速度(tokens/s)Table 6 Training time(mins/epoch)of the model on the DM training set and the decoding speed(tokens/s)on the DM ID test set
另外还比较了模型与前人模型的解码效率。从速度比较结果中可以发现,模型的解码速度相较于Wang等[6]大约提升了19倍,大幅度提高了基于转移方法的语义依存图分析的解码速度,且超过了Lindemann等[27]使用指针网络(混合方法)的速度。另外,也实现了Dozat and Manning[4]基于图的方法,因为他们将选择得分最高图的任务转化为局部判断词对间是否存在边的二分类任务,大大降低了计算空间,所以他们模型的解码效率极高,从实验结果中可以看出本文方法大幅拉近了基于转移方法与这种基于图的方法的差距,但是从表4中的结果看出他们的基于图的方法在仅使用词性信息和使用词性、字符、词根信息的情况下的结果都低于本文方法。
3 相关工作
3.1 语义依存图分析
语义依存图分析有基于转移、基于图以及一些混合的方法。Wang等[6]提出了一个使用Stack-LSTM来建模状态的纯基于转移的方法。CoNLL 2019[28]和 CoNLL 2020[29]公开评测是针对 AMR[30]、UCCA[31]等不同语义表示的评测任务,在这些评测中也有一些针对语义依存图分析的转移方法,Che等[7]使用BERT预训练语言模型改进了Wang等[6]的方法,另外,他们还通过设置转移动作缓冲区,来存储不同转移动作,等缓冲区满后,再将相同的转移动作一起执行,加快了训练速度。与上述工作不同,本文直接通过不同的转移动作过滤器,直接得到操作级批次,不需要等待,所以系统的效率也相对更高。Lai等[13]借鉴 Daniel and Car⁃los[32]的成分句法转移系统,但需要将图结构转化为树结构去处理。
Peng等[23]提出了一个基于图的方法,将图的分数分解为所包含的所有谓词的得分、边的得分以及边上标签的得分总和。其采用典型的编码器-解码器结构,先用BiLSTM编码句子,然后通过多层感知器计算所有得分,解码时AD3(近似对偶分解解码)算法得到最优图。Dozat and Manning[4]在他们之前提出的依存句法分析器Biaffine Parser的基础上提出了一个简单高效的语义依存图分析器,将语义依存图分析问题分解为判断两词间是否存在边和预测边的标签两个模块。预测时,首先计算每条边的分值,只保留分值大于0的边,从而得到不带标签的最优图;然后再预测图中每条边对应的标签,这种方法也成为基于图的主流方法。之后在 Dozat and Manning的基础上 Wang等[24]引入高阶特征,并使用变分推断近似解码;He and Choi[26]同时使用词级别的上下文表示BERT[12]和字符级的表示Flair[22]来进一步提高模型的性能。
Daniel and Carlos[25]和 Lindemann 等[27]借鉴Ma等[33]在依存句法分析上的工作,使用指针网络(Pointer Network)[34]将传统的基于转移的语义依存图分析任务转化为局部头选择任务。他们不使用传统的转移算法(没有栈、缓冲区等结构),而使用指针网络从左往右地,在每一步为当前词选择一个父亲节点,直到已经找到当前词的所有父亲节点再对下一个词选择父亲节点。这与基于图的方法一次性为词选择父亲节点十分相似,可将这类方法归为基于转移和基于图的混合方法。
3.2 动态Oracle
Goldberg and Nivre[11]首次在依存句法分析任务中引入动态Oracle来缓解基于转移方法的错误传播问题。Tokgöz and Eryiǧit[35]使用动态Oracle策略训练一个有向无环图(DAG)解析器,但转移系统需要预处理步骤来支持生成图中非投影边,且模型使用的是手工设计的特征而不是使用神经网络提取的抽象特征。Balles⁃teros等[36]和 Cross and Huang[37]分别在依存句法分析和成分句法分析中使用动态Oracle训练神经网络模型,来提高各自模型的性能。Yuan等[38]针对依存句法分析任务,训练从左向右和从右往左两个转移模型,在解码阶段迭代地以其中一个模型的分析结果作为正确结果,用动态Oracle策略来指导另一个模型解码,直到两个模型的解码结果相同,以此来缓解错误传播问题。
4 结论
本文提出了一个使用原子特征的快速精准的基于转移的语义依存图分析模型,首次在语义依存图分析中使用动态Oracle训练策略缓解基于转移方法的错误传播问题,提高了模型的准确率,超过了所有基于转移的方法,验证了动态Oracle在语义依存图分析上的有效性,并且也实现了转移方法的批量化训练和解码算法,大幅度提高了基于转移方法的效率。未来将考虑在更多语言的数据集上验证方法的有效性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
成都体育学院学报(2021年1期)2021-07-16
南方周末(2019-12-19)2019-12-19
中国外汇(2019年19期)2019-11-26
南方周末(2019-07-18)2019-07-18
阅读(低年级)(2019年4期)2019-05-20
南方周末(2019-05-09)2019-05-09
长江学术(2016年4期)2016-03-11
